Google's new Gemini AI model beats GPT-4o in benchmark test
This is the first time that Google has topped the Chatbot Arena ranking.
 JinseFinance
JinseFinance

Source: Synced
Synced Editorial Department
General AI, AI that can be truly used in daily life, it’s embarrassing to hold a press conference now.
In the early morning of May 15, the annual "Spring Festival Gala of the Technology Industry" Google I/O Developer Conference officially opened. How many times did the 110-minute main keynote mention artificial intelligence? Google itself counted:

Yes, AI is talked about every minute.
The competition of generative AI has reached a new climax recently, and the content of this I/O conference is naturally centered around artificial intelligence.
"A year ago on this stage, we first shared plans for the native multimodal large model Gemini. It marks a new generation of I/O," said Sundar Pichai, CEO of Google. "Today, we hope that everyone can benefit from Gemini's technology. These breakthrough features will enter search, images, productivity tools, Android systems and other aspects."
24 hours ago, OpenAI deliberately released GPT-4o first, shocking the world through real-time voice, video and text interactions. Today, Google demonstrated Project Astra and Veo, which directly target OpenAI's leading GPT-4o and Sora.
This is a real-time shot of the Project Astra prototype:
We are witnessing the most high-end business war, carried out in the most simple way.
At the I/O conference, Google demonstrated the search capabilities enabled by the latest version of Gemini.
25 years ago, Google promoted the first wave of the information age through search engines. Now, with the evolution of generative AI technology, search engines can better help you answer questions, and it can better utilize contextual content, location awareness, and real-time information capabilities.
Based on the latest version of the customized Gemini large model, you can ask the search engine anything you think of, or anything that needs to be done - from research to planning to imagination, Google will take care of it all.
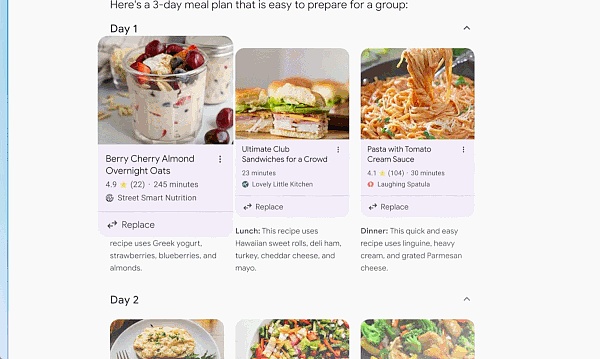
Sometimes you want an answer quickly but don't have time to piece all the information together. That's when the search engine will do the work for you with AI Overview. With AI Overview, AI can automatically visit a large number of websites to provide an answer to a complex question.
With the multi-step reasoning capabilities of custom Gemini, AI Overview will help solve increasingly complex problems. Instead of breaking down the question into multiple searches, you can now ask the most complex questions at once, with all the nuances and considerations you have in mind.
In addition to finding the right answer or information for complex questions, the search engine can also work with you to plan step by step.
At the I/O conference, Google emphasized the multimodal and long text capabilities of large models. Advances in technology have made productivity tools such as Google Workspace more intelligent.
For example, now we can ask Gemini to summarize all the recent emails from the school. It will identify related emails in the background and even analyze attachments such as PDFs. You can then get a summary of the key points and action items.

If you are traveling and can't attend a project meeting, and the recording of the meeting is up to an hour long. If it is a meeting on Google Meet, you can ask Gemini to walk you through the key points. There is a group looking for volunteers and you are free that day. Gemini can help you write an email to apply.
Going further, Google sees more opportunities in large model agents as intelligent systems with reasoning, planning and memory capabilities. Applications that use agents can "think" multiple steps in advance and work across software and systems to help you complete tasks more conveniently. This idea has been reflected in products such as search engines, and people can directly see the improvement in AI capabilities.
At least in terms of full-family applications, Google is ahead of OpenAI.
Google has an inherent advantage in ecology, but the foundation of large models is very important. Google has integrated the strength of its own team and DeepMind for this. Today, Hassabis also took the stage for the first time at the I/O conference and personally introduced the mysterious new model.

