Livepeer: كيفية تقديم حوسبة الفيديو بالذكاء الاصطناعي على شبكة Livepeer
لقد حان الوقت لجلب إمكانات حوسبة الفيديو المدعومة بالذكاء الاصطناعي إلى Livepeer
 JinseFinance
JinseFinance

المؤلف: ساخر، شيجيرو
المقدمة:باستخدام قوة الخوارزميات وقوة الحوسبة والبيانات، فإن تقدم تكنولوجيا الذكاء الاصطناعي يعيد تعريف معالجة البيانات والذكاء حدود اتخاذ القرار وفي الوقت نفسه، يمثل DePIN نقلة نوعية من البنية التحتية المركزية إلى الشبكات اللامركزية القائمة على blockchain.
مع استمرار العالم في التسارع نحو التحول الرقمي، أصبح الذكاء الاصطناعي وDePIN (البنية التحتية المادية اللامركزية) القوة الدافعة للتغيير في جميع مناحي الحياة. التكنولوجيا الأساسية. لن يؤدي تكامل الذكاء الاصطناعي وDePIN إلى تعزيز التكرار السريع والتطبيق الواسع النطاق للتكنولوجيا فحسب، بل سيفتح أيضًا نموذج خدمة أكثر أمانًا وشفافية وكفاءة، مما يؤدي إلى تغييرات بعيدة المدى في الاقتصاد العالمي.
DePIN: تتحول اللامركزية من افتراضية إلى حقيقية، وهي الدعامة الأساسية للاقتصاد الرقمي
DePIN هو اختصار للبنية التحتية المادية اللامركزية. بالمعنى الضيق، يشير DePIN بشكل أساسي إلى الشبكة الموزعة للبنية التحتية المادية التقليدية المدعومة بتكنولوجيا دفتر الأستاذ الموزع، مثل شبكة الطاقة وشبكة الاتصالات وشبكة تحديد المواقع وما إلى ذلك. بشكل عام، يمكن تسمية جميع الشبكات الموزعة التي تدعمها الأجهزة المادية باسم DePIN، مثل شبكات التخزين وشبكات الحوسبة.
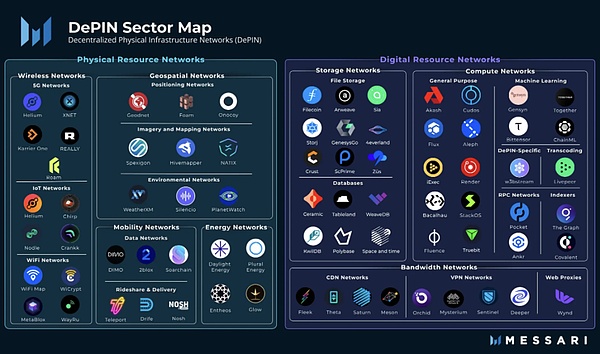
من: Messari
إذا كان التشفير قد أحدث تغييرات في المركزية، فإن DePIN هو الحل اللامركزي في الاقتصاد الحقيقي. يمكن القول أن آلة التعدين PoW هي نوع من DePIN. لقد كان DePIN أحد الركائز الأساسية لـ Web3 منذ اليوم الأول.
من بين العناصر الثلاثة للذكاء الاصطناعي - الخوارزمية وقوة الحوسبة والبيانات، تمتلك DePIN حصريًا اثنين منها
< p style="text -align: left;">يعتبر تطوير الذكاء الاصطناعي بشكل عام يعتمد على ثلاثة عناصر رئيسية: الخوارزميات وقوة الحوسبة والبيانات. تشير الخوارزميات إلى النماذج الرياضية ومنطق البرامج الذي يحرك أنظمة الذكاء الاصطناعي، وتشير قوة الحوسبة إلى موارد الحوسبة المطلوبة لتنفيذ هذه الخوارزميات، والبيانات هي الأساس للتدريب وتحسين نماذج الذكاء الاصطناعي.
