【特集】仮想通貨の高騰──ブルランかブルトラップか?
暗号通貨の価格は最近上昇しましたが、暗号通貨の強気相場が戻ってくると楽観視する人もいれば、強気市場における強気の罠にすぎないと感じる人もいます。これについてあなたの見解は何ですか?
 Catherine
Catherine

ここ数年、人工知能(AI)とWeb3技術の急速な発展は、世界的に広く注目されている。人間の知能を模倣・模倣する技術であるAIは、顔認識、自然言語処理、機械学習などの分野で大きなブレークスルーをもたらしました。
AI産業の市場規模は2023年に2000億ドルに達し、OpenAI、Character.AI、Midjourneyなどの業界大手や傑出したプレーヤーがAIブームをリードするために誕生した。
一方、Web3は新たなネットワークモデルとして、インターネットとその利用方法に対する私たちの認識を徐々に変えつつある。Web3は分散型ブロックチェーン技術に基づき、スマートコントラクト、分散ストレージ、分散認証などの機能を通じて、データの共有と制御性を実現している、Web3のコアコンセプトは、中央集権的な権威からデータを解放し、ユーザーにデータをコントロールする権利とデータの価値を共有する権利を与えることだ。
現在、Web3業界の時価総額は25兆ドルに達しており、ビットコイン、イーサリアム、ソラナ、あるいはUniswap、Stepnなどのプレイヤーのアプリケーションレイヤーであろうと、Web3業界に参加するためにますます多くの人々を惹きつけ、新たな物語とシナリオが生まれている。業界である。
AIとWeb3の組み合わせは、東洋と西洋の建設業者とVCの両方にとって大きな関心のある分野であり、この2つをどのようにうまく統合するかは、探求する価値のある問題であることは容易に理解できる。
本稿では、AI+Web3の開発の現状に焦点を当て、この統合の潜在的な価値と影響を探る。まず、AIとWeb3の基本的な概念と特徴を紹介し、それらの相互関係を探る。その後、AI+Web3プロジェクトの現状を分析し、それらが直面する限界と課題について深く議論する。このような研究を通じて、投資家や関連業界の実務者に貴重な参考資料や洞察を提供することを期待しています。
AIとWeb3の発展は、まるで天秤の裏表のようであり、AIは生産性の向上をもたらし、Web3は生産性の向上をもたらす。AIは生産性の向上をもたらし、Web3は生産関係の変化をもたらした。では、AIとWeb3はどのような火花を散らすのだろうか?まずは、AIとWeb3の業界におけるジレンマと改善の余地を分析し、それぞれがこれらのジレンマの解決にどのように貢献できるかを探っていく。
AI業界のジレンマと潜在的な上昇余地
Web3業界のジレンマと潜在的な上昇余地
Web3業界のジレンマと潜在的な上昇余地
Web3業界のジレンマと潜在的な上昇余地
2.1AI産業が直面するジレンマ
AI産業が直面するジレンマを探るために、まず、以下のことを見てみましょう。AI産業の核心は、演算、アルゴリズム、データという3つの要素から切り離すことはできない。
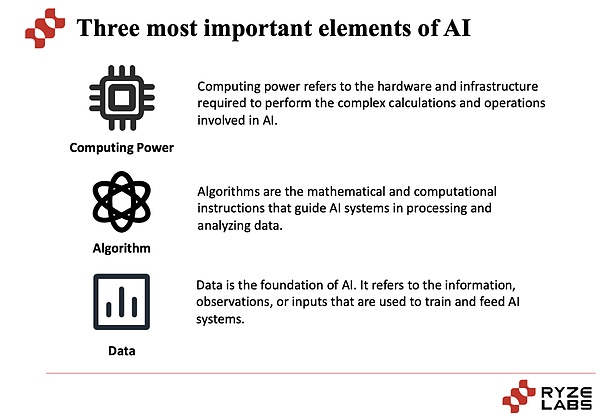
まず、演算能力:演算能力とは、大規模な計算と処理を実行する能力を指します。AIのタスクでは、大量のデータを処理し、ディープ・ニューラル・ネットワーク・モデルのトレーニングなど、複雑な計算を実行する必要があることがよくあります。AIタスクでは、大量のデータを処理し、ディープニューラルネットワークモデルのトレーニングなどの複雑な計算を実行する必要があります。高負荷の計算能力は、モデルのトレーニングと推論プロセスを加速し、AIシステムのパフォーマンスと効率を向上させることができます。近年、グラフィックプロセッサ(GPU)やAI専用チップ(TPUなど)といったハードウェア技術の発展に伴い、演算能力の向上はAI産業の発展を牽引する重要な役割を担っている。近年株価が乱高下しているNvidiaは、大きな市場シェアを獲得し、高い利益を得ているGPUのプロバイダーである。
アルゴリズムとは:アルゴリズムは、AIシステムの中核的な構成要素であり、問題を解決し、タスクを実現するために使用される数学的および統計的手法です。AIアルゴリズムは伝統的な機械学習アルゴリズムと深層学習アルゴリズムに分類され、深層学習アルゴリズムは近年大きなブレークスルーを遂げている。アルゴリズムの選択と設計は、AIシステムの性能と有効性にとって極めて重要である。アルゴリズムの継続的な改善と革新により、AIシステムの精度、ロバスト性、汎化能力を向上させることができる。アルゴリズムが異なれば結果も異なるため、アルゴリズム強化もタスク達成の有効性を高めるために重要です。
なぜデータが重要なのか:AIシステムの中核となるタスクは、学習とトレーニングを通じて、データのパターンと規則性を抽出することです。
データはモデルの学習と最適化の基礎であり、大規模なデータサンプルがあれば、AIシステムはより正確でインテリジェントなモデルを学習することができます。豊富なデータセットは、より包括的で多様な情報を提供し、モデルが未知のデータに対してよりよく一般化できるようにし、AIシステムが実世界の問題をよりよく理解し、解決できるようにします。
AIの現在の中核となる3つの分野を理解した後、AIがこれらの3つの分野で遭遇するジレンマと課題を見てみましょう。算数から始めると、AIタスクは通常、モデルの学習と推論、特にディープラーニングモデルに大量の計算リソースを必要とします。しかし、大規模な演算能力の獲得と管理は、高価で複雑な課題である。高性能演算装置のコスト、エネルギー消費、メンテナンスがすべて問題となる。特に新興企業や個人の開発者にとっては、十分な演算能力を得ることは困難です。
アルゴリズム面では、ディープラーニングアルゴリズムが多くの分野で大きな成功を収めている一方で、ジレンマや課題も残っています。例えば、ディープ・ニューラル・ネットワークの学習には大量のデータと計算リソースが必要であり、タスクによってはモデルの説明性や解釈性が不十分な場合がある。さらに、アルゴリズムのロバスト性と汎化能力は重要な問題であり、未見のデータに対するモデルの性能は不安定になる可能性がある。非常に多くのアルゴリズムが利用可能なため、最良のサービスを提供するための最良のアルゴリズムを見つけることは、継続的に探求する必要があるプロセスです。
