NYDIG: Sự sụt giảm BTC do Đức, Mt. Gox và việc bán miner bị phóng đại
Greg Cipolo của NYDIG cho biết các động thái blockchain gần đây đã làm dấy lên những lo ngại “phi lý”, mang đến cho các nhà đầu tư cơ hội mua vào.
 JinseFinance
JinseFinance

Vào năm 2022, tôi (anna) đã viết đề xuất về mô hình cơ sở do người dùng sở hữu sử dụng dữ liệu riêng tư thay vì dữ liệu được thu thập công khai từ internet. Tiến hành đào tạo. Tôi tin rằng mặc dù có thể đào tạo các mô hình cơ sở bằng cách sử dụng dữ liệu công khai (ví dụ: Wikipedia, 4Chan), nhưng để đưa chúng lên cấp độ tiếp theo, bạn cần có dữ liệu riêng tư chất lượng cao chỉ tồn tại khi cần có quyền hoặc đăng nhập để truy cập Trong các nền tảng biệt lập (chẳng hạn như như Twitter, tin nhắn cá nhân, thông tin công ty).
Dự đoán này đang bắt đầu trở thành hiện thực. Các công ty như Reddit và Twitter đã nhận ra giá trị của dữ liệu nền tảng của họ, vì vậy họ đã khóa API nhà phát triển (1, 2) để ngăn các công ty khác tự do sử dụng dữ liệu văn bản của họ để đào tạo các mô hình cơ bản.
Đây là một thay đổi lớn so với hai năm trước. Nhà đầu tư mạo hiểm Sam Lessin đã tóm tắt sự thay đổi: “[Nền tảng] chỉ cần ném thứ rác rưởi này vào phía sau, không cần giám sát, và rồi đột nhiên, bạn nghĩ, ồ, chết tiệt, thứ rác rưởi đó là vàng, phải không? Rất nhiều. Chúng tôi phải khóa thùng rác." Ví dụ: GPT-3 được đào tạo về WebText2, tổng hợp văn bản từ tất cả các liên kết cam kết Reddit có ít nhất 3 lượt tán thành (3, 4). Với API mới của Reddit, điều này không thể thực hiện được nữa.
Internet ngày càng trở nên kém cởi mở hơn, với các nền tảng biệt lập đang xây dựng những bức tường lớn hơn bao giờ hết để bảo vệ dữ liệu đào tạo quý giá của mình.
Mặc dù các nhà phát triển không thể truy cập dữ liệu này trên quy mô lớn nữa nhưng các cá nhân vẫn có thể truy cập và xuất dữ liệu của riêng họ trên các nền tảng do các quy định về quyền riêng tư dữ liệu (5, 6 ) . Việc các nền tảng khóa API của nhà phát triển, trong khi người dùng cá nhân vẫn có thể truy cập dữ liệu của riêng họ, mang đến một cơ hội: Liệu 100 triệu người dùng có thể xuất dữ liệu nền tảng của họ để tạo ra kho dữ liệu lớn nhất thế giới không? Kho dữ liệu này sẽ tổng hợp tất cả dữ liệu người dùng được thu thập bởi các công ty công nghệ lớn và các công ty khác, những công ty thường miễn cưỡng chia sẻ dữ liệu đó. Đây sẽ là bộ dữ liệu huấn luyện lớn nhất và toàn diện nhất cho đến nay, lớn hơn 100 lần so với bộ dữ liệu dùng để huấn luyện các mô hình cơ sở hàng đầu hiện nay. 1
Huấn luyện mô hình cơ bản Ước tính sơ bộ về cách so sánh tập dữ liệu với tập dữ liệu người dùng mẫu. Nguồn và tính toán

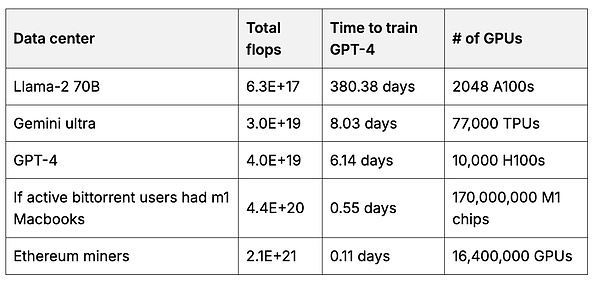
Sau đó, người dùng có thể tạo mô hình cơ sở do người dùng sở hữu sử dụng nhiều dữ liệu hơn bất kỳ công ty nào có thể tổng hợp. Việc đào tạo mô hình cơ sở đòi hỏi rất nhiều khả năng tính toán GPU. Nhưng mỗi người dùng có thể giúp huấn luyện một phần nhỏ của mô hình bằng phần cứng của riêng họ, sau đó hợp nhất các phần lại với nhau để tạo ra một mô hình lớn hơn, mạnh hơn (7, 8, 9). 2 Khi có sự khuyến khích phù hợp, người dùng có thể gộp khối lượng tính toán lớn. Ví dụ: tổng nỗ lực tính toán của các công cụ khai thác Ethereum gấp 50 lần so với nỗ lực đào tạo các mô hình cơ sở hàng đầu.
