来源:PermaDAO
AO 是为链上 AI 设计的异步通信网络,通过与 Arweave 的结合,实现高性能链下计算和永久数据存储。文章介绍了在 AO 上运行 AI 进程的步骤,尽管目前仅支持小型模型,但未来将支持更复杂的计算能力,AI 在链上的发展前景广阔。
什么是 AO 上的 AI?
AO 天生就是为链上 AI 设计的
2023 年被称为 AI 的元年,各种大模型以及 AI 的应用层出不穷。Web3 的世界中,AI 的发展也是关键的一环。但是一直以来,“区块链不可能三角”让区块链的计算一直处于昂贵、拥堵的状态,阻碍了 AI 在 Web 3 上的发展。但是现在这种情况在 AO 上已经得到了初步改善,并且展现了无限的潜力。
AO 被设计为一个消息驱动的异步通信网络。基于存储共识范式(SCP),AO 运行在 Arweave 之上,实现了与 Arweave 的无缝集成。在这种创新的范式中,存储(共识)与计算被有效地分离,使得链下计算和链上共识成为可能。
高性能计算:智能合约的计算在链下执行,不再受制于链上的区块共识过程,从而大大扩展了计算性能。不同节点上的各个进程可以独立地执行并行计算和本地验证,而无需像传统的 EVM 架构中那样等待所有节点完成重复计算和全局一致性验证。Arweave 为 AO 提供了所有指令、中间状态和计算结果的永久存储,作为 AO 的数据可用层和共识层。因此,高性能计算(包括使用 GPU 进行运算)都成为了可能。
永存的数据:这是 Arweave 一直以来所致力于做的事情。我们知道 AI 的训练中很关键的一个环节就是训练数据的收集,而这正好是 Arweave 的强项。至少 200 年时间的数据永存,让 AO + Arweave 的生态中拥有了丰富的数据集。
此外,AO 和 Arweave 的创始人 Sam 在今年 6 月的一次发布会上演示了第一个基于 aos-llama 的 AI 进程。为了保证性能,并没有使用之前一直使用的 Lua,而是使用了 C 编译的 wasm。
使用的模型是 huggingface 上开源的 llama 2。可以在 Arweave 上下载模型,是一个约 2.2GB 的模型文件。
Llama land
Llama Land 是一款前沿的大型多人在线(MMO)游戏,它以 AI 技术为核心,构建于先进的 AO 平台之上。也是在 AO + Arweave 生态上的首个 AI 应用。其中最主要的特征就是 llama coin 的发行,是 100% AI 控制的,也就是用户跟 Llama king 祈愿,得到 Llama king 赏赐的 llama coin。另外,地图中的 Llama Joker、Llama oracle 也都是基于 AI 进程完成的 NPC。
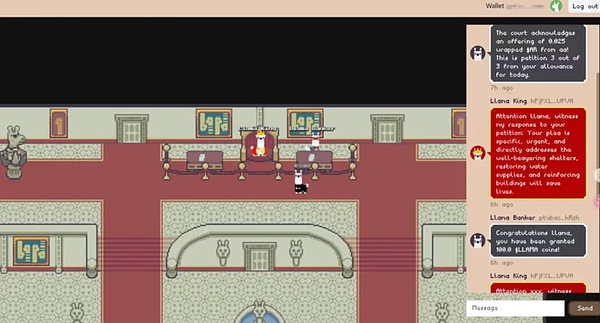
那么接下来我们看看如何自己在 AO 上跑一个 AI 进程。
AI Demo
1. 整体介绍
我们是利用 Sam 已经在 AO 上部署好的 AI 服务来实现我们自己 AI 应用。Sam 部署的 AI 服务由两部分组成:llama-herd、llama-worker(多个 llama-worker)。其中 llama-herd 负责 AI 任务的分派,AI 任务的定价。llama-worker 则是真正跑大模型的进程。然后,我们的 AI 应用是通过请求 llama-herd 来实现 AI 能力的,在请求的同时也会需要支付一定的 wAR。
注意:或许你会疑惑,我们为什么不自己跑 llama-worker 来实现自己的 AI 应用呢?因为 AI 的 module 在实例化为进程的时候,需要 15GB 的内存,我们自己实例化会出现内存不足的报错。
2. 创建进程并充值 wAR
首先,我们需要创建进程,并尽量把进程都升级到最新版本,再进行后续的操作。可以避免一些错误,节约很多时间。

