


破解加密悖论:超越Code is Law 迈向Model is Trust
加密市场,BTC,破解加密悖论:超越Code is Law 迈向Model is Trust 金色财经,我们是否正在实质性迈向理想的未来?
 JinseFinance
JinseFinance

Author: Alec Chen
Source: Volt Capital
The idea of a "modular blockchain" is becoming a category-defining narrative around scalability and blockchain infrastructure.
The theory is simple: by breaking down the core components of a layer 1 blockchain, we can achieve a 100x improvement on a single layer, resulting in a more scalable, composable, and decentralized system. Before we discuss modular blockchains in detail, we must understand existing blockchain architectures and the limitations faced by current applications of blockchains.
Source: Ethereum Foundation
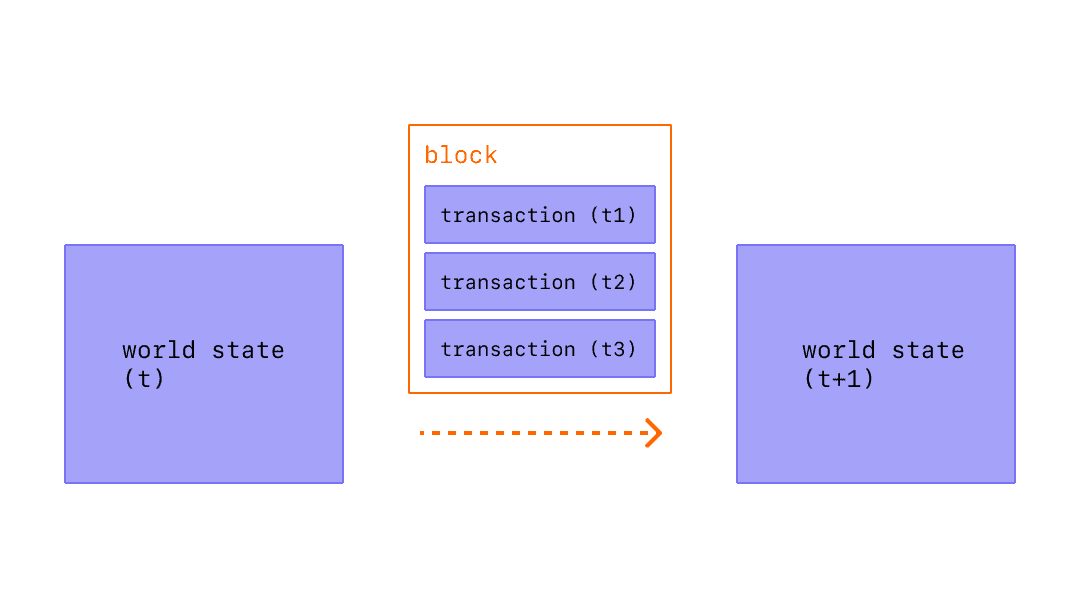
Let’s briefly review the basics of blockchain. A block in a blockchain consists of two components: a block header and the transaction data associated with it. Blocks are validated by "full nodes", which parse and calculate the entire block data to ensure that transactions are valid and users do not send more coins than their account balances.
Let's briefly outline the functional "layers" that make up a blockchain.
executive layer
Transactions and state changes are initially handled here. Users typically also interact with the blockchain through this layer, including signing transactions, deploying smart contracts, and transferring assets.
solution layer
The resolution layer is where rollup execution is verified and disputes are resolved. This layer does not exist in the overall chain and is an optional part of the modular stack. Similar to the U.S. court system, the resolution layer can be thought of as the U.S. Supreme Court, providing final arbitration for disputes.
consensus layer
The consensus layer of the blockchain provides ordering and finality through a network of full nodes downloading and executing block content and reaching consensus on the validity of state transitions.
Data Availability Layer
Data required to verify that state transitions are valid should be published and stored at this layer. In the event of an attack where malicious block producers withhold transaction data, this should be easy to verify. The data availability layer is the main bottleneck in the blockchain scalability trilemma, and we will explore why later.
For example, Ethereum is a monolithic blockchain, which means that the base layer handles all the components mentioned above.
