تخريب ماكينة طباعة النقود في دائرة العملة
اختار جاي ETH بسبب العوائد المحلية التي توفرها شبكة Ethereum.
 JinseFinance
JinseFinance

المؤلف: جيف أميكو; تم إعداده بواسطة: Shenchao TechFlow
حققت ميزة Folding@home إنجازًا كبيرًا خلال جائحة كوفيد-19. حصل المشروع البحثي على 2.4 exaFLOPS من قوة الحوسبة، تم تسليمها بواسطة 2 مليون جهاز متطوع في جميع أنحاء العالم. ويمثل هذا خمسة عشر ضعف قوة المعالجة لأكبر أجهزة الكمبيوتر العملاقة في العالم في ذلك الوقت، مما يسمح للعلماء بمحاكاة ديناميكيات بروتين كوفيد على نطاق واسع. لقد أدى عملهم إلى تطوير فهمنا للفيروس وكيفية حدوثه، خاصة في وقت مبكر من الوباء.
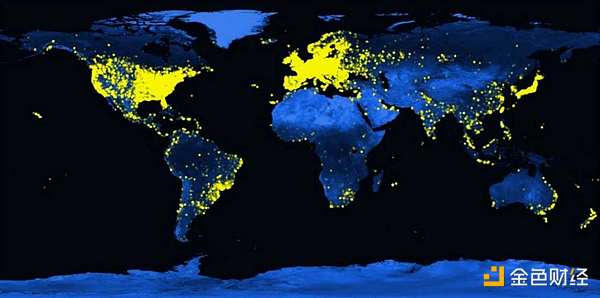
التوزيع العالمي لمستخدمي Folding@home، 2021يعتمد Folding@home على تاريخ طويل من الحوسبة التطوعية، وهو مشروع يجمع موارد الحوسبة بشكل جماعي لحل المشكلات واسعة النطاق. اكتسبت الفكرة اهتمامًا واسع النطاق في التسعينيات من خلال مشروع SETI@home، وهو مشروع جمع أكثر من 5 ملايين جهاز كمبيوتر متطوعًا للبحث عن حياة خارج كوكب الأرض. ومنذ ذلك الحين تم تطبيق الفكرة على مجموعة متنوعة من المجالات، بما في ذلك الفيزياء الفلكية، والبيولوجيا الجزيئية، والرياضيات، والتشفير، والألعاب. وفي كل حالة، عززت القوة الجماعية قدرات المشاريع الفردية بما يتجاوز بكثير ما يمكنها تحقيقه بشكل فردي. وهذا يدفع التقدم ويمكّن من إجراء البحوث بطريقة أكثر انفتاحًا وتعاونًا.
يتساءل الكثير من الناس عما إذا كان بإمكاننا تطبيق نموذج التعهيد الجماعي هذا على التعلم العميق. بمعنى آخر، هل يمكننا تدريب شبكة عصبية كبيرة على الجماهير؟ يعد التدريب على النماذج المتطورة أحد أكثر المهام الحسابية كثافة في تاريخ البشرية. كما هو الحال مع العديد من مشاريع @home، فإن التكاليف الحالية بعيدة عن متناول كبار اللاعبين فقط. وهذا قد يعيق التقدم المستقبلي لأننا نعتمد على عدد أقل من الشركات لتحقيق اختراقات جديدة. يؤدي هذا أيضًا إلى تركيز التحكم في أنظمة الذكاء الاصطناعي لدينا في أيدي عدد قليل من الأشخاص. بغض النظر عن شعورك تجاه التكنولوجيا، فهذا مستقبل يستحق المشاهدة.
يرفض معظم النقاد فكرة التدريب اللامركزي باعتبارها غير متوافقة مع تكنولوجيا التدريب الحالية. ومع ذلك، فإن هذا الرأي عفا عليه الزمن على نحو متزايد. ظهرت تقنيات جديدة تقلل الحاجة إلى الاتصال بين العقد، مما يسمح بالتدريب الفعال على الأجهزة ذات الاتصال الضعيف بالشبكة. تتضمن هذه التقنيات DiLoCo، وSWARM Parallelism، وlo-fi، والتدريب اللامركزي للنماذج الأساسية في بيئات غير متجانسة. العديد منها متسامحة مع الأخطاء وتدعم الحوسبة غير المتجانسة. هناك أيضًا بنيات جديدة مصممة خصيصًا للشبكات اللامركزية، بما في ذلك DiPaCo ونموذج الخبراء الهجين اللامركزي.
نرى أيضًا أن العديد من بدايات التشفير بدأت في النضج، مما يمكّن الشبكات من تنسيق الموارد على نطاق عالمي. تدعم هذه التقنيات سيناريوهات التطبيق مثل العملة الرقمية والمدفوعات عبر الحدود وأسواق التنبؤ. وعلى عكس المشاريع التطوعية السابقة، فإن هذه الشبكات قادرة على تجميع كميات مذهلة من قوة الحوسبة، وغالبًا ما تكون أكبر من أكبر مجموعات التدريب السحابية المتصورة حاليًا.
تشكل هذه العناصر معًا نموذجًا جديدًا للتدريب. يستفيد هذا النموذج استفادة كاملة من موارد الحوسبة في العالم، بما في ذلك العدد الهائل من الأجهزة الطرفية التي يمكن استخدامها إذا كانت متصلة ببعضها البعض. سيؤدي ذلك إلى تقليل تكلفة معظم أعباء العمل التدريبية من خلال إدخال آليات منافسة جديدة. ويمكنه أيضًا فتح تنسيقات تدريب جديدة، مما يجعل تطوير النماذج تعاونيًا ومعياريًا وليس منعزلًا ومتجانسًا. يمكن للنماذج أن تتعلم في الوقت الفعلي عن طريق استيعاب الحسابات والبيانات من الجمهور. يمكن للأفراد امتلاك أجزاء من النماذج التي يقومون بإنشائها. يمكن للباحثين أيضًا مشاركة النتائج الجديدة علنًا مرة أخرى دون الحاجة إلى استثمار نتائجهم لتغطية ميزانيات الحوسبة العالية.
يفحص هذا التقرير الوضع الحالي للتدريب على النماذج واسعة النطاق والتكاليف المرتبطة بها. وهو يستعرض جهود الحوسبة الموزعة السابقة — من SETI إلى Folding إلى BOINC — كمصدر إلهام لاستكشاف مسارات بديلة. يناقش التقرير التحديات التاريخية للتدريب اللامركزي وينتقل إلى الإنجازات الحديثة التي قد تساعد في التغلب على هذه التحديات. وأخيرا، فإنه يلخص الفرص والتحديات المستقبلية.
