Dogizen価格予測:初のTelegram ICOは爆発的な可能性を示す
<nil>
 Weiliang
Weiliang

Compiled by Jiayu, Cage
AIエージェントは我々が注視しているパラダイムシフトであり、一連のLangchainの記事はエージェントのトレンドを理解するのに役立つ。のトレンドを理解するのに役立ちます。今回のまとめでは、第一弾としてLangchainチームが発表した「State of AI Agent」レポートを紹介する。開発者、プロダクトマネージャー、企業幹部など1,300人以上の実務者にインタビューを行い、今年のAgentの現状と着地のボトルネックを明らかにした。90%の企業がAI Agentの計画とニーズを持っているが、Agentの機能の限界により、ユーザーは一部のプロセスやシナリオにしか着地できない。コストや待ち時間に比べ、人々はAgentの能力の強化や、Agentの振る舞いの観察可能性や制御可能性をより重視しています。
第2部では、LangChainのウェブサイトの記事シリーズ「In the Loop」の中で、AIエージェントの重要な要素である計画能力、UI/UXインタラクションの革新、記憶メカニズムの分析をまとめました。この記事では、5つのLLMネイティブ製品のインタラクションを分析し、AIエージェントを理解し、これらの重要な要素を理解する上でインスピレーションとなる、人間の3つの複雑な記憶メカニズムを類推しています。このセクションでは、Reflection AIの創設者へのインタビューなど、代表的なエージェント企業のケーススタディも掲載し、2025年のAIエージェントの重要なブレークスルーを展望しています。
この分析フレームワークでは、2025年にAIエージェントのアプリケーションが出現し始め、人間とコンピュータのコラボレーションの新しいパラダイムに移行すると予想しています。AIエージェントのプランニング能力については、o3を筆頭とするモデルが強い内省能力と推論能力を発揮しており、モデル企業の進歩は推論者からエージェントの段階に近づきつつある。推論能力の向上が進めば、Agentの「最後の1キロメートル」は、製品とのインタラクションや記憶メカニズムになり、スタートアップ企業にとってブレークスルーのチャンスとなる可能性が高くなる。インタラクションに関しては、AI時代の「GUIの瞬間」を待ち望んでいる。記憶に関しては、「コンテキスト」がAgentの着地のキーワードになると信じており、個人レベルでのコンテキストのパーソナライズ化、企業レベルでのコンテキストの統一化が、Agentの製品体験を大きく向上させるだろう。
01. エージェント利用の傾向:
どの企業もエージェントの導入を計画している
どの企業もエージェントの導入を計画している。エージェントの導入を計画している
エージェントのスペースは競争が激しくなっています。たとえば、推論とアクションにLLMと組み合わせたReActを使用したり、オーケストレーションにマルチエージェント・フレームワークを使用したり、LangGraphのようなより制御されたフレームワークを使用したりしています。
エージェントの議論は、Twitter上の誇大広告ばかりではありません。Langchainの企業規模別データによると、従業員数100~2,000人の中規模企業が最も積極的にAgentを本番稼動させており、その割合は63%でした。
さらに、回答者の78パーセントが、近い将来にAgentを本番環境に導入する計画を持っています。AIエージェントに強い関心があることは明らかですが、実際に生産可能なエージェントを正しく導入することは、多くの人にとってまだ課題です。
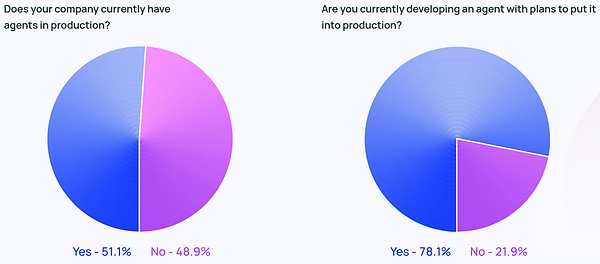
ハイテク業界は、エージェントユーザーの早期採用者と見なされることが多いのですが、エージェントへの関心はまだ高いようです。エージェントへの関心は、あらゆる業界で高まっています。非テクノロジー企業で働く回答者の90%は、すでにAgentを本番稼動させているか、その予定があります(テクノロジー企業とほぼ同じ89%)。
エージェントの一般的なユースケース
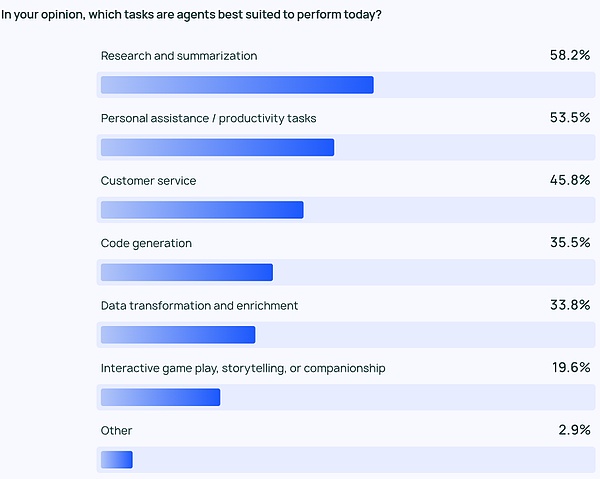
エージェントの最も一般的なユースケースは、調査や要約を行うこと(58%)、次いでカスタマイズされたエージェントでワークフローを合理化すること(58%)です。ワークフローを合理化するためにカスタマイズされたエージェント(53.5%)。
これらは、時間がかかりすぎるタスクを処理してくれる製品への要望を反映しています。ユーザーは、膨大な量のデータに自分で目を通し、プロフィールのレビューや調査分析を行うのではなく、大量の情報から重要な情報や洞察を抽出してくれるAIエージェントに頼ることができます。同様に、AIエージェントは日々のタスクを支援することで個人の生産性を向上させ、ユーザーは重要なことに集中することができます。
