لماذا يجب أن يكون الذكاء الاصطناعي مفتوحًا
دعونا نستكشف "لماذا يحتاج الذكاء الاصطناعي إلى أن يكون مفتوحًا" تكون مفتوحة". خلفيتي هي في مجال التعلم الآلي، ولقد كنت أقوم بالعديد من وظائف التعلم الآلي لمدة عشر سنوات تقريبًا من حياتي المهنية. ولكن قبل أن أشارك في مجال العملات المشفرة وفهم اللغة الطبيعية وتأسيس شركة NEAR، عملت في Google. نقوم الآن بتطوير الإطار الذي يحرك الكثير من الذكاء الاصطناعي الحديث، والذي يسمى Transformer. بعد أن تركت جوجل، أنشأت شركة للتعلم الآلي حتى نتمكن من تعليم الآلات كيفية البرمجة، وبالتالي تغيير كيفية تفاعلنا مع أجهزة الكمبيوتر. لكننا لم نفعل ذلك في عام 2017 أو 2018. كان الوقت مبكرًا جدًا ولم تكن هناك قوة حاسوبية وبيانات للقيام بذلك.

ما كنا نفعله هو جذب الأشخاص من جميع أنحاء العالم للقيام بأعمال تصنيف البيانات لنا، ومعظمهم من الطلاب. وهم في الصين وآسيا وأوروبا الشرقية. والعديد منهم ليس لديهم حسابات مصرفية في هذه البلدان. الولايات المتحدة ليست على استعداد لإرسال الأموال بسهولة، لذلك بدأنا نرغب في استخدام تقنية blockchain كحل لمشكلتنا. نريد أن نسهل عملية الدفع للأشخاص حول العالم بطريقة برمجية، بغض النظر عن مكان وجودهم. بالمناسبة، التحدي الحالي الذي يواجه Crypto هو أنه على الرغم من أن NEAR تحل الآن الكثير من المشكلات، إلا أنك تحتاج عادةً إلى شراء بعض العملات المشفرة قبل أن تتمكن من التداول على blockchain لكسبها، وهو عكس العملية.
مثل الشركات، سيقولون، أولاً وقبل كل شيء، تحتاج إلى شراء بعض الأسهم في الشركة لاستخدامها. هذه واحدة من المشاكل العديدة التي نقوم بحلها في NEAR. الآن دعونا نتعمق في جانب الذكاء الاصطناعي قليلاً. النماذج اللغوية ليست جديدة، فهي موجودة منذ الخمسينيات. إنها أداة إحصائية تستخدم على نطاق واسع في أدوات اللغة الطبيعية. لفترة طويلة، بدءًا من عام 2013، مع إحياء التعلم العميق، بدأ ابتكار جديد. الابتكار هو أنه يمكنك مطابقة الكلمات وإضافتها إلى متجهات متعددة الأبعاد وتحويلها إلى شكل رياضي. يعمل هذا بشكل جيد مع نماذج التعلم العميق، والتي هي مجرد الكثير من وظائف ضرب المصفوفات وتنشيطها.