Source: ResearchGate
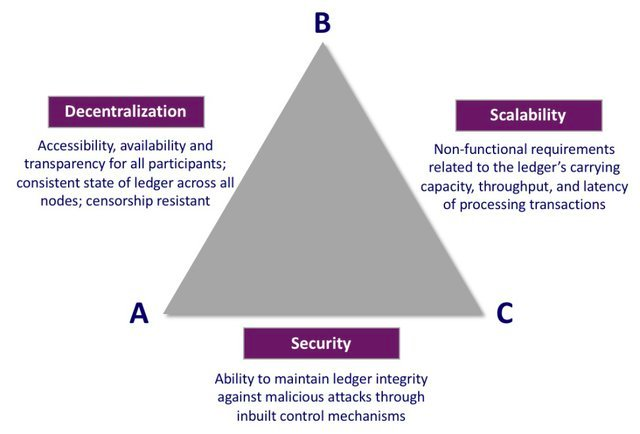
Blockchains currently face a problem known as the “blockchain scalability trilemma.” Similar to Brewer's theorem for distributed systems, blockchain architectures often compromise decentralization, security, or scalability in order to provide strong guarantees for the other two.
Security refers to the ability of a network to function when it is under attack. This principle is a core one of blockchains and should never be compromised, so the real trade-off is usually between scalability and decentralization.
Let's define decentralization in the context of a blockchain system: in order for a blockchain to be decentralized, hardware requirements cannot be a constraint on participation, and the resource requirements of a validating network should be low.
Scalability is the blockchain’s throughput divided by its verification cost: that is, the blockchain’s ability to handle increasing transaction volumes while maintaining low verification resource requirements. There are two main ways to increase throughput. First, the block size can be increased, thereby increasing the capacity of transactions that can be included in a block. Unfortunately, larger block sizes lead to network centralization as hardware requirements to run full nodes increase in response to higher computational output demands. Monolithic blockchains, in particular, suffer from this problem due to increased throughput associated with increased costs of validating the chain, resulting in less decentralization. Second, you can move execution off-chain, shifting the burden of computation off of nodes on the main network, while leveraging proofs that allow verification of on-chain computation.
Through a modular architecture, blockchains have the potential to begin to solve the blockchain scalability trilemma through the principle of separation of concerns. Through modular execution and data availability layers, blockchains are able to scale throughput while maintaining properties that make networks trustless and decentralized by breaking the correlation between computation and verification costs. Let's explore how this can be achieved by introducing Fault Proofs, Optimistic Rollups, and how they relate to the data availability problem.
V God stated in the article "Endgame" that a possible compromise between centralization and decentralization is that for scalability purposes, the future of block production is concentrated on pools and dedicated producers, while important things , block validation (to keep producers honest) is kept decentralized. This can be achieved by splitting the blockchain nodes into full nodes and light clients. There are two issues associated with this model: block validation (verify that the calculations are correct) and block availability (verify that all data has been published). Let's first explore its application to block validation.
Full nodes download, calculate, and verify each transaction in a block, while light clients only download block headers and assume the transactions are valid. Light clients then rely on error proofs generated by full nodes for transaction validation. This in turn allows light clients to autonomously identify invalid transactions, enabling them to operate with nearly the same security guarantees as full nodes. By default, light clients assume that state transitions are valid, and can challenge the validity of the state by receiving a proof of invalidity. When a node's state is challenged by error proofs, a complete node re-executes related transactions to reach a consensus, thereby reducing the interests of dishonest nodes.

The light client and the error proof model are safe under the honest minority assumption that at least one honest full node exists and the chain submitting the error proof is in a complete state. This model is especially suitable for sharded blockchains (such as the merged Ethereum architecture), because validators can choose to run full nodes on one shard and light clients on other shards, while maintaining N on all shards. 1 of 3 security guarantees.

Optimistic Rollup leverages this model to safely abstract the blockchain execution layer into a sequencer, a powerful computer that bundles and executes multiple transactions and periodically sends compressed data back to the parent chain. Moving this computation off-chain (relative to the parent chain) can increase transaction throughput by a factor of 10-100. How can we trust these off-chain sequencers to be well-intentioned? We introduced bonds and tokens that operators must hold to run the sequencer. Since sequencers send transaction data back to the parent chain, we can use validators (nodes that check for state mismatches between the parent chain and its rollup) to issue proofs of errors and subsequently cut the stakes for malicious sequencers. Because Optimistic Rollup utilizes error proofs, it is safe under the assumption that there is a reliable validator in the network. This use of false proofs is where Optimistic Rollup comes in - assuming a state transition is valid until proven valid during a dispute handled by the resolution layer.
