NYDIG: 독일, 마운트곡스 및 채굴자 매도로 인한 BTC 하락이 과장된 이유
NYDIG의 그렉 시폴라로는 최근의 블록체인 움직임이 "비이성적인" 공포를 불러일으키고 투자자들에게 매수 기회를 제공했다고 말합니다.
 JinseFinance
JinseFinance

2022년, 저는 인터넷에서 공개적으로 크롤링된 데이터가 아닌 비공개 데이터를 사용하여 학습된 사용자 소유의 기본 모델에 대한 제안서를 썼습니다. 저는 공개 데이터(예: Wikipedia, 4Chan)를 사용하여 기본 모델을 훈련할 수는 있지만, 다음 단계로 나아가려면 접근 권한이나 로그인이 필요한 고립된 플랫폼(예: 트위터, 개인 메시징, 회사 정보)에만 존재하는 고품질의 개인 데이터가 필요하다고 주장했습니다.
이 예측은 현실화되기 시작했습니다. Reddit과 Twitter 같은 기업들은 플랫폼 데이터의 가치를 깨닫고 다른 기업들이 자사의 텍스트 데이터를 자유롭게 사용해 기본 모델을 학습시키지 못하도록 개발자 API(1, 2)를 잠그고 있습니다.
이것은 2년 전과 비교하면 큰 변화입니다. 벤처 캐피털리스트인 샘 레신은 이러한 변화를 다음과 같이 요약했습니다."[플랫폼]이 모든 쓰레기를 방치한 채 뒤편에 버리더니 갑자기 '젠장, 그 쓰레기가 금이잖아? 쓰레기가 너무 많아요. 쓰레기통을 잠가야겠어." 예를 들어, GPT-3는 찬성 투표가 3개(3, 4) 이상인 모든 Reddit 커밋 링크의 텍스트를 집계하는 WebText2에 대해 학습되었습니다. Reddit의 새로운 API를 사용하면 더 이상 이런 작업이 불가능합니다.
인터넷은 점점 더 개방되고 있으며, 고립된 플랫폼은 귀중한 교육 데이터를 보호하기 위해 더 큰 벽을 쌓고 있습니다.
개발자는 더 이상 이러한 데이터에 대규모로 액세스할 수 없지만 개인은 데이터 개인정보 보호 규정(5, 6)으로 인해 여전히 여러 플랫폼에서 자신의 데이터에 액세스하고 내보낼 수 있습니다. 플랫폼이 개발자 API를 잠그고 있는 반면 개인 사용자는 여전히 자신의 데이터에 액세스할 수 있다는 사실은 기회를 제공합니다. 1억 명의 사용자가 자신의 플랫폼 데이터를 내보내 세계 최대의 데이터 보고를 만들 수 있을까요? 이 데이터의 보고는 공유를 꺼리는 대기업과 기타 회사에서 수집한 모든 사용자 데이터를 한데 모을 수 있습니다. 이는 오늘날의 주요 기본 모델을 학습시키는 데 사용되는 데이터 세트보다 100배 더 큰, 지금까지 만들어진 것 중 가장 크고 포괄적인 학습 데이터 세트가 될 것입니다.1
기본 모델 학습 데이터 세트와 예제 사용자 데이터 세트를 비교한 대략적인 추정치입니다. 출처 및 계산.

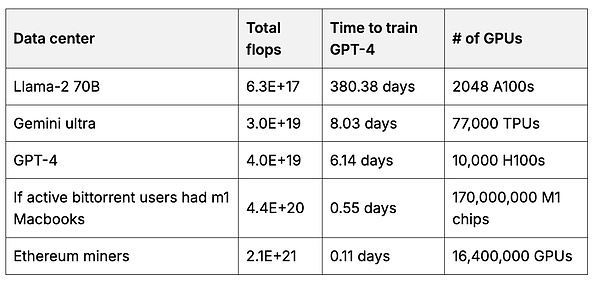
그런 다음 사용자는 더 많은 데이터를 사용하는 사용자 소유의 기본 모델을 만들 수 있습니다. 기본 모델을 훈련하려면 많은 GPU 연산이 필요합니다. 그러나 각 사용자는 자신의 하드웨어를 사용하여 모델의 작은 부분을 학습시킨 다음, 이러한 부분을 병합하여 더 크고 강력한 모델을 만들 수 있습니다(7, 8, 9 ).2 인센티브가 적절하면 사용자는 대량의 계산을 풀링할 수 있습니다. 예를 들어, 이더리움 채굴자는 선도적인 기본 모델을 훈련하는 데 사용되는 총 연산량의 50배에 달하는 연산량을 보유하고 있습니다.
