يفتح التشفير المتماثل بالكامل FHE، الذي أشاد به بوتيرين، إمكانات تطبيقه باللغة العامية
تقديم التشفير المتماثل بالكامل (FHE): استكشف تطبيقاته المثيرة وقيوده وأحدث التطورات التي تزيد شعبيته.
 JinseFinance
JinseFinance

 < /strong>
< /strong>
كان هذا هو حجم مجموعة بيانات ImageNet عندما أراد Li Feifei، الأستاذ المساعد في جامعة برينستون، إنشائها. إنها تأمل أن يساعد القيام بذلك في تطوير مجال رؤية الكمبيوتر الراكد. هذه محاولة جريئة. تعد الفئات البالغ عددها 22000 فئة أكبر بمرتين على الأقل من أي مجموعة بيانات صور تم إنشاؤها من قبل.
يعتقد أقرانها أن الإجابة على بناء أنظمة ذكاء اصطناعي أفضل تكمن في الابتكار الخوارزمي، ويشككون في حكمتها. "كلما ناقشت فكرة ImageNet مع زملائي، شعرت بالوحدة."
على الرغم من الشكوك، فإن Feifei وفريقها الصغير - بما في ذلك المرشحة للحصول على درجة الدكتوراه بدأ جيا دينج - وعدد قليل من الطلاب الجامعيين الذين يكسبون 10 دولارات في الساعة - في وضع علامات على الصور من محركات البحث. وكان التقدم بطيئا ومؤلما. ويقدر جيا دنغ أنه بالمعدل الذي يسيرون به، سوف يستغرق الأمر 18 عامًا لإكمال ImageNet، وهو وقت لم يسبقه أحد. وذلك عندما قام أحد طلاب الماجستير بتقديم Fei Fei إلى Amazon's Mechanical Turk، وهو سوق يجمع المساهمين من جميع أنحاء العالم لاستكمال "مهام الذكاء البشري". أدرك Feifei على الفور أن هذا هو بالضبط ما يحتاجون إليه.
في عام 2009، بعد ثلاث سنوات من بدء Fei Fei لأهم مشروع في حياتها، بمساعدة قوة عاملة عالمية موزعة، أصبحت ImageNet أخيرًا جاهزة. لقد قامت بدورها في المهمة المشتركة المتمثلة في تطوير رؤية الكمبيوتر.
الآن، حان دور الباحثين لتطوير خوارزميات تستخدم مجموعة البيانات الضخمة هذه لمساعدة أجهزة الكمبيوتر على رؤية العالم بالطريقة التي يراها البشر. ومع ذلك، خلال العامين الأولين، لم يحدث هذا. لم يكن أداء أي من هذه الخوارزميات أفضل من الحالة السابقة لـ ImageNet.
بدأت Feifei تتساءل عما إذا كان زملاؤها على حق بشأن كون ImageNet جهدًا غير مجدٍ.
بعد ذلك، في أغسطس 2012، تمامًا كما فقدت فايفي الأمل في أن يلهم مشروعها التغييرات التي تصورتها، اتصلت بها جيا دينغ بشكل عاجل لتخبرها أخبارًا عن AlexNet. هذه الخوارزمية الجديدة، المدربة على ImageNet، تتفوق في الأداء على جميع خوارزميات رؤية الكمبيوتر في التاريخ. يستخدم AlexNet، الذي أنشأه ثلاثة باحثين في جامعة تورنتو، بنية ذكاء اصطناعي مهجورة في الغالب تسمى "الشبكة العصبية" وتجاوزت توقعات Fei Fei الأكثر جموحًا.
في تلك اللحظة، أدركت أن جهودها قد أتت بثمارها. "لقد تم صنع التاريخ للتو، ولا يعرفه سوى عدد قليل من الأشخاص في العالم." شاركت Li Feifei القصة وراء ImageNet في مذكراتها "العالم الذي رأيته".
يعتبر دمج ImageNet مع AlexNet تاريخيًا لعدة أسباب.
أولاً وقبل كل شيء، لطالما اعتبرت إعادة تقديم الشبكات العصبية تقنية مسدودة لقد أصبحت البنية الفعلية وراء الخوارزمية التي قادت النمو الهائل لتطوير الذكاء الاصطناعي لأكثر من عشر سنوات.
ثانيًا، كان ثلاثة باحثين من تورونتو (أحدهم ربما سمعت عنه هو إيليا سوتسكيفر) أول من استخدم واحدًا من أولئك الذين يستخدمون وحدات معالجة الرسومات (GPUs) لتدريب نماذج الذكاء الاصطناعي. وهذا أيضًا هو معيار الصناعة الآن.
ثالثًا، أدركت صناعة الذكاء الاصطناعي أخيرًا ما اقترحه Feifei لأول مرة منذ سنوات عديدة: العناصر الأساسية للذكاء الاصطناعي المتقدم هي بيانات كميات كبيرة.
لقد قرأنا جميعًا وسمعنا عبارات مثل "البيانات هي النفط الجديد" و"القمامة" "هو أن القمامة تخرج" هو المثل الذي لا يحصى من المرات. لو لم تكن هذه الكلمات حقائق أساسية عن عالمنا، لربما شعرنا بالملل منها. على مر السنين، كان الذكاء الاصطناعي يعمل خلف الكواليس ليصبح جزءًا متزايد الأهمية من حياتنا ــ حيث يؤثر على التغريدات التي نقرأها، والأفلام التي نشاهدها، والأسعار التي ندفعها، والفضل الذي نعتبره مستحقًا لنا. كل هذا مدفوع بجمع البيانات التي تتتبع بدقة كل تحركاتنا في العالم الرقمي.
ولكن في العامين الماضيين، منذ أن أصدرت شركة OpenAI الناشئة غير المعروفة نسبيًا تطبيق chatbot يسمى ChatGPT، اكتسب الذكاء الاصطناعي أهمية وقد انتقل من وراء مشاهد إلى المسرح. نحن على أعتاب الذكاء الآلي الذي يتغلغل في كل جانب من جوانب حياتنا. ومع احتدام المنافسة حول من سيتحكم في هذا الذكاء، يتزايد أيضًا الطلب على البيانات التي تحركه.
هذا هو موضوع هذه المقالة. نناقش حجم البيانات التي تحتاجها شركات الذكاء الاصطناعي ومدى إلحاحها، والمشاكل التي تواجهها في الحصول عليها. نستكشف كيف يهدد هذا الطلب الذي لا يشبع حبنا للإنترنت والمليارات من المساهمين فيه. أخيرًا، قمنا بتعريف بعض الشركات الناشئة الناشئة التي تستخدم العملات المشفرة لمعالجة هذه المشكلات والمخاوف.
قبل أن نتعمق، ملاحظة سريعة: تمت كتابة هذه المقالة من منظور تدريب نماذج اللغات الكبيرة (LLMs)، وليس كل أنظمة الذكاء الاصطناعي. ولذلك، غالبًا ما أستخدم "AI" و"LLMs" بالتبادل. في حين أن هذا الاستخدام غير دقيق من الناحية الفنية، فإن المفاهيم والأسئلة التي تنطبق على ماجستير إدارة الأعمال، خاصة فيما يتعلق بالبيانات، تنطبق أيضًا على أشكال أخرى من نماذج الذكاء الاصطناعي.
يتم تدريب نماذج اللغات الكبيرة بواسطة ثلاثة متخصصين قيود الموارد: الحوسبة والطاقة والبيانات. وتتنافس الشركات والحكومات والشركات الناشئة على هذه الموارد، المدعومة بكميات هائلة من رأس المال. من بين الثلاثة، المنافسة على الحوسبة هي الأشد شراسة، ويرجع الفضل في ذلك جزئيًا إلى الارتفاع السريع في سعر سهم NVIDIA.
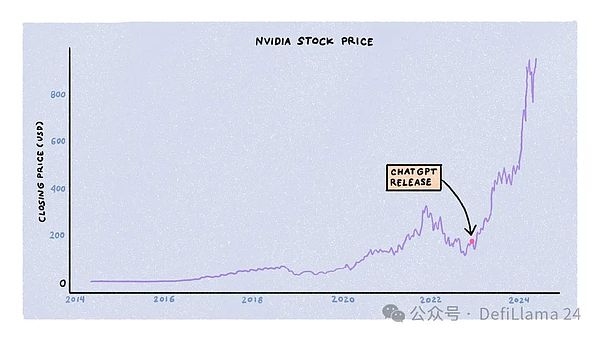
يتطلب تدريب LLMs مجموعات كبيرة من وحدات معالجة الرسومات المتخصصة (GPUs)، وخاصة نماذج A100 وH100 وB100 القادمة من NVIDIA. هذه ليست أجهزة كمبيوتر يمكنك شراؤها من متجر أمازون أو متجر الكمبيوتر المحلي لديك. وبدلا من ذلك، تكلف عشرات الآلاف من الدولارات. تقرر NVIDIA كيفية تخصيص إمداداتها لمختبرات الذكاء الاصطناعي والشركات الناشئة ومراكز البيانات والعملاء ذوي النطاق الواسع.
