IOSG|クライオト・ゲーム沈没市場への深入り - 浪人論文
ユーザー数がそれほど増えないこの時期に、非常に高いユーザー数と成長を維持しているエコシステムがすでに存在する。
 JinseFinance
JinseFinance

一見すると、AIとWeb3はそれぞれ根本的に異なる原理に基づき、異なる機能を果たす別々の技術に見える。Balaji Srinivasan氏は、SuperAIでこの補完的な能力という概念を雄弁に語り、これらの技術が互いにどのように作用し合うことができるかについての詳細な比較を促しました。
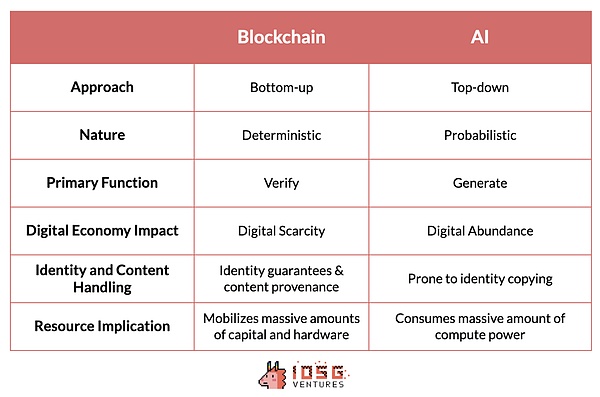
Tokenはボトムアップ的なアプローチをとっており、まず最初に、このようなテクノロジーはどのように相互作用できるかを説明します。アノニマス・サイバーパンクの分散化の取り組みは、世界中の多くの独立した団体の共同作業によって10年以上にわたって進化してきた。これとは対照的に、AIは一握りのテック大手によって支配されたトップダウンのアプローチによって開発された。これらの企業は業界のペースとダイナミクスを支配し、参入障壁は技術的な複雑さよりもリソースの強さによって決定される。
2つのテクノロジーは性質も大きく異なります。基本的に、トークンはハッシュ関数や予測可能性のゼロ知識証明など、不変の結果を生み出す決定論的なシステムです。これは、確率的でしばしば予測不可能なAIの性質とは対照的です。
同様に、暗号は検証を得意とし、トランザクションの真正性とセキュリティを確保し、信頼性のないプロセスやシステムを作成する。strong>に焦点を当て、豊かなデジタル・コンテンツを創造する。しかし、デジタルの豊かさを創造する上で、コンテンツの出所を保証し、なりすましを防ぐことが課題となる。
幸いなことに、トークンはデジタル・アバンダンスの概念に対するアンチテーゼ、つまりデジタル・スカリティを提供する。コンテンツ・ソースの信頼性を確保し、なりすましの問題を回避するために、AI技術に拡張できる比較的洗練されたツールを提供する。
トークンの大きな利点の1つは、特定の目標を達成するために、調整されたネットワークに大量のハードウェアと資本を引き寄せる能力です。この能力は、多くのコンピューティング・パワーを消費するAIにとって特に有益である。利用されていないリソースを動員して安価なコンピューティング・パワーを提供することで、AIの効率を大幅に改善することができる。
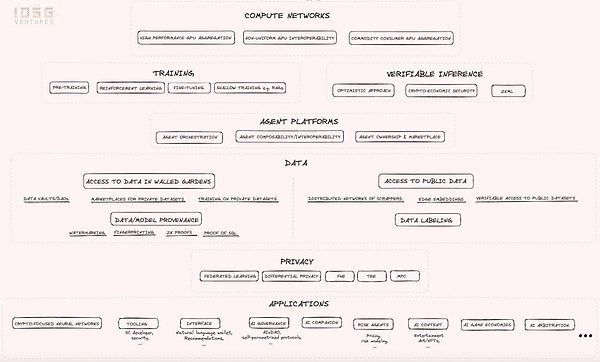
これら2つのテクノロジーを比較対照することで、それぞれの貢献を評価するだけでなく、それらが一緒になることで、テクノロジーと経済に新たな道を切り開くことができることを知ることができる。それぞれの技術がもう一方の技術の欠点を補い、より統合された革新的な未来を創造することができるのだ。このブログポストでは、AI×Web3 業界マップを探求し、これらの技術が交差する新たな垂直統合のいくつかにスポットを当てることを目的としています。
出典:IOSGベンチャー

インダストリー・マッピングは、制約のあるGPUの可用性の問題を解決し、さまざまな方法で計算コストを削減しようとするコンピュート・ネットワークの紹介から始まります。
Non-Unified GPU Interoperability: これは非常に野心的な試みであり、技術的なリスクと不確実性が高いです。しかし、成功すれば、すべてのコンピューティング・リソースを交換可能にし、莫大な規模と影響をもたらす成果を生み出す可能性があります。基本的には、供給側では、あらゆるハードウェアリソースを接続できるようにするコンパイラやその他の前提条件を構築することであり、一方、需要側では、あらゆるハードウェアの不均一性を完全に抽象化し、ネットワーク上のあらゆるリソースにコンピュートリクエストをルーティングできるようにすることである。このビジョンが成功すれば、AI開発者が完全に支配している現在のCUDAソフトウェアへの依存を減らすことができる。技術的なリスクは高く、多くの専門家がこのアプローチの実現可能性に強い懐疑的であるにもかかわらず、です。
高性能GPUアグリゲーション:世界で最も普及しているGPUを、非均一なGPUリソース間の相互運用性を心配することなく、分散したパーミッションなしのネットワークに統合します。
Commodity Consumer GPU Aggregation:供給側で最も十分に活用されていないリソースの一部である、消費者向けデバイスの、性能は低いが潜在的に使用可能なGPUの集合を指します。これは、より安価で長いトレーニングプロセスのために性能と速度を犠牲にすることを厭わない人々を対象としています。