تكلفة التدريب على النماذج المتطورة ليس مهمًا بالنسبة للاعبين غير الكبار. الكلمات لا تطاق بالفعل. وهذا الاتجاه ليس جديدًا، لكن الوضع أصبح أكثر خطورة مع استمرار المختبرات المتطورة في تحدي افتراضات التوسع. يقال إن OpenAI تنفق أكثر من 3 مليارات دولار على التدريب هذا العام. تتوقع أنثروبيك أنه بحلول عام 2025، سنبدأ في تدريب 10 مليارات دولار، ونماذج بقيمة 100 مليار دولار ليست بعيدة جدًا.
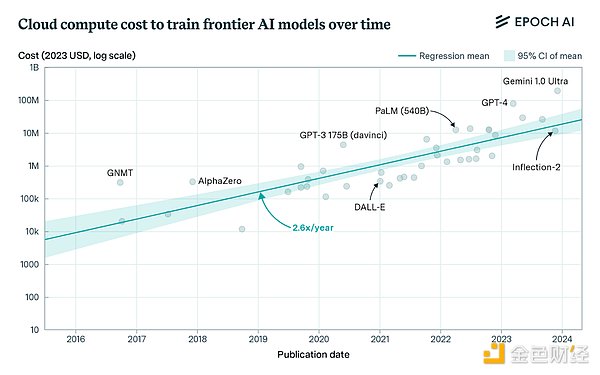
يؤدي هذا الاتجاه إلى تركز الصناعة حيث لا يستطيع سوى عدد قليل من الشركات المشاركة. وهذا يثير سؤالاً سياسيًا أساسيًا للمستقبل – هل يمكننا قبول موقف حيث يتم التحكم في جميع أنظمة الذكاء الاصطناعي الرائدة من قبل شركة واحدة أو اثنتين؟ وهذا يحد أيضًا من معدل التقدم، وهو ما يتضح في مجتمع البحث، حيث لا تستطيع المختبرات الصغيرة تحمل تكاليف موارد الحوسبة اللازمة لتوسيع نطاق التجارب. لقد ذكر قادة الصناعة هذا الأمر عدة مرات:
جو سبيساك من شركة Meta: لكي تفهم حقًا قدرات بنية [النموذج]، عليك القيام بذلك على نطاق واسع الاستكشاف، أنا أعتقد أن هذا هو ما هو مفقود في النظام البيئي الحالي. إذا نظرت إلى الأوساط الأكاديمية - هناك الكثير من المواهب الرائعة في الأوساط الأكاديمية، لكنهم يفتقرون إلى الوصول إلى موارد الحوسبة، وهذا يصبح مشكلة لأن لديهم هذه الأفكار العظيمة ولكن ليس لديهم الأدوات اللازمة لتنفيذها فعليًا على المستوى المطلوب. طريق.
ماكس ريابينين، معًا: الحاجة إلى أجهزة باهظة الثمن تضع الكثير من الضغط على مجتمع البحث. معظم الباحثين غير قادرين على المشاركة في تطوير الشبكات العصبية على نطاق واسع لأنه سيكون باهظ التكلفة بالنسبة لهم لإجراء التجارب اللازمة. إذا واصلنا زيادة حجم نماذجنا عن طريق توسيع نطاقها، فسنكون قادرين في النهاية على المنافسة
فرانسوا شوليه من Google: نحن نعلم أن النماذج اللغوية الكبيرة ( LLMs) لم تحقق بعد الذكاء الاصطناعي العام (AGI). وفي الوقت نفسه، توقف التقدم نحو الذكاء الاصطناعي العام. إن القيود التي نواجهها مع النماذج اللغوية الكبيرة هي بالضبط نفس القيود التي واجهناها قبل خمس سنوات. نحن بحاجة إلى أفكار جديدة واختراقات. أعتقد أن الاختراق التالي من المرجح أن يأتي من فرق خارجية بينما تكون جميع المختبرات الكبيرة مشغولة بتدريب نماذج لغوية كبيرة أكبر. يشكك البعض في هذه المخاوف، بحجة أن تحسينات الأجهزة والنفقات الرأسمالية للحوسبة السحابية ستحل المشكلة. لكن هذا يبدو غير واقعي. لسبب واحد، بحلول نهاية هذا العقد، سوف تحتوي الأجيال الجديدة من شرائح Nvidia على عدد أكبر بكثير من رقائق FLOPs، ربما 10 أضعاف عدد شرائح H100 الحالية. سيؤدي هذا إلى خفض السعر لكل FLOP بنسبة 80-90%. وبالمثل، من المتوقع أن يزيد إجمالي عرض FLOP بنحو 20 ضعفًا بحلول نهاية العقد، إلى جانب التحسينات في الشبكة والبنية التحتية ذات الصلة. كل هذا سيزيد من كفاءة التدريب لكل دولار.
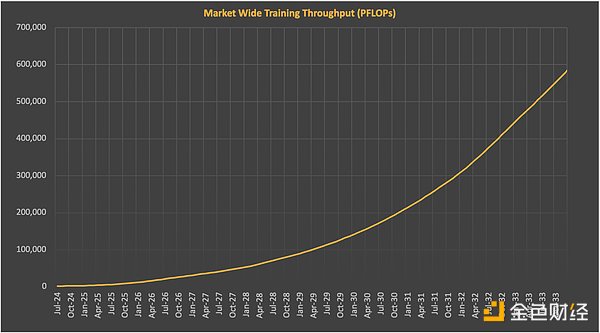
المصدر: نموذج SemiAnalogy AI Cloud TCO
في نفس الوقت، إجمالي الطلب على FLOP سوف يرتفع أيضًا بشكل ملحوظ، حيث يتطلع المختبر إلى التوسع بشكل أكبر. إذا استمرت اتجاهات العشر سنوات في حساب التدريب، فمن المتوقع أن تصل عمليات FLOP للتدريب المتطور إلى 2e29 تقريبًا بحلول عام 2030. سيتطلب التدريب على هذا النطاق ما يقرب من 20 مليون وحدة معالجة رسومات مكافئة لـ H100، بناءً على أوقات تشغيل التدريب الحالية واستخدامها. على افتراض أنه لا يزال هناك العديد من المعامل المتطورة في هذه المنطقة، فإن العدد الإجمالي لـ FLOPS المطلوبة سيكون عدة أضعاف هذا العدد، حيث سيتم تقسيم العرض الإجمالي فيما بينها. تتوقع EpochAI أننا سنحتاج إلى حوالي 100 مليون وحدة معالجة رسوميات مكافئة لـ H100 بحلول ذلك الوقت، أي حوالي 50x 2024 شحنة. قدمت شركة SemiAnalys تنبؤات مماثلة، معتبرة أن الطلب على التدريب المتطور وعرض وحدة معالجة الرسومات سوف ينموان تقريبًا خلال هذه الفترة.