データに関しては、データはAIの原動力ですが、高品質で多様なデータへのアクセスは依然として課題です。医療分野における機密性の高い健康データなど、データの入手が困難な分野もあるだろう。さらに、データの品質、正確性、ラベリングも問題であり、不完全なデータや偏ったデータは、モデルの誤った動作やバイアスにつながる可能性がある。また、データのプライバシーとセキュリティを保護することも重要な検討事項です。
さらに、解釈可能性と透明性の問題もあり、AIモデルのブラックボックス的な性質は社会的な関心事となっています。金融、医療、司法など特定の用途では、モデルの意思決定プロセスが説明可能で追跡可能である必要があるが、既存の深層学習モデルは透明性に欠けることが多い。モデルの意思決定プロセスを説明し、信頼できる説明を提供することは、依然として課題となっています。
その上、多くのAIプロジェクト新興企業のビジネスモデルはあまり明確ではない。
2.2ウェブ3業界が直面するジレンマ
また、ウェブ3業界に関して言えば、現時点で解決すべきジレンマはさまざまな側面があります。Web3のデータ分析、Web3製品の貧弱なユーザーエクスペリエンス、スマートコントラクトのコードの抜け穴やハッキングの問題など、改善の余地はたくさんある。生産性を向上させるツールとしてのAIは、これらの分野でも活躍する可能性を秘めている。
第一に、データ分析と予測能力の向上です。データ分析と予測におけるAI技術の応用は、Web3業界に大きなインパクトをもたらしました。AIアルゴリズムによるインテリジェントな分析とマイニングを通じて、Web3プラットフォームは膨大なデータから価値ある情報を抽出し、より正確な予測と意思決定を行うことができる。これは分散型金融(DeFi)空間におけるリスク評価、市場予測、資産管理にとって重要です。
さらに、ユーザーエクスペリエンスの向上とパーソナライズされたサービスも実現できます。AI技術の応用により、ウェブ3プラットフォームはより優れたユーザーエクスペリエンスとパーソナライズされたサービスを提供できるようになります。ユーザーデータを分析・モデリングすることで、Web3プラットフォームはユーザーにパーソナライズされたレコメンデーション、カスタマイズされたサービス、インテリジェントなインタラクティブ体験を提供することができる。例えば、多くのWeb3プロトコルはChatGPTのようなAIツールにアクセスし、ユーザーにより良いサービスを提供しています。
AIの応用は、セキュリティとプライバシー保護の面でもWeb3業界に大きな影響を与えます。 AI技術は、サイバー攻撃の検出と防御、異常な行動の特定、より強固なセキュリティの提供に利用できます。一方、AIはデータプライバシー保護にも応用でき、データの暗号化やプライバシー計算などの技術を通じて、Web3プラットフォーム上のユーザーの個人情報を保護することができる。スマートコントラクトの監査では、スマートコントラクトの記述と監査プロセスに脆弱性とセキュリティリスクが存在する可能性があるため、AI技術を利用してコントラクトの監査と脆弱性の検出を自動化し、コントラクトのセキュリティと信頼性を向上させることができる。
おわかりのように、AIはWeb3業界が直面しているジレンマや潜在的な強化に役立つさまざまな方法で関与することができます。
AIとWeb3プロジェクトの組み合わせは、主に2つの主要な側面から始まります。そして、AI技術をWeb3プロジェクトの強化に役立てることである。
この2つの側面をめぐって、Io.net、Gensyn、Ritualなどのプロジェクトを含む、多くのプロジェクトがこの道を探求するために出現しました。
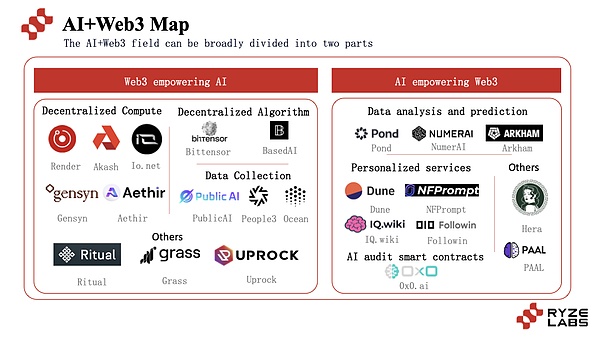
3.1ウェブ3で動くAI
3.1.1分散型算術
2022年末のOpenAIによるChatGPTの発表から、AIブームに火がつきました。AIブームの火付け役となったChatGPTは、Instagramが100万ダウンロードに到達するのに約2ヶ月半かかった後、ローンチから5日後に100万ユーザーに到達した。その後、Chatgptも急速にパワーアップし、2カ月で月間1億ユーザー、2023年11月には週間1億ユーザーに達した。Chatgptの登場とともに、AIスペースはニッチなトラックから注目度の高い産業へと急速に爆発した。
Trendforceのレポートによると、ChatGPTの実行には30,000個のNVIDIA A100 GPUが必要であり、将来のGPT-5では桁違いのコンピューティングが必要になるという。これにより、さまざまなAI企業間の軍拡競争が始まりました。AIの戦いで十分なパワーと優位性を確保する唯一の方法は、十分なコンピューティング・パワーを持つことであり、それゆえにGPUが不足しているのです。
AIの台頭以前、GPUの最大手プロバイダーであるNVIDIAの顧客は、AWS、Azure、GCPの3つの主要クラウド・サービスに集中していました。 AIの台頭により、メタ、オラクルなどの大手ハイテク企業、その他のデータ・プラットフォーム、AIスタートアップなど、新たな購入者が続々と現れました。MetaやTeslaのような大手ハイテク企業は、カスタムAIモデルや社内研究のためにGPUの購入を大量に増やしています。Anthropicのような基本モデリング企業やSnowflakeやDatabricksのようなデータプラットフォームも、顧客がAIサービスを提供できるようにGPUの購入を増やしています。サービスを提供できるようにするためです。
昨年Semi Analysisが「GPUリッチとGPUプア」と述べたように、20,000台以上のA100/H100 GPUを保有し、1つのプロジェクトに100~1,000台のGPUを使用できるチームメンバーがいる企業は一握りです。これらの企業は、OpenAI、Google、Meta、Anthropic、Inflection、Tesla、Oracle、Mistralなどを含む、クラウドプロバイダーまたは自作のLLMです。
