フラクタル・ビットコイン:詳細調査レポート
フラクタル・ビットコインは、世界で最も安全で広く保持されているブロックチェーンの上に構築された、ビットコインのコアコードそのものを使用して、無限のレイヤーを再帰的に拡張する唯一のビットコイン・スケーリング・ソリューションです。
 JinseFinance
JinseFinance

記事:Lucas Tcheyan Article compiled by Block unicorn
はじめに
パブリック・ブロックチェーンの出現は、コンピューターサイエンスの歴史において最も深遠な進歩のひとつである。そして人工知能の発展は、我々の世界に大きな影響を与えるだろうし、すでに与えている。ブロックチェーン技術が取引決済、データ保存、システム設計に新たなテンプレートを提供するとすれば、AIはコンピューティング、分析、コンテンツ配信における革命である。両産業におけるイノベーションが新たなユースケースを解き放ち、今後数年で両産業における採用が加速する可能性がある。本レポートでは、暗号通貨とAIの継続的な統合を調査し、両者のギャップを埋め、両者のパワーを活用しようとする斬新なユースケースに焦点を当てている。具体的には、分散型コンピューティング・プロトコル、ゼロ知識機械学習(zkML)インフラ、AIエージェントを開発するプロジェクトを調査しています。
暗号通貨は、ライセンスレス、トラストレス、コンポーザブルな決済レイヤーをAIに提供します。これにより、分散型コンピューティングシステムを通じてハードウェアをより利用しやすくしたり、価値交換を必要とする複雑なタスクを実行できるAIエージェントを構築したり、シビル攻撃やディープフォージェリーに対抗するためのアイデンティティや証明ソリューションを開発したりといったユースケースが可能になります。人工知能は、Web 2で見られたような多くのメリットを暗号通貨にもたらしている。これには、大規模な言語モデル(特別に訓練されたChatGPTやCopilotなど)を通じてユーザーや開発者のユーザーエクスペリエンス(UX)を向上させるほか、スマートコントラクトの機能や自動化を大幅に改善する可能性も含まれる。ブロックチェーンはAIに必要な透明性の高いデータ豊富な環境である。 しかし、ブロックチェーンは計算能力も限られており、AIモデルを直接統合する際の大きな障壁となっています。
暗号通貨とAIの交差点で現在進行中の実験と最終的な採用の背後にある推進力は、暗号通貨の最も有望なユースケースを推進しているものと同じです。である。巨大な可能性を考えると、この分野のプレーヤーは、これら2つの技術が交差する基本的な方法を理解する必要があります。
注目点:
近い将来(6カ月から1年)には、暗号通貨が統合されます。暗号通貨とAIの統合は、開発者の効率性、スマートコントラクトの監査可能性とセキュリティ、ユーザーのアクセシビリティを向上させるAIアプリによって支配されるでしょう。これらの統合は暗号通貨に特化したものではなく、オンチェーンの開発者とユーザーのエクスペリエンスを向上させるものです。
高性能GPUの深刻な不足があるように、分散型コンピューティングの提供は、AIに合わせたGPUの提供を実装し、採用を促進しています。
ユーザーエクスペリエンスと規制は、分散型コンピューティングの顧客を引き付けるための障壁であり続けています。しかし、OpenAIの最近の進展と米国で進行中の規制の精査は、許可不要で検閲に強く、分散型AIネットワークの価値提案を浮き彫りにしています。
オンチェーンAI統合、特にAIモデルを使用できるスマートコントラクトには、zkML技術やオフチェーンコンピューティングを検証する他の計算アプローチの改善が必要です。包括的なツールや開発者の人材不足、高コストが採用の障壁となっています。
人工知能エージェントは暗号通貨に適しており、ユーザー(またはエージェント自身)はウォレットを作成して、他のサービス、エージェント、または人々と取引することができます。これは現在、従来の金融トラックでは不可能だ。より広く採用されるためには、非暗号化商品との追加的な統合が必要である。
用語
人工知能とは、人間の推論や問題解決能力を模倣するために、計算や機械を使用することです。
人工知能とは、人間の推論や問題解決能力を模倣するために計算や機械を使用することです。
ニューラルネットワークは、AIモデルをトレーニングする方法です。ニューラルネットワークは、離散的なアルゴリズムの層を通して入力を実行し、望ましい出力が得られるまで洗練させます。ニューラルネットワークは、出力を変更するために変更可能な重みを持つ方程式で構成されている。その出力が正確であるように訓練するには、多くのデータと計算が必要になる。これはAIモデルを開発する最も一般的な方法の1つです(ChatGPTはTransformerに依存するニューラルネットワークプロセスを使用しています)。
トレーニングは、ニューラルネットワークやその他のAIモデルを開発するプロセスです。入力が正しく解釈され、正確な出力が得られるようにモデルを訓練するには、大量のデータが必要です。トレーニング中、モデルの方程式の重みは、満足のいく出力が得られるまで継続的に変更されます。トレーニングは非常に高価になります。例えば、ChatGPTはデータ処理に数万台のGPUを使用しています。リソースが少ないチームは、Amazon Web Services、Azure、Google Cloudプロバイダーなどの専用コンピュートプロバイダーに頼ることが多い。
推論とは、出力や結果を得るためにAIモデルを実際に使用することです(例えば、暗号通貨とAIの交差点に関する論文のアウトラインを作成するためにChatGPTを使用するなど)。推論は、学習プロセス全体と最終的な成果物に使用される。計算コストがかかるため、トレーニングが完了した後でも実行するにはコストがかかりますが、トレーニングよりは計算量が少なくて済みます。
ゼロ知識証明(ZKP)は、基礎となる情報を明らかにすることなくステートメントを検証できるようにする。これは暗号通貨において、主に2つの理由で有用である。プライバシーの面では、機密情報(例えばウォレットにETHがいくらあるか)を明かすことなく取引を行うことができる。拡張性については、オフチェーンの計算を再実行するよりも速くオンチェーンで証明することが可能になる。これにより、ブロックチェーンやアプリケーションは、オフチェーンで安価に計算を実行し、オンチェーンで検証することができます。ゼロナレッジとEther VMにおけるその役割の詳細については、Christine Kim氏のレポート「zkEVMs: The Future of Ether Scalability」を参照してください。
人工知能/暗号通貨市場マップ

AIと暗号通貨の統合プロジェクトは、大規模なオンチェーンAIインタラクションをサポートするために必要な基礎インフラを構築中です。
AIモデルの訓練と推論に必要な、主にグラフィック・プロセッシング・ユニット(GPU)の形をした大量の物理的ハードウェアを提供するために、分散型コンピューティング市場が出現しています。こうした双方向市場は、コンピューティングを借りる人と借りようとする人を結びつけ、価値の移転とコンピューティングの検証を促進する。分散型コンピューティングの中には、さらなる機能を提供するいくつかのサブカテゴリーが出現している。二者間市場に加えて、このレポートでは、検証可能なトレーニングと微調整のアウトプットを提供することに特化した機械学習トレーニングベンダーや、しばしばスマートインセンティブネットワークとも呼ばれる、AIのための計算とモデル生成を接続することに特化したプロジェクトについてレビューします。
