Meta releases Llama 3.1, Mark Zuckerberg calls for open source AI
CEO Mark Zuckerberg said Meta is "taking the next step in making open source AI the industry standard."
 JinseFinance
JinseFinance

Source: Heart of the Metaverse
Reuters reported on February 28 that Meta plans to release its latest version of the artificial intelligence large-scale language model Llama 3 in July. Models will provide better answers to controversial questions asked by users.
Meta researchers are trying to upgrade the model to provide relevant answers to controversial questions.
Meta suspended its image generation feature after rival Google launched Gemini because the historical images generated by the feature were sometimes inaccurate.

However, Llama 3 is able to answer questions such as "How to turn off a car engine", which means it understands that the user wants to ask how to turn off the vehicle rather than actually "killing" the engine.
Meta also plans to appoint an in-house person in the coming weeks to oversee tone and safety training in an effort to make the model's responses more nuanced, the report said.
In fact, as early as January this year, Meta CEO Zuckerberg announced in an ins video that Meta AI has recently begun training Llama 3. This is the latest generation of the LLaMa series of large language models. Previously, the Llama 1 model (originally styled as "LLaMA") was released in February 2023, and the Llama 2 model was released in July.
While specific details (such as model size or multi-modal capabilities) have not yet been announced, Zuckerberg said Meta intends to continue to open source the Llama base model.

Worth it Note that Llama 1 took three months to train and Llama 2 took about six months to train. If the next-generation models follow a similar timeline, they will be released around July this year.
But it is also possible that Meta will allocate additional time for fine-tuning to ensure the correct arrangement of the model.
As open source models become more powerful and generative AI models become more widely used, we need to be more cautious in order to reduce the risk of models being used for malicious purposes by bad actors. In the release video, Zuckerberg reiterated Meta's commitment to "responsible and safe training" of models.
Zuckerberg also reiterated Meta’s commitment to open licensing and democratizing AI at the subsequent press conference. “I tend to think that one of the biggest challenges here is that if you build something that’s really valuable, it ends up being very focused and narrow,” he told The Verge. “If you let By being more open, it can solve a lot of the problems that inequality of opportunity and value can bring. So this is an important part of the whole open source vision."
In the release video, Zuckerberg also emphasized Meta’s long-term goal of building AGI (artificial general intelligence). AGI is a theoretical development stage of artificial intelligence. At this stage, < strong>The model will demonstrate overall performance that is comparable to or better than human intelligence.
Zuckerberg also said: “It has become increasingly clear that the next generation of services needs to build comprehensive general intelligence. Build the best artificial intelligence assistant and artificial intelligence that serves creators. , artificial intelligence serving enterprises, etc., all require progress in all areas of artificial intelligence, including reasoning, planning, and coding to memory and other cognitive abilities."
From Zuckerberg From Ge's speech, we can see that the Llama 3 model does not necessarily mean that AGI will be realized, but Meta is consciously conducting LLM development and other AI research in a way that may realize AGI.
Another emerging trend in the field of artificial intelligence is multimodal artificial intelligence, that is, models that can understand and process different data formats (or modalities).
Open source models such as Google’s Gemini, OpenAI’s GPT-4V, and LLaVa, Adept or Qwen-VL can seamlessly switch between computer vision and natural language processing (NLP) tasks without developing Separate models to process text, code, audio, image and even video data.
Although Zuckerberg has confirmed that Llama 3, like Llama 2, will include code generation capabilities, he did not explicitly talk about other multi-modal features.
However, Zuckerberg did discuss how he envisions the intersection of artificial intelligence and the Metaverse in the Llama 3 launch video: "Meta's Ray-Ban smart glasses let artificial intelligence look at you. See what you hear, the ideal shape you hear, it can help at any time."

