OpenAI发布可对话的新ChatGPT机器人
OpenAI 正在推出一款可以与之交谈的先进人工智能聊天机器人。这款机器人现已上市。
 JinseFinance
JinseFinance

来源:元宇宙日爆
还未开放公众测试,OpenAI凭借文本生成视频模型Sora 制作的预告片,就把科技圈、互联网、社交媒体圈给震惊了。
根据OpenAI官方发布的视频,Sora能够根据用户提供的文本信息,生成长达1分钟的复杂场景“超视频”,不仅画面细节逼真,这个模型还会模拟镜头运动感。
从已释出的视频效果看,业内兴奋的正是 Sora 体现出的理解真实世界的能力。相较其他文本到视频的大模型,Sora 在对语义理解、画面呈现、视觉连贯性和时长上都显示出优势。
OpenAI 直接称它为“世界模拟器”,宣告它能够模拟物理世界中的人、动物和环境的特征。但该公司也承认,目前Sora的还不完美,依然存在理解不到位和潜在的安全问题。
因此,Sora仅对非常少数的人开放测试,OpenAI 尚未公布 Sora何时会向大众开放,但它带来的震撼足以让研发同类模型的公司看到差距。
OpenAI文本生成视频模型Sora一出,国内又现“震惊体”评价。
自媒体惊呼“现实不存在了”,互联网大佬也吹爆了Sora的能力。360创始人周鸿祎称,Sora的诞生意味着AGI的实现可能从10年缩短至两年左右。短短几天,Sora的谷歌搜索指数迅速拉升,热度直逼ChatGPT。
Sora的爆火源于OpenAI 发布的48段视频,其中时长最长的为1分钟。这不仅打破了此前文生视频模型Gen2、Runway生成视频的时长极限,而且画面清晰,甚至它还学会了镜头语言。
1分钟视频中,一位身着红裙的女性走在霓虹灯林立的街头,风格写实,画面流畅,最令人惊艳的是女主角的特写,连脸部的毛孔、斑点、痘印都模拟了出来,卡粉脱妆效果堪比直播关掉美颜滤镜,脖子上的颈纹甚至精准“泄露”了年龄,与脸部状态做到了完美统一。
除了对人物写实,Sora还能够模拟现实中的动物与环境。一段视频维多利亚冠鸽的多角度特写,超清呈现了这只鸟全身至冠的蓝色羽毛,甚至细微到红色眼珠的动态和呼吸频率,让人很难分清这到底是AI生成的还是人类拍摄的。
对于非写实的创意动画,Sora的生成效果也达到了迪士尼动画电影的画面感,让网友担忧起动画师的饭碗。
而Sora为文本生成视频模型带来的改进不仅在视频时长与画面效果上,它还能模拟镜头与拍摄的运动轨迹,游戏的第一人称视角,航拍视角,甚至是电影里的一镜到底。
看完OpenAI放出的精彩视频,你就能理解互联网圈、社交媒体舆论为什么会为Sora感到震惊,而这些只是预告片。
那么,Sora是如何实现模拟能力的?
按照Open AI发布的Sora技术报告,这个模型正在超越先前图像数据生成模型的限制。
以往的文本生成视觉画面的研究采用过各种方法,包括循环网络、生成对抗网络(GAN)、自回归变换器和扩散模型,但共性是集中在较少的视觉数据类别、较短的视频或固定尺寸的视频上。
Sora采用了一种基于Transformer的扩散模型,生图过程可以分为正向过程和反向过程两个阶段,以实现Sora能沿时间线向前或向后扩展视频的能力。
正向过程阶段模拟了从真实图像到纯噪点图像的扩散过程。具体来说,模型会逐步地向图像中添加噪点,直到图像完全变成噪点。而反向过程是正向过程的逆过程,模型会从噪点图像逐步恢复出原始图像。一正一反,虚实来回,OpenAI以这种方式让机器Sora理解视觉的形成。
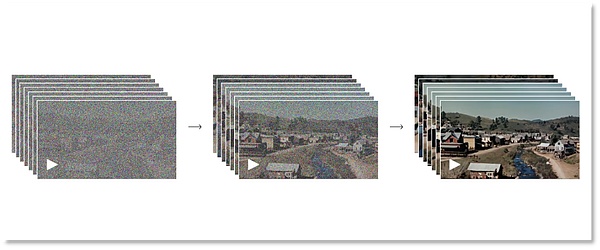 从全噪点到清晰图的过程
从全噪点到清晰图的过程
当然,这个过程需要反复地训练学习,模型会学习如何逐步去除噪声并恢复图像的细节。通过这两个阶段的迭代,Sora的扩散模型能够生成高质量的图像。这种模型在图像生成、图像编辑、超分辨率等领域表现出了优秀的性能。
上述过程解释了Sora能做到高清、超细节的原因。但从静态的图像到动态的视频,仍需要模型进一步积累数据,训练学习。
在扩散模型的基础上,OpenAI将视频和图像等所有类型的视觉数据转换为统一表示,以此来对Sora做大规模的生成训练。Sora 使用的表示方式被OpenAI定义为“视觉补丁(patches)”,即一种更小数据单元的集合,类似于GPT中的文本集合。
研究者首先将视频压缩到一个低维潜空间中,随后把这种表征分解为时空patch,这是一种高度可扩展的表征形式,方便实现从视频到patch的转换,也正适用于训练处理多种类型视频和图片的生成模型。
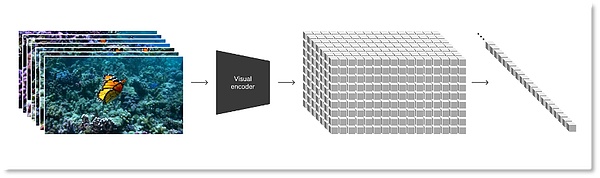 将视觉数据转化为patches
