المصدر: قلب الآلة
لا يزال بإمكان النماذج اللغوية الكبيرة تحقيق اختراقات، وقد أثبت OpenAI قوته مرة أخرى.
في منتصف ليل 13 سبتمبر بتوقيت بكين، أصدرت OpenAI رسميًا سلسلة من نماذج الذكاء الاصطناعي الكبيرة الجديدة المصممة خصيصًا لحل المشكلات الصعبة. يعد هذا إنجازًا كبيرًا، حيث يمكن للنموذج الجديد تمكين التفكير المعقد، وهو نموذج عالمي لحل مشكلات أكثر صعوبة مما تمكنت النماذج العلمية والرمزية والرياضية السابقة من القيام به.

قال OpenAI أن ما تم إصداره حديثًا في ChatGPT وواجهة برمجة التطبيقات النموذجية الكبيرة اليوم هو النموذج الأول في السلسلة، ونسخة المعاينة فقط - معاينة o1. بالإضافة إلى o1، قدمت OpenAI أيضًا تقييمًا للتحديث التالي قيد التطوير حاليًا.
سجل نموذج o1 العديد من الأرقام القياسية التاريخية في ضربة واحدة.
بادئ ذي بدء، o1 هو نموذج الفراولة الكبير الذي قامت شركة OpenAI "بالترويج له بشكل كبير" من Ultraman Sam إلى العلماء. إنها تمتلك قدرات تفكير عالمية حقًا. لقد أظهر قوة فائقة في سلسلة من الاختبارات المعيارية الصعبة، وقد تم تحسينه بشكل كبير، مما يسمح للحد الأعلى للنماذج الكبيرة بالارتفاع مباشرة من المستوى "غير المرئي" إلى المستوى الممتاز ويمكنه الفوز بالميدالية الذهبية مباشرة حصل على ميدالية في أولمبياد الرياضيات دون تدريب خاص، ويمكنه أيضًا التفوق على الخبراء البشريين في جلسات الأسئلة والأجوبة العلمية على مستوى الدكتوراه.
قال ألترامان إنه على الرغم من أن أداء O1 لا يزال به عيوب، إلا أنك لا تزال بمثابة صدمة في المرة الأولى التي تستخدمها.
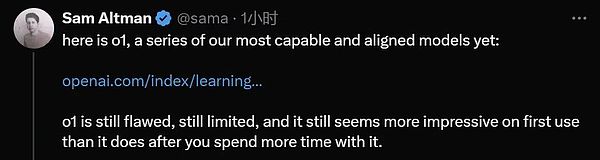
ثانيًا، يجلب o1 بُعدًا جديدًا لمنحنى توسيع نطاق النموذج الكبير مقابل الأداء. إنه يعيد إنتاج نجاح التعلم المعزز لـ AlphaGo في مجال النماذج الكبيرة - كلما زادت قوة الحوسبة التي يوفرها، زاد الذكاء الذي ينتجه، حتى يتجاوز المستويات البشرية.
وبعبارة أخرى، من منظور منهجي، أثبت النموذج الكبير o1 لأول مرة أن نموذج اللغة يمكن أن يؤدي التعلم المعزز الحقيقي.
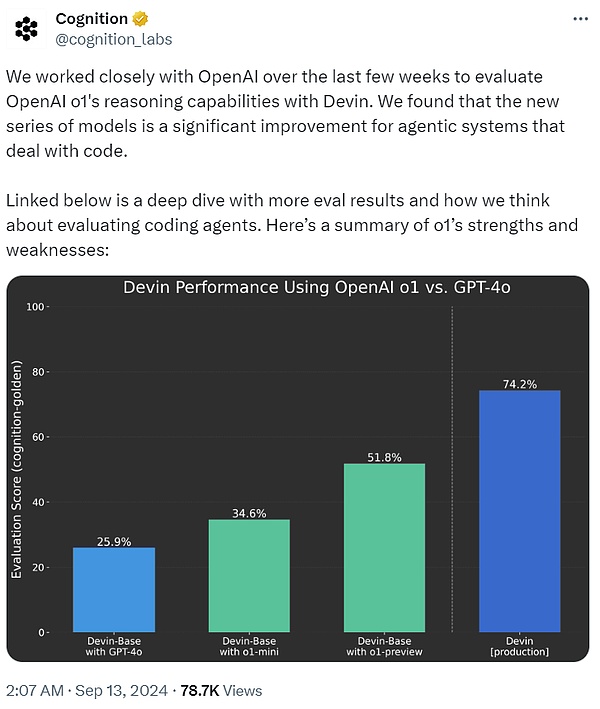
قالت شركة Cognition AI، التي طورت أول مهندس برمجيات للذكاء الاصطناعي Devin، إنه في لقد عملنا بشكل وثيق مع OpenAI في الأسابيع القليلة الماضية لاستخدام Devin لتقييم قدرات التفكير المنطقي لـ o1. لقد وجد أنه بالمقارنة مع GPT-4o، فإن سلسلة نماذج o1 تمثل تحسينًا كبيرًا لأنظمة الوكيل التي تعالج التعليمات البرمجية.
