さようならBTC こんにちはAI:暗号マイナーはAIに目を向ける
CNBCとのインタビューで、ランシアムのアリ・フェン社長は、これは世界最大級のAIデータセンター・キャンパスになると述べ、AI開発をサポートするための競争がますます熾烈になり、ビットコインが取り残されている事実をさらに裏付けている。
 JinseFinance
JinseFinance

著者:YBBキャピタル・ジーク
2月16日、OpenAIはテキスト制御動画生成のための最新の拡散モデル「Sora」を発表した。2月16日、OpenAIはテキスト制御による動画生成のための最新の拡散モデル「Sora」を発表しました。複数の画像から数秒間の動画を生成するPikaのようなAI動画生成ツールとは異なり、Soraは、動画や画像の圧縮されたポテンシャル空間で学習し、時空間位置パッチに分解することで、スケーラブルな動画生成を可能にする。このモデルはまた、物理世界とデジタル世界の両方をシミュレートする能力を実証しており、その結果、「物理世界のユニバーサル・シミュレーター」と表現できる60秒のデモが実現した。
また、構築方法に関して、Soraは以前のGPTモデルの「ソースデータ-トランスフォーマー-拡散-創発」という技術的な道筋を引き継いでいる。"つまり、その発展の成熟にはエンジンとしての演算も必要であり、動画学習に必要なデータ量はテキスト学習に必要なデータ量よりもはるかに大きいため、演算の需要はさらに高まることになる。しかし、AI時代における算術の重要性については、以前の記事「可能性の軌跡展望:分散型算術市場」でも触れたが、昨今のAI熱の高まりに伴い、算術プロジェクトが市場に多数登場し始めており、受動的にDepinプロジェクトの恩恵を受ける他のDepinプロジェクト(ストレージ、算術など)にも盛り上がりの波が押し寄せている。では、Depinだけでなく、Web3とAIの絡みでどんな火花が散るのか。この路線には、他にどんなチャンスが潜んでいるのだろうか。本記事の主な目的は、これまでの記事を更新・補足し、AI時代のWeb3にどのような可能性があるかを考えることである。
人工知能(AI)は、人間の知能をシミュレートし、拡張し、強化することを目的とした新興の科学技術です。1950年代と1960年代に誕生して以来、半世紀以上の発展を経て、AIは現在、社会生活やあらゆる分野の変化を促す重要な技術となっている。この過程で、象徴主義、接続主義、行動主義という3つの主要な研究方向が絡み合った発展が、今日のAIの急速な発展の礎となっている。
あるいはニューラルネットワーク・アプローチは、人間の脳の構造と機能を模倣することで知性を達成することを目的としています。このアプローチは、多数の単純な処理ユニット(ニューロンに似ている)からなるネットワークを構築し、これらのユニット間の接続(シナプスに似ている)の強さを調整することによって学習を達成する。コネクショニズムは、データから学習し汎化する能力を特に重視し、パターン認識、分類、連続入出力マッピング問題に特に適している。ディープラーニングはコネクショニズムの発展形として、画像認識、音声認識、自然言語処理などの分野で画期的な進歩を遂げた。
これら3つの研究の方向性には本質的な違いがあるものの、実用的なAI研究やアプリケーションにおいて、AI分野を発展させるために相互作用し、融合することも可能です。
現段階で爆発的な広がりを見せている人工知能生成コンテンツ(AIGC)は、コネクショニズムの進化と応用であり、AIGCは人間の創造性を模倣した斬新なコンテンツを生成することができます。これらのモデルは、大規模なデータセットとディープラーニング・アルゴリズムを用いて訓練され、データに存在する基本的な構造、関係、パターンを学習する。画像、動画、コード、音楽、デザイン、翻訳、質問への回答、テキストなど、ユーザーの入力プロンプトに基づいて、斬新でユニークな出力が生成される。そして現在のAIGCは基本的に、ディープラーニング(深層学習、DL)、ビッグデータ、大規模演算という3つの要素で構成されている。