しかし、これらの企業のほとんどはGPU貧乏の部類に入り、はるかに少ないGPUで苦労し、エコシステムを前進させるのが難しいことに多くの時間と労力を費やしています。そして、この状況は新興企業に限ったことではない。Hugging Face、Databricks (MosaicML)、Together、さらにはSnowflakeなど、最もよく知られたAI企業の中には、A100/H100が2万台未満しかないところもあります。これらの企業は世界クラスの技術的才能を持っていますが、利用可能なGPUの数によって制限されており、AI競争の大手企業に比べて不利な立場に置かれています。
この不足は「GPU貧困層」に限ったことではなく、2023年末にも、AIのリーダーであるOpenAIは、GPUの供給量を調達する間、十分なGPUを確保できなかったため、有料登録を数週間停止せざるを得ませんでした。GPUの供給。
AIの高速な発展とともに、GPUの供給不足が深刻化していることがわかります。GPUの需要サイドと供給サイドには深刻なミスマッチがあり、供給過剰の問題が差し迫っている。
この問題を解決するために、Akash、Render、Gensynなど、Web3の技術的特徴を組み合わせて分散型演算サービスを提供しようとするWeb3プロジェクトがいくつか始まっている。これらのプロジェクトに共通する特徴は、AI顧客に演算サポートを提供するために、トークンを通じてアイドルGPU演算を提供するよう大多数のユーザーにインセンティブを与えることで、演算の供給側になっていることです。
供給側の肖像画は、クラウドサービスプロバイダー、暗号通貨マイナー、企業の3つの主要分野に分けることができます。
クラウドサービスプロバイダーには、大規模クラウドプロバイダー(AWS、Azure、GCPなど)やGPUクラウドプロバイダー(Coreweave、Lambda、Crusoeなど)が含まれ、ユーザーはアイドルクラウドプロバイダーの演算能力を再販して収益を得ることができる。暗号マイナーは、イーサがPoWからPoSに移行するにつれて、アイドルGPU演算能力の重要な潜在的供給側にもなっている。さらに、TeslaやMetaのような大企業も、戦略的な配置によってGPUを大量に購入しているため、アイドルGPU演算を供給側として利用することができます。
このトラックにおける現在のプレイヤーは、AIの推論に分散型演算を使用するものと、AIのトレーニングに分散型演算を使用するものに大別される。前者はRender(レンダリングに特化しているが、AI演算のプロバイダーとしても使用可能)、Akash、Aethirなど、後者はio.net(推論とトレーニングに対応可能)、Gensynなどであり、両者の最大の違いは演算要件が異なることです。
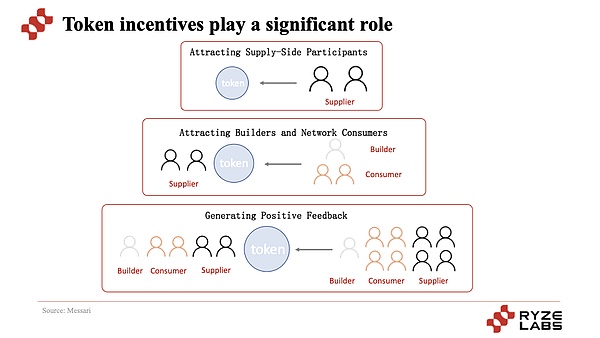
まず、前者のAI推論プロジェクトについて説明すると、この種のプロジェクトは、トークンのインセンティブによってユーザーが演算の提供に参加するように引きつけ、需要側に演算ネットワークサービスを提供し、遊休演算集約の需要と供給を実現する。この種のプロジェクトの紹介と分析は、弊社Ryze Labsの過去のDePIN調査レポート閲覧へようこそ。
最も中心的なポイントは、トークンのインセンティブメカニズムを通じて、プロジェクトはまず供給者を惹きつけ、次に利用者を惹きつけて利用させることで、プロジェクトのコールドスタートと中核機能のメカニズムを実現し、さらなる拡大と成長を可能にしていることである。このサイクルの下で、供給側は見返りとしてより価値の高いトークンを手にし、需要側はより安価で費用対効果の高いサービスを手にし、プロジェクトのトークン価値と供給側と需要側の参加者の成長はトークン価格と歩調を合わせ、トークン価格が上昇するにつれて、より多くの参加者と投機家が価値の獲得形成に参加するようになる。
もう1つのカテゴリーは、AIの訓練に分散型演算を使用することです。Gensynやio.netのようなトレーニング(AIのトレーニングとAIの推論の両方をサポートできる)。実際、この種のプロジェクトとAI推論プロジェクトの実行ロジックは、本質的にはあまり変わりません。それでも、トークンのインセンティブを通じて、供給側が算術の提供に参加し、需要側が使用するように誘致しています。
io.netは分散型演算ネットワークとして、50万以上のGPUを持ち、分散型演算プロジェクトで著名であり、さらにRenderとfilecoinの演算を統合し、エコロジープロジェクトの開発を開始している。

さらに、Gensynは機械学習のタスク割り当てを容易にするスマートコントラクトの世界的なリーディングプロバイダーです。AIトレーニングを可能にするために、機械学習のためのタスクの割り当てと報酬を容易にすることができるアプローチです。下図に示すように、Gensynの機械学習トレーニングのコストは1時間あたり約0.40ドルで、AWSやGCPの1時間あたり2ドル以上のコストよりもはるかに低い。
Gensynのシステムには、提出者、実施者、検証者、内部告発者の4つの参加主体があります。
提出者:需要ユーザーはタスクの消費者であり、計算されるタスクを提供し、AIトレーニングタスクの代金を支払います
実行者:タスクの消費者であり、計算されるタスクを提供し、AIトレーニングタスクの代金を支払います。align: left;">実行者:実行者はモデルによって訓練されたタスクを実行し、検証者の検査のためにタスクが完了したことの証明を生成する。
検証者:非決定論的な訓練プロセスを決定論的な線形計算に関連付け、実行者の証明を期待される閾値と比較する。
内部告発者:検証者の作業をチェックし、問題を見つけてそれに挑戦することで利益を得る。
おわかりのように、Gensynは世界中のディープラーニングモデルのためのハイパースケールでコスト効率の良い計算プロトコルになりたいと考えています。しかし、トラックを見てみると、なぜほとんどのプロジェクトが学習よりもAI推論に分散型演算を選ぶのでしょうか?