في 18 شهرًا منذ إصدار ChatGPT، تجاوز الطلب على وحدة معالجة الرسومات العرض بكثير، مع أوقات انتظار تصل إلى 11 شهرًا. ومع ذلك، مع انقشاع غبار الجنون الأولي، عادت ديناميكيات العرض والطلب إلى طبيعتها. إغلاق الشركات الناشئة، والتحسينات في خوارزميات التدريب وبنيات النماذج، وظهور شرائح متخصصة من شركات أخرى، وزيادة إنتاج NVIDIA، كلها عوامل تساهم في زيادة توافر وحدة معالجة الرسومات وخفض الأسعار.
ثانيًا، الطاقة. يتطلب تشغيل وحدات معالجة الرسومات في مراكز البيانات الكثير من الطاقة. وتشير بعض التقديرات إلى أن مراكز البيانات ستستهلك 4.5% من الطاقة العالمية بحلول عام 2030. وبما أن هذه الزيادة في الطلب تضع ضغوطاً على شبكات الطاقة الحالية، فإن شركات التكنولوجيا تستكشف حلول الطاقة البديلة. اشترت أمازون مؤخرًا مركز بيانات مدعومًا بمحطة للطاقة النووية مقابل 650 مليون دولار. عينت مايكروسوفت رئيسًا للتكنولوجيا النووية. قام Sam Altman من OpenAI بدعم شركات الطاقة الناشئة مثل Helion وExowatt وOklo.
من منظور تدريب نماذج الذكاء الاصطناعي - الطاقة والحوسبة مجرد سلع. إن استخدام B100 بدلاً من H100، أو الطاقة النووية بدلاً من الطاقة التقليدية، قد يجعل عملية التدريب أرخص وأسرع وأكثر كفاءة، لكنه لن يؤثر على جودة النموذج. بمعنى آخر، في السباق لإنشاء أذكى نماذج الذكاء الاصطناعي وأكثرها شبهاً بالإنسان، تعد الطاقة والحوسبة عاملين أساسيين، وليسا عوامل فارقة.
المورد الرئيسي هو البيانات.
جيمس بيتكر هو مهندس أبحاث في OpenAI. وعلى حد تعبيره، فقد قام بتدريب "نماذج أكثر إنتاجية مما يحق لأي شخص أن يدربه". في منشور بالمدونة، أشار إلى أن "التدريب على نفس مجموعة البيانات لفترة كافية، وأي نموذج تقريبًا به أوزان كافية ووقت تدريب سوف يتقارب إلى نفس النقطة. وهذا يعني أن التمييز بين نموذج ذكاء اصطناعي وآخر هو نموذج ذكاء اصطناعي." مجموعة البيانات. لا شيء آخر.
عندما نشير إلى نموذج باسم "ChatGPT" أو "Claude" أو "Mistral" أو "Lambda"، فإننا لا نتحدث عن البنية أو وحدة معالجة الرسومات المستخدمة أو الطاقة المستهلكة، ولكن مجموعة البيانات التي يتم التدريب عليها.
ما مقدار البيانات اللازمة لتدريب نموذج توليدي متطور؟
الإجابة: كثيرًا.
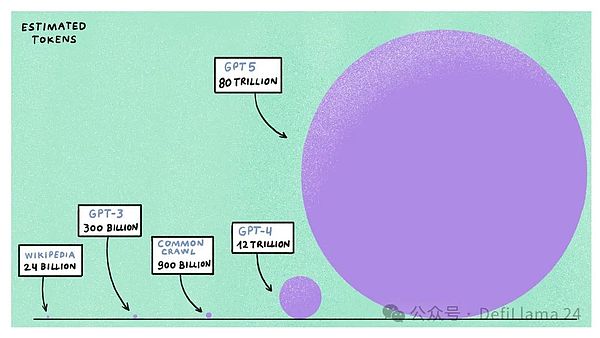
GPT-4، بعد مرور أكثر من عام على إصداره، لا يزال يعتبر أفضل نموذج لغوي واسع النطاق، مع ما يقدر بنحو 1.2 تريليون رمز (أو ما يقرب من 900 مليار كلمات). تأتي البيانات من مصادر متاحة للعامة على الإنترنت، بما في ذلك Wikipedia وReddit وCommon Crawl (مستودع مجاني ومفتوح للبيانات المسروقة على الويب)، وأكثر من مليون ساعة من بيانات YouTube المكتوبة، ومنصات البرمجة مثل GitHub وStack Overflow.
إذا كنت تعتقد أن هذا قدر كبير من البيانات، فانتظر. هناك مفهوم في الذكاء الاصطناعي التوليدي يسمى "قوانين قياس شينشيلا" والذي ينص على أنه بالنسبة لميزانية حوسبة معينة، يكون تدريب نموذج أصغر على مجموعة بيانات أكبر أكثر كفاءة من تدريب نموذج أكبر على مجموعة بيانات أصغر. إذا قمنا باستقراء موارد الحوسبة المخصصة من قبل شركات الذكاء الاصطناعي لتدريب نماذج الذكاء الاصطناعي من الجيل التالي مثل GPT-5 وLlama-4 - نجد أنه من المتوقع أن تتطلب هذه النماذج خمسة إلى ستة أضعاف قوة الحوسبة، باستخدام ما يصل إلى 100 تريليون رمز . يدرب.
نظرًا لأن معظم بيانات الإنترنت العامة يتم الزحف إليها وفهرستها واستخدامها لتدريب النماذج الموجودة، فمن أين تأتي البيانات الإضافية؟ لقد أصبح هذا سؤالًا بحثيًا متطورًا لشركات الذكاء الاصطناعي. هناك طريقتان لحل هذه المشكلة. الأول هو أن تقرر استخدام البيانات الاصطناعية التي تم إنشاؤها مباشرة من قبل LLMs، وليس من قبل البشر. ومع ذلك، لم يتم بعد اختبار فعالية هذه البيانات في جعل النماذج أكثر ذكاءً.
هناك خيار آخر يتمثل في البحث ببساطة عن البيانات عالية الجودة بدلاً من إنشائها بشكل صناعي. ومع ذلك، فإن الحصول على بيانات إضافية يمثل تحديًا، خاصة عندما تواجه شركات الذكاء الاصطناعي مشكلات لا تهدد تدريب النماذج المستقبلية فحسب، بل أيضًا فعالية النماذج الحالية.
تتضمن مشكلة البيانات الأولى مشكلات قانونية. على الرغم من أن شركات الذكاء الاصطناعي تدعي أنها تدرب النماذج على "البيانات المتاحة للعامة"، فإن الكثير منها محمية بحقوق الطبع والنشر. على سبيل المثال، تحتوي مجموعة بيانات Common Crawl على ملايين المقالات من منشورات مثل The New York Times وThe Associated Press، بالإضافة إلى مواد أخرى محمية بحقوق الطبع والنشر مثل الكتب المنشورة وكلمات الأغاني.
تتخذ بعض المنشورات والمبدعين إجراءات قانونية ضد شركات الذكاء الاصطناعي، بدعوى أنها تنتهك حقوق الطبع والنشر وحقوق الملكية الفكرية الخاصة بها. ترفع صحيفة The Times دعوى قضائية ضد OpenAI وMicrosoft بتهمة "نسخ واستخدام عمل The Times الفريد والقيم بشكل غير قانوني". رفعت مجموعة من المبرمجين دعوى قضائية جماعية تطعن في شرعية استخدام كود مفتوح المصدر لتدريب GitHub Copilot، وهو مساعد برمجة شهير يعمل بالذكاء الاصطناعي.
كما ترفع الممثلة الكوميدية سارة سيلفرمان والكاتب بول تريمبلاي دعوى قضائية ضد شركات الذكاء الاصطناعي لاستخدام أعمالها دون إذن.
يتبنى آخرون عصر التغيير من خلال الشراكة مع شركات الذكاء الاصطناعي. وقعت كل من وكالة Associated Press، وFinancial Times، وAxel Springer اتفاقيات ترخيص المحتوى مع OpenAI. وتستكشف شركة Apple شراكات مماثلة مع مؤسسات إخبارية مثل Condé Nast وNBC. وافقت جوجل على دفع 60 مليون دولار سنويًا للوصول إلى Reddit API لتدريب النماذج، وأبرمت Stack Overflow صفقة مماثلة مع OpenAI. تفكر شركة Meta في شراء الناشر Simon & Schuster بشكل كامل.