zkMLは、チェーン上で検証可能なモデル出力をコスト効率の良いタイムリーな方法で提供しようとするプロジェクトにとって、新たな注目分野です。このようなプロジェクトでは、基本的にアプリケーションがオフチェーンでの重い計算要求を処理し、検証可能な出力をオンチェーンで公開することで、オフチェーンでの作業負荷が完全かつ正確であることを証明します。これは、AIモデルの活用を望むzkMLベンダーとDeFi/ゲームアプリとの統合が増えていることからも明らかです。
複雑な計算の可用性とオンチェーン計算を検証する能力は、オンチェーンAIエージェントへの扉を開きます。エージェントは、ユーザーに代わってリクエストを実行できる訓練されたモデルです。エージェントは、ユーザーがチャットボットに話しかけるだけで複雑なトランザクションを実行できるようにすることで、オンチェーン・エクスペリエンスを大幅に向上させる機会を提供する。しかし現在のところ、エージェント・プロジェクトはまだ、簡単で迅速な展開を可能にするインフラとツールの開発に集中している。
分散コンピューティング
概要
人工知能はモデルを訓練し、推論を実行するために多くの計算を必要とします。過去10年間で、モデルがより複雑になるにつれて、必要な計算量は指数関数的に増加しています。例えば、OpenAIの調査によると、2012年から2018年にかけて、モデルの計算量は2年ごとに倍増していたのが、3カ月半ごとに倍増している。これによりGPUの需要が急増し、一部の暗号通貨採掘業者はGPUをクラウド・コンピューティング・サービスに再利用している。アクセス・コンピューティングの競争が激化し、コストが上昇する中、暗号を活用して分散型コンピューティング・ソリューションを提供するプロジェクトも出てきている。これらのプロジェクトは、チームが手頃な価格でトレーニングやモデルの実行ができるよう、オンデマンド・コンピューティングを競争力のある価格で提供している。場合によっては、パフォーマンスとセキュリティがトレードオフになることもあります。
Nvidia製のような最先端のGPUは需要が高い。9月、Tetherはドイツのビットコイン採掘会社Northern Dataの株式を取得したが、同社は4億2000万ドルを投じて10,000台のH100 GPUを購入したと報じられている(そのうちの最初のものはAIトレーニングに使用された)。H100GPUは、AIトレーニング用の最先端GPUのひとつである)。一流のハードウェアを手に入れるまでの待ち時間は、少なくとも6カ月、多くの場合はそれ以上かかる。さらに悪いことに、企業はしばしば、使わないかもしれないコンピュートについて長期契約を結ぶよう求められる。このため、利用可能なコンピュートが存在するにもかかわらず、市場で入手できないという事態が発生しかねない。分散型コンピューティング・システムは、コンピュート所有者が余剰容量を即座にサブリースできるセカンダリー・マーケットを創出し、新たな供給を解放することで、こうした市場の非効率性に対処するのに役立ちます。
競争力のある価格設定とアクセシビリティに加えて、分散型コンピューティングの重要な価値提案は検閲への耐性です。AI Index 2023の年次報告書で強調された最初の主要テーマは、AIモデルの開発において産業界が学界を追い抜く傾向が強まっており、少数の技術リーダーの手にコントロールが集中していることです。このことは、AIモデルを支える規範や価値観の設定において、彼らが大きな影響力を持つことに懸念を抱かせます。特に、これらのハイテク企業が、自分たちがコントロールできないAI開発を制限する規制を推し進めた後ではなおさらです。
分散型コンピューティングの垂直統合
近年、いくつかの分散型コンピューティングモデルが登場しており、それぞれが独自の焦点とトレードオフを持っています。strong>
Akash、io.net、iExec、Cudosなどのプロジェクトは、データや汎用コンピューティングソリューションに加えて、AIのトレーニングや推論専用の計算へのアクセスを提供する、または提供しようとしている分散型コンピューティングアプリです。
アカッシュは、利用可能な唯一の完全オープンソースの「ハイパークラウド」プラットフォームです。akashは2020年に最初のメインネットを立ち上げ、ライセンスなしでクラウドマーケットプレイスへのアクセスを提供することに注力し、当初はストレージとCPUのリースサービスを特徴としていました。2023年6月には、GPUに特化した新しいテストネットがアカシによって立ち上げられ、9月にはGPUメインネットが立ち上げられ、ユーザーはAIのトレーニングや推論のためにGPUをレンタルできるようになった。
アカシのエコシステムには、テナントとベンダーという2つの主要プレーヤーが存在する。テナントは、計算リソースを購入したいAkashネットワークのユーザーです。ベンダーはコンピューティングのプロバイダーです。テナントとサプライヤーをマッチングするために、Akashは逆オークション方式を採用している。テナントはコンピュート・リクエストを提出し、サーバーの場所やコンピュート実行のためのハードウェアの種類など、特定の条件と支払う金額を指定します。そして、プロバイダーは希望価格を提出し、最も安い入札者にタスクが発注されます。
アカッシュのバリデータは、ネットワークの整合性を維持します。バリデーターは現在100人に限定されており、時間をかけて徐々に増やしていく予定である。また、AKT保有者はAKTをバリデーターに委任することもできる。ネットワークの取引手数料とブロック報酬はAKTの形で分配される。さらに、各リースについて、アカシネットワークはコミュニティによって決定されたレートで「収集料」を獲得し、AKT保有者に分配されます。
二次市場
分散型コンピューティング市場は、既存のコンピューティング市場の非効率性を埋めるために設計されています。供給の制約により、企業は必要以上のコンピューティング・リソースをため込んでおり、継続的なアクセスが必要ない場合でも、顧客を長期契約に拘束するクラウド・プロバイダーとの契約構造によって、供給はさらに制約されています。分散型コンピューティング・プラットフォームは、コンピューティングの必要性を持つ世界中の誰もがプロバイダーになれるように、新たな供給を解き放ちます。
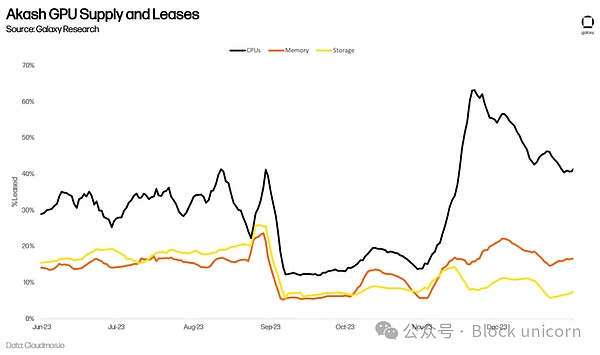
AIトレーニングのためのGPU需要の急増は、Akidasの長期的なネットワーク使用量につながるのでしょうか?Akashの長期的なネットワーク利用につながるかどうかは、まだわかりません。 例えば、Akashは以前からCPUのマーケットプレイスを提供しており、集中型の代替サービスと同様のサービスを70~80%の割引価格で提供している。 しかし、低価格が大きな普及につながっていない。 ネットワーク上のアクティブリースは頭打ちで、2023年第2四半期までに平均でコンピュート33%、メモリー16%、ストレージ13%にとどまっている。これらは、このチェーンにおける採用のための印象的な指標ではありますが(参考までに、大手ストレージ・プロバイダのFilecoinは、2023年第3四半期にストレージの利用率をすでに12.6%としています)、これは、これらの製品の供給が依然として需要を上回っていることを示唆しています。
アカッシュがGPUネットワークを立ち上げてから半年以上が経過しており、長期的な採用率を正確に評価するには時期尚早です。現在までのところ、GPUの利用率は平均44%で、CPU、メモリ、ストレージよりも高く、これは需要の兆候である。これは主に、90%以上がリースされているA100のような最高品質のGPUに対する需要によってもたらされています。
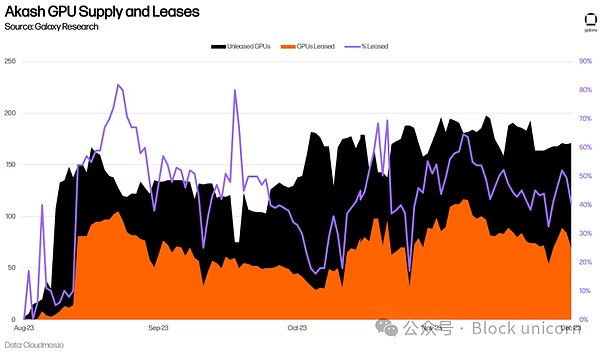
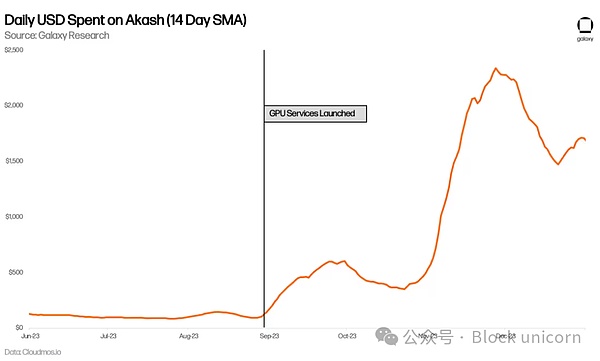
アカシは、1日の使用量も増加しています。GPUが登場する前のほぼ2倍だ。
アカシはまた、GPUが登場する前と比べて、1日の使用量がほぼ倍増している。