أخيرًا، بعد اتصال o1 بالإنترنت، يستطيع ChatGPT الآن الإجابة على الأسئلة قبل التفكير بعناية أولاً بدلاً من تشويش إجابتك على الفور. تمامًا مثل النظام 1 والنظام 2 للدماغ البشري، تطور ChatGPT من استخدام النظام 1 فقط (سريع، تلقائي، بديهي، معرض للخطأ) إلى استخدام تفكير النظام 2 (بطيء، متعمد، واعي، موثوق). وهذا يسمح لها بحل المشاكل التي لم يتم حلها في السابق.
انطلاقًا من تجربة مستخدم ChatGPT اليوم، تعد هذه خطوة صغيرة إلى الأمام. من خلال المطالبات البسيطة، قد لا يلاحظ المستخدمون فرقًا كبيرًا، ولكن إذا طرحوا بعض الأسئلة الصعبة في الرياضيات أو البرمجة، يبدأ الفرق في الظهور. والأهم من ذلك أن الطريق إلى الأمام قد بدأ بالفعل في الظهور.
بشكل عام، لقد صدم الفيلم الرائج الذي أسقطته OpenAI الليلة مجتمع الذكاء الاصطناعي بأكمله، حيث أعربوا جميعًا عن TQL، ولم يتمكنوا من النوم، وبدأوا الدراسة في وقت متأخر من الليل. بعد ذلك، دعونا نلقي نظرة على التفاصيل الفنية للنموذج الكبير OpenAI o1.
كيفية عمل OpenAI o1
في المدونة الفنية "تعلم التفكير مع LLMs"، قدمت OpenAI مقدمة فنية مفصلة لسلسلة o1 من نماذج اللغة .
OpenAI o1 هو نموذج لغة جديد تم تدريبه باستخدام التعلم المعزز لأداء مهام التفكير المعقدة. السمة هي أن o1 سوف يفكر قبل الإجابة - يمكنه إنشاء سلسلة تفكير داخلية طويلة قبل الرد على المستخدم.
أي أن النموذج يحتاج إلى قضاء المزيد من الوقت في التفكير في المشكلة كما يفعل البشر قبل الرد. ومن خلال التدريب، يتعلمون تحسين عمليات التفكير لديهم، وتجربة استراتيجيات مختلفة، والتعرف على أخطائهم.
في اختبارات OpenAI، كان أداء النماذج اللاحقة في السلسلة مشابهًا لطلاب الدكتوراه في المهام المعيارية الصعبة في الفيزياء والكيمياء وعلم الأحياء. كما تبين أن OpenAI تتفوق في الرياضيات والبرمجة.
في الاختبار التأهيلي لأولمبياد الرياضيات الدولي (IMO)، أجاب GPT-4o بشكل صحيح على 13% فقط من الأسئلة، بينما أجاب نموذج o1 على 83% من الأسئلة بشكل صحيح.
تم أيضًا تقييم قدرات النموذج في البرمجة في المسابقة، حيث حصل على 89% في مسابقة Codeforces.
يقول OpenAI إنه كنموذج مبكر، فإنه لا يحتوي حتى الآن على العديد من ميزات ChatGPT المفيدة، مثل تصفح الويب للحصول على معلومات وتحميل الملفات والصور.
ولكن بالنسبة لمهام الاستدلال المعقدة، يعد هذا تقدمًا كبيرًا ويمثل مستوى جديدًا من قدرات الذكاء الاصطناعي. في ضوء ذلك، تقوم OpenAI بإعادة ضبط العداد إلى 1 وتسمي سلسلة الطرازات OpenAI o1.
النقطة الأساسية هي أن خوارزمية التعلم المعزز واسعة النطاق من OpenAI تعلم النموذج كيفية استخدام سلسلة أفكاره للتفكير بكفاءة أثناء عملية التدريب باستخدام بيانات فعالة للغاية. وبعبارة أخرى، على غرار قانون القياس للتعلم المعزز.
وجدت OpenAI أن أداء o1 استمر في التحسن مع المزيد من التعلم المعزز (المحسوب في وقت التدريب) والمزيد من وقت التفكير (المحسوب في وقت الاختبار). والقيود المفروضة على توسيع نطاق هذا النهج تختلف تمامًا عن القيود المفروضة على التدريب المسبق للنماذج الكبيرة، والتي تواصل OpenAI البحث فيها.