تتوافق عمليات التعاون هذه مع المشكلة الثانية التي تواجه شركات الذكاء الاصطناعي: إغلاق الشبكات المفتوحة.
لقد أدركت منتديات الإنترنت ومواقع التواصل الاجتماعي القيمة التي تخلقها شركات الذكاء الاصطناعي من خلال الاستفادة من البيانات الموجودة على منصاتها لتدريب النماذج. قبل إبرام صفقة مع جوجل (وربما شركات الذكاء الاصطناعي الأخرى في المستقبل)، بدأ Reddit في فرض رسوم على واجهة برمجة التطبيقات (API) المجانية سابقًا، مما أدى إلى إغلاق عملاء الطرف الثالث المشهورين. وعلى نحو مماثل، قام تويتر بتقييد الوصول إلى واجهة برمجة التطبيقات الخاصة به ورفع الأسعار، ويستخدم إيلون موسك بيانات تويتر لتدريب النماذج لصالح شركته الخاصة العاملة في مجال الذكاء الاصطناعي، xAI.
حتى المنشورات الأصغر حجمًا، ومنتديات خيال المعجبين، والأركان المتخصصة الأخرى على الإنترنت تنتج محتوى يمكن للجميع استهلاكه بحرية، ومن خلال الإعلانات (إن وجدت) تتحقق الأرباح الآن البدء في الإغلاق أيضًا. تم تصور الإنترنت في الأصل على أنه فضاء إلكتروني سحري حيث يمكن للجميع العثور على قبيلة تشترك في اهتماماتهم ومراوغاتهم الفريدة. يبدو أن السحر يتبدد ببطء.
لقد اجتمع التهديد بالدعاوى القضائية، والاتجاه المتزايد لمعاملات المحتوى بملايين الملايين، وإغلاق الشبكات المفتوحة لإحداث تأثيرين:
< p style="text-align: left;"> p>أولاً وقبل كل شيء، حرب البيانات هي متحيز للغاية تجاه عمالقة التكنولوجيا. لا تستطيع الشركات الناشئة والشركات الصغيرة الوصول إلى واجهات برمجة التطبيقات المتاحة مسبقًا ولا دفع الأموال النقدية المطلوبة لشراء حقوق الاستخدام دون التعرض لمخاطر قانونية. وهذا له تأثير تركيز واضح، أي أن الأغنياء القادرين على شراء أفضل البيانات وإنشاء أفضل النماذج سوف يصبحون أكثر ثراءً.
ثانيًا، أصبح نموذج الأعمال لمنصات المحتوى التي ينشئها المستخدم غير مواتٍ للمستخدمين بشكل متزايد. تعتمد منصات مثل Reddit وStack Overflow على مساهمات الملايين من المبدعين والمشرفين البشريين بدون أجر. ومع ذلك، عندما تبرم هذه المنصات صفقات بملايين الدولارات مع شركات الذكاء الاصطناعي، فإنها لا تعوض المستخدمين ولا تطلب إذنهم، وبدون المستخدمين، لا توجد بيانات للبيع.
واجه كل من Reddit وStack Overflow إضرابات ملحوظة من قبل المستخدمين احتجاجًا على هذه القرارات. من جانبها، فتحت لجنة التجارة الفيدرالية (FTC) تحقيقًا في ممارسات Reddit المتمثلة في بيع منشورات المستخدم وترخيصها ومشاركتها مع المنظمات الخارجية لتدريب نماذج الذكاء الاصطناعي.
تثير هذه المشكلات أسئلة ذات صلة بتدريب الجيل القادم من نماذج الذكاء الاصطناعي ومستقبل محتوى الويب. وفي الوقت الحالي، يبدو هذا المستقبل ميؤوسًا منه إلى حد كبير. هل تستطيع حلول التشفير تكافؤ الفرص أمام الشركات الصغيرة ومستخدمي الإنترنت وحل هذه المشكلات؟
تدريب نماذج الذكاء الاصطناعي وإنشاء تطبيقات مفيدة هي مساعي معقدة ومكلفة تتطلب أشهرًا من التخطيط وتخصيص الموارد والتنفيذ. تتضمن هذه العمليات مراحل متعددة، لكل منها أغراض مختلفة ومتطلبات بيانات مختلفة.
دعونا نقسم هذه المراحل لنفهم كيف يتناسب التشفير مع أحجية الذكاء الاصطناعي الأكبر.
التدريب المسبق هو ماجستير إدارة الأعمال عملية التدريب تشكل الخطوة الأولى والأكثر كثافة في استخدام الموارد أساس النموذج. في هذه المرحلة، يتم تدريب نموذج الذكاء الاصطناعي على كميات كبيرة من النصوص غير المسماة لالتقاط المعرفة العامة ومعلومات استخدام اللغة حول العالم. عندما نقول تم تدريب GPT-4 على 1.2 تريليون رمز، فهذا يشير إلى البيانات المستخدمة للتدريب المسبق.
نحن بحاجة إلى نظرة عامة رفيعة المستوى حول كيفية عمل LLMs لفهم سبب كون التدريب المسبق هو أساس LLMs. لاحظ أن هذه نظرة عامة مبسطة. يمكنك العثور على شرح أكثر شمولاً في هذه المقالة الممتازة بقلم
جون ستوكس
أو في هذا الفيديو الرائع،
أندريه كارباثي
أو حتى في هذا الكتاب الرائع ابحث عن المزيد انهيار متعمق في .
ستيفن ولفرام
يستخدم حاملو ماجستير إدارة الأعمال تقنية إحصائية تسمى التنبؤ بالرمز التالي. ببساطة، في ضوء سلسلة من الرموز (أي الكلمات)، يحاول النموذج التنبؤ بالرمز المميز التالي الأكثر احتمالا. يتم تكرار هذه العملية لتكوين استجابة كاملة. لذلك، يمكنك التفكير في نموذج اللغة الكبير باعتباره "آلة اتحاد كاملة".
دعونا نفهم ذلك من خلال مثال.
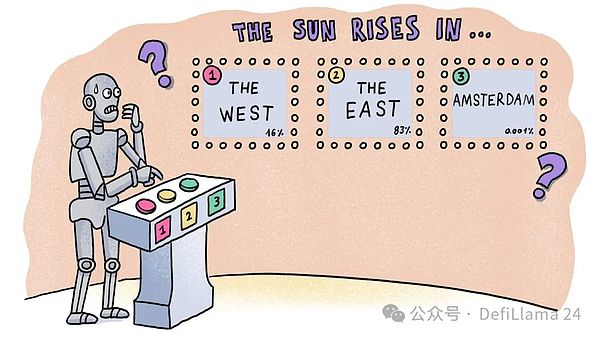
عندما أسأل ChatGPT سؤالاً مثل "في أي اتجاه تشرق الشمس؟" فإنه يتنبأ أولاً بكلمة "the" ثم عبارة "الشمس" كل كلمة لاحقة في "الطلوع من المشرق". ولكن من أين تأتي هذه التوقعات؟ كيف يحدد ChatGPT أنه بعد "الشمس من" يجب أن تكون "شرقًا" بدلاً من "غربًا" أو "شمالًا" أو "أمستردام"؟ بمعنى آخر، كيف يمكن معرفة أن الخيار "الشرقي" هو الأكثر احتمالاً إحصائيًا من الخيارات الأخرى؟

هناك طريقة أخرى لفهم ذلك وهي مقارنة عدد صفحات ويكيبيديا التي تحتوي على هذه العبارات. يقع كتاب "طلوع الشمس من المشرق" في 55 صفحة، بينما يقع كتاب "طلوع الشمس من مغربها" في 27 صفحة. لم يتم عرض أي نتائج ل "Sunrise in Amsterdam"! هذه هي الأوضاع التي اختارها ChatGPT.
تكمن الإجابة في تعلم الأنماط الإحصائية من كميات كبيرة من بيانات التدريب عالية الجودة. إذا نظرت إلى جميع النصوص الموجودة على الإنترنت، فما الذي من المرجح أن يظهر - "الشمس تشرق من الشرق" أم "الشمس تشرق من الغرب"؟ يمكن العثور على الأخير في سياقات محددة، مثل الاستعارات الأدبية ("إنه أمر سخيف مثل الاعتقاد بأن الشمس تشرق في الغرب") أو المناقشات حول الكواكب الأخرى (مثل كوكب الزهرة، حيث تشرق الشمس في الغرب). ولكن بشكل عام، الأول هو أكثر شيوعا.
