
咳の音から呼吸器疾患を検知するAIモデルが世界の医療を強化
グーグルのAIモデル「HEAR」は、咳の音を分析することによって結核などの呼吸器疾患を検出するために使用されており、特に従来の医療サービスへのアクセスが限られている地域において、グローバルヘルスケアに有望な新しいツールを提供している。
 Bernice
Bernice

Author: Misty Moon, GeekWeb3
周知の通り、EVMはイーサリアムの「実行エンジン」「スマートコントラクト実行環境」として位置づけられている。周知の通り、EVMはイーサリアムの「実行エンジン」「スマートコントラクト実行環境」として位置づけられており、イーサリアムの最も重要なコアコンポーネントの1つと言えます。パブリックチェーンは何千ものノードを含むオープンネットワークであり、ノードによってハードウェアのパラメータは大きく異なります。 スマートコントラクトを複数のノード上で同じ結果で実行し、一貫性を満たしたいのであれば、異なるデバイス上で同じ環境を構築する方法を見つける必要があり、これは仮想マシンで実現できます。
イーサリアムの仮想マシンであるEVMは、異なるオペレーティングシステム(Windows、Linux、macOSなど)やデバイス上でスマートコントラクトを同じように実行し、このクロスプラットフォーム互換性により、コントラクトを実行するすべてのノードが一貫した結果を得ることができます。その代表例がJava仮想マシンJVMです。
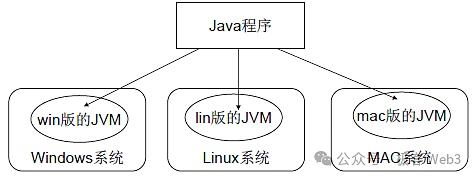
私たちが通常ブロックブラウザで目にするスマートコントラクトは、チェーン上に保存される前にEVMバイトコードにコンパイルされます。EVMは、コントラクトを実行する際にこれらのバイトコードを直接、順次読み込みます。バイトコードに対応する各命令(opCode)には、対応するガスコストがあります。の複雑さに依存します。
さらに、イーサネットのコア実行エンジンとして、EVM はトランザクションをシリアルに処理し、すべてのトランザクションは単一のキューにキューイングされ、定義された順序で順次実行されます。並列化を使用しない理由は、ブロックチェーンは一貫性を厳密に満たさなければならず、トランザクションのバッチはすべてのノードで同じ順序で処理されなければならないため、対応するスケジューリングアルゴリズムが導入されない限り、トランザクションが並列処理された場合の順序を正確に予測することは難しく、より複雑になるからです。
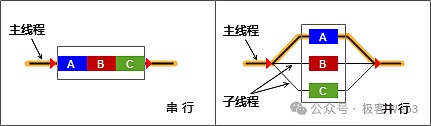
2014年から15年にかけてのイーサリアム創設チームシリアル実行が選ばれたのは、時間的な制約からでした。これは、シンプルでメンテナンスしやすいように設計されていたからです。しかし、ブロックチェーン技術の反復とユーザーベースが大きくなるにつれて、ブロックチェーンのTPSとスループットに対する要件はますます高くなり、ロールアップ技術が登場し、地上に成熟した後、EVMシリアル実行によってもたらされたパフォーマンスのボトルネックは、EtherChannelの第2層で露呈しました。
レイヤー2の重要なコンポーネントであるシーケンサーは、単一のサーバーとしてすべてのコンピューティングタスクを引き継ぎます。 シーケンサーと連携する外部モジュールの効率が十分に高ければ、最終的なボトルネックはシーケンサー自体の効率に依存します。最終的なボトルネックはシーケンサー自体の効率に依存し、その時点でシリアル実行は大きな障害となります。
