タイ証券取引委員会、投資信託と私募ファンドに暗号通貨投資の門戸を開く
タイの証券取引委員会(SEC)は、投資信託や私募ファンドが米国上場のETFを含む暗号通貨に投資できるよう、規制の近代化を進めている。この動きは、機関投資家を誘致し、市場の整合性とコンプライアンスを強化しながら、様々なデジタル資産に対する明確なルールを確立することを目的としている。
 Weatherly
Weatherly

なぜAIはオープンにする必要があるのか
「なぜAIはオープンにする必要があるのか?".私のバックグラウンドは機械学習で、キャリアの約10年間、さまざまな機械学習に取り組んできました。しかし、暗号や自然言語理解に手を出し、NEARを設立する前は、Googleで働いていました。グーグルを辞めた後、私は機械学習会社を立ち上げ、機械にプログラミングを教えることで、コンピューターとの関わり方を変えることができるようにした。しかし、2017年や18年にそれをしたわけではありません。時期尚早でしたし、当時はそれをするための計算能力やデータがなかったのです。

私たちが当時行っていたのは、世界中の人々を集めて、データにラベルを付ける作業をさせることでした。主に学生だった。彼らは中国、アジア、東ヨーロッパにいた。彼らの多くはこれらの国に銀行口座を持っていない。アメリカは簡単に送金することにあまり積極的ではないので、私たちはブロックチェーンを問題の解決策として使いたいと思い始めました。世界中の人々がどこにいても、プログラムされた方法で簡単に支払いができるようにしたかったのです。ところで、Cryptoの現在の課題は、NEARが多くの問題を解決してくれる一方で、通常、Cryptoを獲得するためにはブロックチェーン上で取引する前にCryptoを購入する必要があり、そのプロセスが裏目に出ていることです。
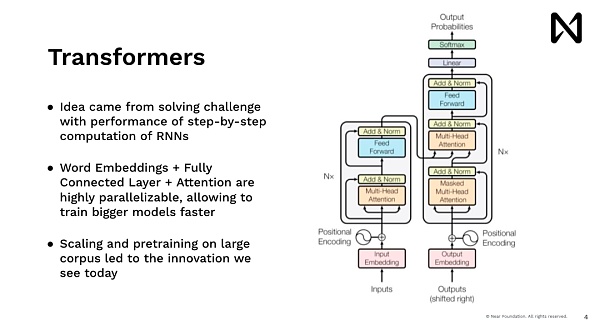
ビジネスと同じで、それを使うにはまず会社の株式を買う必要がある。これはNEARが解決しようとしている多くの問題のひとつだ。では、AIの側面をもう少し掘り下げてみましょう。言語モデリングは新しいものではなく、50年代から存在しています。自然言語ツールで広く使われている統計ツールです。2013年から長い間、ディープラーニングが再起動し、新しい種類のイノベーションが始まった。このイノベーションとは、単語をマッチングさせ、多次元ベクトルに加え、数学的な形に変換できるというものだ。これは、行列の掛け算と活性化関数をたくさん並べただけのディープラーニング・モデルでうまく機能した。

これにより、高度なディープラーニングを始めることができます。を開始し、多くの興味深いことを行うモデルを訓練することができます。振り返ってみると、当時私たちがやっていたのはニューロンニューラルネットワークで、人間を模倣したモデルで、一度に1つの単語を読み取るようなものでした。だから、とても時間がかかった。Google.comでユーザーに何かを示そうとする場合、答えを出す前にウィキペディアを5分も読んで待つ人はいないでしょう。つまり、ChatGPTやMidjourney、そして最近のすべての進歩を牽引しているモデルであるトランスフォーマーモデルは、データを並列処理し、推論し、すぐに答えを出せるものを持ちたいという同じ考えから来ているのです。
このアイデアの主な革新のひとつは、高度な並列計算能力を持つGPUやその他のアクセラレーターを活用して、すべての単語、すべてのトークン、すべての画像ブロックを並列処理することです。こうすることで、スケールの大きな推論が可能になります。このスケーリングによって、自動トレーニングデータを扱うトレーニングの規模を拡大することができました。その後に登場したのがDopamineで、これは短期間でトレーニングを爆発的に向上させるという素晴らしい仕事をした。膨大な量のテキストを持ち、世界の言語についての推論と理解において驚くべき結果を達成し始めた。
現在の方向性は、AIの技術革新を加速させることです。
以前は、データサイエンティストや機械学習エンジニアが使用するツールであり、それをどうにかして製品に反映させたり、意思決定者にデータの意味を伝えたりするものでした。それが今では、AIが人々と直接コミュニケーションをとるというモデルになっている。AIは製品の背後に隠れているため、自分がAIとコミュニケーションしていることに気づかないかもしれない。つまり、以前はAIがどのように機能するかを理解していた人々が、AIを理解し、活用できるようになったのです。