이더 채굴자 GPU와 비교하여 기본 모델을 훈련하는 데 사용된 데이터 센터에서 수행한 총 부동 소수점 계산 수(초당 부동 소수점 계산 = 0.5)입니다. 모든 GPU의 "사고" 속도 합계)를 이더 채굴기 GPU와 비교한 것입니다.3 계산 소스.
모델에 기여하는 사용자는 공동으로 모델을 소유하고 모델을 관리합니다. 사용자들은 자신의 데이터가 모델을 얼마나 개선했는지에 따라 비례적으로 모델 사용에 대한 대가를 받을 수 있습니다. 집단은 누가 모델에 액세스할 수 있는지, 어떤 종류의 제어를 구현해야 하는지 등 사용 규칙을 설정할 수 있습니다. 각 국가의 사용자들이 각자의 이념과 문화를 반영하여 자신만의 모델을 만들 수도 있습니다. 또는 한 국가가 올바른 구분선이 아니며 각 네트워크 국가가 회원들의 데이터를 기반으로 자체적인 기본 모델을 갖는 세상을 보게 될 수도 있습니다.
저는 여러분이 기본 모델의 어떤 부분을 갖고 싶은지, 여러분이 사용하는 플랫폼에서 어떤 학습 데이터를 제공할 수 있을지 생각해 보시기를 권하고 싶습니다. 연구 논문, 미발표 아트웍, Google 문서, 데이트 프로필, 의료 기록, Slack 메시지 등 생각보다 많은 데이터를 보유하고 있을 것입니다. 이 모든 데이터를 한데 모으는 한 가지 방법은 개인 서버를 통해 로컬 LLM에서 개인 데이터를 쉽게 사용할 수 있도록 하는 것입니다. 향후에는 개인 서버를 사용자 기반 모델의 일부가 되도록 학습시킬 수도 있습니다.
기본 모델은 데이터와 연산에 많은 초기 투자가 필요하기 때문에 독점적인 경향이 있습니다. 몇 세대 뒤처진 오픈 소스 모델, 즉 대형 AI 기업의 잔재를 최대한 활용하는 쉬운 방법을 선택하기 쉽습니다. 하지만 몇 세대 뒤처져 남은 것을 먹는 것에 만족해서는 안 됩니다! 사용자로서 우리는 우리만의 최고의 모델을 만들어야 하며, 이를 실현할 수 있는 데이터와 컴퓨팅 파워를 가지고 있습니다.
AI가 점점 더 가치 있는 경제적 업무를 수행할 수 있게 되면서 엄청난 경제적 변화가 일어나고 있습니다. 대형 기술 기업들은 사용자의 공개 작업, 글, 예술 작품, 사진 및 기타 데이터와 다른 사람들의 데이터를 기반으로 AI 모델을 학습시켜 연간 수십억 달러의 수익을 창출하기 시작했습니다(1). 이제 이들은 공개 인터넷에서 접근할 수 없는 데이터를 노리고 있으며, Reddit과 같은 회사에서 사용자의 개인 데이터를 구매하여 연간 수조 달러의 AI 수익을 올리고 있습니다(2, 3 ).
데이터 DAO가 바로 여기에 있습니다. 데이터 DAO는 사용자가 데이터를 집계 및 관리하고 기여자에게 특정 데이터 세트의 소유권을 나타내는 데이터 세트별 토큰으로 보상할 수 있는 탈중앙화된 엔티티입니다. 일종의 데이터 연합이라고 할 수 있습니다. 이러한 데이터 세트는 대형 기술 기업이 수억 달러에 판매하는 데이터 세트를 복제하고 심지어 능가할 수도 있습니다(<그림 4> 참조). DAO는 데이터 세트를 임대하거나 익명화된 사본을 판매할 수 있는 옵션과 함께 데이터 세트에 대한 완전한 통제권을 갖습니다. 예를 들어, Reddit 데이터는 새로운 사용자 소유의 플랫폼에 친구, 과거 게시물 및 새로운 플랫폼에서 쉽게 사용할 수 있는 기타 데이터를 제공하는 데에도 사용될 수 있습니다.
