Tiêu đề gốc: "Khám phá vòng tròn STARKs" Viết bởi: Vitalik Buterin, đồng sáng lập Ethereum Biên soạn bởi: Chris, Techub News
Điều kiện tiên quyết để hiểu bài viết này là bạn đã hiểu được nguyên tắc cơ bản của SNARK và STARK. Nếu bạn không quen với điều này, tôi khuyên bạn nên đọc một số phần đầu tiên của bài viết này để hiểu những điều cơ bản.
Trong những năm gần đây, xu hướng thiết kế giao thức STARK là hướng tới sử dụng các trường nhỏ hơn. Việc triển khai sản xuất STARK sớm nhất đã sử dụng các trường 256 bit, tức là số học modulo trên số lớn (ví dụ: 21888...95617), khiến các giao thức này tương thích với chữ ký dựa trên đường cong elip. Tuy nhiên, hiệu quả của thiết kế này tương đối thấp, trong trường hợp bình thường, việc xử lý và tính toán những con số lớn này không có tác dụng thực tế và sẽ lãng phí rất nhiều sức mạnh tính toán, chẳng hạn như xử lý X (đại diện cho một số nhất định) và xử lý bốn lần X. , xử lý Chỉ cần một phần chín thời gian tính toán. Để giải quyết vấn đề này, STARK bắt đầu chuyển sang các lĩnh vực nhỏ hơn: đầu tiên là Goldilocks, sau đó là Mersenne31 và BabyBear.
Sự thay đổi này đã cải thiện tốc độ chứng minh, chẳng hạn như Starkware có thể chứng minh 620.000 băm Poseidon2 mỗi giây trên máy tính xách tay M3. Điều này có nghĩa là miễn là chúng ta sẵn sàng tin tưởng Poseidon2 làm hàm băm, chúng ta có thể giải quyết vấn đề khó khăn trong việc phát triển ZK-EVM hiệu quả. Vậy những công nghệ này hoạt động như thế nào? Làm thế nào để những bằng chứng này được xây dựng trên các lĩnh vực nhỏ hơn? Các giao thức này so sánh với các giải pháp như Binius như thế nào? Bài viết này sẽ khám phá những chi tiết này, đặc biệt tập trung vào một sơ đồ có tên Circle STARKs (được triển khai trong stwo của Starkware, plonky3 của Polygon và phiên bản của riêng tôi trong Python), có chức năng tương tự như các trường Mersenne31.
Các vấn đề thường gặp khi làm việc với các trường toán nhỏ hơn
Khi tạo A dựa trên hàm băm Rất quan trọng Bí quyết khi đưa ra bằng chứng (hoặc bằng chứng dưới bất kỳ hình thức nào) là có thể gián tiếp xác minh các tính chất của đa thức bằng cách chứng minh đánh giá của nó tại các điểm ngẫu nhiên. Cách tiếp cận này có thể đơn giản hóa rất nhiều quá trình chứng minh, vì việc đánh giá tại các điểm ngẫu nhiên thường dễ dàng hơn nhiều so với việc xử lý toàn bộ đa thức.
Ví dụ: giả sử một hệ thống chứng minh yêu cầu bạn tạo ra một cam kết đối với đa thức A, phải thỏa mãn A^3 (x) + x - A ( \omega* x) = x^N (một loại bằng chứng rất phổ biến trong giao thức ZK-SNARK). Giao thức có thể yêu cầu bạn chọn tọa độ ngẫu nhiên và chứng minh rằng A (r) + r - A (\omega*r) = r^N. Sau đó, tính ngược lại A (r) = c và bạn chứng minh được rằng Q = \frac {A - c}{X - r} là một đa thức.
Nếu bạn hiểu trước chi tiết hoặc cơ chế bên trong của các giao thức, bạn có thể tìm cách vượt qua hoặc bẻ khóa chúng. Những hành động hoặc phương pháp cụ thể để đạt được điều này có thể được đề cập tiếp theo. Ví dụ, để thỏa mãn phương trình A (\omega * r), bạn có thể đặt A (r) thành 0 và đặt A là một đường thẳng đi qua hai điểm này.
Để ngăn chặn các cuộc tấn công này, chúng ta cần chọn r sau khi kẻ tấn công cung cấp A (Fiat-Shamir là một kỹ thuật được sử dụng để tăng cường bảo mật giao thức, tránh các cuộc tấn công bằng cách cài đặt các tham số nhất định cho các giá trị băm nhất định Các tham số được chọn cần phải từ một bộ đủ lớn để đảm bảo rằng kẻ tấn công không thể dự đoán hoặc đoán được các tham số này, từ đó cải thiện tính bảo mật của hệ thống. left;">Trong các giao thức dựa trên đường cong elip và STARK trong giai đoạn 2019, vấn đề rất đơn giản: tất cả các phép toán của chúng ta đều được thực hiện trên các số 256 bit, vì vậy chúng ta có thể chọn r là số 256 bit ngẫu nhiên, Tuy nhiên, trong STARK trên các trường nhỏ hơn, chúng tôi gặp phải một vấn đề: chỉ có khoảng 2 tỷ giá trị có thể có của r để lựa chọn, vì vậy người ta muốn làm sai lệch bằng chứng. Kẻ tấn công chỉ cần thử 2 tỷ. Mặc dù khối lượng công việc rất lớn nhưng đối với một kẻ tấn công quyết tâm, điều đó vẫn có thể thực hiện được!