قد تصبح ظروف القدرة أكثر إرهاقًا لعدة أسباب. على سبيل المثال، هذا هو الحال غالبًا إذا أدت اختناقات التصنيع إلى تأخير المهل الزمنية المقدرة للشحن. أو إذا فشلنا في إنتاج طاقة كافية لتشغيل مراكز البيانات. أو إذا واجهنا مشكلة في توصيل مصادر الطاقة هذه بالشبكة. أو إذا كان التدقيق المتزايد في الإنفاق الرأسمالي يؤدي في نهاية المطاف إلى تقليص حجم الصناعة، من بين عوامل أخرى. وفي أفضل الأحوال، لا تسمح أساليبنا الحالية إلا لعدد قليل من الشركات بمواصلة دفع الأبحاث إلى الأمام، وقد لا يكون ذلك كافيا.
من الواضح أننا بحاجة إلى نهج جديد. بدلاً من التوسع المستمر في مراكز البيانات والنفقات الرأسمالية واستهلاك الطاقة بحثًا عن التقدم التالي، يستخدم هذا النهج بكفاءة البنية التحتية الحالية لدينا مع المرونة في التوسع مع تقلب الطلب. وهذا سيسمح بمزيد من الإمكانيات التجريبية في مجال البحث، حيث لن تحتاج عمليات التدريب بعد الآن إلى ضمان عائد الاستثمار لميزانيات الحوسبة التي تبلغ مليارات الدولارات. وبمجرد التحرر من هذا القيد، يمكننا أن نتجاوز نموذج نموذج اللغة الكبير الحالي (LLM)، كما يعتقد الكثيرون أنه ضروري لتحقيق الذكاء العام الاصطناعي (AGI). لفهم الشكل الذي قد يبدو عليه هذا البديل، يمكننا أن نستمد الإلهام من ممارسات الحوسبة الموزعة السابقة.
لقد شاع SETI@home هذا المفهوم في عام 1999، مما سمح ملايين المشاركين لتحليل إشارات الراديو في البحث عن ذكاء خارج كوكب الأرض. يقوم SETI بجمع البيانات الكهرومغناطيسية من تلسكوب أريسيبو، وتقسيمها إلى دفعات، وإرسالها إلى المستخدمين عبر الإنترنت. يقوم المستخدمون بتحليل البيانات في أنشطتهم اليومية وإرسال النتائج مرة أخرى. ليس هناك حاجة إلى أي اتصال بين المستخدمين، ويمكن مراجعة الدفعات بشكل مستقل، مما يسمح بدرجة عالية من المعالجة المتوازية. في ذروته، كان لدى SETI@home أكثر من 5 ملايين مشارك وقوة معالجة أكبر من أكبر أجهزة الكمبيوتر العملاقة في ذلك الوقت. تم إغلاقه في نهاية المطاف في مارس 2020، لكن نجاحه ألهم حركة الحوسبة التطوعية التي تلت ذلك.
واصلت شركة Folding@home هذه الفكرة في عام 2000، باستخدام حوسبة الحافة لمحاكاة طي البروتين في أمراض مثل الزهايمر والسرطان ومرض باركنسون. يقضي المتطوعون أوقات فراغهم على أجهزة الكمبيوتر الخاصة بهم في إجراء عمليات محاكاة للبروتين، مما يساعد الباحثين على دراسة كيفية اختلال البروتينات وتسببها في الإصابة بالأمراض. في مراحل مختلفة من تاريخها، تجاوزت قوتها الحاسوبية قدرة أكبر أجهزة الكمبيوتر العملاقة في ذلك الوقت، بما في ذلك في أواخر العقد الأول من القرن الحادي والعشرين وأثناء فيروس كورونا، عندما أصبح أول مشروع حوسبة موزع يتجاوز إكسافلوبس واحد. منذ بدايتها، نشر باحثو Folding أكثر من 200 ورقة بحثية تمت مراجعتها من قبل النظراء، كل منها يعتمد على القوة الحاسوبية للمتطوعين.
قامت البنية التحتية المفتوحة لحوسبة الشبكة في بيركلي (BOINC) بنشر هذه الفكرة في عام 2002، حيث وفرت منصة حوسبة جماعية لمجموعة متنوعة من المشاريع البحثية. وهو يدعم العديد من المشاريع مثل SETI@home وFolding@home، بالإضافة إلى مشاريع جديدة في مجالات مثل الفيزياء الفلكية والبيولوجيا الجزيئية والرياضيات والتشفير. بحلول عام 2024، تدرج BOINC 30 مشروعًا مستمرًا، وما يقرب من 1000 ورقة علمية منشورة، تم إنتاجها باستخدام شبكتها الحاسوبية.
خارج مجال البحث العلمي، يتم استخدام الحوسبة التطوعية لتدريب محركات الألعاب مثل Go (LeelaZero، KataGo) والشطرنج (Stockfish، LeelaChessZero). تم تدريب LeelaZero في الفترة من 2017 إلى 2021 من خلال الحوسبة التطوعية، مما سمح لها بلعب أكثر من 10 ملايين لعبة ضد نفسها، مما أدى إلى إنشاء أحد أقوى محركات Go المتوفرة اليوم. وبالمثل، تم تدريب Stockfish بشكل مستمر على شبكة تطوعية منذ عام 2013، مما يجعلها واحدة من أكثر محركات الشطرنج شهرة وقوة.
ولكن هل يمكننا تطبيق هذا النموذج على الدراسة المتعمقة؟ هل يمكننا ربط الأجهزة الطرفية حول العالم لإنشاء مجموعة تدريب عامة منخفضة التكلفة؟ تتحسن الأجهزة الاستهلاكية - بدءًا من أجهزة كمبيوتر Apple المحمولة وحتى بطاقات رسومات الألعاب Nvidia - في التعلم العميق. وفي كثير من الحالات، يتجاوز أداء هذه الأجهزة أداء بطاقات الرسومات الخاصة بمراكز البيانات لكل دولار.