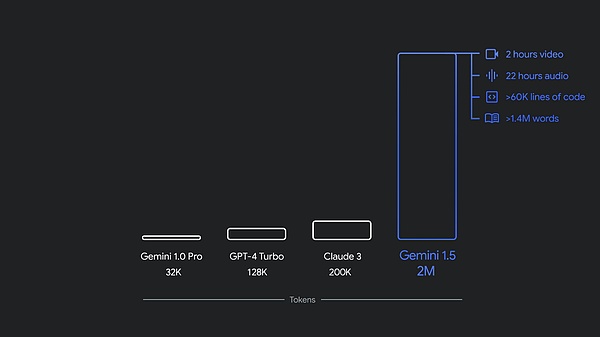
Last December, Google launched its first native multimodal model Gemini 1.0, which comes in three sizes: Ultra, Pro and Nano. Just a few months later, Google released a new version 1.5 Pro, which has enhanced performance and the context window has exceeded 1 million tokens.
Now, Google has announced a series of updates to the Gemini series of models, including the new Gemini 1.5 Flash, a lightweight model that Google pursues speed and efficiency, and Project Astra, Google's vision for the future of artificial intelligence assistants.
Currently, both 1.5 Pro and 1.5 Flash are available in public preview and offer 1 million token context windows in Google AI Studio and Vertex AI. Now, 1.5 Pro also offers 2 million token context windows to developers and Google Cloud customers using the API through a waitlist.
In addition, Gemini Nano has also expanded from plain text input to image input. Later this year, starting with Pixel, Google will launch the multimodal Gemini Nano. This means that mobile phone users will be able to process not only text input, but also understand more contextual information, such as vision, sound, and spoken language.
The new 1.5 Flash is optimized for speed and efficiency.
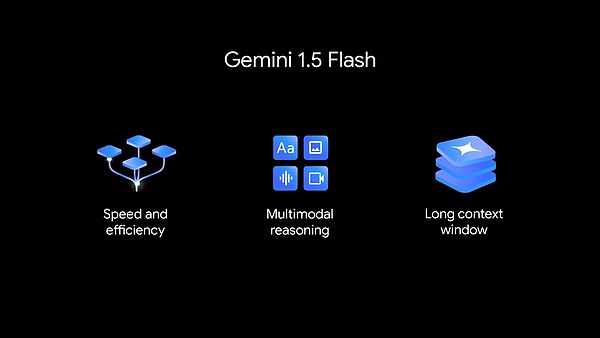
1.5 Flash is the latest member of the Gemini model family and the fastest Gemini model in the API. It is optimized for large-scale, high-volume, high-frequency tasks, is more cost-effective to serve, and has a breakthrough long context window (1 million tokens).

Gemini 1.5 Flash has strong multimodal reasoning capabilities and a breakthrough long context window.
1.5 Flash excels at summarization, chat applications, image and video subtitles, extracting data from long documents and tables, etc. This is because 1.5 Pro trained it through a process called "distillation", which transfers the most basic knowledge and skills from a larger model into a smaller, more efficient model.
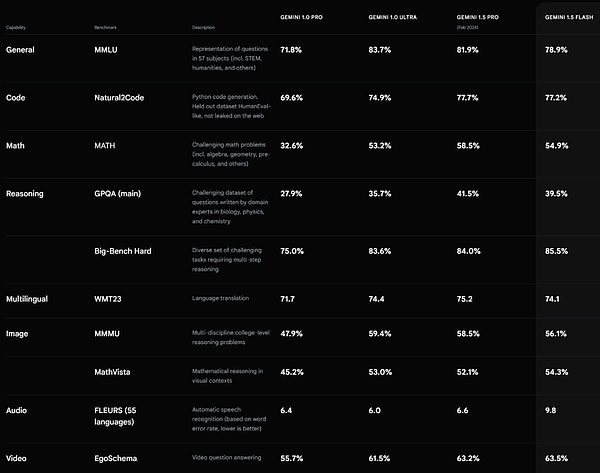
Gemini 1.5 Flash performance. Source https://deepmind.google/technologies/gemini/#introduction
Google mentioned that more than 1.5 million developers are using the Gemini model today, and more than 2 billion product users have used Gemini.