من خلال التنبؤ المتكرر بالكلمة التالية، يطور LLM رؤية شاملة للعالم (ما نسميه الفطرة السليمة) وفهمًا لقواعد اللغة وأنماطها. هناك طريقة أخرى للنظر إلى LLM وهي نسخة مضغوطة من الإنترنت. كما أنه يساعد على فهم سبب ضرورة أن تكون البيانات كبيرة (المزيد من الفئات للاختيار من بينها) وعالية الجودة (لتحسين دقة تعلم الأنماط).
ولكن كما ناقشنا سابقًا، تنفد البيانات من شركات الذكاء الاصطناعي اللازمة لتدريب نماذج أكبر. ينمو الطلب على بيانات التدريب بشكل أسرع بكثير من معدل إنشاء البيانات الجديدة على الإنترنت المفتوح. ومع الدعاوى القضائية التي تلوح في الأفق وإغلاق المنتديات الكبرى، تواجه شركات الذكاء الاصطناعي أسئلة جدية.
تتفاقم المشكلة بالنسبة للشركات الصغيرة التي لا تستطيع تحمل صفقات بملايين الدولارات مع موفري البيانات المملوكة مثل Reddit.
يقودنا هذا إلى Grass، وهو مزود خدمة وكيل سكني لامركزي يهدف إلى حل بعض مشكلات البيانات هذه. يطلقون على أنفسهم اسم "طبقة بيانات الذكاء الاصطناعي". دعونا أولاً نفهم دور مزود خدمة الوكالة السكنية.
يعد الإنترنت أفضل مصدر لبيانات التدريب، ويعتبر الزحف على الإنترنت هو الطريقة المفضلة للشركات للحصول على هذه البيانات. من الناحية العملية، غالبًا ما تتم استضافة برامج الزحف في مراكز البيانات من أجل التوسع والراحة والكفاءة. ومع ذلك، فإن الشركات التي لديها بيانات قيمة لا تريد أن يتم استخدام بياناتها لتدريب نماذج الذكاء الاصطناعي (ما لم يتم الدفع لها). لفرض هذه القيود، غالبًا ما يقومون بحظر عناوين IP من مراكز البيانات المعروفة، مما يمنع الزحف على نطاق واسع.
هذا هو المكان الذي يلعب فيه مقدمو خدمات الوكالات السكنية. تحظر مواقع الويب عناوين IP الخاصة بمراكز البيانات المعروفة فقط، وليس عناوين IP لمستخدمي الإنترنت العاديين مثلي ومثلك، مما يجعل اتصالنا بالإنترنت، أو اتصال الإنترنت السكني، ذا قيمة. يقوم موفرو خدمة الوكيل السكني بتجميع الملايين من هذه الاتصالات للزحف إلى مواقع الويب على نطاق واسع لشركات الذكاء الاصطناعي.
ومع ذلك، يعمل موفرو خدمة الوكيل السكني المركزيون سرًا. في كثير من الأحيان لا يذكرون نواياهم بوضوح. إذا علم المستخدمون أن أحد المنتجات يستخدم النطاق الترددي الخاص بهم وأن المنتج لا يعوضهم، فقد يترددون في توفير النطاق الترددي الخاص بهم. والأسوأ من ذلك أنهم قد يطالبون بتعويض عن استخدامهم للنطاق الترددي، مما يؤدي بدوره إلى تقليل أرباحهم.
لحماية أرباحهم النهائية، يقوم موفرو خدمة الوكيل السكني بإرفاق تعليمات برمجية تستهلك النطاق الترددي بالتطبيقات المجانية الموزعة على نطاق واسع، مثل تطبيقات أدوات الهاتف المحمول (مثل الآلات الحاسبة و مسجلات الصوت)، وموفري VPN، وحتى شاشات توقف التلفزيون الاستهلاكي. غالبًا ما لا يعرف المستخدمون الذين يعتقدون أنهم يحصلون على منتج مجانًا أن موفري الخدمات السكنية التابعين لجهات خارجية يستهلكون النطاق الترددي الخاص بهم (غالبًا ما يتم دفن هذه التفاصيل في شروط الخدمة التي لا يقرأها سوى القليل).
في نهاية المطاف، سوف تتدفق بعض هذه البيانات إلى شركات الذكاء الاصطناعي، التي تستخدمها لتدريب النماذج وخلق قيمة لأنفسهم.
أثناء إدارة مزود خدمة البروكسي السكني الخاص به، أصبح أندريه رادونيتش مدركًا للطبيعة غير الأخلاقية لهذه الممارسات وعدم عدالتها تجاه المستخدمين. لقد رأى نمو العملات المشفرة وحدد طريقة لإيجاد حل أكثر إنصافًا. ولهذا السبب تأسست شركة جراس في أواخر عام 2022. وبعد بضعة أسابيع، تم إصدار ChatGPT، مما أدى إلى تغيير العالم ووضع Grass في المكان المناسب في الوقت المناسب.

خلافًا للتكتيكات المخادعة لموفري خدمات الوكيل السكنيين الآخرين، تجعل Grass استخدامها لعرض النطاق الترددي لتدريب نماذج الذكاء الاصطناعي واضحًا للمستخدمين. وفي المقابل يحصلون على مكافآت مباشرة. يُحدث هذا النموذج ثورة في الطريقة التي يعمل بها مقدمو خدمات الوكالات السكنية. ومن خلال توفير الوصول إلى النطاق الترددي طوعًا والتحول إلى مالكين جزئيين للشبكة، يتحول المستخدمون من مشاركين سلبيين غير مطلعين إلى مبشرين نشطين، مما يزيد من موثوقية الشبكة ويستفيد من القيمة التي أنشأها الذكاء الاصطناعي.
لقد كان نمو العشب كبيرًا. منذ إطلاقها في يونيو 2023، جمعت أكثر من 2 مليون مستخدم نشط يقومون بتشغيل العقد (إما عن طريق تثبيت ملحقات المتصفح أو تطبيقات الهاتف المحمول) والمساهمة في النطاق الترددي للشبكة. ويحدث هذا النمو دون أي تكاليف تسويقية خارجية، وهو مدفوع ببرنامج إحالة ناجح للغاية.
يسمح استخدام خدمة Grass للشركات من جميع الأحجام، بدءًا من مختبرات الذكاء الاصطناعي الكبيرة وحتى الشركات الناشئة مفتوحة المصدر، بالتخلص من بيانات التدريب دون دفع ملايين الدولارات. وفي الوقت نفسه، تتم مكافأة المستخدمين العاديين مقابل مشاركة اتصالاتهم بالإنترنت، ليصبحوا جزءًا من اقتصاد الذكاء الاصطناعي المتنامي.
إلى جانب البيانات الأولية المسروقة، تقدم Grass أيضًا بعض الخدمات الإضافية لعملائها.
أولاً، يقومون بتحويل صفحات الويب غير المنظمة إلى بيانات منظمة يمكن معالجتها بسهولة أكبر بواسطة نماذج الذكاء الاصطناعي. تُسمى هذه الخطوة بتنظيف البيانات وهي مهمة كثيفة الاستخدام للموارد يتم تنفيذها عادةً بواسطة مختبرات الذكاء الاصطناعي. ومن خلال توفير مجموعات بيانات منظمة ونظيفة، تزيد شركة Grass من قيمتها بالنسبة للعملاء. بالإضافة إلى ذلك، يقوم Grass بتدريب أحد طلاب LLM مفتوح المصدر لأتمتة عملية استخراج البيانات وتنظيفها وتصنيفها.
ثانيًا، تقوم شركة Grass بتجميع مجموعة البيانات مع إثبات المصدر الذي لا يمكن إنكاره. ونظرا لأهمية البيانات عالية الجودة لنماذج الذكاء الاصطناعي، فمن الأهمية بمكان بالنسبة لشركات الذكاء الاصطناعي أن تتأكد من أن الجهات الفاعلة السيئة - سواء كانت مواقع الويب أو موفري خدمة البروكسي السكنية - لا تملك القدرة على التلاعب بمجموعات البيانات.
ينعكس حجم المشكلة في تشكيل منظمات مثل Data and Trust Alliance، وهو تحالف من المنظمات بما في ذلك Meta وIBM وWalmart وهي منظمة غير ربحية منظمة تضم أكثر من اثنتي عشرة شركة تعمل معًا لإنشاء معايير المصدر التي تساعد المؤسسات على تحديد ما إذا كانت مجموعة البيانات مناسبة وموثوقة للاستخدام.
يتخذ العشب خطوات مماثلة. في كل مرة تزحف فيها عقدة Grass إلى صفحة ويب، فإنها تسجل أيضًا البيانات الوصفية للتحقق من صفحة الويب التي تم الزحف إليها. يتم تخزين إثباتات المصدر هذه على blockchain ومشاركتها مع العملاء (الذين يمكنهم مشاركتها بشكل أكبر مع مستخدميهم).