Có hai giải pháp cho vấn đề này:
Được thực hiện nhiều lần Phương pháp kiểm tra ngẫu nhiên là đơn giản và hiệu quả nhất: thay vì kiểm tra trên một tọa độ, có thể lặp lại việc kiểm tra trên bốn tọa độ ngẫu nhiên, nhưng sẽ có vấn đề về hiệu quả nếu bạn đang xử lý một mức độ nhỏ hơn một giá trị nhất định và hoạt động trên một miền có kích thước nhất định, kẻ tấn công thực sự có thể tạo ra các đa thức độc hại. Do đó, liệu họ có thể phá vỡ giao thức thành công hay không là một câu hỏi mang tính xác suất. Số lượng vòng kiểm tra cần được tăng lên để tăng cường bảo mật tổng thể và đảm bảo khả năng phòng thủ hiệu quả trước những kẻ tấn công. text-align: left;">Điều này dẫn đến một giải pháp khác: mở rộng miền. , trường mở rộng tương tự như số phức, nhưng dựa trên trường hữu hạn. Chúng tôi giới thiệu một giá trị mới, ký hiệu là α\alphaα, và tuyên bố rằng nó thỏa mãn một mối quan hệ nhất định, chẳng hạn như α2=some value\alpha^2 = \text {some value}α2=some value. Bằng cách này, chúng ta tạo ra một cấu trúc toán học mới có khả năng thực hiện các phép toán phức tạp hơn trên các trường hữu hạn. Trong miền mở rộng này, phép tính phép nhân trở thành phép nhân sử dụng giá trị mới α\alphaα. Bây giờ chúng ta có thể thao tác trên các cặp giá trị trong một miền mở rộng chứ không chỉ các số đơn lẻ. Ví dụ: nếu chúng tôi đang làm việc trên một lĩnh vực như Mersenne hoặc BabyBear, thì tiện ích mở rộng như vậy cho phép chúng tôi có nhiều lựa chọn giá trị hơn, do đó cải thiện tính bảo mật. Để tăng thêm kích thước trường, chúng ta có thể áp dụng lặp đi lặp lại kỹ thuật tương tự. Vì chúng ta đã sử dụng α\alphaα nên chúng ta cần xác định một giá trị mới, giá trị này trong Mersenne31 được biểu thị bằng cách chọn α\alphaα sao cho α2=some value\alpha^2 = \text {some value}α2=some value.

Mã (bạn có thể cải thiện nó bằng Karatsuba )
Bằng cách mở rộng trường, Bây giờ chúng tôi có đủ giá trị để lựa chọn đáp ứng nhu cầu bảo mật của chúng tôi. Nếu bạn đang xử lý các đa thức có bậc nhỏ hơn ddd, điều này cung cấp 104 bit bảo mật mỗi vòng. Điều này có nghĩa là chúng tôi có đủ an ninh. Nếu cần mức bảo mật cao hơn, chẳng hạn như 128-bit, chúng tôi có thể thêm một số công việc tính toán bổ sung vào giao thức để tăng cường bảo mật.
Miền mở rộng chỉ thực sự được sử dụng trong giao thức FRI (Fast Reed-Solomon Interactive) và các tình huống khác yêu cầu kết hợp tuyến tính ngẫu nhiên. Hầu hết phép toán vẫn được thực hiện trên các trường cơ bản, thường là các trường modulo ppp hoặc qqq. Ngoài ra, hầu hết tất cả dữ liệu đã băm đều được thực hiện trên các trường cơ bản, do đó chỉ có bốn byte cho mỗi giá trị được băm. Làm như vậy sẽ tận dụng được hiệu quả của các trường nhỏ đồng thời cho phép sử dụng các trường lớn hơn khi cần cải thiện bảo mật.
FRI thông thường
Khi xây dựng SNARK hoặc STARK, bước đầu tiên thường là số học hóa. Đây là sự chuyển đổi bất kỳ vấn đề tính toán nào thành một phương trình trong đó một số biến và hệ số là đa thức. Cụ thể, phương trình này thường có dạng P (X,Y,Z)=0P (X,Y,Z) = 0P (X,Y,Z)=0, trong đó P là đa thức và Z là tham số đã cho và người giải cần cung cấp các giá trị X và Y. Khi bạn có một phương trình như vậy, nghiệm của phương trình đó sẽ tương ứng với nghiệm của bài toán tính toán cơ bản.