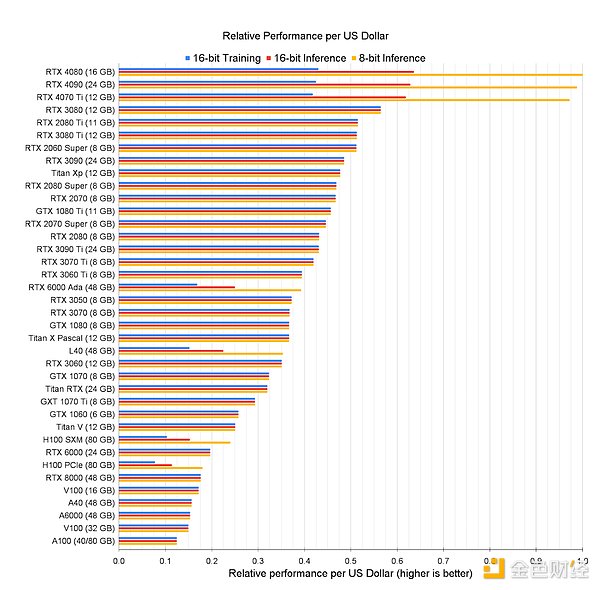
ومع ذلك، للاستفادة الفعالة من هذه الموارد في بيئة موزعة، نحتاج إلى التغلب على التحديات المختلفة.
أولاً، تفترض تقنيات التدريب الموزعة الحالية وجود اتصال متكرر بين العقد.
لقد تطورت النماذج الحديثة الحالية بشكل كبير لدرجة أنه يجب تقسيم التدريب عبر الآلاف من وحدات معالجة الرسومات. ويتم تحقيق ذلك من خلال مجموعة متنوعة من تقنيات الموازاة، وعادةً ما يتم تقسيم النموذج أو مجموعة البيانات أو كليهما في نفس الوقت عبر وحدات معالجة الرسومات المتاحة. يتطلب هذا عادةً شبكة ذات نطاق ترددي عالٍ وزمن وصول منخفض، وإلا ستبقى العقد في وضع الخمول في انتظار وصول البيانات.
على سبيل المثال، يقوم توازي البيانات الموزعة (DDP) بتوزيع مجموعة البيانات على وحدات معالجة الرسومات المختلفة، وتقوم كل وحدة معالجة رسومات بتدريب نموذج كامل على جزء البيانات المحدد الخاص بها، ثم مشاركتها تحديثات التدرج لإنشاء أوزان نموذجية جديدة في كل خطوة. يتطلب ذلك حملًا محدودًا نسبيًا للاتصالات، حيث تتشارك العقد فقط في تحديثات التدرج بعد كل انتشار خلفي، ويمكن أن تتداخل عمليات الاتصال الجماعية جزئيًا مع الحساب. ومع ذلك، فإن هذا الأسلوب يعمل فقط مع النماذج الأصغر حجمًا لأنه يتطلب من كل وحدة معالجة رسومات (GPU) تخزين أوزان النموذج بالكامل وعمليات التنشيط وحالة المُحسِّن في الذاكرة. على سبيل المثال، يتطلب GPT-4 أكثر من 10 تيرابايت من الذاكرة عند التدريب، في حين أن جهاز H100 الواحد يحتوي على 80 جيجابايت فقط.
لمعالجة هذه المشكلة، نستخدم أيضًا تقنيات متنوعة لتقسيم النموذج للتوزيع عبر وحدات معالجة الرسومات. على سبيل المثال، يقوم توازي الموتر بتقسيم الأوزان الفردية داخل طبقة واحدة، مما يسمح لكل وحدة معالجة رسومات بتنفيذ العمليات اللازمة وتمرير الإخراج إلى وحدات معالجة الرسومات الأخرى. وهذا يقلل من متطلبات الذاكرة لكل وحدة معالجة رسومات، ولكنه يتطلب اتصالاً مستمرًا بينها، وبالتالي يتطلب اتصالاً بنطاق ترددي عالٍ وزمن وصول منخفض لتحقيق الكفاءة.
يعمل التوازي على توزيع طبقات النموذج على وحدات معالجة الرسومات المختلفة، حيث تؤدي كل وحدة معالجة رسومات عملها ومشاركة التحديثات مع وحدة معالجة الرسومات التالية في المسار. على الرغم من أن هذا يتطلب اتصالًا أقل من توازي الموتر، إلا أن "الفقاعات" (على سبيل المثال، أوقات الخمول) قد تحدث حيث تنتظر وحدة معالجة الرسومات في الجزء الخلفي من خط الأنابيب معلومات من وحدة معالجة الرسومات في المقدمة لبدء عملها.
ولحل هذه التحديات، تم تطوير تقنيات مختلفة. على سبيل المثال، ZeRO (Zero Redundancy Optimizer) هي تقنية لتحسين الذاكرة تعمل على تقليل استخدام الذاكرة عن طريق زيادة حمل الاتصالات، مما يسمح بتدريب النماذج الأكبر حجمًا على أجهزة معينة. تعمل تقنية ZeRO على تقليل متطلبات الذاكرة عن طريق تقسيم معلمات النموذج والتدرجات وحالة المُحسّن بين وحدات معالجة الرسومات، ولكنها تعتمد على اتصالات واسعة النطاق حتى يتمكن الجهاز من الحصول على البيانات المقسمة. إنه النهج الأساسي للتقنيات الشائعة مثل Fully Sharded Data Parallel (FSDP) وDeepSpeed.
غالبًا ما يتم دمج هذه التقنيات في تدريب النماذج الكبيرة لتحقيق أقصى قدر من الاستفادة من الموارد، وهو ما يسمى بالتوازي ثلاثي الأبعاد. في هذا التكوين، غالبًا ما يتم استخدام توازي الموتر لتوزيع الأوزان عبر وحدات معالجة الرسومات داخل خادم واحد بسبب الاتصال المكثف المطلوب بين كل طبقة مقسمة. يتم بعد ذلك استخدام موازاة خطوط الأنابيب لتوزيع الطبقات بين خوادم مختلفة (ولكن داخل نفس الجزيرة في مركز البيانات) لأنها تتطلب اتصالاً أقل. بعد ذلك، يتم استخدام توازي البيانات أو توازي البيانات المجزأة بالكامل (FSDP) لتقسيم مجموعة البيانات عبر جزر الخادم المختلفة، حيث يمكنها استيعاب مجموعات بيانات أطول من خلال مشاركة التحديثات و/أو ضغط التدرجات اللونية بشكل غير متزامن. يستخدم Meta هذا النهج المدمج لتدريب Llama 3.1، كما هو موضح في الرسم البياني أدناه.
