How does the Lightning Network work (1)?
In today’s article, we will continue to introduce the Lightning Network and explain its operating principles and related technologies.
 JinseFinance
JinseFinance

At the beginning of 2024, OpenAI threw another AI bomb to the world-the video generation model Sora.
Just like ChatGPT a year ago, Sora is considered to be another milestone moment in AGI (Artificial General Intelligence).
"Sora means that AGI implementation will be shortened from 10 years to 1 year," Zhou Hongyi, chairman of 360, made a prediction.
But this model is so sensational not just because the videos generated by AI are longer and higher in definition, but because OpenAI has surpassed all previous ones. The ability of AIGC generates video content related to the real physical world.
The nonsensical cyberpunk is cool, but how everything in the real world can be reproduced by AI is more meaningful.
To this end, OpenAI has proposed a brand new concept - World Simulator.
In the technical report officially issued by OpenAI, Sora is positioned as"a video generation model as a world simulator", "Our research results It shows that extending the video generation model is a feasible way to build a general simulator of the physical world."

(Source: OpenAI official website)
OpenAI believes thatSora has laid the foundation for models that can understand and simulate the real world, which will be an important milestone in the realization of AGI. With this, it has completely separated itself from companies such as Runway and Pika in the AI video track.

From text (ChatGPT) to pictures (DALL·E) to video (Sora), for OpenAI, it is like collecting puzzle pieces one by one, trying to completely break the boundary between virtuality and reality through the form of image media, becoming The movie "Ready Player One"-like existence.
If Apple Vision Pro is the hardware display of the number one player, then an AI system that can automatically build a simulated virtual world is the soul.
"The language model approximates the human brain, and the video model approximates the physical world," said Yao Fu, a doctoral student at the University of Edinburgh.
"OpenAI's ambition is beyond everyone's imagination, but it seems that it is the only one that can do it." Many AI entrepreneurs lamented about Light Cone Intelligence road.
How does Sora become a "world simulator"?
OpenAI’s newly released Sora model has opened the door to the AI video track in 2024, completely different from that in 2023 A dividing line was drawn between the old world.
In the 48 demonstration videos it released in one breath, Light Cone Intelligence found that most of the problems that were criticized for AI videos in the past have been solved: clearer Generate pictures, more realistic generation effects, more accurate understanding, smoother logical understanding, more stable and consistent generation results, etc.
But all this is just the tip of the iceberg that OpenAI has shown,because OpenAI has not been targeting videos from the beginning, but all existing images. .
Image is a larger concept, and video is a subset of it, such as the large scrolling screens on the street and the virtual scenes in the game world. etc. What OpenAI wants to do is to use video as an entry point to cover all images, simulate and understand the real world, which is the concept of "world simulator" it emphasizes.
As Chen Kun, the producer of the AI movie "Wonderland of Mountains and Seas" and Xingxian Culture, told Lightcone Intelligence, "OpenAI is showing us its capabilities in video. But the real purpose is to obtain people's feedback data to explore and predict what kind of videos people want to generate. Just like large model training, once the tool is opened, it will be equivalent to people all over the world working for it, through Continuous marking and input make its world model become smarter and smarter."
So we see thatAI video has become a way to understand the physical world. In the first stage, it mainly highlights its properties as a "video generation model"; in the second stage, it can provide value as a "world simulator".
The core of grasping Sora's "video generation" attribute is to find the differences, that is, Sora, Runway, and Pika Where is the difference reflected? This question is crucial because it explains to some extent why Sora is able to crush.
First of all, OpenAI follows the idea of training a large language model, using large-scale visual data to train a generative model with general capabilities.
This is completely different from the logic of "dedicated personnel only" in the field of Wensheng video. Last year, Runway had a similar plan, which it called a "universal world model." The idea was roughly similar, but there was no follow-up. This time Sora took the lead in fulfilling Runway's dream.
According to calculations by New York University Assistant Professor Xie Saining, the number of Sora parameters is about 3 billion. Although it is insignificant compared to the GPT model, this order of magnitude has far exceeded Runway and Pika. For some companies, it can be called a dimensionality reduction attack.
Qi Borquan, general manager of Wanxing Technology AI Innovation Center, commented that Sora's success once again verified the possibility of "big miracles", "Sora still follows OpenAI's Scaling Law, relies on hard work to achieve miracles, a large amount of data, large models and a large amount of computing power. The bottom layer of Sora uses world models verified in the fields of games, driverless driving and robotics to build a Vincent video model to achieve the ability to simulate the world."
Secondly, Sora demonstrated for the first time the perfect integration of diffusion model and large model capabilities.
AI video is like a blockbuster movie, depending on two important elements: script and special effects. Among them, the script corresponds to the "logic" in the AI video generation process, and the special effects correspond to the "effect". In order to achieve "logic" and "effect", two technical paths are differentiated behind the diffusion model and the large model.