Để chứng minh rằng bạn có lời giải, bạn cần chỉ ra rằng các giá trị bạn đưa ra thực sự là những đa thức hợp lý (chứ không phải phân số, hoặc trong một số trường hợp những nơi trông giống như một đa thức, nhưng lại là một đa thức khác ở nơi khác, v.v.), và những đa thức này có một mức độ tối đa nhất định. Để làm điều này, chúng tôi sử dụng ứng dụng từng bước các kỹ thuật kết hợp tuyến tính ngẫu nhiên:
Giả sử bạn có Đánh giá đa thức A. Bạn muốn chứng minh rằng bậc của nó nhỏ hơn 2^{20>
Xét đa thức B ( x ^2) = A (x) + A (-x), C (x^2) = \frac {A (x) - A (-x)}{x>
-
D là tổ hợp tuyến tính ngẫu nhiên của B và C, nghĩa là D=B+rCD = B + rCD=B+rC, trong đó r là hệ số ngẫu nhiên.
Về cơ bản, điều xảy ra là B cô lập các hệ số chẵn A và ? cô lập các hệ số lẻ. Cho B và C, bạn có thể khôi phục đa thức A ban đầu: A (x) = B (x^2) + xC (x^2). Nếu bậc của A thực sự nhỏ hơn 2^{20} thì bậc của B và C sẽ lần lượt là bậc của A và bậc của A trừ 1. Vì sự kết hợp giữa số chẵn và số lẻ không làm tăng độ. Vì D là tổ hợp tuyến tính ngẫu nhiên của B và C nên bậc của D cũng phải là bậc của A, điều này cho phép bạn sử dụng bậc của D để xác minh rằng bậc của A đáp ứng yêu cầu.
Đầu tiên, FRI đơn giản hóa quá trình xác minh bằng cách giảm bài toán chứng minh đa thức bậc d xuống bài toán chứng minh đa thức bậc d/2. Quá trình này có thể được lặp lại nhiều lần, mỗi lần đơn giản hóa vấn đề đi một nửa.
FRI hoạt động bằng cách lặp lại quá trình đơn giản hóa này. Ví dụ, nếu bạn bắt đầu bằng cách chứng minh rằng bậc của đa thức là d, thông qua một loạt các bước cuối cùng bạn sẽ chứng minh được rằng bậc của đa thức là d/2. Sau mỗi lần đơn giản hóa, bậc của đa thức thu được giảm dần. Nếu đầu ra của một giai đoạn không có mức độ đa thức như mong đợi thì vòng kiểm tra này sẽ thất bại. Nếu ai đó cố gắng đẩy một đa thức không có bậc d thông qua kỹ thuật này, thì ở vòng đầu ra thứ hai, bậc của nó sẽ không đáp ứng được mong đợi với một xác suất nhất định và ở vòng thứ ba, nó sẽ có nhiều khả năng không nhất quán, và cuối cùng Việc kiểm tra sẽ thất bại. Thiết kế này có thể phát hiện và loại bỏ hiệu quả những đầu vào không đáp ứng yêu cầu. Một tập dữ liệu có khả năng vượt qua xác thực FRI nếu nó bằng đa thức bậc d ở hầu hết các vị trí. Tuy nhiên, để xây dựng một tập dữ liệu như vậy, kẻ tấn công cần phải biết các đa thức thực tế, do đó, ngay cả một bằng chứng hơi thiếu sót cũng cho thấy rằng người chứng minh có thể tạo ra bằng chứng "thực".
Chúng ta hãy xem xét kỹ hơn những gì đang diễn ra ở đây và các thuộc tính cần thiết để thực hiện tất cả những điều này. Ở mỗi bước, chúng ta giảm một nửa mức độ của đa thức và cũng giảm một nửa tập hợp các điểm (tập hợp các điểm mà chúng ta quan tâm). Cái trước là chìa khóa để làm cho giao thức FRI (Fast Reed-Solomon Interactive) hoạt động bình thường. Vòng sau làm cho thuật toán chạy cực kỳ nhanh: do kích thước của mỗi vòng giảm đi một nửa so với vòng trước nên tổng chi phí tính toán là O (N) thay vì O (N*log (N)).
Để đạt được mức giảm lũy tiến của miền, ánh xạ hai thành một được sử dụng, nghĩa là mỗi điểm được ánh xạ tới một trong hai điểm điểm. Ánh xạ này cho phép chúng tôi giảm một nửa kích thước của tập dữ liệu. Ưu điểm quan trọng của ánh xạ hai-một này là nó có thể lặp lại. Nghĩa là khi chúng ta áp dụng ánh xạ này, tập kết quả thu được vẫn giữ nguyên các thuộc tính. Giả sử chúng ta bắt đầu với một nhóm con nhân. Nhóm con này là một tập hợp S trong đó mọi phần tử x đều có bội số 2x trong tập hợp đó. Nếu bạn bình phương tập hợp S (tức là ánh xạ từng phần tử x trong tập hợp thành x^2), thì tập hợp S^2 mới sẽ giữ nguyên các thuộc tính. Hoạt động này cho phép chúng tôi tiếp tục giảm kích thước của tập dữ liệu cho đến khi cuối cùng chỉ còn lại một giá trị. Mặc dù về lý thuyết, chúng tôi có thể thu nhỏ tập dữ liệu xuống chỉ một giá trị, nhưng trên thực tế, chúng tôi thường dừng lại trước khi đạt đến tập hợp nhỏ hơn.