أي العناصر الثلاثة هو الأكثر أهمية؟ قبل ظهور chatGPT، كان الناس عادة ما يعتبرونه خوارزمية، وإلا فلن تكون المؤتمرات الأكاديمية وأوراق المجلات مليئة بخوارزميات الضبط الدقيق واحدة تلو الأخرى. ولكن عندما تم الكشف عن chatGPT ونموذج اللغة الكبير LLM الذي يدعم ذكائه، بدأ الناس يدركون أهمية النموذجين الأخيرين. إن القوة الحاسوبية الهائلة هي شرط أساسي لميلاد النماذج. وتشكل جودة البيانات وتنوعها أهمية بالغة لبناء نظام ذكاء اصطناعي قوي وفعال. وفي المقابل، لم تعد متطلبات الخوارزميات محسنة كالمعتاد.
في عصر النماذج الكبيرة، تغير الذكاء الاصطناعي من الحرفية الدقيقة إلى الطوب الطائر القوي. ويتزايد الطلب على قوة الحوسبة والبيانات يومًا بعد يوم، وDePIN يمكن أن توفر ذلك. تعمل الحوافز الرمزية على الاستفادة من سوق المنتجات طويلة الأمد، وستصبح قوة الحوسبة والتخزين الهائلة على مستوى المستهلك أفضل تغذية للنماذج الكبيرة.
لا تعد لامركزية الذكاء الاصطناعي خيارًا، بل ضرورة
بالطبع سوف يتساءل البعض، بما أن قوة الحوسبة والبيانات متوفرة في غرفة كمبيوتر AWS، وهي أفضل من DePIN من حيث الاستقرار وتجربة المستخدم، فلماذا نختار DePIN بدلاً من الخدمة المركزية؟
هذا البيان منطقي بشكل طبيعي. بعد كل شيء، وبالنظر إلى الوضع الحالي، يتم تطوير جميع النماذج الكبيرة تقريبًا بشكل مباشر أو غير مباشر بواسطة شركات الإنترنت الكبيرة. خلف chatGPT تقف Microsoft وخلف جيميني يأتي جوجل، وكل شركة إنترنت كبرى في الصين تقريبًا لديها نموذج ضخم. لماذا؟ لأن شركات الإنترنت الكبيرة فقط هي التي تمتلك ما يكفي من البيانات عالية الجودة وقدرة حاسوبية مدعومة بموارد مالية قوية. ولكن هذا غير صحيح. فالناس لم يعودوا راغبين في الخضوع لسيطرة عمالقة الإنترنت.
من ناحية، ينطوي الذكاء الاصطناعي المركزي على مخاطر تتعلق بخصوصية البيانات وأمانها وقد يخضع للرقابة والتحكم؛ ومن ناحية أخرى، فإن الذكاء الاصطناعي الذي تنتجه عمالقة الإنترنت سيجعلون الناس أكثر تعزيز الاعتماد ويؤدي إلى تركيز السوق وزيادة الحواجز أمام الابتكار.

من: https://www.gensyn.ai/
إنسان لا ينبغي أن تكون هناك حاجة لمارتن لوثر في عصر الذكاء الاصطناعي، بل ينبغي أن يكون للناس الحق في التحدث مباشرة إلى الله.
DePIN من منظور الأعمال: خفض التكلفة وزيادة الكفاءة هما المفتاح
حتى لو وضعنا جانبًا النقاش حول القيمة بين اللامركزية والمركزية، من منظور الأعمال، فإن استخدام DePIN للذكاء الاصطناعي لا يزال يتمتع بمزاياه.
أولاً وقبل كل شيء، علينا أن نفهم بوضوح أنه على الرغم من أن عمالقة الإنترنت لديهم عدد كبير من موارد بطاقات الرسومات المتطورة، إلا أن الجمع بين بطاقات الرسومات المخصصة للمستهلكين المنتشرة بين القطاع الخاص يمكن أيضًا أن تشكل شبكة رائعة جدًا من القوة الحاسوبية، وهو التأثير الطويل للقوة الحاسوبية. معدل الخمول لهذا النوع من بطاقات الرسومات المخصصة للمستهلك مرتفع جدًا في الواقع. وطالما أن الحوافز التي تقدمها DePIN يمكن أن تتجاوز فاتورة الكهرباء، فسيكون لدى المستخدمين الحافز للمساهمة في الطاقة الحاسوبية للشبكة. وفي الوقت نفسه، تتم إدارة جميع المرافق المادية من قبل المستخدمين أنفسهم. ولا تحتاج شبكة DePIN إلى تحمل تكاليف التشغيل التي لا مفر منها للموردين المركزيين، وتحتاج فقط إلى التركيز على تصميم البروتوكول نفسه.