このような効率アップを必要としているのは個人だけでなく、企業やチームも同様です。カスタマーサービス(45.8%)は、企業が問い合わせを処理し、問題をトラブルシューティングし、チーム全体の顧客対応時間を短縮するのに役立つエージェントのもう1つの主要なアプリケーションです。4位と5位は、より低レベルのコードとデータのアプリケーションです。
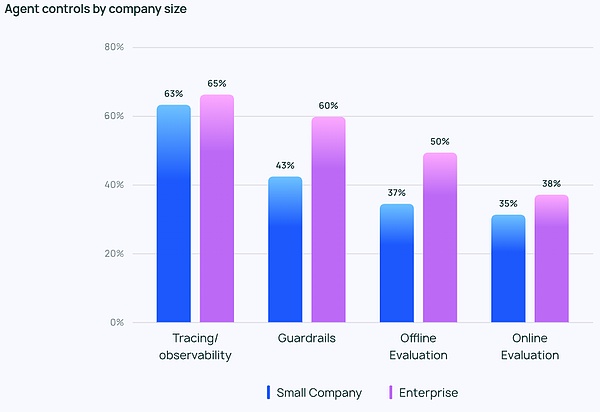
モニタリング:エージェントアプリケーションには観測性と制御性が必要です
エージェントの実装がより強力になるにつれ、エージェントを管理・監視する方法が必要となります。開発者がエージェントの動作とパフォーマンスを理解するのを助けるために、トレースと観測可能なツールは、必需品リストの最上位にあります。また、多くの企業はエージェントが軌道から外れないようにガードレールを使用しています。
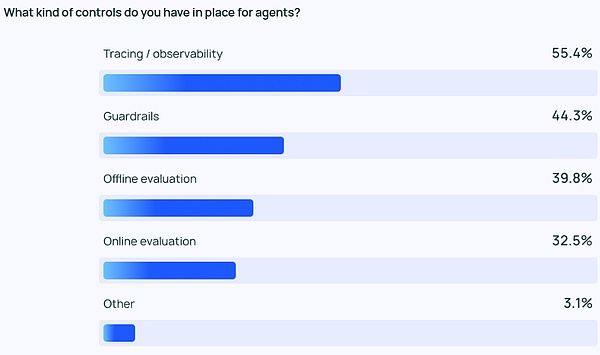
LLMアプリをテストする際、オフライン評価(39.8%)がオンライン評価(32.5%)よりも頻繁に使用されており、これはLLMをリアルタイムでモニタリングすることの難しさを反映している。LangChainが提供した自由形式の回答では、多くの企業が、さらなる防止策として、人間の専門家が手作業で回答をチェックまたは評価しています。
熱心さとは裏腹に、エージェントの権限に関しては一般的に保守的です。エージェントに読み取り、書き込み、削除を自由に許可している回答者はほとんどいません。その代わりに、ほとんどのチームは、ツールのパーミッションに対して読み取りアクセスのみを許可するか、書き込みや削除のような、よりリスクの高いアクションをエージェントが行うには人間の承認が必要です。
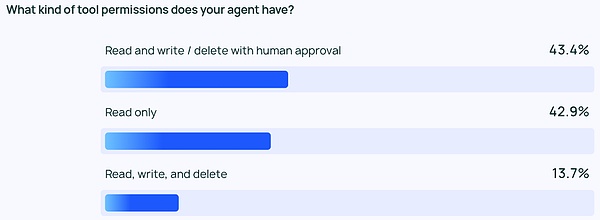
企業規模が異なれば、エージェント管理の優先順位も異なります。また、優先順位も異なります。当然のことながら、大規模な組織(従業員数2,000人以上)はより慎重で、不必要なリスクを避けるために「読み取り専用」のパーミッションに大きく依存しています。また、ガードレール保護とオフライン評価を組み合わせる傾向があり、顧客に問題を見せたがりません。
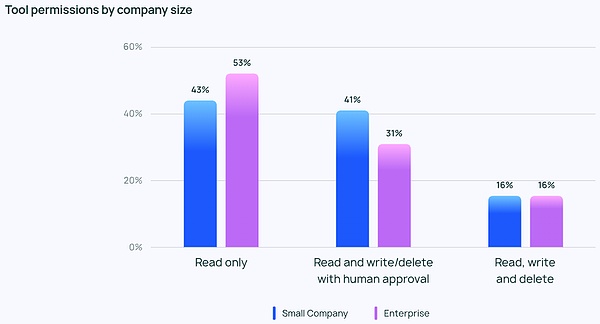
一方、小規模な企業や新興企業(従業員数100人未満)は、より多くの問題を追跡することに重点を置いています。従業員数100人未満)は、(他のコントロールよりも)Agentアプリケーションで何が起きているかを理解するためのトラッキングに重点を置いています。LangChainの調査データによると、小規模な企業は、結果を理解するためにデータを見ることに重点を置く傾向があり、大規模な組織では、全体的により多くの管理が行われています。
エージェントを導入する障害と課題
LLM sのために高品質のパフォーマンスを保証することは難しく、回答は非常に正確で正しいスタイルである必要があります。これはエージェント開発者とユーザーにとって大きな関心事であり、コストやセキュリティといった他の要因の2倍以上重要です。
LLMエージェントは確率的なコンテンツ出力であり、より予測不可能であることを意味します。そのため、エラーの可能性が高くなり、チームはエージェントが一貫して正確で文脈に沿った応答を提供できるようにすることが難しくなります。
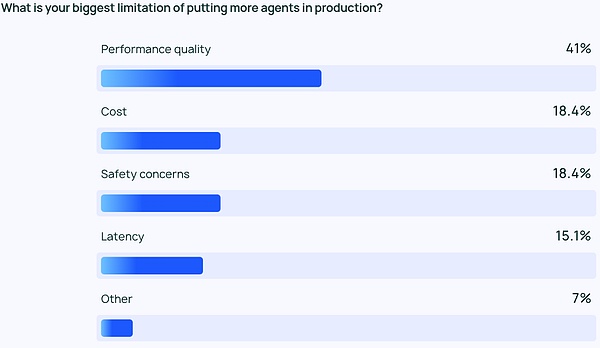
これは特に中小企業に当てはまり、パフォーマンスの質は他の検討事項よりもはるかに高く、ユーザーの45パーセントがパフォーマンスに満足しています。のユーザーがパフォーマンスに満足しているのに対し、45.8%のユーザーは他の考慮事項よりもパフォーマンスを重視しており、コスト(2番目に重要な懸念事項)はわずか22.4%であった。このギャップは、エージェントを開発から本番へと移行させる組織にとって、信頼性が高く高品質なパフォーマンスが重要であることを強調しています。
厳格なコンプライアンスを必要とし、顧客データを繊細に扱う大企業では、セキュリティに関する懸念も広がっています。
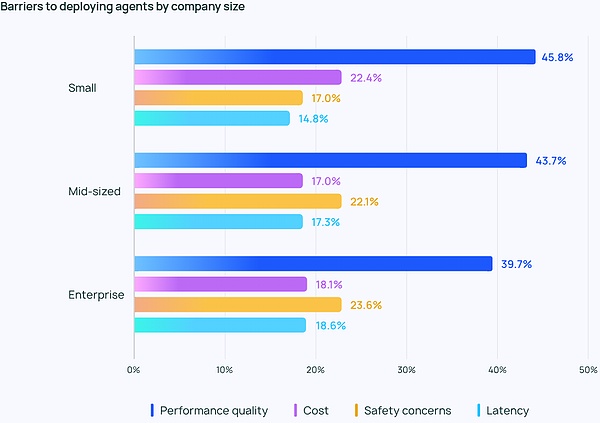
課題は品質にとどまりません。LangChainが提供した自由形式の回答では、企業が継続的にエージェントの開発やテストに投資したいかどうかについては、多くの人が懐疑的な姿勢を崩していません。エージェントを開発するために必要な知識は広範囲に及び、常に最先端の技術を維持する必要があること、そしてエージェントを開発し展開するために必要な時間はコストがかかり、信頼性の高い運用のための利点が不確かであることです。
その他の新たなテーマ
自由形式の質問では、これらの能力を示すAIエージェントを称賛する声が多く聞かれました:
- Managing multi-step tasks: AI Agentがより深い推論とコンテキスト管理を行う能力によって、より複雑なタスクを処理することができます。