opBNBチームは、DAレイヤーとデータ読み取り/書き込みモジュールの極端な最適化により、Sequencerに1秒あたり最大約2,000以上のERC-20転送を実行させました。この数字は高いように見えますが、処理されるトランザクションがERC-20転送よりもはるかに複雑な場合、TPS値はもっと低くなるはずです。そのため、トランザクション処理の並列化は将来的に避けられないトレンドになるでしょう。
以下では、より具体的な内容から、従来のEVMの限界と並列EVMの利点を説明します。
イーサ・トランザクション実行の2つのコアコンポーネント
コードモジュール・レベルでは、EVMに加えて、トランザクション実行に関連するgo-ethereumのもう1つのコアコンポーネントは、イーサ・トランザクション管理システムです。実行に関連する、go-ethereumのもう1つのコア・コンポーネントはstateDBであり、これはイーサにおけるアカウントの状態とデータの保存を管理するために使用される。イーサネットは、Merkle Patricia Trieと呼ばれるツリー構造を使用してデータベースのインデックス(カタログ)として機能し、EVMでの各トランザクションの実行によってstateDBに保存されているデータの一部が変更され、最終的にMerkle Patricia Trie(以降、グローバルステートツリーと呼ぶ)に反映されます。
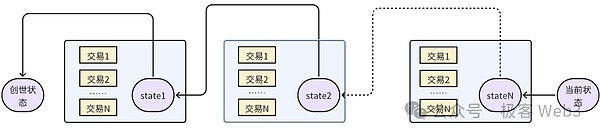
具体的には、stateDBはすべてのイーサネットアカウントの状態を維持する役割を担っています。具体的には、stateDBはEOAアカウントやコントラクトアカウントを含むすべてのイーサネットアカウントの状態を維持する役割を担っており、その保存データにはアカウント残高やスマートコントラクトコードなどが含まれる。トランザクションの実行中、stateDBは対応するアカウントのデータを読み書きする。そしてトランザクションの実行が終わると、stateDBは新しい状態を永続化のために基礎となるデータベース(LevelDBなど)に提出する必要がある。
一言で言えば、EVMはスマートコントラクトコマンドの解釈と実行を担当し、その計算結果に基づいてブロックチェーン上の状態を変更する一方、stateDBはグローバルな状態ストアとして機能し、すべてのアカウントとコントラクトの状態変更を管理する。両者はイーサネットのトランザクション実行環境を構築するために協力している。
シリアル実行の仕様
イーサにおけるトランザクションには、EOAトランザクションとコントラクトトランザクションの2種類があります。EOA送金は最もシンプルな取引タイプで、通常の口座間でのETH送金です。このタイプの取引はコントラクトコールを伴わず、非常に迅速に処理されます。シンプルであるため、EOA送金のガス料金は非常に低くなっています。
単純なEOA送金とは異なり、コントラクト取引はスマートコントラクトの呼び出しと実行を伴い、EVMはコントラクト取引を処理する際にスマートコントラクト内のバイトコードコマンドを1つずつ解釈して実行しなければならず、コントラクトのロジックが複雑であればあるほど、より多くのコマンドを伴い、より多くのリソースを消費します。
例えば、ERC-20送金の処理時間はEOA送金の約2倍で、Uniswapでのトランザクション操作など、より複雑なスマートコントラクトではさらに時間がかかり、EOA送金の10倍以上遅くなることさえあります。これは、DeFiプロトコルが取引時に流動性のプール、価格計算、トークンのスワップなどの複雑なロジックを処理する必要があり、非常に複雑な計算が必要になるためです。
では、EVMとstateDBの2つのコンポーネントは、どのように連携してシリアル実行モードのトランザクションを処理するのでしょうか?