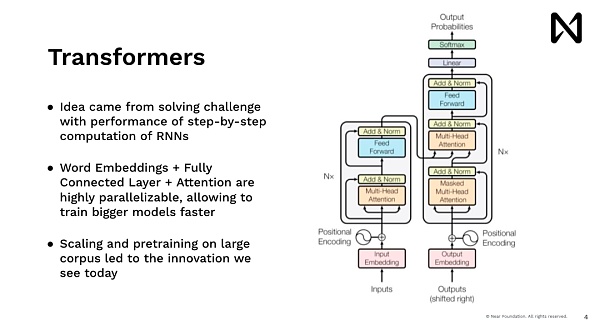
يسمح لنا هذا بالبدء في إجراء التعلم العميق المتقدم وتدريب النماذج للقيام بالكثير من الأشياء المثيرة للاهتمام. إذا نظرنا إلى الوراء الآن، ما كنا نفعله هو الشبكات العصبية العصبية، والتي تم تصميمها على غرار البشر إلى حد كبير، وكان بإمكاننا قراءة كلمة واحدة في كل مرة. لذا فإن القيام بذلك بطيء جدًا، أليس كذلك. إذا كنت تحاول عرض شيء ما للمستخدمين على Google.com، فلن ينتظر أحد لقراءة ويكيبيديا، على سبيل المثال، لمدة خمس دقائق قبل إعطاء إجابة، ولكنك تريد الإجابة على الفور. لذا فإن نموذج Transformers، وهو النموذج الذي يحرك ChatGPT وMidjourney وكل التقدم الأخير، يأتي من نفس فكرة وجود نظام يمكنه معالجة البيانات بالتوازي، ويمكنه التفكير، ويمكنه تقديم الإجابات على الفور.
لذا فإن أحد الابتكارات الرئيسية لهذه الفكرة هنا هو أن كل كلمة وكل رمز وكل صورة تتم معالجتها بالتوازي، مع الاستفادة من وحدات معالجة الرسومات لدينا وغيرها مسرعات ذات قدرات حوسبة متوازية للغاية. ومن خلال القيام بذلك، نكون قادرين على التفكير في الأمر بطريقة قابلة للتطوير. يتيح هذا التوسع إمكانية توسيع نطاق التدريب للتعامل مع بيانات التدريب الآلية. إذن، بعد ذلك، لدينا الدوبامين، الذي يقوم بعمل رائع في فترة قصيرة من الزمن، مما يتيح التدريب المتفجر. يحتوي على كمية هائلة من النصوص ويبدأ في تحقيق نتائج مذهلة في التفكير وفهم لغات العالم.
الاتجاه الحالي هو تسريع الابتكار في مجال الذكاء الاصطناعي. في السابق كان بمثابة أداة يستخدمها علماء البيانات ومهندسو التعلم الآلي، ثم يشرحونها بطريقة ما في منتجاتهم أو يكونون قادرين على مناقشة البيانات مع صناع القرار . محتوى. الآن لدينا هذا النموذج من الذكاء الاصطناعي للتواصل مباشرة مع الناس. قد لا تعرف حتى أنك تتواصل مع النموذج لأنه مخفي بالفعل خلف المنتج. لقد مررنا بهذا التحول من أولئك الذين يفهمون كيفية عمل الذكاء الاصطناعي إلى الفهم والقدرة على استخدامه.

لذا سأعطيك بعض السياق هنا، عندما نقول إننا نستخدم وحدة معالجة الرسومات لتدريب النموذج، فهي ليست نوع وحدة معالجة الرسومات المخصصة للألعاب التي نستخدمها على أجهزة الكمبيوتر المكتبية لدينا لتشغيل ألعاب الفيديو.

يحتوي كل جهاز عادةً على ثماني وحدات معالجة رسوميات، جميعها متصلة ببعضها البعض عبر اللوحة الأم، ثم يتم تجميعها في رفوف تضم كل منها حوالي 16 جهازًا. جميع هذه الرفوف متصلة الآن ببعضها البعض عبر كابلات شبكة مخصصة لضمان إمكانية نقل المعلومات مباشرة بين وحدات معالجة الرسومات بسرعات عالية للغاية. لذلك، لا يتم احتواء المعلومات في وحدة المعالجة المركزية. في الواقع، لن تقوم بمعالجتها على وحدة المعالجة المركزية على الإطلاق. تتم جميع الحسابات على GPU. إذن هذا هو إعداد الكمبيوتر العملاق. مرة أخرى، هذه ليست العبارة التقليدية "مرحبًا، هذا شيء يتعلق بوحدة معالجة الرسومات". لذلك استخدم نموذج واسع النطاق مثل GPU4 10000 H100 للتدريب في حوالي ثلاثة أشهر، بتكلفة 64 مليون دولار. أنت تعرف ما هو مقياس التكلفة الحالي وكم يكلف تدريب بعض النماذج الحديثة.
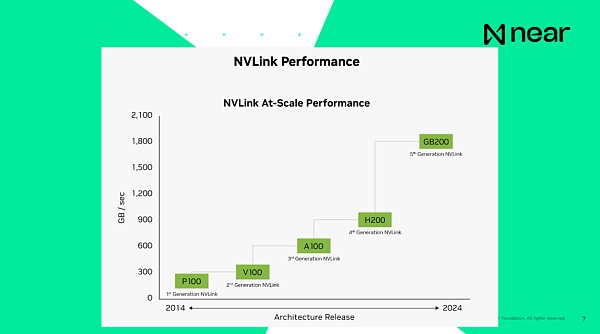
المهم، عندما أقول أن الأنظمة مترابطة، فإن سرعة الاتصال الحالية لجهاز H100، الجيل السابق، هي 900 جيجابايت في الثانية، وسرعة الاتصال بين وحدة المعالجة المركزية الداخلية للكمبيوتر وذاكرة الوصول العشوائي هي 200 جيجابايت في الثانية، وكلاهما محلي للكمبيوتر . ونتيجة لذلك، يمكن إرسال البيانات من وحدة معالجة الرسومات إلى أخرى بشكل أسرع من جهاز الكمبيوتر الخاص بك داخل نفس مركز البيانات. يمكن لجهاز الكمبيوتر الخاص بك أن يتصل بشكل أساسي من تلقاء نفسه داخل الصندوق. تبلغ سرعة الاتصال للجيل الجديد من المنتجات بشكل أساسي 1.8 تيرابايت في الثانية. من وجهة نظر المطور، هذه ليست وحدة حوسبة فردية. هذه هي أجهزة الكمبيوتر العملاقة التي تتمتع بكمية هائلة من الذاكرة وقدرة الحوسبة، مما يوفر لك عمليات حسابية واسعة النطاق للغاية.