- Automating repetitive tasks.
- Automating repetitive tasks: AIエージェントは、自動化されたタスクを処理する鍵であると引き続き考えられています。
- Human-like reasoning(人間のような推論): 従来のLLMとは異なり、AIエージェントは、新しい情報に照らして過去の決定を見直し、修正するなど、遡及的に決定を下すことができます。過去の決定を思い出し、修正する。
さらに、最も期待されている2つの発展があります:
- Exppectations for open-source AI Agents: オープンソースのAIエージェントに明確な関心があり、多くの人がエージェントを加速させる方法として集合知を挙げています。
- Expectations for more powerful models: 多くの人が、より大きく、より強力なモデルによって駆動されるAIエージェントの次の飛躍を期待しています。
AIエージェントの次の飛躍:多くの人が、より大きく、より強力なモデルによって駆動されるAIエージェントの次の飛躍を期待しています。
Q&Aでは、エージェント開発における最大の課題である「エージェントの行動を理解する方法」についても多くの人が言及していました。エンジニアの中には、会社の利害関係者にAIエージェントの能力や動作を説明するのが難しいという人もいました。視覚的なプラグインがAgentの動作を説明するのに役立つ場合もありますが、多くの場合LLMはブラックボックスのままです。解釈可能性という付加的な負担は、エンジニアリング・チームに委ねられているのです。
02.AIエージェントのコア要素
エージェントシステムとは?システム
「AIエージェントの現状」レポートが発表される前に、Langchainチームはすでにエージェント領域で独自のLangraphフレームワークを書いていました。以下は、そこから主要な要素をまとめたものです。
まず第一に、AIエージェントの定義は人によって少し異なりますが、LangChainの創設者であるHarrison Chaseは以下のように定義しています:
AIエージェントは、LLMを使ってプログラムを制御するメカニズムです。LLMはプログラムに関する制御フローの決定を行う。
AIエージェントとは、LLMを使ってアプリケーションの制御フローを決定するシステムのことである。
この記事では、その実装のために、エージェントがどのように考え、システムがどのようにLLMをコード化/プロンプト化するのかを指す、コグニティブ・アーキテクチャの概念を紹介しています:
コグニティブ:エージェントはLLMを使用します。-
- アーキテクチャ:これらのエージェントシステムは、従来のシステムと同様に、依然として多くのアーキテクチャを含んでいます。
次の図は、さまざまなレベルのコグニティブ・アーキテクチャの例を示しています。
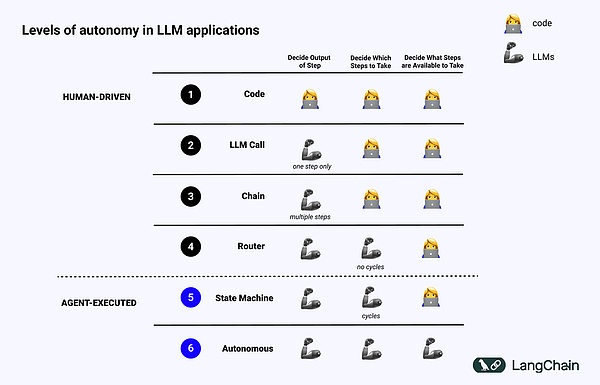
- Standardised software code(標準化されたソフトウェアコード):すべてがハードコードで、出力または入力に関連するパラメータはソースコードに直接固定されています。
- LLM コール、いくつかのデータ前処理に加えて、単一のLLMコールがアプリケーションの大部分を構成します。style="text-align: "left;">- チェーン:一連のLLM呼び出し、チェーンはいくつかのステップに問題を解決しようとし、問題を解決するために異なるLLMを呼び出します。
- Router: 前の3つのシステムでは、ユーザはプログラムが取るすべてのステップを事前に知ることができるが、Routerでは、LLMは、プログラムが取るすべてのステップを事前に知ることができる。
- State Machine (ステートマシン): LLMとルータを組み合わせたもの。
- State Machine(ステートマシン):LLMとRouter(ルーター)を組み合わせたもの。ステートマシンを使用する場合、どのようなアクションを取ることができ、そのアクションの後にどのような処理を実行することができるかについて、まだ制限がありますが、自律エージェントを使用する場合、これらの制限はなくなります。これは、異なるプロンプト、ツール、またはコードを使用することによって行うことができます。
簡単に言えば、システムが「エージェント的」であればあるほど、LLMはシステムがどのように振る舞うかを決定します。
エージェントの主な要素
計画
Agentic
LLMは、システムがどのように振る舞うかを決定します。align: left;">エージェントの信頼性は大きな痛手です。LLMを使用してエージェントを構築した企業は、エージェントがうまく計画や推論ができないと言及することがよくあります。ここでいう計画と推論とはどういう意味でしょうか?
