Tác giả: Gerry Wang @ Arweave Oasis, bài viết gốc được xuất bản lần đầu trên @ArweaveOasis Twitter
Tại Giải thích (3) Trong bài viết này, chúng tôi chứng minh tính khả thi của #SPoRes thông qua đạo hàm toán học. Bob và Alice trong bài viết đã cùng nhau tham gia trò chơi chứng minh này. Trong quá trình khai thác #Arweave, giao thức đã triển khai phiên bản sửa đổi của trò chơi SPoRes này. Trong quá trình khai thác, giao thức đóng vai Bob và tất cả các thợ mỏ trong mạng cùng đóng vai Alice. Mọi bằng chứng hợp lệ của trò chơi SPoRes đều được sử dụng để tạo khối tiếp theo của Arweave. Cụ thể, việc tạo khối Arweave có liên quan đến các tham số sau:
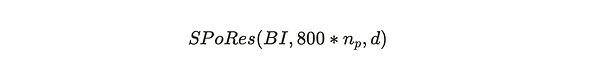
Trong số đó :
BI = Chỉ mục khối của mạng Arweave;
800*n_p = Tối đa 800 được mở khóa trên mỗi phân vùng trên mỗi điểm kiểm tra Số lượng băm , n_p, là số lượng phân vùng 3,6 TB được người khai thác lưu trữ và nhân với hai là số lượng thao tác băm tối đa mà người khai thác có thể thực hiện mỗi giây.
d = Độ khó của mạng.
Bằng chứng thành công và hợp lệ là bằng chứng lớn hơn giá trị độ khó và giá trị độ khó này sẽ được điều chỉnh theo thời gian để đảm bảo rằng trung bình 120 giây một khối được khai thác. Nếu chênh lệch thời gian giữa khối i và khối (i+10) là t thì việc điều chỉnh từ độ khó cũ d_i sang độ khó mới d_{i+10} được tính như sau:
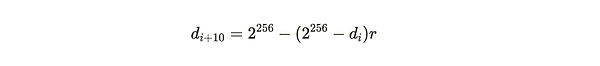
Trong số đó:

Ghi chú về công thức:Như có thể thấy từ hai điều trên công thức, mạng Việc điều chỉnh độ khó chủ yếu phụ thuộc vào tham số r và r có nghĩa là tham số bù đắp của thời gian thực tế cần thiết để tạo khối so với thời gian tiêu chuẩn dự kiến của hệ thống là 120 giây cho một khối.
Độ khó mới được tính toán xác định xác suất khai thác thành công một khối dựa trên từng bằng chứng SPoA được tạo, như sau:

Ghi chú công thức:Sau cách suy luận trên, có thể rút ra rằng xác suất khai thác thành công trong độ khó mới giống như ở độ khó cũ Xác suất thành công được nhân với tham số r.
Tương tự, độ khó VDF cũng được tính toán lại để đảm bảo chu kỳ điểm kiểm tra diễn ra đúng thời gian một giây.
Cơ chế khuyến khích tạo ra các bản sao hoàn chỉnh
Arweave sử dụng cơ chế SPoRes để tạo từng khối dựa trên Such một giả thuyết:
Dưới sự khuyến khích, cho dù người khai thác riêng lẻ hay người khai thác hợp tác theo nhóm sẽ duy trì một bản sao dữ liệu hoàn chỉnh như một chiến lược khai thác tốt nhất.
Trong trò chơi SPoRes được giới thiệu trước đó, việc lưu trữ hai bản sao của cùng một phần của tập dữ liệu sẽ giải phóng số lượng băm SPoA giống như việc lưu trữ một bản sao hoàn chỉnh của toàn bộ tập dữ liệu. , điều này để lại khả năng đầu cơ giữa các thợ mỏ. Vì vậy, Arweave đã thực hiện một số sửa đổi đối với cơ chế này khi triển khai nó. Giao thức chia số lượng thử thách SPoA được mở khóa mỗi giây thành hai phần:
Một phần chỉ định một phân vùng trong số các phân vùng lưu trữ của thợ mỏ để giải phóng một số thử thách SPoA nhất định;
Phần còn lại chỉ định ngẫu nhiên một phân vùng trong số tất cả các phân vùng dữ liệu trong Arweave Để giải phóng Thử thách SPoA, nếu người khai thác không lưu trữ bản sao của phân vùng này, nó sẽ mất phần số thử thách này.
Ở đây có thể bạn cảm thấy hơi bối rối về mối quan hệ giữa SPoA và SPoRes. Cơ chế đồng thuận là SPoRes, tại sao thử thách SPoA lại được đưa ra? Trên thực tế, giữa chúng có mối quan hệ phụ thuộc. SPoRes là tên chung của cơ chế đồng thuận này, bao gồm một loạt các thách thức chứng minh SPoA mà người khai thác bắt buộc phải thực hiện.
Để hiểu điều này, chúng ta sẽ xem xét cách sử dụng VDF được mô tả trong phần trước để giải quyết các thách thức SPoA.