الآن، يؤدي هذا إلى المشكلة التي لدينا، وهي هذه الشركات الكبيرة التي لديها الموارد والقدرات اللازمة لبناء هذه النماذج والتي تقدم لنا الآن هذه الخدمة إلى حد كبير، لا أعرف مقدار العمل المطلوب في الواقع في ذلك، أليس كذلك؟ إذن هذا مثال، أليس كذلك؟ تذهب إلى مزود خدمة مركزي بالكامل وتقوم بإدخال استعلام. اتضح أن هناك العديد من الفرق التي ليست فرق هندسة برمجيات ولكن هي الفرق التي تقرر كيفية عرض النتائج، أليس كذلك؟ لديك فريق يقرر البيانات التي تدخل في مجموعة البيانات.
على سبيل المثال، إذا قمت فقط باستخراج البيانات من الإنترنت، فإن عدد المرات التي ولد فيها باراك أوباما في كينيا وولد باراك أوباما في هاواي هو بالضبط نفس الشيء لأن الناس يحبون التكهن بالجدل. لذلك عليك أن تقرر ما الذي تريد التدرب عليه. لقد قررت تصفية بعض المعلومات لأنك لا تصدق أنها صحيحة. لذا، إذا قرر فرد مثل هذا أي البيانات سيتم استخدامها وموجودة، فإن تلك القرارات تتأثر إلى حد كبير بالشخص الذي اتخذها. لديك فريق قانوني يقرر أي محتوى لا يمكننا مشاهدته محمي بحقوق الطبع والنشر وأي محتوى غير قانوني. لدينا "فريق الأخلاقيات" الذي يقرر ما هو غير أخلاقي وما هو المحتوى الذي لا ينبغي أن نعرضه.
لذلك، بطريقة ما، هناك الكثير من عمليات التصفية والتلاعب هذه الجارية. هذه النماذج هي نماذج إحصائية. يتم إعدامهم من البيانات. إذا لم يكن هناك شيء ما في البيانات، فلن يعرفوا الإجابة. إذا كان هناك شيء ما في البيانات، فمن المرجح أن يتعاملوا معه على أنه حقيقة. الآن، عندما تحصل على إجابة من الذكاء الاصطناعي، يمكن أن يكون الأمر مقلقًا. يمين. الآن، من المفترض أن تحصل على إجابات من النموذج، لكن لا توجد ضمانات. أنت لا تعرف كيف تم إنشاء النتائج. قد تغير الشركة النتيجة فعليًا عن طريق بيع جلستك المحددة لمن يدفع أعلى سعر. تخيل أنك تسأل عن السيارة التي يجب أن تشتريها، وتقرر شركة تويوتا أنها يجب أن تفضل شركة تويوتا، وسوف تدفع للشركة 10 سنتات مقابل القيام بذلك.

لذا، حتى لو كنت تستخدم هذه النماذج كقاعدة معرفية من المفترض أن تكون محايدة وتمثل البيانات، في الواقع قبل أن تحصل على النتائج، تحدث أشياء كثيرة تؤدي إلى تحيز النتائج بطريقة محددة للغاية. هذا يثير بالفعل الكثير من الأسئلة، أليس كذلك؟ لقد كان في الأساس أسبوعًا من المعارك القانونية المختلفة بين الشركات الكبرى ووسائل الإعلام. هيئة الأوراق المالية والبورصة، يحاول الجميع تقريبًا مقاضاة بعضهم البعض في الوقت الحالي لأن هذه النماذج تخلق الكثير من عدم اليقين والقوة. وإذا كنت تتطلع إلى المستقبل، فالمشكلة هي أن شركات التكنولوجيا الكبرى سيكون لديها دائمًا حافز لمواصلة زيادة الإيرادات، أليس كذلك؟ على سبيل المثال، إذا كنت شركة عامة، فأنت بحاجة إلى الإبلاغ عن الإيرادات، وتحتاج إلى الاستمرار في النمو.
من أجل تحقيق هذا الهدف، إذا كنت قد احتلت السوق المستهدف بالفعل، فلنفترض أن لديك بالفعل 2 مليار مستخدم. لم يعد هناك الكثير من المستخدمين الجدد على الإنترنت بعد الآن. ليس لديك الكثير من الخيارات باستثناء زيادة متوسط الإيرادات إلى الحد الأقصى، مما يعني أنك بحاجة إلى استخراج قيمة أكبر من المستخدمين الذين قد تكون لديهم قيمة قليلة على الإطلاق، أو تحتاج إلى تغيير سلوكهم. يعد الذكاء الاصطناعي التوليدي جيدًا جدًا في معالجة سلوك المستخدم وتغييره، خاصة إذا اعتقد المرء أنه يأتي في شكل ذكاء يعرف كل شيء. لذلك لدينا هذا الوضع الخطير للغاية حيث يوجد الكثير من الضغوط التنظيمية ولا يفهم المنظمون تمامًا كيفية عمل هذه التكنولوجيا. نحن لا نفعل الكثير لحماية المستخدمين من التلاعب.