エージェントの計画と推論とは、LLMがどのような行動を取るべきかを考える能力のことです。これは短期的な推論と長期的な推論の両方を含み、LLMは利用可能なすべての情報を評価し、次のように決定します:私はどのような一連のステップを取る必要があり、今取るべき最初のステップはどれですか?
多くの場合、開発者は関数呼び出しを使って、LLMが実行するアクションを選択できるようにします。関数呼び出しは、2023年6月にOpenAIによって初めてLLM apiに追加された機能で、これを通してユーザーは異なる関数のJSON構造を提供し、LLMにそれらの構造の1つ(または複数)にマッチさせることができます。
複雑なタスクを成功裏に完了させるために、システムは一連の行動を順番に取る必要があります。この長期的な計画と推論はLLMにとって非常に複雑です。第一に、LLMは長期的な行動計画を検討した後、取るべき短期的な行動に戻らなければなりません。第二に、エージェントがより多くの行動を実行するにつれて、行動の結果がLLMにフィードバックされ、その結果コンテキストウィンドウが大きくなり、LLMが "注意散漫 "になってパフォーマンスが低下する可能性があります。LLMは「注意散漫」になり、パフォーマンスが低下します。
プランニングを改善する最も簡単な解決策は、LLMが推論/プランニングを適切に行うために必要なすべての情報を確保することです。これは単純に聞こえますが、LLMに渡される情報は、LLMが理にかなった決断を下すには十分でないことが多く、検索ステップを追加するか、プロンプトを明確にすることが簡単な改善策になります。
その後、アプリの認知アーキテクチャを変更することを検討してください。
1.一般的な認知アーキテクチャ
一般的な認知アーキテクチャは、任意のタスクに適用できます。どんなタスクにも適用できます。ここでは、2つの論文で2つの一般的なアーキテクチャを提案しています。1つは、「Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models」における「Plan and Solve」アーキテクチャです。これは、エージェントがまず計画を提案し、その計画の各ステップを実行するというものである。もう一つの一般的なアーキテクチャは、Reflexion: Language Agents with Verbal Reinforcement Learningで提案されているReflexionアーキテクチャである。このアーキテクチャでは、エージェントはタスクを実行し、タスクを正しく実行したかどうかを振り返るために、タスクを実行した後に明示的な "振り返り "のステップがあります。ここでは詳細は省きますが、詳細は最後の2つの論文を参照してください。
これらのアイデアは改善を示していますが、本番でエージェントが実際に使用するには一般的すぎることがよくあります。(
2.ドメイン固有の認知アーキテクチャ
その代わりに、エージェントはドメイン固有の認知アーキテクチャを使用して構築されることがわかります。ドメイン固有の認知アーキテクチャ。これは多くの場合、ドメイン固有の分類/計画ステップ、ドメイン固有の検証ステップに現れます。プランニングとリフレクションのアイデアのいくつかはここで適用できますが、通常はドメイン固有の方法で適用されます。
この特別な例は、AlphaCodiumによる論文で示されています:最先端のパフォーマンスは、彼らが「フローエンジニアリング」(認知アーキテクチャについての別の言い方)と呼ぶものを使用することによって達成されました。
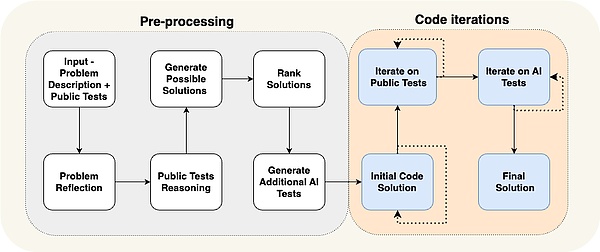
エージェントのフローは、解決しようとしている問題に非常に特化していることがわかります。解決しようとしている問題に特化していることがわかります。テストを思いつき、解決策を思いつき、さらにテストを繰り返す、といった具合です。この認知アーキテクチャは非常にドメイン固有であり、他のドメインに一般化することはできません。
ケーススタディ:
リフレクションAIの創始者 Laskin氏 エージェントの未来に対するビジョン
セコイア・キャピタルのReflection AI創業者ミーシャ・ラスキン氏へのインタビューの中で、ミーシャ氏は自身のビジョンを実現し始めていると述べている:それは、RLの検索機能とLLMを組み合わせることで、彼の新会社Reflection AIで最高のエージェント・モデルを構築することだ。彼と共同設立者のIoannis Antonoglou氏(AlphaGo、AlphaZero、Gemini RLHFの責任者)は、エージェント型ワークフロー用に設計されたモデルをトレーニングしています。
深さはAIの開発において最も重要な要素です。- 深さはAIエージェントに欠けているピースです。
- 学習と探索の組み合わせが、超人的なパフォーマンスを達成する鍵です。
-学習と探索の組み合わせが、超人的なパフォーマンスを達成する鍵である。
-事後学習と報酬のモデル化は、重要な課題を提起します。 明示的な報酬があるゲームとは異なり、実世界のタスクには実際の報酬がないことがよくあります。信頼できる報酬モデルを開発することは、信頼できるAIエージェントを作成する上で重要な課題です
- 普遍的なエージェントは、私たちが考えているよりも近いかもしれません。ラスキン氏は、「デジタルAGI」、つまり、広さと深さを併せ持つAIシステムまで、あと3年しかないのではないかと見積もっています。