Etherの設計では、ブロック内のトランザクションは一度に1つずつシーケンシャルに処理され、各トランザクション(tx)はそのトランザクションの特定のアクションを実行する個別のインスタンスを持ちます。
トランザクションの実行中、EVMは常にstateDBと相互作用し、stateDBから関連データを読み取り、stateDBに変更データを書き戻す必要があります。
トランザクションの実行中、EVMは常にstateDBと相互作用し、stateDBから関連データを読み取り、stateDBに変更データを書き戻す必要があります。
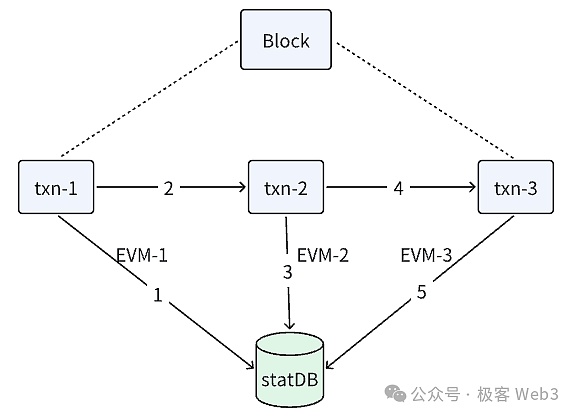
EVMとstateDBがどのように連携してトランザクションを実行するのか、コードの観点から大まかに見てみましょう:
1.processBlock()関数は、Process()関数を呼び出し、ブロックに含まれるトランザクションを処理する。

2.Process()関数の中でforループが定義されており、トランザクションが1つずつ実行されているのがわかる。
3.すべてのトランザクションが処理された後、processBlock()関数はwriteBlockWithState()関数を呼び出します。そして、statedb.Commit()関数を呼び出し、状態変更の結果をコミットします。
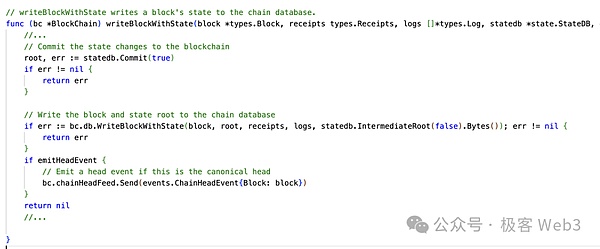
ブロック内のトランザクションがすべて実行されると、Statedb.トランザクションが実行され、stateDB内のデータが前述のグローバル・ステート・ツリー(Merkle Patricia Trie)にCommitされ、新しいstateRootが生成される。 stateRootは、ブロック実行後の新しいグローバル状態の「圧縮結果」を記録する、各ブロックの重要なパラメータである。
EVMのシリアル実行モデルのボトルネックは簡単にわかる。トランザクションは順次キューに入れなければならず、長引いたスマートコントラクトのトランザクションがあれば、他のトランザクションはそれが処理されるまで待つしかない。
EVMのマルチスレッド並列最適化
実際の例を使ってシリアル実行と並列実行を比較すると、前者はカウンターが1つしかない銀行に似ています。パラレルEVMは複数のカウンタを持つバンクに似ています。並列モードでは、複数のトランザクションを同時に処理するために複数のスレッドを開くことができ、効率は数倍向上しますが、厄介なのは状態競合の問題です。
コンフリクトは、複数のトランザクションが同時に処理される際に、特定の口座のデータを書き換えたいと宣言した場合に発生する。例えば、あるNFTが1に対してのみ造幣可能で、トランザクション1と2がともにそのNFTを造幣したいと宣言し、両方の要求が満たされた場合、明らかにエラーが発生する。このような状況に対処するには協調処理が必要である。実際の状態競合はこれまで述べてきたよりも頻繁に起こる傾向があるため、トランザクション処理を並列化するのであれば、状態競合に対処する対策が必要である。
ReddioによるEVMの並列最適化の根拠
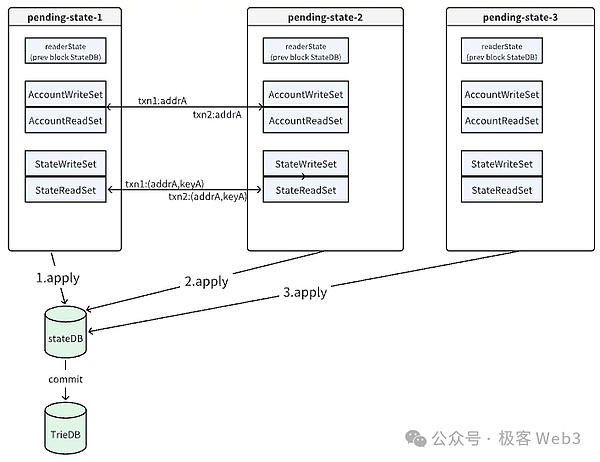
ZKRollupプロジェクトのReddioにおけるEVMの並列最適化の根拠を見ることができます。.Reddioのアイデアは、各スレッドにトランザクションを割り当て、各スレッドにpending-stateDBと呼ばれる一時的な状態データベースを提供することです。詳細は以下の通りです:
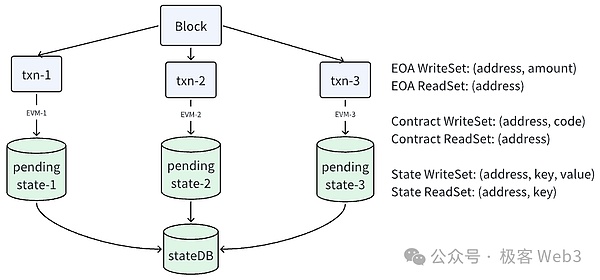
1.トランザクションのマルチスレッド並列実行:Reddioは、異なるトランザクションを同時に処理するために複数のスレッドを設定し、スレッド同士が干渉しないようにします。これにより、トランザクション処理が数倍高速化されます。
2.各スレッドに一時状態データベースを割り当てる: Reddioは、各スレッドに個別の一時状態データベース(pending-stateDB)を割り当てます。トランザクションの実行時にグローバルなステートDBを直接変更する代わりに、各スレッドはステートの変更結果を一時的にpending-stateDBに記録します。
3.状態変更の同期:ブロック内のすべてのトランザクションが実行された後、EVMは各pending-stateDBに記録された状態変更の結果を順番にグローバルstateDBに同期させます。異なるトランザクションの実行中に状態の競合が発生しなければ、pending-stateDBのレコードはスムーズにグローバルstateDBにマージされます。
Reddioは、トランザクションが状態データに正しくアクセスし、競合を回避できるように、読み取りと書き込みの操作方法を最適化しています。
読み取り操作: トランザクションが状態を読み取る必要がある場合、EVMはまずpending-stateのReadSetをチェックします。pending-stateDBから直接データを読み込む。ReadSetに対応するkey-value(keyとvalueのペア)が見つからない場合は、前のブロックに対応するglobal stateDBから過去の状態データを読み込む。
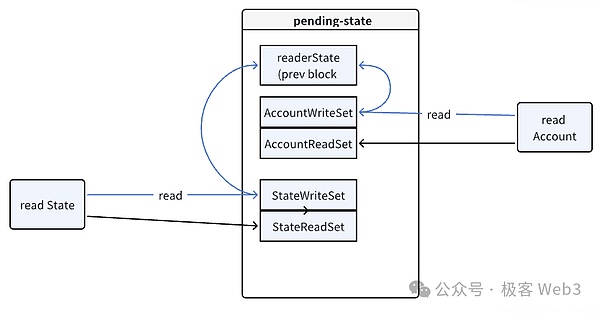
書き込み操作:
すべての書き込み操作(すなわち、すべてのキーと値のペア)。strong>すべての書き込み操作(すなわち状態への変更)は、グローバルstateDBに直接書き込まれるのではなく、まずPending-stateのWriteSetに記録される。トランザクションが実行された後、競合検出は状態変更の結果をグローバルstateDBにマージしようとします。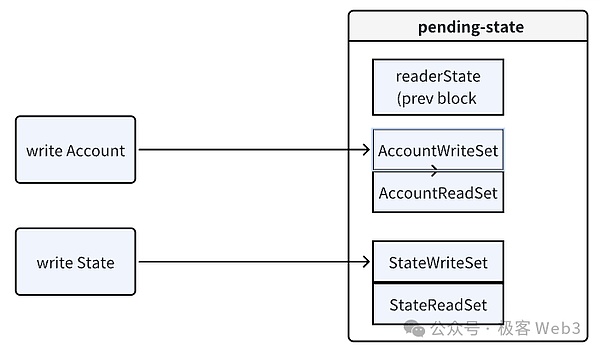
並列実行における重要な問題は、以下のような場合の状態の競合です。複数のトランザクションが同じアカウントの状態を読み書きしようとする場合です。
- コンフリクトの検出: トランザクションの実行中、EVMは異なるトランザクションのReadSetとWriteSetを監視し、複数のトランザクションが同じステータス項目を読み書きしようとした場合、コンフリクトと見なされます。を競合とみなす。
- 競合の処理: 競合が検出されると、競合するトランザクションは再実行のためにマークされる。
すべてのトランザクションが実行された後、複数のpending-stateDBの変更レコードがグローバルstateDBにマージされます。マージが成功すると、EVMは最終状態をグローバル状態ツリーにコミットし、新しい状態ルートを生成する。
マルチスレッド並列最適化のパフォーマンス上の利点は明らかです。特に複雑なスマート・コントラクト・トランザクションを扱うときには明らかです。