Với GPU khai thác Ethereum So sánh đây là ước tính tổng số thao tác dấu phẩy động (phép toán dấu phẩy động mỗi giây = tổng tốc độ "suy nghĩ" của tất cả GPU) trong trung tâm dữ liệu được sử dụng để huấn luyện mô hình cơ sở. 3Với nguồn tính toán.
Những người dùng đóng góp cho mô hình sẽ cùng sở hữu và quản lý mô hình. Họ có thể được trả tiền khi sử dụng mô hình và thậm chí được trả theo tỷ lệ dựa trên mức độ cải thiện mô hình của dữ liệu của họ. Tập thể có thể phát triển các quy tắc sử dụng, bao gồm ai có thể truy cập mô hình và những biện pháp kiểm soát nào nên được thực hiện. Có lẽ người dùng ở mỗi quốc gia sẽ tạo ra những mẫu xe riêng, đại diện cho hệ tư tưởng, văn hóa của họ. Hoặc có thể một quốc gia không phải là đường phân chia phù hợp và chúng ta sẽ thấy một thế giới nơi mỗi quốc gia trong mạng lưới có mô hình cơ bản riêng dựa trên dữ liệu thành viên của quốc gia đó.
Tôi khuyến khích bạn dành thời gian suy nghĩ về những phần của mô hình cơ sở mà bạn muốn có và dữ liệu đào tạo nào bạn có thể đóng góp từ nền tảng bạn đang sử dụng. Bạn có thể có nhiều dữ liệu hơn bạn tưởng—các tài liệu nghiên cứu, tác phẩm nghệ thuật chưa xuất bản, Google Docs, hồ sơ hẹn hò, hồ sơ y tế, tin nhắn Slack của bạn. Một cách để tập hợp dữ liệu này lại với nhau là thông qua máy chủ cá nhân, cho phép bạn dễ dàng sử dụng dữ liệu riêng tư của mình với LLM cục bộ. Trong tương lai, máy chủ cá nhân của bạn cũng có thể đào tạo một phần mô hình cơ sở người dùng mà bạn có.
Các mô hình cơ bản có xu hướng độc quyền vì chúng yêu cầu đầu tư ban đầu lớn vào dữ liệu và điện toán. Thật dễ dàng để chúng tôi chọn phương án dễ dàng: làm những gì có thể với mô hình nguồn mở đã đi sau vài thế hệ, tàn tích của các công ty AI lớn. Nhưng chúng ta không nên chấp nhận việc tụt lại phía sau một vài thế hệ và chỉ ăn những thứ còn sót lại! Với tư cách là người dùng, chúng ta nên tạo ra những mô hình tốt nhất của riêng mình—và chúng ta có dữ liệu và sức mạnh tính toán để biến điều đó thành hiện thực.
Một sự thay đổi kinh tế to lớn đang diễn ra khi trí tuệ nhân tạo ngày càng có khả năng thực hiện các công việc kinh tế có giá trị. Các công ty công nghệ lớn đã đào tạo các mô hình trí tuệ nhân tạo về công việc công cộng, bài viết, tác phẩm nghệ thuật, ảnh và dữ liệu khác của bạn cũng như dữ liệu của người khác và đang bắt đầu kiếm được hàng tỷ đô la mỗi năm (1). Họ hiện đang theo đuổi dữ liệu của bạn không có trên internet công cộng, mua dữ liệu riêng tư của bạn từ các công ty như Reddit để họ có thể tăng doanh thu AI lên hàng nghìn tỷ đô la mỗi năm (2, 3).
Đây là mục đích sử dụng của DAO dữ liệu. Data DAO là một thực thể phi tập trung cho phép người dùng tổng hợp và quản lý dữ liệu của họ, đồng thời thưởng cho những người đóng góp bằng mã thông báo dành riêng cho tập dữ liệu thể hiện quyền sở hữu của một tập dữ liệu cụ thể. Nó giống như một sự kết hợp của dữ liệu. Những bộ dữ liệu này có thể sao chép hoặc thậm chí vượt qua những bộ dữ liệu được bán bởi các công ty công nghệ lớn với giá hàng trăm triệu đô la ( 4 ). DAO có toàn quyền kiểm soát tập dữ liệu và có thể chọn cho thuê hoặc bán các bản sao ẩn danh. Ví dụ: dữ liệu Reddit thậm chí có thể được sử dụng để tạo nền tảng mới do người dùng sở hữu, bao gồm bạn bè, các bài đăng trước đây của bạn và dữ liệu khác có thể dễ dàng sử dụng trên nền tảng mới.