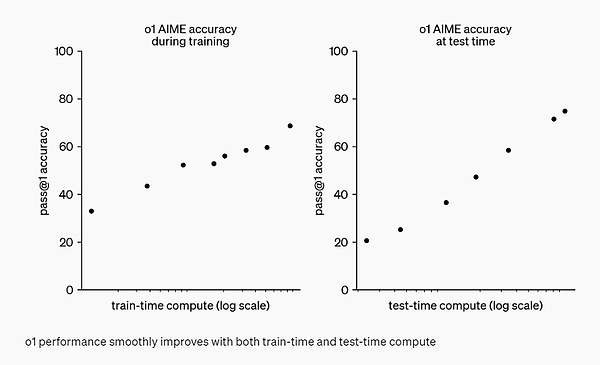
التقييم
لـ من خلال تسليط الضوء على تحسينات أداء الاستدلال عبر GPT-4o، قامت OpenAI باختبار نموذج o1 على مجموعة من الاختبارات البشرية المختلفة ومعايير التعلم الآلي. تظهر النتائج التجريبية أن أداء o1 أفضل بكثير من أداء GPT-4o في الغالبية العظمى من مهام الاستدلال.
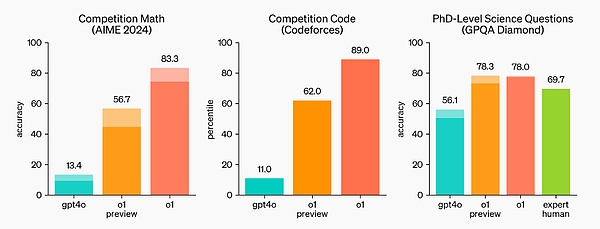
o1 يوفر تحسينات كبيرة على GPT-4o في معايير الاستدلال الصعبة.
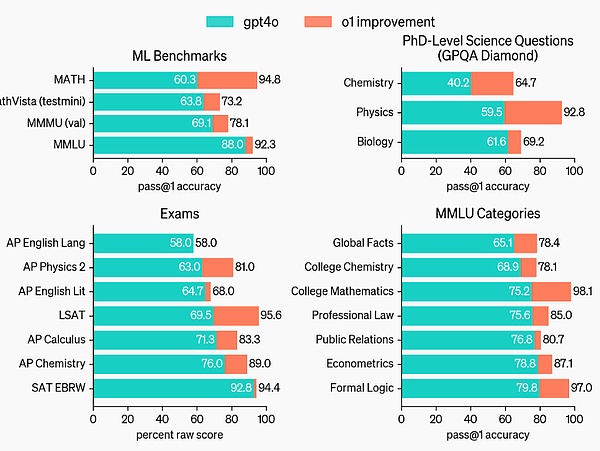
يتحسن o1 مقارنة بـ GPT-4o في مجموعة واسعة من المعايير، بما في ذلك الفئات الفرعية 54/57 MMLU، 7 منها معروضة للتوضيح.
يُقارن أداء O1 بأداء الخبراء البشريين في العديد من معايير الاستدلال المكثفة. تعمل النماذج المتطورة الحديثة بشكل جيد جدًا على MATH وGSM8K، بحيث لم تعد هذه المعايير فعالة في التمييز بين النماذج. لذلك قامت OpenAI بتقييم أداء الرياضيات على AIME، وهو اختبار مصمم لاختبار ألمع طلاب الرياضيات في المدارس الثانوية في الولايات المتحدة.
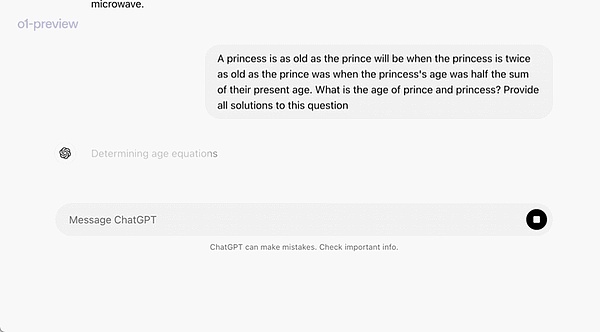
في عرض توضيحي رسمي، حلت o1-preview مشكلة تفكير صعبة للغاية: عندما يكون عمر الأميرة ضعف عمر الأمير، يكون عمر الأميرة مثل عمر الأمير، والأميرة نصف عمرها الحالي الأعمار مجتمعة. ما هو عمر الأمير والأميرة؟ تقديم كافة الحلول لهذه المشكلة.
في اختبار AIME لعام 2024، حل GPT-4o 12% فقط (1.8/15) من الأسئلة في المتوسط، بينما بلغ متوسط o1 74 مع عينة واحدة فقط لكل سؤال٪ (11.1/15) )، 83% (12.5/15) عند التوصل إلى اتفاق بين 64 عينة، و93% (13.9/15) عند إعادة ترتيب 1000 عينة باستخدام وظيفة التسجيل المستفادة. إن الحصول على درجة 13.9 سيضعك ضمن أفضل 500 شخص في البلاد وهو أعلى من الحد المسموح به في أولمبياد الرياضيات بالولايات المتحدة.