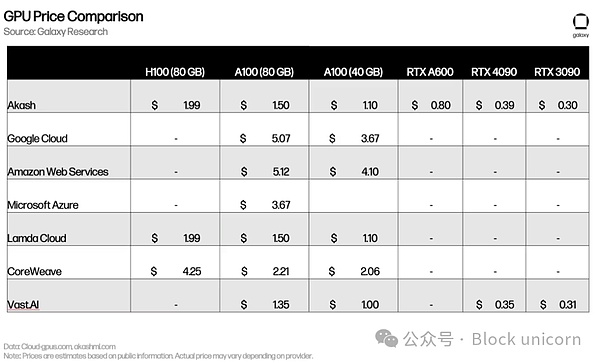
価格設定は、Lambda CloudやVast.aiのような中央集権型サービスと似ている。Vast.aiやその他の集中型競合サービス(場合によってはさらに高価)と同様です。H100やA100のような最高級GPUに対する巨大な需要は、デバイスの所有者のほとんどが、価格競争に直面する市場で市場に出ることにほとんど関心がないことを意味する。
初期のマージンは良好でしたが、まだ障壁が存在します。障壁が存在する(後述)。 分散型コンピューティング・ネットワークは、需要と供給を生み出すための追加的なステップを踏む必要があり、各チームは新しいユーザーを惹きつける最善の方法を試行錯誤している。 例えば、2024年初頭、Akashは提案240を可決し、GPUベンダーからのAKT排出量を増加させ、特にハイエンドGPUの供給を増やすインセンティブを与えた。 チームはまた、潜在的なユーザーにネットワークのリアルタイム機能を実証するため、概念実証モデルの展開に取り組んでいる。 Akashは独自のベースモデルをトレーニングしており、Akash GPUを使って出力を作成できるチャットボットや画像生成製品をすでに発表している。 同様に、io.netは安定した拡散モデルを開発し、ネットワークのパフォーマンスとスケールをよりよく模倣するために、新しいネットワーク機能を展開しています。
分散型機械学習トレーニング
AIのニーズを満たすことができる汎用コンピュート・プラットフォームに加えて、AI専門のGPUプロバイダーも台頭しています。GPUプロバイダーのグループも出現している。たとえばGensynは、「誰かが何かを訓練したいと思い、誰かがそれを訓練する意思があるのなら、その訓練は行われるべきだ」という考えのもと、「集合知を構築するためにパワーとハードウェアを編成」しています。
プロトコルには4つの主な参加者がいる:提出者、解決者、検証者、内部告発者だ。提出者はネットワークにトレーニング要求のタスクを提出する。これらのタスクには、トレーニング目的、トレーニング対象モデル、トレーニングデータが含まれる。提出プロセスの一環として、提出者はソルバーが必要とする推定計算量の前払いを要求される。
提出後、タスクは実際にモデルを訓練するソルバーに割り当てられる。ソルバーが完了したタスクをバリデーターに提出すると、バリデーターはトレーニングが正しく完了したかどうかをチェックする責任を負う。バリデーターが正直に行動していることを確認するのは、内部告発者の責任である。内部告発者にネットワークへの参加を奨励するため、ゲンシン社は意図的なミスの証拠を定期的に提供し、それを発見した内部告発者には報奨金を与える予定である。
AI関連のワークロードにコンピュートを提供する以外に、Gensynの重要な価値提案は、まだ開発中の検証システムである。検証は、GPUプロバイダーの外部計算が正しく実行されることを保証するために必要であり(すなわち、ユーザーのモデルがユーザーの望むように訓練されていることを保証するために)、Gensynは、確率的学習証明、グラフベースの精度プロトコル、およびTruebitスタイルの動機付けゲームとして知られる新しい検証手法を利用する独自の方法でこの問題を解決します。Gensynは、「確率論的学習証明、グラフベースの正確なプロトコル、およびTruebitスタイルの動機付けゲーム」と呼ばれる斬新な検証手法を利用し、ユニークな方法でこの問題に取り組んでいる。これは楽観的な解モデルであり、検証者は、コストのかかる非効率的なプロセスであるモデル自体を完全に再実行することなく、ソルバーがモデルを正しく実行したことを確認することができる。
革新的な検証手法に加え、Gensynは中央集権的な代替手段や暗号通貨の競合他社と比較して費用対効果が高いとも主張しています-MLトレーニングをAWSより最大80%安く提供する一方で、テストの面ではTruebitのような同様のプロジェクトを凌駕しています。
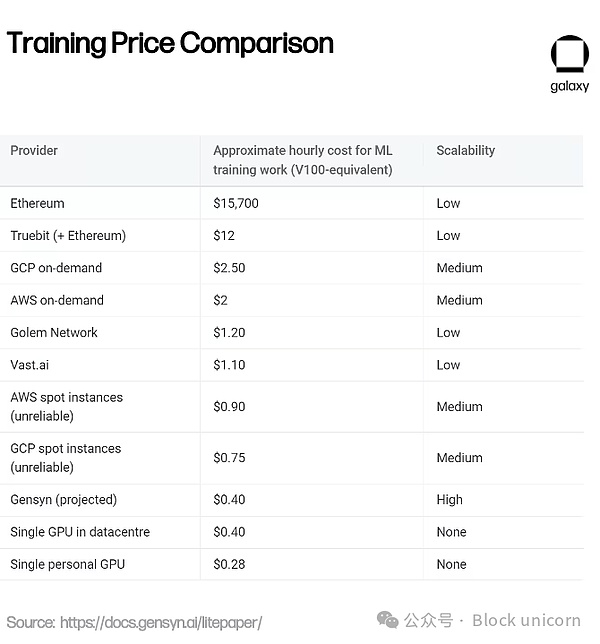

この初期結果を分散型ネットワークで大規模に再現できるかどうかはまだわかりません。Gensynは、小規模データセンター、小売ユーザー、将来の携帯電話などの小型モバイル機器の余剰コンピューティングパワーを活用したいと考えています。Gensynは、小規模データセンター、小売ユーザー、将来の携帯電話などの小型モバイル機器の余剰コンピューティング能力を活用したいと考えている。しかし、Gensynチーム自身が認めているように、異種コンピューティング・プロバイダーに依存することは、いくつかの新しい課題をもたらします。
グーグル・クラウドやコアウィーブのような集中型プロバイダーにとって、コンピュートは高価ですが、コンピュート間の通信(帯域幅とレイテンシー)は安価です。Gensynはこの枠組みを破壊し、世界中の誰もがGPUを利用できるようにすることで計算コストを削減しますが、ネットワークが遠く離れた異種ハードウェア上の計算ジョブを調整する必要があるため、通信コストも増加します。概念実証。
分散型一般知能
分散型計算プラットフォームは、AIの作成方法を設計する可能性も開きます。 Bittensorは、分散型計算プラットフォームをベースにしています。Bittensorは、Substrate上に構築された分散型コンピューティング・プロトコルで、「AIを協調的手法に変えるにはどうすればよいか」という問いに答えようとしている。Bittensorは、AI生成の分散化とコモディティ化を目指している。2021年にローンチされるこのプロトコルは、より優れたAIを反復し生産するために、協調的な機械学習モデルの力を活用することを望んでいる。
Bittensorはビットコインからヒントを得ている。ビットコインのネイティブ通貨TAOの供給量は2100万枚で、半減サイクルは4年(最初の半減は2025年)だ。正しい乱数を生成してブロックで報酬を得るためにプルーフ・オブ・ワークを使う代わりに、Bittensorは正しい乱数を生成してブロックで報酬を得るために「スマートプルーフ」に頼っている。正しい乱数を生成してブロック報酬を受け取るためにプルーフ・オブ・ワークを使用する代わりに、Bittensorはマイナーが推論要求に応じて出力を生成するモデルを実行することを要求する「スマート証明」に依存しています。
Motivating Intelligence
Bittensorは当初、出力を生成するためにMixed-Mode of Expertise(MoE)モデルに依存していました。推論要求を送信するとき、一般化されたモデルに頼るのではなく、MoEモデルは与えられた入力タイプに対して最も正確なモデルに推論要求を転送します。家を建てるとき、建設プロセスのさまざまな側面(建築家、エンジニア、塗装工、建築業者など......)について、さまざまな専門家を雇うことを想像してほしい。MoEはこれを機械学習モデルに応用し、入力に基づいて異なるモデルの出力を活用しようとしている。Bittensorの創設者であるAla Shaabana氏が説明するように、これは「一人の人間と話すのではなく、部屋いっぱいの頭のいい人たちと話して最良の答えを得る」ようなものだ。正しいルーティング、適切なモデルへのメッセージ同期、インセンティブを確保する上での課題があるため、このアプローチはプロジェクトがさらに発展するまで保留されることになった。
Bittensorネットワークには、バリデータとマイナーという2つの主役がいる。バリデーターはマイナーに推論リクエストを送り、その出力をレビューし、その回答の質に基づいてランキングするのが仕事だ。彼らのランキングが信頼できるものであることを保証するために、検証者には他の検証者のランキングとどれだけ一致したかに基づいて「vtrust」スコアが与えられる。検証者のvtrustスコアが高いほど、より多くのTAO排出量を受け取ることができる。これは、より多くの検証者がランキングに同意すればするほど、個々のvtrustスコアが高くなるため、検証者が長期にわたってモデルのランキングに同意するインセンティブを与えるためである。