على الرغم من أن Grass مبني على Solana، وهي واحدة من أعلى سلاسل الكتل إنتاجية، إلا أن تخزين كل مهمة تجريف على L1 المصدر غير واقعي. لذا، تقوم شركة Grass بإنشاء نسخة مجمعة (واحدة من أولى البرامج الموجودة على Solana) تستخدم معالجات ZK لتجميع إثباتات المصدر ثم نشرها على Solana. تصبح هذه المجموعة، التي يسميها جراس "طبقة بيانات الذكاء الاصطناعي"، بمثابة دفتر أستاذ البيانات لجميع البيانات التي يجمعونها.
يمنحها نهج Grass Web 3-first العديد من المزايا مقارنة بموفري البروكسي السكنيين المركزيين. أولا، من خلال استخدام الحوافز للسماح للمستخدمين بمشاركة عرض النطاق الترددي مباشرة، فإنهم يوزعون القيمة التي أنشأها الذكاء الاصطناعي بشكل أكثر إنصافا (في حين يوفرون أيضا تكلفة الدفع لمطوري التطبيقات لتجميع أكوادهم البرمجية). ثانياً، يمكنهم أن يتقاضوا علاوة مقابل تقديم "حركة مرور مشروعة"، وهي ذات قيمة عالية في هذه الصناعة.
هناك بروتوكول آخر تم إنشاؤه من منظور "حركة المرور المشروعة" وهو Masa. تسمح الشبكة للمستخدمين بتمرير معلومات تسجيل الدخول الخاصة بهم لمنصات مثل Reddit أو Twitter أو TikTok. تقوم العقد الموجودة على الشبكة بعد ذلك بالحصول على البيانات السياقية المحدثة. وتتمثل ميزة هذا النموذج في أن البيانات التي تم جمعها هي ما سيراه مستخدم تويتر العادي في خلاصته. يمكنك الحصول على مجموعات بيانات غنية في الوقت الفعلي للتنبؤ بالمشاعر أو المحتوى الذي على وشك الانتشار
ما هي مجموعات البيانات المستخدمة؟ في الوقت الحالي، هناك حالتان رئيسيتان للاستخدام لهذه البيانات السياقية.
الشؤون المالية - إذا كانت لديك آلية لرؤية آلاف الأشخاص في خلاصتهم بناءً على ما كما ترى أعلاه، يمكنك تطوير استراتيجية التداول. ويمكن تدريب العملاء الأذكياء المعتمدين على البيانات العاطفية على مجموعة بيانات ماسا.
اجتماعي - ظهور الرفاق المعتمدين على الذكاء الاصطناعي (أو أدوات مثل Replika) يعني أننا بحاجة إلى مجموعات بيانات تحاكي المحادثة البشرية. تحتاج هذه المحادثات أيضًا إلى التحديث بأحدث المعلومات. يمكن استخدام تدفقات بيانات Masa لتدريب الوكلاء الذين يمكنهم التحدث بشكل هادف عن أحدث الاتجاهات على تويتر.
يتمثل نهج Masa في الحصول على المعلومات من الحدائق المغلقة (مثل تويتر) وإتاحتها بعد الحصول على موافقة المستخدم للمطورين لبناء التطبيقات. يسمح هذا النهج الاجتماعي الأول لجمع البيانات أيضًا ببناء مجموعات البيانات حول لغات وطنية مختلفة.
على سبيل المثال، يمكن استخدام الروبوت الناطق باللغة الهندية لجمع البيانات من الشبكات الاجتماعية التي تعمل باللغة الهندية. ولم يتم بعد استكشاف أنواع التطبيقات التي تتيحها هذه الشبكات.
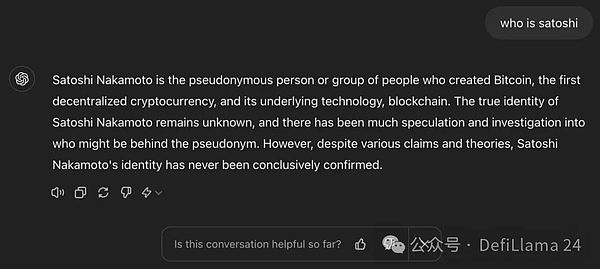
ماجستير في القانون مُدرب مسبقًا بعيدًا عن أن يكون كذلك جاهز جيد للإنتاج. فكر في الأمر. حتى الآن، كل ما يعرفه النموذج هو كيفية التنبؤ بالكلمة التالية في التسلسل، لا شيء آخر. إذا أعطيت نموذجًا تم تدريبه مسبقًا بعض النص، مثل "من هو ساتوشي ناكاموتو"، فستكون أي من الإجابات التالية استجابات صالحة:
أكمل السؤال: ساتوشي ناكاموتو؟
تحويل العبارة إلى جملة: هذا سؤال حير المؤمنين بالبيتكوين لسنوات.
إجابة حقيقية على السؤال: ساتوشي ناكاموتو هو الشخص الذي أنشأ عملة البيتكوين (أول عملة مشفرة لامركزية) والكتل الأساسية الخاصة بها أشخاص مجهولون أو المجموعات التي تستخدم تقنية blockchain.
إن ماجستير إدارة الأعمال المصمم لتقديم إجابات مفيدة سيوفر الاستجابة الثالثة. ومع ذلك، فإن استجابات النموذج المدرّب لم تكن متسقة أو صحيحة. في الواقع، غالبًا ما يقومون بإخراج نص عشوائي لا يعني شيئًا للمستخدم النهائي. في أسوأ الأحوال، يستجيب النموذج سرًا بمعلومات خاطئة أو سامة أو ضارة. عندما يحدث هذا، يقال أن النموذج "يهلوس".
p style="text-align: left;">هذه هي الطريقة التي يجيب بها GPT-3 المدرب مسبقًا على السؤال.
الهدف من محاذاة النموذج هو جعل النموذج المُدرب مسبقًا مفيدًا في النهاية للمستخدمين. بمعنى آخر، قم بتحويله من مجرد أداة نصية إحصائية إلى برنامج دردشة يفهم احتياجات المستخدم ويتوافق معها ويجري محادثات متماسكة ومفيدة.
الخطوة الأولى في هذا العملية هي تعديلات الحوار. الضبط الدقيق هو استخدام نموذج تعلم آلي تم تدريبه مسبقًا وتدريبه بشكل أكبر على مجموعة بيانات أصغر ومستهدفة لمساعدته على التكيف مع مهمة محددة أو حالة استخدام. بالنسبة لتدريب LLM، فإن حالة الاستخدام المحددة هذه هي إجراء محادثات تشبه المحادثات البشرية. وبطبيعة الحال، فإن مجموعة البيانات لمثل هذا الضبط الدقيق هي مجموعة من أزواج الاستجابة السريعة التي أنشأها الإنسان، والمحادثات التي توضح كيف ينبغي أن يتصرف النموذج.
تغطي مجموعات البيانات هذه أنواعًا مختلفة من المحادثات (الأسئلة والإجابات والتلخيص والترجمة وإنشاء التعليمات البرمجية) ويتم إنتاجها عادةً بواسطة متحدثين مدربين يتمتعون بمهارات وخبرات لغوية ممتازة. التصميم البشري (يسمى أحيانًا مدرس الذكاء الاصطناعي) للتعليم العالي.
من المقدر أن يتم تدريب النماذج الحديثة مثل GPT-4 على حوالي 100000 زوج من الاستجابة الإشاراتية .

أمثلة على أزواج الاستجابة السريعة
فكر في هذه المرحلة على أنها مشابهة لتدريب البشر للكلاب الأليفة: مكافأة السلوك الجيد ومعاقبة السلوك السيئ. يقدم النموذج مطالبة وتتم مشاركة استجابته مع مُصمم بشري، والذي يقوم بتقييم المخرجات على مقياس رقمي (على سبيل المثال، 1-5) بناءً على دقتها وجودتها. إصدار آخر من RLHF هو الحصول على مطالبة تنتج استجابات متعددة، والتي يتم بعد ذلك ترتيبها من الأفضل إلى الأسوأ بواسطة مُصنِّف بشري.
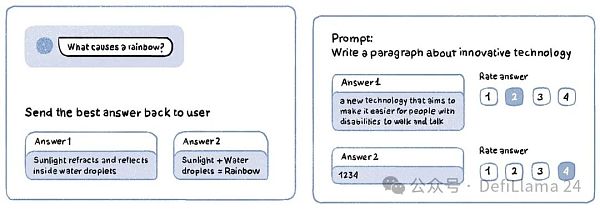
مثال لمهمة RLHF
يساعد RLHF في دفع النماذج نحو التفضيلات البشرية والسلوك المرغوب فيه . في الواقع، إذا كنت تستخدم ChatGPT، فإن OpenAI يستخدمك أيضًا كعلامة بيانات RLHF! يحدث هذا عندما ينتج النموذج أحيانًا استجابتين ويطلب منك اختيار الإجابة الأفضل.