そこで、GPUを使用する際の背景を説明します。

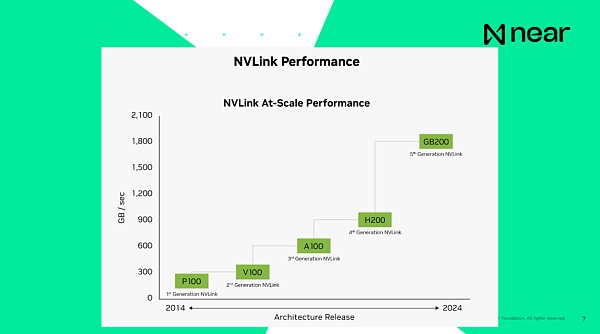
重要なのは、システムが相互接続されているということです。システムが互いに接続されていると言うとき、前世代である現在のH100の接続速度は毎秒900GBで、コンピューター内のCPUとRAMの接続速度は毎秒200GBで、どちらもコンピューターにローカルです。つまり、同じデータセンター内でGPUから別のGPUにデータを送信するのは、コンピューターよりも速いのです。コンピューターは基本的に、箱の中で単独で通信することができます。そして新世代は、基本的に毎秒1.8テラバイトで接続しています。開発者の観点からすると、これは個々のコンピューティング・ユニットではありません。これらは、非常に大規模な計算を提供するために、膨大な量のメモリと計算能力を持つスーパーコンピュータです。

さて、これが私たちが直面している問題につながります。これらの大企業は、リソースとモデルを構築する能力を持っており、私たちにこのサービスを提供してくれています。これはその一例です。完全に中央集権化されたプロバイダーに行き、クエリーを入力する。その結果、ソフトウェア・エンジニアリング・チームではなく、結果の表示方法を決定するチームがいくつかあることがわかった。どのデータをデータセットに入れるかを決めるチームがある。
たとえば、インターネットからデータをクロールしているだけなら、バラク・オバマがケニア生まれであることと、バラク・オバマがハワイ生まれであることの回数はまったく同じです。だから、何を基準にするかを決めなければならない。真実とは思えないからこそ、情報の一部をフィルターにかけることを決めなければならない。だから、もしこのような個人がどのようなデータを使用し、存在させるかを決めたとしたら、その決定はその決定者に大きく影響されることになる。著作権で閲覧できないものや違法なものを決める法務チームがいる。何が非倫理的で、何を表示すべきではないかを決める "倫理チーム "がいる。
つまり、ある意味、多くのフィルタリングと操作が行われているのです。これらのモデルは統計モデルです。データから取捨選択する。データに特定の内容がなければ、答えはわからない。データの中に何かがあれば、それを事実として受け取る可能性が高い。さて、AIから答えが返ってくると、それは心配になりますね。そうですね。今、あなたはモデルから答えを得ることになっていますが、保証はありません。結果がどのように生成されたかはわからない。会社があなたの特定のセッションを最高入札者に売って、実際に結果を変えるかもしれない。あなたがどの車を買うべきかを聞きに行き、トヨタがその結果としてトヨタを支持するべきだと判断し、トヨタがそのためにこの会社に10セントを支払うとします。

つまり、これらのモデルを中立的なものとして使用し、データの知識ベースを表現したとしても、その結果はトヨタに有利になります。そのため、これらのモデルを中立的なものとして、データの知識ベースを表現するために使用したとしても、実際には、結果を得る前に、非常に特定の方法で結果を偏らせるようなことがたくさん起こります。それが多くの問題を引き起こしているのです。これは基本的に、大企業とメディア、証券取引委員会(SEC)の間のさまざまな訴訟の1週間であり、今ではほとんどすべての人がお互いを訴えようとしている。そして、前向きに考えれば、問題は、大手のハイテク企業は常に収益を増やし続けるインセンティブを持っているということです。例えば、上場企業であれば、収益を報告し、成長し続ける必要があります。
そのためには、ターゲット市場をすでに獲得しているとして、20億人のユーザーを獲得したとしましょう。インターネット上に残っている新規ユーザーはそれほど多くはない。平均収益を最大化する以外の選択肢はあまりない。つまり、価値がまったくない可能性のあるユーザーからより多くの価値を引き出すか、彼らの行動を変える必要がある。ジェネレーティブAIは、ユーザーの行動を操作し、変化させることに長けている。そのため、規制圧力が強く、規制当局がこの技術の仕組みを十分に理解していないという、非常に危険な状況になっています。利用者を操作から守る手立てがほとんどないのです。