サーバーとしても知られるマイナーは、実際の機械学習モデルを実行するネットワーク参加者です。マイナーは、与えられたクエリに対して最も正確な出力をベリファイアに提供するために互いに競争します。より正確な出力であればあるほど、TAO排出量は多くなる。たとえば、将来のシナリオでは、Bittensorの採掘者が以前にGensynでモデルを訓練し、TAO排出量を獲得するためにそれらを使用することは完全に可能です。
現在、ほとんどのやり取りは検証者と採掘者の間で直接行われています。検証者は採掘者に入力を提出し、出力を要求する(つまりモデルを訓練する)。検証者がネットワーク上のマイナーに問い合わせ、その回答を受け取ると、マイナーをランク付けし、そのランキングをネットワークに提出する。
検証者(PoSに依存)とマイナー(PoWの一種であるモデル証明に依存)の間のこの相互作用は、ユマ・コンセンサスとして知られている。これは、TAOの排出量を得るために最高のアウトプットを生成するようマイナーにインセンティブを与え、より高いvtrustスコアを得てTAOの報酬を増やすためにマイナーのアウトプットを正確にランク付けするよう検証者にインセンティブを与えるように設計されている。
サブネットとアプリ
Bittensorのインタラクションは、主にベリファイアがマイナーにリクエストを提出し、そのアウトプットを評価することで成り立っています。しかし、貢献するマイナーの質が向上し、ネットワークの全体的なインテリジェンスが高まるにつれて、Bittensorは既存のスタックの上にアプリケーションレイヤーを作成し、開発者がBittensorネットワークにクエリするアプリケーションを構築できるようにします。
2023年10月、BittensorはRevolutionアップグレードを通じてサブネットを導入し、この目標達成に向けて大きな一歩を踏み出しました。サブネットとは、Bittensor上の独立したネットワークで、特定の行動にインセンティブを与えるものです。Revolutionは、サブネットの作成に興味がある人なら誰でも、ネットワークを開放します。リリースから数ヶ月の間に、テキストプロンプト、データキャプチャ、画像生成、ストレージ用のサブネットを含む32以上のサブネットが立ち上げられた。サブネットが成熟し、製品として使用できるようになるにつれ、サブネットの作成者は、特定のサブネットに問い合わせるアプリケーションをチームが構築できるようにするアプリケーション統合も作成するようになる。現在、いくつかのアプリケーション(チャットボット、画像ジェネレーター、Twitter返信ボット、予測市場など)は存在していますが、バリデーターには、Bittensor Foundationからの資金提供以外に、これらのクエリーを受け入れて転送する正式なインセンティブはありません。
よりわかりやすく説明するために、アプリがネットワークに統合された後のBittensorの動作例を示します。
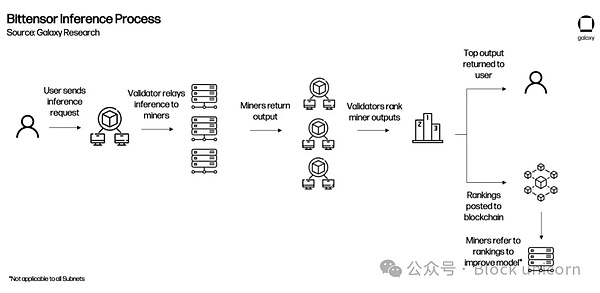
サブネットは、ルートネットワークによって評価されたパフォーマンスに基づいてTAOを獲得します。ルートネットワークはすべてのサブネットの上に位置し、基本的に特別なサブネットとして機能し、64の最大のサブネットバリデータによって公平に管理されます。ルートネットワークバリデーターは、サブネットをそのパフォーマンスに基づいてランク付けし、定期的にTAO排出量をサブネットに割り当てる。このようにして、個々のサブネットはルートネットワークの採掘者として機能する。
Bittensor s Outlook
Bittensorは、複数のサブネットにわたるインテリジェントな生成を奨励するためにプロトコルの機能を拡張しているため、まだ成長痛を経験しています。Bittensorは、複数のサブネットにまたがるインテリジェントな生成にインセンティブを与えるためにプロトコルの機能を拡張しているため、まだ成長中の痛みを経験しています。マイナーは、より多くのTAO報酬を得るためにネットワークを攻撃する新しい方法を常に考案しています。たとえば、モデル実行で高評価を得た推論の出力をわずかに修正し、複数の亜種を提出することなどです。ネットワーク全体に影響を与えるガバナンスの提案は、Opentensor Foundation関係者のみで構成されるTriumvirateによってのみ提出され、実施されることができる(提案は、実施前にBittensor Validatorsで構成されるBittensor Senateの承認を得る必要があることは注目に値する)。プロジェクトのトークンエコノミーは、サブネット間でのTAO利用のインセンティブを向上させるために修正されている。このプロジェクトはまた、最も人気のあるAIサイトの1つであるHuggingFaceのCEOが、Bittensorはこのサイトにリソースを追加すべきだと述べるなど、そのユニークなアプローチで急速に知名度を上げています。
コア開発者による最近の記事では、「Bittensorパラダイム」と題し、チームはBittensorが最終的に次のように進化するビジョンを示している。"何が測定されているのかに不可知論的"。理論的には、これによってBittensorは、TAOがサポートするあらゆるタイプの行動を動機づけるサブネットを開発できるようになる。最も重要なことは、これらのネットワークがこのような多様なプロセスを処理するために拡張できること、そして潜在的なインセンティブが中央集権的な製品を超えて進歩を促進することを証明することです。
AIモデルのための分散型コンピュートスタックの構築
上記のセクションでは、開発中のさまざまなタイプの分散型AIコンピュートプロトコルの詳細な概要を説明します。.開発と採用の初期段階では、DeFiの「Money Lego」コンセプトのような「AIビルディングブロック」の作成を最終的に促進できるエコシステムの基盤を提供します。パーミッションレス・ブロックチェーンの複合可能性は、より包括的な分散型AIエコシステムを提供するために、各プロトコルが別のプロトコルの上に構築される可能性を開く。
例えば、これはAkash、Gensyn、Bittensorが推論リクエストに応答するために相互作用する一つの方法です。
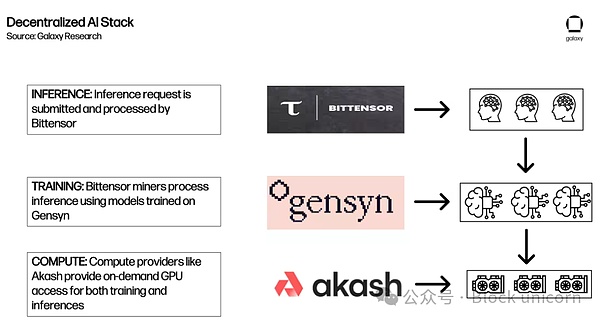
これは将来起こりうることの一例に過ぎません。
これは将来起こりうることの一例であり、現在のエコシステムや既存のパートナーシップ、起こりうる結果を表しているわけではありません。相互運用性の限界と以下に述べるその他の考慮事項により、今日の統合の可能性は大きく制限されている。 その上、流動性の断片化と複数のトークンを使用する必要性は、AkashとBittensorの両創設者が指摘したように、ユーザーエクスペリエンスに悪影響を及ぼす可能性があります。
その他の分散型サービス
コンピューティング以外にも、暗号通貨の新興AIエコシステムをサポートするために、いくつかの分散型インフラサービスが開始されています。エコシステムをサポートするために開始されました。これらすべてをリストアップすることは本レポートの範囲を超えていますが、いくつかの興味深い、例示的な例を挙げます。
Ocean: 分散型データマーケットプレイスです。ユーザーは自分のデータを表すデータNFTを作成し、データトークンを使って購入することができます。ユーザーは自分のデータを収益化し、より大きな主権を持つと同時に、AIチームにモデルの開発と訓練に必要なデータへのアクセスを提供することができる。
