RSS3 は Web3 分野で有望なプロジェクトとして注目されています。最近、Web3 アプリケーションを体験し、Web3 のコア要素の定義パラダイムを見つけようとしていました。RSS3 を調べていたところ、探していたプロトコルを見つけました。これはデータ仕様プロトコルとして定義でき、そのプロトコルは RFC3986 Unique Resource Identifier であり、一般的な文法としても理解できます。
ドキュメントの原文は 3 ワードを超え、読みにくいため、ドキュメントを大幅に削除および変更し、web3 のデータ形式を理解するためのサンプルを作成しました。
知っておく必要があるのは、この仕様はインターネット情報の標準であり、長い間適用されてきたものであり、RSS3 は Web3 分野での適用を目的として作成された開発手法に基づいているということです。
RSS3
RSS3 は、Web3 での効率的かつ分散型の情報配信をサポートするために設計されたオープンな情報シンジケーション プロトコルです。これは、他の消費者が広範な互換性ロジックなしで統一フォーマットのさまざまなコンテンツ ソースに簡単にアクセスできるように、情報の表示と通信のフォーマットを定義します。
RSS3 プロトコルでは、情報は設定ファイル、リンク、アセット、コメントの 4 つのタイプに分類されます。
RSS3 アプリケーションは、RSS3SDK を使用して、RSS3 プロトコルで定義された形式でデータにアクセスし、公開します。RSS3 SDK は、RSS3 ネットワークからデータを取得し、そのデータを RSS3 でサポートされているネットワークに公開します。RSS3 ネットワークは、RSS3 がサポートするさまざまなネットワークからデータをクロールし、データをキャッシュします高効率データベースでは、検索機能を提供するために人工知能の推奨アルゴリズムを適用するなど、いくつかの前処理を実行します。
このような製品設計では、ネットワーク伝送データの詳細を定義することで最もオリジナルなデータ仕様が完成し、データが定義されると、基本的なデータ利用部分が完成します。上位層アプリケーションはより簡単に実装できるため、このプロトコル RFC3986 Unique Resource Identifier を見てみましょう。コンテンツを削除および変更した後、作成者はインターネット データ処理を簡単に理解するために、いくつかの関連要件を満たすよう努めます。
RFC3986: 統一リソース識別子
この仕様は、RFC2396 [RFC2396]、RFC1808 [RFC1808]、および RFC1738 [RFC1738] から派生しており、ホスト構文の IPv6 リテラルの更新 (および修正) が含まれています。
URI (Uniform Resource Identifier) は、抽象的なリソースまたは物理的なリソースを表すコンパクトな文字列であり、リソースを識別するためのシンプルで拡張可能な方法を提供します。この仕様では、汎用 URI 構文と相対形式での URI 参照の手続き的解決、および URI を使用するためのガイドラインとセキュリティに関する考慮事項が定義されています。
URI 文法は、構文スーパーセットを定義します。有効な URI では、共通コンポーネント解析が可能になり、特定のスキームで必要とされない場合に、URI を使用して考えられるすべての識別子を参照できるようになります。仕様では、URI 生成文法は定義されていません。
URI (Uniform Resource Identifier) セマンティクスは、World Wide Web Global Information Initiative によって導入された概念から派生しており、その構文は、「インターネット機能」にリストされているリソース ロケーター [RFC1736] およびユニフォーム リソース ネーム機能の要件を満たすように設計されています。推奨事項」 [RFC1737] 。
この文書は [RFC2396] を廃止し、「Uniform Resource Locators」[RFC1738] と「Relative Uniform Resource Locators」[RFC1808] を統合して、すべての URI に共通する単一の構文を定義します。 IPv6 アドレスの構文を導入した [RFC2732] は廃止されました。
URIの特徴
均一
これにより、リソースへのアクセスに使用されるメカニズムが異なる場合でも、異なるタイプのリソースが同じコンテキスト内で同じリソース識別子を使用できるようになります。
これにより、共通の文の統一された意味解釈が可能になり、さまざまなタイプのリソース識別子にわたる合意を完成させることができます。
これにより、既存の識別子の使用方法を妨げることなく、新しいタイプのリソース識別子を導入できます。
これにより、識別子をさまざまなコンテキストで再利用できるようになり、新しいアプリケーションやプロトコルが既存の大規模で広く使用されているリソース識別子のセットを利用できるようになります。
リソース