بالنسبة للبيانات، يمكن لشبكة DePIN إطلاق توفر البيانات المحتملة وتقليل تكاليف النقل من خلال حوسبة الحافة وطرق أخرى. وفي الوقت نفسه، تتمتع معظم شبكات التخزين الموزعة بوظائف إلغاء البيانات المكررة تلقائيًا، مما يقلل من عمل تنظيف بيانات تدريب الذكاء الاصطناعي.
أخيرًا، تعمل اقتصاديات التشفير التي قدمتها DePIN على تعزيز تحمل النظام للأخطاء ومن المتوقع أن تحقق وضعًا مربحًا للجانبين لمقدمي الخدمات والمستهلكين والمنصات.
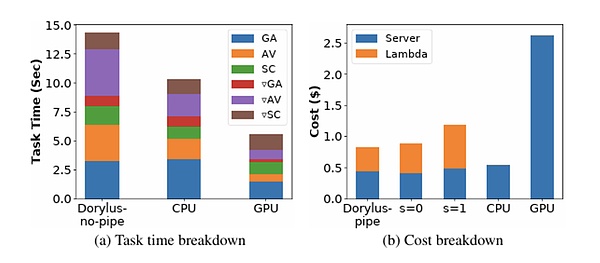
من: UCLA
في حالة عدم تصديقك، فإن UCLA تظهر أحدث الأبحاث أن استخدام الحوسبة اللامركزية يحقق أداءً يصل إلى 2.75 مرة مقارنة بمجموعات وحدات معالجة الرسومات التقليدية بنفس التكلفة، وعلى وجه التحديد، فهو أسرع بـ 1.22 مرة وأرخص بـ 4.83 مرة.
الطريق الصعب أمامك: ما هي التحديات التي ستواجهها AIxDePIN؟
لقد اخترنا الذهاب إلى القمر في هذا العقد والقيام بالأشياء الأخرى، ليس لأنها سهلة، ولكن لأنها صعبة.< /p>
——جون فيتزجيرالد كينيدي
التخزين الموزع والحوسبة الموزعة باستخدام DePIN بدون ثقة لا يزال هناك العديد من التحديات في بناء نماذج الذكاء الاصطناعي.
التحقق من العمل
التعلم العميق الحسابي بشكل أساسي تعتبر تعدين النموذج وإثبات العمل بمثابة حسابات للأغراض العامة، والطبقة الأدنى هي تغيرات الإشارة بين دوائر البوابة. من منظور كلي، يعد تعدين إثبات العمل (PoW) "حسابًا عديم الفائدة"، حيث يحاول الحصول على قيمة تجزئة بأصفار n مسبوقة بعدد لا يحصى من توليد الأرقام العشوائية وحسابات دالة التجزئة؛ في حين أن حسابات التعلم العميق هي "حسابات مفيدة"، من خلال إنشاء عدد لا يحصى من الأرقام العشوائية و حسابات دالة التجزئة: يحسب الاشتقاق الأمامي والاشتقاق الخلفي قيم المعلمات لكل طبقة في التعلم العميق لبناء نموذج ذكاء اصطناعي فعال.
الحقيقة هي أن "الحسابات غير المفيدة" مثل تعدين إثبات العمل (PoW) تستخدم دالات التجزئة. من السهل حساب الصورة من الصورة المسبقة، ومن السهل جدًا حساب الصورة الأولية من الصورة أمر صعب، لذلك يمكن لأي شخص التحقق بسهولة وسرعة من صحة الحساب؛ لحساب نموذج التعلم العميق، بسبب البنية الهرمية، يتم استخدام مخرجات كل طبقة كمدخل للطبقة الطبقة التالية، لذلك يتطلب التحقق من صحة الحساب أن جميع الأعمال السابقة لا يمكن التحقق منها ببساطة وكفاءة.