In the past few months, in addition to expanding the Gemini 1.5 Pro context window to 2 million tokens, Google has also enhanced its code generation, logical reasoning and planning, multi-turn dialogue, and audio and image understanding capabilities through improvements in data and algorithms.

1.5 Pro can now follow increasingly complex and nuanced instructions, including those that specify product-level behaviors involving roles, formats, and styles. In addition, Google has given users the ability to guide model behavior by setting system instructions.
Now that Google has added audio understanding to the Gemini API and Google AI Studio, 1.5 Pro can now perform reasoning on video images and audio uploaded in Google AI Studio. In addition, Google has integrated 1.5 Pro into Google products, including Gemini Advanced and Workspace applications.
Gemini 1.5 Pro is priced at $3.5 per 1 million tokens.
In fact, one of the most exciting transformations of Gemini is Google Search.
In the past year, Google Search has answered billions of queries as part of the search generation experience. Now people can use it to search in entirely new ways, asking new types of questions, longer, more complex queries, even searching using photos, and getting the best the web has to offer.

Google is about to launch Ask Photos. Take Google Photos, for example. The feature was launched about nine years ago. Today, users upload more than 6 billion photos and videos every day. People love to use photos to search their lives. Gemini makes it easier.
Say you're paying for parking and can't remember your license plate number. Before, you could search for keywords in photos and scroll through years of photos to find the license plate. Now, you can just ask the photo.

Or, let's say you're recalling your daughter Lucia's early life. Now, you can ask the photo: When did Lucia learn to swim? You can also follow up on something more complex: Tell me how Lucia's swimming is going.
Here, Gemini goes beyond simple search and identifies different backgrounds - including different scenes such as swimming pools and the sea, and photos bring everything together for users to view. Google will launch the Ask Photos feature this summer, and more features will be launched.


Today, Google also released a series of updates to the open source large model Gemma - Gemma 2 is here.
It is reported that Gemma 2 adopts a new architecture, designed to achieve breakthrough performance and efficiency, and the parameters of the new open source model are 27B.