ここで、AIのトレーニングと推論の違いを理解していない人のために、ちょっとしたヘルプも紹介しましょう。strong>AIトレーニング:AIを学生に例えるなら、トレーニングとは、AIに大量の知識を提供することに似ています。学習の性質上、大量の情報を理解し、記憶する必要があるため、このプロセスには多くの計算能力と時間が必要です。
AIによる推論: では、推論とは何でしょうか?それは、学習した知識を使って問題を解いたり、試験を受けたりすることだと理解できます。推論の段階では、AIは新しい知識を活動させるのではなく、学習した知識を使って答えを出すので、推論プロセスに必要な計算量は少なくて済みます。
この2つの演算要件はかなり異なることがわかります。AIの推論とAIのトレーニングのための分散演算の可用性については、後の「挑戦」のセクションでさらに詳しく分析します。
さらに、分散型ネットワークとモデルの作成者を組み合わせることで、分散化と安全性を維持したいというRitualの願望がある。
Infernetのコーディネーターは、ネットワーク内のノードの行動を管理し、消費者の発信するコンピューティング要求に応答する責任を負う。コンピューティング・リクエストに対応する。ユーザーがinfernetを使用すると、推論、証明、その他の作業はチェーンの下に配置され、出力はコーディネータに返され、最終的に契約を通じてチェーン上の消費者に渡されます。
分散型演算ネットワークに加えて、データ伝送の速度と効率を向上させるためのGrassのような分散型帯域幅ネットワークもある。全体として、分散型演算ネットワークの出現は、AIの演算の供給側に新たな可能性を提供し、AIをより遠い方向へと押し進める。
3.1.2分散型アルゴリズムモデル
第2章で述べたように、AIの3つの中核要素は演算、アルゴリズム、データである。算術の力は分散化によって供給ネットワークを形成することができるので、アルゴリズムも同様の方法で考えることができ、アルゴリズムモデルの供給ネットワークを形成することができるのでしょうか?
トラックプロジェクトを分析する前に、まず分散化されたアルゴリズムモデルの意義を理解しましょう。すでにOpenAIがあるのに、なぜ分散化されたアルゴリズムネットワークが必要なのか、多くの人は疑問に思うでしょう。
要するに、分散型アルゴリズム・ネットワークとは、AIアルゴリズム・サービスのための分散型マーケットプレイスであり、それぞれが専門的な知識やスキルを持つ多数の異なるAIモデルをリンクさせることで、ユーザーが質問をすると、マーケットプレイスがその質問に答えるのに最適なAIモデルを選び、答えを提供する。そして、Chat-GPTは、人間のようなテキストを理解し、生成するためにOpenAIによって開発されたAIモデルである。
簡単に言えば、ChatGPTは様々なタイプの問題を解決するのを助ける能力の高い生徒のようなもので、分散型アルゴリズムネットワークは、問題を解決するのを助ける生徒がたくさんいる学校のようなものです。その生徒は、今は能力が高いですが、長い期間をかけて、世界中から生徒を募って参加させることができる学校です。可能性の余地は大きい。
現在、分散型アルゴリズムモデルを試み、探求しているプロジェクトが数多くあります。分散型アルゴリズムモデルの分野では、多くのプロジェクトが試みられ、探求されています。代表的なプロジェクトであるBittensorをケーススタディとして使用し、このニッチな分野の発展を理解していただきます。
Bittensorでは、アルゴリズムモデルの供給側(マイナー)は、機械学習モデルをネットワークに提供します。これらのモデルはデータを分析し、洞察を提供することができる。モデルの供給者は、その貢献に対して暗号通貨トークンTAOで報酬を得る。
質問に対する答えの質を保証するために、Bittensorはネットワークが最良の答えに同意することを保証する独自のコンセンサスメカニズムを使用しています。質問がされると、複数のモデル採掘者が答えを提供する。その後、ネットワーク内の検証者がベストアンサーを決定し、ユーザーに送り返す。
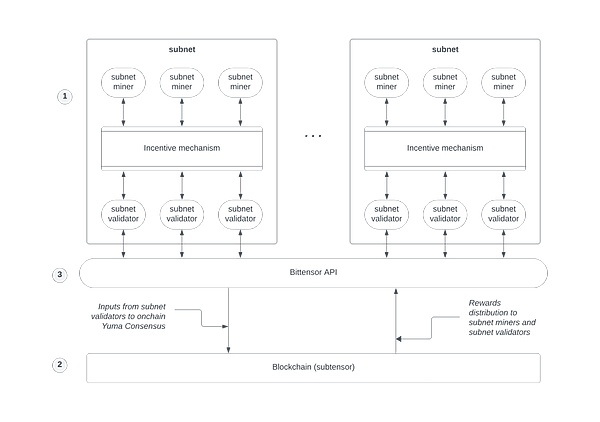
BittensorのトークンであるTAOは、その役割を担っています。これは、マイナーがアルゴリズムモデルをネットワークに貢献するインセンティブとして、また、ユーザーがトークンを使って質問し、ネットワークがタスクを完了できるようにするインセンティブとして使用される。
Bittensorは分散型であるため、インターネットにアクセスできる人なら誰でも、質問をするユーザーとして、あるいは回答を提供するマイナーとして、ネットワークに参加することができる。これにより、より多くの人が強力なAIにアクセスできるようになる。
要するに、Bittensorのようなネットワークに代表されるように、アルゴリズムモデルの分散型分野は、AIモデルがエコシステムの中で安全かつ分散化された方法で訓練、共有、利用できるような、よりオープンで透明性の高い状況を作り出す可能性を秘めている。もちろん、より興味深いのは、ZKを通じてモデルと相互作用するユーザーのデータ・プライバシーの保護にあります。
分散型アルゴリズムモデリングプラットフォームが進化するにつれ、一流のAIツールの使用において、小規模な企業が大規模な組織と競争することが可能になり、業界全体に大きな影響を与える可能性があります。
3.1.3分散型データ収集
AIモデルのトレーニングには、大量のデータの供給が不可欠です。しかし現在、ほとんどのウェブ2企業は、X、Reddit、TikTok、Snapchat、Instagram、YouTubeなどのプラットフォームがAIトレーニングのためのデータ収集を禁止しているように、ユーザーのデータを自分たちのために取っているのが現状です。これはAI産業の成長にとって大きな障害となった。
しかし一方で、一部のWeb2プラットフォームは、ユーザーに利益を分配することなく、ユーザーのデータをAI企業に売却している。例えば、レディットはグーグルと6,000万ドルの契約を結び、グーグルに自分たちの投稿でAIモデルを学習させた。これにより、データの収集は大資本とビッグデータ関係者に乗っ取られ、超資本集約型の産業へと発展した。