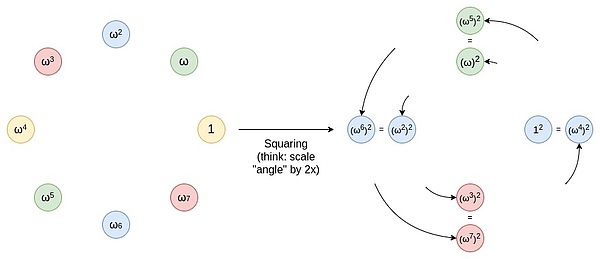
Bạn có thể coi thao tác này như một quá trình kéo dài một đường thẳng (ví dụ: một đoạn thẳng hoặc một cung) trên chu vi của một vòng tròn để nó quay hai lần quanh vòng tròn. Ví dụ: nếu một điểm ở vị trí x độ trên chu vi, nó sẽ di chuyển lên 2x độ sau thao tác này. Mỗi điểm trên đường tròn từ 0 đến 179 độ đều có một điểm tương ứng từ 180 đến 359 độ và hai điểm này sẽ trùng nhau. Điều này có nghĩa là khi bạn ánh xạ một điểm từ x độ đến 2x độ, nó sẽ trùng với vị trí ở x+180 độ. Quá trình này có thể được lặp đi lặp lại. Nghĩa là, bạn có thể áp dụng thao tác ánh xạ này nhiều lần, mỗi lần di chuyển các điểm trên chu vi đến vị trí mới của chúng.
Để kỹ thuật ánh xạ có hiệu quả, kích thước của nhóm con nhân ban đầu cần phải có thừa số lũy thừa lớn là 2. BabyBear là một hệ thống có mô đun nhất định sao cho nhóm con nhân tối đa của nó chứa tất cả các giá trị khác 0, sao cho kích thước của nhóm con là 2k−1 (trong đó k là số chữ số trong mô đun). Các nhóm con có kích thước này rất phù hợp với kỹ thuật trên vì nó cho phép giảm bậc của đa thức một cách hiệu quả bằng cách áp dụng lặp lại phép toán ánh xạ. Trong BabyBear, bạn có thể chọn một nhóm con có kích thước 2^k (hoặc chỉ sử dụng toàn bộ nhóm), sau đó áp dụng phương pháp FRI để giảm dần bậc của đa thức xuống 15 và kiểm tra bậc của đa thức ở cuối. Phương pháp này tận dụng các đặc tính của mô đun và kích thước của nhóm con nhân, giúp cho quá trình tính toán trở nên rất hiệu quả. Mersenne31 là một hệ thống khác có mô đun có giá trị nào đó sao cho kích thước của nhóm con nhân là 2^31 - 1. Trong trường hợp này, kích thước của nhóm con nhân chỉ có thừa số là 2, điều này cho phép chia nó cho 2 chỉ một lần. Quá trình xử lý sau đó không còn phù hợp với các kỹ thuật trên, tức là không thể sử dụng FFT để giảm bậc đa thức hiệu quả như BabyBear.
Các miền Mersenne31 lý tưởng để thực hiện các phép toán số học trên các hoạt động CPU/GPU 32-bit hiện có. Do các thuộc tính mô đun của nó (chẳng hạn như 2^{31} - 1), nhiều phép toán có thể được hoàn thành bằng cách sử dụng các phép toán bit hiệu quả: nếu kết quả của việc cộng hai số vượt quá mô đun, thì kết quả có thể được dịch chuyển bằng phép toán mô đun để giảm nó đến một phạm vi thích hợp. Hoạt động dịch chuyển là một hoạt động rất hiệu quả. Trong các phép nhân, các lệnh CPU cụ thể (thường được gọi là lệnh dịch bậc cao) được sử dụng để xử lý kết quả. Các hướng dẫn này có thể tính toán hiệu quả phần bậc cao của phép nhân, từ đó nâng cao hiệu quả của phép toán. Trong miền Mersenne31, các phép tính số học nhanh hơn khoảng 1,3 lần so với miền BabyBear do các đặc tính được mô tả ở trên. Mersenne31 mang lại hiệu quả tính toán cao hơn. Nếu FRI có thể được triển khai trong miền Mersenne31, điều này sẽ cải thiện đáng kể hiệu quả tính toán và làm cho các ứng dụng FRI hiệu quả hơn.
Circle FRI
Đó là điều thú vị về Circle STARK được cấp cho số nguyên tố p, một quần thể có kích thước p có thể được tìm thấy có các thuộc tính hai-một tương tự. Quần thể này bao gồm tất cả các điểm thỏa mãn các điều kiện nhất định, ví dụ: tập hợp các điểm trong đó x^2 mod p bằng một giá trị nhất định.