Grass:帯域幅の分散型マーケットプレイス。ユーザーは余った帯域幅をAI企業に売ることができ、AI企業はそれを使ってインターネットからデータを取得する。Wyndネットワーク上に構築され、個人が帯域幅を収益化できるだけでなく、帯域幅の買い手に、個々のユーザーがオンラインで見ているもの(個人のインターネットアクセスは多くの場合、IPアドレスに合わせて特別に調整されているため)のより多様なビューを提供する。)
HiveMapper:は、日常の運転手から収集した情報を使って、分散型のマッピング製品を構築しています。HiveMapperは、ユーザーのダッシュボードカメラから収集された画像を解釈するためにAIに依存しており、強化人間学習フィードバック(RHLF)を通じてAIモデルの微調整を支援することで、ユーザーにトークンで報酬を与える。
全体として、これらはAIモデルやその開発に必要な周辺インフラをサポートする分散型マーケットプレイスモデルを探求するほぼ無限の機会を指し示しています。現在、これらのプロジェクトのほとんどは概念実証の段階にあり、本格的なAIサービスを提供するのに必要な規模で運営できることを証明するには、さらなる研究開発が必要です。
展望
分散コンピューティング製品はまだ開発の初期段階にある。最も強力なAIモデルをトレーニングできる最先端のコンピューティングパワーを、製品として展開し始めているところです。有意義な市場シェアを獲得するためには、中央集権型の代替製品に対する具体的な優位性を示す必要がある。
GPU supply/demand. GPUの希少性は、急速に増大するコンピュート需要と相まって、GPUの軍拡競争につながっています。OpenAIはすでに、GPUの制限のためにプラットフォームへのアクセスを一時的に制限しており、AkashやGensynなどのプラットフォームは、ハイパフォーマンス・コンピューティングを必要とするチームにコスト競争力のある代替手段を提供することができます。今後6~12カ月は、分散コンピューティング・ベンダーにとって、より広範な市場へのアクセスがないために分散型製品の検討を余儀なくされている新規ユーザーを引きつける、特にまたとないチャンスとなる。MetaのLLaMA2のようなますます高性能になるオープンソースモデルと相まって、ユーザーは、計算リソースが主要なボトルネックとなるような、効率的に微調整されたモデルを展開する上で、もはや同じハードルに直面することはない。しかし、プラットフォームの存在自体が、十分な計算機供給とそれに対応する消費者需要を保証するわけではない。ハイエンドGPUの調達は依然として困難であり、需要側にとってコストは必ずしも主要な動機とはならない。これらのプラットフォームは、粘着性の高いユーザーを獲得するために、分散型コンピューティングのオプション(コスト、検閲への耐性、稼働時間や回復力、アクセスしやすさなど)を使用する具体的な利点を実証する必要があります。GPUインフラへの投資と構築は、驚くべきスピードで進んでいます。
規制。規制は依然として分散コンピューティングの動きの足かせとなっています。短期的には、明確な規制がないということは、プロバイダーとユーザーの両方が、これらのサービスを利用する際の潜在的なリスクにさらされていることを意味します。プロバイダーがコンピューティングを提供したり、買い手が知らずに制裁を受けた団体からコンピューティングを購入したりしたらどうなるでしょうか。利用者は、中央集権的な事業体の統制や監視を欠く分散型プラットフォームの利用をためらうかもしれない。プロトコルは、プラットフォームに制御を組み込んだり、既知の計算ベンダーのみにアクセスするフィルタ(Know-Your-Customer(KYC)情報の提供)を追加することで、こうした懸念を軽減しようとしているが、コンプライアンスを確保しながらプライバシーを保護するには、より強固なアプローチが必要である。短期的には、このような懸念に対処するため、プロトコルへのアクセスを制限するKYCおよびコンプライアンス・プラットフォームが出現する可能性が高い。さらに、米国における新たな規制の枠組みの可能性をめぐる議論(安全でセキュアで信頼できる人工知能の開発と利用に関する大統領令の発表がその最たる例)は、GPUへのアクセスをさらに制限する規制措置の可能性を浮き彫りにしています。
検閲。規制は双方向に機能し、分散型コンピューティング製品はAIへのアクセスを制限する行動から恩恵を受けることができます。大統領令に加えて、OpenAIの創設者であるサム・アルトマンは、AI開発を許可する規制当局の必要性について議会で証言した。AI規制に関する議論は始まったばかりだが、AI機能へのアクセスを制限したり検閲したりするような試みは、そのような障壁を持たない分散型プラットフォームの採用を加速させる可能性がある。11月に行われたOpenAIのリーダー交代(またはその欠如)は、最も強力な既存のAIモデルに対する意思決定権を一部の人間に与えることのリスクをさらに実証した。加えて、すべてのAIモデルは、意図的か意図的でないかにかかわらず、それを作成した人々のバイアスを必然的に反映する。このようなバイアスを排除する1つの方法は、モデルを微調整やトレーニングに対して可能な限りオープンにし、誰でも、どこでも、あらゆるタイプやバイアスのモデルにアクセスできるようにすることです。
データのプライバシー。分散型コンピューティングは、ユーザーにデータの自律性を提供する外部のデータおよびプライバシー・ソリューションと統合された場合、集中型の代替案よりも魅力的になる可能性があります。サムスンは、エンジニアがチップ設計を支援するためにChatGPTを使用し、機密情報をChatGPTに漏らしていたことに気づき、被害者となりました。 Phala NetworkとiExecは、ユーザーデータを保護するためにSGXセキュアなエンクレーブを提供すると主張しており、現在進行中の完全ホモモーフィック暗号化の研究は、プライバシーを保証する分散コンピューティングをさらに解き放つ可能性があります。AIがより生活に溶け込むようになるにつれ、ユーザーはプライバシー保護されたアプリケーション上でモデルを実行できることをより重視するようになるだろう。ユーザーはまた、あるモデルから別のモデルへデータをシームレスに移植できるように、データの複合性をサポートするサービスを必要とするでしょう。
ユーザーエクスペリエンス(UX)。UXは、あらゆる種類の暗号アプリケーションやインフラをより広く採用する上で、依然として大きな障壁となっています。これは、分散型コンピューティングの提供においても変わりはなく、場合によっては、開発者が暗号通貨やAIを理解する必要性によって悪化することもあります。ブロックチェーンとのインタラクションの組み込みや抽出など、基本的なところから改善しなければ、現在のマーケットリーダーと同じような高品質のアウトプットを提供することはできない。安価な製品を提供する相互運用可能な分散型コンピューティング・プロトコルの多くが、通常の利用が難しいことを考えれば、これは明らかだ。
スマートコントラクトとzkML
スマートコントラクトは、あらゆるブロックチェーンエコシステムの中核となるビルディングブロックです。特定の条件セットが与えられれば、実行を自動化し、信頼できる第三者の必要性を削減または排除することで、DeFiのような複雑な分散型アプリケーションの作成を可能にします。しかし、スマートコントラクトは、更新されなければならない事前定義されたパラメーターに基づいて実行されるため、その機能性にはまだ限界がある。
例えば、貸し借りプロトコルを展開するスマートコントラクトには、特定の貸借比率に基づいてポジションを清算するタイミングの仕様が含まれています。静的な環境では有用だが、リスクが常に変化する動的な状況では、これらのスマートコントラクトはリスク許容度の変化に適応するために継続的に更新されなければならない。例えば、分散型のガバナンス・プロセスに依存するDAOは、システミック・リスクに対処するのに十分迅速に反応できない可能性がある。
