AI+暗号の組み合わせの可能性
チェーンの抽象化,人工知能,AI+暗号の組み合わせの可能性 ゴールデンファイナンス,技術的な観点から、チェーンの抽象化は断片化問題を解決できるか?
 JinseFinance
JinseFinance

著者: Misty Moon, geekweb3
今日のブロックチェーン技術の反復はますます速くなり、パフォーマンスの最適化は重要なトピックになっています。
以前の投稿 - "Reddioからの並列EVM最適化パス"では、Reddioの並列EVM設計アイデアの簡単な概要を説明しましたが、今日の記事では、技術的なソリューションと、AIと組み合わせることができるシナリオについて、さらに詳しく見ていきます。
Reddioの技術的ソリューションは、GPUを使用してEVMの実行効率を向上させるプロジェクトであるCuEVMを使用しているため、まずはCuEVMについて説明します。
CuEVMはGPUでEVMを加速するプロジェクトで、イーサネットEVMのオペコードをNVIDIA GPU上で並列実行するためのCUDAカーネルに変換します。GPUの並列計算能力を利用して、EVM命令の実行効率を向上させる。
コンピュート ユニファイド デバイス アーキテクチャ
CUDA CUDA は、NVIDIA によって開発された並列コンピューティング プラットフォームおよびプログラミング モデルです。Compute Unified Device Architecture (CUDA)は、NVIDIA
が開発した並列コンピューティングプラットフォームおよびプログラミングモデルで、開発者がGPUの並列コンピューティングパワーを汎用コンピューティング(たとえば、暗号のマイニング、ZK演算など)に活用することを可能にします。オープンな並列コンピューティングフレームワークとして、CUDAは本質的にC/C++言語の拡張であり、C/C++に精通した基本的なプログラマーであれば誰でもすぐに始めることができます。また、CUDAの非常に重要な概念はカーネルであり、これもC++関数です。

しかし、1 回だけ実行される通常の C++ 関数と異なり、これらのカーネル関数は、構文的に <<<... が起動されるまで実行されません。>>> は、N 個の異なる CUDA スレッドによって N 回並列実行されます。
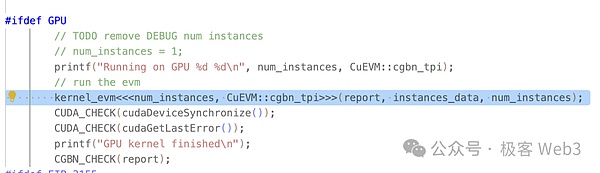
各CUDAスレッドには個別のスレッドIDが割り当てられ、スレッド階層を使用してスレッドをブロックとグリッドに割り当てることで、多数の並列スレッドを簡単に管理できます。スレッド階層が使用されます。NVIDIAのnvccコンパイラーを使用して、CUDAコードをGPU上で実行可能なプログラムにコンパイルすることができました。

CUDAの基本概念一式を理解したら、次はCuEVM
のワークフローを見てみましょう。のワークフローを見てみましょう。CuEVMへの主なエントリーポイントはrun_interpreterで、ここから並列処理されるトランザクションがjsonファイルの形式で入力されます。プロジェクトのユースケースからわかるように、入力は標準的なEVMコンテンツであり、開発者が個別に処理、翻訳などを行う必要はありません。

CUDA 定義の <<...>> 構文を使用する run_interpreter() で確認できます。kernel_evm()カーネル関数が呼び出されます。上で述べたように、カーネル関数はGPU内で並列に呼び出されます。
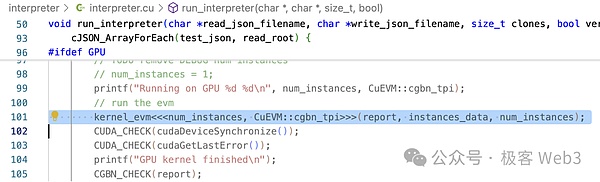
kernel_evm()メソッドでは、evm->run()の呼び出しがあります。操作に変換するために、ここで多くの分岐判断が行われていることがわかります。
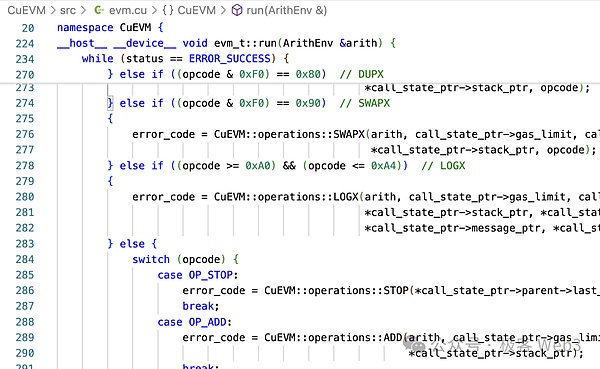
EVMの加算オペコードであるOP_ADDを例にとると、ADDをcgbn_addに変換していることがわかります。 CGBN (Cooperative Groups Big Numbers)は、CUDAのオペコードです。Big Numbers)は、CUDAの高性能多精度整数演算ライブラリです。