2.2 トレーニングと推論
計算ネットワークは、トレーニングと推論という2つの主要な機能に使用されます。これらのネットワークの必要性は、Web 2.0とWeb 3.0の両方のプロジェクトから来ています。Web 3.0の領域では、Bittensorのようなプロジェクトがモデルの微調整に計算リソースを使用している。推論に関しては、Web 3.0プロジェクトはプロセスの検証可能性を重視している。この焦点は、プロジェクトが分散化を維持しながら、AI推論をスマートコントラクトに統合する方法を模索している市場の垂直方向として、検証可能な推論を生み出しました。
次はインテリジェント・エージェント・プラットフォームで、マッピングの概要は以下の通りです。
Agent interoperability and discovery and communication capabilities: エージェントは互いに発見し、通信することができます。
Agent cluster building and management capabilities: エージェントはクラスタを形成し、他のエージェントを管理することができます。
AIエージェントのオーナーシップとマーケットプレイス:AIエージェントのオーナーシップとマーケットプレイスを提供します。
これらの特徴は、幅広いブロックチェーンとAIアプリケーションにシームレスに統合できる柔軟でモジュール化されたシステムの重要性を強調しています。私たちは、AIエージェントが以下のような方法でインフラに依存することを想定しています:
分散型クローリングネットワークを使用してリアルタイムのウェブデータにアクセスする
インターネットにアクセスするエージェント間の支払いにDeFiチャネルを使用する
金銭的な入金の必要性は、不品行が発生したときにペナルティを与えるためだけでなく、エージェントの発見性を向上させるためでもある(つまり、発見プロセスにおいて金銭的なシグナルとして入金を使用する)
。li>
コンセンサスを活用して、どのイベントが削減をもたらすべきかを決定する
相互運用性を開く。combinable collectives
変動するデータ履歴に基づいて過去のパフォーマンスを評価し、リアルタイムで適切なエージェントの集合体を選択する
変動するデータ履歴に基づいて過去のパフォーマンスを評価し、リアルタイムで適切なエージェントの集合体を選択する

ソース: IOSGVentures
2.4 データレイヤー
AI×Web3 convergence において、データは中核的な要素である。データはAI競争における戦略的資産であり、計算リソースとともに重要なリソースを構成します。しかし、業界のほとんどの関心が計算レベルに集中しているため、このカテゴリーは見落とされがちである。実際、プリミティブは、データ取得プロセスにおいて、以下の2つの主要なハイレベルの方向性を含む、多くの興味深い価値の方向性を提供します。strong>
保護されたデータへのアクセス
公共のインターネットデータへのアクセス:この方向性は、次のことを目的としています。数日でインターネット全体をクロールしたり、巨大なデータセットにアクセスしたり、非常に特定のインターネットデータにリアルタイムでアクセスしたりできる分散クローラーネットワークを構築することです。しかし、インターネット上の大規模なデータセットをクロールするためのネットワーク要件は非常に高く、意味のあることを始めるには少なくとも数百のノードが必要である。幸いなことに、クローラーノードの分散ネットワークであるGrassは、インターネット全体をクロールすることを目標に、すでに200万を超えるノードが積極的にインターネット帯域幅をネットワークにシェアしている。これは、価値ある資源を引き寄せる経済的インセンティブの大きな可能性を示している。
グラスは公共データに関しては競争条件を公平にするが、基礎となるデータの利用、すなわち専有データセットへのアクセスという課題がまだある。具体的には、機密性の高いデータのため、プライバシーが保護された形で保管されているデータがまだ大量に存在する。多くの新興企業は、AI開発者が機密情報を非公開にしながら、専有データセットの基礎となるデータ構造を使用して大規模な言語モデルを構築し、微調整することを可能にする数多くの暗号化ツールを活用しています。