من: AWS
التحقق من العمل أمر بالغ الأهمية، وإلا فإن الحساب يمكن لموفر الخدمة تخطي الحساب تمامًا وإرسال نتيجة تم إنشاؤها عشوائيًا.
إحدى الأفكار هي السماح لخوادم مختلفة بأداء نفس مهام الحوسبة والتحقق من فعالية العمل من خلال تكرار التنفيذ والتحقق مما إذا كان هو نفسه. ومع ذلك، فإن الغالبية العظمى من حسابات النماذج غير حتمية، ولا يمكن إعادة إنتاج نفس النتائج حتى في ظل نفس بيئة الحوسبة، ولا يمكن أن تكون متشابهة إلا من الناحية الإحصائية. بالإضافة إلى ذلك، سيؤدي العد المزدوج إلى زيادة سريعة في التكاليف، وهو ما يتعارض مع هدف DePIN الرئيسي المتمثل في تقليل التكاليف وزيادة الكفاءة.
نوع آخر من الأفكار هو آلية التفاؤل، التي تعتقد في البداية بشكل متفائل أن النتائج قد تم حسابها بشكل فعال، وفي الوقت نفسه تسمح لأي شخص بالتحقق من نتائج الحساب إذا تم العثور على أخطاء، يمكنك تقديم دليل على الاحتيال، وستفرض الاتفاقية غرامة على المحتال ومكافأة المبلغ.
التوازي
كما ذكرنا سابقًا، تستفيد DePIN من ذلك وهي في الأساس سوق طاقة حوسبة استهلاكية طويلة الذيل، مما يعني أن قوة الحوسبة التي يمكن أن يوفرها جهاز واحد محدودة نسبيًا. بالنسبة لنماذج الذكاء الاصطناعي الكبيرة، سيستغرق التدريب على جهاز واحد وقتًا طويلاً جدًا، ويجب استخدام التوازي لتقصير وقت التدريب.
تكمن الصعوبة الرئيسية في موازاة التدريب على التعلم العميق في الاعتماد بين المهام السابقة واللاحقة، وهذه التبعية ستجعل تحقيق الموازاة صعبًا.
في الوقت الحالي، تنقسم موازاة التدريب على التعلم العميق بشكل أساسي إلى توازي البيانات وتوازي النماذج.
يشير توازي البيانات إلى توزيع البيانات على أجهزة متعددة، حيث يحفظ كل جهاز جميع معلمات النموذج، ويستخدم البيانات المحلية للتدريب، وأخيراً يقوم بتدريب معلمات كل جهاز يتم تجميعها. تعمل موازية البيانات بشكل جيد عندما تكون كمية البيانات كبيرة، ولكنها تتطلب اتصالاً متزامنًا لتجميع المعلمات.
يعني توازي النموذج أنه عندما يكون حجم النموذج كبيرًا جدًا بحيث لا يتناسب مع جهاز واحد، يمكن تقسيم النموذج إلى أجهزة متعددة، ويتم حفظ كل جهاز جزء من معلمات النموذج. يتطلب الانتشار الأمامي والخلفي التواصل بين الأجهزة المختلفة. يتمتع توازي النموذج بمزايا عندما يكون النموذج كبيرًا، لكن حمل الاتصال أثناء الانتشار للأمام والخلف يكون كبيرًا.
للحصول على معلومات التدرج بين الطبقات المختلفة، يمكن تقسيمها إلى تحديث متزامن وتحديث غير متزامن. التحديث المتزامن بسيط ومباشر، لكنه سيزيد من وقت الانتظار؛ خوارزمية التحديث غير المتزامن لها وقت انتظار قصير، ولكنها ستؤدي إلى مشاكل في الاستقرار.