حتى رمز الإعجاب أو عدم الإعجاب البسيط الذي يطالبك بتقييم مدى فائدة الإجابة هو شكل من أشكال تدريب RLHF النموذجي.
عندما نستخدم نماذج الذكاء الاصطناعي، نادرًا ما نأخذ في الاعتبار ملايين الساعات البشرية التي تستغرقها. هذا ليس فريدًا بالنسبة إلى LLM. تاريخيًا، حتى حالات استخدام التعلم الآلي التقليدي، مثل الإشراف على المحتوى، والقيادة الذاتية، واكتشاف الأورام، تطلبت مشاركة بشرية كبيرة في شرح البيانات.
Mechanical Turk هي الخدمة التي يستخدمها Li Feifei لإنشاء قاعدة بيانات ImageNet، ويطلق عليها جيف بيزوس اسم "الذكاء الاصطناعي الاصطناعي" لأن العاملين فيها يعملون خلف الكواليس تدريب الذكاء الاصطناعي. لعب دور شرح البيانات.
في
"قصص غريبة" في وقت سابق من هذا العام، تم الكشف عن أن أمازون. متجر Just Walk Out، حيث يمكن للعملاء اختيار العناصر من الرفوف والخروج (وسيتم تحصيل رسومهم تلقائيًا لاحقًا)، لا يتم تشغيله بواسطة بعض الذكاء الاصطناعي المتقدم. وبدلاً من ذلك، يقوم 1000 مقاول هندي بفحص لقطات المتجر يدويًا.

النقطة المهمة هي أن كل نظام ذكاء اصطناعي واسع النطاق يعتمد على البشر إلى حد ما، ولا تؤدي LLM إلا إلى زيادة الطلب على هذه الخدمات. وقد استفادت شركات مثل Scale AI، التي يشمل عملاؤها OpenAI، من هذا الطلب للوصول إلى تقييمات مكونة من 11 رقمًا. حتى أن شركة أوبر تقوم بإعادة استخدام بعض عمالها في الهند لتسمية مخرجات الذكاء الاصطناعي عندما لا يقودون سياراتهم.
في سعيهم لأن يصبحوا حلاً متكاملاً لبيانات الذكاء الاصطناعي، دخلت شركة Grass أيضًا هذا السوق. سيصدرون قريبًا حلاً للتعليقات التوضيحية بتقنية الذكاء الاصطناعي (كامتداد لمنتجهم الرئيسي) حيث سيتمكن المستخدمون على نظامهم الأساسي من الحصول على حوافز لاستكمال مهام RLHF.
السؤال هو: ما الميزة التي تكتسبها شركة Grass من خلال عملية اللامركزية مقارنة بمئات الشركات المركزية في نفس المجال؟
يمكن أن يستخدم Grass حوافز رمزية لتمهيد شبكة من العمال. تمامًا مثلما يستخدمون الرموز المميزة لمكافأة المستخدمين على مشاركة النطاق الترددي للإنترنت الخاص بهم، يمكن استخدامها أيضًا لمكافأة البشر على تصنيف بيانات تدريب الذكاء الاصطناعي. في عالم Web2، يعد دفع أجور العاملين في اقتصاد الوظائف المؤقتة، خاصة بالنسبة للوظائف الموزعة عالميًا، تجربة مستخدم سيئة مقارنة بالسيولة الفورية المتاحة في blockchain سريع مثل Solana.
بشكل عام، يضم مجتمع العملات المشفرة، وخاصة مجتمع Grass الحالي، بالفعل تركيزًا كبيرًا من المستخدمين المتعلمين ومستخدمي الإنترنت والمتميزين تقنيًا. وهذا يقلل من الموارد التي تحتاج شركة Grass إلى إنفاقها على توظيف وتدريب العمال.
قد تتساءل عما إذا كان تبادل الحوافز لمهمة شرح استجابات نماذج الذكاء الاصطناعي من شأنه أن يجذب انتباه المزارعين والروبوتات. لدي نفس السؤال. لحسن الحظ، تم إجراء بحث مكثف باستخدام تقنيات مبنية على الإجماع لتحديد التعليقات التوضيحية عالية الجودة وتصفية الروبوتات.
يرجى ملاحظة أنه، على الأقل في الوقت الحالي، تدخل Grass فقط إلى سوق RLHF (التعلم المعزز من خلال التعليقات البشرية) ولا تساعد الشركات على تحسين المحادثات. الأمر الذي يتطلب درجة عالية من سوق العمل المتخصص ويصعب أتمتته.
بمجرد التدريب المسبق وبعد الانتهاء من خطوات المحاذاة نحصل على ما يسمى بالنموذج الأساسي. تتمتع النماذج الأساسية بفهم عام لكيفية عمل العالم، ويمكنها إجراء محادثات بطلاقة تشبه المحادثات البشرية حول مجموعة واسعة من المواضيع. كما أنه يتمتع بإجادة اللغات ويساعد المستخدمين على إنشاء رسائل البريد الإلكتروني والقصص والقصائد والمقالات والأغاني بسهولة.
عند استخدام ChatGPT، فإنك تتفاعل مع النموذج الأساسي GPT-4.
النموذج الأساسي هو نموذج عالمي. في حين أن لديهم الكثير من المعرفة حول الملايين من فئات المواضيع، إلا أنهم لا يتخصصون في أي منها. عندما يُطلب منك المساعدة في فهم اقتصاد عملة البيتكوين، ستكون الإجابات مفيدة ودقيقة في الغالب. ومع ذلك، لا يجب أن تثق به عندما تطلب منه توضيح كيفية التخفيف من مخاطر بروتوكول الاستعادة مثل EigenLayer.
تذكر أن الضبط الدقيق يتطلب نموذجًا للتعلم الآلي تم تدريبه مسبقًا ويقوم بتدريبه بشكل أكبر على مجموعة بيانات أصغر ومستهدفة لمساعدته على التكيف مع مهمة معينة أو عملية حالة الاستخدام. لقد ناقشنا سابقًا الضبط الدقيق في سياق تحويل أدوات إكمال النص الخام إلى نماذج محادثة. وبالمثل، يمكننا ضبط النموذج الأساسي الذي تم إنشاؤه لتخصيصه في مجال أو مهمة محددة.
تم تدريب Med-PaLM2، وهو إصدار محسّن من نموذج Google الأساسي PaLM-2، على تقديم إجابات عالية الجودة للأسئلة الطبية. تم ضبط MetaMath بدقة على Mistral-7B لأداء التفكير الرياضي بشكل أفضل. تتخصص بعض النماذج المحسّنة في فئات محددة، مثل رواية القصص، وتلخيص النصوص، وخدمة العملاء، بينما يتخصص البعض الآخر في مجالات متخصصة، مثل الشعر البرتغالي، والترجمة الهندية-الإنجليزية، والقانون السريلانكي.
يتطلب الضبط الدقيق لنموذج لحالة استخدام محددة مجموعة بيانات عالية الجودة ذات صلة بحالة الاستخدام تلك. يمكن أن تنشأ مجموعات البيانات هذه من مواقع الويب الخاصة بمجال معين (مثل النشرات الإخبارية التي تحتوي على بيانات مشفرة)، أو مجموعات البيانات الخاصة (قد يسجل المستشفى الآلاف من التفاعلات بين الطبيب والمريض)، أو خبرة الخبراء (الأمر الذي سيتطلب مقابلات شاملة لالتقاطها).

مع انتقالنا إلى عالم يضم الملايين من نماذج الذكاء الاصطناعي، أصبحت مجموعات البيانات المتخصصة ذات الذيل الطويل هذه ذات قيمة متزايدة. ومن شركات المحاسبة الكبرى مثل إرنست ويونغ إلى المصورين المستقلين في غزة، تتم مغازلة أصحاب مجموعات البيانات هذه لأنها ستصبح قريبًا السلعة الأكثر سخونة في سباق التسلح للذكاء الاصطناعي. ظهرت خدمات مثل Gulp Data لمساعدة الشركات على تقييم قيمة بياناتها بشكل عادل.
لدى OpenAI طلب عام يسعى إلى إقامة شراكات بيانات مع كيانات لديها "مجموعات بيانات واسعة النطاق تعكس المجتمع البشري ولا تتوفر بسهولة للجمهور عبر الإنترنت اليوم." .