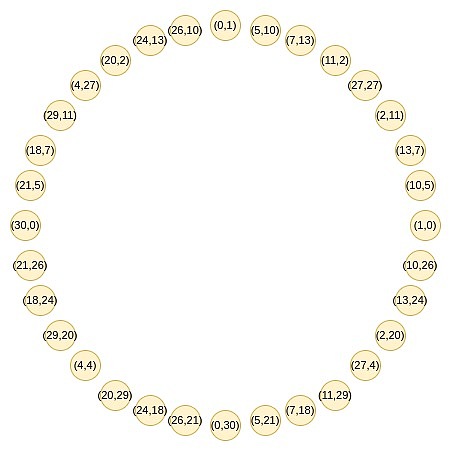
Những điểm này tuân theo một mẫu cộng, có vẻ quen thuộc với bạn nếu gần đây bạn đã làm bất cứ điều gì liên quan đến lượng giác hoặc phép nhân phức tạp.
(x_1, y_1) + (x_2, y_2) = (x_1x_2 - y_1y_2, x_1y_2 + x_2y_1)
< p style="text-align: left;">Dạng nhân đôi là:
2 * (x, y) = (2x^2 - 1, 2xy)
Bây giờ, chúng ta hãy tập trung vào các điểm đánh số lẻ trên vòng tròn:
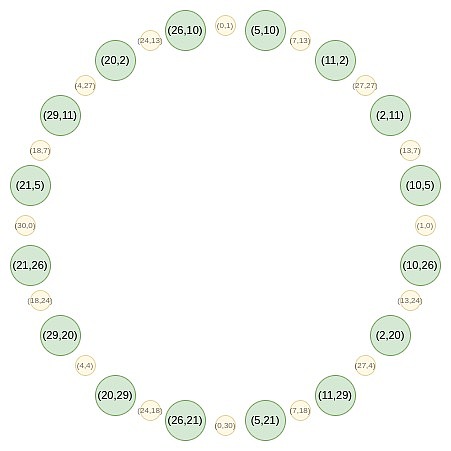
Đầu tiên, chúng ta hội tụ tất cả các điểm thành một đường thẳng. Dạng tương đương của công thức B (x²) và C (x²) mà chúng tôi sử dụng trong FRI thông thường là:
f_0 (x) = \frac { F (x,y) + F (x,-y)}{2}
Sau đó, chúng ta có thể thực hiện các kết hợp tuyến tính ngẫu nhiên để có được For là P(x một chiều), đa thức này được xác định trên một tập con của dòng x:

Bắt đầu từ vòng thứ hai, ánh xạ đã thay đổi:
f_0 (2x^2-1) = \frac {F (x) + F (-x)}{2}
Việc ánh xạ này thực sự mỗi lần giảm kích thước của tập hợp trên xuống một nửa, điều đang xảy ra ở đây là mỗi x đại diện cho hai điểm theo một nghĩa: (x, y) và (x, -y) . Và (x → 2x^2 - 1) là quy tắc nhân đôi điểm ở trên. Do đó, ta quy đổi tọa độ x của hai điểm đối nhau trên đường tròn thành tọa độ x của điểm bị nhân.
Ví dụ: nếu chúng ta lấy giá trị thứ hai trên vòng tròn tính từ bên phải là 2 và áp dụng ánh xạ 2 → 2 (2^2) - 1 = 7, Kết quả ta được là 7. Nếu chúng ta quay lại hình tròn ban đầu, (2, 11) là điểm thứ ba tính từ bên phải, nhân đôi để chúng ta có điểm thứ sáu tính từ bên phải, tức là (7, 13).
Việc này có thể được thực hiện theo hai chiều, nhưng việc vận hành theo một chiều sẽ giúp quy trình hiệu quả hơn.
Vòng tròn FFT
Một thuật toán có liên quan chặt chẽ với FRI là FFT, Chuyển đổi n đánh giá của đa thức bậc nhỏ hơn n đến n hệ số của đa thức. Quá trình của FFT tương tự như FRI, ngoại trừ việc thay vì tạo ra một tổ hợp tuyến tính ngẫu nhiên của f_0 và f_1 ở mỗi bước, FFT thực hiện đệ quy một FFT có kích thước bằng một nửa trên chúng và chuyển đổi FFT (f_0). Đầu ra của FFT (f_1) là được sử dụng làm hệ số chẵn và đầu ra của FFT (f_1) được sử dụng làm hệ số lẻ.
Nhóm vòng tròn cũng hỗ trợ FFT, được xây dựng theo cách tương tự như FRI. Tuy nhiên, điểm khác biệt chính là Circle FFT (và Circle FRI) xử lý các đối tượng không phải là đa thức. Thay vào đó, chúng được gọi là không gian Riemann-Roch về mặt toán học: trong trường hợp này, đa thức có dạng tròn modulo ( x^2 + y^2 - 1 = 0 ). Nghĩa là, chúng ta coi mọi bội số của x^2 + y^2 - 1 đều bằng 0. Một cách khác để nghĩ về nó là: chúng tôi chỉ cho phép y có lũy thừa: ngay khi thuật ngữ y^2 xảy ra, chúng tôi thay thế nó bằng 1 - x^2 .
Điều này cũng có nghĩa là các hệ số đầu ra của Circle FFT không phải là đơn thức như FRI thông thường (ví dụ: nếu đầu ra FRI thông thường là [6, 2, 8, 3], thì chúng ta biết rằng điều này có nghĩa P (x) = 3x^3 + 8x^2 + 2x + 6). Ngược lại, các hệ số của Circle FFT đặc trưng cho cơ sở Circle FFT: {1, y, x, xy, 2x^2 - 1, 2x^2y - y, 2x^3 - x, 2x^3y - xy, 8x^4 - 8x^2 + 1...