- Universal Agentへの道にはアプローチが必要です。 Reflection AI は、ブラウザ、コーディング、コンピュータのオペレーティング システムなどの特定の環境から始めて、エージェントの機能を拡張することに重点を置いています。彼らの目標は、特定のタスクに限定されないユニバーサルエージェントを開発することです。
UI/UXインタラクション
人間とコンピュータのインタラクションは、今後数年間の重要な研究分野となるでしょう。エージェントシステムは、待ち時間や利用不可能性、他の人とインタラクションできる必要性から、これまでの伝統的なコンピュータシステムとは異なります。エージェントシステムが過去の伝統的なコンピュータシステムとは異なるのは、待ち時間、信頼性の低さ、自然言語インターフェイスが新たな課題となっているためです。その結果、これらのエージェントアプリケーションと対話するための新しいUI/UXパラダイムが出現するでしょう。エージェントシステムはまだ初期段階にありますが、すでにさまざまなUXパラダイムが出現しています。
1.チャットUI
チャットは一般的に、ストリーミング・チャット、nストリーミング・チャット、nストリーミング・チャットの2つのカテゴリに分けられます。
チャットには一般的にストリーミングチャットと非ストリーミングチャットの2種類があります。
ストリーミングチャットは、圧倒的に最も一般的なUXです。これは、チャット形式で自分の考えや行動をストリームバックするチャットボットで、ChatGPTが最も人気のある例です。このインタラクション・モードはシンプルに見えますが、次のような理由でうまく機能します。1つは、自然言語を使ってLLMと会話することが可能で、クライアントとLLMの間に障壁がないこと、2つ目は、LLMは動作に時間がかかることがあり、ストリーミングによってユーザーはバックグラウンドで何が起こっているかを正確に知ることができること、3つ目は、LLMはしばしば間違えることがあり、チャットはそれを修正し、自然に導くための優れたインターフェースを提供することです。そして、人々はチャットでフォローアップの会話や物事についての反復的な議論をすることにとても慣れています。
しかし、ストリーミングチャットには欠点もあります。第一に、ストリーミングチャットは比較的新しいユーザーエクスペリエンスなので、既存のチャットプラットフォーム(iMessage、Facebook Messenger、Slackなど)にはありません。
非ストリーミングチャットとの大きな違いは、応答がバッチで返されること、LLMがバックグラウンドで動作すること、ユーザーがLLMにすぐに回答させようと急がないことです。ワークフロー。人々は人間とのメールに慣れている。なぜAIとのメールに適応できないのだろうか?非ストリーミングチャットは、より複雑なエージェントシステムとの対話を容易にします。これらのシステムはしばしば時間がかかり、即座の応答が期待される場合、イライラすることがあります。非ストリーミングチャットは、一般的にその期待を取り除き、より複雑なことを実行しやすくします。
これら2つのタイプのチャットには、次のような長所と短所があります:

2.バックグラウンド環境(アンビエントUX)
ユーザーはAIにメッセージを送ることを考えますが、これは上でチャットが話したことです。
ユーザーはAIにメッセージを送ることを考えるでしょう。
エージェントシステムがその潜在能力を真に発揮するためには、AIがバックグラウンドで働くことを可能にする方向にシフトする必要があります。タスクがバックグラウンドで処理されると、ユーザーは完了までの時間が長くなっても(待ち時間が少ないという期待を緩和されるため)寛容になることがよくあります。これは、エージェントがより多くの仕事をするために解放され、しばしばチャットUXよりもより注意深く、勤勉に推論します。
さらに、バックグラウンドでエージェントを実行することは、人間のユーザーの能力を拡張します。チャットインターフェースでは、一度に1つのタスクに制限されることがよくあります。しかし、Agentがバックグラウンド環境で動作している場合、同時に複数のタスクに取り組んでいる多くのAgentがいるかもしれません。
バックグラウンドでエージェントを実行させるには、ユーザの信頼が必要です。簡単なアイデアは、エージェントが何をしているかをユーザーに正確に見せることです。実行中のすべてのステップを表示し、ユーザに何が起こっているかを観察させます。これらのステップは(応答をストリーミングするときのように)すぐには見えないかもしれませんが、ユーザがクリックして観察できるようにする必要があります。次のステップは、ユーザに何が起こっているかを見せるだけでなく、ユーザにエージェントを修正させることです。もしエージェントがステップ4(10のうち)で間違った選択をしたことに気づいたら、顧客はステップ4に戻り、何らかの方法でエージェントを修正することができます。
このアプローチは、ユーザーを「イン・ザ・ループ」から「オン・ザ・ループ」に移行させます。「オンザループ」には、エージェントが実行しているすべての中間ステップをユーザーに表示する機能が必要です。
AIソフトウェアエンジニアのDevinは、UXのようなものを実装したアプリケーションです。Devinの実行には長い時間がかかりますが、顧客は実行されたすべてのステップを見ることができ、特定の時点での開発状態に巻き戻し、そこから修正を加えることができます。Agentがバックグラウンドで動作しているからといって、完全に自律的にタスクを実行する必要はありません。時には、Agentは何をすべきか、どのように答えるべきかわからないことがあります。そのようなときこそ、人間の注意を引き、助けを求める必要があるのです。