ディープラーニングは機械学習(ML)の一分野であり、ディープラーニング・アルゴリズムは人間の脳をモデルにしたニューラルネットワークである。例えば、人間の脳には何百万もの相互接続されたニューロンがあり、それらが連携して情報を学習・処理している。同様に、ディープラーニング・ニューラルネットワーク(または人工ニューラルネットワーク)は、コンピューター内部で協働する人工ニューロンの複数の層で構成されている。人工ニューロンはノードと呼ばれるソフトウェア・モジュールで、数学的計算を使ってデータを処理する。人工ニューラルネットワークは、これらのノードを使用して複雑な問題を解決する深層学習アルゴリズムである。
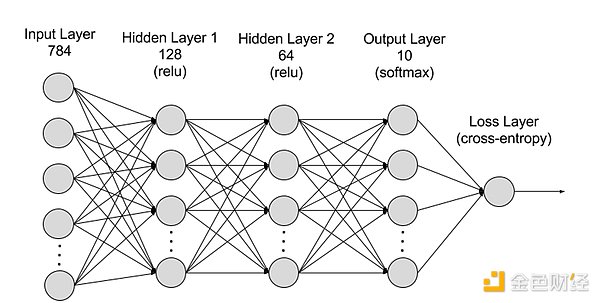
階層的にニューラルネットワークは入力層、隠れ層、出力層に分けることができ、異なる層間の接続がパラメータとなる。
入力層: 入力層はネットワークの入力に使われる層です。strong>:入力層はニューラルネットワークの最初の層で、外部入力データを受け取る役割を果たします。入力層の各ニューロンは入力データの特徴に対応する。例えば、画像データを処理する場合、各ニューロンは画像のピクセル値に対応します。
隠れ層: 入力層はデータを処理し、ニューラルネットワークのさらに下の層にデータを渡します。これらの隠れ層は異なる層の情報を処理し、新しい情報を受け取るとその振る舞いを適応させる。ディープ・ラーニング・ネットワークは何百もの隠れ層を持っており、様々な角度から問題を分析することができる。例えば、分類すべき未知の動物の画像が与えられたら、すでに知っている動物と比較する。例えば、耳の形、足の本数、瞳孔の大きさなどから、どんな動物かを判断する。ディープ・ニューラル・ネットワークの隠れ層も同じように機能する。ディープラーニング・アルゴリズムが動物の画像を分類しようとしている場合、隠れ層のそれぞれが動物の異なる特徴を処理し、正確に分類しようとします。strong>出力層: 出力層はニューラルネットワークの最後の層で、ネットワークの出力を生成します。出力層の各ニューロンは、可能な出力カテゴリまたは値を表します。例えば、分類問題では、各出力層のニューロンはカテゴリに対応するかもしれないが、回帰問題では、値が予測値を表す出力層のニューロンは1つだけかもしれない。
パラメータ: ニューラルネットワークでは、異なる層間の接続はWeightsとBiasパラメータによって表されます。パラメータを増やすと、ニューラルネットワークのモデルキャパシティ、つまりデータ内の複雑なパターンを学習し、表現するモデルの能力が向上する。しかし、対応するパラメーターの増加は、コンピューティングパワーの需要を増加させます。="font-size: 18px;">効果的なトレーニングのために、ニューラルネットワークは通常、複数のソースからの大規模で多様かつ高品質なデータを必要とします。これは機械学習モデルのトレーニングと検証の基礎となる。ビッグデータを分析することで、機械学習モデルはデータのパターンと関係を学習し、予測や分類を行うことができる。
膨大な演算能力
ニューラルネットワークの多層複雑構造、多数のパラメーター、大規模なデータ処理要件、反復学習法(学習段階では、モデルを繰り返し反復する必要があり、学習プロセスでは、活性化関数の計算、損失関数の計算、勾配の計算、重みの更新を含む、各層の計算の順伝播と逆伝播が必要)、高精度計算の必要性、並列計算の能力、以下の必要性最適化および正則化技術の必要性、モデルの評価および検証プロセスなどを総合して、高い計算能力を必要とします。

OpenAIのビデオ生成AIモデルの最新リリースであるSoraは、多様なビジュアルデータを処理し理解するAIの能力の大きな進歩を表しています。ビデオ圧縮ネットワークと空間的時間的パッチ技術を採用することで、Soraは、世界中から異なるデバイスでキャプチャされた大量のビジュアルデータを統一された表現に変換することができ、複雑なビジュアルコンテンツの効率的な処理と理解を可能にします。テキスト条件付けの拡散モデルに基づき、Soraはテキストを手がかりに高度にマッチした動画や画像を生成することができ、高い創造性と適応性を発揮します。