Đoạn mã trên mô tả chi tiết cách để vượt qua Quá trình VDF (đồng hồ mật mã) để mở khóa phạm vi xem lại bao gồm một số SPoA nhất định trong một nhóm.
Khoảng mỗi giây, chuỗi băm VDF sẽ xuất ra một điểm kiểm tra (Kiểm tra);
- < p>Điểm kiểm tra này Kiểm tra sẽ được sử dụng cùng với địa chỉ khai thác (addr), chỉ mục phân vùng (index(p)) và hạt giống VDF gốc (hạt giống) để tính giá trị băm H0 bằng thuật toán RandomX. Giá trị băm là A 256 -số bit;
C1 là phần bù quay lui, có được bằng cách chia H0 cho kích thước của kích thước phân vùng (p) để tạo ra phần dư, sẽ là Số bắt đầu phần bù của phạm vi truy nguyên đầu tiên;
Các khối dữ liệu 400 256 KB trong phạm vi 100 MB liên tục bắt đầu từ phần bù bắt đầu này là Thử thách SPoA có phạm vi ngược đầu tiên được mở khóa.
C2 là độ lệch bắt đầu của phạm vi truy ngược thứ hai. Nó có được bằng cách chia H0 cho phần còn lại của tổng tất cả các kích thước phân vùng. Nó cũng được mở khóa. 400 thử thách SPoA cho phạm vi xem lại thứ hai.
Ràng buộc đối với những thách thức này là thách thức SPoA trong phạm vi thứ hai yêu cầu cũng phải có thách thức SPoA tại vị trí tương ứng trong phạm vi đầu tiên.
Hiệu suất trên mỗi phân vùng được đóng gói
Hiệu suất trên mỗi phân vùng được đóng gói đề cập đến đến số lượng thách thức SPoA được tạo bởi mỗi phân vùng tại mỗi điểm kiểm tra VDF. Khi người khai thác lưu trữ Bản sao duy nhất của một phân vùng, số lượng thử thách SPoA sẽ lớn hơn khi người khai thác lưu trữ nhiều bản sao lưu của cùng một dữ liệu.
Khái niệm "chỉ sao chép" ở đây rất khác với khái niệm "sao lưu". Để biết chi tiết, bạn có thể đọc bài viết trước đây "Arweave 2.6 có thể phù hợp hơn với tầm nhìn của Satoshi Nakamoto".
Nếu người khai thác chỉ lưu trữ dữ liệu sao chép duy nhất của phân vùng thì mỗi phân vùng được đóng gói sẽ tạo ra các thách thức cho tất cả các phạm vi truy nguyên đầu tiên, sau đó tạo ra các thách thức nằm trong phân vùng dựa trên số lượng phân vùng lưu trữ bản sao.Phạm vi xem lại thứ hai. Nếu có m phân vùng trong toàn bộ mạng dệt Arweave và người khai thác lưu trữ các bản sao duy nhất của n phân vùng thì hiệu suất của từng phân vùng được đóng gói là:

