Apple Vision Proは失敗作?アップルかメタか?
一方、メタ社はルフトハンザやテンセントと戦略的提携を結び、VR市場への積極的な参入を表明している。
 Weatherly
Weatherly

ソース:Heart of the Metaverse
Google, Samsung, MicrosoftがPCやモバイルデバイスでAI生成技術を強力にプッシュし続けているのと同じように、AppleもOpenELMでバンドワゴンに加わろうとしています。
これはオープンソースの大規模言語モデル(LLM)の新しいファミリーで、クラウドサーバーに接続することなく、1つのデバイスですべて実行できます。サーバーに接続する必要がありません。
人工知能コードコミュニティのHugging Faceで現地時間の水曜日にリリースされたOpenELMは、テキスト生成タスクを効率的に実行するように設計された一連の小さなモデルで構成されています。
OpenELMには、4つの事前学習済みモデルと4つの命令調整済みモデルの合計8つのモデルがあり、2億7,000万から30億の異なるパラメータをカバーしています(パラメータとは、LLMの人工ニューロン間の接続数を指し、通常、パラメータが多いほど高いパフォーマンスとより多くの機能を示します)。
事前トレーニングは、LLMに首尾一貫した、潜在的に役立つテキストを生成させるための方法ですが、それは主に予測的なエクササイズであり、一方、インストラクションチューニングは、LLMに特定のユーザーリクエストに応じて、より関連性の高い出力をさせるための方法です。
事前トレーニングの結果、モデルは単純なテキストでプロンプトを完了するだけになる可能性があります。たとえば、「パンの焼き方を教えてください」というユーザーのプロンプトに直面した場合、モデルは実際のステップバイステップの指示ではなく、「家でオーブンを使ってください」というような内容で応答する可能性があります。
Appleは、OpenELMモデルの重みを「サンプルコードライセンス」と呼ぶものの下で提供し、さまざまなトレーニングのチェックポイント、モデルのパフォーマンス統計、事前トレーニング、評価、命令のチューニング、パラメーターの微調整についての説明も提供しています。
サンプルコードライセンスは、商用利用や改変を禁止しているわけではなく、「Appleのソフトウェアの全内容を改変せずに再配布する場合は、テキストにこの通知を残しておかなければならない」と述べているだけです。
アップルはさらに、これらのモデルには「いかなるセキュリティ保証も付属していない」と指摘しています。その結果、これらのモデルはユーザーのプロンプトに対して「不正確、有害、偏った、または不快な出力」を生成する可能性があります。
秘密主義で知られ、典型的な「閉鎖的」技術企業であるAppleは、モデルや論文をオンラインに掲載するだけで、この分野での研究プロセスを公には発表していません。
さらにAppleは昨年10月、マルチモーダル機能を備えたオープンソースの言語モデル「Ferret」をひっそりとリリースし、大きな話題となりました。
OpenELM(Open-source Efficient Language Modelsの略)はリリースされたばかりで、まだ公開テストは行われていませんが、AppleがHuggingFaceに掲載していることから、以下のようなデバイスアプリをターゲットにしていることがわかります。HuggingFaceに掲載されていることから、ライバルのGoogleやSamsung、Microsoftと同様に、このモデルのデバイスアプリをターゲットにしていることがわかります。
マイクロソフトが今週、スマートフォンのみで動作するPhi-3 Miniモデルをリリースしたことは注目に値する。
Appleは、モデルファミリーを説明する論文の中で、OpenELMの開発は「Sachin Mehtaが主導し、Mohammad RastegariとPeter Zatloukalが主要な貢献者であった。「そして、モデルファミリーは「オープンリサーチコミュニティに力を与え、強化し、将来の研究努力を促進することを目的としている」と述べています。
OpenELMモデルには、2億7,000万、4億5,000万、11億、30億の4つのパラメータサイズがあり、それぞれ多くの高性能モデル(通常約70億のパラメータを持つ)よりも小さく、訓練済みバージョンと指示済みバージョンがあります。
モデルは、Reddit、Wikipedia、arXiv.orgなどのサイトから1.8兆トークンを集めた公開データセットで事前に訓練されました。
このモデルは、市販のラップトップや一部のスマートフォンでも実行可能です!ベンチマークは「Intel i9-13900KF CPU, NVIDIA RTX 4090 GPU, Ubuntu 22.04 workstation, MacBook Pro with macOS 14.4.1」で実行されました。
興味深いことに、新シリーズのすべてのモデルは、トランスフォーマーモデルの各レイヤーでパラメータを割り当てるレイヤースケーリング戦略を採用しています。
Appleによると、これにより、計算効率を向上させながら、より精度の高い結果を提供することができます。一方、Appleは新しいCoreNetライブラリを使用してモデルを事前に訓練しました。
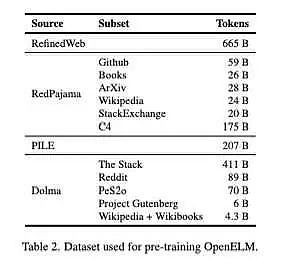