Tin vui là với tư cách là nhà phát triển, bạn gần như có thể hoàn toàn bỏ qua điều này. STARK không bao giờ yêu cầu bạn phải biết các hệ số. Thay vào đó, bạn chỉ cần lưu trữ đa thức dưới dạng tập hợp các giá trị đánh giá trên một miền cụ thể. Nơi duy nhất mà bạn cần sử dụng FFT là thực hiện mở rộng mức độ thấp (tương tự như không gian Riemann-Roch): cho trước các giá trị N, tạo ra các giá trị k*N, tất cả trên cùng một đa thức. Trong trường hợp này, bạn có thể sử dụng FFT để tạo các hệ số, thêm (k-1) n số 0 vào các hệ số này, sau đó sử dụng FFT nghịch đảo để thu được tập hợp giá trị được đánh giá lớn hơn.
Hình tròn FFT không phải là loại FFT đặc biệt duy nhất. Đường cong Elliptic FFT mạnh hơn vì chúng có thể hoạt động trên bất kỳ trường hữu hạn nào (trường nguyên tố, trường nhị phân, v.v.). Tuy nhiên, ECFFT phức tạp hơn và kém hiệu quả hơn, vì vậy vì chúng tôi có thể sử dụng Circle FFT trên p = 2^{31}-1 nên chúng tôi chọn sử dụng nó.
Từ đây, chúng ta sẽ đi sâu vào một số chi tiết khó hiểu hơn khiến việc triển khai Circle STARK khác với STARK thông thường.
Quotiienting
Trong giao thức STARK, một thao tác phổ biến là thực hiện một Quotient điểm cụ thể hoạt động, những điểm này có thể được chọn có chủ ý hoặc ngẫu nhiên. Ví dụ: nếu bạn muốn chứng minh P (x) = y, bạn có thể tiến hành các bước sau:
Tính thương: Cho đa thức P ( x) và hằng số y, Tính thương Q ={P - y}/{X - x}, trong đó X là điểm được chọn.
Chứng minh đa thức: Chứng minh Q là đa thức, không phải là phân số. Bằng cách này, người ta chứng minh được P (x)=y là đúng.
Ngoài ra, trong DEEP-FRI giao thức, các điểm đánh giá được chọn ngẫu nhiên nhằm giảm số lượng nhánh Merkle, từ đó nâng cao tính bảo mật và hiệu quả của FRI giao thức.
Khi xử lý giao thức STARK của nhóm vòng tròn, do không có hàm tuyến tính nào có thể đi qua một điểm duy nhất nên cần sử dụng các kỹ thuật khác nhau để thay thế giao thức truyền thống phương pháp hoạt động thương số. Điều này thường đòi hỏi phải thiết kế các thuật toán mới sử dụng các đặc tính hình học độc đáo của các nhóm vòng tròn.
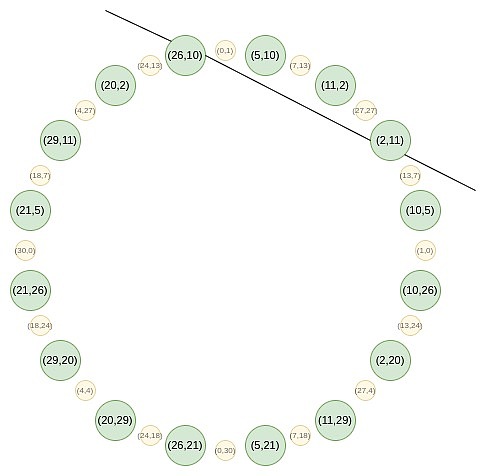
Trong nhóm đường tròn, bạn có thể xây dựng hàm tiếp tuyến sao cho nó tiếp xúc với điểm tại một điểm nhất định (P_x, P_y), nhưng hàm này sẽ có bội số 2 qua điểm, Tức là là, để một đa thức là bội số của hàm tuyến tính này, nó phải thỏa mãn các điều kiện chặt chẽ hơn là chỉ bằng 0 tại điểm đó. Vì vậy, bạn không thể chỉ chứng minh kết quả đánh giá tại một thời điểm. Vậy chúng ta giải quyết vấn đề này như thế nào?
Chúng ta phải chấp nhận thử thách này và chứng minh nó bằng cách đánh giá ở hai điểm, từ đó thêm một điểm ảo mà chúng ta không cần tập trung vào.

Hàm dòng: ax + by + c. Nếu bạn biến nó thành một phương trình, buộc nó bằng 0, thì bạn có thể nhận ra nó là một đường thẳng ở dạng chuẩn trong môn toán trung học.
Nếu chúng ta có đa thức P bằng y_1 tại x_1 và bằng y_2 tại x_2, chúng ta có thể chọn hàm nội suy L bằng y_1 tại x_1 bằng y_1 và bằng y_2 tại x_2. Điều này có thể được biểu thị đơn giản là L = \frac {y_2 - y_1}{x_2 - x_1} \cdot (x - x_1) + y_1.