以上の2つのステップにより、EVMオペコードがCUDAオペレーションに変換されます。CuEVMは、CUDA上のすべてのEVM演算の実装でもあると言えます。最後に、run_interpreter()メソッドは操作の結果、つまりワールドの状態やその他の情報を十分に返します。
CuEVMの基本的なロジックが紹介されました。
CuEVMにはトランザクションを並列処理する機能がありますが、CuEVMプロジェクトの目的(または主に実証された使用例)はファジングテストを行うことです。これにより、潜在的なバグやセキュリティ上の問題を特定することができます。
ファジングは並列処理に適していることがわかります。CuEVMがトランザクションの競合のような問題を扱わないのに対して、それはCuEVMの関心事ではありません。CuEVMを統合したいのであれば、競合するトランザクションも処理する必要があります。
これについては以前の記事"Reddioから並列EVMの最適化の道を参照してください"でReddioは、競合処理機構の使用を導入している、ここでは繰り返しません。 ソートした後、競合処理機構とトランザクション内のReddioは、その後、CuEVMに送信することができます。競合処理とCuEVM並列実行:言い換えれば、ReddioのL2のトランザクションシーケンスメカニズムは2つの部分に分けることができます。
並列EVMとL2はReddioの出発点に過ぎず、将来のロードマップではAIのシナリオと明示的に組み合わせることになると言われています。高速並列トランザクションにGPUを使用するReddioは、多くの点で本質的にAI操作に適しています。
GPU は高度に並列化されており、ディープラーニングにおける畳み込み演算の実行に適しています。これらは基本的に大規模な行列の乗算であり、GPUはこれらのタスクに最適化されています。
GPUのスレッド階層は、AI計算のさまざまなデータ構造に対応し、計算効率を向上させ、スレッドのオーバーマッチングとWarp実行ユニットによってメモリレイテンシーを隠蔽します。
計算強度はAI計算性能の重要な指標であり、GPUはTensor Coreの導入などを通じて計算強度を最適化し、AI計算における行列乗算の性能を向上させ、計算とデータ転送の効果的なバランスを実現しています。
Rollupのアーキテクチャ設計では、ネットワーク全体にいるのは実際にはシーケンサーだけでなく、トランザクションを検証したり収集したりするスーパーバイザーやフォワーダーのような役割もあることがわかっています。伝統的なRollupでは、これらの二次的な役割は、Arbitrumのウォッチャーのような、本質的に受動的で防御的対公益的な役割であり、疑わしい収益モデルを持っているような、非常に限られた機能と権限を持っています。
Reddioは分散型シーケンサーアーキテクチャを使用し、採掘者はGPUをノードとして提供します。Reddioネットワーク全体は、純粋なL2から統合されたL2+AIネットワークへと進化することができ、多くのAI+ブロックチェーンのユースケースに適しています:
ブロックチェーン技術の継続的な進化に伴い、AIエージェントはブロックチェーン・ネットワークに応用できる大きな可能性を秘めています。金融取引を実行するAIエージェントを例にとってみましょう。これらのインテリジェントエージェントは、自律的に複雑な決定を下し、取引業務を実行することができ、高頻度の状況下で迅速に反応することもできます。しかし、このような集中的な業務に対処する際、L1が巨大な取引負荷を運ぶことは基本的に不可能です。

そしてReddioはL2プロジェクトとして、GPUアクセラレーションによってトランザクションの並列処理を劇的に改善することができます。L1と比較して、トランザクションの並列実行をサポートするL2は、より高いスループットを持ち、ネットワークの円滑な運用を保証するために、多数のAIエージェントからの高頻度のトランザクション要求を効率的に処理することができます。