قامت OpenAI أيضًا بتقييم o1 على معيار GPQA Diamond، وهو معيار ذكاء صعب يختبر الخبرة في الكيمياء والفيزياء والبيولوجيا. لمقارنة النماذج بالبشر، قامت شركة OpenAI بتعيين خبراء حاصلين على درجة الدكتوراه للإجابة على الأسئلة المعيارية لـ GPQA Diamond.
تظهر النتائج التجريبية: يتفوق o1 على أداء الخبراء البشريين، ليصبح النموذج الأول الذي يفعل ذلك وفقًا لهذا المعيار.
لا تعني هذه النتائج أن o1 أكثر قدرة من حاملي الدكتوراه في جميع الجوانب - بل تعني فقط أن النموذج أفضل في حل بعض المشكلات التي يجب أن يكون حاملو الدكتوراه قادرين على حلها. من بين العديد من معايير تعلم الآلة الأخرى، يحقق o1 SOTA الجديد.
مع تمكين الإدراك البصري، سجل o1 78.2% على مقياس MMMU، ليصبح النموذج الأول الذي يتساوى مع الخبراء البشريين. يتفوق o1 أيضًا على GPT-4o في 54 فئة فرعية من أصل 57 MMLU.
سلاسل التفكير (CoT)
على غرار الطريقة التي يفكر بها البشر لفترة طويلة قبل الإجابة على سؤال صعب، يستخدم o1 سلاسل التفكير عند محاولة حلها مشكلة. من خلال التعلم المعزز، يتعلم o1 صقل سلسلة أفكاره وتحسين الاستراتيجيات التي يستخدمها. o1 تعلم كيفية التعرف على الأخطاء وتصحيحها ويمكنه تقسيم الخطوات الصعبة إلى خطوات أبسط. تعلمت o1 أيضًا تجربة أساليب مختلفة عندما لم ينجح النهج الحالي. تعمل هذه العملية على تحسين قدرات التفكير للنموذج بشكل كبير.
قدرة البرمجة
بعد التهيئة بناءً على o1 والتدريب الإضافي على مهارات البرمجة، نتج عن تدريب OpenAI نموذج برمجة قوي جدًا (o1- ioi). سجل النموذج 213 نقطة في مسابقة الأولمبياد الدولي للمعلوماتية (IOI) لعام 2024، ليحتل المرتبة الأولى بنسبة 49%. وشروط مشاركة النموذج في المسابقة هي نفس شروط المتسابقين من البشر في IOI لعام 2024: حيث يحتاج إلى حل 6 أسئلة خوارزمية صعبة خلال 10 ساعات، ويمكن لكل سؤال تقديم 50 إجابة فقط.
بالنسبة لكل سؤال، يقوم نموذج o1 المدرب خصيصًا بأخذ عينات من عدد من إجابات المرشحين ثم يرسل 50 منها بناءً على استراتيجية اختيار وقت الاختبار. تتضمن معايير الاختيار الأداء في حالات الاختبار العامة IOI، وحالات الاختبار التي تم إنشاؤها بواسطة النموذج، ووظيفة التسجيل المستفادة.
تظهر الأبحاث أن هذه الإستراتيجية ناجحة. لأنه إذا قمت بإرسال إجابة مباشرة بشكل عشوائي، فإن متوسط الدرجات هو 156 فقط. وهذا يعني أنه في ظل ظروف المنافسة هذه، تبلغ قيمة هذه الإستراتيجية 60 نقطة على الأقل.
وجدت OpenAI أنه يمكن تحسين أداء النموذج بشكل كبير إذا تم تخفيف قيود الإرسال. إذا تم السماح بتقديم 10000 إجابة لكل سؤال، حتى بدون استخدام استراتيجية اختيار وقت الاختبار الموضحة أعلاه، لكان النموذج قد سجل 362.14 نقطة، وهو ما يكفي للحصول على ميدالية ذهبية.
أخيرًا، قامت OpenAI بمحاكاة مسابقة برمجة تنافسية استضافتها Codeforces لإظهار مهارات البرمجة الخاصة بالنموذج. التقييم المعتمد قريب جدًا من قواعد المسابقة، مما يسمح بتقديم 10 أكواد. حصل GPT-4o على درجة 808 في Elo، مما يضعه ضمن أفضل 11% من المنافسين من البشر. يتفوق النموذج بشكل ملحوظ على GPT-4o وo1 - مع درجة Elo البالغة 1807، يتفوق على 93% من منافسيه.
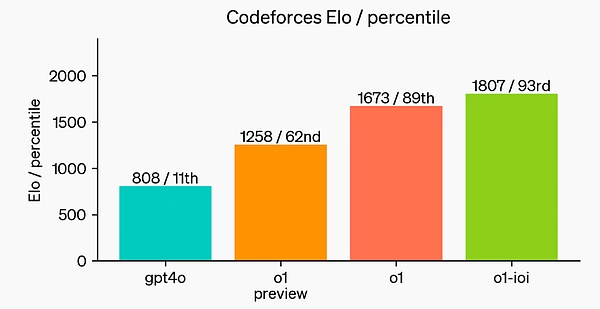
أدى المزيد من الضبط الدقيق في مسابقات البرمجة إلى زيادة قدرات o1 وتم تصنيفه ضمن أفضل 49% بموجب قواعد الأولمبياد الدولي للمعلوماتية (IOI) لعام 2024.