並列EVMの研究によると、競合の少ないワークロード(プール内の競合が少ない、または同じリソースを占有するトランザクション)では、ベンチマークは従来のシリアル実行と比較して約3~5倍のTPS向上を示しています。競合の多いワークロードでは、すべての最適化が使用された場合、理論的には60倍に達する可能性さえあります。
要約
ReddioのEVMのマルチスレッド並列最適化は、各トランザクションに一時状態リポジトリを割り当て、異なるスレッドでトランザクションを並列実行することで、EVMのパフォーマンスを大幅に向上させます。EVMのトランザクション処理能力を大幅に向上させます。読み取り/書き込み操作を最適化し、競合検出メカニズムを導入することで、EVMパブリックチェーンは、状態の一貫性を保証することを前提に、トランザクションの大規模な並列化を実現し、従来のシリアル実行モードによる性能ボトルネックを解決する。これは、イーサネット・ロールアップの将来の発展のための重要な基礎を築くものです。
Reddioの実装の詳細をさらに分析します。たとえば、ストレージ効率の最適化から効率をさらに向上させる方法、高競合への最適化、GPUへの最適化などです。
グーグルのAIモデル「HEAR」は、咳の音を分析することによって結核などの呼吸器疾患を検出するために使用されており、特に従来の医療サービスへのアクセスが限られている地域において、グローバルヘルスケアに有望な新しいツールを提供している。
BerniceSOLANA,データ公開:ソラーナは天皇の新しい服か? ゴールデンファイナンス、一般的に引用されるSOL指標は著しく誇張されている
 JinseFinance
JinseFinanceソラーナは本当にイーサを超え、パブリックチェーンの次の王になる可能性を秘めているのだろうか?それとも逆に、ソラーナの繁栄は人為的に作り上げられた幻想なのか、それとも皇帝の新しい服なのか?
JinseFinance今日は、私が考えるNostrについて、そしてなぜNostrがサイバースペースにとって重要なのかについて話したい。
JinseFinanceビットコインは、世界的な分散型デジタル通貨になるという約束を果たすことができず、合法的な送金に使用することは依然として困難である。 ETFが承認されても、ビットコインが決済や投資の手段として適していないという事実は変わらない。
JinseFinance型破りな宣伝策か、それとも常軌を逸した技術革新か?バイナンスは、有名なサッカー・アイコンであるクリスティアーノ・ロナウドを嘘発見器テストにかける。
 Kikyo
Kikyo彼は、仮想通貨の成功は主に金利がほとんど存在しないことに起因しており、それが人々を「実際の金融」ではなく投機へと駆り立てていることを示唆しています。
 Others
Othersチャイナ・ライニングは、ボアド・エイプ・ヨット・クラブ#4102をイメージし、ピクセルスタイルやストリートなどのトレンド要素を取り入れた「チャイナ・ライニング・ボアド・エイプ・トレンド・スポーツ・クラブ」シリーズのアパレルを発売したとSNSに投稿した。スタイル。
 链向资讯
链向资讯分散型金融は、厳格な境界がある世界でデジタル遊牧民に不可欠な経済的自由ツールを提供します。
 Cointelegraph
Cointelegraphビットコインのハッシュレートは過去最高を記録し、最後の半減期が採掘されてから 105,000 ブロックに達し、次の半減期への道のりを示しました。
Cointelegraph