高頻度取引では、AIエージェントは取引速度と応答時間の点で非常に要求が厳しく、L2は取引の検証と実行にかかる時間を短縮することで、待ち時間を短縮します。これは、ミリ秒単位で応答する必要があるAIエージェントにとって非常に重要です。大量のトランザクションをL2に移行することで、メインネットワークの混雑も効果的に緩和される。これにより、AIエージェントの運用はより費用対効果が高くなります。
ReddioのようなL2プロジェクトが成熟するにつれ、AIエージェントはブロックチェーン上でより重要な役割を果たすようになり、DeFiやAIと組み合わせた他のブロックチェーンアプリケーションシナリオのイノベーションを促進するでしょう。
Reddioは将来的に分散型シーケンサーアーキテクチャを採用し、マイナーたちはGPU演算を使ってシーケンシングの権利を決定し、ネットワーク参加者全体のGPUの性能は競争によって徐々に向上し、AIのトレーニングとして使われるレベルにまで達することができるようになるでしょう。
分散型GPU演算市場を構築し、AIの訓練や推論に低コストな演算リソースを提供する。小規模から大規模まで、パーソナルコンピュータからマシンルームクラスターまで、GPU演算のあらゆるレベルがこの市場に参加し、遊休演算を提供して収益を得ることができ、このモデルはAI演算のコストを削減できるため、より多くの人がAIモデルの開発と応用に参加できる。
分散型演算市場のユースケースでは、シーケンサーは主にAIの直接演算を担当しないかもしれませんが、その主な機能は、トランザクションを処理し、ネットワーク全体のAI演算を調整することです。また、演算とタスクの割り当てに関して、ここには2つのモデルがあります:
トップダウンの集中型割り当て。シーケンサーが利用できるため、シーケンサーは受け取った演算要求を、要求を満たし、より良い評判を持つノードに割り当てることができます。この割り当ては理論的には中央集権的で不公平ですが、実際には効率的な利点がその欠点をはるかに上回り、長期的にはシーケンサーが繁栄するためにはネットワーク全体の肯定性を満たさなければなりません。
ボトムアップの自発的なタスク選択。ユーザーはAI計算リクエストをサードパーティのノードに提出することもできます。これは明らかに、与えられたAIアプリケーション領域のシーケンサーに直接提出するよりも効率的であり、シーケンサーにおける検閲や偏りを防ぐことができます。このノードは、計算が完了した後、結果を同期してシーケンサーにアップリンクします。
L2 + AIアーキテクチャでは、演算マーケットプレイスは非常に柔軟であり、リソースの利用を最大化するために演算を双方向でプールできることがわかります。
現在、オープンソースモデルの成熟度は、多様なニーズを満たすのに十分です。AI推論サービスの標準化により、自動価格決定のためのアップチェーン演算の方法を探求することが可能になりました。しかし、これにはいくつかの技術的な課題を克服する必要があります。
Efficient Request Distribution and Recording:大規模なモデルの推論には高いレイテンシーが要求されます。効率的なリクエスト配布メカニズムが重要です。リクエストとレスポンスのデータ量とプライバシーはブロックチェーン上で公開するには大きすぎますが、ハッシュを保存するなどして、ロギングと検証のバランスを見つけなければなりません。
算術ノード出力の検証:ノードは、そのために策定された算術タスクを実際に実行したのでしょうか?例えば、ノードは大きなモデルを小さなモデルの算術演算の結果で置き換えることを偽って報告します。
スマートコントラクト推論:AIモデルとスマートコントラクトを組み合わせて演算を行うことは、多くのシナリオで必要です。AIの推論は不確実であり、チェーンのあらゆる側面で使用される可能性は低いため、将来のAI dAppsのロジックは、一部はオフチェーンに、一部はオンチェーンコントラクトに配置され、オフチェーンで提供される入力の妥当性と数値的正当性を修飾することになると考えられます。一方、イーサネットのエコシステムでは、スマートコントラクトと組み合わせることで、EVMの非効率的なシリアルな性質に対処しなければならない。