기술적인 세부 사항에 관심이 있으신 경우: 데이터 DAO에는 1) 데이터 기부를 통해 토큰을 획득하는 온체인 거버넌스와 2) 커뮤니티 소유 데이터 세트가 상주하는 공개-개인 키 쌍으로 암호화된 보안 서버의 두 가지 주요 구성 요소가 있습니다. 기여하려면 먼저 데이터의 유효성을 검사하여 소유권을 증명하고 가치를 추정합니다. 그런 다음 서버의 공개 키를 사용해 브라우저에서 데이터를 암호화하고 암호화된 데이터는 클라우드에 저장됩니다. 데이터는 DAO가 액세스 권한을 부여하는 제안을 승인할 때만 해독됩니다. 예를 들어, AI 회사에서 모델 학습을 위해 데이터를 대여할 수 있습니다. 데이터 세트와 모델의 공동 소유를 가능하게 하는 Vana 네트워크의 아키텍처에 대한 자세한 내용은 여기에서 확인할 수 있습니다.
데이터 DAO는 사용자에게 혜택을 제공할 뿐만 아니라 오픈 소스 소프트웨어처럼 AI를 구축할 수 있게 함으로써 AI를 발전시켜 기여하는 모든 사람에게 혜택을 줍니다. 오픈 소스 AI는 실행 가능한 비즈니스 모델을 찾는 데 어려움을 겪고 있습니다. GPU, 데이터, 연구원에게 비용을 지불하는 데 비용이 많이 들기 때문입니다. 게다가 모델이 학습되고 나면 오픈 소스인 경우 이러한 비용을 회수하는 것이 불가능합니다. 데이터 DAO의 기술 아키텍처는 사용자와 개발자가 데이터, 연산, 연구에 기여하는 대가로 모델에 대한 소유권을 갖는 모델 DAO에도 적용될 수 있습니다.
오늘날의 사회에서 기본 옵션은 대형 기술 회사가 우리의 데이터에 액세스하여 우리를 위해 작동하는 AI 모델을 훈련하는 데 사용하는 것입니다. 그들은 우리의 데이터로 훈련된 모델로 대체되면서 이러한 AI 모델을 통해 이익을 얻습니다. 이는 사회에는 매우 나쁜 일이지만 대기업에게는 좋은 일입니다. 이를 막을 수 있는 유일한 방법은 집단적 행동입니다. 데이터는 화폐이고 집단적 데이터는 힘입니다. 여러분의 참여를 독려합니다. 오늘 세계 최초로 Reddit 데이터에 초점을 맞춘 데이터 DAO가 Vana 네트워크에서 시작되었습니다. 데이터 DAO는 소수의 특권층이 통제하는 데이터 해자를 허물고 진정한 사용자 소유의 인터넷으로 나아가는 길을 열어줍니다.
NYDIG의 그렉 시폴라로는 최근의 블록체인 움직임이 "비이성적인" 공포를 불러일으키고 투자자들에게 매수 기회를 제공했다고 말합니다.
JinseFinance원장 사용자는 소셜 미디어 검열에 항의합니다.
 Beincrypto
BeincryptoReddit은 제한된 수량의 무료 Rabbids 아바타 NFT를 출시했으며 사용자는 이미 여러 종류가 고갈된 상태에서 이를 퍼내고 있습니다.

3백만 개 이상의 Reddit Vault 지갑이 생성되었습니다.
Beincrypto채굴자는 거래 비용을 지불하기 위해 거의 3천만 gwei를 사용했습니다.
 Coindesk
Coindesk중국은 지난해 암호화폐 거래와 채굴을 금지했다.
CoindeskBeincrypto이 회사는 이 프로젝트가 분산 거래 및 타사 판매를 위해 Polygon(MATIC) 블록체인을 활용할 예정이라고 말했습니다.
 Cointelegraph
Cointelegraph인기 있는 소셜 미디어 플랫폼인 Reddit에서 Collectible Avatars라는 새로운 기능을 출시합니다. 이러한 블록체인 지원 항목은 대체 불가능한 토큰(NFT)입니다.
 Bitcoinist
Bitcoinist데이터에 따르면 비트코인 채굴기 수익은 현재 시중보다 61% 적게 벌고 있기 때문에 최근 스트레스를 받고 있습니다.
Bitcoinist