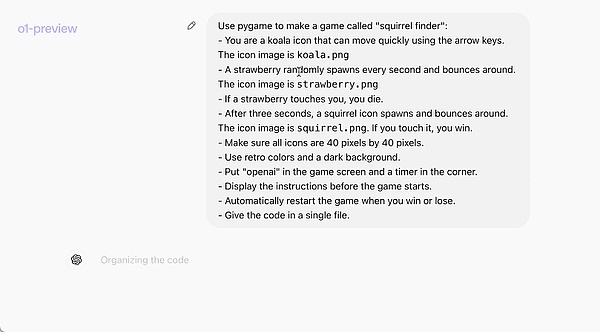
يوضح المثال الرسمي التالي بشكل حدسي القدرات البرمجية لـ o1-preview: كلمة سريعة تسمح لها بكتابة لعبة كاملة قابلة للتشغيل.
تقييم تفضيلات الإنسان
بالإضافة إلى الاختبارات والمعايير الأكاديمية، تقوم OpenAI بتقييم التفضيلات البشرية لمعاينة o1 وGPT-4o في المطالبات المفتوحة الصعبة في المزيد من المجالات.
في هذا التقييم، أجاب المدربون البشريون بشكل مجهول على المطالبات من o1-preview وGPT-4o وصوتوا للإجابة التي يفضلونها. في الفئات ذات القدرات المنطقية القوية مثل تحليل البيانات والبرمجة والرياضيات، تعد معاينة o1 أكثر شيوعًا من GPT-4o. ومع ذلك، فإن o1-preview ليس شائعًا في بعض مهام اللغة الطبيعية، مما يشير إلى أنه غير مناسب لجميع حالات الاستخدام.
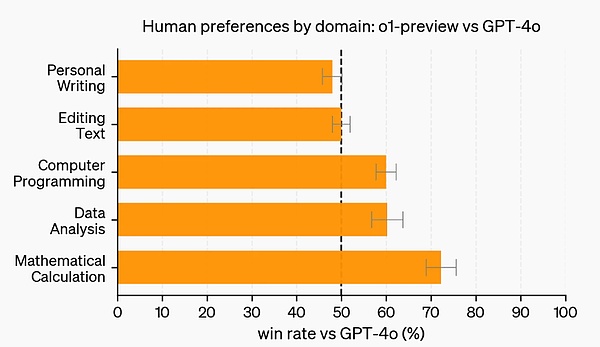
في المجالات التي تتطلب قدرات تفكير أقوى، يفضل الأشخاص معاينة o1.
الأمان
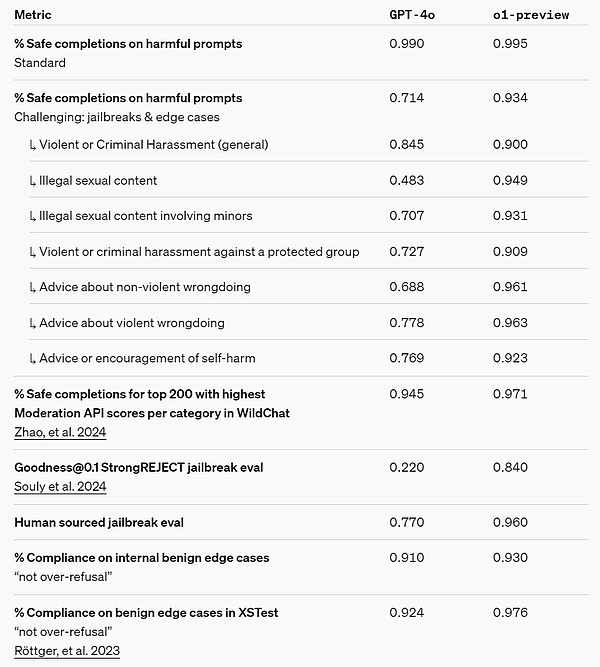
يوفر منطق سلسلة الأفكار (CoT) أفكارًا جديدة للأمان والمواءمة. وجدت OpenAI أن دمج الاستراتيجيات السلوكية النموذجية في سلسلة تفكير نماذج الاستدلال يمكن أن يعلم القيم والمبادئ الإنسانية بكفاءة وقوة. من خلال تدريس النماذج قواعد الأمان الخاصة بها وكيفية التفكير فيها في السياق، وجدت OpenAI دليلاً على أن قدرات التفكير المنطقي تفيد بشكل مباشر قوة النموذج: o1-معاينة تقييمات كسر الحماية الحرجة والمعايير الداخلية الأكثر صرامة المستخدمة لتقييم حدود رفض أمان النموذج، تم إجراء تحسينات كبيرة حقق.