In addition, the Gemma family is also expanding with the expansion of PaliGemma, Google's first visual language model inspired by PaLI-3.
Intelligent agents have always been a key research direction for Google DeepMind.
Yesterday, we watched OpenAI's GPT-4o and were shocked by its powerful real-time voice and video interaction capabilities.
Today, DeepMind's visual and voice interactive general AI agent project Project Astra was unveiled, which is a vision of Google DeepMind's future AI assistant.
Google said that in order to really work, intelligent agents need to understand and respond to the complex and dynamic real world like humans, and also need to absorb and remember what they see and hear to understand the context and take action. In addition, the agent needs to be proactive, educable, and personalized so that users can talk to it naturally without lag or delay.
Over the past few years, Google has been working to improve the perception, reasoning, and conversation methods of the model to make the speed and quality of interaction more natural.
In today's Keynote, Google DeepMind demonstrated the interactive capabilities of Project Astra:
It is reported that Google developed an agent prototype based on Gemini, which can process information faster by continuously encoding video frames, combining video and voice input into an event timeline, and caching this information for effective calls.
Through the voice model, Google also strengthened the pronunciation of the agent, providing the agent with a wider range of intonations. These agents can better understand the context in which they are used and respond quickly in conversations.
Here is a brief comment. Machine Heart feels that the Demo released by the Project Astra project is much worse than the real-time demonstration capabilities of GPT-4o in terms of interactive experience. Whether it is the length of the response, the emotional richness of the voice, interruptibility, etc., the interactive experience of GPT-4o seems to be more natural. I wonder how readers feel?
In terms of AI-generated videos, Google announced the launch of the video generation model Veo. Veo can generate high-quality 1080p resolution videos of various styles, with a duration of more than one minute.
With a deep understanding of natural language and visual semantics, the Veo model has made breakthroughs in understanding video content, rendering high-definition images, and simulating physical principles. The videos generated by Veo can accurately and meticulously express the user's creative intent.
For example, enter the text prompt:
Many spotted jellyfish pulsating under water. Their bodies are transparent and glowing in deep ocean.
(Many spotted jellyfish pulsating underwater. Their bodies are transparent and glowing in the deep ocean.)
For another example, to generate a character video, enter prompt:
A lone cowboy rides his horse across an open plain at beautiful sunset, soft light, warm colors.
(A lone cowboy rides his horse across an open plain at beautiful sunset, soft light, warm colors.)
For a close-up character video, enter prompt:
A woman sitting alone in a dimly lit cafe, a half-finished novel open in front of her. Film noir aesthetic, mysterious atmosphere. Black and white.
(A woman sitting alone in a dimly lit cafe, an unfinished novel open in front of her. Film noir aesthetic, mysterious atmosphere. Black and white.)
It is worth noting that the Veo model provides an unprecedented level of creative control and understands film terms such as "time-lapse" and "aerial photography", making the video coherent and realistic.
For example, for a movie-level coastline aerial shot, enter the prompt:
Drone shot along the Hawaii jungle coastline, sunny day
(Drone shot along the Hawaii jungle coastline, sunny day)
Veo also supports using images and text as prompts to generate videos. By providing reference images and text prompts, the video generated by Veo will follow the image style and user text instructions.
Interestingly, the demo released by Google is a "alpaca" video generated by Veo, which is easily reminiscent of Meta's open source series model Llama.

In terms of long videos, Veo can produce videos of 60 seconds or even longer. It can do this with a single prompt or by providing a series of prompts that together tell a story. This is critical for the application of video generation models in film and television production.
Veo is based on Google's work in visual content generation, including Generative Query Networks (GQN), DVD-GAN, Imagen-Video, Phenaki, WALT, VideoPoet, Lumiere, etc.
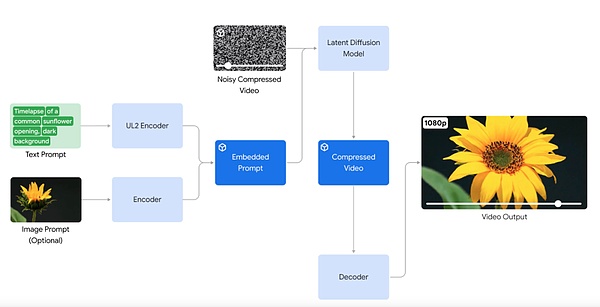
Starting today, Google will provide a preview version of Veo in VideoFX for some creators, who can join Google's waitlist. Google will also introduce some of Veo's features to products such as YouTube Shorts.
In terms of text-to-image generation, Google has once again upgraded its series of models - releasing Imagen 3.
Imagen 3 has been optimized and upgraded in terms of generating details, lighting, interference, etc., and its ability to understand prompts has been significantly enhanced.
To help Imagen 3 capture details from longer prompts, such as specific camera angles or compositions, Google has added richer details to the title of each image in the training data.
For example, by adding "slightly out of focus in the foreground", "warm light", etc. to the input prompt, Imagen 3 can generate images as required:

In addition, Google has made special improvements to the problem of "blurred text" in image generation, that is, it has optimized image rendering to make the text in the generated image clear and stylized.

