Author: Faust; Source: Geek web3
B^2 Hub: Universal under the Bitcoin chain DA layer and verification layer
Today's Bitcoin ecosystem can be said to be a blue ocean where opportunities and scams coexist. This new field that has been revitalized by the Summer of Inscription is simply A fertile virgin land, the smell of money is everywhere. With the collective emergence of Bitcoin Layer 2 in January this year, this originally barren land instantly became the cradle of countless dream-makers.
But back to the most essential issue: what is Layer2, people never seem to reach a consensus. Is it a side chain? Is it an indexer? Is the chain that builds a bridge called Layer2? Can a simple plug-in that relies on Bitcoin and Ethereum be used as a Layer? These questions are like a set of difficult equations that never have a definite ending.
According to the thinking of the Ethereum and Celestia communities, Layer2 is just a special case of modular blockchain. In this case, the so-called "second layer" There will be a tight coupling relationship with the "first layer", and the second layer network can inherit the security of Layer 1 to a large extent or to a certain extent. As for the concept of security itself, it can be broken down into multiple subdivided indicators, including: DA, status verification, withdrawal verification, censorship resistance, reorganization resistance, etc.
Because the Bitcoin network itself has many problems, it is inherently not conducive to supporting a more complete Layer 2 network. For example, on DA, the data throughput of Bitcoin is much lower than that of Ethereum. Calculated based on its average block generation time of 10 minutes, the maximum data throughput of Bitcoin is only 6.8KB/s, which is almost 1/20 of Ethereum. , such a crowded block space naturally creates high data publishing costs.
(The cost of publishing data in a Bitcoin block can even reach $5 per KB)
If Layer2 directly publishes the newly added transaction data to the Bitcoin block, neither high throughput nor low handling fees can be achieved. So either use high compression to compress the data size as small as possible, and then upload it to the Bitcoin block. Citrea currently adopts this solution. They claim that they will upload the state change amount (state diff) over a period of time, that is, the result of the state changes that occurred on multiple accounts, together with the corresponding ZK certificate, to the Bitcoin chain. .
In this case, anyone can download the state diff and ZKP from the Bitcoin mainnet to verify whether they are valid, but the data size on the chain can Lightweight.
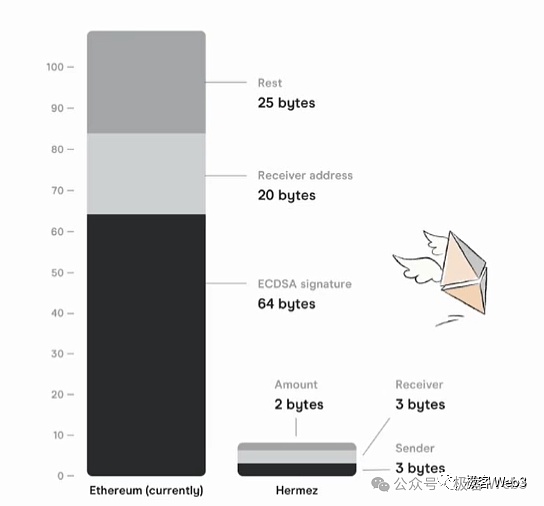
(The principle of the above compression scheme is explained in the white paper of the former Polygon Hermez)
While this solution greatly compresses the data size, it is still prone to encountering bottlenecks in the end. For example, assuming that tens of thousands of transactions occurred within 10 minutes, causing status changes in tens of thousands of accounts, you will eventually have to upload the changes in these accounts to the Bitcoin chain. Although it is much lighter than directly uploading each transaction data, it will still incur considerable data release costs.
So many Bitcoin Layer 2 simply do not upload DA data to the Bitcoin main network and directly use third-party DA layers such as Celestia. B^2 adopts another approach, building a DA network (data distribution network) directly under the chain, called B^2 Hub. In the B^2 protocol design, important data such as transaction data or state diff are stored off-chain, and only the storage index of these data, as well as the data hash (actually the merkle root, which is called data for convenience of expression), are uploaded to the Bitcoin mainnet. hash).
These data hashes and storage indexes are written to the Bitcoin chain in a manner similar to inscriptions. As long as you run a Bitcoin node, you can hash the data. And the storage index is downloaded locally. According to the index value, the original data can be read from the off-chain DA layer or storage layer of B^2. Based on the data hash, you can judge whether the data you obtained from the off-chain DA layer is correct (whether it corresponds to the data hash on the Bitcoin chain). Through this simple method, Layer2 can avoid over-reliance on the Bitcoin mainnet for DA issues, save handling fee costs and achieve high throughput.