تطرح هذه الأساليب تحديات أساسية للتدريب اللامركزي للشبكات التي تعتمد على الوصول عبر معدات اتصالات الإنترنت (الأبطأ والأكثر تقلبًا) المخصصة للمستهلكين. في هذه البيئة، يمكن أن تفوق تكاليف الاتصالات بسرعة فوائد الحوسبة الطرفية لأن الأجهزة غالبًا ما تكون في وضع الخمول، في انتظار وصول البيانات. وكمثال بسيط، يتطلب التدريب الموازي للبيانات الموزعة لنموذج نصف الدقة مع مليار معلمة من كل وحدة معالجة رسومات مشاركة 2 جيجابايت من البيانات في كل خطوة من خطوات التحسين. إذا أخذنا عرض النطاق الترددي النموذجي للإنترنت (على سبيل المثال، 1 جيجابت في الثانية) كمثال، وبافتراض أن الحساب والاتصالات لا يتداخلان، فإن إرسال التحديثات المتدرجة يستغرق 16 ثانية على الأقل، مما يؤدي إلى خمول كبير. تقنيات مثل التوازي الموتر (التي تتطلب مزيدًا من التواصل) سيكون أداؤها أسوأ بالطبع.
ثانيًا، تفتقر تقنية التدريب الحالية إلى القدرة على تحمل الأخطاء. مثل أي نظام موزع، تصبح مجموعات التدريب أكثر عرضة للفشل مع زيادة حجمها. ومع ذلك، تتفاقم هذه المشكلة في التدريب لأن التكنولوجيا الحالية لدينا متزامنة في المقام الأول، مما يعني أن وحدات معالجة الرسومات يجب أن تعمل معًا لإكمال تدريب النموذج. يمكن أن يؤدي فشل وحدة معالجة رسوميات واحدة من بين آلاف وحدات معالجة الرسومات إلى إيقاف عملية التدريب بأكملها، مما يجبر وحدات معالجة الرسومات الأخرى على بدء التدريب من الصفر. في بعض الحالات، لا تتعطل وحدة معالجة الرسومات تمامًا، ولكنها بدلاً من ذلك تصبح بطيئة لأسباب مختلفة، مما يؤدي إلى إبطاء آلاف وحدات معالجة الرسومات الأخرى في المجموعة. ونظراً لحجم التجمعات اليوم، فإن هذا قد يعني تكاليف إضافية تقدر بعشرات إلى مئات الملايين من الدولارات.
تناول ميتا هذه المشكلات بالتفصيل أثناء تدريبهم على اللاما، حيث واجهوا أكثر من 400 مقاطعة غير متوقعة، بمتوسط حوالي 8 انقطاعات يوميًا. تُعزى هذه الانقطاعات بشكل أساسي إلى مشكلات في الأجهزة، مثل وحدة معالجة الرسومات أو فشل الأجهزة المضيفة. وينتج عن ذلك استخدام وحدة معالجة الرسومات بنسبة 38-43% فقط. أداء OpenAI أسوأ أثناء التدريب على GPT-4، بنسبة 32-36% فقط، وذلك أيضًا بسبب الأخطاء المتكررة أثناء التدريب.
بعبارة أخرى، تجري المختبرات المتطورة الأبحاث في بيئات محسنة بالكامل تتضمن أجهزة وشبكات وأنظمة طاقة وتبريد متجانسة ومتطورة عند التدريب، لا يزال من الصعب تحقيق الاستفادة بنسبة 40٪. ويرجع ذلك في المقام الأول إلى فشل الأجهزة ومشكلات الشبكة، والتي تتفاقم في بيئات التدريب المتطورة لأن الأجهزة بها اختلالات في قوة المعالجة وعرض النطاق الترددي وزمن الوصول والموثوقية. ناهيك عن أن الشبكات اللامركزية معرضة للجهات الفاعلة الخبيثة التي قد تحاول تقويض المشروع ككل أو الغش في أعباء عمل محددة لعدة أسباب. حتى SETI@home، وهي شبكة تطوعية بحتة، تعرضت للغش من قبل العديد من المشاركين.
ثالثًا، يتطلب التدريب على النماذج المتطورة قوة حاسوبية واسعة النطاق. في حين أن مشاريع مثل SETI وFolding قد وصلت إلى نطاق مثير للإعجاب، إلا أنها تتضاءل بالمقارنة مع قوة الحوسبة المطلوبة للتدريب المتطور اليوم. تم تدريب GPT-4 على مجموعة مكونة من 20000 A100 وحقق إنتاجية قصوى تبلغ 6.28 ExaFLOPS بنصف الدقة. وهذا يمثل قوة حاسوبية أكبر بثلاثة أضعاف من قوة Folding@home في ذروتها. تم تدريب Llama 405b باستخدام 16000 H100 وحقق إنتاجية قصوى تبلغ 15.8 ExaFLOPS، أي 7 أضعاف الذروة القابلة للطي. سوف تتسع هذه الفجوة بشكل أكبر حيث تخطط العديد من المعامل لبناء مجموعات تضم أكثر من 100.000 وحدة H100، تتمتع كل منها بقدرة حوسبة مذهلة تصل إلى 99 ExaFLOPS.
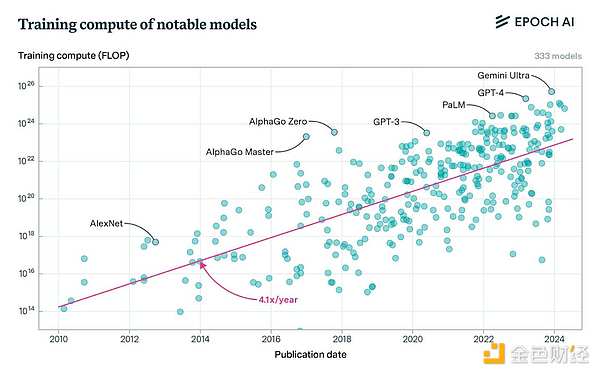
هذا أمر منطقي نظرًا لأن مشروع @home يعتمد على المتطوعين. يتبرع المساهمون بدورات الذاكرة والمعالج الخاصة بهم ويتحملون التكاليف المرتبطة بها. وهذا يحد بشكل طبيعي من حجمها بالنسبة للمشاريع التجارية.