To improve usability, Imagen 3 will provide multiple versions, each optimized for different types of tasks.
Starting today, Google is offering a preview of Imagen 3 in ImageFX to some creators, and users can sign up to join the waitlist.
Generative AI is changing the way humans interact with technology, while bringing huge efficiency opportunities to enterprises. But these advances require more computing, memory, and communication capabilities to train and fine-tune the most powerful models.
To this end, Google launched the sixth-generation TPU Trillium, which is the most powerful and energy-efficient TPU to date and will be officially available at the end of 2024.
TPU Trillium is a highly customized AI-specific hardware. Many of the innovations announced at this Google I/O conference, including new models such as Gemini 1.5 Flash, Imagen 3 and Gemma 2, are trained on TPUs and served using TPUs.

It is reported that compared with TPU v5e, Trillium TPU has a 4.7 times higher peak computing performance per chip, while it also doubles the bandwidth of high-bandwidth memory (HBM) and inter-chip interconnect (ICI). In addition, Trillium is equipped with the third-generation SparseCore, which is specifically designed to handle the very large embeddings common in advanced ranking and recommendation workloads.
Google said that Trillium can train a new generation of AI models at a faster speed while reducing latency and costs. In addition, Trillium is also known as Google's most sustainable TPU to date, with energy efficiency improved by more than 67% compared to its predecessor.
Trillium can be expanded to up to 256 TPUs (tensor processing units) in a single high-bandwidth, low-latency computing cluster (pod). In addition to this cluster-level scalability, through multislice technology and Titanium Intelligence Processing Units (IPUs), Trillium TPUs can scale to hundreds of clusters, connecting thousands of chips to form a supercomputer interconnected by a multi-petabit-per-second data center network.
Google launched the first TPU v1 back in 2013, followed by Cloud TPUs in 2017, which have been powering services as diverse as real-time voice search, photo object recognition, language translation, and even products like self-driving car company Nuro.
Trillium is also part of Google's AI Hypercomputer, a groundbreaking supercomputing architecture designed to handle cutting-edge AI workloads. Google is working with Hugging Face to optimize the hardware for open source model training and serving.

The above are all the highlights of today's Google I/O conference. It can be seen that Google has launched a comprehensive competition with OpenAI in terms of large model technology and products. And through the releases of OpenAI and Google in the past two days, we can also find that the competition for large models has entered a new stage: multimodal and more natural interactive experience has become the key to the productization of large model technology and its acceptance by more people.
I look forward to the innovation of large model technology and products in 2024, which will bring us more surprises.
This is the first time that Google has topped the Chatbot Arena ranking.
JinseFinanceOpenAI stated that the launch of GPT-4o mini marks significant progress in reducing costs and enhancing model capabilities, and is committed to making AI more popular and reliable.
 WenJun
WenJunOpenAI launched "GPT-4o mini" on 18 July, claiming it’s cheaper and more efficient than GPT-3.5 Turbo. Is OpenAI mimicking Apple's frequent releases, and will this impact the quality of their generative AI models?
 Kikyo
KikyoOpenAI ramps up efforts with a successor to GPT-4, focusing on safety. Amid ethical scrutiny and criticism, a safety and security committee is formed to address concerns and ensure responsible AI development.
 Huang Bo
Huang BoWith the recent release of OpenAI 4o, let’s talk about our views on AI+blockchain.
JinseFinanceRecent resignations at OpenAI, including Chief Scientist Ilya Sutskever and Jan Leike from the "superalignment team," follow disagreements over prioritising safety amid the launch of GPT-4o. Concerns linger over OpenAI's shift towards profit and potential security risks in collaborations like Apple's iOS 18 update integrating OpenAI technology.
 Weatherly
WeatherlyOnly 17 months after ChatGPT came out, OpenAI has come up with a super AI like that in science fiction movies, and it is completely free and available to everyone.
JinseFinanceOpenAI announced its latest artificial intelligence large language model on Monday, which it says will make ChatGPT smarter and easier to use.
JinseFinanceThe latest release transforms AI interactions by expanding the knowledge base to April 2023 and introducing support for 300-page documents.
 JixuJinseFinance
JixuJinseFinance