「リソース」という用語は、一般的な意味で、URI によって識別できるあらゆるコンテンツを指します。よく知られた例には、電子ドキュメント、画像、情報ソース、サービス、およびその他のリソースのコレクションが含まれます。リソースは必ずしもインターネット経由でアクセスできるとは限りません。同様に、抽象化は、数式の演算子やオペランド、関係の種類 (「親」や「従業員」など)、数値 (0、1、無限大など) などのリソースにすることができます。
識別子
識別子は、必要な情報をその範囲内の他のすべてのものから区別するコンテンツ認証プロセスを具体化します。ただし、これらの定義は、識別子の定義や、参照されるコンテンツの ID を具体化するものと誤解されるべきではありません。多くの場合、URI はリソースを示すために使用されますが、リソースにアクセスできることを示すためには使用されません。同様に、識別される「a」リソースは、本質的に単数ではない場合があります (たとえば、リソースは名前付きセットまたは経時的なマッピングである可能性があります)。
URI はグローバル スコープを持ち、何があっても一貫してコンテキストを解釈するために使用されますが、この解釈の結果はエンド ユーザーのコンテキストに関連する場合があります。たとえば、「http://localhost/」は、「localhost」に対応するネットワーク インターフェイスが異なるユーザーであっても、参照されるすべてのユーザーに対して同じ解釈を持ちます。これは、解釈がアクセスに依存しないことを意味します。
共通文法
URI 構文は、フェデレーテッドで拡張可能な命名システムであり、各スキームの仕様により、そのスキームを使用する識別子の構文とセマンティクスをさらに制限できます。
URI 参照は、独立した解決メカニズムを使用します。これにより、URI 参照の形式を使用するプロトコルとデータは、まだ定義されていないスキームを含む、この仕様で許可されている構文の全範囲を参照して URI を定義できます。
汎用 URI 文法のパーサーは、あらゆる URI 参照をその主要コンポーネントに解析できます。計画決定後はさらに
シナリオ固有の解析はコンポーネントに対して実行できます。言い換えれば、URI 汎用構文はすべての URI 構文のスーパーセットです。
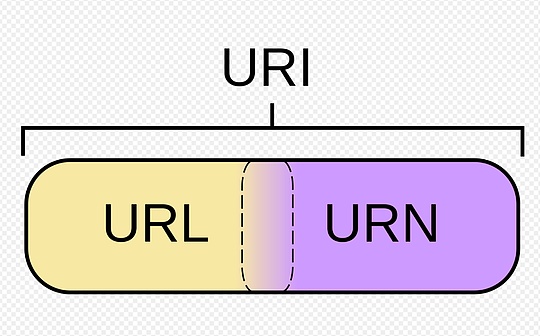
URI、URL、URN
URI は、ロケーター、名前、またはその両方としてさらに分類できます。
「Uniform Resource Locator」(URL) は、URI のサブセットを指します。リソースを識別することに加えて、リソースのアクセスメカニズム (ネットワークの「場所」など) を記述することによってリソースの場所を特定する方法も提供します。
「Uniform Resource Name」(URN) は、リソースが存在しなくなった後、または使用できなくなった後でも、グローバルに一意なままである他の URI を参照するために使用されていました。
URI は、ラテン文字、数字、およびいくつかの特殊文字という非常に限られたセットから抽出されます。
URI は、紙上のインク、画面上のピクセル、文字エンコード オクテットのシーケンスなど、さまざまな方法で表現できます。 URI の解釈は、使用される文字のみに依存します。ローカルまたは地域環境では、テクノロジーの進歩に伴い、ユーザーはより広範囲の文字を使用できるようになります。
認識と相互作用の分離
URI についてよくある誤解は、URI はアクセス可能なリソースを参照するためにのみ使用されるということです。 URI 自体は認証を提供するだけであり、リソース ヒントへの URI アクセスの存在は保証されません。代わりに、関連する URI 参照は、データ形式属性やそれが出現する自然言語テキストなどのプロトコル要素によって定義されます。
URI が与えられると、システムは、おそらく「アクセス」、「更新」、「置換」、または「プロパティの検索」などの単語によって特徴付けられる、リソース上でさまざまな操作の実行を試みる可能性があります。このような操作は、URI を使用するプロトコルによって定義されます。
階層識別子
URI 構文は階層的に構成されており、コンポーネントは左から右に重要度の降順に並んでいます。
汎用構文では、コンポーネントを区切るためにスラッシュ ("/")、疑問符 ("?")、およびシャープ記号 ("#") 文字が使用されます。これは、このクラスの読み取り可能な識別子が一貫していることを除き、汎用パーサーの階層解釈にとって重要です。構文を使用すると、名前付けスキーム全体で階層を統一して表現できるため、その階層に対してスキームに依存しない参照を行うことができます。
通常、ドキュメントのセットまたは「ツリー」は共通の目的を果たすように構築されており、これらのドキュメント内の URI 参照の大部分は、ツリーの外側ではなくツリー内のリソースを指します。特定の場所にあるドキュメント サイトは、リモート サイトにあるリソースよりも、そのサイトにある他のリソースを参照する可能性が高くなります。 URI への参照により、ドキュメント ツリー パーツをその場所やアクセス スキームから独立させることができます。