This seems to mean that Meta's plans for the Llama model, whether in the upcoming Llama 3 version or in subsequent versions, include integrating visual and Audio data is integrated with text and code data already processed by LLM.
This also seems to be a natural development in the pursuit of AGI.
Zuckerberg said in an interview with "The Verge": "You can argue whether general intelligence is similar to human-level intelligence, or similar to human-plus-human intelligence, or some kind of distant future of superintelligence. But to me, the important part is actually the breadth of it, that intelligence has all these different abilities and you have to be able to reason and have intuition."
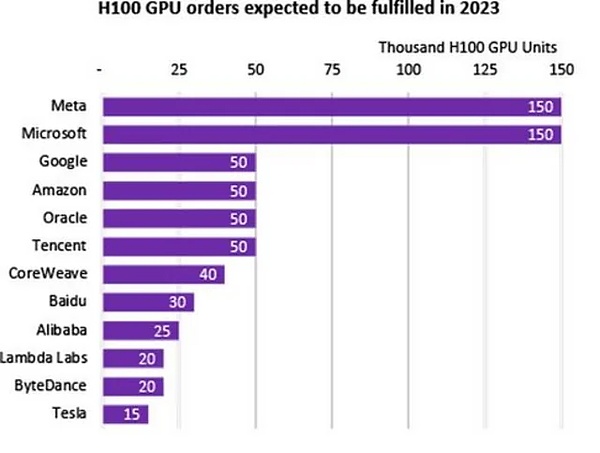
Zuckerberg also announced significant investments in training infrastructure. By the end of 2024, Meta plans to have approximately 350,000 NVIDIA H100 GPUs.
This will bring Meta’s total available computing resources to 600,000 H100 computing equivalents, including the GPUs they already own. Only Microsoft currently has a comparable computing power reserve.
Therefore , we have reason to believe that even if the Llama 3 model is not larger than the previous model, its performance will be significantly improved compared to the Llama 2 model.
Deepmind put forward the hypothesis that Llama's performance would be significantly improved in a paper published in March 2022, which was subsequently proved by Meta's model and other open source models (such as the French Mistral company's model) This, i.e., training a smaller model on more data yields higher performance than training a larger model on less data.
Although the scale of the Llama 3 model has not yet been announced, it is likely to continue the pattern of previous generations of models, that is, improving performance within a 7-7 billion parameter model. Meta’s recent investments in infrastructure will provide more powerful pre-training capabilities for models of any size.
Llama 2 also doubles the context length of Llama 1, which means that Llama 2 can "remember" twice the context during inference, and Llama 3 has the potential to make further progress in this regard. .
While the smaller LLaMA and Llama 2 models met or exceeded the performance of the larger, 175 billion-parameter GPT-3 model on some benchmarks, they were unable to compete with The GPT-3.5 and GPT-4 models available in ChatGPT are comparable.

With With the launch of a new generation of models, Meta seems intent on bringing state-of-the-art performance to the open source world.
Zuckerberg told "The Verge": "Llama 2 is not the industry's leading model, but it is the best open source model. With Llama 3 and beyond, our goal is to create a The most advanced level of products, and eventually become the industry's leading model."
With the new basic model, There are new opportunities to gain a competitive advantage through improved applications, chatbots, workflows, and automation.
Being at the forefront of emerging developments is the best way to avoid falling behind, and adopting new tools can differentiate your company's products and provide the best experience for customers and employees.
CEO Mark Zuckerberg said Meta is "taking the next step in making open source AI the industry standard."
JinseFinanceBuilding upon its predecessor, Llama, the new model offers enhanced capabilities and expanded possibilities for various applications.
 Coinlive
Coinlive Meta expects losses for Reality Labs to increase in 2023.
 cryptopotato
cryptopotatoWhile 2022 has been a tough year for the tech industry, Meta has had an especially rough run.
 decrypt
decryptStarting with Teams and Office, Microsoft said its Windows operating system would also be available through the headsets in the future.
 Beincrypto
BeincryptoMeta kicked off the rebrand in the United States in June, and is now making the change globally.
 Others
Others
V God said that Meta started too early in metaverse innovation because "it's too early to know what people want."
 Cointelegraph
CointelegraphINTERNET CITY, DUBAI, Jul. 29, 2022 – LBank Exchange, a global digital asset trading platform, has listed META PROTOCOL (MPC) ...
 Bitcoinist
BitcoinistThe remnants of Meta's once-ambitious cryptocurrency project are fading away. According to a notification on its website, a pilot program ...
Bitcoinist