しかしReddioのアーキテクチャでは、これらは比較的簡単に対処できます:
シーケンサーによるリクエストの払い出しは、L1よりもはるかに効率的です。Web2の効率と同等と考えることができる。また、データをどこでどのように記録し、保持するかは、安価なさまざまなDAソリューションで対処できます。
AIの計算結果は、最終的にZKPによってその正しさと善意を検証することができる。そしてZKPは、検証は非常に速いが、証明の生成は遅いという特徴があります。また、ZKPの生成は、GPUやTEEを使用して加速されることもあります。
Solidty→CUDA→GPUの主なEVM並列スレッドは、もともとReddioの基礎でした。そのため、表面的には、これはReddioにとって最も簡単な問題のように見えます。Reddioは現在、AiI6zのelizaと協力して、彼らのモジュールをReddioに導入しようとしています。
全体として、レイヤー2ソリューション、並列EVM、AI技術の分野は無関係に見えるかもしれませんが、ReddioはGPUのコンピューティングの性質を活用することで、これらの革新的な分野を巧みに組み合わせました。
GPUの並列コンピューティングの性質を活用することで、Reddioはレイヤー2でのトランザクション速度と効率を改善し、イーサリアムのレイヤー2でのパフォーマンス強化を可能にしました。AI技術のブロックチェーンへの統合は、さらに斬新で有望な試みです。AIの導入は、オンチェーン・オペレーションにインテリジェントな分析と意思決定のサポートを提供し、よりインテリジェントでダイナミックなブロックチェーンアプリケーションを可能にします。この分野横断的な統合は間違いなく、業界全体の発展に新たな道筋とチャンスを開く。
しかし、この分野はまだ初期段階にあり、まだ多くの研究と探求が必要であることに注意することが重要です。
Reddioはすでにこの交差点で重要かつ大胆な一歩を踏み出しており、今後この統合スペースでさらなるブレークスルーと驚きを目にすることを楽しみにしています。
チェーンの抽象化,人工知能,AI+暗号の組み合わせの可能性 ゴールデンファイナンス,技術的な観点から、チェーンの抽象化は断片化問題を解決できるか?
JinseFinanceミーム市場が暴落に直面しているようで、市場の不安が再び広がっている。その理由は?新たな物語がないこと、そして資金が賢いので優良NFTsのトップに走っていること。
JinseFinance人工知能,Grayscale,Grayscale: 暗号×AIプロジェクトの考察 暗号が分散型AIを実現する方法 Golden Finance,AIの時代が到来、暗号はAIを正しく理解できる
JinseFinanceコンピュート、AIエージェント、コプロセッサーなど、Crypto x AIエコシステムのさまざまなサブパートを探索する。
JinseFinance私はAIと暗号通貨の交差点について多くの時間を費やして研究してきた。この2つの組み合わせは、AIをより公正でユーザー所有のものにするために不可欠だと思います。
JinseFinance暗号AIの分野では、Bittensor、Ritual、Virtual Protocolがそれぞれ異なる分野に深く関わっている。Bittensorは現在、時価総額で暗号AI分野をリードしている。
JinseFinanceこのAI+Cryptoブームは、WorldCoinのコインオファリングに代表される2023年のGPT-4のクロスオーバー以来再燃しており、人類はAIが生産性を、Cryptoが流通を担当するユートピア時代に突入しようとしているようだ。
JinseFinance本稿では、第一次市場の視点から、過去1年間に観察されたAIと暗号技術の新興企業を概観し、起業家たちがどのような角度から市場に切り込み、これまでにどのような成果を上げ、どのような分野がまだ模索されているのかを確認する。
JinseFinanceJinseFinance