具体的な例としては、Harrisonが構築しているEメールアシスタントエージェントがあります。メールアシスタントは基本的なメールには対応できますが、複雑なLangChainのバグレポートの確認、ミーティングに出席するかどうかの判断など、自動化したくない特定のタスクをハリソンに入力させることがよくあります。この場合、メールアシスタントはハリソンに返信するための情報が必要であることを伝える方法が必要です。その代わりに、特定のタスクに関するハリソンの意見を求めており、それを使って素敵なメールを作成し送信したり、カレンダーの招待をスケジュールしたりすることができます。
現在、ハリソンはこのヘルパーをSlackに設定している。これはハリソンに質問を送り、ハリソンはダッシュボードでそれに答え、ワークフローとネイティブに統合する。このタイプのUXは、カスタマーサポートダッシュボードのUXに似ている。このインターフェイスは、アシスタントが人間の助けを必要とするすべての領域、リクエストの優先度、およびその他のデータを表示する。

3.スプレッドシート (表計算UX)
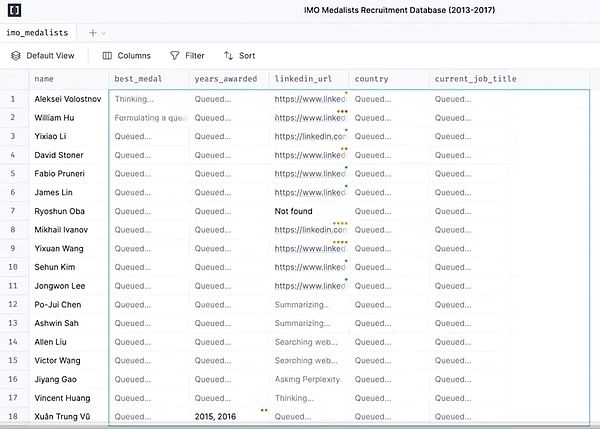
Spreadsheet UXは、バッチ処理ジョブをサポートする超直感的でユーザーフレンドリーな方法です。各フォーム、あるいは各列は、特定の何かに取り組むための独自のエージェントになります。このバッチ処理により、ユーザは複数のエージェントとのインタラクションを拡張することができます。
このUXには他にも利点があります。スプレッドシート形式は、ほとんどのユーザーが慣れ親しんでいるUXなので、既存のワークフローにうまくフィットします。このタイプのUXは、データの拡張に最適です。これは、各列が拡張される異なる属性を表すことができる、一般的なLLMのユースケースです。
このタイプのUXは、Exa AI、Clay AI、Manaflowなどの製品で使用されており、Manaflowは、このスプレッドシートUXがワークフローを処理する方法の例として使用されています。
ケーススタディ:
Manaflowはどのように電子フォームをワークフローに使用しているか。
Manaflowがエージェントのインタラクションにスプレッドシートを使う方法
Manaflowは、創設者のローレンスが勤めていたMinion AI社にインスパイアされ、Web Agentという製品を作りました。このエージェントは、ローカルのGeogle Chromeをコントロールし、フライトの予約、Eメールの送信、洗車の予約などのアプリケーションと対話できるようにする。ManaflowはMinion AIにインスパイアされ、エージェントにスプレッドシートを操作させることにした。エージェントは人間のUIを操作するのは得意ではなく、本当に得意なのはコーディングなので、ManaflowはエージェントにUIでPythonスクリプトを呼び出させ、データベースとインターフェースさせ、APIにリンクさせた。Manaflowは、エージェントがUIでPythonスクリプトを呼び出し、データベースとインターフェイスし、APIにリンクし、そしてデータベースを直接操作できるようにします。
ワークフローは以下の通りです:Manaflowのメインインターフェイスはスプレッドシートで、各列はワークフローのステップを表し、各行はタスクを実行するAIエージェントに対応しています。各スプレッドシートのワークフローは自然言語でプログラムできる(技術者でないユーザーが自然言語でタスクやステップを記述できる)。各スプレッドシートには、各列の実行順序を決定する内部依存グラフがある。これらの順序は、各行のエージェントに割り当てられ、並列にタスクを実行し、データ変換、APIコール、コンテンツ検索、メッセージ送信などのプロセスを処理します。">
マナシートの生成は、上の赤枠のような自然言語を入力することで行うことができます。例えば、上の画像のように顧客に価格設定メールを送信したい場合、チャットを通じてプロンプトを入力し、マナシートを生成することができます。顧客の名前、Eメールアドレス、業種、Eメールが送信されたかどうかが表示され、タスクを実行するにはマナシートの実行をクリックします。
4.ジェネレーティブUI
ジェネレーティブUIには2つの異なる実装があります。"は2つの異なる方法で実装されています。
1つの方法は、モデルが自分で必要な生のコンポーネントを生成することです。これはWebsimのような製品に似ています。バックグラウンドでは、エージェントは主に生のHTMLを記述し、何が表示されるかを完全にコントロールします。しかし、このアプローチでは、生成されるウェブアプリケーションの品質に高い不確実性があるため、最終結果は非常に不安定に見えることがあります。
もう1つの、より制約の多いアプローチは、UIコンポーネントの一部を事前に定義することです。これは通常、ツールの呼び出しによって行われます。たとえば、LLMが天気APIを呼び出すと、天気図UIコンポーネントのレンダリングがトリガーされます。レンダリングされたコンポーネントは実際には生成されないので(しかし、より多くのオプションがあります)、生成されたUIはより洗練されたものになるでしょう。
Case Study:
Personal AI Product dot