人工知能(機械学習モデルなど)を統合したスマートコントラクトは、全体的なユーザーエクスペリエンスを向上させながら、機能性、安全性、効率性を高める可能性のある方法の1つです。しかし、これらのスマートコントラクトを支えるモデルが悪用されないようにしたり、ロングテールの状況(データ入力の希少性を考えるとモデルを訓練するのは難しい)を考慮したりすることは不可能であるため、これらの統合にはさらなるリスクも存在します。
ゼロ知識機械学習(zkML)
機械学習は、複雑なモデルを実行するために大量の計算を必要とするため、AIモデルは高コストで実行不可能です。スマート・コントラクトで直接実行することもできる。例えば、ユーザーに収益最適化モデルを提供するDeFiプロトコルは、法外なガス料金を支払わなければ、オンチェーンでモデルを実行することは難しい。一つの解決策は、基礎となるブロックチェーンの計算能力を高めることだ。しかし、これではチェーン検証者の要件が増え、分散型の性質が損なわれる可能性がある。その代わりに、一部のプロジェクトではzkMLを使用して、チェーン上での集中的な計算を必要とせずに、非信頼の方法で出力を検証することを模索している。
zkMLの有用性を示す一般的な例として、ユーザーが他の誰かにデータをモデルを通して実行させ、その相手が実際に正しいモデルを実行したことを検証する必要がある場合があります。zkML は、計算プロバイダーがデータをそのモデルで実行し、入力からモデルの出力が正しいことを示す証明を生成し、オンチェーンで検証することを可能にします。この場合、モデル提供者は、出力を生成する基礎となる重みを開示することなくモデルを提供できるという利点があります。
逆のことも可能です。ユーザーが自分のデータを使ってモデルを実行したいが、プライバシーの問題からモデルを提供するプロジェクトが自分のデータにアクセスすることを望まない場合(例:健康診断や独自のビジネス情報の場合)、ユーザーはデータを共有することなく自分のデータでモデルを実行し、正しいモデルを実行したことを証明で検証することができます。このような可能性により、AIとスマートコントラクト機能の統合のための設計空間が、禁止された計算上の制約に対処することで大きく広がります。
インフラとツール
zkML空間の初期の状態を考えると、開発は主に、チームがモデルと出力を検証可能な証明に変換するために必要なインフラとツールを構築することに集中しています。チェーン上で検証可能な証明に変換するために、チームが必要とするインフラやツールを構築することに主眼が置かれている。これらの製品は、開発における知識ゼロの側面を可能な限り引き出します。
EZKLとGizaは、機械学習モデル実行の検証可能な証明を提供することで、このツールを構築する2つのプロジェクトです。どちらも機械学習モデルを構築するチームを支援し、チェーン上で信頼できる方法で結果を検証できる形で実行できるようにします。両プロジェクトは、TensorFlowやPytorchのような汎用言語で書かれた機械学習モデルを標準フォーマットに変換するために、Open Neural Network Exchange(ONNX)を使用している。ezklはオープンソースでzk-SNARKSを生成し、Gizaはクローズドソースでzk-STARKSを生成します。どちらのプロジェクトも、現時点ではEVMとしか互換性がありません。
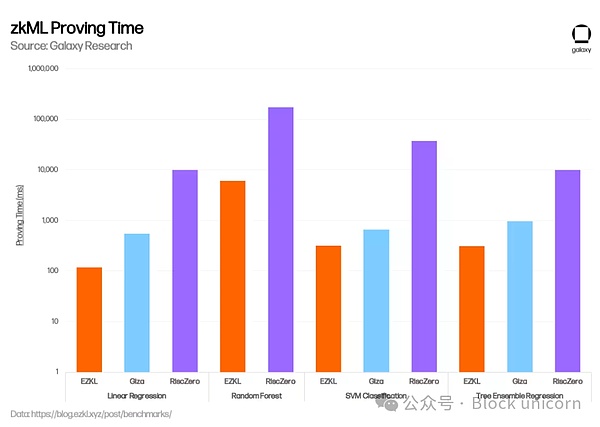
過去数ヶ月間、ezklはその強化において大きな進歩を遂げました。zkMLソリューションは、主にコスト削減、セキュリティの向上、プルーフ生成のスピードアップに重点を置き、ここ数カ月の間に大きな進歩を遂げました。例えば、2023年11月、EZKLは新しいオープンソースのGPUライブラリを統合し、集約された証明時間を35%短縮しました。また、1月には、EZKLの証明を使用する際にHPCクラスターを統合し、並行ジョブシステムをオーケストレーションするためのソフトウェアソリューションであるLilithをリリースしました。Gizaのユニークな点は、検証可能な機械学習モデルを作成するためのツールを提供することに加えて、Web3に相当するHugging Faceを実装し、zkMLのコラボレーションとモデル共有のためのユーザー・マーケットプレイスをオープンし、最終的には分散コンピューティング製品を統合することを計画している点である。EZKLは1月に、EZKL、Giza、RiscZero(後述)のパフォーマンスを比較したベンチマーク評価を発表した。

モジュラス・ラボはまた、AIモデルに特化した新しいzk証明技術に取り組んでいます。 Modulusは、AIモデルのzk証明を改善する能力とボトルネックを特定するために、当時既存のzk証明システムをベンチマークした「The Cost of Intelligence」(AIモデルのオンチェーン実行は非常に高価であることを示唆する)という論文を発表しました。 2023年1月に発表されたこの論文は、既存の製品がAIアプリケーションを大規模に実現するにはあまりにも高価で非効率的であることを示した。 最初の研究を基に、Modulusは11月にRemainderを発表した。Remainderは、AIモデルのコストと証明時間を削減するために特別に設計されたゼロ知識証明器で、スマートコントラクトにモデルを大規模に統合するプロジェクトを経済的に実行可能にすることを目標としている。 彼らの研究はクローズドソースであるため、上記のソリューションとベンチマークを比較することはできないが、最近、暗号とAIに関するヴィタリックのブログ記事で引用された。
ツールやインフラの開発は、必要なzkチームと検証可能なオフチェーン計算を実行する回線を配備する必要があるという摩擦を大幅に軽減するため、zkMLスペースの将来の成長にとって非常に重要です。機械学習に取り組んでいる非暗号化ネイティブ・ビルダーが、そのモデルをチェーン上に持ち込むことを可能にするセキュアなインタフェースを作成することで、アプリケーションの真に斬新なユースケースでより大きな実験が可能になります。このツールはまた、zkMLをより広く採用するための主な障壁の1つ、すなわちゼロ知識、機械学習、暗号の交差点での作業に興味を持つ知識豊富な開発者の不足にも対処します。
コプロセッサ
開発中の他のソリューション(「コプロセッサ」と呼ばれる)には次のようなものがあります。これらのネットワークは、チェーン上のチェーン外の計算の検証など、さまざまな役割を果たします。EZKL、Giza、Modulusと同様に、これらのコプロセッサの目標は、ゼロ知識証明生成のプロセスを完全に抽出することであり、基本的にオフチェーン手続きを実行し、オンチェーン検証証明を生成できるゼロ知識仮想マシンを作成することである。モデルで使用するために特別に構築されています。
Infernetは Ritual の最初のインスタンスであり、開発者が推論要求をネットワークに提出し、出力と証明を(オプションで)受け取ることを可能にする Infernet SDK を含みます。Infernet のノードはこれらの要求を受け取り、出力を返す前にダウン・ザ・チェーンの計算を処理する。たとえば、DAOは、すべての新しい統治提案が提出される前に一定の前提条件を満たすことを保証するプロセスを作成することができる。新しい提案が提出されるたびに、ガバナンス契約は DAO の特定のガバナンスによって訓練された AI モデルを呼び出す Infernet 経由の推論要求をトリガーします。モデルはすべての必要な基準が提出されていることを確認するために提案をレビューし、提案の提出を承認または拒否するための出力と証拠を返します。
