The two mainstream blockchain architecture designs that have differentiated from Web3 today have inevitably caused some aesthetic fatigue. Whether it is the rampant modular public chain or the new L1 that always emphasizes performance but does not reflect performance advantages, its ecology can be said to be a replica or slight improvement of the Ethereum ecology. The highly homogeneous experience has long made users lose their sense of freshness. However, the AO protocol newly proposed by Arweave is eye-catching, achieving ultra-high performance computing on the storage public chain and even achieving a quasi-Web2 experience. This seems to be a huge difference from the expansion methods and architectural designs we are currently familiar with. So what exactly is AO? Where does the logic that supports its performance come from?
AO is named after Actor Oriented, a programming paradigm in the concurrent computing model Actor Model. Its overall design concept is derived from the extension of Smart Weave, and also follows the concept of Actor Model with message passing as the core. In simple terms, we can understand AO as a "super-parallel computer" running on the Arweave network through a modular architecture. From the implementation point of view, AO is not actually the modular execution layer that we often see today, but a communication protocol that regulates message passing and data processing. The core goal of this protocol is to achieve collaboration between different "roles" within the network through information transmission, thereby realizing a computing layer with infinitely superimposed performance, and ultimately enabling Arweave, a "giant hard drive", to have centralized cloud-level speed, scalable computing power and scalability in a decentralized trust environment.
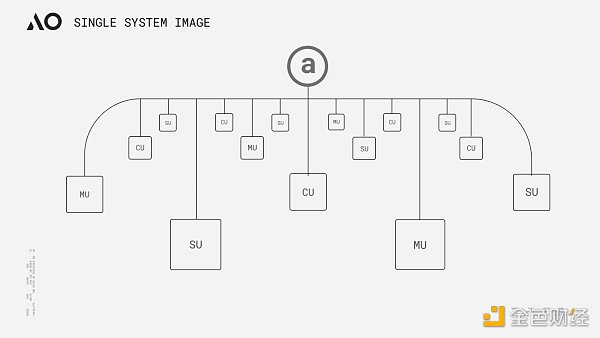
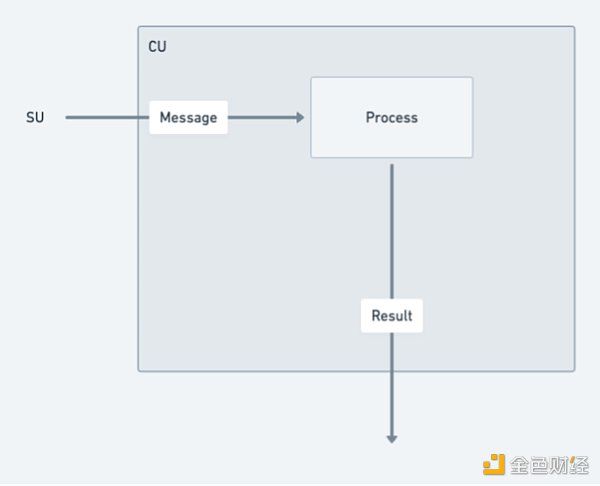
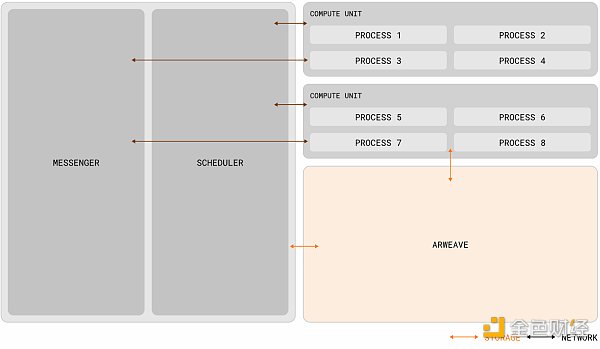
AO's concept seems to be similar to the "Core Time" segmentation and recombination proposed by Gavin Wood at the Polkadot Decoded conference last year. Both are to achieve the so-called "high-performance world computer" through the scheduling and coordination of computing resources. But there are actually some differences between the two in essence. Exotic Scheduling is the deconstruction and reorganization of the relay chain block space resources. It does not change the architecture of Polkadot much. Although the computing performance has broken through the limitation of a single parallel chain under the slot model, the upper limit is still limited by the maximum number of idle cores in Polkadot. In theory, AO can provide nearly unlimited computing power (in actual situations, it should depend on the level of network incentives) and higher degrees of freedom through the horizontal expansion of nodes. From an architectural point of view, AO standardizes the data processing method and the expression of messages, and completes the sorting, scheduling and calculation of information through three network units (subnets). Its standardization method and the functions of different units can be summarized as follows according to official data analysis:
AOS can be regarded as an operating system or terminal tool in the AO protocol, which can be used to download, run and manage threads. It provides an environment in which developers can develop, deploy and run applications. On AOS, developers can use the AO protocol to develop and deploy applications and interact with the AO network.