このような現状を前に、Web3を組み合わせ、トークンのインセンティブによって分散型のデータ収集を実現したプロジェクトもある。
1つのタイプはAIデータの提供者であり、ユーザーはXに関する価値あるコンテンツを見つけることができます。PublicAI公式が洞察し、#AIまたは#Web3を分類タグとして使用することで、コンテンツはデータ収集のためにPublicAIデータセンターに送られます。
もう1つのカテゴリーは「データ検証者」で、ユーザーはPublicAIデータセンターにログインし、AIトレーニング用に選ばれた最も価値のあるデータに投票することができる。
その見返りとして、ユーザーは両方のタイプの貢献に対してトークンでインセンティブを得ることができ、データの貢献者とAI産業の発展との間に手と手を取り合うWin-Winの関係が育まれます。
AIトレーニングのために特別にデータを収集するPublicAIのようなプロジェクトに加え、トークン化を通じてAIのためにユーザーデータを収集するOceanや、AIのためにユーザーの車載カメラを通じてユーザーデータを収集するHivemapperなど、トークンのインセンティブを通じてデータ収集を分散化しているプロジェクトは他にも数多くある。Hivemapperはユーザーの車載カメラを通じて地図データを収集し、Dimoはユーザーの車載データを収集し、WiHiは天気データを収集するなど、分散化を通じてデータを収集するこの種のプロジェクトは、AIトレーニングの供給側にもなりうるため、広義にはWeb3を活用したAIパラダイムにも含まれる。
3.1.4ZKはAIにおけるユーザーのプライバシーを保護する
分散化の利点に加えて、ブロックチェーン技術がもたらす重要なものの1つが、ゼロ知識証明です。証明です。ゼロ知識技術により、情報の検証を可能にしながらプライバシーを保護することができます。
従来の機械学習では、データは通常、一元的に保存・処理される必要があり、データのプライバシー漏えいのリスクにつながる可能性がある。一方、データの暗号化やデータの非識別化など、データのプライバシーを保護する方法は、機械学習モデルの精度や性能を制限する可能性があります。
また、ゼロ知識証明技術は、プライバシー保護とデータ共有の間の対立を解決することで、このジレンマに直面するのに役立ちます。
ZKML(ゼロ知識機械学習)は、ゼロ知識証明技術を使用することで、元のデータを明らかにすることなく、機械学習モデルの訓練と推論を可能にします。ゼロ知識証明では、実際のデータ内容を明らかにすることなく、データの特徴とモデルの結果が正しいことを証明することができます。
ZKMLの中心的な目標は、プライバシー保護とデータ共有のバランスを達成することです。医療データ分析、金融データ分析、組織横断的なコラボレーションなど、さまざまなシナリオで使用することができます。ZKMLを使用することで、個人は自分の機密データのプライバシーを保護しながら、他の人と共有することで、データプライバシー侵害のリスクなしに、より広範な洞察やコラボレーションの機会を得ることができます。
この分野はまだ初期段階にあり、ほとんどのプロジェクトはまだ調査中です。例えばBasedAIは、データの機密性を維持するためにFHEとLLMをシームレスに統合する分散型アプローチを提案しています。Zero Knowledge Large Language Model (ZK-LLM)を活用し、分散型ネットワーク・インフラストラクチャのコアにプライバシーを組み込むことで、ネットワークの運用中もユーザーデータのプライバシーが保たれるようにしています。
ここで、完全同相暗号化(FHE)とは何かについて簡単に説明します。Full Homomorphic Encryption(完全同相暗号化)とは、暗号化された状態で、復号化の必要なくデータを計算できるようにする暗号化技術です。つまり、FHEで暗号化されたデータに対して行われるさまざまな数学的演算(加算、乗算など)は、データを暗号化したまま行うことができ、暗号化されていない元のデータに対して行われたのと同じ結果を得ることができるため、ユーザーのデータのプライバシーを保護することができます。
また、Web3に対応したAIという点では、上記4つのカテゴリーに加え、チェーン上でのAIプログラムの実行をサポートするCortexのようなブロックチェーンプロジェクトも存在する。現在、従来のブロックチェーン上での機械学習プログラムの実行には課題があり、仮想マシンは複雑でない機械学習モデルを実行する上で極めて効率が悪い。その結果、ブロックチェーン上でAIを実行することは不可能だと考える人がほとんどだ。一方、Cortex Virtual Machine(CVM)は、チェーン上でAIプログラムを実行するためにGPUを利用し、EVMと互換性がある。言い換えれば、CortexチェーンはすべてのEther Dappsを実行することができ、その上、それらのDappsにAIの機械学習を組み込むことができます。したがって、ネットワークコンセンサスがAIの推論のすべてのステップを検証するため、機械学習モデルを分散型で不変かつ透明な方法で実行することができます。
3.2ウェブ3を煽るAI
AIとウェブ3の衝突では、ウェブ3がAIを煽ることに加えて、AIのウェブ3産業への後押しも非常に注目されます。AIとWeb3の衝突では、Web3がAIを煽ることに加えて、AIのWeb3産業への押し上げも非常に注目に値する。AIの核心的な貢献は生産性の向上であるため、AIによるスマートコントラクトの監査、データ分析と予測、パーソナライズされたサービス、セキュリティとプライバシー保護など、多くの試みが行われている。
3.2.1データ分析と予測
現在、多くのWeb3プロジェクトが、既存のAIサービス(例:ChatGPT)を統合したり、自己開発したりして、データ分析と予測を提供し始めています。Web3ユーザーは、データ分析や予測タイプのサービスを提供するために、既存のAIサービス(例:ChatGPT)を統合したり、独自に開発したりしている。AIアルゴリズムによる投資戦略の提供、オンチェーン分析のためのAIツール、価格や市場の予測など、その対象は非常に幅広い。
例えば、PondはAIグラフアルゴリズムを通じて将来の価値あるアルファトークンを予測し、ユーザーや機関に投資支援の推奨を提供します。