This is how we scale while minimizing trust: allowing computation to be centralized while keeping verification of computation decentralized.
False proofs are an effective tool to address decentralized block validation, while full nodes rely on block availability to generate false proofs. Malicious block producers may choose to publish only block headers, retaining some or all of the corresponding data, thereby preventing full nodes from verifying and identifying invalid transactions, thereby generating false proofs. This type of attack is trivial for full nodes since they can easily download entire blocks and leave invalid chains when they notice an inconsistency or retain data. However, light clients will continue to track block headers of potentially invalid chains, forked from full nodes. (Remember, light clients do not download entire blocks and assume state transitions are valid by default.)
This is the essence of the data availability problem as it relates to error proofs: light clients must ensure that all transactional data is published in a block prior to validation, so that full nodes and light clients must automatically A block header is agreed upon.
Looks like we're back to square one. How does the light client ensure that it does not violate the original intention of the light client, and releases all transaction data in the block without the need for centralized hardware and without downloading the entire block?
One way to achieve this is through a mathematical primitive called erasure coding. By duplicating the bytes in a block, erasure codes can reconstruct the entire block even if a certain percentage of the data is lost. This technique is used to perform data availability sampling, allowing light clients to probabilistically determine that the entirety of a block has been published by randomly sampling a fraction of the block. This allows light clients to ensure that all transaction data is included in a particular block before accepting it as valid and following the corresponding block header. However, there are some caveats to this technique: data availability sampling has high latency, and similar to the honest minority assumption, safety guarantees rely on having enough light clients performing the sampling to be able to determine block availability probabilistically.
Simplified Model of Data Availability Sampling
Another solution to decentralized block validation is that transaction data is not required for state transitions. In contrast, validity proofs are more pessimistic than falsehood proofs. By eliminating the dispute process, the validity proof can guarantee the atomicity of all state transitions, but each state transition needs to be proved. This is done by utilizing new zero-knowledge techniques SNARKs and STARKs. Compared with error proofs, validity proofs require more computational intensity in exchange for stronger state guarantees, affecting scalability.
A zero-knowledge proof is a proof of state verification using a validity proof instead of a false proof. They follow a computation and verification model similar to Optimistic Rollup (although the schema is validity proofs rather than error proofs), via a sequencer/validator model, where the sequencer handles the computation and the verifier generates the corresponding proofs. For example, Starknet used a centralized sequencer during its launch, and has gradually decentralized open sequencers and validators on the roadmap. The computation of a zero-knowledge rollup (ZK rollup) is itself uncontrolled due to off-chain execution on the sequencer. However, since proofs of these computations must be verified on-chain, finality remains a bottleneck for proof generation.
It should be noted that the technique of state verification using light clients is only applicable to the false proof architecture. Since state transitions are guaranteed to be valid through validity proofs, transaction data is no longer required for nodes to validate blocks. However, the data availability problem for proof-of-validity remains, and is more subtle: although the state is guaranteed, transaction data for proof-of-validity is still necessary so that nodes can update and serve state transitions to end users. Therefore, rollups utilizing validity proofs are still subject to data availability issues.
Recall V God’s argument: all roads lead to centralized block production and decentralized block verification. While we can exponentially increase rollup throughput through advances in block generator hardware, the real scalability bottleneck is block availability, not block validation. This leads to an important insight: no matter how powerful we make the execution layer, or what proof model we use, our throughput will eventually be limited by data availability.
One way we currently ensure data availability is by publishing blockchain data on-chain. The Rollup implementation utilizes the Ethereum mainnet as a data availability layer and regularly publishes all rollup blocks on Ethereum. The main problem with this temporary solution is that Ethereum's current architecture relies on full nodes that guarantee data availability by downloading entire blocks, rather than light clients performing data availability sampling. As we increase the block size to gain additional throughput, this inevitably leads to increased hardware requirements for full node validation data availability, centralized networks.
In the future, Ethereum plans to move to a sharding architecture that utilizes data availability sampling, consisting of full nodes and light clients, thereby ensuring network security. (Note: Ethereum sharding technically uses KZG commitments rather than error proofs, but the data availability issue is related.) However, this only solves part of the problem: another fundamental problem facing the Rollup architecture is that rollup blocks are used as calldata dumped to Ethereum mainnet. This poses a follow-up problem, as calldata is expensive to use at scale, hindering L2 users at a cost of 16 gas per byte regardless of the rollup transaction batch size.