Actor Model advocates a philosophical view called "everything is an actor". All components and entities in the model can be regarded as "actors". Each actor has its own state, behavior and mailbox. They communicate and collaborate through asynchronous communication, so that the entire system can be organized and operated in a distributed and concurrent manner. The operating logic of the AO network is the same. Components and even users can be abstracted as "actors" and communicate with each other through the message passing layer, so that processes are linked to each other. A distributed working system that can be parallelized and non-shared is established in the interweaving.
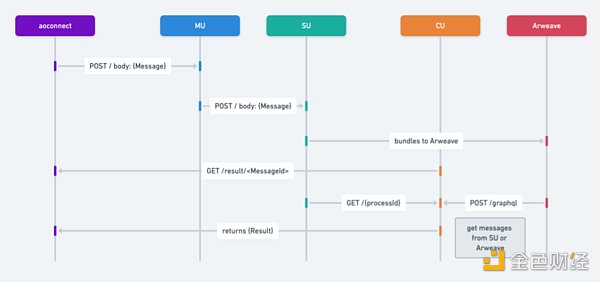
The following is a brief description of the steps in the information transmission flowchart:
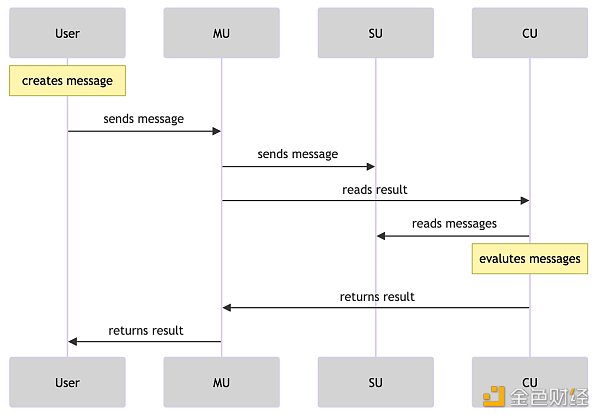
The user or process creates a message to send a request to other processes.
The MU (Messenger Unit) receives the message and sends it to other services using a POST request.
Message processing and forwarding:
Retrieve results based on message ID:
CU (Compute) receives the GET request, retrieves results based on the message ID, and evaluates the situation of the message on the process. It is able to return results based on a single message identifier.
Retrieve Information:
Push Outbox Messages:
The final step is to push all outbox messages.
This step involves inspecting the messages and builds in the result object.
Depending on the results of this inspection, steps 2, 3, and 4 can be repeated for each relevant message or build.
What Changed in the AO? 「1」
Differences from common networks:
Parallel processing capabilities: Unlike networks such as Ethereum, where the base layer and each Rollup actually run as a single process, AO supports any number of processes running in parallel while ensuring that the verifiability of the calculation remains intact. In addition, these networks operate in a globally synchronized state, while AO processes maintain their own independent state. This independence enables AO processes to handle higher numbers of interactions and computational scalability, making them particularly suitable for applications that require high performance and reliability;
Verifiable reproducibility: While some decentralized networks, such as Akash and peer-to-peer systems such as Urbit, do provide large-scale computing power, unlike AO, they do not provide verifiable reproducibility of interactions, or rely on non-permanent storage solutions to save their interaction logs.
How AO's node network differs from traditional computing environments:
Compatibility: AO supports various forms of threads, whether based on WASM or EVM, which can be connected to AO through certain technical means.
Content co-creation projects: AO also supports content co-creation projects, which can publish atomic NFTs on AO, upload data and build NFTs on AO in combination with UDL.
Data composability: AR and NFTs on AO can achieve data composability, allowing an article or content to be shared and displayed on multiple platforms while maintaining the consistency and original properties of the data source. When content is updated, the AO network is able to broadcast these updated states to all relevant platforms to ensure the synchronization of content and the dissemination of the latest state.
Value feedback and ownership: Content creators can sell their works as NFTs and pass ownership information through the AO network to achieve value feedback for the content.