At the end of last year, Light Cone Intelligence predicted that in order to satisfy both effects and logic, the two routes of diffusion and large models will eventually converge. Unexpectedly, OpenAI solved this problem so quickly.
(Source: OpenAI official website)
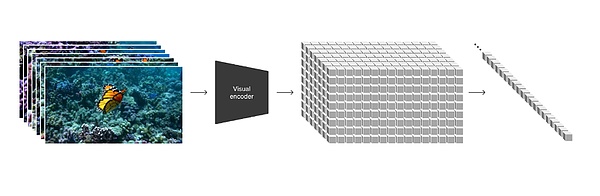
OpenAI draws in technical report Highlights: “Our approach transforms various types of visual data into a unified representation that can be used for large-scale training of generative models.”
Specifically, OpenAI encodes each frame of the video into visual patches. Each patch is similar to a token in GPT and becomes the smallest unit of measurement in videos and images. And it can be broken and reorganized anytime and anywhere. Having found a way to unify data and unify weights and measures, we have found a bridge between the diffusion model and the large model.
During the entire generation process, the diffusion model is still responsible for the generation effect. After adding the attention mechanism of the large model Transformer, there will be more control over the generation. Prediction and reasoning capabilities, which explains why Sora can generate videos from existing acquired still images, and can also expand existing videos or fill in missing frames.
Since its development, video models have shown a trend of compounding. While models are moving toward fusion, technology is also moving toward compounding.
Applying previously accumulated technology accumulation to visual models has also become OpenAI’s advantage. During the training process of Sora Vincent's video, OpenAI introduced the language understanding capabilities of DALL-E3 and GPT. According to OpenAI, training based on DALL-E3 and GPT can enable Sora to accurately generate high-quality videos according to user prompts.
After a set of combined punches, the result is simulation ability, which forms the basis of the "world simulator".
"We found that video models exhibit a number of interesting emerging capabilities when trained at scale. These capabilities make Sora Ability to simulate certain aspects of people, animals and environments in the physical world. These properties arise without any clear inductive bias towards three dimensions, objects, etc.—they are purely phenomena of scale," says OpenAI.
The fundamental reason why "simulation" can explode so much is that people are accustomed to using large models to create things that don't exist, but they can accurately understand physics. The logic of how the world works, such as how forces interact, how friction is generated, how a basketball hits a parabola, etc. These are things that no previous model has been able to accomplish, and this is the fundamental meaning of Sora beyond the level of video generation.
However, from the demo to the actual finished product, it may be a surprise or a shock. Yang Likun, chief scientist of Meta, directly questioned Sora. He said: "Just being able to generate realistic videos based on prompts does not mean that the system truly understands the physical world. The generation process is different from causal prediction based on world models. Generative models You only need to find a reasonable sample from the possibility space, without understanding and simulating the causal relationship in the real world."
Qi Borquan also said that although OpenAI It has been verified that the large Vincent video model based on the world model is feasible, but there are also difficulties in the accuracy of physical interactions. Although Sora can simulate some basic physical interactions, it may encounter difficulties when dealing with more complex physical phenomena; There are challenges in dealing with long-term dependencies, that is, how to maintain temporal consistency and logic; the accuracy of spatial details. If the processing of spatial details is not accurate enough, it may affect the accuracy and credibility of the video content.
Disrupting video, but much more than just video
Sora may have become a world simulator a long time ago, but in terms of generating videos, it has already had an impact on the current world.
The first category is to solve problems that could not be broken through in previous technologies and push some industries to a new stage.
The most typical one is the film and television production industry. The most revolutionary ability of Sora this time is that the longest generated video length reaches 1 minute. For reference, the popular Pika can generate a length of 3 seconds, and Runway’s Gen-2 can generate a length of 18 seconds. This means that with Sora, AI video will become a real productivity, achieving cost reduction and efficiency improvement.
Chen Kun told Guangcone Intelligence that before Sora was born, the cost of using AI video tools to produce science fiction movies had dropped to half. After Sora was launched, it became even more worthwhile. expect.
After Sora was released, what impressed him most was a demo of a dolphin riding a bicycle. In that video, the upper body is a dolphin, the lower body is two human legs, and there are shoes on the legs. In a very weird style of painting, the dolphin completes the action of riding a bicycle as a human.
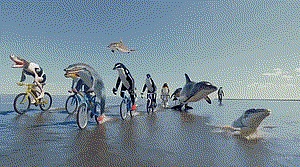
"This is simply amazing to us! This picture creates a sense of absurdity that is both imaginative and in line with the laws of physics. It is both reasonable and unexpected. This is what makes the audience marvel. film and television works," said Chen Kun.
Chen Kun believes thatSora will lower the threshold for all content creators by a big step, just like smartphones and Douyin back then. Order of magnitude magnification.
