AI on AO发布会的Llama Land、Apus Network是何项目
AI on AO 发布会特别介绍了两个项目:LlaMA Land 与 Apus Network。
 JinseFinance
JinseFinance

来源:元宇宙之心
2月28日路透社报道,Meta计划在7月份发布其最新版本的人工智能大型语言模型Llama 3,该模型将对用户提出的有争议的问题做出更好的回答。
Meta公司的研究人员正试图升级该模型,使其能够对存在争议的问题提供相关联的解答。
在竞争对手谷歌推出Gemini后,Meta暂停了图像生成功能,因为该功能生成的历史图像有时并不准确。

Meta的Llama 2为其社交媒体平台上的聊天机器人提供支持,但根据相关的测试,它拒绝回答一些争议性较小的问题,例如如何恶作剧朋友、如何赢得战争或怎样“杀死”汽车发动机。
然而,Llama 3能够回答“如何关闭汽车发动机”等问题,这意味着它能够理解用户想要问的是如何关闭车辆而不是真的“杀死”发动机。
报道称,Meta公司还计划在未来几周内任命一名内部人员,负责监督语气和安全培训,以努力使模型的反应更加细致入微。
其实早在今年1月份,Meta首席执行官扎克伯格(Zuckerberg)就在ins视频中宣布,Meta AI最近已开始训练Llama 3。这是LLaMa系列大型语言模型的最新一代,此前,2023年2月发布了Llama 1模型(最初文体为 “LLaMA”),7月发布了Llama 2模型。
虽然具体细节(如模型大小或多模态功能)尚未公布,但扎克伯格表示Meta打算继续开源Llama基础模型。

值得注意的是,Llama 1花了三个月的时间进行训练,Llama 2花了大约六个月的时间进行训练。如果下一代模型遵循类似的时间表,它们将于今年7月左右发布。
但Meta公司也有可能分配额外的时间进行微调,以确保模型的正确排列。
随着开源模型越来越强大和生成式人工智能模型的应用愈加广泛,我们需要更加谨慎,以降低模型被不良行为者用于恶意目的的风险。扎克伯格在发布视频中重申了Meta对模型进行“负责任、安全训练”的承诺。
扎克伯格在随后的新闻发布会上也重申了Meta对开放许可和实现AI民主化的承诺。他在接受《The Verge》采访时说:“我倾向于认为,这里最大的挑战之一是,如果你打造的东西真的很有价值,那么它最终会变得非常集中和狭隘。如果你让它更加开放,那么就能解决机会和价值不平等可能带来的大量问题。因此,这是整个开源愿景的重要组成部分。”
扎克伯格在发布视频中也强调了Meta构建AGI(人工通用智能)的长期目标,AGI是人工智能的一个理论发展阶段,在这一阶段,模型将展现出与人类智能相当或优于人类智能的整体表现。
扎克伯格也表示:“下一代服务需要构建全面的通用智能,这一点已经变得越来越清晰。打造最好的人工智能助手、为创作者服务的人工智能、为企业服务的人工智能等等,这都需要人工智能各个领域的进步,包括从推理、规划、编码到记忆和其他认知能力。”
从扎克伯格的发言中我们可以看出,Llama 3模型并不一定意味着AGI将会实现,但Meta公司正在有意识地以可能实现AGI的方式来进行LLM开发和其它AI研究。
人工智能领域的另一个新兴趋势是多模态人工智能,也就是能够理解和处理不同数据格式(或模态)的模型。
例如谷歌的Gemini、OpenAI的GPT-4V以及LLaVa、Adept或Qwen-VL等开源模型,可以在计算机视觉和自然语言处理(NLP)任务之间无缝切换,而不是开发单独的模型来处理文本、代码、音频、图像甚至视频数据。
虽然扎克伯格已经确认,Llama 3和Llama 2一样,将包括代码生成功能,但他没有明确谈到其他多模态功能。
不过,扎克伯格确实在Llama 3发布视频中讨论了他如何设想人工智能与Metaverse(元宇宙)的交集:“Meta的Ray-Ban智能眼镜是让人工智能看你所看,听你所听的理想外形,它可以随时提供帮助。”

