ما هي مشاريع Llama Land وApus Network في مؤتمر AI on AO؟
قدم مؤتمر AI on AO مشروعين بشكل خاص: LlaMA Land وApus Network.
 JinseFinance
JinseFinance

المصدر: Heart of the Metaverse
ذكرت رويترز في 28 فبراير أن تخطط Meta لإصدار أحدث نسخة من نموذج اللغة واسع النطاق للذكاء الاصطناعي Llama 3 في يوليو. ستوفر النماذج إجابات أفضل للأسئلة المثيرة للجدل التي يطرحها المستخدمون.
يحاول الباحثون في مجال Meta ترقية النموذج لتقديم إجابات ذات صلة بالأسئلة المثيرة للجدل.
قامت Meta بتعليق ميزة إنشاء الصور الخاصة بها بعد أن أطلقت شركة Google المنافسة Gemini لأن الصور التاريخية التي تم إنشاؤها بواسطة الميزة كانت في بعض الأحيان غير دقيقة.
 <ص تعمل لعبة Meta's Llama 2 على تشغيل برامج الدردشة الآلية على منصة التواصل الاجتماعي الخاصة بها، ولكن وفقًا للاختبارات ذات الصلة، رفضت الإجابة على أسئلة أقل إثارة للجدل، مثل كيفية مزاح الأصدقاء، أو كيفية الفوز في الحروب، أو كيفية "قتل" محرك السيارة.
<ص تعمل لعبة Meta's Llama 2 على تشغيل برامج الدردشة الآلية على منصة التواصل الاجتماعي الخاصة بها، ولكن وفقًا للاختبارات ذات الصلة، رفضت الإجابة على أسئلة أقل إثارة للجدل، مثل كيفية مزاح الأصدقاء، أو كيفية الفوز في الحروب، أو كيفية "قتل" محرك السيارة.
ومع ذلك، فإن Llama 3 قادر على الإجابة على أسئلة مثل "كيفية إيقاف تشغيل محرك السيارة"، مما يعني أنه يفهم أن المستخدم يريد أن يسأل عن كيفية إيقاف تشغيل السيارة بدلاً من "القتل" فعليًا. المحرك. وقال التقرير إن شركة ميتا تخطط أيضًا لتعيين شخص داخلي في الأسابيع المقبلة للإشراف على التدريب على النغمة والسلامة في محاولة لجعل استجابات النموذج أكثر دقة.
في الواقع، في وقت مبكر من شهر يناير من هذا العام، أعلن الرئيس التنفيذي لشركة Meta Zuckerberg في مقطع فيديو إضافي أن Meta AI بدأت مؤخرًا في تدريب Llama 3. هذا هو أحدث جيل من سلسلة LLaMa من نماذج اللغات الكبيرة، في السابق، تم إصدار نموذج Llama 1 (الذي تم تصميمه في الأصل باسم "LLaMA") في فبراير 2023، وتم إصدار نموذج Llama 2 في يوليو.
بينما لم يتم الإعلان عن تفاصيل محددة (مثل حجم النموذج أو إمكانيات الوسائط المتعددة) بعد، قال زوكربيرج إن Meta تعتزم الاستمرار في فتح المصدر لنموذج Llama الأساسي.

القيمة لاحظ أن Llama 1 استغرق تدريبه ثلاثة أشهر بينما استغرق تدريب Llama 2 حوالي ستة أشهر. إذا اتبعت نماذج الجيل التالي جدولًا زمنيًا مشابهًا، فسيتم إصدارها في شهر يوليو من هذا العام تقريبًا.
ولكن من الممكن أيضًا أن تقوم Meta بتخصيص وقت إضافي للضبط الدقيق لضمان الترتيب الصحيح للنموذج.
نظرًا لأن النماذج مفتوحة المصدر أصبحت أكثر قوة وأصبحت نماذج الذكاء الاصطناعي التوليدية تستخدم على نطاق أوسع، فإننا نحتاج إلى توخي المزيد من الحذر من أجل تقليل مخاطر استخدام النماذج لأغراض ضارة من قبل جهات فاعلة سيئة
قوي > . وفي فيديو الإصدار، كرر زوكربيرج التزام ميتا بـ "التدريب المسؤول والآمن" للعارضات.أكد زوكربيرج أيضًا على التزام ميتا بالترخيص المفتوح وإضفاء الطابع الديمقراطي على الذكاء الاصطناعي في المؤتمر الصحفي اللاحق. قال لموقع The Verge: "أميل إلى الاعتقاد بأن أحد أكبر التحديات هنا هو أنك إذا قمت ببناء شيء ذي قيمة حقيقية، فسينتهي الأمر بأن يكون مركزًا وضيقًا للغاية. إذا سمحت لك بأن تكون أكثر انفتاحًا، فيمكن أن تحل مشكلة الكثير من المشاكل التي يمكن أن يجلبها عدم المساواة في الفرص والقيمة. لذا فإن هذا جزء مهم من رؤية المصدر المفتوح بأكملها. "
في فيديو الإصدار، أكد زوكربيرج أيضًا على هدف ميتا طويل المدى المتمثل في بناء AGI (الذكاء العام الاصطناعي). AGI هي مرحلة تطوير نظرية للذكاء الاصطناعي. في هذه المرحلة، <قوي> سيوضح النموذج الأداء العام الذي يمكن مقارنته بالذكاء البشري أو أفضل منه.