しかし、ビデオ生成や実世界でのインタラクションのシミュレーションにおけるブレークスルーにもかかわらず、Soraは、物理世界のシミュレーションの精度、長時間のビデオ生成の一貫性、複雑なテキスト指示の理解など、多くの制限に直面しています。複雑なテキスト指示の理解、トレーニングや生成の効率などである。そして、そらはまだ本質的にOpenAIの独占コンピューティングパワーと先行者利益を介して、暴力的な美学を達成するために、この古い技術のパスの "ビッグデータ - トランスフォーマー - 拡散 - 出現 "の継続は、他のAI企業はまだ可能な車を追い抜くために道路を曲げる技術を通じて存在しています。
そらはブロックチェーンとはあまり関係がありませんが、個人的には来年か再来年にはそうなると思います。というのも、Soraの影響で他の高品質なAI生成ツールがどんどん登場・発展し、Web3の中でもGameFi、ソーシャル、クリエイションプラットフォーム、Depinなど複数のトラックに放射状に広がっていくでしょうから、Soraの全体像を把握しておく必要がありますし、今後のAIがWeb3とどのように効果的に組み合わされていくのかは、考えておくべきポイントかもしれません。
AI×Web3の4つの道
以上のように、生成的AIに必要な基盤は、実はアルゴリズム、データ、演算の3点だけであることがわかる。一方、ユビキタス性と生成的効果の観点から見ると、AIは生産様式を破壊するツールである。 そしてブロックチェーンの最大の役割は、生産関係の再構成と分散化の2点である。
Decentralised arithmetic
関連記事は過去に書かれているので、この段落の主な目的は、算術トラックにおける最近の動向をアップデートすることです。AIに関して言えば、算数は常に難しい分野である。AIの算数に対する要求は、ソラの誕生以来、想像を絶するものだった。そして最近、スイスのダボスで開催された2024年世界経済フォーラムで、オープンAIのサム・アルトマンCEOは、現段階では算術とエネルギーが最大の足かせであり、将来的には両者の重要性は通貨に匹敵するとまで露骨に発言した。そして続く2月10日、サム・アルトマンはツイートで、7兆米ドル(中国の国家GDPの23年分に相当する40%)を融資し、半導体産業の現在の世界的なパターンを塗り替える、チップ帝国の創造という極めて驚くべき計画を発表した。コンピューティングパワーに関連する記事を書く際に、私の想像力はまだ国家封鎖、巨大な独占に限定され、今の会社は、世界の半導体産業を支配したい本当にまだ非常にクレイジーです。
だから、分散コンピューティングパワーの重要性は自明であり、ブロックチェーンの特性は、実際にコンピューティングパワーの現在の独占の問題を解決することができますだけでなく、専用のGPUの購入の問題は高価です。AIのニーズの観点から、演算の使用は2つの方向に分けることができます:推論と訓練、主な訓練プロジェクトは、まだ非常に少数のプロジェクトがあり、分散型ネットワークからニューラルネットワークの設計と組み合わせる必要があり、その後、ハードウェアの超高需要のために、それは一種の方向に着陸するのは非常に高く、困難のしきい値になる運命にある。推論は比較的単純で、一方では、分散型ネットワークの設計では複雑ではありませんが、第二は、ハードウェアと帯域幅の要件が低いですが、現在より主流の方向です。
集中型演算市場の想像空間は巨大で、しばしば「兆」というキーワードと結びつき、またAIの時代に最も頻繁に推測される。AIの時代において、最も推測されやすいテーマである。しかし、最近、多くのプロジェクトが出現していることからすると、その大半はまだ、棚ぼたのカモに属し、熱をさましている。常に分散化の正しい旗印を掲げるが、分散型ネットワークの非効率性については語らない。そして、設計の同質性の高度があり、多数のプロジェクトは、最終的に鶏の羽につながる可能性があり、非常によく似ている(1キーL2プラスマイニング設計)、そのような状況は、従来のAIトラックの一部を取得したい本当に難しいです。
機械学習アルゴリズムとは、データから法則やパターンを学習し、それに従って予測や決定を行うことができるアルゴリズムのことです。アルゴリズムの設計と最適化には、深い専門知識と技術革新が必要であるため、アルゴリズムは技術集約的である。アルゴリズムはAIモデルのトレーニングの中核であり、データを有用な洞察や意思決定に変換する方法を定義する。Generative Adversarial Networks (GAN)、Variational Auto-Encoders (VAE)、Transformers などの一般的な生成 AI アルゴリズムは、それぞれ特定のドメイン (描画、言語認識、翻訳、動画生成など) や目的に合わせて作成され、専用の AI モデルの学習に使用されます。