على الرغم من أن هذه المشكلات ابتليت تاريخيًا بالعمل التدريبي اللامركزي، إلا أنها لم تعد موجودة يبدو لا يمكن التغلب عليه. ظهرت تقنيات تدريب جديدة تقلل الحاجة إلى الاتصال بين العقد، مما يسمح بالتدريب الفعال على الأجهزة المتصلة بالإنترنت. تنشأ العديد من هذه التقنيات من مختبرات كبيرة ترغب في إضافة نطاق أوسع إلى التدريب النموذجي، وبالتالي تتطلب تكنولوجيا اتصال فعالة عبر مراكز البيانات. نحن نشهد أيضًا تقدمًا في أساليب التدريب المتسامحة مع الأخطاء وأنظمة حوافز التشفير التي يمكنها دعم التدريب على نطاق واسع في البيئات الطرفية.
DiLoCo هو أحد الأبحاث الحديثة التي أجرتها Google، مما يقلل من حمل الاتصالات عن طريق إجراء التحسينات المحلية قبل تمرير حالة النموذج المحدثة بين الأجهزة. أظهر نهجهم (المعتمد على أبحاث التعلم الموحد السابقة) نتائج مماثلة للتدريب المتزامن التقليدي مع تقليل الاتصال بين العقد بعامل 500. وقد تم تكرار هذا النهج منذ ذلك الحين من قبل باحثين آخرين وتوسيع نطاقه لتدريب نماذج أكبر (أكثر من مليار معلمة). ويمتد أيضًا إلى التدريب غير المتزامن، مما يعني أن العقد يمكنها مشاركة تحديثات التدرج في أوقات مختلفة بدلاً من مشاركتها جميعًا مرة واحدة. ويتناسب هذا بشكل أفضل مع أجهزة الحافة ذات قدرات المعالجة وسرعات الشبكة المختلفة.
تهدف الطرق الموازية للبيانات الأخرى، مثل lo-fi وDisTrO، إلى تقليل تكاليف الاتصال بشكل أكبر. تقترح Lo-fi أسلوب ضبط دقيق محليًا بالكامل، مما يعني أن العقد يتم تدريبها بشكل مستقل ويتم تمرير الأوزان فقط في النهاية. يحقق هذا النهج أداءً مشابهًا للخطوط الأساسية مع التخلص تمامًا من عبء الاتصالات عند ضبط نماذج اللغة بما يزيد عن مليار معلمة. في تقرير أولي، تدعي DisTrO أنها تستخدم مُحسِّنًا موزعًا جديدًا تعتقد أنه يمكن أن يقلل متطلبات الاتصال بمقدار أربعة إلى خمسة أوامر من حيث الحجم، على الرغم من أن هذا النهج لم يتم تأكيده بعد.
كما ظهرت أساليب نموذجية جديدة للتوازي، مما يجعل من الممكن تحقيق نطاق أكبر. يقوم DiPaCo (أيضًا من Google) بتقسيم النموذج إلى وحدات متعددة، تحتوي كل منها على وحدات خبراء مختلفة لتسهيل التدريب على مهام محددة. يتم بعد ذلك تقسيم بيانات التدريب بواسطة "مسارات"، وهي عبارة عن تسلسلات متخصصة تتوافق مع كل عينة بيانات. بالنظر إلى القطعة، يمكن لكل عامل تدريب مسار معين بشكل مستقل تقريبًا، باستثناء الاتصال المطلوب لمشاركة الوحدات، والذي يتم التعامل معه بواسطة DiLoCo. تعمل هذه البنية على تقليل وقت التدريب لنموذج يحتوي على مليار معلمة بأكثر من النصف.
يقترح توازي SWARM والتدريب اللامركزي للنماذج الأساسية في البيئات غير المتجانسة (DTFMHE) أيضًا طرقًا لتوازي النماذج لتحقيق التنفيذ في بيئات غير متجانسة لتدريب النماذج الكبيرة. وجدت SWARM أنه مع زيادة حجم النموذج، تنخفض قيود الاتصال المتوازي لخط الأنابيب، مما يجعل من الممكن تدريب نماذج أكبر بكفاءة عند عرض نطاق ترددي أقل للشبكة وزمن وصول أعلى. لتطبيق هذا المفهوم في بيئة غير متجانسة، يستخدمون "اتصالات الأنابيب" المؤقتة بين العقد التي يمكن تحديثها في الوقت الفعلي مع كل تكرار. يسمح هذا للعقدة بإرسال مخرجاتها إلى أي نظير لمرحلة خط الأنابيب التالية. وهذا يعني أنه إذا كان أحد الأقران أسرع من الآخرين، أو إذا انقطع اتصال أي مشارك، فيمكن إعادة توجيه المخرجات ديناميكيًا لضمان استمرار التدريب طالما كان هناك مشارك نشط واحد على الأقل في كل مرحلة. لقد استخدموا هذا النهج لتدريب نموذج يحتوي على أكثر من مليار معلمة على وحدات معالجة الرسومات غير المتجانسة منخفضة التكلفة ذات التوصيلات البينية البطيئة (كما هو موضح في الشكل أدناه).
تقترح DTFMHE أيضًا خوارزمية جدولة جديدة، إلى جانب توازي خطوط الأنابيب وتوازي البيانات، لتدريب نماذج كبيرة على الأجهزة عبر 3 قارات. على الرغم من أن سرعات شبكتهم أبطأ بمقدار 100 مرة من Deepspeed القياسي، إلا أن نهجهم أبطأ بمقدار 1.7 إلى 3.5 مرة فقط من استخدام Deepspeed القياسي في مركز البيانات. وكما هو الحال مع SWARM، يوضح DTFMHE أنه يمكن إخفاء تكاليف الاتصالات بشكل فعال مع زيادة حجم النموذج، حتى في الشبكات الموزعة جغرافيًا. وهذا يسمح لنا بالتغلب على الاتصالات الأضعف بين العقد من خلال تقنيات مختلفة، بما في ذلك زيادة حجم الطبقات المخفية وإضافة المزيد من الطبقات في كل مرحلة من مراحل خط الأنابيب.
العديد من الأساليب الموازية للبيانات المذكورة أعلاه يكون التسامح مع الخطأ افتراضيًا لأن كل عقدة تخزن النموذج بأكمله في الذاكرة. يعني هذا التكرار عادةً أن العقد لا تزال قادرة على العمل بشكل مستقل حتى في حالة فشل العقد الأخرى. يعد هذا أمرًا مهمًا للتدريب اللامركزي لأن العقد غالبًا ما تكون غير موثوقة وغير متجانسة وقد تتصرف بشكل ضار. ومع ذلك، كما ذكرنا من قبل، فإن الطرق الموازية للبيانات البحتة مناسبة فقط للنماذج الأصغر حجمًا، وبالتالي فإن حجم النموذج مقيد بسعة الذاكرة لأصغر عقدة في الشبكة.
