カマラ・ハリス、Polymarketの大統領選賭けオッズでトランプに並ぶ
Polymarketの大統領選ベッティングプールでは、カマラ・ハリスとドナルド・トランプが49%で並んだ。
 ZeZheng
ZeZheng

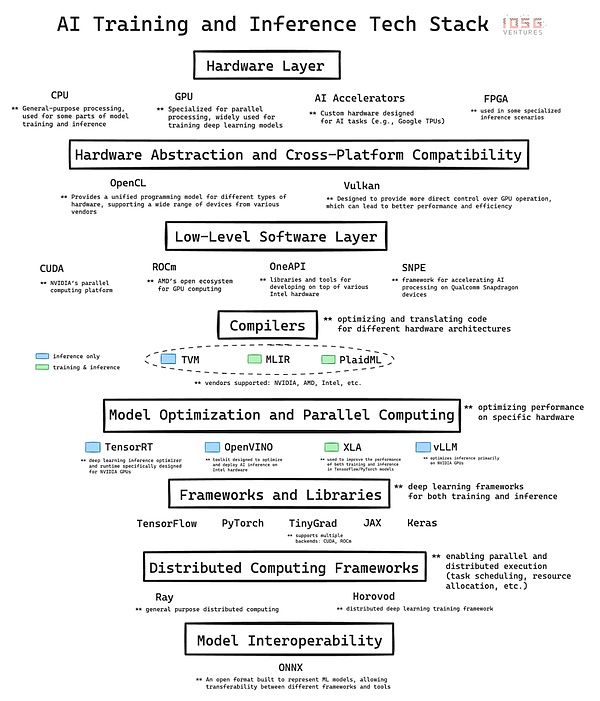
AIの急成長は複雑なインフラに基づいている。テクノロジー・スタックとは、現在のAI革命のバックボーンとなっている、ハードウェアとソフトウェアの階層化されたアーキテクチャのことである。ここでは、テクノロジー・スタックの主要レイヤーを詳細に分析し、AIの開発と実装における各レイヤーの貢献について詳しく説明する。最後に、特にDePIN(Decentralised Physical Infrastructure)プロジェクトやGPUネットワークなど、暗号通貨とAIが交差する機会を評価する際に、これらの基礎を習得することの重要性について考えます。

階層の一番下にあるのがハードウェアで、AIのための物理的な計算能力を提供します。
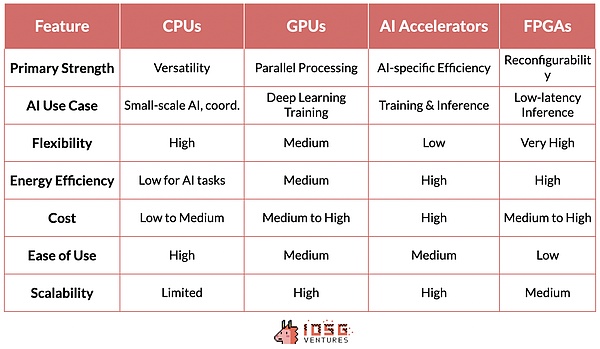
CPU(中央演算処理装置):コンピューティングの基本プロセッサーです。シーケンシャルなタスクに特化しており、データの前処理、小規模なAIタスク、他のコンポーネントの調整など、汎用コンピューティングにとって重要です。
GPU(グラフィックス・プロセッサー):もともとはグラフィックス・レンダリングのために設計されましたが、多数の単純な計算を同時に実行できるため、AIにとって重要な役割を果たすようになりました。この並列処理能力により、GPUはディープラーニングモデルのトレーニングに理想的に適しており、最新のGPTモデルはGPUの開発なしでは実現できなかったでしょう。
AIアクセラレーター:一般的なAI演算用に最適化されたAIワークロード専用に設計されたチップで、トレーニングや推論タスクに高いパフォーマンスとエネルギー効率を提供します。
FPGA(プログラマブル・アレイ・ロジック):再プログラム可能な性質により、柔軟性を提供します。特定のAIタスク、特に低レイテンシーを必要とする推論シナリオに最適化できます。