محتوى متلاعب، ومحتوى مضلل، حتى لو لم تكن هناك إعلانات، يمكنك فقط التقاط لقطة شاشة لشيء ما، وتغيير العنوان، ونشره على تويتر وسيصاب الناس بالجنون. لديك حوافز مالية تقودك إلى تعظيم دخلك باستمرار. وليس الأمر كما لو كنت داخل Google تفعل الشر، أليس كذلك؟ عندما تقرر النموذج الذي تريد إطلاقه، فإنك تقوم بإجراء اختبار A أو B لمعرفة النموذج الذي يحقق المزيد من الإيرادات. لذا، فأنت تعمل باستمرار على زيادة الإيرادات إلى أقصى حد عن طريق استخلاص المزيد من القيمة من المستخدمين. علاوة على ذلك، لم يكن لدى المستخدمين والمجتمع أي مساهمة في محتوى النموذج، أو البيانات المستخدمة، أو ما كان يحاول تحقيقه بالفعل. هذا هو الحال بالنسبة لمستخدمي التطبيق. هذا هو التعديل.
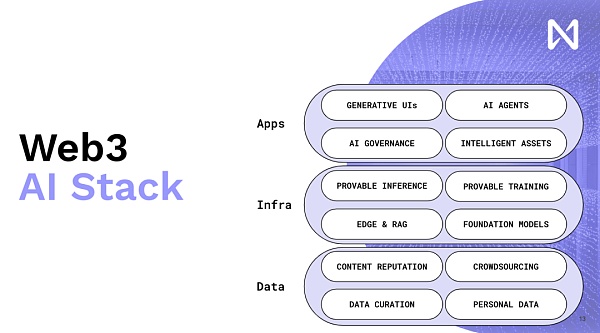
لهذا السبب نواصل تعزيز تكامل WEB 3 والذكاء الاصطناعي. يمكن أن يكون Web 3 أداة مهمة تتيح لنا الحصول على حوافز جديدة وفي شكل لا مركزي لتشجيعنا على إنتاج المزيد من المنتجات والبرمجيات والمنتجات الجيدة. هذا هو الاتجاه العام لتطوير الويب 3 للذكاء الاصطناعي بالكامل. الآن للمساعدة في فهم التفاصيل، سأتحدث بإيجاز عن الأجزاء المحددة أولاً، الجزء الأول هو سمعة المحتوى.