Validium is another way to improve scalability and throughput while maintaining data availability guarantees: granular transaction data (relative to raw data) can be sent to data availability committees, PoS guardians, or data availability layers. By moving data availability from Ethereum calldata to an off-chain solution, Validium bypasses the fixed byte gas costs associated with increasing rollup usage.
The Rollup architecture also brings the unique insight that the blockchain itself does not need to provide execution or computation, but only the ability to order blocks and guarantee data availability for those blocks. This is the design principle behind Celestia, the first modular blockchain network. Celestia, formerly known as LazyLedger, started as a "lazy blockchain" that left execution and validation to other modular layers, focusing only on providing a data availability layer for transaction ordering and data availability guarantees through data availability sampling. Centralized block production and decentralized block validators are the core premise of Celestia's design: even a mobile phone can participate as a light client, ensuring network security. Due to the nature of data availability sampling, inserting rollups into Celestia as a data availability layer can support higher block sizes (aka throughput) as the number of Celestia light nodes grows while maintaining the same probabilistic guarantees.
Other solutions now include StarkEx, zkPorter, and Polygon Avail. StarkEx is currently the only Validium used in production. Regardless, most validity contains implicit assumptions of trust in the source of data availability, whether this is managed through trusted committees, guardians, or a general data availability layer. This trust also demonstrates that malicious operators can prevent user funds from being withdrawn.
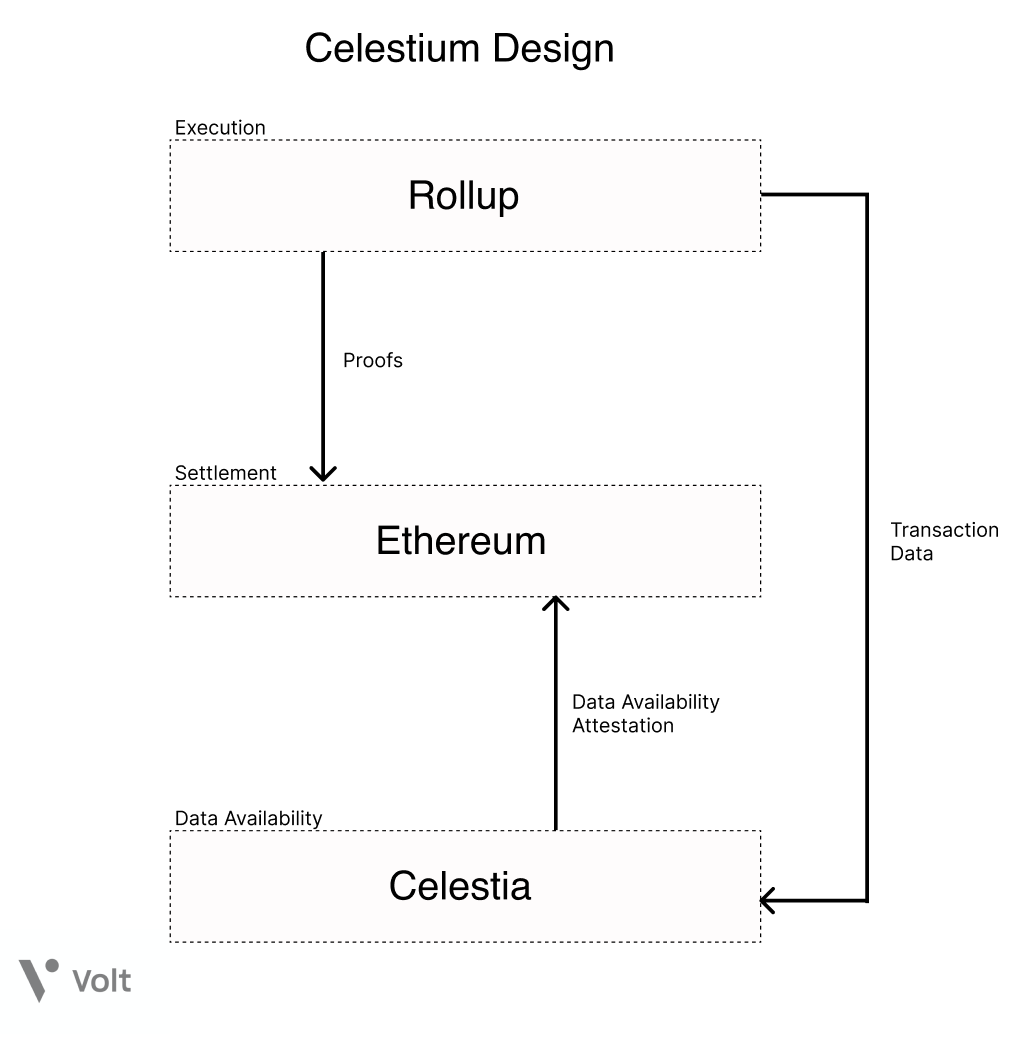
Modular blockchain architecture is a hotly debated topic in the crypto space right now. Celestium's vision for a modular blockchain architecture has suffered major setbacks due to security concerns and additional trust assumptions associated with fragmentation solutions and data availability layers.