这似乎意味着,无论是在即将发布的Llama 3版本中,还是在后续版本中,Meta对Llama模型的计划都包括将视觉和音频数据与LLM已经处理的文本和代码数据整合在一起。
这似乎也是追求AGI的自然发展。
扎克伯格在接受《The Verge》采访时表示:“你可以争论通用智能是类似于人类水平的智能,还是类似于人类加人类的智能,或者是某种遥远未来的超级智能。但对我来说,重要的部分其实是它的广度,即智能具有所有这些不同的能力,你必须能够推理并拥有直觉。”
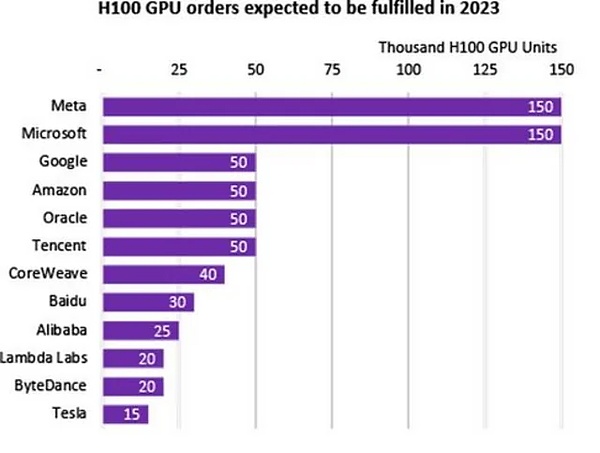
扎克伯格还宣布对培训基础设施进行大量投资。到2024年底,Meta公司打算拥有大约35万个英伟达H100 GPU。
这将使Meta公司的可用计算资源总量达到60万个H100计算当量,其中包括他们已经拥有的GPU,目前只有微软拥有与之相当的计算能力储备。
因此,我们有理由相信,即使Llama 3型号并不比前代型号大,其性能也会比Llama 2型号有大幅提升。
Deepmind在2022年3月发表的一篇论文中提出了Llama的性能会大幅提升的假设,随后Meta公司的模型和其他开源模型(例如法国Mistral公司的模型)也证明了这一点,即在更多数据上训练较小的模型比在较少数据上训练较大的模型能产生更高的性能。
虽然Llama 3模型的规模尚未公布,但很可能会延续前几代模型的模式,即在70-70亿参数模型内提高性能。Meta最近在基础设施方面的投资必将为任何规模的模型提供更强大的预训练功能。
Llama 2还将Llama 1的上下文长度增加了一倍,这意味着Llama 2在推理过程中可以“记住”两倍的上下文,Llama 3有可能在这方面取得进一步进展。
虽然较小的LLaMA和Llama 2模型在某些基准测试中达到或超过了较大的、参数为1750亿的GPT-3模型的性能,但它们无法与ChatGPT中提供的GPT-3.5和GPT-4模型相媲美。

随着新一代模型的推出,Meta似乎有意为开源世界带来最先进的性能。
扎克伯格向《The Verge》表示:“Llama 2并不是业界领先的模型,但却是最好的开源模型。有了Llama 3及以后,我们的目标是打造处于最先进水平的产品,并最终成为业界领先的模型。”
有了新的基础模型,就有了通过改进应用程序、聊天机器人、工作流程和自动化来获得竞争优势的新机会。
走在新兴发展的前列是避免落后的最佳途径,采用新工具能使企业的产品与众不同,并为客户和员工提供最佳体验。
AI on AO 发布会特别介绍了两个项目:LlaMA Land 与 Apus Network。
JinseFinance阿里巴巴强调了 Qwen-7B 和 Qwen-7B-Chat 的多功能性,使全球的学者、研究人员和商业机构可以访问它们的编码、模型权重和文档。
 Coinlive
Coinlive 虽然 2022 年对科技行业来说是艰难的一年,但 Meta 的表现尤其艰难。
 decrypt
decryptInstagram 很快将内置 NFT 创建和交易工具,但应用内购买将“收取适用的应用商店费用”。
 Others
Others从 Teams 和 Office 开始,微软表示其 Windows 操作系统也将在未来通过耳机提供。
 Beincrypto
BeincryptoMeta 于 6 月在美国启动品牌重塑,目前正在全球范围内进行变革。
Others
V神称,Meta在元宇宙创新方面起步过早,因为“现在知道人们想要什么还为时过早。”
 Cointelegraph
Cointelegraph互联网城,迪拜,2022 年 7 月 29 日——全球数字资产交易平台 LBank Exchange 已上线 META PROTOCOL (MPC) ...
 Bitcoinist
BitcoinistMeta 曾经雄心勃勃的加密货币项目的残余正在逐渐消失。根据其网站上的通知,一个试点项目......
Bitcoinist