وقال زوكربيرج أيضًا: "لقد أصبح من الواضح بشكل متزايد أن الجيل القادم من الخدمات يحتاج إلى بناء ذكاء عام شامل. بناء أفضل مساعد للذكاء الاصطناعي والذكاء الاصطناعي الذي يخدم المبدعين، والذكاء الاصطناعي الذي يخدم المؤسسات، وما إلى ذلك". .، كلها تتطلب التقدم في جميع مجالات الذكاء الاصطناعي، بما في ذلك التفكير والتخطيط وترميز الذاكرة والقدرات المعرفية الأخرى."
من خطاب زوكربيرج، يمكننا أن نرى أن لا يعني نموذج Llama 3 بالضرورة أنه سيتم تحقيق الذكاء الاصطناعي العام، لكن Meta تجري بوعي تطوير LLM وأبحاث الذكاء الاصطناعي الأخرى بطريقة قد تحقق الذكاء الاصطناعي العام.
هناك اتجاه ناشئ آخر في مجال الذكاء الاصطناعي وهو الذكاء الاصطناعي متعدد الوسائط، أي النماذج التي يمكنها فهم ومعالجة تنسيقات البيانات المختلفة (أو الطرائق).
يمكن للنماذج مفتوحة المصدر مثل Google's Gemini وOpenAI's GPT-4V وLLaVa أو Adept أو Qwen-VL التبديل بسلاسة بين مهام رؤية الكمبيوتر ومعالجة اللغة الطبيعية (NLP) دون تطوير نماذج منفصلة لمعالجة النص، الكود والصوت والصورة وحتى بيانات الفيديو.
على الرغم من تأكيد زوكربيرج أن Llama 3، مثل Llama 2، ستتضمن إمكانات إنشاء التعليمات البرمجية، إلا أنه لم يتحدث صراحةً عن ميزات أخرى متعددة الوسائط.
ومع ذلك، ناقش زوكربيرج كيف يتصور تقاطع الذكاء الاصطناعي وMetaverse في فيديو إطلاق Llama 3: "نظارات Ray-Ban الذكية من Meta's تسمح للذكاء الاصطناعي بالنظر إليك. انظر إلى ما تسمعه، الشكل المثالي الذي تسمعه، يمكن أن يساعدك في أي وقت."

يبدو أن هذا يعني أن خطط Meta لنموذج Llama، سواء في إصدار Llama 3 القادم أو في الإصدارات اللاحقة، تتضمن دمج البيانات المرئية والصوتية المدمجة مع البيانات النصية والكود بالفعل معالجتها بواسطة LLM.
يبدو أن هذا أيضًا تطور طبيعي في السعي وراء الذكاء الاصطناعي العام.
وقال زوكربيرج في مقابلة مع موقع "The Verge": "يمكنك الجدال حول ما إذا كان الذكاء العام مشابهًا للذكاء على مستوى الإنسان، أو مشابهًا لذكاء الإنسان زائد الإنسان، أو نوع من الذكاء في المستقبل البعيد". الذكاء الفائق. لكن بالنسبة لي، الجزء المهم هو في الواقع اتساع نطاقه، حيث يتمتع الذكاء بكل هذه القدرات المختلفة ويجب أن تكون قادرًا على التفكير ويكون لديك حدس."
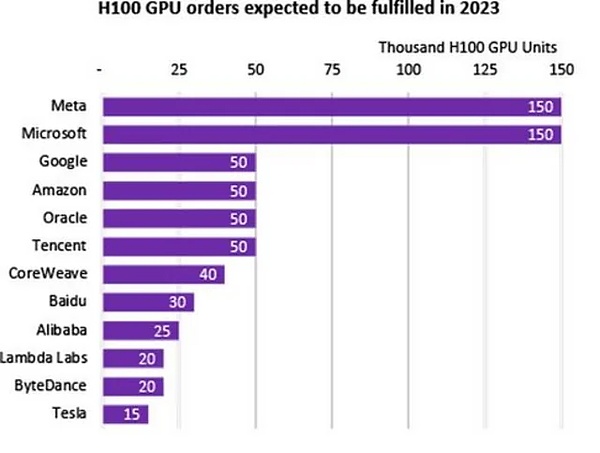
كما أعلن زوكربيرج عن استثمارات كبيرة في البنية التحتية للتدريب. بحلول نهاية عام 2024، تخطط Meta للحصول على ما يقرب من 350000 وحدة معالجة رسوميات NVIDIA H100.