文法記号
ABNF [RFC2234] の表記を使用します。これには、次のコア ABNF 構文規則が含まれます。
ALPHA(文字)、CR(キャリッジリターン)、DIGIT(10進数)、DQUOTE(ダブルクォーテーションマーク)、HEXDIG(16進数)、LF(ラインフィード)、SP(スペース)など。
URI 構文は、おそらくリソースを一連の文字として識別するために、データをエンコードする方法を提供します。また、URI 文字は、送信または表示のためにオクテットにエンコードされることがよくあります。
ABNF 表記は、US-ASCII コード化文字セット [ASCII] に基づいて、その終端値を負でない整数 (コード ポイント) として定義します。 URI は一連の文字であるため、URI 構文を理解するにはその関係を逆転する必要があります。したがって、ABNF で使用される整数値は、構文ルールを完成させるために対応する US-ASCII にマッピングし直す必要があります。
予約文字
URI は、コンポーネントとサブコンポーネントを区切る「予約済み」文字で構成されます。
予約文字の目的は、URI 内の他のデータと区切り文字を区別する一連の文字を提供することです。予約文字のサブセット (gen-delim) は、汎用 URI コンポーネントの区切り文字として使用されます。コンポーネントの ABNF 文法規則では、直接指定された予約または gen-delim は使用されません。代わりに、各文法規則はそのコンポーネント内で許可される (つまり、区切られていない) 文字をリストし、他のサブコンポーネントは URI スキーム定義によって指定できます。
予約文字はありません
URI で許可されているが予約されていない文字。大文字と小文字、10 進数字、ハイフン、ピリオド、アンダースコア、チルダが含まれます。
未予約=ALPHA/DIGIT/"-"/"."/"_"/"~"
異なる URI の非予約文字を置き換えますが、対応するパーセントエンコードされた US-ASCII オクテットは同等であり、同じリソースを識別します。一貫性を保つため、ALPHA 範囲内のパーセントでエンコードされたオクテット (%41-%5A および %61-%7A)、DIGIT (%30-%39)、ハイフン (%2D)、ピリオド (%2E) を使用して、URI を作成しないでください。アンダースコア (%5F) またはチルダ (%7E) プロデューサーは、URI 内で見つかった場合、URI ノーマライザーの対応する予約されていない文字にデコードされる必要があります。
識別データ
URI 文字は、識別されたシステム外部インターフェイスとして、各 URI の識別データ コンポーネントを提供します。
URI の生成と送信: ローカル名とデータのエンコーディング、パブリック インターフェイスのエンコーディング、URI 文字エンコーディング、データ形式のエンコーディング、プロトコル エンコーディング。
ローカル名 (ファイルシステム名など) はローカル文字エンコーディングで保存されます。 URI 生成アプリケーション (オリジン サーバーなど) は通常、意味のある名前を生成するための基礎としてローカル エンコーディングを使用します。 URI プロデューサは、ローカル エンコーディングをパブリック インターフェイスに適したエンコーディングに変換し、次にパブリック インターフェイスのエンコーディングを制限付きの URI 文字セット (予約済み、未予約、およびパーセント エンコード) に変換します。
これらの文字は、文書文字セットなどのデータ形式の参照として使用するためにオクテットにエンコードされ、多くの場合、インターネット プロトコル経由で送信するためにエンコードされます。
場合によっては、URI コンポーネントとそれが表すデータの識別は、文字エンコーディングの変換よりもはるかに簡単ではありません。
文法コンポーネント
汎用 URI 構文は、スキーム、権限、パス、クエリ、およびフラグメントの階層シーケンスで構成されます。
スキームとパスのコンポーネントは必須ですが、パスは空 (文字なし) であってもかまいません。アクセス許可が存在する場合、パスは空であるか、スラッシュ (「/」) 文字で始まる必要があります。権限が存在しない場合、パスは 2 つのスラッシュ文字 (「//」) で始まってはなりません。これらの制限により 5 つの異なる ABNF パス ルールが作成され、指定された URI 参照に一致するのはそのうちの 1 つだけです。
プラン
すべての URI は、そのスキーム内で識別子を割り当てるための仕様を参照するスキーム名で始まります。
スキーム名は、文字で始まり、文字、数字、プラス記号 (「+」)、ピリオド (「.」)、またはハイフン (「-」) の任意の組み合わせが続く一連の文字で構成されます。
スキーム=ALPHA*(ALPHA/DIGIT/"+"/"-"/".")