それでは、これほど多くのアルゴリズムやモデルがあり、そのすべてに長所と短所がある中で、テキストとテキストの両方に使える単一のモデルに統合することはできるのでしょうか?Bittensorはこの方向性をリードする企業であり、異なるAIモデルやアルゴリズムがマイニングのインセンティブを通じて互いに協力し、学習することで、より効率的で汎用性の高いAIモデルを生み出すことを可能にしている。Commune AI(コード・コラボレーション)もこの方向性のリーダーだが、アルゴリズムとモデルは昨今のAI企業の合言葉であり、自由に貸し出されるものではない。
つまり、AIコラボレーション・エコシステムという物語は非常に斬新で興味深いものであり、コラボレーション・エコシステムはブロックチェーンを活用してサイロ化されたAIアルゴリズムの欠点を統合するものだが、それに対応する価値を生み出せるかどうかはまだわかっていない。はまだわからない。結局のところ、AI企業のクローズドソースのアルゴリズムとモデルの頭は、更新の反復と統合は非常に強力な能力は、例えば、OpenAIの開発の2年未満は、モデルのマルチドメイン生成に初期のテキスト生成モデルから反復されている、Bittensorとフィールドをターゲットにしたモデルとアルゴリズムの他のプロジェクトでは、別のアプローチを取ることかもしれません。
単純な観点から言えば、AIにデータを供給するためにプライベートデータを使用することや、タグ付けされたデータは、ブロックチェーンによく適合する方向性であり、スパムやいたずらを防ぐ方法に注意を払うだけでよく、FILやARなどのDepinプロジェクトにも利益をもたらすことができるデータストレージである。また、複雑さという点では、ブロックチェーンのデータを機械学習(ML)に利用し、それによってブロックチェーンのデータアクセシビリティに対処することも興味深い方向性である(ギザのマッピングの方向性の1つ)。
理論的には、ブロックチェーンのデータはいつでもアクセス可能で、ブロックチェーン全体の状態を反映します。しかし、ブロックチェーンエコシステムの外部の人間にとって、こうした膨大なデータへのアクセスは容易ではない。ブロックチェーンを丸ごと保存するには、広範な専門知識と多くの専用ハードウェア・リソースが必要だ。ブロックチェーン・データへのアクセスの課題を克服するため、業界ではいくつかのソリューションが登場している。例えば、RPCプロバイダーはAPIを通じてノードにアクセスし、インデックスサービスはSQLやGraphQLを通じてデータ抽出を可能にし、いずれも問題解決に重要な役割を果たしている。しかし、これらのアプローチには限界があります。RPCサービスは、大量のデータクエリを必要とする高密度な利用シナリオには適しておらず、しばしば需要を満たすことができません。一方、インデックス・サービスは、より構造化されたデータ検索の方法を提供しますが、Web3プロトコルの複雑さにより、効率的なクエリを構築することは非常に難しく、時には数百行から数千行の複雑なコードを必要とします。この複雑さは、平均的なデータ実務者やWeb3の詳細についてあまり知識のない人にとっては大きな障害となる。このような制限の積み重ねが、この分野でのより幅広い採用とイノベーションを促進できるような、ブロックチェーンデータへの簡単なアクセスと活用方法の必要性を浮き彫りにしています。
それなら、ZKML(Zero-Knowledge Proof Machine Learning、チェーン上の機械学習の負担を減らす)を通して高品質のブロックチェーンデータを組み合わせれば、ブロックチェーンのアクセシビリティに対応したデータセットを作成できるかもしれません。
そして、AIがブロックチェーンのデータアクセシビリティの障壁を劇的に下げることができる一方で、ML分野の開発者、研究者、熱狂的なファンは、時間の経過とともに、効果的で革新的なソリューションを構築するために使用できる、より高品質で関連性の高いデータセットにアクセスできるようになるでしょう。