また、Numeraiのような投資コンテストもあり、参加者はAIやビッグ・ランゲージ・モデルなどに基づいて株式市場を予測し、プラットフォームが提供する無料の高品質データでモデルを訓練し、毎日予測を提出する。Numeraiはその予測の向こう1ヶ月のパフォーマンスを計算し、参加者はそのモデルにNMRを賭けることができる。Numeraiは翌月の予測パフォーマンスを計算し、参加者はそのモデルにNMRを賭けることができ、モデルのパフォーマンスに応じて収入を得ることができる。
また、AIをサービスと組み合わせたアーカムのようなオンチェーンデータ分析プラットフォームもある。アーカムは、ブロックチェーンのアドレスを取引所、ファンド、メガホールなどのエンティティに接続し、これらのエンティティからの重要なデータと分析をユーザーに提示し、意思決定において優位に立てるようにする。AIとの統合の一部は、アーカム・ウルトラの現実世界のエンティティへのアドレスのアルゴリズムマッチングにあり、パランティアとOpenAIの創設者の支援を受けて、アーカムの中心的な貢献者によって3年以上かけて開発された。
3.2.2パーソナライゼーション
Web2のプロジェクトでは、ユーザーのパーソナライズされたニーズに応えるため、検索と推薦の両方の領域でAIを使用できるシナリオが数多くあります。.Web3のプロジェクトでも、多くのプロジェクト関係者がAIを統合することでユーザー体験を最適化しています。
たとえば、データ分析プラットフォームでおなじみのDuneは、大規模な言語モデルの助けを借りてSQLクエリを記述するためのツール「Wand」を最近発表した。Wand Create機能により、ユーザーは自然言語の質問に基づいてSQLクエリを自動生成することができ、SQLを知らないユーザーでも非常に簡単に検索することができる。
さらに、コンテンツの要約のためにChatGPTを統合し始めているWeb3コンテンツプラットフォームが多数あります。例えば、ChatGPTを統合して特定のトラックに関する見解や最新情報を要約するWeb3メディアプラットフォームであるFollowinや、ブロックチェーン技術と最新ニュースのためのウェブ上で最高の場所であるように努めるWeb3百科事典プラットフォームであるIQ.wikiなどです。IQ.wikiは、ブロックチェーン技術と暗号通貨に関連するあらゆることに関する客観的で質の高い知識をウェブ上で提供する主要な情報源となり、ブロックチェーンをより発見しやすく、世界的にアクセスしやすくし、ユーザーが信頼できる情報を提供します。情報アクセスを変えるWeb3検索プラットフォームとなることを約束する。
オーサリング側では、AIによってNFTを生成しやすくするNFPromptのように、ユーザーのオーサリングコストを削減し、オーサリング側で多くのパーソナライズされたサービスを提供するプロジェクトもあります。
3.2.3スマートコントラクトのAI監査
スマートコントラクトの監査もまた、Web3ドメインにおいて非常に重要なタスクであり、AIを使用してスマートコントラクトの監査を実現することで、スマートコントラクトの監査が可能になります。AIによるスマートコントラクトコードの監査は、より効率的かつ正確にコードの脆弱性を特定し、発見することができます。
ヴィタリックが言及しているように、暗号通貨分野が直面している最大の課題の1つは、コードのバグです。そして、1つの有望な可能性は、人工知能(AI)が、特定のプロパティを満たすコードの集合を証明するための形式的検証ツールの使用を大幅に簡素化できることだ。これが実現すれば、エラーのないSEK EVM(イーサネットVMなど)を実現できる可能性がある。エラーの数を減らせば減らすほど、その空間のセキュリティは向上し、AIはこれを達成するのに非常に役立ちます。
例えば、0x0.aiプロジェクトは、高度なアルゴリズムを使ってスマートコントラクトを分析し、詐欺やその他のセキュリティリスクにつながる可能性のある潜在的な脆弱性や問題を特定するツール「Artificial Intelligence Smart Contract Auditor」を提供している。監査人は、機械学習技術を使用してコード内のパターンや異常を特定し、さらなるレビューのために潜在的な問題にフラグを立てます。
上記の3つのカテゴリーに加えて、Web3スペースを強化するためにAIを使用するネイティブな例がいくつかあります。AIを搭載したマルチチェーンDEXアグリゲーターであるHeraは、AIを使用して、最も幅広いトークンと任意のトークンペア間の最良の取引経路を提供します。 全体的に、AIはツールレベルとしてよりWeb3に力を与えます。
4.1 分散型算術に対する現実世界の障害
4.1 分散型算術に対する現実世界の障害
現在のWeb3対応AIプロジェクトの大部分は、分散型算術に焦点を当てており、トークンのインセンティブを通じて、グローバルユーザーが算術の供給側になることを促進することは、非常に興味深いイノベーションです。
中央集権型の算術サービスプロバイダーとは対照的に、分散型の算術サービスは通常、コンピューティングリソースを提供するために、グローバルに分散したノードと参加者に依存しています。これらのノード間のネットワーク接続は遅延や不安定性の影響を受ける可能性があるため、パフォーマンスと安定性は集中型演算製品よりも劣る可能性があります。
さらに、分散型演算製品の可用性は、需要と供給のマッチング具合に影響される。サプライヤーが十分でなかったり、需要が高すぎたりすると、リソースが不足したり、ユーザーの需要に応えられなかったりする可能性がある。
最後に、分散型演算製品は一般的に、集中型演算製品よりも技術的な詳細さや複雑さを伴う。ユーザーは、分散型ネットワーク、スマートコントラクト、暗号通貨決済を理解し、扱う必要がある場合があり、ユーザーが理解し、使用するためには、より高価になる可能性があります。
多くの分散型算術プロジェクト関係者と綿密に議論した結果、現在の分散型算術は基本的にまだ、AIの訓練というよりはAIの推論に限られていることが明らかになった。
1.なぜほとんどの分散型算術プロジェクトは、AIトレーニングではなくAI推論を選択するのですか?