Meanwhile, significant progress has been made across all aspects of the blockchain stack: Fuel Labs is developing a parallelized virtual machine at the execution layer, while the Optimism team is working on sharding, incentivized verification, and a decentralized sequencer. Hybrid Optimistic and zero-knowledge solutions are also in development.
Ethereum’s post-merger development roadmap includes plans to unify the solution and data availability layers. Specifically, Danksharding is a promising development in the Ethereum roadmap that aims to transform and optimize Ethereum L1 data shards and block space into a "data availability engine," allowing L2 rollups to achieve low-cost, high-throughput transaction.
Celestia's opinion-free architecture also allows a wide range of execution layer implementations to use it as a data availability layer, laying the foundation for alternative non-EVM virtual machines such as WASM, Starknet, and FuelVM. This shared data availability for various execution solutions allows developers to create trust-minimized bridges between Celestia clusters, unlocking cross-chain and cross-ecosystem composability and interoperability, just like in Ethereum and as possible between its rollups.
Volitions, pioneered by Starkware, introduces an innovative solution to the on-chain and off-chain data availability dilemma: users and developers can choose to use Validium to send transaction data off-chain, or keep transaction data on-chain, each Has its own unique advantages and disadvantages.
Furthermore, the use and popularity of Layer 2 solutions opens up layer 2: fractal scaling. Fractal extensions allow application-specific rollups to be deployed at layer 2 - developers can now deploy applications with full control over their infrastructure, from data availability to privacy. Deploying at layer 3 also unlocks layer 2 interoperability for all layer 3 applications, rather than expensive base chains like application-specific sovereign chains such as Cosmos.
Similar to the evolution of web infrastructure from on-premises servers to cloud servers, the decentralized web is evolving from monolithic blockchains and siled consensus layers to modular, application-specific chains of shared consensus layers. Regardless of which solutions and applications ultimately catch on, one thing is clear: in a modular future, the end users will be the winners.
加密市场,BTC,破解加密悖论:超越Code is Law 迈向Model is Trust 金色财经,我们是否正在实质性迈向理想的未来?
JinseFinanceBinance Labs has invested in Particle Network, a Layer-1 blockchain platform aimed at unifying the fragmented Web3 landscape. With features like universal accounts and liquidity, Particle Network simplifies blockchain interactions, enhancing accessibility and user experience.
 Weatherly
WeatherlyDeFi researcher Chris Powers explores the new trend of "modular lending" in the lending sector, illustrating its potential in addressing market challenges and providing better services. This article, based on an article by Chris Powers, is compiled, translated, and written by BlockBeats.
 Miyuki
MiyukiICC Camp S1 officially opens! The list of the first batch of signed projects has been released, the list of tutors and tutors has been fully announced, and the ecological map of partner institutions has been made public.
JinseFinanceModular blockchain, TIA, modular blockchain "division of labor" expansion, who is the next TIA? Golden Finance, high-profile modular blockchains have many investment plans from CEXs
JinseFinanceThis article will explain the differences between monolithic and modular blockchains, and how the Astar Network fits into the mix.
JinseFinanceETH’s Shanghai upgrade is highly anticipated because once executed, this change will allow users to withdraw their staked Ethereum.
 Catherine
CatherineAlthough it took more than a week to schedule FTX’s first bankruptcy hearing, it did finally happen. The live tweets detailed what went on.
CatherineBlockchain technology eliminates the need for a trusted party to facilitate digital relationships and is the backbone of cryptocurrencies.
 Coindesk
Coindesk Cointelegraph
Cointelegraph