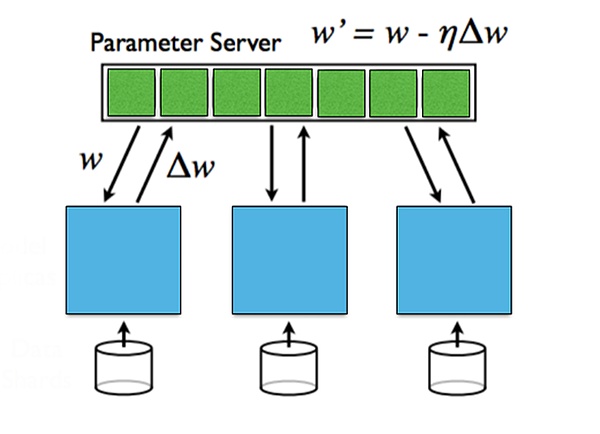
من: جامعة ستانفورد، التعلم العميق الموازي والموزع
الخصوصية
يشهد الاتجاه العالمي لحماية الخصوصية الشخصية ارتفاعًا، وتعمل الحكومات في جميع أنحاء العالم على تعزيز حماية أمن خصوصية البيانات الشخصية. على الرغم من أن الذكاء الاصطناعي يستخدم مجموعات البيانات العامة على نطاق واسع، فإن ما يميز نماذج الذكاء الاصطناعي المختلفة حقًا هو بيانات المستخدم الخاصة بكل مؤسسة.
كيفية الحصول على فوائد البيانات الخاصة أثناء التدريب دون الكشف عن الخصوصية؟ كيف يمكن التأكد من عدم تسرب معلمات نموذج الذكاء الاصطناعي المدمج؟
هذان جانبان من الخصوصية، خصوصية البيانات وخصوصية النموذج. تحمي خصوصية البيانات المستخدمين، بينما تحمي خصوصية النموذج المؤسسة التي تبني النموذج. في السيناريو الحالي، تعد خصوصية البيانات أكثر أهمية من خصوصية النموذج.
تحاول مجموعة متنوعة من الحلول حل مشكلة الخصوصية. ويضمن التعلم الموحد خصوصية البيانات من خلال التدريب على مصدر البيانات، والاحتفاظ بالبيانات محليًا، ونقل معلمات النموذج؛ وقد يصبح إثبات المعرفة الصفرية نجمًا صاعدًا.
تحليل الحالة: ما هي المشاريع عالية الجودة المتوفرة في السوق؟
Gensyn
Gensyn هو توزيع شبكة حوسبة الصيغة لتدريب نماذج الذكاء الاصطناعي. تستخدم الشبكة طبقة من blockchain تعتمد على Polkadot للتحقق من تنفيذ مهام التعلم العميق بشكل صحيح وتشغيل المدفوعات عبر الأوامر. تأسست في عام 2020، وكشفت عن تمويل من الفئة A بقيمة 43 مليون دولار أمريكي في يونيو 2023، بقيادة a16z.
يستخدم Gensyn البيانات الوصفية لعمليات التحسين القائمة على التدرج لإنشاء شهادات للعمل المنجز، بما يتوافق مع بروتوكولات الدقة متعددة الحبيبات والقائمة على الرسوم البيانية وتنفيذ المقيمين المتقاطعين للسماح بإعادة تشغيل أعمال التحقق ومقارنتها للتأكد من اتساقها، وتأكيدها في النهاية من قبل السلسلة نفسها للتأكد من صحة الحسابات. لزيادة تعزيز موثوقية التحقق من العمل، تقدم Gensyn التوقيع المساحي لإنشاء الحوافز.
هناك أربعة أنواع من المشاركين في النظام: مقدمو الطلبات، والمحللون، والمتحققون، والمراسلون.
• المرسلون هم المستخدمون النهائيون للنظام الذين يقدمون المهام التي سيتم حسابها ويدفعون مقابل وحدات العمل المكتملة.
• يعتبر القائم بالحل هو العامل الرئيسي في النظام، حيث يقوم بإجراء التدريب النموذجي وإنشاء البراهين للفحص بواسطة المدقق.