Khi phân vùng được người khai thác lưu trữ là bản sao lưu của cùng một dữ liệu, mỗi phân vùng được đóng gói sẽ vẫn tạo ra tất cả thử thách phạm vi truy nguyên đầu tiên . Nhưng chỉ trong trường hợp 1/m, phạm vi truy nguyên thứ hai sẽ nằm trong phân vùng này. Điều này mang đến một hình phạt hiệu suất đáng kể đối với hành vi chính sách lưu trữ này và tỷ lệ số lượng thách thức SPoA được tạo ra chỉ là:

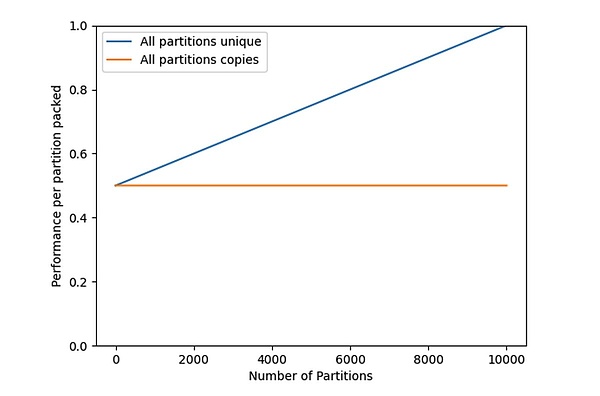
Hình 1: Khi một thợ mỏ (hoặc một nhóm thợ mỏ cộng tác) hoàn thành việc đóng gói tập dữ liệu của họ, hiệu suất của một phân vùng nhất định sẽ tăng lên.
Đường màu xanh lam trong Hình 1 là hiệu suất hoàn hảo_{unique}(n,m) của bản sao duy nhất của phân vùng lưu trữ. Hình này cho thấy một cách trực quan rằng khi người khai thác chỉ cửa hàng Với rất ít bản sao phân vùng, hiệu suất khai thác trên mỗi phân vùng chỉ là 50%. Hiệu suất khai thác đạt tối đa là 1 khi tất cả các phần của tập dữ liệu được lưu trữ và duy trì, tức là n=m.
Tổng tỷ lệ băm
Tổng tỷ lệ băm (được hiển thị trong Hình 2) được tính theo phương trình sau, bằng cách chia từng phân vùng (mỗi phân vùng) nhân với n để có:
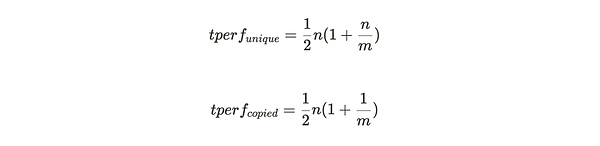
Công thức trên cho thấy rằng khi kích thước của mạng dệt (Dệt) tăng lên, nếu dữ liệu sao chép duy nhất không được lưu trữ thì hàm phạt (Hàm phạt) sẽ tăng theo phương trình bậc hai khi số lượng phân vùng lưu trữ tăng lên.
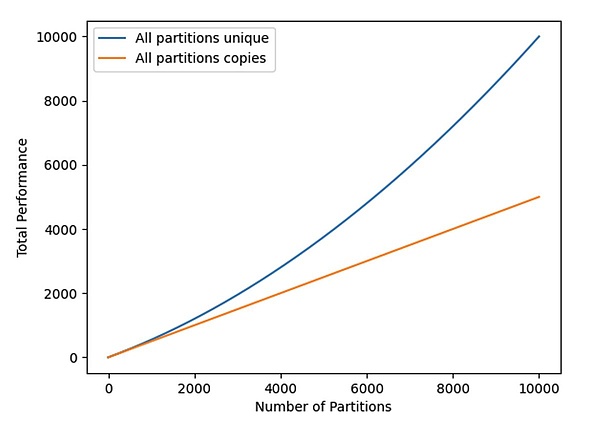
Hình 2: Tổng tốc độ băm khai thác cho các tập dữ liệu duy nhất và sao lưu
Hiệu quả phân vùng cận biên
Hiệu suất phân vùng cận biên
strong>
Dựa trên khung này, chúng tôi sẽ khám phá vấn đề ra quyết định mà những người khai thác gặp phải khi thêm các phân vùng mới, nghĩa là chọn sao chép một trong Đối với các phân vùng hiện có, dữ liệu mới được lấy từ các công cụ khai thác khác và được đóng gói thành các bản sao duy nhất. Khi họ đã lưu trữ các bản sao duy nhất của n phân vùng trong số m phân vùng tối đa có thể, tốc độ băm khai thác của họ tỷ lệ thuận:

Vì vậy, việc thêm một bản sao duy nhất của một phân vùng mới sẽ mang lại những lợi ích bổ sung là:

Lợi ích (nhỏ hơn) của việc sao chép phân vùng được đóng gói là:
p>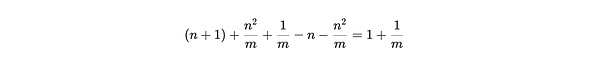
Chia đại lượng thứ nhất cho Đại lượng thứ hai, chúng ta thu được hiệu suất phân chia cận biên tương đối của công cụ khai thác:
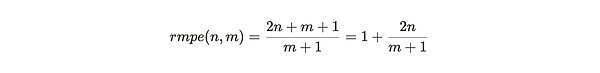
< p>
Hình 3: Công cụ khai thác là được khuyến khích xây dựng thành bản sao đầy đủ (tùy chọn 1) thay vì tạo thêm bản sao dữ liệu mà họ đã sở hữu (tùy chọn 2)
Giá trị rmpe có thể được coi là một hình phạt đối với người khai thác để sao chép các phân vùng hiện có khi thêm dữ liệu mới. Trong biểu thức này, chúng ta có thể xử lý m tiến tới vô cùng và sau đó xem xét sự đánh đổi hiệu quả dưới các giá trị n khác nhau:
Khi a thợ mỏ Phần thưởng cho việc hoàn thành một bản sao là cao nhất khi bạn có một bản sao của tập dữ liệu gần như hoàn chỉnh. Bởi vì nếu n tiến tới m và m tiến đến vô cùng thì giá trị của rmpe là 3. Điều này có nghĩa là, với một bản sao gần như hoàn chỉnh, việc tìm kiếm dữ liệu mới hiệu quả gấp 3 lần so với việc đóng gói lại dữ liệu hiện có.
Khi người khai thác lưu trữ một nửa mạng dệt (Dệt), ví dụ: khi n= 1/2 m, rmpe là 2. Điều này có nghĩa là những người khai thác tìm kiếm dữ liệu mới kiếm được gấp đôi so với việc sao chép dữ liệu hiện có.
Đối với các giá trị thấp hơn của n, giá trị rmpe có xu hướng nhưng luôn lớn hơn 1. Điều này có nghĩa là lợi ích của việc lưu trữ một bản sao duy nhất luôn lớn hơn lợi ích của việc sao chép dữ liệu hiện có.
Khi mạng phát triển (m tiến tới vô tận), động cơ khuyến khích thợ mỏ xây dựng các bản sao hoàn chỉnh sẽ tăng lên. Điều này tạo điều kiện thuận lợi cho việc tạo ra các nhóm khai thác hợp tác cùng lưu trữ một bản sao hoàn chỉnh của ít nhất một tập dữ liệu.
Bài viết này chủ yếu giới thiệu chi tiết về việc xây dựng giao thức đồng thuận Arweave. Tất nhiên, đây chỉ là phần khởi đầu của nội dung cốt lõi này. Từ phần giới thiệu cơ chế và mã, chúng ta có thể hiểu chi tiết cụ thể của giao thức một cách rất trực quan. Hy vọng nó sẽ giúp mọi người hiểu.


 Sanya
Sanya