来年にかけて、RitualチームはRitual Superchainと呼ばれるインフラ層を形成する追加機能を展開する予定だ。Ritualチームは証明を生成するためにEZKLと統合しており、近いうちに他の主要ベンダーの機能を追加する可能性がある。 Ritual上のInfernetノードは、Bittensorサブネットで訓練されたクエリーモデルだけでなく、Akashやio.net GPUも使用できる。Bittensorサブネットで訓練されたモデル。彼らの最終的な目標は、オープンなAIインフラストラクチャのプロバイダーとして選ばれるようになることであり、あらゆるネットワーク上で、あらゆるワークロードに対して、機械学習やその他のAI関連のタスクを提供できるようになることである。
アプリケーション
zkMLは、本質的にリソースに制約のあるブロックチェーンと、大量の計算とデータを必要とするAIとの間の緊張を調整するのに役立ちます。の間の緊張を調整するのに役立つ。イーサリアムの初期の頃、スマート・コントラクトのユースケースは何かと問われたときのようなものだ。" しかし、前述したように、今日の開発は主にツールとインフラレベルで行われている。アプリはまだ探索段階にあり、チームはzkMLを使ってモデルを実装することで生まれる価値が、その複雑さとコストを上回ることを証明することに挑戦している。
現在のアプリケーションには次のようなものがあります:
分散型金融。
ゲーム。
アイデンティティ、出所、プライバシー。暗号通貨は、真正性を検証する手段として、またAIが生成/操作したコンテンツや深い偽造の増加に対抗する手段として、すでに使用されています。将来的には、バイオメトリクスIDは、暗号化されたストレージを使用し、ローカルで実行されるバイオメトリクスの認証に必要なモデルを使用して、個人デバイス上でセルフホストすることができます。そうすれば、ユーザーは自分の身元を明かすことなくバイオメトリクスの証拠を提供できるため、魔女の攻撃をかわしながらプライバシーを確保することができる。これはまた、病気を検出するために医療データ/画像を分析するモデルを使用したり、出会い系アプリで性格を確認したり、マッチングアルゴリズムを開発したり、金融情報を確認する必要がある保険機関や融資機関など、プライバシーが必要とされる他の推論にも適用できる。
展望
zkMLはまだ実験段階にあり、ほとんどのプロジェクトはインフラプリミティブの構築と概念実証に集中しています。今日の課題には、計算コスト、メモリ制約、モデルの複雑さ、限られたツールやインフラ、開発者の才能などがあります。つまり、zkMLが消費者向け製品に必要な規模で実装されるまでには、かなりの作業が必要なのです。
しかし、この分野が成熟し、これらの制限が解決されれば、zkMLはAIと暗号の統合の重要な要素になるでしょう。基本的にzkMLは、オンチェーン・オペレーションと同じかそれに近いセキュリティ保証を維持しながら、あらゆる規模のオフチェーン計算をチェーン上に導入できることを約束している。しかし、このビジョンが実現されるまでは、この技術の初期ユーザーは、zkMLのプライバシーとセキュリティを、代替手段の効率と比較検討する必要があります。
人工知能エージェント
AIと暗号通貨の最もエキサイティングな統合の1つは、現在進行中のAIエージェントの実験です。エージェントは、AIモデルを使用してタスクを受信、解釈、実行できる自律型ロボットです。これは、あなたの好みに合わせて微調整された、すぐに利用可能なパーソナル・アシスタントを持つことから、あなたのリスク選好に基づいてポートフォリオを管理・調整する金融エージェントを雇うことまで、何でもあり得る。
暗号通貨は無許可で非信頼の決済インフラを提供するため、エージェントと暗号通貨は相性が良い。トレーニング後、エージェントにはウォレットが与えられ、スマートコントラクトを使って自分で取引ができるようになる。例えば、今日のエージェントはインターネット上の情報を取得し、モデルに基づいて予測市場で取引することができる。
エージェントプロバイダー
Morpheusは、2024年にイーサとArbitrumで稼働する最新のオープンソースエージェントプロジェクトの1つです。2023年9月に匿名で発表されたホワイトペーパーは、コミュニティが形成され、(エリック・ヴォーヒーズのような著名人を含む)コミュニティが構築される基礎を提供しています。このホワイトペーパーには、ダウンロード可能なスマートエージェントプロトコルが含まれている。これは、ローカルで実行され、ユーザーのウォレットによって管理され、スマートコントラクトと相互作用するオープンソースのLLMである。このプロトコルはスマートコントラクトのランキングを使用し、エージェントが処理されたトランザクションの数などの基準に基づいて、どのスマートコントラクトとやりとりするのが安全かを判断するのに役立ちます。
ホワイトペーパーはまた、スマートエージェントプロトコルを機能させるために必要なインセンティブ構造やインフラストラクチャなど、モーフィアスネットワークを構築するためのフレームワークも提供している。これには、エージェントと相互作用するためのフロントエンドを構築する貢献者へのインセンティブ、エージェント同士が相互作用できるようにエージェントにプラグインするアプリケーションを構築する開発者向けのAPI、エージェントの実行に必要なコンピュートやエッジデバイス上のストレージへのアクセスをユーザーに提供するクラウドソリューションなどが含まれる。プロジェクトの初期資金調達は2月初旬に開始され、完全な契約は2024年の第2四半期に開始される予定です。
Decentralised Autonomous Infrastructure Network(DAIN)は、Solana上にエージェント間エコノミーを構築する新しいエージェントインフラストラクチャプロトコルです。 DAINの目標は、異なる企業のエージェントが共通のAPIを通じてシームレスに相互作用できるようにすることで、AIエージェントの設計空間を劇的に開放することです。DAINの目標は、異なる企業のエージェントが共通のAPIを通じてシームレスに相互作用できるようにすることで、AIエージェントの設計空間を大幅に開放することであり、特にWeb2およびWeb3製品と相互作用できるエージェントの実現に重点を置いている。DAINは1月、アセット・シールドとの初のコラボレーションを発表し、ユーザーが設定したルールに基づいて取引を解釈し、承認/拒否できる「代理署名者」をマルチ署名に追加できるようにした。
Fetch.AIは、最初に導入されたAIプロキシプロトコルの1つであり、FETトークンとFetch.AIウォレットを使用してオンチェーンでプロキシを構築、導入、使用するためのエコシステムを開発しました。このプロトコルは、プロキシと対話し、プロキシを注文するためのウォレット内機能を含む、プロキシを使用するためのツールとアプリケーションの包括的なセットを提供します。
Fetchチームの元メンバーを創設者に持つAutonolasは、分散型AIエージェントの作成と使用のためのオープンマーケットプレイスです。オートノラスはまた、ポリゴン、イーサリアム、グノーシス・チェーン、ソラナなどの複数のブロックチェーンにプラグイン可能な、オフチェーンホストAIエージェントを構築するための一連のツールを開発者に提供している。彼らは現在、予測市場やDAOガバナンスを含む、エージェントのための多くのアクティブな概念実証製品を持っている。
SingularityNetはAIエージェントのための分散型マーケットプレイスを構築しており、そこで人々は、複雑なタスクを実行するために他の人々やエージェントに雇われることができるフォーカスされたAIエージェントを展開することができる。他の企業はNFTと統合するAIエージェントを構築している。ユーザーはNFTにランダムな属性を持たせることで、さまざまなタスクに長所と短所を持たせることができる。これらのエージェントは、ゲームやDeFi、仮想アシスタントとして使用したり、他のユーザーと取引したりするために、特定の属性を強化するように訓練することができます。