• تعتبر أدوات التحقق من الصحة أساسية لربط عملية التدريب غير الحتمية مع الحسابات الخطية الحتمية، وتكرار البراهين الجزئية ومقارنة المسافات بالعتبات المتوقعة.
• المخبرون هم خط الدفاع الأخير، يدققون في عمل المدققين ويرفعون التحديات، ويتم مكافأتهم بعد اجتياز التحديات.
يحتاج الحل إلى التعهد، وسيقوم المراسل باختبار عمل الحل. إذا وجد فعلًا شريرًا، فسوف يتحداه. وبعد اجتياز التحدي، يتم الحصول على الرموز المميزة ستتم مصادرة التعهدات التي تعهد بها الحلال، وسيحصل المبلغون عن المخالفات على مكافآت.
وفقًا لتوقعات Gensyn، من المتوقع أن يؤدي هذا الحل إلى تقليل تكاليف التدريب إلى 1/5 من تكاليف مقدمي الخدمة المركزيين.
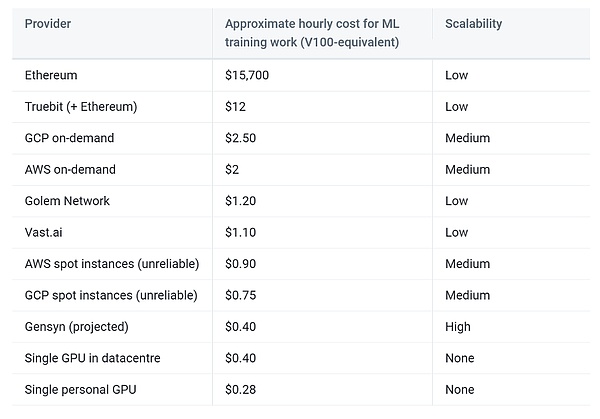
من: جينسين
FedML
FedML عبارة عن منصة تعلم آلي تعاوني لامركزي للذكاء الاصطناعي اللامركزي والتعاوني، في أي مكان وعلى أي نطاق. وبشكل أكثر تحديدًا، يوفر FedML نظامًا بيئيًا لـ MLOps يقوم بتدريب نماذج التعلم الآلي ونشرها ومراقبتها وتحسينها باستمرار أثناء التعاون في البيانات المجمعة والنماذج وموارد الحوسبة بطريقة تحافظ على الخصوصية. تأسست FedML في عام 2022، وكشفت عن جولة تأسيسية بقيمة 6 ملايين دولار في مارس 2023.
يتكون FedML من مكونين رئيسيين، FedML-API وFedML-core، اللذين يمثلان واجهة برمجة التطبيقات عالية المستوى وواجهة برمجة التطبيقات منخفضة المستوى على التوالي.
يتضمن FedML-core وحدتين مستقلتين: الاتصال الموزع والتدريب النموذجي. وحدة الاتصال مسؤولة عن الاتصال الأساسي بين مختلف العمال/العملاء وتعتمد على MPI؛ وتعتمد وحدة التدريب النموذجية على PyTorch.
FedML-API مبني على FedML-core. باستخدام FedML-core، يمكن تنفيذ الخوارزميات الموزعة الجديدة بسهولة من خلال اعتماد واجهات البرمجة الموجهة للعميل.
أثبت أحدث عمل لفريق FedML أن استخدام FedML Nexus AI لإجراء استدلال نموذج الذكاء الاصطناعي على وحدة معالجة الرسومات RTX 4090 للمستهلك أرخص 20 مرة وأسرع 1.88 مرة من A100 .
