Exploring Monad’s Cryptographic Secrets: Can It Help Ethereum Regain Its Glory?
Ethereum is the backbone of the new global financial system for L2 and L1 applications, and no other chain can compare.
 JinseFinance
JinseFinance

Author: Decentralised.Co Source: X, @Decentralisedco Translation: Shan Ouba, Golden Finance
Transaction scalability has always been a hot topic of discussion in the industry. In the past few weeks, we have been discussing how Monad can help improve transaction processing speed (TPS). This article explains in detail how Monad works.
TPS is a metric we have been paying attention to. We hope that blockchains can support higher TPS to accommodate more users and applications. The figure below shows the TPS numbers for Ethereum and L2. So far, no chain has broken the 100 TPS mark. It should be noted that TPS is a general term used to measure scalability. Since not all transactions are equally complex, the pure TPS data is not accurate enough. But for convenience, we still regard TPS as an indicator of scalability.

What are the ways to improve TPS?
One way is to build a brand new system from scratch like Solana. Solana sacrifices compatibility with EVM in exchange for speed. It uses multi-threaded execution instead of single-threaded execution (which can be compared to multi-core CPU and single-core CPU), processes transactions in parallel, and uses different consensus mechanisms.
The second way is to use off-chain execution and use a centralized sorter to scale Ethereum.
The third approach is to break the EVM into separate components and optimize them for scalability.
Monad, a newly raised $225 million EVM-compatible L1 blockchain, chose to build the EVM from scratch rather than using an existing version. Monad takes the third approach to scalability.
Below we discuss some of the major changes introduced by Monad.
The Ethereum Virtual Machine (EVM) executes transactions serially. The next transaction must wait until the previous transaction is finished. Here’s an example: Imagine a platform for a motorcycle assembly warehouse. Multiple trucks arrive with motorcycle parts (each truck is loaded with all the parts needed to build 50 motorcycles). The assembly warehouse has four different functions, each of which is handled by a dedicated team - unloading, sorting, assembly, and loading.
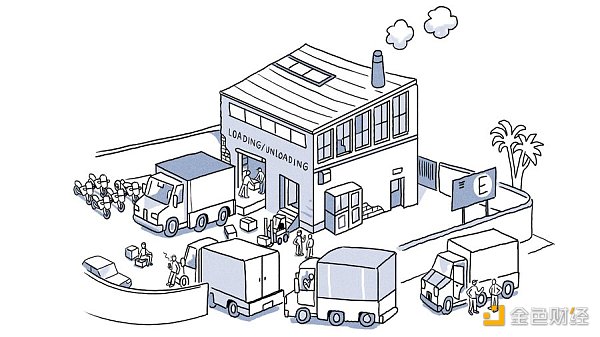
In the current EVM setup, there is only one platform and one spot for loading and unloading. So when a truck stops, motorcycle parts are unloaded, sorted, assembled, and loaded on the same truck. While the sorting team works, the other teams are waiting. So if their work is considered as different slots, each team will only work once in every four slots. This leads to serious inefficiencies and highlights the need for a more streamlined approach.
Now imagine there are four platforms with separate loading and unloading areas. Even if the unloading team can only handle one truck at a time, they don't have to wait for the next three slots to work. They can just move to the next truck and start working.
The same goes for the sorting, assembly, and loading teams. When a truck is finished unloading, it drives to the loading area and waits for the loading team to load the assembled motorcycles. So a warehouse with only one platform and loading area will perform all operations sequentially, while a warehouse with 4 platforms and different loading areas can process tasks in parallel.