Sau đó, chúng ta chứng minh P bằng y_1 tại x_1 và bằng y_2 tại x_2, bằng cách trừ L (sao cho P - L bằng 0) , rồi chia L (tức là hàm tuyến tính giữa x_2 - x_1) cho L để chứng minh thương Q là đa thức.
Đa thức biến mất
Trong STARK, phương trình đa thức bạn đang cố chứng minh thường có dạng là C (P (x), P ({next}(x))) = Z (x) ⋅ H (x) , trong đó Z (x) là một đa thức bằng 0 trên toàn bộ miền đánh giá ban đầu. Trong STARK thông thường, hàm này là x^n - 1. Trong STARK hình tròn, hàm tương ứng là:
Z_1 (x,y) = y
Z_2 (x,y) = x
Z_{n+1 } (x,y) = (2 * Z_n (x,y)^2) - 1
Lưu ý rằng bạn có thể Suy ra đa thức biến mất: Trong STARK thông thường, bạn sử dụng lại x → x^2 và trong STARK tròn, bạn sử dụng lại x → 2x^2 - 1. Tuy nhiên, đối với vòng đầu tiên, bạn làm khác đi vì vòng đầu tiên rất đặc biệt.
Đảo ngược thứ tự bit
Trong STARK, đa thức thường không được đánh giá theo kiểu "tự nhiên" không tuần tự (ví dụ: P (1), P (ω), P (ω2),…, P (ωn−1)), mà theo thứ tự mà tôi gọi là thứ tự bit ngược:
P (\omega^{\frac {3n}{8}})
Nếu chúng ta đặt n =16 và chỉ tập trung vào lũy thừa của ω mà chúng ta đánh giá, khi đó danh sách sẽ trông như thế này:
{0, 8, 4, 12, 2, 10, 6, 14, 1, 9, 5, 13, 3, 11, 7, 15
Một thuộc tính quan trọng của điều này sắp xếp là các giá trị được nhóm lại với nhau sớm trong quá trình đánh giá FRI sẽ liền kề trong quá trình sắp xếp. Ví dụ: bước đầu tiên của FRI sẽ là x và -x Nhóm. 16 , ω^8 = -1, nghĩa là P (ω^i) ) và ( P (-ω^i) = P (ω^{i+8} ) \). Như chúng ta có thể thấy, đây chính xác là những cặp nằm ngay cạnh nhau. Bước thứ hai của nhóm FRI P (ω^i) , P (ω^{i+4}) , P (ω^{i+8}) và P (ω^{i+12}). Đây chính xác là những gì chúng ta thấy trong nhóm bốn người, v.v. Việc làm này giúp FRI tiết kiệm không gian hơn vì nó cho phép bạn cung cấp bằng chứng Merkle cho các giá trị được gấp lại với nhau (hoặc, nếu bạn gấp k vòng cùng một lúc, tất cả các giá trị 2^k).
Trong STARK hình tròn, cấu trúc gấp hơi khác một chút: ở bước đầu tiên, chúng ta so sánh (x, y) với (x, -y) Pair; ở bước thứ hai, ghép x với -x; ở bước tiếp theo, ghép p với q , chọn p q sao cho Q^i ( p) = -Q ^i (q), trong đó Q^i là ánh xạ lặp lại x → 2x^2-1 i lần. Nếu chúng ta nghĩ về các điểm theo vị trí của chúng trên vòng tròn thì ở mỗi bước, điểm này trông giống như điểm đầu tiên được ghép với điểm cuối cùng, điểm thứ hai với điểm thứ hai đến điểm cuối cùng, v.v.
Để điều chỉnh thứ tự bit đảo ngược nhằm phản ánh cấu trúc gấp này, chúng ta cần đảo ngược mọi bit ngoại trừ bit cuối cùng. Chúng tôi giữ bit cuối cùng và sử dụng nó để quyết định xem có lật các bit khác hay không.
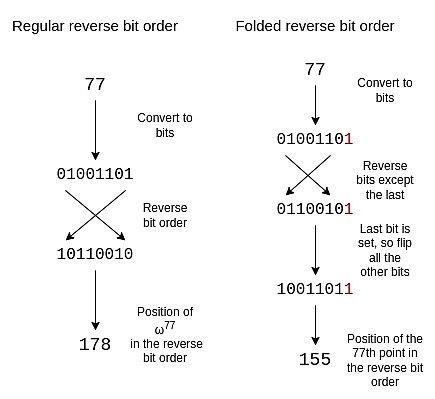
Thứ tự đảo ngược của nếp gấp 16 như sau:
{0, 15, 8, 7 , 4, 11, 12, 3, 2, 13, 10, 5, 6, 9, 14, 1}
Nếu bạn quan sát Đối với đường tròn trong một phần, bạn sẽ thấy các điểm 0, 15, 8 và 7 (ngược chiều kim đồng hồ từ bên phải) là (x, y), (x, -y), (-x, -y) và (- x, y), đó chính xác là những gì chúng ta cần.