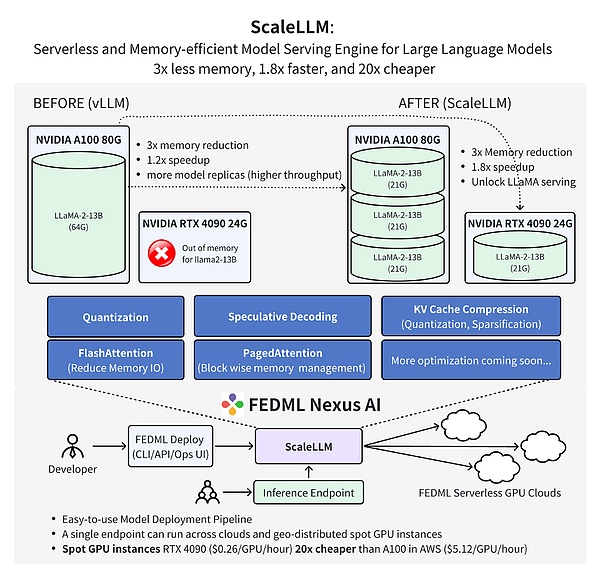
من: FedML
التوقعات المستقبلية: DePIN يجلب ديمقراطية الذكاء الاصطناعي
في يوم من الأيام، سوف يتطور الذكاء الاصطناعي إلى الذكاء الاصطناعي العام، وسوف تصبح قوة الحوسبة العملة العالمية بحكم الأمر الواقع. وستعمل تقنية DePIN على تعزيز هذه العملية .
لقد فتح تكامل الذكاء الاصطناعي وDePIN نقطة نمو تكنولوجي جديدة وقدم فرصًا هائلة لتطوير الذكاء الاصطناعي. يوفر DePIN للذكاء الاصطناعي قوة حوسبة وبيانات موزعة هائلة، مما يساعد على تدريب نماذج واسعة النطاق وتحقيق ذكاء أقوى. وفي الوقت نفسه، يعمل DePIN أيضًا على تمكين الذكاء الاصطناعي من التطور في اتجاه أكثر انفتاحًا وأمانًا وموثوقية، مما يقلل الاعتماد على بنية تحتية مركزية واحدة.
بالنظر إلى المستقبل، سيستمر الذكاء الاصطناعي وDePIN في التطور بشكل تعاوني. ستوفر الشبكة الموزعة أساسًا قويًا لتدريب نماذج كبيرة جدًا، وستلعب هذه النماذج دورًا مهمًا في تطبيق DePIN. مع حماية الخصوصية والأمان، سيساعد الذكاء الاصطناعي أيضًا على تحسين بروتوكولات وخوارزميات شبكة DePIN. نحن نتطلع إلى أن يقدم الذكاء الاصطناعي وDePIN عالمًا رقميًا أكثر كفاءة وعدالة وجديرة بالثقة.
لقد حان الوقت لجلب إمكانات حوسبة الفيديو المدعومة بالذكاء الاصطناعي إلى Livepeer
JinseFinanceالأكثر شهرة لارتباطها بلعبة Web3 Axie Infinity، أثبتت Ronin موثوقيتها من خلال خدمة الملايين من المستخدمين النشطين يوميًا وإدارة أحجام كبيرة من المعاملات - تتجاوز 4 مليارات دولار من أحجام NFT حتى الآن.
 BrianJinseFinance
BrianJinseFinanceتقدم الولايات المتحدة مشاريع قوانين للحد من دور الصين في blockchain والعملات المشفرة، بهدف حماية الأمن القومي وخصوصية البيانات.
 Hui Xin
Hui Xinتقدم OP Labs نظامًا مقاومًا للأخطاء في شبكة اختبار Goerli الخاصة بشركة التفاؤل، مما يمهد الطريق لنظام بيئي فائق اللامركزية.
 Bitcoinworld
Bitcoinworldأعلنت شركة Mastercard يوم أمس عن خطط لإطلاق نسخة تجريبية من شبكة Mastercard Multi-Token Network (MTN).
 Ledgerinsights
Ledgerinsightsانخفض سعر SOL إلى أدنى مستوى له منذ مارس 2021.
 Beincrypto
Beincryptoيثبت Ethereum أنه اختراق وعامل مقيد لبروتوكولات blockchain الجديدة.
 Cointelegraph
Cointelegraphسجلت شبكة البيتكوين أدنى طلب على الطاقة في عام 2022 بلغ 10.65 جيجاوات. في ذروتها ، طلبت شبكة BTC 16.09 جيجاوات من الطاقة.
Cointelegraph随着实际采用的增长,比特币第二层扩展解决方案闪电网络的支付额增长超过400%。
Cointelegraph