AI対応Dappsは、ChatGPT3が炎上した23年以降、ごく一般的な方向性になっています。非常に汎用性の高いジェネレーティブAIは、APIを通じてアクセスできるため、データプラットフォーム、取引ボット、ブロックチェーン百科事典などのアプリケーションを簡素化し、インテリジェントに分析することができる。一方、チャットボット(Myshellなど)やAIコンパニオン(Sleepless AI)の役割を果たすこともでき、生成AIによってチェーンツアーのNPCを作成することもできる。 しかし、技術的な障壁が低いため、APIにアクセスした後に微調整するものがほとんどであり、プロジェクト自体との組み合わせも完全ではないため、あまり言及されることはない。
しかし、そらの登場以降、個人的にはAIを活用したGameFi(メタユニバースを含む)やクリエイションプラットフォームの方向性が次に注目されるのではないかと考えています。Web3の領域はボトムアップ型であるため、従来のゲーム会社やクリエイティブ会社に対抗できるものを作るのが難しいのは間違いなく、Soraの登場はこのジレンマを打破することになりそうだ(わずか2~3年後かもしれないが)。Soraのデモは、マイクロスケッチ企業と競合する可能性があることを示しているし、Web3の活気あるコミュニティ文化は、多くの面白いアイデアを生み出すことができる。唯一の制限条件が想像力であるとき、ボトムアップ産業とトップダウン産業の垣根は取り払われるだろう。: 18px;">ジェネレーティブAIツールが進歩し続けるにつれて、私たちは今後、より多くのエポックな「iPhoneの瞬間」を経験することになるだろう。AIとWeb3の組み合わせを嘲笑する人も多いが、実は私は現在の方向性はほぼ問題ないと考えている。解決すべきペインポイントは、必要性、効率性、フィット感の3つだけだ。この2つの統合は、まだ試行錯誤の段階だが、この路線が次の強気市場の主流になることを妨げるものではない。
私たちは十分な好奇心を維持し、新しいものを受け入れる必要があります必要な考え方であり、歴史、瞬時にシフトの馬車を置き換えるために車が当然の結論となっているだけでなく、碑文とNFTの過去。過去の碑文やNFTと同様、偏りすぎるとチャンスを逃すことになる。
CNBCとのインタビューで、ランシアムのアリ・フェン社長は、これは世界最大級のAIデータセンター・キャンパスになると述べ、AI開発をサポートするための競争がますます熾烈になり、ビットコインが取り残されている事実をさらに裏付けている。
JinseFinanceミスAIは、AIモデルとAIが生成した審査員による初の美人コンテストとして先月デビューしたばかりだ。現在、トップ10の候補者が発表されているが、私たちはAIを推し進めすぎて、社会の美の基準を歪めているのだろうか?
 Kikyo
Kikyo3EXのAI取引プラットフォームは、虎のようにAIトラックを活用し、このテクノロジーと富の革命の最初のチャンスをつかむことができます!
JinseFinanceSoraはOpenAIが開発したAIモデルで、ユーザーが入力したテキストコマンドに基づいて、リアルで想像力豊かなビデオシーンを生成する。
JinseFinanceAI熱狂後のハイテク株急落、AIの財務的実現性に疑問。GenAIの収益遅れが疑念を招き、ハイテク業界の変革を示唆。
 Xu Lin
Xu LinCoinSmart Miningはこの度、42番目のプロジェクトとして、Web3+AIゲームプラットフォーム「Sleepless AI(AI)」を立ち上げました。
JinseFinanceJinseFinanceAIとWeb3は産業を再構築する可能性を秘めている。しかし、データのプライバシー、相互運用性、倫理的なAIの利用といった課題は、これらの技術が融合する中で解決されなければならない。
 Catherine
Catherine近年、AI (人工知能) は、最も興味深く、急速に拡大している技術物語の 1 つとして浮上しています。
 Bitcoinist
BitcoinistAndre Cronje 氏によると、ブロックチェーンと AI は根本的な原則が異なり、単一のシステムに統合することは困難です。
 Beincrypto
Beincrypto