من أجل حل المشكلات المذكورة أعلاه، اقترح بعض الأشخاص تقنيات متسامحة مع الأخطاء مناسبة للتدريب المتوازي النموذجي (أو المتوازي الهجين). يستجيب SWARM لحالات فشل عقدة النظير من خلال إعطاء الأولوية للأقران المستقرين ذوي زمن الوصول الأقل وإعادة توجيه المهام في مراحل خط الأنابيب في حالة الفشل. تتبع الأساليب الأخرى، مثل Oobleck، نهجًا مشابهًا عن طريق إنشاء "قوالب خطوط أنابيب" متعددة لتوفير التكرار في حالة فشل العقدة الجزئي. وعلى الرغم من اختباره في مركز بيانات، فإن نهج Oobleck يوفر ضمانات موثوقية قوية تنطبق بالتساوي على البيئات اللامركزية.
لقد رأينا أيضًا بعض بنيات النماذج الجديدة (مثل المزيج اللامركزي من الخبراء (DMoE)) لدعم اللامركزية في التدريب على تحمل الأخطاء في البيئات. على غرار النماذج المختلطة التقليدية للخبراء، يتكون DMoE من شبكات "خبراء" مستقلة متعددة موزعة عبر مجموعة من العقد العاملة. يستخدم DMoE جدول تجزئة موزع لتتبع التحديثات غير المتزامنة ودمجها بطريقة لا مركزية. هذه الآلية (المستخدمة أيضًا في SWARM) مقاومة جيدًا لفشل العقد، حيث يمكنها استبعاد بعض الخبراء من الحساب المتوسط إذا فشلت بعض العقد أو فشلت في الاستجابة في الوقت المناسب.
أخيرًا، مثل Bitcoin وEthereum التشفير -يمكن لنظام الحوافز المعتمد من قبل blockchain أن يساعد في تحقيق النطاق المطلوب. تعمل كلا الشبكتين على التعهيد الجماعي للحسابات من خلال دفع أصول أصلية للمساهمين تزداد قيمتها مع نمو التبني. يحفز هذا التصميم المساهمين الأوائل من خلال منحهم مكافآت سخية، والتي يمكن تقليلها تدريجيًا بمجرد وصول الشبكة إلى الحد الأدنى من الحجم القابل للتطبيق.
في الواقع، هناك العديد من المزالق في هذه الآلية والتي يجب تجنبها. ويتمثل المأزق الرئيسي في الإفراط في تحفيز العرض دون توليد الطلب المقابل. بالإضافة إلى ذلك، قد يثير هذا مشكلات تنظيمية إذا لم تكن الشبكة الأساسية لا مركزية بدرجة كافية. ومع ذلك، عندما يتم تصميم أنظمة الحوافز اللامركزية بشكل صحيح، فإنها يمكن أن تحقق نطاقًا كبيرًا على مدى فترة طويلة من الزمن.
على سبيل المثال، يبلغ استهلاك الكهرباء السنوي للبيتكوين حوالي 150 تيراواط ساعة (TWh)، وهو أعلى مرتين من استهلاك الطاقة لأكبر مجموعة تدريب للذكاء الاصطناعي تم تصورها حاليًا أوامر من الحجم (100000 H100s تعمل بكامل طاقتها لمدة عام واحد). كمرجع، تم تدريب GPT-4 من OpenAI على 20000 طائرة من طراز A100، وتم تدريب نموذج Llama 405B الرائد من Meta على 16000 طائرة من طراز H100. وبالمثل، في ذروته، بلغ استهلاك إيثريوم للكهرباء حوالي 70 تيراواط في الساعة، موزعة على ملايين وحدات معالجة الرسوميات. وحتى مع السماح بالنمو السريع لمراكز بيانات الذكاء الاصطناعي في السنوات المقبلة، فإن شبكات الحوسبة المحفزة مثل هذه سوف تتجاوز حجمها عدة مرات.
بالطبع، ليست كل الحسابات قابلة للاستبدال، والتدريب له متطلبات فريدة تتعلق بالتعدين والتي يجب أخذها في الاعتبار. ومع ذلك، تثبت هذه الشبكات النطاق الذي يمكن تحقيقه من خلال هذه الآليات.
من خلال ربط هذه الأجزاء معًا، يمكننا رؤية الطريق إلى الأمام بداية طريق جديد.
قريبًا، ستسمح لنا تقنيات التدريب الجديدة بالتوسع خارج حدود مركز البيانات، حيث لم تعد الأجهزة بحاجة إلى التواجد في موقع مشترك لتكون فعالة. سيستغرق هذا بعض الوقت لأن أساليب التدريب اللامركزية الحالية لدينا لا تزال على نطاق أصغر، معظمها في حدود مليار إلى 2 مليار معلمة، وهي أصغر بكثير من نماذج مثل GPT-4. هناك حاجة إلى مزيد من الإنجازات لزيادة حجم هذه الأساليب دون التضحية بالخصائص الأساسية مثل كفاءة الاتصال والتسامح مع الأخطاء. أو نحتاج إلى بنيات نموذجية جديدة تختلف عن النماذج المتجانسة الكبيرة الموجودة اليوم - ربما أصغر حجمًا وأكثر نمطية، وتعمل على الأجهزة الطرفية بدلاً من تشغيلها على السحابة
في أي وفي هذه الحالة، فمن المعقول أن نتوقع المزيد من التقدم في هذا الاتجاه. إن تكاليف أساليبنا الحالية غير مستدامة، وهو ما يوفر حوافز سوقية قوية للإبداع. نحن نشهد هذا الاتجاه بالفعل، حيث تقوم الشركات المصنعة مثل Apple ببناء أجهزة متطورة أكثر قوة لتشغيل المزيد من أعباء العمل محليًا بدلاً من الاعتماد على السحابة. نحن نشهد أيضًا دعمًا متزايدًا للحلول مفتوحة المصدر - حتى داخل شركات مثل Meta - لتعزيز المزيد من البحث والتطوير اللامركزي. ولن تتسارع هذه الاتجاهات إلا بمرور الوقت.