Of course, one thing that cannot be ignored is that the third-party DA platform under the chain may engage in data withholding and refuse to allow the outside world to obtain new data. There is a special term for this scenario called "data withholding attack" , can be summarized as the anti-censorship problem in data distribution. Different DA solutions have different solutions, but the core purpose is to disseminate data as quickly and as widely as possible to prevent a small group of privileged nodes from controlling data acquisition permissions.
According to B^2 Network’s official new roadmap, its DA solution draws on Celestia. In the latter design, third-party data providers will continuously provide data to the Celestia network. Celestia block producers will organize these data fragments into the form of Merkle Tree, stuff them into TIA blocks, and broadcast them to the network. Validator/full node.
Because there is a lot of data and the blocks are relatively large, most people cannot afford to run full nodes and can only run light nodes. The light node does not synchronize the complete block, but only synchronizes a block header with the root of the Mekrle Tree written on it.
Light nodes only rely on the block header, so they naturally do not know the whole picture of the Merkle Tree, do not know what the new data contains, and cannot verify whether there is any problem with the data. But the light node can ask the full node for a certain leaf on the tree. The full node will submit the leaf and the corresponding Merkle Proof to the light node as required, so that the latter can be convinced that the leaf does exist on the Merkle Tree in the Celestia block and is not false data fabricated out of thin air by the node. .
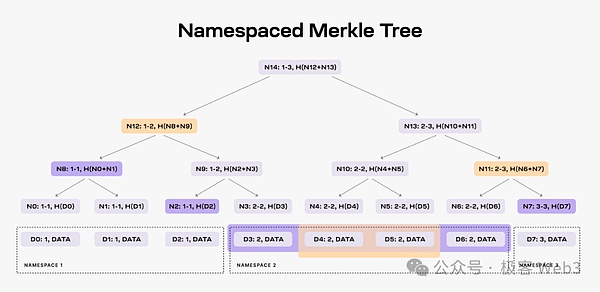
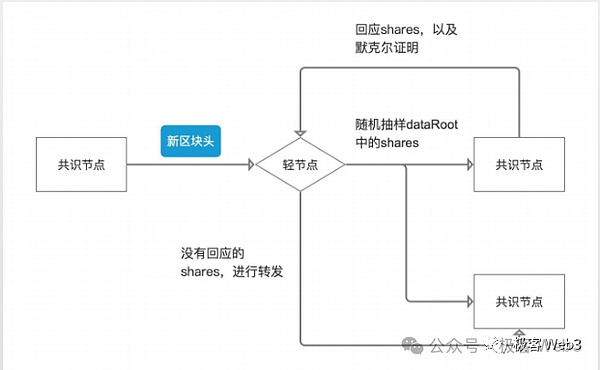
(Picture source: W3 Hitchhiker)
There are a large number of light nodes in the Celestia network, and these light nodes can initiate high-level requests to different full nodes. Frequent data sampling, randomly selecting certain data fragments on the Merkle Tree. After the light node obtains these data fragments, it can also spread them to other nodes it can connect to, so that the data can be quickly distributed to as many people/devices as possible to achieve efficient data dissemination, as long as there are enough All nodes can quickly obtain the latest data, and people no longer need to trust a small group of data providers. This is actually one of the core purposes of DA/data distribution.
Of course, there are still attack scenarios based on the solution described above, because it can only ensure that people can quickly obtain the data when the data is distributed, but it cannot Ensure that the source of data production does not do evil. For example, the Celestia block producer may add some junk data into the block. Even if people obtain all the data fragments in the block, they cannot restore the complete data set that "should be included" (note: here "should be" This word is important).
Furthermore, there may be 100 transactions in the original data set, and the data of a certain transaction has not been completely disseminated to the outside world. At this time, only 1% of the data fragments need to be hidden, and the outside world will not be able to parse the complete data set. This is exactly the scenario discussed in the earliest data withholding attack problems.
In fact, based on the scenario described here to understand data availability, the word availability describes whether the transaction data in the block is complete, available, and whether it can be directly It is left to others to verify, rather than as many people understand, availability represents whether the historical data of the blockchain can be read by the outside world. Therefore, Celestia officials and L2BEAT founders have pointed out that data availability should be renamed data release, which refers to whether a complete availability transaction data set is released in the block.