AppleはHuggingFaceで、「私たちの事前訓練データセットには、RefinedWeb、重複するPILE、RedPajamaのサブセット、Dolma v1.6のサブセットが含まれており、合計で約1兆8000億トークンが含まれています」と述べています。p>
パフォーマンスに関しては、Appleによって共有されたOpenLLMの結果は、特に4.5億パラメータのインジケータバリアントで、モデルが非常にうまく機能していることを示しています。
さらに、11億パラメータの"OpenELMバリアント "は、12億パラメータの "OLMo "を2.36%上回る一方で、2倍少ない事前訓練トークンを必要とします。
OLMoはAllen Institute for Artificial Intelligence (AI2)によって最近リリースされた「真にオープンソースで最先端の大規模言語モデル」です。
事前に訓練されたOpenELM-3Bの亜種は、知識と推論能力をテストするために設計されたARC-Cベンチマークで42.24パーセントの精度を示しました。一方、MMLUとHellaSwagでは、それぞれ26.76パーセントと73.28パーセントの精度でした。
OpenELMモデルをテストし始めたあるユーザーは、OpenELMモデルは「信頼できるモデルだが、非常に画一的」であるようだと指摘しています。
ライバルのMicrosoftが最近発表したPhi-3 Miniは、38億のパラメータと4kのコンテキスト長を持ち、現在この分野をリードしています。
最近共有された統計によると、OpenELMは10個のARC-Cベンチマークで84.9パーセント、5個のMMLUテストで68.8パーセント、5個のHellaSwagテストで76.7パーセントを記録しました。
OpenELMのパフォーマンスは長期的には向上すると予想されます。
しかし、Appleのオープンソースのイニシアチブはすでにコミュニティを興奮させており、コミュニティがさまざまな環境でOpenELMをどのように使用するか見ていくことになるでしょう。
Appleは、そのジェネレーティブAI計画について沈黙を守ってきましたが、新しいAIモデルのリリースにより、同社の最近の野心は「AIを機能させる」ことにしっかりと設定されているようです。
Appleはこれまで、ジェネレーティブAI計画について沈黙を守ってきました。
アップルのティム・クック最高経営責任者(CEO)は、「AIを生み出す機能はアップルのデバイスに搭載される」と予告しており、今年2月にはアップルのAIはアップルのデバイスで利用できるようになると述べていた。また2月には、アップルがこの分野で「多くの時間と労力を費やしている」とも語っていた。しかし、アップルはまだAIアプリケーションの具体的な詳細を明らかにしていない。
同社は以前にも他のAIモデルをリリースしているが、競合他社のように商用利用を目的としたAIベースのモデルはリリースしていない。
Appleは昨年12月、OpenELMに加えてMLXという機械学習フレームワークを発表した。また、MGIEと呼ばれる画像編集モデルも発表された。また、スマートフォンのナビゲーションに使用できるFerret-UIと呼ばれるモデルも発表された。
しかし、アップルがリリースしたすべてのモデルでも、同社はグーグルとOpenAIに、彼らのモデルをアップル製品に導入するよう働きかけていると伝えられている。
一方、メタ社はルフトハンザやテンセントと戦略的提携を結び、VR市場への積極的な参入を表明している。
Weatherlyアップル社のMシリーズ・チップに深刻な脆弱性が発見され、ハッカーが暗号鍵にアクセスできるようになった。この "パッチ不可能な "欠陥は、アップルのセキュリティ・インフラに重大な課題を突きつけている。
 Alex
Alexソラーナ、オピニオン:ソラーナは "暗号資産のアップル "になるかもしれない ゴールド・ファイナンス、新たな調査によると、ソラーナがトップに立った。
 JinseFinance
JinseFinanceスティーブ・ウォズニアックは、ビットコイン詐欺を宣伝するためにYouTubeの動画が改ざんされているとして、YouTubeとその親会社であるグーグルを提訴した。
JinseFinanceアップル(AAPL)、アマゾン(AMZN)、メタ(META)の決算に投資家が期待。iPhoneの需要、ホリデーシーズンの業績、広告戦略に注目。決算前の取引は楽観的。
 Edmund
Edmund最近、Bitgetのような暗号アプリがアップルのApp Storeから削除されたことは、憂慮すべき傾向を浮き彫りにし、暗号空間における透明性とユーザーの安全性への懸念を高めている。
 Brian
Brianアップル、遅れをとるAI構想の加速に10億ドルを計上。経営陣の不安の中、巨大ハイテク企業は、よりスマートなSiriなどを実現するためのジェネレーティブAI技術の開発を急ピッチで進めている。
 YouQuan
YouQuanWatcher.guruの報告によると、イーサリアムのセルフ・カストディ・ウォレットであるMetaMaskが、アプリストアから謎の消滅を遂げた。
 Davin
Davinテクノロジーの巨人は、メタバースに大きなチャンスがあると考えています。メタバースとは、現実世界との結びつきの可能性を秘めた、将来のより没入型のインターネットのビジョンに付けられた名前です。
 decrypt
decryptティム・クック氏は投資家との電話会議で、メタバースアプリには多くの可能性があり、同社はオンデバイスAR開発に投資していると述べた。
 Cointelegraph
Cointelegraph