وفي الوقت نفسه، نحتاج أيضًا إلى بنية تحتية جديدة للشبكة لتوصيل الأجهزة الطرفية حتى نتمكن من استخدامها بهذه الطريقة. تتضمن هذه الأجهزة أجهزة الكمبيوتر المحمولة وأجهزة الكمبيوتر المكتبية المخصصة للألعاب، وربما حتى الهواتف المحمولة المزودة ببطاقات رسومات عالية الأداء وكميات كبيرة من الذاكرة. وهذا سيسمح لنا ببناء "مجموعة عالمية" من القدرات الحاسوبية منخفضة التكلفة والمستمرة في التشغيل والتي يمكنها معالجة مهام التدريب بالتوازي. إنها أيضًا مشكلة صعبة تتطلب التقدم في مجالات متعددة.
نحتاج إلى تقنيات جدولة أفضل للتدريب في بيئات غير متجانسة. لا توجد حاليًا طريقة لموازاة النموذج تلقائيًا من أجل التحسين، خاصة عندما يمكن فصل الأجهزة أو توصيلها في أي وقت. تعد هذه خطوة تالية حاسمة في تحسين التدريب مع الاحتفاظ بمزايا نطاق الشبكات القائمة على الحافة.
علينا أيضًا أن نتعامل مع التعقيدات العامة للشبكات اللامركزية. لتحقيق أقصى قدر من النطاق، يجب بناء الشبكات كبروتوكولات مفتوحة - مجموعة من المعايير والتعليمات التي تملي التفاعلات بين المشاركين، مثل TCP/IP إلى حد كبير ولكن لحوسبة التعلم الآلي. سيؤدي هذا إلى تمكين أي جهاز يلتزم بمواصفات محددة من الاتصال بالشبكة، بغض النظر عن المالك والموقع. كما يضمن أيضًا أن تظل الشبكة محايدة، مما يسمح للمستخدمين بتدريب النماذج التي يفضلونها.
بينما يؤدي هذا إلى زيادة الحجم إلى الحد الأقصى، فإنه يتطلب أيضًا آلية للتحقق من صحة جميع مهام التدريب دون الاعتماد على كيان واحد. وهذا أمر بالغ الأهمية لأن هناك حوافز متأصلة للغش - على سبيل المثال، الادعاء بأنك أكملت مهمة تدريبية للحصول على المال، ولكن لا تفعل ذلك في الواقع. وهذا يمثل تحديًا خاصًا نظرًا لأن الأجهزة المختلفة غالبًا ما تؤدي عمليات التعلم الآلي بشكل مختلف، مما يجعل من الصعب التحقق من صحتها باستخدام تقنيات النسخ القياسية. يتطلب حل هذه المشكلة بشكل صحيح بحثًا متعمقًا في التشفير والتخصصات الأخرى.
لحسن الحظ، ما زلنا نرى التقدم على كل هذه الجبهات. ولم تعد هذه التحديات تبدو مستعصية على الحل مقارنة بالسنوات الماضية. كما أنها شاحبة بالمقارنة مع الفرص. يلخص Google هذا الأمر بشكل أفضل في ورقة DiPaCo، مشيرًا إلى آلية ردود الفعل السلبية التي يمكن أن يكسرها التدريب اللامركزي:
التعلم الآلي للتدريب الموزع قد يسهل التقدم في النماذج البناء المبسط للبنية التحتية، مما يؤدي في النهاية إلى توافر موارد الحوسبة على نطاق أوسع. حاليًا، تم تصميم البنية التحتية حول الأساليب القياسية لتدريب النماذج المتجانسة الكبيرة، وتم تصميم نماذج التعلم الآلي للاستفادة من البنية التحتية الحالية وأساليب التدريب. يمكن أن تؤدي حلقة ردود الفعل هذه إلى إيقاع المجتمع في حد أدنى محلي مضلل، حيث تكون الموارد الحسابية مقيدة أكثر مما هو مطلوب بالفعل.
ولعل الأمر الأكثر إثارة هو الحماس المتزايد بين مجتمع البحث لحل هذه المشكلات. يقوم فريقنا في Gensyn ببناء البنية التحتية للشبكة الموضحة أعلاه. تطبق فرق مثل Hivemind وBigScience العديد من هذه التقنيات عمليًا. وتُظهِر مشاريع مثل Petals، وsahajBERT، وBloom قدرات هذه التقنيات، فضلاً عن الاهتمام المتزايد بالتعلم الآلي المجتمعي. ويعمل العديد من الآخرين أيضًا على دفع الأبحاث إلى الأمام، بهدف بناء نظام تدريب نموذجي أكثر انفتاحًا وتعاونًا. إذا كنت مهتمًا بهذا العمل، يرجى الاتصال بنا للمشاركة.
اختار جاي ETH بسبب العوائد المحلية التي توفرها شبكة Ethereum.
JinseFinanceفي الفترة من 15 إلى 16 أبريل، سيكون المنتدى الدولي Blockchain Life 2024 هو الحدث الرئيسي لهذا العام في دبي.
 Joy
Joyتُظهر تغريدة 91Porn الرسمية أنه سيتم إدراج AVAV قريبًا للتداول في منطقة Bitget Innovation Zone
 铭文老幺
铭文老幺لقد تجاوزت هبة رمز BONK المقدمة من هاتف Solana's Saga المحمول سعر بيع الهاتف بشكل مذهل، مما أدى إلى زيادة الطلب وتقييم السوق، وعرض التآزر المتقلب لتكنولوجيا التشفير.
 Alex
Alex Coinlive
Coinlive جاء الاستطلاع من إحدى الصحف المعارضة الرائدة في السلفادور ، مما أدى إلى تغريدة تهنئة ذاتية من رئيس Bitcoin.
 CryptoSlate
CryptoSlateأشركت Meta شركة البرمجيات الصينية Tencent لتوزيع نظارة Meta Quest VR الخاصة بها على الرغم من خسارة Meta Reality Labs 17 ٪ من الإيرادات في الربع الرابع من العام الماضي.
 Beincrypto
Beincrypto Nulltx
Nulltxعلى الرغم من الموافقة الساحقة على الاقتراح اعتبارًا من يوم الأربعاء ، اقترح العديد من مستخدمي Terra على وسائل التواصل الاجتماعي أن الشبكة تحرق رموز LUNA الخاصة بها.
 Cointelegraph
Cointelegraphيتم التقديم الرسمي لـ Cointelegraph France في قمة أسبوع Blockchain في باريس ، وهو حدث أوروبي رائد في مجال blockchain.
Cointelegraph