تعتقد شركة OpenAI أن استخدام سلاسل التفكير يمكن أن يؤدي إلى تحسينات كبيرة على السلامة والمواءمة لأنه 1) يتيح طريقة واضحة لمراقبة التفكير النموذجي، و2) يعتبر الاستدلال النموذجي حول قواعد السلامة أكثر موثوقية بالنسبة للأشخاص خارج نطاق العمل. سيناريوهات التوزيع.
لاختبار التحسينات التي أدخلتها، أجرت OpenAI سلسلة من اختبارات الأمان واختبار الفريق الأحمر استنادًا إلى إطار الاستعداد الأمني الخاص بها قبل النشر. لقد وجد أن التفكير المتسلسل ساعد في تحسين القدرات خلال عملية التقييم. وتجدر الإشارة بشكل خاص إلى أن OpenAI لاحظت حالات مثيرة للاهتمام لاختراق المكافآت.
رابط إطار إعداد السلامة: https://openai.com/safety/
سلسلة التفكير الخفية
تعتقد OpenAI أن سلاسل التفكير المخفية توفر فرصًا فريدة لمراقبة النماذج. على افتراض أنها صادقة وواضحة، فإن سلاسل التفكير المخفية تجعل من الممكن "قراءة" عقل النموذج وفهم عملية تفكيره. على سبيل المثال، قد يرغب المرء في المستقبل في مراقبة سلاسل التفكير بحثًا عن علامات التلاعب بالمستخدمين.
ولكن للقيام بذلك، يجب أن يكون النموذج قادرًا على التعبير بحرية عن أفكاره في شكل غير متغير، وبالتالي لا يمكن تدريبه على سلاسل التفكير لأي امتثال للسياسة أو تدريب على تفضيلات المستخدم. لا يريد OpenAI أيضًا أن يرى المستخدمون سلاسل فكرية غير متناسقة بشكل مباشر.
لذلك، بعد تقييم عوامل متعددة مثل تجربة المستخدم والميزة التنافسية وخيارات متابعة مراقبة سلسلة التفكير، قررت OpenAI عدم عرض سلسلة التفكير الأصلية للمستخدمين. تعترف OpenAI بالجانب السلبي لهذا القرار وتسعى جاهدة للتعويض جزئيًا عن طريق تعليم النموذج لإعادة إنتاج أي أفكار مفيدة في سلسلة التفكير في إجاباته. في الوقت نفسه، بالنسبة لسلسلة نماذج o1، يعرض OpenAI ملخصًا لسلسلة التفكير التي أنشأها النموذج.
يمكن القول أن o1 قد أدى إلى تحسين كبير في أحدث أساليب تفكير الذكاء الاصطناعي. تخطط OpenAI لإصدار إصدارات محسنة من هذا النموذج في عملية تكرارية وتتوقع أن تعمل قدرات التفكير الجديدة هذه على تحسين القدرة على مواءمة النموذج مع القيم والمبادئ الإنسانية. تعتقد OpenAI أن شركة o1 وخلفائها ستفتح حالات استخدام جديدة للذكاء الاصطناعي في العلوم والبرمجة والرياضيات والمجالات ذات الصلة.
OpenAI o1-mini
o1 عبارة عن سلسلة من النماذج. هذه المرة أصدرت OpenAI أيضًا نسخة مصغرة من OpenAI o1-mini. قدمت الشركة تعريفات مختلفة للمعاينة والإصدار المصغر في مدونتها: "من أجل تزويد المطورين بحلول أكثر كفاءة، أصدرنا أيضًا OpenAI o1-mini، وهو إصدار أسرع وأرخص وجيد بشكل خاص في البرمجة. نموذج الاستدلال. " بشكل عام، تكلفة o1-mini أقل بنسبة 80% من تكلفة o1-preview.
نظرًا لأن النماذج اللغوية الكبيرة مثل o1 تم تدريبها مسبقًا على مجموعات البيانات النصية الكبيرة، وعلى الرغم من أنها تتمتع بمعرفة عالمية واسعة، إلا أنها يمكن أن تكون مكلفة وبطيئة للتطبيقات العملية.
في المقابل، o1-mini هو نموذج أصغر تم تحسينه لاستدلال العلوم والتكنولوجيا والهندسة والرياضيات (STEM) أثناء التدريب المسبق. بعد التدريب باستخدام نفس خط أنابيب التعلم المعزز حسابيًا (RL) مثل o1، يحقق o1-mini أداءً مشابهًا في العديد من مهام الاستدلال المفيدة مع كونه أكثر فعالية من حيث التكلفة بشكل ملحوظ.
على سبيل المثال، في المعايير التي تتطلب الذكاء والتفكير المنطقي، يكون أداء o1-mini جيدًا مقارنة بـ o1-preview وo1. لكن أداؤها كان سيئًا في المهام التي تتطلب معرفة واقعية غير متعلقة بالعلوم والتكنولوجيا والهندسة والرياضيات.