运行 AI 进程需要耗费少量的 wAR。通过 arconnect 转成功以后,会在进程中看到 Action = Credit-Notice 的一条消息。执行一次 AI 需要消耗 wAR,但是消耗的并不多,作为 demo 之用的话,向进程转 0.001 wAR 即可。
注意:wAR 可以通过 AOX 跨链桥获取,跨链需要 3 ~ 30 分钟。
可以通过以下命令查看当前进程中 wAR 的余额。下面是我执行了 5 次左右还剩下的 wAR。消耗的数量跟 token 的长度以及当前运行一次大模型的实时价格有关系。另外,如果当前请求处于拥堵状态,那么也会需要一个额外的费用。(在文章最后,我会根据代码详细解析下费用计算,感兴趣的小伙伴可以看看)
注意:这里小数点为 12 位,也就是说 999999673 表示的是 0.000999999673 个 wAR。

3. 安装/更新 APM

APM 全称为 ao package management,构建 AI 进程的话,需要通过 APM 安装对应的包。执行上述命令,出现对应的提示,就是安装/更新 APM 成功了。
4. 安装 Llama Herder

执行完成以后,在进程内会有一个 Llama 对象,可以通过输入 Llama 进行访问,那么 Llama Herder 就是安装成功了。

注意:这里如果运行的进程中没有足够的 wAR 则 Llama.run 方法是无法执行的,会出现 Transfer Error。需要按照第一步充值 wAR。
5. Hello Llama
接下来我们做一个简单的交互。问一下 AI 进程“生命的意义是什么?”,限定了最多生成 20 个 token。然后把结果放到 OUTPUTS 中。AI 进程的执行需要几分钟的时间,如果有 AI 任务排队的话,则需要等待更久。
如下面代码中的返回,AI 回复“生命的意义是一个深刻而哲学的问题,一直吸引着人类。”

注意:这里如果运行的进程中没有足够的 wAR 则 Llama.run 方法是无法执行的,会出现 Transfer Error。需要按照第一步充值 wAR。
6. 做一个 Llama Joker
更加深入一步,我们来看下 Llama Joker 的实现。(由于篇幅有限,仅展示 AI 相关的核心代码。)
构建一个 Llama Joker 其实相当简单,与你在 Web 2 的 AI 应用中构建一个聊天机器人类似。
首先,用 <|system|> / <|user|> / <|assistant|> 在构建的 Prompt 中区分不同角色。
其次,确定好固定的提示语部分。Llama Joker 的例子中就是 <|system|> 的内容 “Tell a joke on the given topic”。
最后,构建 Llama Joker Npc 与用户进行交互。但是这里为了篇幅,直接定义了变量 local userContent = "cats"。说明了用户想听一个与猫咪相关的笑话。
是不是 so easy 呢。


更多
在链上实现 AI 的能力,在之前是无法想象的东西。现在已经可以在 AO 上,基于 AI 实现了完成度较高的应用,其前景让人期待,也给与了大家无限的想象空间。
但是就目前而言,局限也是比较明显的。目前只能支持 2 GB 左右的“小语言模型”,尚不能利用 GPU 进行运算等。不过值得庆幸的是,AO 的架构设计中也都对这些短板有着对应解决方案。例如,编译一个可以利用 GPU 的 wasm 虚拟机。
期待在不久的将来,AI 可以在 AO 的链上,开放出更加绚烂的花朵。
附录
前面留下的一个坑,一起看下 Llama AI 的费用计算。
下面是初始化好以后的 Llama 对象,分别对重要的对象给出一个我的理解。
M.herder: 存储了 Llama Herder 服务的标识符或地址。
M.token: 用于支付 AI 服务的 token。
M.feeBase: 基础费用,用于计算总费用的基础值。
M.feeToken: 每个 token 对应的费用,用于根据请求中的 token 数量计算额外费用。
M.lastMultiplier: 上一次交易费用的乘数因子,可能用于调整当前费用。
M.queueLength: 当前请求队列的长度,影响费用计算。
M.feeBump: 费用增长因子,默认设置为 1.005,意味着每次增加 0.5%。

计算费用的具体步骤:
根据 M.feeBase 加上 feeToken 与 token 数量的乘积,得到一个初始的费用。
在初始费用的基础上,再乘以 M.lastMultiplier。
最后,如果存在请求排队的情况,会再乘以 M.feeBump,也就是 1.005 得到最后的费用。
引用链接
1. Arweave 上的模型地址:
https://arweave.net/ISrbGzQot05rs_HKC08O_SmkipYQnqgB1yC3mjZZeEo
2. aos llama 源码:
https://github.com/samcamwilliams/aos-llama
3. AOX 跨链桥:
https://aox.arweave.dev/


 Weatherly
Weatherly