権限
多くの URI スキームには、命名のための階層要素権限が含まれているため、管理は URI の残りの部分によってその権限に委任されます。汎用構文は、汎用レジストリ ベースの名前またはサーバー アドレス、およびオプションでポートとユーザー情報を提供します。
権限コンポーネントの前には二重スラッシュ (「//」) があり、その後にスラッシュ (「/」)、疑問符 (「?」)、または番号の終わり (「#」) 文字が続きます。 URIの終わり。
権限 = [ユーザー情報 "@"]ホスト[":"ポート]
ザ・ホスト
機関のホスト サブコンポーネントは、角括弧で囲まれた IP リテラルによって識別されます。多くの場合、ホスト構文は単に DNS 内に既存のレジストリを作成して展開するために使用されるため、別のレジストリを展開するコストをかけずにグローバルに一意の名前を取得できます。
ホスト=IPフィールド/IPv4アドレス/登録名
IP フィールド = "["(IPv6Address/IPvFuture)"]"
IPvFuture="v"1*HEXDIG"."1*(未予約/サブセパレータ/":")
お問い合わせ
クエリ コンポーネントには、非階層データと、URI スキームおよび命名機関の範囲内のリソースを識別するパス コンポーネント内のデータが含まれます。
クエリ コンポーネントは疑問符 (「?」) 文字で表され、シャープ記号 (#) 文字で終了します。
クエリ=*(pchar/"/"/"?")
使用法
アプリケーションが URI を参照する場合、「URI」構文ルールで定義された完全な参照形式を常に使用するとは限りません。スペースを節約し、階層的な局所性を利用して、多くのインターネット プロトコル要素とメディア タイプの形式では短縮 URI が許可されていますが、構文を特定の形式の URI に制限しているものもあります。
ベース URI を構築する
フラグメントのみの参照に加えて、ベース URI が必要であることが知られています。リゾルバーはベース URI を確立する必要があります。ベース URI は、<absolute-URI> の構文規則に準拠する必要があります。
ベース URI は 4 つの方法のいずれかで確立できます。
コンテンツに埋め込まれたベース URI
エンティティのベース URI をカプセル化します。
エンティティの取得に使用される URI
デフォルトのベース URI (アプリケーションによって異なります)
正規化して比較する
URI に対する最も一般的な操作は、2 つの URI が URI を使用せずにそれぞれのリソースに同等にアクセスするかどうかを判断する単純な比較です。通常、URI を比較する前に広範な正規化が行われます。 URI 比較は、いくつかの特定の目的のために実行されます。
等価
URI はリソースを識別するために存在するため、同じリソースを識別する場合は同等とみなされます。ただし、この等価性の定義は実際にはあまり役に立ちません。2 つのリソースについて十分な知識または制御がない限り、それらを比較する方法がないからです。
2 つの URI が同等であると判断できたとしても、URI の比較だけでは、2 つの URI が異なるリソースを識別していると判断するには不十分です。
構文ベースの正規化
構文ベースの正規化には、ケース正規化、パーセント エンコード正規化、ドット セグメント除去などの手法が含まれます。
安全上のご注意
URI 自体はセキュリティ上の脅威を引き起こすものではありません。ただし、URI は、アクセスするためのコンパクトな命令セットを提供するためによく使用されます。
Web リソースの場合は、URI 内のデータを正しく解釈して、データが誤ってアクセスされないようにしたり、公開すべきではないデータ テキストが含まれないように注意する必要があります。
機密情報
URI プロデューサーは、ユーザー名を含むパスワードや秘密にすることを目的としたパスワードを提供しないでください。 URI は多くの場合、ブラウザーによって表示され、平文のブックマークに保存され、ユーザー エージェントの履歴や仲介アプリケーション (プロキシ) によっても表示されます。
セマンティック攻撃
userinfo サブコンポーネントはめったに使用されないため、authority コンポーネントに表示されるホストを使用して、ユーザーを信頼させる URI を構築することができます。
ftp://cnn.example.com&story=break_news@10.0.0.1/top_story.htm
実際にはホストが「10.0.0.1」であるにもかかわらず、ユーザーはホストが「cnn.example.com」であると想定する可能性があります。誤解を招く URI はユーザーに対する攻撃となる可能性があり、ユーザーの先入観を攻撃します。ソフトウェア自体に関しては、URI の個々のコンポーネントを区別することで、このような攻撃を回避できます。
 JinseFinance
JinseFinance
 Miyuki
Miyuki Blockworks
Blockworks CryptoSlate
CryptoSlate Bitcoinist
Bitcoinist