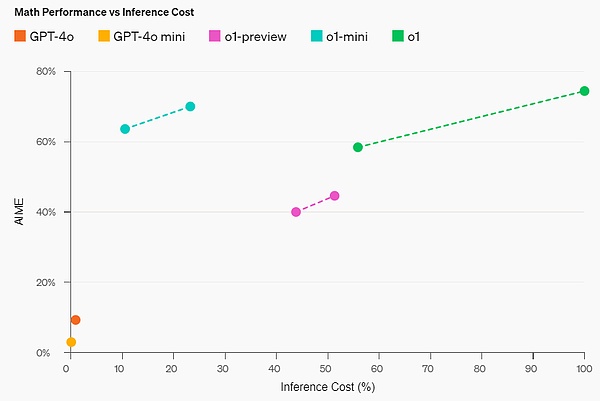
القدرة الرياضية: في مسابقة الرياضيات AIME بالمدرسة الثانوية، o1-mini (70.0) % ) على قدم المساواة مع o1 (74.4%)، ولكنه أرخص بكثير وأفضل من o1-preview (44.6%). النتيجة في o1-mini (حوالي 11/15 سؤالًا) هي تقريبًا من بين أفضل 500 طالب في المدارس الثانوية في الولايات المتحدة.
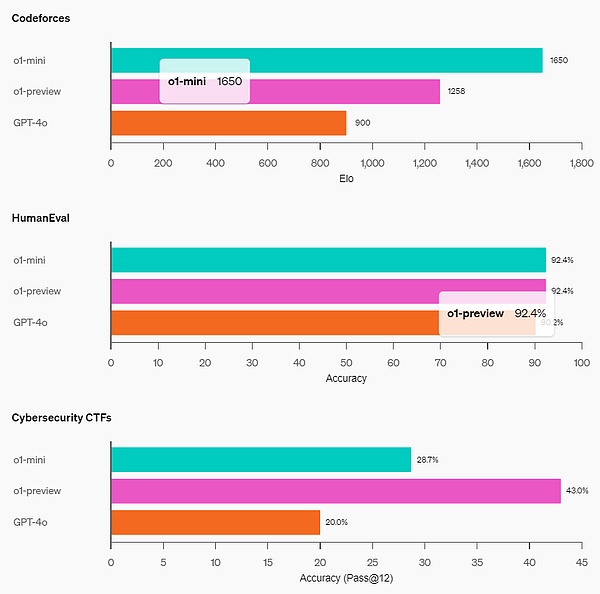
القدرة على البرمجة: على موقع مسابقة Codeforces، حصل o1-mini على درجة Elo تبلغ 1650، وهي تعادل o1 (1673) وأعلى من o1-preview (1258). بالإضافة إلى ذلك، كان أداء o1-mini جيدًا في معيار ترميز HumanEval وتحدي الأمن السيبراني في المدرسة الثانوية (Capture the Flag (CTF).
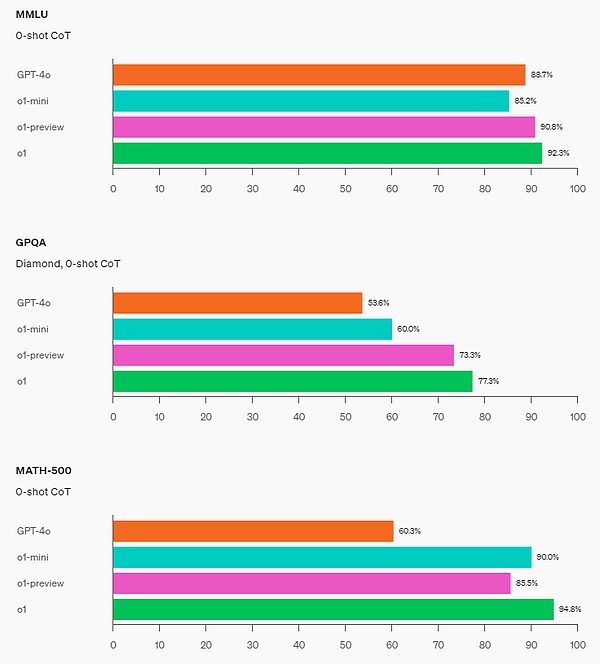
STEM: في بعض المعايير الأكاديمية التي تتطلب الاستدلال، مثل GPQA (العلوم) وMATH-500، أداء o1-mini أفضل من أداء GPT-4o. أداء o1-mini أسوأ من GPT-4o في مهام مثل MMLU، ويتخلف عن معاينة o1 في معايير GPQA بسبب الافتقار إلى المعرفة العالمية الواسعة.