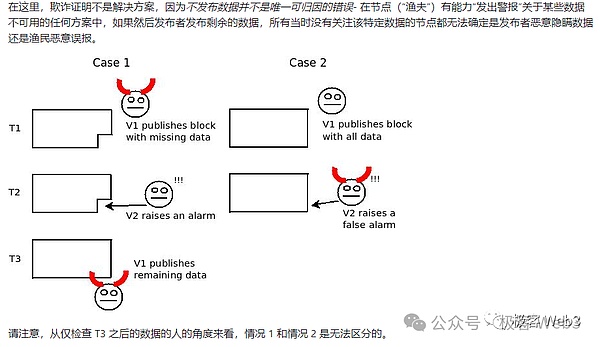
Celestia introduces two-dimensional erasure coding to solve the data withholding attack described above. As long as 1/4 of the data fragments (erasure codes) contained in the block are valid, people can restore the corresponding original data set. Unless the block producer mixes 3/4 of the junk data fragments into the block, the outside world cannot restore the original data set. However, in this case, the block contains too much junk data, and it can easily be Light nodes are detected. Therefore, for block producers, it is better not to do evil, because doing evil will be noticed by countless people almost immediately.
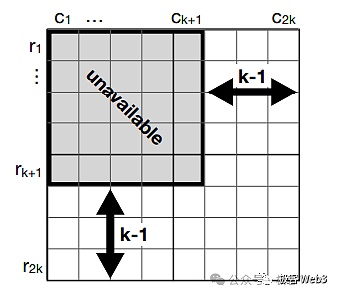
Through the solution described above, data withholding on the "data distribution platform" can be effectively prevented. In the future, B^2 Network will use Celestia's data sampling as an important reference, and may combine it with cryptography technologies such as KZG Commitment to further reduce the number of light nodes. The cost of performing data sampling and validation. As long as there are enough nodes performing data sampling, the distribution of DA data can be made effective and trustless.
Of course, the above solution only solves the data retention problem of the DA platform itself, but in the underlying structure of Layer2, it is not only the DA platform that has the ability to initiate data retention. There is also a Sequencer. In B^2 Network and even most Layer 2 workflows, new data is generated by the sequencer, which summarizes and processes the transactions sent by the user, along with the status change results after the execution of these transactions, and packages them into batches times (batch), and then sent to the B^2 Hub nodes acting as the DA layer.
If there is a problem with the batch generated by the sorter at the beginning, there is still the possibility of data withholding, and of course other forms of evil scenarios. Therefore, after B^2's DA network (B^2 Hub) receives the Batch generated by the sequencer, it will first verify the contents of the Batch and reject it if there is any problem. It can be said that B^2 Hub not only acts as a DA layer similar to Celestia, but also acts as an off-chain verification layer, somewhat similar to the role of CKB in the RGB++ protocol.
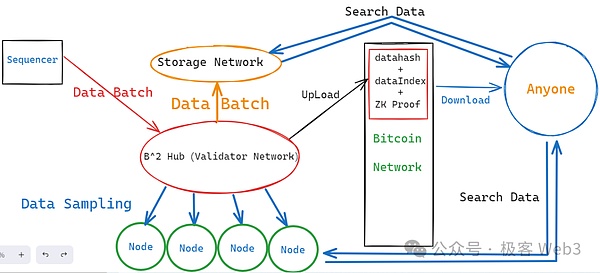
(Incomplete B^2 Network underlying structure diagram)
Follow B^2 Network's latest technology roadmap. After B^2 Hub receives and verifies the Batch, it will only retain it for a period of time. After this window period, the Batch data will be expired and deleted locally from the B^2 Hub node. Lose. In order to solve the problem of data obsolescence and loss similar to EIP-4844, B^2 Network has set up a group of storage nodes. These storage nodes will be responsible for permanently storing Batch data. In this way, anyone can access the data in the storage network at any time. Search for the historical data you need.
However, no one will run B^2 storage nodes for no reason. If you want more people to run storage nodes and enhance the trustlessness of the network, It is necessary to provide an incentive mechanism; to provide an incentive mechanism, it is necessary to first find ways to prevent cheating. For example, if you propose an incentive mechanism, anyone who stores data locally on their device can get rewards. Someone may secretly delete part of the data after downloading it, but claim that the data they stored is is complete, this is the most common cheating method.
Filecoin uses proof protocols called PoRep and PoSt to allow storage nodes to present storage certificates to the outside world to prove that they have indeed been completely saved within a given time period. data. However, this storage proof scheme requires the generation of ZK proofs, and the calculation complexity is very high. It will have high requirements on the hardware equipment of the storage nodes, and may not be an economically feasible method.