مرة أخرى، هذه ليست مشكلة ذكاء اصطناعي بحت، على الرغم من أن النماذج اللغوية توفر قوة هائلة وحجمًا للناس للتعامل مع المعلومات واستغلالها. ما تريده هو سمعة تشفير قابلة للتتبع ويمكن تتبعها والتي ستظهر عندما تنظر إلى محتوى مختلف. لذا تخيل أن لديك بعض عقد المجتمع المشفرة بالفعل والمتاحة في كل صفحة من كل موقع ويب. الآن، إذا ذهبت إلى ما هو أبعد من ذلك، فإن جميع منصات التوزيع هذه سوف تتعطل لأن هذه النماذج سوف تقرأ الآن كل هذا المحتوى تقريبًا وتعطيك ملخصات مخصصة ومخرجات مخصصة.
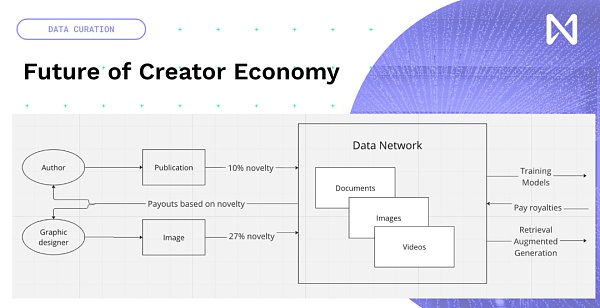
لذا لدينا بالفعل فرصة لإنشاء محتوى إبداعي جديد، وبدلاً من محاولة إعادة الابتكار، فلنضيف blockchain وNFTs إلى المحتوى الحالي. اقتصاد منشئ جديد يدور حول تدريب النماذج ووقت الاستدلال، حيث ستنتقل البيانات التي ينشئها الأشخاص، سواء كانت منشورًا جديدًا أو صورة أو موقع YouTube أو موسيقى تنشئها، إلى شبكة بناءً على مقدار مساهمتها في تدريب النماذج. وبناءً على ذلك، هناك بعض التعويضات المتاحة عالميًا بناءً على المحتوى. لذا، فإننا ننتقل من اقتصاد ملفت للنظر مدفوع الآن بشبكات الإعلانات إلى اقتصاد يقدم بالفعل معلومات مبتكرة ومثيرة للاهتمام.
أحد الأشياء المهمة التي أود أن أذكرها هو أن الكثير من عدم اليقين يأتي من عمليات الفاصلة العائمة. تتضمن كل هذه النماذج الكثير من عمليات الفاصلة العائمة والضرب. هذه عمليات غير مؤكدة.
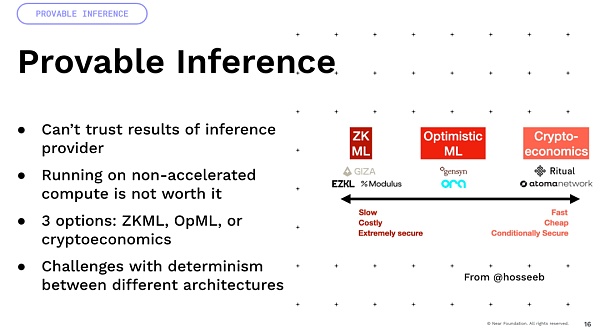
الآن، إذا قمت بضربهم على بنية مختلفة لوحدة معالجة الرسومات. لذا، إذا أخذت A100 وH100، ستكون النتائج مختلفة. ولذلك، فإن العديد من الأساليب التي تعتمد على الحتمية، مثل الاقتصاد المشفر والتفاؤل، ستواجه في الواقع الكثير من الصعوبات وتتطلب الكثير من الابتكار لتحقيق ذلك. أخيرًا، هناك فكرة مثيرة للاهتمام، لقد قمنا ببناء عملات قابلة للبرمجة وأصول قابلة للبرمجة، ولكن إذا كنت تتخيل أنك تضيف هذا الذكاء إليها، فمن الممكن أن يكون لديك أصول ذكية لم يتم تعريفها الآن بواسطة الكود، بل تم تحديدها من خلال القدرة اللغة الطبيعية للتفاعل مع العالم، أليس كذلك؟ هذا هو المكان الذي يمكننا فيه الحصول على الكثير من تحسين العائد المثير للاهتمام، DeFi، يمكننا القيام باستراتيجيات التداول داخل العالم.

التحدي الآن هو أن أياً من الأحداث الحالية ليس له سلوك قوي. لم يتم تدريبهم ليكونوا أقوياء في المواجهة لأن الغرض من التدريب هو التنبؤ بالرمز التالي. لذلك، سيكون من الأسهل إقناع العارضة بإعطائك كل أموالك. قبل المتابعة، من المهم معالجة هذه المشكلة فعليًا. لذلك سأترككم مع هذه الفكرة، نحن على مفترق طرق، أليس كذلك؟ هناك نظام بيئي مغلق للذكاء الاصطناعي يتمتع بحوافز وحذافات كبيرة لأنه عندما يطلقون منتجًا ما، فإنهم يحققون الكثير من الإيرادات ثم يستثمرون هذه الإيرادات في بناء المنتج. ومع ذلك، فإن المنتج مصمم بطبيعته لتعظيم إيرادات الشركة وبالتالي القيمة المستخرجة من مستخدميها. أو لدينا هذا النهج المفتوح المملوك للمستخدم حيث يكون المستخدم هو المتحكم.

تعمل هذه النماذج في الواقع لصالحك، حيث تحاول تعظيم فوائدك. إنها توفر لك طريقة لحمايتك حقًا من المخاطر العديدة على الإنترنت. ولهذا السبب نحتاج إلى مزيد من التطوير والتطبيقات لـ AI x Crypto. شكرا لكم جميعا.


 Hui Xin
Hui Xin