操作的なコンテンツ、誤解を招くようなコンテンツは、たとえ広告がなくても、利用者を操作することができます。広告がなくても、何かのスクリーンショットを撮ってタイトルを変え、ツイッターに投稿するだけで、人々は熱狂する。経済的なインセンティブがあるため、常に収益を最大化しなければならない。それに、グーグルの中で悪事を働いているわけでもないでしょう?どのモデルをローンチするかを決めるとき、AかBのテストを行い、どちらがより多くの収益をもたらすかを確認します。つまり、ユーザーからより多くの価値を引き出すことで、常に収益を最大化するわけです。そして、ユーザーやコミュニティは、そのモデルがどのようなもので、どのようなデータを使用し、実際に何を達成しようとしているのかについて、インプットすることはない。これがアプリ・ユーザーに起こることだ。それは条件付けなのだ。
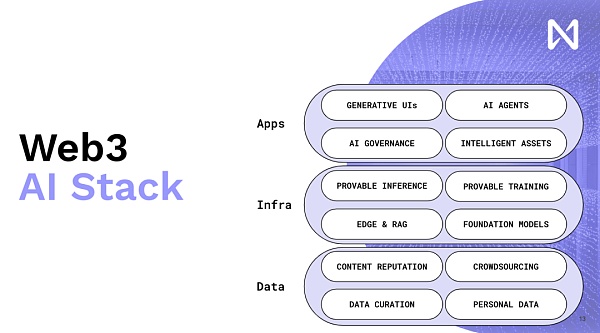
だからこそ、私たちはウェブ3とAIの融合を推し進めるのです。ウェブ3は、私たちに新しいインセンティブを与える方法を可能にする重要なツールであり、より良いソフトウェアや製品を分散型形態で生産するインセンティブを与えてくれます。

繰り返しになりますが、言語モデルは人々が情報を操作し利用する方法に大きな影響力と規模をもたらしましたが、これは純粋なAIの問題ではありません。あなたが欲しいのは、追跡可能で、追跡可能な暗号化された評判であり、それはあなたが異なるコンテンツを見たときに明らかになる。つまり、実際に暗号化され、あらゆるウェブサイトのあらゆるページで見つけることができるコミュニティ・ノードがあるとしよう。このようなモデルは、ほとんどすべてのコンテンツを読み、パーソナライズされた要約とパーソナライズされた出力を提供するようになるからだ。
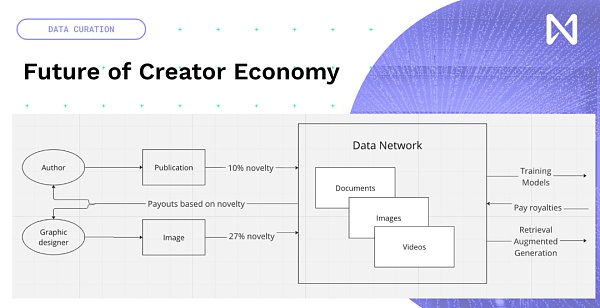
ですから、私たちは実際に新しい創造的なコンテンツを作成する機会があります。モデルの訓練と推論時間にまつわる新たなクリエイター・エコノミー。そこでは、新しい出版物であれ、写真であれ、YouTubeであれ、あなたが作った音楽であれ、人々が作ったデータは、それがモデルの訓練に貢献する度合いに基づいてネットワークに入る。そのため、コンテンツに応じて世界的に何らかの支払いが行われる可能性がある。目玉を集める広告ネットワークが牽引する経済モデルから、イノベーションと興味深い情報をもたらす経済モデルへと移行しつつあるのです。
ひとつ重要なことを申し上げると、不確実性の多くは浮動小数点演算に由来します。これらのモデルはすべて、多くの浮動小数点演算と乗算を伴います。これらは不確定性演算です。
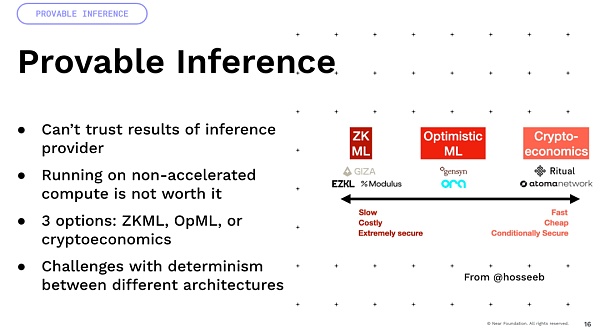
さて、これらを異なるアーキテクチャのGPUで乗算すると、次のようになります。乗算を実行するGPUのアーキテクチャが異なります。つまり、A100とH100では結果が異なるのです。ですから、暗号経済学や楽観主義のような決定論に依存する多くのアプローチは、実際には多くの困難にぶつかり、それを実現するためには多くのイノベーションが必要なのです。最後に、私たちはプログラマブル通貨やプログラマブル資産を構築してきましたが、そこにインテリジェンスを追加することを想像すれば、コードではなく、世界と相互作用する自然言語の能力によって定義されるスマート資産を手に入れることができるという興味深いアイデアがあります。そこで、多くの興味深い利回りの最適化、DeFi、世界の中での取引戦略が可能になるのです。