2、NVIDIAが実際に牛耳る?分散型算術トレーニングが難しいのはなぜか?
3、分散型算術(Render、Akash、io.netなど)の終着点は?
4.分散型アルゴリズム(Bittensor)の終着点は?
次に、繭を1層ずつ引っ張ってみましょう。
1)このトラックを通して、分散型演算プロジェクトのほとんどは、トレーニングよりもAI推論を行うことを選択しています。算術と帯域幅に対する異なる要件にあります。
理解を深めるために、AIを学生に例えてみましょう。
AIのトレーニング:AIを学生に例えるなら、トレーニングはAIに多くの知識を与えることに似ています、例は、私たちがよくデータとして参照するものとしても理解でき、AIはこれらの知識の例から学習します。学習の性質上、大量の情報を理解し記憶する必要があるため、このプロセスには多くの計算能力と時間が必要となる。
AIの推論:では、推論とは何でしょうか?推論の段階では、AIは新しい知識を活動させるのではなく、問題に答えるために学習した知識を使っているので、推論プロセスで必要な計算量は少なくなります。
この2つの難易度の差は、本質的にAIのトレーニングが膨大な量のデータを必要とし、また必要なデータの高速通信には極めて高い帯域幅が必要であるため、現在のトレーニングに使用されている分散型演算の実現が極めて困難であることにあることは容易に理解できる。推論は、必要なデータと帯域幅の点ではるかに小さく、実現できる可能性が高い。
大規模なモデルの場合、最も重要なのは安定性であり、学習が中断されると再学習が必要になり、サンクコストが非常に高くなります。一方、比較的低い演算要件は、上記のAIの推論、またはペンダント中小モデルの訓練のいくつかの特定のシナリオが可能であるように、達成することができ、分散演算ネットワークでは、これらの比較的大規模な演算のニーズに応えることができる比較的大規模なノードサービスプロバイダの数があります。
2)それでは、データと帯域幅のチョークポイントはどこなのでしょうか?なぜ分散型トレーニングの実現が難しいのでしょうか?
ここで、ビッグモデルのトレーニングの2つの重要な要素、シングルカード演算とマルチカード並行処理について説明します。
シングルカード演算:ビッグモデルをトレーニングする必要がある現在のすべてのセンターで、私たちはスーパーコンピューティングセンターと呼んでいます。理解を容易にするため、人体に例えて説明すると、スーパーコンピューティング・センターは人体の組織であり、GPUの基礎となる単位は細胞である。1つの細胞(GPU)の演算が強ければ、全体の演算(個々の細胞×数)も強いかもしれません。
マルチカード並列:そして、トレーニングの大規模なモデルは、多くの場合、スーパーコンピューティングセンターの大規模なモデルのトレーニングのために、1000億GBであり、A100の少なくとも10,000レベルが底を打つ。だから、訓練のためにカードのこれらの数万人を動員する必要がある、しかし、大規模なモデルの訓練は、2番目のカードで訓練した後、最初のA100カードではなく、単純なシリーズではありませんが、モデルのさまざまな部分は、別のカードで訓練し、訓練は、Bの結果を訓練する必要がある場合がありますので、マルチカードの並列処理が含まれます。
なぜNVIDIAは非常に強力であり、市場価値はすべての方法、およびAMDと国内Huaweiは、Horizonは現在追いつくことは困難である。そのコアはシングルカード演算そのものではなく、CUDAソフトウェア環境とNVLinkマルチカード通信という2つの側面にあります。
一方では、NVIDIAのCUDAシステムのように、ハードウェアが非常に重要であり、新しいシステムを構築することは非常に困難であり、新しい言語を構築するように、交換コストは非常に高いに適応することができるソフトウェアエコシステムがありません。
一方、マルチカード通信があり、これは基本的に複数のカード間の情報の入力と出力であり、どのように並列に、どのように送信します。NVLinkの存在のため、NVIDIAとAMDのカードを接続する方法はありません。さらに、NVLinkは、グラフィックスカード間の物理的な距離を制限し、カードが世界中に分散された場合、分散コンピューティングパワーを達成することがより困難である分散コンピューティングパワーにつながる、同じスーパーコンピューティングセンターにする必要があります。
1つ目のポイントは、AMDや国内のHuawei、Horizonが現在追いつくのに苦労している理由を説明するもので、2つ目のポイントは、分散型トレーニングの実現が難しい理由を説明するものです。
3)分散型演算の終着点は?
分散演算は現在、大規模モデルのトレーニングでは困難です。その核心は、大規模モデルのトレーニングで最も重要なのは安定性であり、トレーニングが中断されると再トレーニングが必要で、サンクコストが非常に高いという事実にあります。複数のカードを並列に使用するための要件は高く、帯域幅は物理的な距離によって制限される。NVIDIAはマルチカード通信を実現するためにNVLinkを使用していますが、スーパーコンピューティングセンター内では、NVLinkはグラフィックカード間の物理的な距離を制限するため、分散したコンピューティングパワーは、大規模なモデルトレーニングを実施するためのコンピューティングパワークラスターを形成することはできません。
しかし、その一方で、比較的低い電力要件は、AIの推論、または中小規模のモデルトレーニングのペンダントクラスのいくつかの特定のシナリオが可能であるような、達成することができる分散コンピューティングネットワークでは、比較的大規模なノードプロバイダの数がある、これらの比較的大規模なコンピューティングパワーのニーズを提供する可能性があります。このような比較的大規模な演算サービスに対する需要がある。レンダリングのようなエッジコンピューティングのシナリオも、比較的簡単に実装できます。
4)分散型アルゴリズムモデルの最終目標は?