Hiệu quả
Trong các STARK hình tròn (và STARK nguyên tố 31 bit nói chung), những điều này Giao thức này rất hiệu quả. Một phép tính đã được chứng minh trong Circle STARK thường bao gồm một số loại phép tính:
1. Số học gốc: được sử dụng cho logic nghiệp vụ, chẳng hạn như đếm.
2. Số học nguyên gốc: được sử dụng trong mật mã, chẳng hạn như các hàm băm như Poseidon
3. Tra cứu tham số: Một phương pháp tính toán tổng quát và hiệu quả thực hiện nhiều phép tính khác nhau bằng cách đọc các giá trị từ bảng.
Thước đo chính của hiệu quả là liệu bạn có tận dụng tối đa toàn bộ không gian trong dấu vết tính toán của mình để thực hiện công việc hữu ích hay bạn đang để lại nhiều không gian trống . Trong SNARK dành cho các trường lớn, thường có nhiều không gian trống: logic nghiệp vụ và bảng tra cứu thường liên quan đến các phép tính trên các số nhỏ (các số này có xu hướng nhỏ hơn N, trong đó N là tổng số bước trong một phép tính, vì vậy trong thực hành ít hơn 2^{25 }), nhưng bạn vẫn phải trả chi phí sử dụng trường có kích thước 2^{256} bit. Ở đây, kích thước của trường là 2^{31}, do đó không gian bị lãng phí không lớn. Hàm băm có độ phức tạp số học thấp được thiết kế cho SNARK (chẳng hạn như Poseidon) tận dụng tối đa từng bit của mọi số trong dấu vết trong bất kỳ trường nào.
Binius là giải pháp tốt hơn Circle STARK vì nó cho phép bạn kết hợp các trường có kích thước khác nhau, dẫn đến việc đóng gói bit hiệu quả hơn. Binius cũng cung cấp tùy chọn thực hiện các phép cộng 32 bit mà không cần sử dụng bảng tra cứu. Tuy nhiên, những ưu điểm này (theo ý kiến của tôi) phải trả giá bằng việc làm cho khái niệm trở nên phức tạp hơn, trong khi Circle STARK (và STARK dựa trên BabyBear thông thường) về mặt khái niệm đơn giản hơn nhiều.
Kết luận: Suy nghĩ của tôi về Circle STARKs
Circle STARKs Dành cho nhà phát triển Không còn nữa phức tạp hơn STARK. Trong quá trình triển khai, ba vấn đề nêu trên về cơ bản là những điểm khác biệt so với FRI thông thường. Mặc dù phép toán đằng sau các đa thức mà Circle FRI vận hành rất phức tạp và cần một chút thời gian để hiểu và đánh giá cao, nhưng sự phức tạp này thực sự bị ẩn giấu đến mức các nhà phát triển không thể trực tiếp cảm nhận được.
Hiểu về Circle FRI và Circle FFT cũng có thể là một cách để hiểu các FFT đặc biệt khác: đáng chú ý nhất là các FFT tên miền nhị phân, chẳng hạn như Binius và các FFT trước đó LibSTARK sử dụng FFT, cũng như một số cấu trúc phức tạp hơn, chẳng hạn như FFT đường cong elip. Các FFT này sử dụng ánh xạ từ ít đến nhiều và có thể được kết hợp tốt với các phép toán điểm trên đường cong elip.
Kết hợp với Mersenne31, BabyBear và các công nghệ miền nhị phân như Binius, chúng tôi thực sự cảm thấy như mình đang đạt đến giới hạn hiệu quả của lớp cơ sở STARK. Tại thời điểm này, tôi dự đoán hướng tối ưu hóa của STARK sẽ tập trung vào các điểm sau:
Số học hóa hàm băm và chữ ký để tối đa hóa hiệu quả : Tối ưu hóa các nguyên hàm mã hóa cơ bản chẳng hạn như hàm băm và chữ ký số thành các dạng hiệu quả nhất để chúng có thể đạt được hiệu suất tốt nhất khi được sử dụng trong bằng chứng STARK. Điều này có nghĩa là phải tối ưu hóa đặc biệt cho những nguyên thủy này để giảm nỗ lực tính toán và tăng hiệu quả.
Xây dựng đệ quy để cho phép song song hóa nhiều hơn: Xây dựng đệ quy đề cập đến việc áp dụng quy trình chứng minh STARK đệ quy ở các cấp độ khác nhau, từ đó tăng khả năng xử lý song song. Bằng cách này, tài nguyên máy tính có thể được sử dụng hiệu quả hơn và quá trình chứng minh có thể được tăng tốc.
Máy ảo số học giúp cải thiện trải nghiệm của nhà phát triển: Việc xử lý số học của máy ảo cho phép các nhà phát triển tạo và chạy các tác vụ tính toán hiệu quả và đơn giản hơn . Điều này bao gồm việc tối ưu hóa máy ảo để sử dụng trong các bằng chứng STARK và cải thiện trải nghiệm của nhà phát triển khi xây dựng và thử nghiệm các hợp đồng thông minh hoặc các tác vụ điện toán khác.


 Anais
Anais