現在の課題は、すべての時事的な出来事には強いロバスト性がないことです。強いロバストな振る舞いをしないことだ。トレーニングは次のトークンを予測することを目的としているため、敵対的で強力になるように訓練されていないのです。したがって、すべてのお金を渡すようにモデルを説得するのは簡単です。次に進む前に、この問題を実際に解決することが非常に重要だ。私たちは今、岐路に立たされているということですね。クローズドなAIのエコシステムがあり、彼らは製品をローンチすると多くの収益を生み出し、その収益を製品の構築に回すため、極端なインセンティブとフライホイールを持っている。しかし、その製品は本質的に企業の収益を最大化するように設計されているため、ユーザーから引き出される価値も最大化される。あるいは、ユーザーが主導権を握る、オープンなユーザー所有のアプローチもある。

これらのモデルは、実際にあなたの利益を最大化しようと有利に働きます。このようなモデルは、あなたの利益を最大化するために、実際に有利に働きます。インターネット上に存在する多くの危険からあなたを守る方法を提供します。だからこそ、AI×暗号のさらなる開発と導入が必要なのです。ありがとうございました。
タイの証券取引委員会(SEC)は、投資信託や私募ファンドが米国上場のETFを含む暗号通貨に投資できるよう、規制の近代化を進めている。この動きは、機関投資家を誘致し、市場の整合性とコンプライアンスを強化しながら、様々なデジタル資産に対する明確なルールを確立することを目的としている。
Weatherlyサイバーセキュリティ企業Doctor Webは、28,000人以上のユーザーに影響を与えた正規のソフトウェアを装ったマルウェアを発見したと報告した。これは強盗の失敗なのだろうか、それとも単に攻撃者の不運なのだろうか?
 Catherine
Catherine韓国では、離婚訴訟において暗号通貨を夫婦の資産として認め、配偶者が有形・無形の資産を分割できるようにしている。これは、暗号通貨を財産と分類した2018年の最高裁判決に由来するもので、裁判所は離婚訴訟中に隠されたデジタル資産の価値を調査・判断することができる。
 Anais
Anais韓国の金融委員会は、暗号通貨取引所の最大手であるUpbitを調査している。Upbitは、資産の20%近くをUpbitの預金に依存しているK銀行に大きな影響を与えているとの懸念があるためだ。議員らは、Upbitに何らかの問題が発生すれば、K銀行への資金流出につながりかねないと懸念しており、両社の密接な関係に伴うリスクと暗号通貨市場における規制監督の必要性を強調している。
Anais2024年10月9日、世界的なビットコイン業界のイベント「Bitcoin 2024 Amsterdam Conference」がオランダ・アムステルダムのWestergasで盛大に開幕した。
 Alex
Alex木曜日(10月10日)、ビットコインは昨日下落傾向を続け、現在60,500ドル前後で取引されている。最新の連邦準備制度理事会(FRB)議事録ではハト派的なシグナルが発表されたものの、ビットコインを押し上げるには至らなかった。同時にマスク氏は、トランプ氏が選挙で負ければ、トランプ氏は終わり、ビットコインも終わり、Dogecoinも終わると露骨に発言した。
 Miyuki
Miyuki<nil>
 Weiliang
Weiliangソラナのゲーム・エコシステムは、ソラナのSonic SVMを介してTikTokに統合されたタップ・トゥ・アーニング・ゲームであるSonicXで成長している。Notcoinの成功に続き、SonicXはゲームとソーシャルメディアを融合させることで、新たなプレイヤー層の獲得を目指している。重要なのは、ノットコインの成功を反映するのか、それとも他の多くのゲームのように消えていくのか、ということだ。
Catherineリップル社は、8月7日の好意的な判決に異議を唱えるSECの10月2日の上訴に対し、クロスアピールを提出した。リップル社は現在、米国の高等裁判所に戦いを挑む構えだ。この長期化する法廷闘争に決着はつくのだろうか?
 Kikyo
Kikyoチャールズ・ホスキンソン氏は、カルダノを取り巻く否定的な感情に触れ、それはガバナンスの分散化と長年の問題への対処を目指すヴォルテール時代へのネットワークの移行に起因すると述べた。同氏は、カルダノの透明性と独自のガバナンスが他のブロックチェーンとは一線を画しており、イノベーション、プライバシー、長期的成長へのコミットメントを強化していると強調した。
Anais