分散型アルゴリズムモデルの終着点は、AIの未来の終着点次第です。AIの未来の戦いは、おそらく、クローズドソースの巨大モデル(ChatGPTなど)が1~2個、それに加えて100個のモデルが存在するようなものになると思います。この文脈では、Bittensorのこのモデルの可能性はまだ非常に高いです。
4.2AI+Web3の組み合わせは比較的大雑把で、1+1>2を実現していない
現在、Web3とAIを組み合わせたプロジェクト、特にAIを搭載したWeb3プロジェクトのほとんどは、まだ非常に大雑把です。Web3プロジェクトのほとんどは、AIと暗号通貨の間の深い統合を本当に反映することなく、まだ表面的にしかAIを使用していません。
第一に、データ分析や予測にAIを使おうが、推薦や検索シナリオにAIを使おうが、コード監査を実行しようが、AIと暗号通貨はあまり変わりません。Web2プロジェクトとAIの組み合わせに大きな違いはない。これらのプロジェクトは、単に効率を改善し、分析を実行するためにAIを使用しているだけで、AIと暗号通貨の間のネイティブな統合と革新的なソリューションを示していません。
第二に、多くのWeb3チームは、より純粋にAIのコンセプトを利用したマーケティングレベルでAIと組み合わせています。彼らは非常に限定された分野でしかAI技術を利用せず、その後AIのトレンドを宣伝し始め、プロジェクトがAIと非常に密接に連携しているかのような錯覚を起こします。しかし、本当のイノベーションとなると、これらのプロジェクトにはまだ大きなギャップがある。
現在のWeb3とAIプロジェクトのこのような限界にもかかわらず、私たちは、これが開発の初期段階にすぎないことを認識すべきです。将来的には、AIと暗号通貨のより緊密な統合を可能にし、金融、分散型自律組織、予測市場、NFTなどの分野でよりネイティブで有意義なソリューションを生み出す、より詳細な研究とイノベーションが期待されます。
4.3AIプロジェクトの物語の緩衝材としてのトークン経済
AIプロジェクトのビジネスモデルのジレンマの冒頭で述べたように、現在、より多くのマルチモデルがオープンソース化され、多くのAIプロジェクトが開発されています。
徐々にオープンソース化され始めた現在の多数のAI + Web3プロジェクトは、Web2での開発や資金調達が難しい純粋なAIプロジェクトであることが非常に多く、ユーザーの参加を促進するためにWeb3の物語とトークンエコノミクスを重ねることを選択しています。
しかし、本当に重要なのは、トークンエコノミクスを取り入れることが本当にAIプロジェクトが本当のニーズに対応するのに役立つのか、それとも単に物語なのか、短期的な価値を求めているのか、ということです。
現在、AI+Web3プロジェクトのほとんどは、まだ実用段階にはほど遠い。トークンをAIプロジェクトの勢いとして利用するだけでなく、実際に実際の需要シナリオに対応できるような、地に足の着いた思慮深いチームが増えることを願っている。
現在、AI+Web3プロジェクトには多くの事例や応用例がある。まず、AI技術はWeb3により効率的でインテリジェントなアプリケーションシナリオを提供することができます。また、AIはスマートコントラクトのコードを監査し、スマートコントラクトの実行プロセスを最適化し、ブロックチェーンのパフォーマンスと効率を向上させることができる。同時に、AI技術は分散型アプリケーションに対して、より正確でインテリジェントな推奨やパーソナライズされたサービスを提供し、ユーザー体験を向上させることもできる。
一方、Web3の分散型でプログラム可能な機能は、AI技術の開発にも新たな機会を提供する。トークンのインセンティブを通じて、分散型演算プロジェクトはAI演算の供給過剰というジレンマに新たな解決策を提供し、Web3のスマートコントラクトと分散ストレージメカニズムは、AIアルゴリズムの共有とトレーニングのためのより広い空間とリソースを提供します。Web3のユーザー自律性と信頼メカニズムもAI開発に新たな可能性をもたらし、ユーザーはデータの共有とトレーニングへの参加を独自に選択できるため、データの多様性と質が向上します。Web3のユーザー自律性と信頼メカニズムはまた、AI開発に新たな可能性をもたらし、ユーザーが自律的にデータ共有とトレーニングへの参加を選択できるため、データの多様性と質が向上し、AIモデルの性能と精度がさらに向上する。
現在のAI+Web3クロスオーバー・プロジェクトはまだ初期段階にあり、直面するジレンマも多いが、多くの利点ももたらしている。例えば、分散型の算数製品にはいくつかの欠点があるが、中央集権的な機関への依存を減らし、より高い透明性と監査可能性を提供し、より幅広い参加とイノベーションを可能にする。データ収集の場合も同様で、分散型データ収集プロジェクトは、単一のデータ源への依存を減らし、より広いデータ範囲を提供し、データの多様性と包摂を促進するなどの利点をもたらす。実際には、分散型データ収集プロジェクトがAIの発展にプラスの影響を与えるよう、これらの利点と欠点を比較検討し、課題を克服するための適切な規制および技術的措置を講じる必要がある。
全体として、AI+Web3の融合は、将来の技術革新と経済発展に無限の可能性をもたらします。AIのインテリジェントな分析と意思決定能力を、Web3の分散化とユーザーの自律性と組み合わせることで、よりスマートで、よりオープンで公平な経済システム、さらには社会システムを将来構築できると考えられています。
暗号通貨の価格は最近上昇しましたが、暗号通貨の強気相場が戻ってくると楽観視する人もいれば、強気市場における強気の罠にすぎないと感じる人もいます。これについてあなたの見解は何ですか?
Catherineプロジェクト開発者は、トークンをすぐに買い戻すと述べました。
 Others
OthersSOL 価格は 2021 年 3 月以来の最低点に急落しました。
 Beincrypto
BeincryptoAPT は、下降するパラレル チャネル内で取引されています。
BeincryptoVoyager のクライアントは、資金の 72% を取り戻すことができました。
Beincrypto彼はチャートシステムを大いに信じており、2022 年 9 月初旬に ADA の弱気の軌道を予測し始めました。
Beincrypto暗号通貨スペースの「イーサリアムキラー」がシステムの欠陥機構によりオフラインになったため、ソラナネットワークは再び不安定になった。
 Bitcoinist
Bitcoinist NulltxNulltxNulltx
NulltxNulltxNulltx