将视觉数据转化为patches
为了用更少的信息与计算量训练Sora,OpenAI 开发了一个视频压缩网络,把视频先降维到像素级别的地低维潜空间,然后再去拿压缩过的视频数据去生成 patches,这样就能使输入的信息变少,从而减少计算压力。同时,OpenAI还训练了相应的解码器模型,将压缩后的信息映射回像素空间。
基于视觉补丁的表示方式,研究者能对Sora针对不同分辨率、持续时间和长宽比的视频/图像进行训练。进入推理阶段,Sora能通过在适当大小的网格中排列随机初始化的patches来判断视频逻辑、控制生成视频的大小。
OpenAI报告,在大规模训练时,视频模型就表现出令人兴奋的功能,包括Sora 能够真实模拟现实世界中的人、动物和环境,生成高保真的视频,同时实现3D一致性、时间一致性,从而真实模拟物理世界。
从结果到研发过程,Sora显示着强大的能力,但普通用户还无从体验,目前只能写好提示词,在X上@OpenAI创始人Sam Altman,由他作为二传手,帮网友们在Sora上生成视频后放出来给公众看效果。
这也不免令人怀疑Sora是否真的如OpenAI官方展示得那么牛。
对此,OpenAI直言,目前模型还存在一些问题。如同早期的GPT一样,现在的Sora也有“幻觉”,这种错误表示在以视觉为主的视频结果上显示地更为具象。
例如,它不能准确地模拟许多基本相互作用的物理过程,例如跑步机履带与人的运动关系,玻璃杯破碎与杯内液体流出的时序逻辑等等。
在下面这个“考古工作者们挖掘出一个塑料椅”的视频片段里,塑料椅直接从沙子里“飘”了出来。
还有凭空出现的小狼崽,被网友戏称为“狼的有丝分裂”。
它有时也分不清前后左右。
这些动态画面中存在的纰漏似乎都在证明,Sora仍需要对物理世界运动的逻辑去做更多的理解和训练。此外,相比ChatGPT的风险,给人直观视觉体验的Sora存在的道德、安全风险更甚。
此前,文生图模型Midjourney已经告诉人类 “有图不见得有真相”,人工智能生成的以假乱真的图片开始成为谣言要素。身份验证公司 iProov 的首席科学官纽维尔博士就表示,Sora能让“恶意行为者更容易生成高质量的假视频。”
可想而知,如果Sora生成的视频被恶意滥用,搞在欺诈和诽谤、传播暴力和色情上,造成的后果也难以估量,这也是Sora让人在震惊之余还会害怕的原因。
OpenAI也考虑到了Sora可能带来的安全问题,这大概也是Sora仅对非常少数人以邀请制开放测试的原因。何时会大众开放?OpenAI没有给出时间表,而从官方释出的视频看,其他公司追赶Sora模型的时间不多了。
OpenAI 正在推出一款可以与之交谈的先进人工智能聊天机器人。这款机器人现已上市。
JinseFinance加密市场,本次市场低迷何时结束? 金色财经,对于加密货币来说,过去几个月是艰难的几个月。
JinseFinance借着近期OpenAI 4o版本的发布,侃一下对AI+区块链的看法。
JinseFinance前两天外媒对Sora核心团队做了次专访,看了下原视频,约等于什么都没说,场面神似发改委马科长讲话。
JinseFinanceChina recently aired its first GenAI cartoon series, "Qianqiu Shisong," showcasing AI's role in animation alongside Sora-like tools. This move reflects China's push for AI integration in media, sparking debates on its impact on creativity and job security.
 Weatherly
WeatherlySora是OpenAI开发的一种人工智能模型,它可以根据用户输入的文本指令生成逼真和富有想象力的视频场景。
JinseFinanceOpenAI,Sora涌现:OpenAI又一次暴力美学的胜利 金色财经,我们距离 AGI(通用人工智能)又近了一步。
JinseFinanceOpenAI's launch of a video generation model named "Sora" has led to a surge in cryptocurrency prices, including the tokens SORA and meme coins.
 Huang Bo
Huang Bo Coinlive
Coinlive  Cointelegraph
Cointelegraph