In the new version of the technology roadmap of B^2 Network, storage nodes will adopt a mechanism similar to Arweave and need to compete for the right to produce blocks to obtain token incentives. If a storage node privately deletes some data, its probability of becoming the next block producer will decrease. The node that retains the most data is more likely to successfully produce blocks and receive more rewards. Therefore, for most storage nodes, it is better to retain the complete historical data set.
Of course, there are incentives not only for storage nodes, but also for the B^2 Hub nodes mentioned earlier. According to the roadmap, B^2 Hub will be established A permissionless POS network, anyone who pledges enough Tokens can become a member of the B^2 Hub or storage network. In this way, B^2 Network attempts to create a decentralized DA off-chain. platform and storage platform, and will integrate Bitcoin Layer 2 other than B^2 in the future to build a universal DA layer and data storage layer under the Bitcoin chain.
State verification scheme using mixed ZK and fraud proof
We explained B^2 earlier Network's DA solution, next we will focus on its status verification solution. The so-called state verification scheme refers to how Layer 2 ensures that its state transition is sufficiently "trustless".
We mentioned earlier that in B^2 Network and even most Layer 2 workflows, new data is generated by the sequencer, which summarizes and processes the transactions sent by the user, and executes these transactions. The final status change results are packaged into batches and sent to other nodes in the Layer 2 network, including ordinary Layer 2 full nodes and B^2 Hub nodes.
After receiving the Batch data, the B^2 Hub node will parse its content and verify it. This includes the "status verification" mentioned above. . In fact, state verification is to verify whether the "state changes after transaction execution" recorded in the batch generated by the sequencer are correct. If the B^2 Hub node receives a Batch containing an error status, it will reject it.
In fact, B^2 Hub is essentially a POS public chain, and there will be a distinction between block producers and verifiers. Every once in a while, the block producers of B^2 Hub will generate new blocks and propagate them to other nodes (validators). These blocks contain the Batch data submitted by the sequencer. The remaining workflow is somewhat similar to the Celestia mentioned earlier. There are many external nodes that frequently request data fragments from the B^2 Hub node. In this process, the Batch data will be distributed to many node devices, including The storage network mentioned earlier.
There is a rotatable role named Committer in B^2 Hub, which will hash the Batch data (actually the Merkle root), and The storage index is submitted to the Bitcoin chain in the form of an inscription. As long as you read the data hash and storage index, there is a way to obtain the complete data in the DA layer/storage layer off the chain. Assume that there are N nodes under the chain that store Batch data. As long as one of the nodes is willing to provide data to the outside world, anyone can obtain the data it needs. The trust assumption here is 1/N.
Of course, it is not difficult for us to find that in the above process, the B^2 Hub, which is responsible for verifying the validity of Layer 2 state transitions, is independent of the Bitcoin main network and is just an off-chain verification layer. Therefore, at this time, Layer 2 The state verification scheme cannot be equivalent to the Bitcoin mainnet in terms of reliability.
Generally speaking, ZK Rollup can completely inherit the security of Layer1, but currently the Bitcoin chain only supports some extremely simple calculations and cannot directly verify ZK Proof, so there is no Layer2 that can be equivalent to the ZK Rollup of Ethereum in terms of security model, including Citrea and BOB.
At present, it seems that the "more feasible" idea is as explained in the BitVM white paper. The complex calculation process is moved off the Bitcoin chain and is only used when necessary. Sometimes some simple calculations are moved to the chain. For example, the calculation traces generated when verifying the ZK proof can be made public and handed over to the outside world for inspection. If people find that there is a problem with one of the more subtle calculation steps, they can verify this "controversial calculation" on the Bitcoin chain. This requires the use of Bitcoin scripting language to simulate the functions of special virtual machines such as EVM. The amount of engineering consumed may be very huge, but it is not unfeasible.
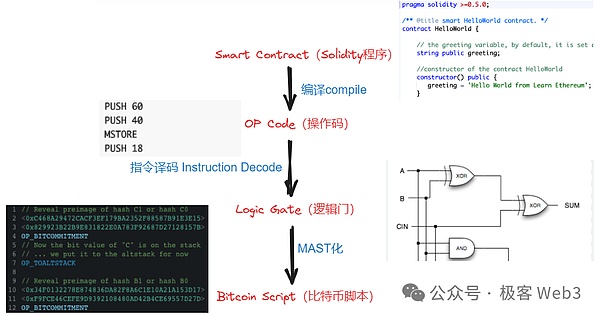
Reference material: "A minimalist interpretation of BitVM: How to verify fraud proof on the BTC chain (execute the operation code of EVM or other VM)"
In B^2 Network's technical solution, after the sorter generates a new Batch, it will be forwarded to the aggregator and Prover, which will verify the data of the Batch. ZKize, generate a ZK certificate, and finally forward it to the B^2 Hub node. The B^Hub node is EVM compatible. ZK Proof is verified through the Solidity contract. All the calculation processes involved will be split into very low-level logic gate circuits. These logic gate circuits will be written in the Bitcoin script language. Express it in form and submit it all to a third-party DA platform with sufficient throughput.