連合学習、差分プライバシー、信頼された実行環境、完全同型性、マルチパーティコンピューティングの技術は、さまざまなレベルのプライバシー保護とトレードオフを提供します。Bagelの研究論文(https://blog.bagel.net/p/Bagelの研究記事(with-great-data-comes-great-responsibility-d67)は、これらの技術の優れた概要を要約しています。これらの技術は、機械学習中のデータプライバシーを保護するだけでなく、計算レベルでの包括的なプライバシー保護AIソリューションを可能にします。
2.5 データとモデルのソーシング
データとモデルのソーシング技法は、ユーザーが意図したモデルやデータとやりとりしていることを保証できるプロセスを確立することを目的としています。プロセスです。さらに、これらの技術は真正性と出所を保証する。例えば、電子透かしは、機械学習アルゴリズムに直接、より具体的にはモデルの重みに署名を埋め込むモデル証明技術の1つであり、これにより、検索時に、推論が意図されたモデルからのものであることを検証することができます。
2.6 アプリケーション
アプリケーションに関しては、設計の可能性は無限です。上記の業界レイアウトでは、AI技術がWeb 3.0スペースに適用される際に特に有望な開発のユースケースをいくつか挙げています。これらのユースケースのほとんどは自明であるため、ここでの補足説明は省略する。しかし、AIとWeb 3.0の交差点は、この分野の多くの分野を再形成する可能性を秘めていることは注目に値します。なぜなら、これらの新しいプロト言語学は、革新的なユースケースを作成し、既存のものを最適化する自由を開発者に提供するからです。strong>
AI×Web3の融合は、革新と可能性を約束します。各技術のユニークな強みを活用することで、課題を解決し、新しい技術的な道を切り開くことができます。この新興産業を探求する上で、AI×Web3の相乗効果は進歩を促し、私たちのデジタル体験とウェブ上での交流方法の未来を再構築することができます。
デジタルの希少性とデジタルの豊富性の融合、計算効率を達成するための十分に活用されていないリソースの動員、安全でプライバシーを保護するデータプラクティスの確立は、技術進化の次の時代を定義するでしょう。
しかし、この業界がまだ黎明期にあり、現在の業界風景が短期間で時代遅れになる可能性があることを認識することが重要です。技術革新のペースが速いということは、今日の最先端ソリューションがすぐに新たなブレークスルーに取って代わられる可能性があるということだ。とはいえ、計算ネットワーク、エージェント・プラットフォーム、データ・プロトコルなど、探求された基礎概念は、AIがWeb 3.0と融合することの広大な可能性を浮き彫りにしている。
ユーザー数がそれほど増えないこの時期に、非常に高いユーザー数と成長を維持しているエコシステムがすでに存在する。
JinseFinance完全同型暗号化(FHE)は、暗号化されたデータ(暗号文)に対して、データを復号化することなく計算を実行できるようにする暗号化方式の一種で、プライバシーやデータ保護のためのさまざまなユースケースを開拓する。
JinseFinanceFarcasterは、分散型ソーシャルグラフへの道を開く堅牢なインフラレイヤーを構築し、ユーザーとそのソーシャルデータ全体を追跡している。
JinseFinanceBitVM,レイヤー2,BTC,IOSG |BitVM:ビットコインのプログラマビリティの夜明け 黄金の金融、ビットコイン・スケーリング・ソリューションの急拡大
JinseFinance私たちはAIとWeb3の黎明期にあり、AIとブロックチェーン分野の統合は、他の産業と比べるとまだ初期段階にある。
JinseFinance最近、EigenLayerのrepledgingとLRTをめぐる議論が盛んで、ユーザーはプロトコルの潜在的なエアドロップの期待に賭けており、repledgingはイーサリアムのエコシステムで最もホットな物語になっています。この記事では、LRTに関する筆者の考えや見解について簡単に説明します。
JinseFinanceAIGC,IOSG|GPU供給の危機:AIスタートアップの躍進への道 Golden Finance,新たなGPU供給が逼迫する中、ブロックチェーンの出番は?
JinseFinance2023年は、IOSGベンチャーズにとって誇りを持ち、果敢に前進する年です。
JinseFinance暗号通貨の時価総額が拡大し、チェーン上で可処分資本を持つ人が増えるにつれ、予測市場産業は儲かるか、少なくとも同じくらい有用である。
JinseFinance像《黑暗森林》这样的全链游戏已经证明,你可以把游戏逻辑都放在链上,且由于其具有无许可的互操作性,鼓励了社区创造新工具、联盟和 DAO 等等。
 Others
Others