نحن نعرف طريقة واحدة على الأقل للتوفيق بين المشترين الذين يبحثون عن منتجات محددة مع البائعين: الأسواق عبر الإنترنت! أنشأت شركة Ebay سوقًا للمقتنيات، وأنشأت Upwork سوقًا للعمالة البشرية، وأنشأت منصات لا تعد ولا تحصى أسواقًا لعدد لا يحصى من الفئات الأخرى. وليس من المستغرب أن نشهد أيضًا ظهور أسواق، بعضها لامركزي، لمجموعات البيانات المتخصصة.
تقوم شركة Bagel ببناء "بنية تحتية مشتركة"، وهي مجموعة من الأدوات التي ستمكن أصحاب "البيانات المتنوعة وعالية الجودة" من الحصول على طريقة جديرة بالثقة والحفاظ على الخصوصية لمشاركة بياناتهم مع شركات الذكاء الاصطناعي. لقد حققوا ذلك باستخدام تقنيات مثل المعرفة الصفرية (ZK) والتشفير المتماثل بالكامل (FHE).
غالبًا ما تحتفظ الشركات ببيانات قيمة للغاية ولا يمكنها تحقيق الدخل منها، بسبب مشكلات الخصوصية أو المنافسة. على سبيل المثال، قد يكون لدى مختبر الأبحاث كميات كبيرة من البيانات الجينومية التي لا يمكنه مشاركتها لحماية خصوصية المريض، أو قد يكون لدى الشركة المصنعة للسلع الاستهلاكية بيانات حول تقليل خردة سلسلة التوريد والتي لا يمكنها الكشف عنها دون الكشف عن أسرار تنافسية. يستخدم Bagel التطورات في مجال التشفير لجعل مجموعات البيانات هذه مفيدة مع تخفيف المخاوف المصاحبة.
يمكن أن تساعد خدمات الوكيل السكني لشركة Grass أيضًا في إنشاء مجموعات بيانات احترافية. على سبيل المثال، إذا كنت ترغب في تحسين نموذج لتقديم نصائح متخصصة في الطهي، فيمكنك أن تطلب من Grass استخراج البيانات من مواقع Reddit الفرعية مثل r/Cooking وr/AskCulinary. وبالمثل، يمكن لمنشئ نموذج موجه للسفر أن يطلب من Grass استخراج البيانات من منتدى TripAdvisor.
على الرغم من أن هذه المصادر ليست مملوكة بالكامل، إلا أنها لا تزال بمثابة مكملات قيمة لمجموعات البيانات الأخرى. تخطط Grass أيضًا لاستخدام شبكتها لإنشاء مجموعات بيانات مؤرشفة يمكن لأي عميل إعادة استخدامها.
حاول أن تسأل ماجستير إدارة الأعمال المفضل لديك " متى هل الموعد النهائي للتدريب الخاص بك؟ ”سوف تحصل على إجابة مثل نوفمبر 2023. وهذا يعني أن النموذج الأساسي يوفر فقط المعلومات المتوفرة قبل ذلك التاريخ. وهذا أمر منطقي بالنظر إلى التكلفة الحسابية واستهلاك الوقت لتدريب هذه النماذج (أو ضبطها).
لإبقائها محدثة في الوقت الفعلي، سيتعين عليك تدريب ونشر نموذج جديد كل يوم، وهو أمر غير ممكن (على الأقل حتى الآن).
ومع ذلك، فإن الذكاء الاصطناعي الذي لا يحتوي على معلومات محدثة حول العالم يكون عديم الفائدة إلى حد ما بالنسبة للعديد من حالات الاستخدام. على سبيل المثال، إذا كنت أستخدم مساعدًا رقميًا شخصيًا يعتمد على ردود خبراء LLM، فسيكون محدودًا عندما يُطلب منهم تلخيص رسائل البريد الإلكتروني غير المقروءة أو تقديم الهداف من مباراة ليفربول الأخيرة.
لتجاوز هذه القيود وتزويد المستخدمين بإجابات بناءً على المعلومات في الوقت الفعلي، يمكن لمطوري التطبيقات الاستعلام عن المعلومات وإدراجها في ما يسمى "سياق" التطبيق نافذة النموذج الأساسي". نافذة السياق هي نص إدخال يمكن لـ LLM معالجته لإنشاء استجابة. يتم قياسه بالرموز ويمثل النص الذي يمكن لـ LLM "رؤيته" في أي لحظة.
لذا، عندما أطلب من مساعدي الرقمي تلخيص رسائل البريد الإلكتروني غير المقروءة، يقوم التطبيق أولاً باستعلام موفر البريد الإلكتروني الخاص بي عن محتويات جميع رسائل البريد الإلكتروني غير المقروءة، وإدراج الرد في تم إرسال مطالبة إلى LLM، وإلحاق شيء مثل: "لقد قدمت قائمة بجميع الرسائل غير المقروءة في صندوق الوارد الخاص بـ Shlok. يرجى تلخيصها باستخدام هذا السياق الجديد، يمكن لـ LLM بعد ذلك إكمال المهام وتقديم الردود. فكر في هذه العملية كما لو أنك قمت بنسخ ولصق بريد إلكتروني في ChatGPT وطلبت منه إنشاء رد، ولكنه يحدث في الواجهة الخلفية.
لإنشاء تطبيقات ذات استجابات محدثة، يحتاج المطورون إلى الوصول إلى البيانات في الوقت الفعلي. يمكن للعقد العشبية الزحف إلى أي موقع ويب في الوقت الفعلي ويمكنها توفير هذه البيانات للمطورين. على سبيل المثال، يمكن لتطبيق إخباري قائم على LLM أن يطلب من Grass الزحف إلى جميع المقالات الشائعة في أخبار Google كل خمس دقائق. عندما يستفسر أحد المستخدمين "ما هو حجم الزلزال الذي ضرب مدينة نيويورك؟"، يقوم تطبيق الأخبار باسترداد المقالات ذات الصلة، ويضيفها إلى نافذة سياق LLM، ويشارك الاستجابة مع المستخدم.
هذا هو المكان الذي تتأقلم فيه ماسا اليوم. في الوقت الحالي، تعد Alphabet وMeta وX هي المنصات الكبيرة الوحيدة التي تحتوي على بيانات مستخدم يتم تحديثها باستمرار بسبب قاعدة مستخدميها. تعمل ماسا على تكافؤ الفرص أمام الشركات الناشئة الصغيرة.
المصطلح الفني لهذه العملية هو إنشاء عملية الاسترجاع المعززة (RAG). يقع سير عمل RAG في قلب جميع التطبيقات الحديثة المستندة إلى LLM. تتضمن هذه العملية توجيه النص، أو تحويل النص إلى مجموعة من الأرقام التي يمكن بعد ذلك تفسيرها ومعالجتها وتخزينها والبحث فيها بسهولة بواسطة أجهزة الكمبيوتر.
تخطط شركة Grass لإصدار عقد الأجهزة المادية في المستقبل لتزويد العملاء ببيانات موجهة ومنخفضة زمن الوصول في الوقت الفعلي لتبسيط سير عمل RAG الخاص بهم.
يتوقع معظم منشئي الصناعة أن الاستعلامات على مستوى السياق (المعروفة أيضًا باسم الاستدلال) ستستخدم غالبية الموارد (الطاقة والحوسبة والبيانات) في المستقبل . هذا يبدو منطقيا. سيكون تدريب النموذج دائمًا عملية محددة زمنياً وتستهلك قدرًا معينًا من تخصيص الموارد. من ناحية أخرى، يمكن أن يكون للاستخدام على مستوى التطبيق، من الناحية النظرية، متطلبات غير محدودة.
لقد شهدت شركة Gras حدوث ذلك، حيث تأتي غالبية طلبات البيانات النصية الخاصة بها من العملاء الذين يبحثون عن البيانات في الوقت الفعلي.
تتوسع نافذة سياق LLM بمرور الوقت. عندما أصدرت OpenAI ChatGPT لأول مرة، كانت نافذة السياق الخاصة بها تحتوي على 32000 رمزًا مميزًا. وبعد أقل من عامين، أصبح لدى نموذج Gemini من Google نافذة سياقية تضم أكثر من مليون رمز مميز. مليون رمز يعادل أكثر من أحد عشر كتابًا مكونة من 300 صفحة - الكثير من النصوص.
تسمح هذه التطورات للنوافذ السياقية بالدمج في أشياء أكبر بكثير من مجرد الوصول إلى المعلومات في الوقت الفعلي. على سبيل المثال، يمكن لشخص ما تفريغ جميع كلمات تايلور سويفت، أو أرشيف هذه النشرة الإخبارية بالكامل، في نافذة السياق ويطلب من LLM إنشاء جزء جديد من المحتوى بأسلوب مماثل.
ما لم تتم برمجة النموذج بشكل صريح على عدم القيام بذلك، فسوف ينتج مخرجات جيدة جدًا.