DotはNew Computerの製品である。その目標は、より優れたタスク管理ツールではなく、ユーザーの長期的な伴侶となることであり、共同創業者のジェイソン・ユアンによれば、Dotの感覚は、どこに行けばいいのか、何をすればいいのか、何を言えばいいのかわからないときに、Dotに頼るというものだ。
- Founder Jason Yuanはよく、深夜に酔いたいと言ってDotにバーを勧めさせる。ある日の仕事後、ユアンはまた同じような質問をし、ドットはジェイソンがこのままではいけないと説得し始めた。
- ファスト・カンパニーのマーク・ウィルソン記者もドットと数カ月一緒にいて、この件についてドットと考えを共有した。彼がカリグラフィーのクラスで書いた手書きの「O」をドットに披露すると、ドットは数週間前の彼の手書きの「O」の写真を出して彼を驚かせ、カリグラフィーが上達したことを褒めた。
- Dot を使う時間が長くなるにつれて、Dot はユーザーがカフェに行くのが好きだということをよりよく理解し、積極的にオーナーに近隣の良いカフェをプッシュし、このカフェが良い理由を添付し、最後にナビゲートするかどうかを尋ねます。
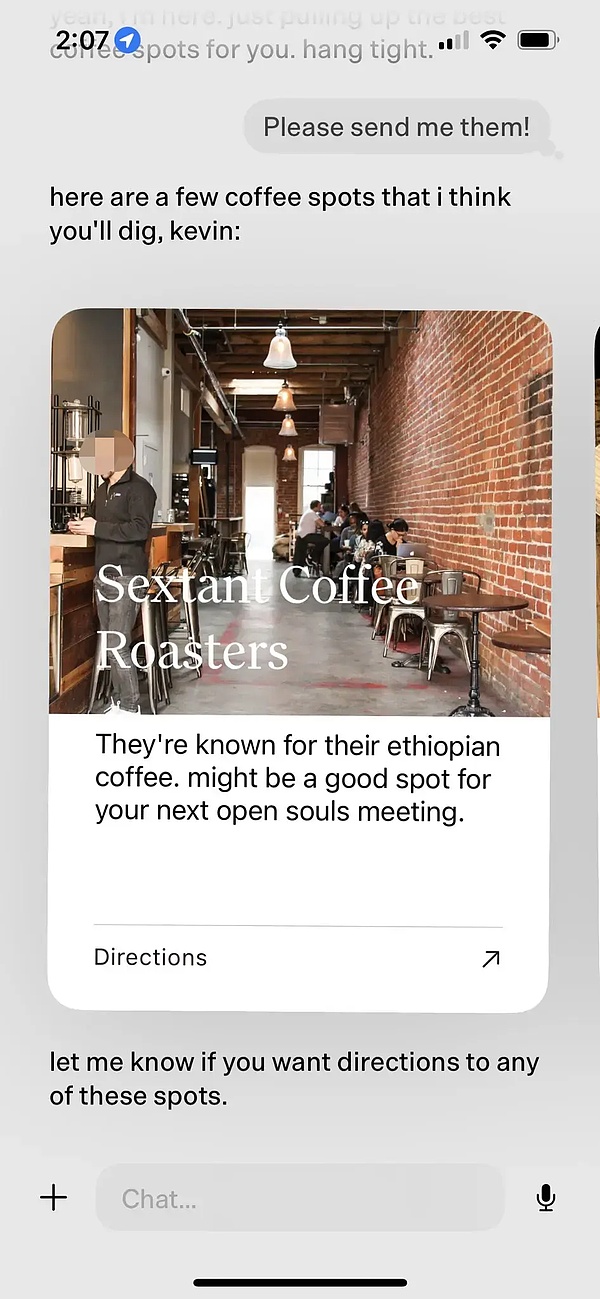
このカフェのレコメンデーションの例を見ていただければわかると思います。DotはUIコンポーネントを事前に定義することで、LLMネイティブのインタラクションを実現しています。
5.コラボレーティブUX
エージェントと人間が一緒に働くとどうなるでしょうか?Googleドキュメントを考えてみてください。そこでは、顧客はチームメンバーと共同でドキュメントを書いたり編集したりすることができます。
ジェフリー・リットとインク&スイッチによるパッチワークプロジェクトは、人間とエージェントのコラボレーションの素晴らしい例です。エージェントのコラボレーション(訳者注:これは、最近のOpenAI Canvas製品のアップデートのインスピレーションになったかもしれません)。
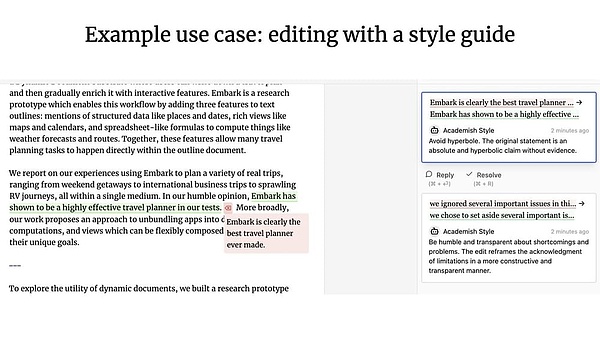
コラボレーションUXは、以前議論したものと比べてどうでしょうか?
-コラボレーティブUXでは、クライアントとLLMは、しばしば同時に作業し、互いの作業内容を共有します。
- Environmental UXでは、ユーザーがまったく別のことに集中している間、LLMはバックグラウンドで継続的に作業します。
メモリ
メモリは優れたエージェント エクスペリエンスにとって非常に重要です。もし、あなたが話したことを覚えていない同僚がいて、その情報を何度も何度も繰り返さなければならないとしたら、コラボレーション体験は非常に悪くなるでしょう。おそらくLLMはすでに人間的な感覚を持っているからでしょう。しかし、LLMは本質的に何も覚えていない。
エージェントの記憶は、製品自体が必要とするものに基づいており、異なるUXは情報を収集し、フィードバックを更新するための異なる方法を提供します。私たちは、エージェント製品の記憶メカニズムに異なるタイプの高レベル記憶を見ることができます。
論文『CoALA: Cognitive Architectures for Language Agents』では、人間の記憶タイプをエージェントの記憶にマッピングし、以下のように分類しています:
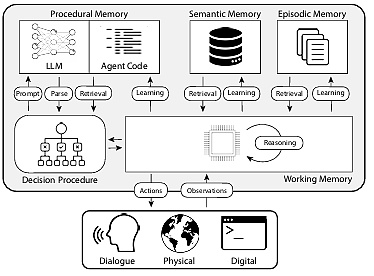
1.手続き的記憶:タスクがどのように実行されたかについての記憶。strong>タスクの実行方法に関する長期記憶で、脳のコア命令セットに似ている
- human procedural memory: 自転車の乗り方を覚えている。
- Agent's procedural memory(エージェントの手続き記憶):CoALAの論文では、手続き記憶をLLMの重みとエージェントのコードの組み合わせとして記述しており、これがエージェントの働き方を根本的に決定しています。
実際には、Langchainチームはエージェントシステムが自動的にLLMを更新したり、コードを書き換えたりするのを見たことはありませんが、エージェントがシステムプロンプトを更新する例はいくつかあります。
2.意味記憶:長期知識リザーブ
Human意味記憶:学校で学んだ事実、概念、それらの関係などの情報の断片からなる。
- Agent's semantic memory(エージェントの意味記憶):CoALAの論文では、意味記憶を事実のリポジトリとして説明している。
実際には、これはLLMを使ってエージェントの対話や対話から情報を抽出することで実現されることが多いです。この情報が保存される正確な方法は、通常アプリケーション固有です。この情報は、将来のダイアログで取得され、エージェントの応答に影響を与えるためにシステムプロンプトに挿入されます。
3. エピソード記憶:特定の過去の出来事を思い出す
- 人間のエピソード記憶。人間のエピソード記憶:人が過去に経験した特定の出来事(または「エピソード」)を思い出すこと。
- Situational memory in an agent(エージェントにおける状況記憶):CoALAの論文では、状況記憶をエージェントの保存された過去の行動のシーケンスとして定義しています。
これは主に、エージェントが期待通りに行動を実行できるようにするために使用されます。実際には、状況記憶への更新はFew-Shots Promptsによって達成される。関連する更新があるFew-Shots Promptが十分にあれば、次の更新はDynamic Few-Shot Promptによって行われます。
