Source: Heart of the Metaverse
Just as Google, Samsung and Microsoft continue to vigorously promote artificial intelligence generation technology on personal computers and mobile devices, Apple has also joined the ranks and launched OpenELM.
This is a new series of open source large language models (LLMs) that can run entirely on a single device without connecting to a cloud server.
01. Model characteristics and performance
OpenELM was released on the artificial intelligence code community Hugging Face on Wednesday local time. It consists of a series of small models designed to efficiently perform text generation tasks.
OpenELM has a total of eight models: four pre-trained models and four instruction adjustment models, covering different parameters from 270 million to 3 billion (parameters refer to the number of connections between artificial neurons in LLM. Generally, more parameters mean stronger performance and more functions).
While pre-training is a way to get LLM to generate coherent and potentially helpful text, it is mainly a predictive exercise, while instruction adjustment is a way to get LLM to make more relevant outputs for specific requests from users.
Pre-training may result in models that simply complete prompts with simple text. For example, in response to a user prompt "Teach me how to bake bread", the model may respond with something like "Use your oven at home" instead of actual step-by-step instructions.
Apple provides the weights of the OpenELM model under its so-called "Sample Code License", as well as instructions for different training checkpoints, model performance statistics, pre-training, evaluation, instruction adjustment, and parameter fine-tuning.
The "Sample Code License" does not prohibit commercial use or modification, but only stipulates that "if the entire content of the Apple software is redistributed without modification, this notice must be retained in the text."
Apple further noted that these models "do not have any security guarantees." Therefore, these models may produce "inaccurate, harmful, biased, or offensive output results" when responding to user prompts.
Apple is a notoriously secretive and typically "closed" technology company, and has not publicly announced its research process in this area other than posting these models and papers online.
In addition, as early as October last year, Apple quietly released an open source language model Ferret with multimodal capabilities, which made headlines.
OpenELM is the abbreviation for "Open-source Efficient Language Models". Although it has just been released and has not yet been publicly tested, Apple's listing on HuggingFace shows that it is targeting device applications of the model, just like its competitors Google, Samsung and Microsoft.
It is worth noting that Microsoft just released the Phi-3 Mini model that can run entirely on smartphones this week.
02. Technical details and training process
In a paper introducing the model series, Apple pointed out that the development of OpenELM "was led by Sachin Mehta, with Mohammad Rastegari and Peter Zatloukal also major contributors", and the model series "is designed to empower and strengthen the open research community and promote future research work."
OpenELM models come in four parameter sizes: 270 million, 450 million, 1.1 billion, and 3 billion, each of which is smaller than many high-performance models (which typically have around 7 billion parameters), and each model has a pre-trained and guided version.
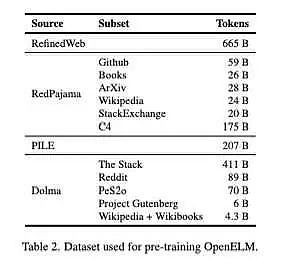
The models are pre-trained on a public dataset of 1.8 trillion tokens from sites such as Reddit, Wikipedia, arXiv.org, and others.
The models are suitable for running on commercial laptops and even some smartphones, and the benchmarks were run on "Intel i9-13900KF CPU, Nvidia RTX 4090 GPU, Ubuntu 22.04 Workstation, MacBook Pro with macOS 14.4.1".
Interestingly, all models in the new series adopt a layered scaling strategy that distributes parameters in each layer of the transformer model.
According to Apple, this enables them to provide higher accuracy results while improving computational efficiency. At the same time, Apple pre-trained the models using the new CoreNet library.
Apple pointed out on HuggingFace: "Our pre-training dataset contains RefinedWeb, Repeated PILE, a subset of RedPajama, and a subset of Dolma v1.6, totaling approximately 1.8 trillion tokens."
In terms of performance, the OpenLLM results shared by Apple show that the performance of these models is quite good, especially the indicated variant with 450 million parameters.
In addition, the "OpenELM variant" with 1.1 billion parameters is 2.36% higher than the "OLMo" with 1.2 billion parameters, while requiring 2 times fewer pre-training tokens.
OLMo is a "truly open source, state-of-the-art large language model" recently released by the Allen Institute for Artificial Intelligence (AI2).
03. Performance Testing and Community Feedback
On the ARC-C benchmark designed to test knowledge and reasoning capabilities, the pre-trained OpenELM-3B variant has an accuracy of 42.24%. At the same time, on MMLU and HellaSwag, its accuracy is 26.76% and 73.28%, respectively.
One user who has begun testing the OpenELM model noted that the model appears to be a "solid model, but very uniform," meaning its responses are neither broadly creative nor likely to venture into NSFW territory.
Competitor Microsoft's recently launched Phi-3 Mini, with 3.8 billion parameters and 4k context length, currently leads the field.
According to recently shared statistics, OpenELM scored 84.9% in 10 ARC-C benchmarks, 68.8% in 5 MMLU tests, and 76.7% in 5 HellaSwag tests.
OpenELM's performance is expected to improve in the long run.
But Apple's open source move has already excited the community, and we will wait and see how the community uses OpenELM in different environments.
04. Apple's AI Vision
Apple has been quiet about its plans for generative AI, but with the release of new AI models, the company's recent ambitions seem firmly in the realm of "making AI run locally on Apple devices."
Apple CEO Tim Cook has previewed that "AI generative features will appear on Apple devices," and said in February that Apple is spending "a lot of time and effort" in the field. However, Apple has not yet revealed specific details of AI applications.
The company has previously released other AI models, but has not released any AI-based models for commercial use like its competitors have.
In addition to OpenELM, Apple launched MLX, a machine learning framework in December last year, which is ideally designed to make it easier for AI models to run on Apple silicon. In addition, an image editing model called MGIE was released that allows people to repair photos through prompts. And a model called Ferret-UI can be used for smartphone navigation.
However, even with so many models released, Apple is said to have contacted Google and OpenAI to introduce their models into Apple products.


 Weatherly
Weatherly