If people have questions about these disclosed ZK verification traces and feel that there is an error in a small step, they can "challenge" on the Bitcoin chain. Bitcoin nodes are asked to directly examine this problematic step and punish it appropriately.
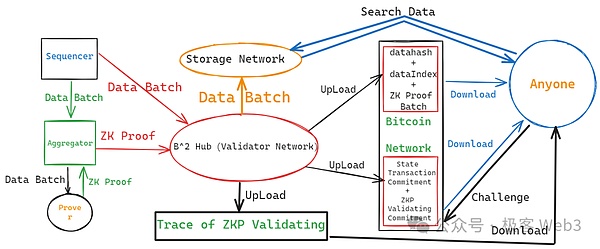
(The overall structure diagram of B^2 Network, excluding data sampling nodes)
So who is punished? Actually it's Committer. In the setting of B^2 Network, the Committer will not only publish the data hash mentioned above to the Bitcoin chain, but also publish the verification "commitment" of the ZK certificate to the Bitcoin main network. Through some settings of Bitcoin Taproot, you can question and challenge the "ZK Proof Verification Commitment" issued by Committer on the Bitcoin chain at any time.
Here is an explanation of "Commitment". The meaning of "commitment" is that some people claim that certain off-chain data is accurate and publish a corresponding statement on the chain. This statement is a "commitment", and the commitment value is bound to specific off-chain data. In the B^2 solution, if someone thinks there is a problem with the ZK verification commitment issued by the Committer, they can challenge it.
Some people may ask, wasn’t it mentioned earlier that B^2 Hub will directly verify the validity of the Batch after receiving it? Why is there so much more here? Verification ZK proof in one fell swoop? Why not just publicly disclose the process of verifying the batch and let people directly challenge it? Why do we have to introduce ZK proof? This is actually to compress the calculation traces to a small enough size. If the calculation process of verifying Layer 2 transactions and generating state changes is directly disclosed publicly in the form of logic gates and Bitcoin scripts, it will produce a huge data size. After ZKization, the data size can be greatly compressed before being released.
Here is a rough summary of the workflow of B^2:
< li>B^2's sequencer is responsible for generating new Layer2 blocks and aggregating multiple blocks into data batches. The data batch will be sent to the aggregator Aggregator and the Validator node in the B^Hub network.
The aggregator will send the data Batch to the Prover node, allowing the latter to generate the corresponding zeros Proof of knowledge. The ZK certificate will then be sent to B^2’s DA and verifier network (B^2Hub).
B^2Hub node will verify whether the ZK Proof sent by the aggregator can be sent to the Sequencer The Batch that came over corresponds. If the two can correspond, the verification is passed. The data hash and storage index of the verified Batch will be sent to the Bitcoin chain by a designated B^Hub node (called Committer).
B^Hub node will publicly disclose the entire calculation process of verifying ZK Proof, and will calculate The Commitment of the process is sent to the Bitcoin chain, allowing anyone to challenge it. If the challenge is successful, the B^Hub node that issued the Commitment will be economically punished (its UTXO on the Bitcoin chain will be unlocked and transferred to the challenger)
B^2 Network's state verification scheme introduces ZK on the one hand and uses fraud proof on the other. It is actually a hybrid state verification method. As long as there is at least one honest node under the chain and is willing to initiate a challenge after detecting an error, it can be guaranteed that there will be no problem with the state transition of B^2 Network.
According to the views of Western Bitcoin community members, the Bitcoin mainnet may undergo appropriate forks in the future to support more computing functions, perhaps in the future , directly verifying ZK proofs on the Bitcoin chain will become a reality, which will bring new paradigm-level changes to the entire Bitcoin Layer 2. As a general DA layer and verification layer, B^2 Hub can not only serve as a dedicated module of B^2 Network, but also empower other Bitcoin layer 2. In the era of Bitcoin Layer 2 competition, off-chain functions The expansion layer will surely become more and more important, and the emergence of B^Hub and BTCKB may have just revealed the tip of the iceberg of these functional expansion layers.


 JinseFinance
JinseFinance