Nếu bạn quan tâm đến chi tiết kỹ thuật: Dữ liệu DAO có hai thành phần chính: 1) quản trị trên chuỗi, nơi nhận được mã thông báo thông qua đóng góp dữ liệu; 2) máy chủ bảo mật, được mã hóa bằng cặp khóa công khai, nơi chứa các bộ dữ liệu thuộc sở hữu cộng đồng. Để đóng góp, trước tiên bạn phải xác minh dữ liệu để chứng minh quyền sở hữu và ước tính giá trị của dữ liệu đó. Sau đó, dữ liệu được mã hóa trong trình duyệt bằng khóa chung của máy chủ và dữ liệu được mã hóa sẽ được lưu trữ trên đám mây. Dữ liệu sẽ chỉ được giải mã khi DAO chấp thuận đề xuất cấp quyền truy cập. Ví dụ, nó có thể cho phép các công ty AI thuê dữ liệu để đào tạo mô hình. Bạn có thể đọc thêm về kiến trúc của mạng Vana, được thiết kế để cho phép sở hữu tập thể các bộ dữ liệu và mô hình tại đây.
Data DAO không chỉ mang lại lợi ích cho người dùng mà còn thúc đẩy sự phát triển của AI, giúp xây dựng AI giống như phần mềm nguồn mở, cho phép tất cả những người đóng góp Lợi ích. AI nguồn mở đang nỗ lực tìm kiếm một mô hình kinh doanh khả thi: chi phí cho GPU, dữ liệu và nhà nghiên cứu rất tốn kém. Hơn nữa, một khi mô hình được đào tạo, sẽ không có cách nào bù lại những chi phí này nếu nó là nguồn mở. Kiến trúc kỹ thuật của DAO dữ liệu có thể được áp dụng cho DAO mô hình, nơi người dùng và nhà phát triển có thể đóng góp dữ liệu, tính toán và nghiên cứu để đổi lấy quyền sở hữu mô hình.
Lựa chọn mặc định trong xã hội ngày nay là cho phép các công ty công nghệ lớn lấy dữ liệu của chúng ta và sử dụng dữ liệu đó để đào tạo các mô hình trí tuệ nhân tạo phù hợp với chúng ta. Họ thu lợi từ các mô hình AI này vì chúng tôi được thay thế bằng các mô hình được đào tạo trên dữ liệu của chúng tôi. Đây là một thỏa thuận rất tồi tệ cho xã hội nhưng lại là điều tốt cho các công ty công nghệ lớn. Cách duy nhất để ngăn chặn điều này xảy ra là thông qua hành động tập thể. Dữ liệu là tiền tệ và dữ liệu tập thể là sức mạnh. Tôi khuyến khích bạn tham gia: Dữ liệu DAO đầu tiên trên thế giới tập trung vào dữ liệu Reddit sẽ xuất hiện trực tuyến ngày hôm nay trên mạng Vana. Bằng cách phá vỡ các hào dữ liệu do một số ít người có đặc quyền kiểm soát, Data DAO tạo ra đường dẫn đến một mạng Internet thực sự do người dùng sở hữu.
Greg Cipolo của NYDIG cho biết các động thái blockchain gần đây đã làm dấy lên những lo ngại “phi lý”, mang đến cho các nhà đầu tư cơ hội mua vào.
JinseFinanceNgười dùng sổ cái phản đối kiểm duyệt mạng xã hội.
 Beincrypto
BeincryptoReddit đã phát hành một số lượng hạn chế NFT hình đại diện Rabbids miễn phí và người dùng đang tìm kiếm chúng, với nhiều loại đã cạn kiệt.

Hơn 3 triệu ví Reddit Vault đã được tạo.
BeincryptoNgười khai thác đã sử dụng gần 30 triệu gwei để thanh toán cho giao dịch đó.
 Coindesk
CoindeskTrung Quốc đã cấm giao dịch và khai thác tiền điện tử vào năm ngoái.
CoindeskBeincryptoCông ty cho biết dự án được thiết lập để sử dụng chuỗi khối Polygon (MATIC) cho giao dịch phi tập trung và bán hàng của bên thứ ba.
 Cointelegraph
CointelegraphNền tảng truyền thông xã hội nổi tiếng Reddit sẽ ra mắt một tính năng mới có tên là Hình đại diện sưu tập. Các mặt hàng được hỗ trợ bởi chuỗi khối này là các mã thông báo không thể thay thế (NFT) ...
 Bitcoinist
BitcoinistDữ liệu cho thấy doanh thu của những người khai thác Bitcoin gần đây đang bị căng thẳng vì họ hiện đang kiếm được ít hơn 61% so với ...
Bitcoinist