سيؤدي هذا إلى رفع إجمالي موارد الحوسبة المتاحة لشركة Meta إلى 600000 مكافئ حوسبة H100، بما في ذلك وحدات معالجة الرسومات التي تمتلكها بالفعل. ولا تملك سوى شركة Microsoft حاليًا احتياطي طاقة حاسوبي مماثل.
لذلك ، لدينا سبب للاعتقاد بأنه حتى لو لم يكن نموذج Llama 3 أكبر من النموذج السابق، فسيتحسن أداءه بشكل ملحوظ مقارنةً بنموذج Llama 2.
طرحت شركة Deepmind الفرضية القائلة بأن أداء اللاما سيتحسن بشكل ملحوظ في ورقة بحثية نشرت في مارس 2022، وهو ما تم إثباته لاحقًا من خلال نموذج ميتا ونماذج أخرى مفتوحة المصدر (مثل نموذج شركة ميسترال الفرنسية) هذا، أي أن تدريب نموذج أصغر على المزيد من البيانات يؤدي إلى أداء أعلى من تدريب نموذج أكبر على بيانات أقل.
على الرغم من عدم الإعلان عن حجم نموذج Llama 3 بعد، إلا أنه من المرجح أن يستمر نمط الأجيال السابقة من النماذج، أي تحسين الأداء ضمن نموذج مكون من 7 إلى 7 مليارات معلمة . ستوفر استثمارات Meta الأخيرة في البنية التحتية إمكانات تدريب مسبق أكثر قوة للنماذج من أي حجم.
يعمل Llama 2 أيضًا على مضاعفة طول سياق Llama 1، مما يعني أن Llama 2 يمكنه "تذكر" السياق مرتين أثناء الاستدلال، ولدى Llama 3 القدرة على تحقيق مزيد من التقدم في هذا الصدد. .
بينما حقق طرازا LLaMA وLlama 2 الأصغر أداءً أو تجاوزا أداء نموذج GPT-3 الأكبر الذي يحتوي على 175 مليار معلمة في بعض المعايير، إلا أنهما لم يتمكنا من التنافس مع GPT-3.5 ونماذج GPT-4 المتوفرة في ChatGPT قابلة للمقارنة.

مع مع إطلاق جيل جديد من النماذج، يبدو أن Meta عازمة على تقديم أداء متطور إلى عالم مفتوح المصدر.
وقال زوكربيرج لـ "The Verge": "إن Llama 2 ليس النموذج الرائد في الصناعة، ولكنه أفضل نموذج مفتوح المصدر. مع Llama 3 وما بعده، هدفنا هو إنشاء المستوى الأكثر تقدمًا من المنتجات، وتصبح في نهاية المطاف النموذج الرائد في الصناعة."
مع النموذج الأساسي الجديد، هناك فرص جديدة لتحقيق مكاسب ميزة تنافسية من خلال التطبيقات المحسنة وروبوتات الدردشة وسير العمل والأتمتة.
إن التواجد في طليعة التطورات الناشئة هو أفضل طريقة لتجنب التخلف عن الركب، كما أن اعتماد أدوات جديدة يمكن أن يميز منتجات شركتك ويوفر أفضل تجربة للعملاء والموظفين.
قدم مؤتمر AI on AO مشروعين بشكل خاص: LlaMA Land وApus Network.
JinseFinanceيسلط Alibaba الضوء على تعدد استخدامات Qwen-7B و Qwen-7B-Chat ، مما يجعل الترميز وأوزان النموذج والوثائق في متناول الأكاديميين والباحثين والمؤسسات التجارية في جميع أنحاء العالم.
 Coinlive
Coinlive على الرغم من أن عام 2022 كان عامًا صعبًا بالنسبة لصناعة التكنولوجيا ، إلا أن Meta كانت تمر بمرحلة صعبة بشكل خاص.
 decrypt
decryptسيحتوي Instagram قريبًا على أدوات إنشاء وتداول NFT مضمنة ، ولكن عمليات الشراء داخل التطبيق ستكون "خاضعة لرسوم متجر التطبيقات المعمول بها".
 Others
Othersبدءًا من Teams و Office ، قالت Microsoft إن نظام التشغيل Windows الخاص بها سيكون متاحًا أيضًا من خلال سماعات الرأس في المستقبل.
 Beincrypto
Beincryptoبدأت Meta تغيير علامتها التجارية في الولايات المتحدة في يونيو ، وتقوم الآن بإجراء التغيير على مستوى العالم.
Others
V神称,Meta在元宇宙创新方面起步过早,因为“现在知道人们想要什么还为时过早。”
 Cointelegraph
Cointelegraphمدينة الإنترنت ، دبي ، 29 يوليو 2022 - أدرجت LBank Exchange ، وهي منصة تداول أصول رقمية عالمية ، بروتوكول META PROTOCOL (MPC) ...
 Bitcoinist
Bitcoinistتتلاشى بقايا مشروع Meta للعملات المشفرة الذي كان طموحًا في يوم من الأيام. وبحسب إشعار على موقعها على الإنترنت ، فإن البرنامج التجريبي ...
Bitcoinist