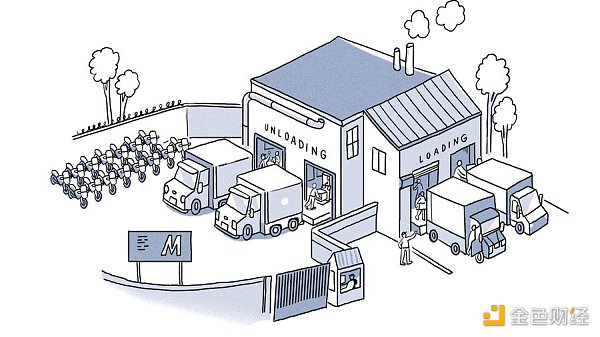
You can think of Monad as a warehouse infrastructure with multiple truck platforms, but it is much more complex than this example. The complexity increases when there are dependencies between trucks. For example, what if a truck does not have all the parts needed to build 50 motorcycles? Transactions are not always independent. So when Monad executes them in parallel, it has to handle transactions that depend on each other.
How does it do this? It performs something called optimistic parallel execution. The protocol can only execute independent transactions in parallel. For example, consider 4 transactions where Joel has a balance of 1 ETH:
Joel sends 0.2 ETH to Saurabh.
Sid mints an NFT.
Joel sends 0.1 ETH to Sid.
Shlok buys PEPE.
All of these transactions are executed in parallel with pending results that are committed one by one. If the pending result output conflicts with the original input of any transaction, the transaction is re-executed. Transactions 2 and 4 are independent of each other, so their pending results do not conflict with the inputs of other transactions. But 1 and 4 are not independent.
Note that since all 4 transactions start from the same initial state (Joel's balance is 1 ETH), the focus here is on Joel's balance. After sending 0.2 ETH, Joel's balance becomes 0.8 ETH. After sending 0.1 ETH to West, his balance becomes 0.9 ETH. The results are submitted one by one, ensuring that the output does not conflict with any input. After the pending result of 1 is submitted, Joel's new balance becomes 0.8 ETH.
This output conflicts with the input of 3. Therefore, 3 is now re-executed with an input of 0.8 ETH. After executing 3, Joel's balance becomes 0.7 ETH.
At this point, an obvious question is, how do we know that we don't have to re-execute most of the transactions? The answer is that re-execution is not the bottleneck. The bottleneck is accessing Ethereum's memory. It turns out that the way Ethereum stores its state in the database makes it difficult (time-consuming and expensive) to access the state. This is where another improvement of Monad comes into play - MonadDb. Monad builds its database in a way that reduces the overhead associated with read operations.
When a transaction needs to be re-executed, all the inputs are already cached in cache memory, which is much faster to access than accessing the entire state.
Solana has 50k TPS on testnet, but only ~1k TPS on mainnet. Monad claims to have achieved 10k real TPS on its internal testnet. While this is not always representative of real-world performance, we can’t wait to see how Monad performs in real-world applications.
Ethereum is the backbone of the new global financial system for L2 and L1 applications, and no other chain can compare.
JinseFinanceAmid the rapid development of blockchain technology, Monad and MegaETH, as two emerging projects, are driving the evolution of the Ethereum ecosystem in their own unique ways.
JinseFinanceMonad stands out with its goal to be a highly scalable single large L1 blockchain that is both EVM-compatible and capable of processing over 10,000 transactions per second with a block time of 1 second.
JinseFinanceMonad, Bankless: Why does Monad have the potential to replace Ethereum? Golden Finance, Monad is one of the most powerful challengers to ETH.
JinseFinanceTPS reaches 10,000+, financing reaches 19 million US dollars: Will L1 dark horse Monad disappoint people after it goes online?
JinseFinanceAs the dominant standard for smart contracts, the EVM chain has (to date) the majority of TVL, the largest developer and research network, and an incredible community that has stood the test of time (and multiple bear markets).
JinseFinanceBinance and CEO Zhao Changpeng admit intentional violations, facilitating billions in unregulated crypto transactions. Zhao resigns as CEO, faces potential 18-month sentence. Legal battles continue over sentencing and extradition. Binance.US claims independence from Zhao's governance.
 CaptainX
CaptainXBinance faces $34 billion in fines from FinCEN and $9.68 billion from OFAC for not reporting over 100,000 suspicious transactions involving terrorism, ransomware, child exploitation, and other illegal activities. Future penalties and strict regulations may impact Binance for the next five years.
CaptainXHopefully Ethereum becomes a system more like Bitcoin.
 链向资讯
链向资讯Hope Ethereum becomes a more Bitcoin-like system
 Ftftx
Ftftx