Support for the project:
Built on Arweave: AO leverages the features of Arweave to eliminate the vulnerabilities associated with centralized providers, such as single points of failure, data leakage, and censorship. Computations on AO are transparent and can be verified through decentralized trust minimization features and reproducible message logs stored on Arweave;
Decentralized foundation: AO's decentralized foundation helps overcome the scalability limitations imposed by physical infrastructure. Anyone can easily create an AO process from their terminal without specialized knowledge, tools, or infrastructure, ensuring that even individuals and small-scale entities can have global influence and participation.
AO's Verifiability Issue
After we understand the framework and logic of AO, there is usually a common question. AO does not seem to have the global characteristics of traditional decentralized protocols or chains. Can verifiability and decentralization be achieved by simply uploading some data to Arweave? ? In fact, this is the mystery of AO's design. AO itself is an off-chain implementation, and does not solve the verifiability problem or change the consensus. The idea of the AR team is to separate the functions of AO and Arweave, and then connect them modularly. AO only communicates and calculates, and Arweave only provides storage and verification. The relationship between the two is more like a mapping. AO only needs to ensure that the interaction log is stored on Arweave, and its state can be projected to Arweave to create a hologram. This holographic state projection ensures the consistency, reliability, and certainty of the output when calculating the state. In addition, the message log on Arweave can also reversely trigger the AO process to perform specific operations (it can wake up by itself according to preset conditions and schedules, and perform corresponding dynamic operations).
According to Hill and Outprog's sharing, if the verification logic is explained more simply, AO can be imagined as an inscription calculation framework based on a super parallel indexer. We all know that the Bitcoin inscription indexer verifies the inscription, which requires extracting JSON information from the inscription and recording the balance information in the off-chain database, and completing the verification through a set of indexing rules. Although the indexer is an off-chain verification, users can verify the inscription by replacing multiple indexers or running the index themselves, so there is no need to worry about the indexer doing evil. We mentioned above that the order of messages and the holographic state of the process are uploaded to Arweave. Then, based on the SCP paradigm (storage consensus paradigm, which can be simply understood as SCP is the indexer of index rules on the chain. It is also worth noting that SCP appeared much earlier than the indexer), anyone can restore AO or any thread on AO through the holographic data on Arweave. Users do not need to run a full node to verify the trusted state. Just like changing the index, users only need to make a query request to a single or multiple CU nodes through SU. Arweave has high storage capacity and low cost, so under this logic, AO developers can realize a supercomputing layer that far exceeds the function of Bitcoin inscriptions.
AO and ICP
Let's use some keywords to summarize the characteristics of AO: giant native hard disk, unlimited parallelism, unlimited computing, modular overall architecture, and holographic state process. All of this sounds very beautiful, but friends who are familiar with various public chain projects in the blockchain may find that AO is very similar to a "death-level" project, that is, the once popular "Internet Computer" ICP.
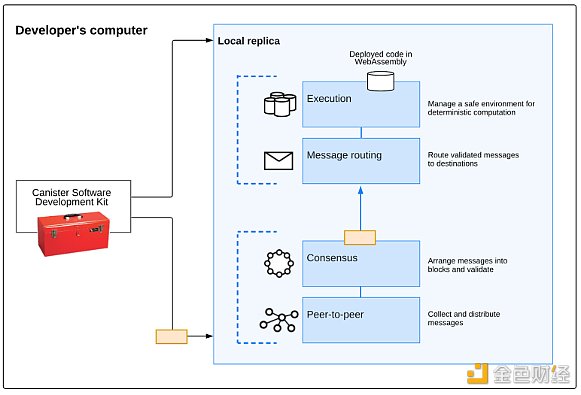
ICP was once hailed as the last king-level project in the blockchain world, and was highly favored by top institutions. In the crazy bull market of 21 years, it also reached a FDV of 200 billion US dollars. But as the wave receded, the value of ICP's tokens also plummeted. Until the bear market of 23 years, the value of ICP tokens had fallen by nearly 260 times compared to the historical high. But if you don't consider the performance of the token price, even if you re-examine ICP at this time, its technical features are still very unique. Many of the amazing advantages and characteristics of AO today were also possessed by ICP back then, so will AO fail like ICP? Let's first understand why the two are so similar. Both ICP and AO are designed based on the Actor Model and focus on locally running blockchains, so the characteristics of the two have many similarities. The ICP subnet blockchain is formed by a number of independently owned and controlled high-performance hardware devices (node machines) that run the Internet Computer Protocol (ICP). The Internet Computer Protocol is implemented by many software components that are a replica as a bundle because they replicate states and calculations on all nodes in the subnet blockchain.