全体として、これらのプロジェクトは、タスクを実行するだけでなく、汎用AIの構築を支援するために一緒に働くことができるインテリジェンスの将来のエコシステムを想定しています。真に洗練されたエージェントは、あらゆるユーザータスクを自律的に実行する能力を持つだろう。例えば、完全に自律的なエージェントは、APIを使用する前にエージェントが外部API(例えば旅行予約サイト)と統合されていることを確認することなく、APIを統合するために他のエージェントを雇う方法を見つけ出し、タスクを実行することができるようになる。ユーザーから見れば、エージェントがタスクを完了できるかどうかを確認する必要はありません。
ビットコインと人工知能エージェント
2023年7月、ライトニングラボは、ライトニングネットワーク上でエージェントを使用するための概念実証の実装を発表しました。LangChain's Bitcoin Suite」と呼ばれる。この製品が特に興味深いのは、Web 2の世界で大きくなっている問題、つまりWebアプリのためのゲート化された高価なAPIキーを解決することを目指しているからだ。
LangChainは、エージェントがビットコインを売買・保有したり、APIキーを照会したり、マイクロペイメントを送信したりできるツール群を開発者に提供することで、この問題を解決します。マイクロペイメントは、従来の決済トラックでは手数料のためにコストがかかるが、ライトニングネットワークでは、エージェントは最小限の手数料で1日あたり無制限にマイクロペイメントを送信できる。LangChainのL402ペイメントメータリングAPIフレームワークと併用することで、企業はコストのかかる単一の基準を設定するのではなく、使用量の増減に応じてAPIへのアクセスコストを調整することができます。
オンチェーンでの活動がスマートとスマートが相互作用することによって支配される未来では、スマートがコストが法外にならない方法で相互作用できることを保証するために、このようなものが必要になるでしょう。これは、無許可で費用対効果の高い支払いトラックでプロキシを使用することで、新しい市場と経済的相互作用の可能性がどのように開かれるかを示す初期の例である。
展望
エージェントの分野はまだ始まったばかりです。プロジェクトは、単純なタスクを処理するためにインフラストラクチャを使用できる機能的なエージェントを展開し始めているところです。しかし、時間の経過とともに、AIエージェントが暗号通貨に与える最も大きな影響の1つは、あらゆる業種におけるユーザー体験の向上である。取引はクリックベースからテキストベースに移行し始め、ユーザーはLLMを通じてオンチェーン・エージェントとやり取りできるようになる。Dawn Walletなどのチームはすでに、ユーザーがオンチェーンでやり取りできるチャットボット・ウォレットを立ち上げている。
さらに、金融トラックは24時間365日稼働したり、シームレスなクロスボーダー取引を行うことができない規制された銀行機関に依存しているため、エージェントがWeb 2でどのように機能するかは不明です。Lyn Aldenが強調しているように、暗号トラックは払い戻しがなく、マイクロトランザクションを処理できるため、クレジットカードと比較して特に魅力的である。しかし、プロキシがより一般的な取引形態となった場合、既存の決済プロバイダーやアプリは、既存の金融レール上で動作するために必要なインフラを実装するために迅速に動く可能性が高く、暗号通貨を使用する利点の一部が損なわれる可能性があります。
現在、プロキシは、所定の入力が所定の出力を保証する決定論的な暗号通貨取引に限定される可能性がある。どちらのモデルも、これらのエージェントが複雑なタスクを実行する方法を見つけ出す能力を特定するものであり、ツールはエージェントが達成できる範囲を拡大するものである。暗号化エージェントがオンチェーン暗号の斬新なユースケースを超えて有用になるには、より広範な統合と、決済形態としての暗号の受け入れ、規制の明確化が必要である。しかし、これらのコンポーネントが進化するにつれて、プロキシは上記の分散コンピューティングとzkMLソリューションの最大の消費者の1つになり、自律的で非決定論的な方法であらゆるタスクを受け取り、解決する準備が整っています。
結論
AIは、ウェブ2で見たのと同じイノベーションを暗号通貨に導入し、インフラ開発からユーザーエクスペリエンスやアクセシビリティまで、あらゆるものを強化します。という側面がある。しかし、このプロジェクトはまだ開発の初期段階にあり、暗号通貨とAIの統合は近い将来、オフチェーン統合が主流になるだろう。
Copilotのような製品は開発者を「10倍効率的に」するだろうし、Layer 1やDeFi appsはマイクロソフトのような大手企業と提携し、AI支援開発プラットフォームを立ち上げている。Cub3.aiやTest Machineなどの企業は、スマートコントラクトの監査やリアルタイムの脅威監視のためのAI統合を開発し、オンチェーンセキュリティを強化しており、LLMチャットボットはオンチェーンデータ、プロトコル文書、トレーニング用アプリを使用して、アクセシビリティとユーザーエクスペリエンスを強化している。
暗号通貨の基盤技術を真に活用する、より高度な統合については、AIソリューションをオンチェーンで実装することが技術的に実現可能であり、経済的にも実行可能であることを証明することが課題として残っています。分散型コンピューティング、zkML、AIエージェントの開発は、暗号通貨とAIが深く相互接続された未来への土台を築く有望な分野を指し示しています。
フラクタル・ビットコインは、世界で最も安全で広く保持されているブロックチェーンの上に構築された、ビットコインのコアコードそのものを使用して、無限のレイヤーを再帰的に拡張する唯一のビットコイン・スケーリング・ソリューションです。
JinseFinanceRollupのスケーラビリティの限界と、それを最大化するための決定オプションについて学ぶ。
JinseFinance政府がするあらゆる悪いことは、彼らがマネーサプライをコントロールしているからに他ならない。
JinseFinance2024年5月9日から10日まで、香港のカイタック・クルーズ・ターミナルでビットコイン・アジアが開催される。このカンファレンスには業界のビッグネームが多数集まりますが、Golden Financeでは安心してカンファレンスに参加できるようガイドをまとめました。
JinseFinanceビットコインのエコシステムにおける業界の現状、Bitcoin Magazineが提案するLayer2の定義についての考え、そしてビットコインのLayer2をどのように判断するかについてのあなた自身の考え。
JinseFinance汎用の計算スマートコントラクトのためのビットコイン上のLayer2は、スマートコントラクトをセキュアにするためにビットコインネットワークに頼ることができないため、常に課題となっている。
JinseFinance自 2023 年年初 Ordinals 开启 Bitcoin 的 NFT 试验以来,如何在 Bitcoin 上创立丰富的去中心化用例项目,成为行业关注的热点。
 MarsBit
MarsBitこの拡大には、必ずしもメルカド ビットコインがメキシコを拠点とする仮想通貨取引所を買収して国内で運営することが含まれるわけではありません。
 Cointelegraph
Cointelegraphビットコイン SV はハード フォークに参加し、Terra UST の大失敗に粉塵が落ち着く中、悲惨な価格パフォーマンスを記録しています。
Cointelegraphこの仮想通貨取引所は以前、ブロックチェーンインフラストラクチャプラットフォームのBison TrailsとRoutefireプラットフォームの買収を発表した。
Cointelegraph