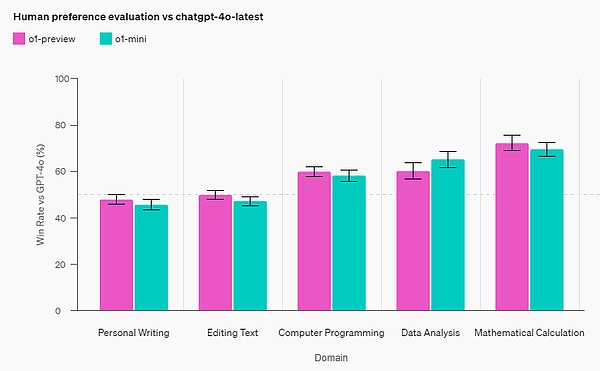
تقييم تفضيلات الإنسان: OpenAI يجعل المقيمين البشريين يواجهون تحديًا في مختلف المجالات مقارنة o1-mini وGPT-4o في المطالبات المفتوحة. على غرار o1-preview، يعد o1-mini أكثر شيوعًا من GPT-4o في المجالات كثيفة الاستدلال؛ ولكن في المجالات التي تركز على اللغة، لا يعد o1-mini أكثر شيوعًا من GPT-4o.
من حيث السرعة، قامت OpenAI بمقارنة GPT-4o وo1-mini وo1 -معاينة الإجابة على سؤال الاستدلال كلمة. أظهرت النتائج أن GPT-4o يجيب بشكل غير صحيح، بينما يجيب كل من o1-mini وo1-preview بشكل صحيح، مع وصول o1-mini إلى الإجابة بشكل أسرع بحوالي 3-5 مرات.

كيفية استخدام OpenAI o1؟
يمكن لمستخدمي ChatGPT Plus وTeam (الإصدارات الفردية والجماعية) البدء في استخدام نموذج o1 في منتج chatbot الخاص بالشركة ChatGPT على الفور. يمكنك اختيار استخدام o1-preview أو o1-mini يدويًا. ومع ذلك، استخدام المستخدم محدود.
في الوقت الحالي، يمكن لكل مستخدم إرسال 30 رسالة فقط إلى o1-preview و50 رسالة إلى o1-mini في الأسبوع.
نعم، قليل جدًا! ومع ذلك، قالت OpenAI إنها تعمل جاهدة لزيادة عدد المرات التي يمكن للمستخدمين استخدامها والسماح لـ ChatGPT بتحديد واستخدام النموذج المناسب تلقائيًا لكلمة مطالبة معينة.
أما بالنسبة لمستخدمي الإصدارين Enterprise وEducation، فلن يتمكنوا من البدء في الاستخدام هذا البرنامج حتى الأسبوع المقبل نموذجين.
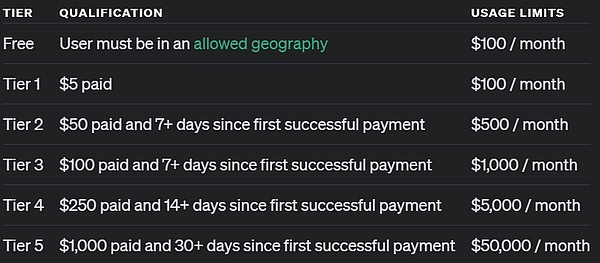
أما بالنسبة للمستخدمين الذين يصلون عبر واجهة برمجة التطبيقات، فقد ذكرت OpenAI أن المطورين الذين وصلوا إلى المستوى الخامس من استخدام واجهة برمجة التطبيقات يمكنهم البدء فورًا في استخدام هذين النموذجين لبدء تطوير النماذج الأولية للتطبيقات، ولكن السرعة محدودة أيضًا: 20 دورة في الدقيقة. ما هو استخدام المستوى 5 لواجهة برمجة التطبيقات (API)؟ ببساطة، هذا يعني أنك أنفقت أكثر من 1000 دولار وكنت مستخدمًا مدفوعًا لأكثر من شهر واحد. الرجاء إلقاء نظرة على الصورة أدناه:
يشير OpenAI إلى أن واجهة برمجة التطبيقات تستدعي هذين الاثنين النماذج لا تتضمن استدعاءات الوظائف، والبث، ورسائل دعم النظام، وما إلى ذلك. وبالمثل، تقول OpenAI إنها تعمل على تحسين هذه الحدود.
المستقبل
ذكرت OpenAI أنه في المستقبل، بالإضافة إلى تحديثات النموذج، ستضيف أيضًا وظائف مثل تصفح الشبكة وتحميل الملفات والصور، إلخ لجعل هذه النماذج أكثر فائدة.
"بالإضافة إلى نماذج سلسلة o1 الجديدة، نخطط لمواصلة تطوير وإصدار نماذج سلسلة GPT."
المحتوى المرجعي:
https://openai.com/index/introducing-openai-o1-preview/
https://openai.com/index/openai-o1-mini-advancing-cost-efficiency-reasoning/
https: //openai.com/index/learning-to-reason-with-llms/
https://x .com/ sama/status/1834283100639297910


 JinseFinance
JinseFinance