إذا كان بإمكانك الشعور بتوجه هذه المناقشة، فانتظر وشاهد ما سيحدث بعد ذلك. لقد ناقشنا حتى الآن النماذج النصية بشكل أساسي، لكن النماذج التوليدية أصبحت أيضًا ماهرة جدًا في الأساليب الأخرى مثل توليد الصوت والصورة والفيديو. لقد عثرت مؤخرًا على هذا الرسم التوضيحي الرائع للندن بواسطة Orkhan Isayen على Twitter.

Midjourney، تحتوي أداة تحويل النص إلى صورة الشائعة (والجيدة جدًا) هذه على ميزة تسمى Style Modifier والتي يمكنها إنشاء صور جديدة بنفس نمط الصور الموجودة (تعتمد هذه الميزة أيضًا على سير عمل يشبه RAG، ولكن ليس بالضبط نفس الشيء). لقد قمت بتحميل الرسم التوضيحي المصنوع يدويًا من Orkhan واستخدمت أداة تعديل النمط Midjourney لتغيير المدينة إلى نيويورك. هذا ما أحصل عليه:

أربع صور، إذا نظرت إلى الرسوم التوضيحية لهذا الفنان، يمكن أن تخطئ بسهولة في أنها أعماله. ويتم إنشاء هذه الصور بواسطة الذكاء الاصطناعي في 30 ثانية بناءً على صورة إدخال واحدة. لقد طلبت "نيويورك"، ولكن الموضوع يمكن أن يكون أي شيء، حقًا. ويمكن تحقيق أنواع مماثلة من التكرار بطرائق أخرى، مثل الموسيقى.
تذكر مناقشتنا السابقة حول بعض الكيانات التي تقاضي شركات الذكاء الاصطناعي، بما في ذلك المبدعين، ويمكنك أن ترى السبب وراء كون ذلك منطقيًا.
كان الإنترنت بمثابة نعمة للمبدعين، ووسيلة لهم لمشاركة قصصهم وفنونهم وموسيقاهم وأشكال التعبير الإبداعي الأخرى مع العالم لكي يتمكنوا من إيجاد الطريق إلى 1000 معجب حقيقي لديك. والآن، أصبحت نفس المنصة العالمية أكبر تهديد لسبل عيشهم.
لماذا تدفع رسوم عمولة قدرها 500 دولار بينما يمكنك الحصول على نسخة قريبة بما فيه الكفاية من حيث الأسلوب لعمل Orkhan مقابل اشتراك شهري بقيمة 30 دولارًا من القماش الصوفي في Midjourney؟
هل يبدو الأمر بائسًا؟
إن الشيء العظيم في التكنولوجيا هو أنها تأتي دائمًا بطرق جديدة لحل المشكلات التي تخلقها. إذا قلبت الوضع الذي يبدو قاتمًا بالنسبة لمنشئي المحتوى رأسًا على عقب، فسترى أن هذه هي فرصتهم لتحقيق الدخل من مواهبهم على نطاق غير مسبوق.
قبل الذكاء الاصطناعي، كانت كمية الأعمال الفنية التي يمكن للأوركان إنشاؤها محدودة بعدد الساعات التي يقضونها في اليوم الواحد. ومع الذكاء الاصطناعي، يمكنهم الآن من الناحية النظرية خدمة قاعدة عملاء غير محدودة.
لفهم ما أعنيه، دعونا نلقي نظرة على elf.tech، منصة الموسيقى المدعومة بالذكاء الاصطناعي من الموسيقار غرايمز. يتيح لك Elf Tech تحميل تسجيل لأغنية، والتي تتحول بعد ذلك إلى صوت وأسلوب Grimes. يتم تقسيم أي عائدات مكتسبة من الأغنية بنسبة 50-50 بين غرايمز والمبدع. هذا يعني أنه، باعتبارك من محبي غرايمز أو صوتها أو حفلاتها الموسيقية أو توزيعها، يمكنك ببساطة التوصل إلى فكرة لأغنية ومن ثم تستفيد المنصة من الذكاء الاصطناعي لتحويلها إلى صوت غرايمز.
إذا حققت هذه الأغنية نجاحًا كبيرًا، فستستفيد أنت وغرايمز. يسمح هذا أيضًا لـ Grimes بتوسيع مواهبها والاستفادة من توزيعها بشكل سلبي.
TRINITI، التكنولوجيا التي تدعم elf.tech، هي أداة أنشأتها شركة CreateSafe. يكشف ورقهم الأدبي عن أحد التقاطعات الأكثر إثارة للاهتمام التي نتوقعها بين تقنيات blockchain وتقنيات الذكاء الاصطناعي التوليدية.
توسيع تعريف المحتوى الرقمي من خلال العقود الذكية التي يتحكم فيها منشئ المحتوى وإعادة تصور التوزيع من خلال المعاملات الدقيقة المستندة إلى blockchain والند للند والدفع مقابل الوصول، يسمح لأي منصة بث بالمصادقة على المحتوى الرقمي والوصول إليه على الفور. يقوم الذكاء الاصطناعي التوليدي بعد ذلك بتنفيذ عمليات دفع صغيرة فورية بناءً على الشروط التي يحددها المنشئ ويبث التجربة إلى المستهلك.
يضعها بالاجي بشكل أكثر إيجازًا.
مع ظهور وسائل الإعلام الجديدة، نسارع إلى معرفة كيفية تفاعل البشر معها. وعندما تقترن بالشبكات، فإنها تصبح محركات قوية للتغيير. قدمت الكتب الوقود للثورة البروتستانتية. كانت الإذاعة والتلفزيون جزءًا مهمًا من الحرب الباردة. إن وسائل الإعلام غالبا ما تكون سلاحا ذا حدين. يمكن استخدامه للخير أو للشر.
ما لدينا اليوم هو شركات مركزية تمتلك معظم بيانات المستخدم. يبدو الأمر كما لو أننا نثق في شركاتنا للقيام بالشيء الصحيح من أجل الإبداع وصحتنا العقلية ومجتمع أفضل. وهذه قوة كبيرة جدًا بحيث لا يمكن منحها لحفنة من الشركات التي لا نعرف الكثير عن أعمالها الداخلية.
ما زلنا في المراحل الأولى من ثورة LLM. كما هو الحال مع إيثريوم في عام 2016، ليس لدينا أي فكرة تقريبًا عن نوع التطبيقات التي يمكن إنشاؤها باستخدامها. ماجستير في القانون الذي يمكنه التحدث مع جدتي باللغة الهندية؟ وكيل ذكي قادر على تصفح تدفقات المعلومات وتقديم بيانات عالية الجودة فقط؟ آلية للمساهمين المستقلين لمشاركة الفروق الدقيقة ثقافيًا (مثل اللغة العامية)؟ هناك الكثير من الاحتمالات التي لا نعرفها بعد.
ومع ذلك، فمن الواضح أن إنشاء هذه التطبيقات سيكون مقيدًا بعنصر رئيسي واحد: البيانات.
تمثل البروتوكولات مثل Grass وMasa وBagel البنية الأساسية التي توفر مصدر البيانات بطريقة عادلة. الخيال البشري هو الحد عند النظر في ما يمكن البناء عليه. بالنسبة لي، يبدو هذا مثيرًا.
تقديم التشفير المتماثل بالكامل (FHE): استكشف تطبيقاته المثيرة وقيوده وأحدث التطورات التي تزيد شعبيته.
JinseFinanceمع استكمال Zama تمويلًا بقيمة 73 مليون دولار، ظهر نظام التشفير المتماثل بالكامل.
JinseFinanceمن الواضح أن إثباتات المعرفة الصفرية (ZKP) مفيدة لتحسين قابلية التوسع والخصوصية في web3، ولكن يعوقها الاعتماد على أطراف ثالثة للتعامل مع البيانات غير المشفرة.
JinseFinanceفي 20 أبريل، أصدر أكثر من 40 منظمة وخبراء في الأمن السيبراني، بما في ذلك أعضاء في تحالف التشفير العالمي، بيانًا مشتركًا يدعو الحكومة التركية إلى عدم تقويض التشفير الشامل.
 Pr0phetMoggy
Pr0phetMoggy Coinlive
Coinlive  CointelegraphCoinlive
CointelegraphCoinlive 本文是对最近崭露头角的“加密艺术”领域的概述,也包含了使用“非同质化代币(NFT)”作为数字艺术发行机制的内容。
 Ftftx
FtftxBlockchain Life创始人表示,许多扎根于俄罗斯的加密货币交易所已逃离该国或者在非法经营。
Cointelegraph一群众议院民主党人的最新提议试图改变税法更新对“不从事经纪服务”的加密实体的影响。
Cointelegraph