ICP's replication architecture can be divided into four layers from top to bottom:
Peer-to-peer (P2P) network layer: used to collect and announce messages from users, other nodes in their subnet blockchain, and other subnet blockchains. Messages received by the peer layer will be replicated to all nodes in the subnet to ensure security, reliability, and resilience;
Consensus layer: Select and sort messages received from users and different subnets to create blockchain blocks that can be notarized and finalized through a Byzantine fault-tolerant consensus that forms an evolving blockchain. These finalized blocks are passed to the message routing layer;
Message routing layer: used to route user and system-generated messages between subnets, manage Dapp's input and output queues, and schedule message execution;
Execution environment layer: calculates the deterministic calculations involved in executing smart contracts by processing messages received from the message routing layer.
Subnet Blockchain
The so-called subnet is a collection of interacting replicas that run separate instances of the consensus mechanism in order to create their own blockchain on which a set of "containers" can be run. Each subnet can communicate with other subnets and is controlled by a root subnet, which delegates its authority to individual subnets using chain key cryptography. ICP uses subnets to allow it to scale infinitely. The problem with traditional blockchains (and individual subnets) is that they are limited by the computing power of a single node machine, because each node must run everything that happens on the blockchain to participate in the consensus algorithm. Running multiple independent subnets in parallel allows ICP to break through this single-machine barrier.
Why Failed
As mentioned above, the purpose of the ICP architecture is, in simple terms, a decentralized cloud server. A few years ago, this concept was as shocking as AO, but why did it fail? Simply put, it was neither high nor low, and it did not find a good balance between Web3 and its own concept, which ultimately led to the embarrassing situation that the project was not as good as Web3 and was not as good as the centralized cloud. In summary, there are three problems. First, ICP's program system Canister, which is the "container" mentioned above, is actually a bit similar to AOS and processes in AO, but the two are not the same. ICP's program is encapsulated and implemented by Canister, which is not visible to the outside world and requires access to data through specific interfaces. It is not friendly to the contract call of the DeFi protocol under asynchronous communication, so ICP did not capture the corresponding financial value in DeFi Summer.
The second point is that the hardware requirements are extremely high, resulting in the project not being decentralized. The figure below is the minimum hardware configuration diagram of the node given by ICP at the time. Even now, it is very exaggerated, far exceeding Solana's configuration, and even the storage requirements are higher than the storage public chain.

The third point is the lack of ecology. ICP is still a public chain with extremely high performance even now. If there is no DeFi application, what about other applications? Sorry, ICP has not produced a killer application since its birth. Its ecology has neither captured Web2 users nor Web3 users. After all, with such insufficient decentralization, why not directly use rich and mature centralized applications? But in the end, it is undeniable that ICP's technology is still top-notch. Its advantages of reverse Gas, high compatibility, and unlimited expansion are still necessary to attract the next billion users. In the current wave of AI, if ICP can make good use of its own architectural advantages, it may still be possible to turn things around.
Then back to the question above, will AO fail like ICP? I personally think that AO will not repeat the same mistakes. First of all, the last two points that led to the failure of ICP are not a problem for AO. Arweave already has a good ecological foundation, holographic state projection also solves the centralization problem, and AO is more flexible in compatibility. More challenges may focus on the design of economic models, support for DeFi, and a century-old problem: in the non-financial and storage fields, how should Web3 be presented?
Web3 should not stop at narrative
The most frequently used word in the world of Web3 must be "narrative". We are even accustomed to using narrative to measure the value of most tokens. This is naturally due to the dilemma that most Web3 projects have great visions but are awkward to use. In contrast, Arweave already has many fully implemented applications, and they are all benchmarked against Web2-level experiences. For example, Mirror and ArDrive, if you have used these projects, it should be difficult to feel the difference from traditional applications. However, Arweave still has great limitations in value capture as a storage public chain, and computing may be the only way. Especially in today's external world, AI is already a general trend, and Web3 still has many natural barriers in the current integration, which we have also talked about in past articles. Now Arweave's AO uses a non-Ethereum modular solution architecture, which provides a good new infrastructure for Web3 x AI. From the Library of Alexandria to super-parallel computers, Arweave is following a paradigm of its own.


 JinseFinance
JinseFinance