エージェントに何かをする正しい方法を最初から指示する方法がある場合、後で同じ問題にその方法を使うのは簡単です。逆に、何かをする正しい方法がない場合、またはエージェントが常に新しいことをする場合、意味記憶がより重要になります。逆に、正しいやり方がない場合や、常に新しいことをする場合は、意味記憶がより重要になります。
開発者は、エージェントの記憶を更新するタイプについて考えることに加えて、エージェントの記憶を更新する方法についても考えなければなりません。
エージェントの記憶を更新する最初の方法は、「ホットパスで」です。「ホットパスで"です。
Agentのメモリを更新するもう一つの方法は"in the background"です。バックグラウンド"です。この場合、バックグラウンドプロセスがセッション後に実行され、メモリを更新します。
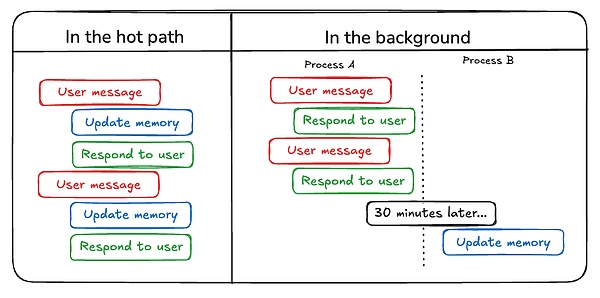
これら2つの方法を比較します。ホットパス内 "メソッドの欠点は、応答が配信されるまでに若干の遅延があること、また、メモリロジックをエージェントロジックと組み合わせる必要があることです。
しかし、"in the background "はこれらの問題を回避します - 遅延を追加せず、メモリロジックは独立したままです。しかし、"in the background "にはそれ自身の欠点があります。メモリはすぐに更新されず、バックグラウンドプロセスをいつ開始するかを決定するために追加のロジックが必要になります。
メモリを更新するもう1つの方法は、特に状況記憶に関連するユーザーフィードバックを含みます。例えば、ユーザーがインタラクションを高く評価した場合(Postive Feedback)、エージェントはそのフィードバックを将来の呼び出しのために保存することができます。
以上のまとめから、プランニング、インタラクション、記憶の各コンポーネントが同時に進歩することで、2025年にはより使いやすいAIエージェントが登場し、人間と機械のコラボレーションの新時代を迎えられると期待しています。
<nil>
Weiliangソラナのゲーム・エコシステムは、ソラナのSonic SVMを介してTikTokに統合されたタップ・トゥ・アーニング・ゲームであるSonicXで成長している。Notcoinの成功に続き、SonicXはゲームとソーシャルメディアを融合させることで、新たなプレイヤー層の獲得を目指している。重要なのは、ノットコインの成功を反映するのか、それとも他の多くのゲームのように消えていくのか、ということだ。
 Catherine
Catherineリップル社は、8月7日の好意的な判決に異議を唱えるSECの10月2日の上訴に対し、クロスアピールを提出した。リップル社は現在、米国の高等裁判所に戦いを挑む構えだ。この長期化する法廷闘争に決着はつくのだろうか?
 Kikyo
Kikyoチャールズ・ホスキンソン氏は、カルダノを取り巻く否定的な感情に触れ、それはガバナンスの分散化と長年の問題への対処を目指すヴォルテール時代へのネットワークの移行に起因すると述べた。同氏は、カルダノの透明性と独自のガバナンスが他のブロックチェーンとは一線を画しており、イノベーション、プライバシー、長期的成長へのコミットメントを強化していると強調した。
 Anais
AnaisOpenAIの最近の報告書は、同社のチャットボットが国政選挙中に有権者に影響を与えることを目的とした誤った情報を生成するために悪用されていると警告している。AIが生成したコンテンツが将来的に悪用される可能性は、特に大統領選挙が近づいている今、深刻な懸念を抱かせる。民主主義プロセスの完全性は危機に瀕しているのだろうか?
Catherineユービーアイソフトは、初のウェブ3ゲーム「チャンピオン・タクティクス」を2024年10月23日に発売する:グリモリア・クロニクルズは、Oasysプラットフォームを通じてブロックチェーン技術を利用し、2024年10月23日に発売される。このゲームでは、プレイヤーは神話に登場するチャンピオンのチームを結成し、戦略的なPvPバトルを楽しむことができ、没入感のあるゲーム体験を目指している。
 Weatherly
WeatherlyZoomは2025年に本物そっくりのAIクローンを発表する準備を進めており、同社は職場のコミュニケーションに革命を起こそうとしている。デジタルツインがあなたの代わりに会議に出席してくれる日も近いかもしれない。しかし、この技術革新は生産性を高めるのだろうか、それとも怠慢や自己満足を助長するのだろうか?
KikyoCato Networksは、犯罪者が暗号通貨取引所向けに偽のIDとリアルな動画を作成することで、KYCチェックを回避できるProKYCディープフェイクツールについて懸念を表明した。この高度な詐欺テクニックは多額の金銭的損失をもたらしており、金融機関におけるセキュリティ対策強化の必要性を浮き彫りにしている。
 Joy
Joyロンドンの男が、違法な暗号通貨ATMビジネスを運営し、FCA認可を得ずに30万ポンドを資金洗浄した容疑を否認した。現在保釈中の彼の次の審問は11月7日に予定されている。
CatherineContinue Capitalに関連する暗号通貨事業体が、ユーザーを騙して悪意のある取引に署名させるフィッシング攻撃により、ラップされたイーサリアムトークンで3600万ドル以上を失った。この事件はfwDETHの価格を95%以上大幅に下落させ、暗号空間におけるフィッシング攻撃の継続的なリスクを浮き彫りにした。
Anais