"In the future, content creators may not need to take pictures. They only need to say a paragraph or a word to express the unique ideas in their heads. Come out and be seen by more people. By then, I think there may be a new platform bigger than Douyin. Taking a step forward, maybe Sora can understand everyone's subconscious thoughts and automatically generate and create Content does not require users to actively seek expression,” Chen Kun said.
The same industry also includes games. The end of the OpenAI technical report is a game video of "Minecraft" with the following sentence written next to it: "Sora can Simultaneously control players in Minecraft through basic strategies while rendering the world and its dynamics with high fidelity. Simply mentioning 'Minecraft' in Sora's prompt subtitles will trigger these features up close."

AI Game entrepreneur Chen Xi told us, "Any game practitioner will break into a cold sweat when they see this sentence! OpenAI shows its ambitions without reservation." Chen Xi’s interpretation and analysis believes that this short sentence conveys two things:Sora can control the game character and at the same time render the game environment.
"As OpenAI said, Sora is a simulator, a game engine, and a conversion interface between imagination and the real world. The future For games, as long as you talk about it, the picture can be rendered. Sora has now learned to build a world in one minute, and can also generate stable characters. Coupled with its own GPT-5, a purely AI-generated, thousands of square kilometers , a map full of active creatures of various colors, it no longer sounds like a fantasy. Of course, whether the screen can be generated in real time and whether it supports multi-player online are very real issues. But no matter what, the new game mode is already coming, at least with It’s no problem for Sora to generate “It’s over, I’m surrounded by beauties”,” Chen Xidao said.
The second category is based on the ability to simulate the world to create new things in more fields.
Yao Fu, a doctoral student at the University of Edinburgh, said: "Generative models learn algorithms that generate data, rather than remembering the data itself. Just like language Just as models encode the algorithms (in your brain) that generate language, video models encode the physics engines that generate video streams.Language models can be thought of as approximating the human brain, while video models approximate the physical world.”< /p>
Learning the universal laws in the physical world makes embodied intelligence closer to human intelligence.
For example, in the field of robotics, the previous transmission process was to first give a handshake instruction to the robot brain and then pass it to the hand. However, because the robot cannot really understand "Handshake" means, so the instruction can only be converted into "how many centimeters can the diameter of the hand be reduced to?" If the world simulator becomes a reality, robots can directly skip the process of command conversion and understand human command needs in one step.
Jia Kui, founder of Cross-Dimensional Intelligence and professor at South China University of Technology, expressed to Light Cone Intelligence that explicit physical simulation may be applied to robots in the future field, "Sora's physical simulation is implicit. It shows effects that can only be generated by its internal understanding and simulation of the physical world. To be directly useful to robots, I think it is better to make it explicit."
"Sora's capabilities are still achieved through massive video data and recaptioning technology. There is not even 3D explicit modeling, let alone physical simulation. . Although the effect it generates has reached/closed to the effect achieved through physical simulation. But the physics engine can do more than just generate videos, and there are many other elements necessary for training robots," Jacqui said .
Although Sora still has many limitations, a link has been established between the virtual and real worlds, which makes whether it is a Ready Player One-style virtual world, Whether robots are more like humans, they are full of greater possibilities.
In today’s article, we will continue to introduce the Lightning Network and explain its operating principles and related technologies.
JinseFinanceArweave, Arweave's working principle and significance of existence Golden Finance, this article briefly introduces Arweave's working principle and value.
JinseFinanceGoogle's new AI model, HeAR, uses bioacoustic analysis to detect early signs of health conditions by analyzing sounds like coughs and breaths. Partnering with Salcit Technologies, Google aims to enhance early disease detection and accessibility, though challenges remain in ensuring the AI’s accuracy and gaining medical trust.
 Joy
JoyZircuit, an Ethereum Layer 2 network, stands out with its AI-powered sequencer for enhanced transaction security and efficiency, attracting over $3.3 billion in staked assets ahead of its mainnet launch backed by Binance Labs.
JoyTwo days ago, foreign media conducted an exclusive interview with the Sora core team. After watching the original video, it was almost as if nothing was said. The scene looked like a speech by Section Chief Ma of the National Development and Reform Commission.
JinseFinanceExplore the future of the integration of AI and Web3: decentralized computing power, big data, Dapp innovation, and its profound impact on industrial innovation.
JinseFinanceThere are four ways to integrate AI and Web3: decentralized computing power, algorithm and model collaboration, decentralized big data, and AI-empowered Dapp.
JinseFinanceWhy can Sora be called a new milestone in the AI industry? How did it break through the AIGC, the upper limit of AI content creation? Objectively speaking, are there any limitations or shortcomings in the current version of Sora?
JinseFinanceSora is an artificial intelligence model developed by OpenAI that can generate realistic and imaginative video scenes based on user-entered text instructions.
JinseFinanceThe AI track is booming again. Which projects are performing well and which new forces are emerging?
JinseFinance