2.CUDA、ROCm、OneAPI、SNPEなどのテクノロジーは、高度なフレームワークと特定のハードウェア・アーキテクチャの間の接続を強化し、パフォーマンスの最適化を可能にします。
NVIDIA独自のソフトウェア層として、CUDAはAIハードウェア市場における同社の台頭の礎石となっており、NVIDIAのリーダーとしての地位は、ハードウェアの優位性だけでなく、ソフトウェアとエコシステムの統合による強力なネットワーク効果にも根ざしています。
CUDAが非常に影響力があるのは、AIテクノロジースタックに深く統合されており、この分野のデファクトスタンダードとなっている最適化ライブラリ一式を提供しているからです。このソフトウェア・エコシステムは、強力なネットワーク効果を構築します。CUDAに精通したAI研究者や開発者は、トレーニング中にその使用を学界や産業界に広めます。
その結果、CUDAベースのツールとライブラリのエコシステムがAIの実務家にとってますます不可欠になり、NVIDIAの市場リーダーシップが強化されるという好循環が生まれます。
このハードウェアとソフトウェアの共生は、AIコンピューティングの最前線におけるNVIDIAの地位を確固たるものにするだけでなく、コモディティ化しがちなハードウェア市場では珍しい、大きな価格決定力をNVIDIAに与えます。
CUDAの優位性と競合他社の相対的な知名度の低さは、参入に大きな障壁を作り出した多くの要因に起因しています。NVIDIAがGPUアクセラレーション・コンピューティングで先行者利益を得たことで、CUDAは競合他社が足場を築く前に強力なエコシステムを構築することができました。AMDやIntelなどの競合他社は優れたハードウェアを持っていますが、ソフトウェア層には必要なライブラリやツールが不足しており、既存の技術スタックとシームレスに統合されていません。

TVM(テンソル仮想マシン)、MLIR(多層中間表現)、およびPlaidMLは、複数のハードウェア・アーキテクチャにわたってAIワークロードを最適化するという課題に対する異なるソリューションを提供します。
ワシントン大学の研究から生まれたTVMは、高性能GPUからリソースに制約のあるエッジデバイスまで、幅広いデバイス向けに深層学習モデルを最適化する能力で、急速に支持を集めています。その強みは、推論シナリオで特に効果を発揮するエンドツーエンドの最適化プロセスにある。これは、基礎となるベンダーやハードウェアの違いを完全に抽象化し、NVIDIAデバイスであろうと、AMD、Intelなどであろうと、異なるハードウェア上で推論ワークロードをシームレスに実行できるようにします。
しかし、推論を超えると、状況はより複雑になり、AIトレーニングのためのハードウェア代替コンピューティングの最終的なゴールは未解決のままです。しかし、この点に関しては、注目に値する取り組みがいくつかあります。
グーグルのプロジェクトであるMLIRは、より基本的なアプローチを取っています。複数の抽象レベルに対して統一された中間表現を提供することで、推論とトレーニングのユースケースをターゲットとするコンパイラ・インフラ全体を簡素化することを目的としています。
現在インテルが主導するPlaidMLは、このレースのダークホースとして位置づけられています。
PlaidMLは、複数のハードウェア・アーキテクチャ(従来のAIアクセラレータ以外のものも含む)間での移植性に重点を置き、AIワークロードがあらゆる種類のコンピューティング・プラットフォーム上でシームレスに実行される未来を見据えています。
これらのコンパイラーのいずれかが、モデルの性能に影響を与えたり、開発者による追加修正を必要とすることなく、テクノロジースタックにうまく統合できれば、CUDAの堀を脅かす可能性が高くなります。しかし、MLIRとPlaidMLは現在、十分に成熟しておらず、AIテクノロジースタックにうまく統合されていないため、CUDAのリーダーシップに大きな脅威を与えることはありません。


4.align: left;">RayとHorovodは、AIにおける分散コンピューティングへの2つの異なるアプローチを表しており、それぞれが大規模なAIアプリケーションにおけるスケーラブルな処理の重要なニーズに対応しています。
UCバークレーのRISELabによって開発されたRayは、汎用分散コンピューティングフレームワークです。柔軟性に優れており、機械学習以外にもさまざまな種類のワークロードを分散させることができます。Rayのアクターベースのモデルは、Pythonコードの並列化を大幅に簡素化するため、複雑で多様なワークフローを必要とする強化学習やその他のAIタスクに特に適しています。
HorovodはもともとUberによって設計されたもので、ディープラーニングの分散実装に焦点を当てています。Horovodのハイライトは、TensorFlowやPyTorchなどの主流のディープラーニングフレームワークとシームレスに統合できる使いやすさと、ニューラルネットワークデータの並列トレーニングの最適化です。これにより、開発者は大規模なコード変更を行うことなく、既存のトレーニングコードを簡単に拡張することができます。

既存のAIスタックとの統合は、分散コンピューティングシステムの構築を目指すDePinプロジェクトにとって極めて重要です。この統合により、現在のAIワークフローやツールとの互換性が確保され、採用への障壁が低くなります。
暗号通貨空間では、基本的に分散型GPUレンタルプラットフォームである現在のGPUネットワークは、より複雑な分散型AIインフラへの初期段階を示しています。これらのプラットフォームは、分散型クラウドとして稼働しているというよりも、Airbnbスタイルのマーケットプレイスに近い。一部のアプリケーションには有用ですが、これらのプラットフォームは、大規模なAI開発を進めるための重要な要件である、真の分散トレーニングをサポートするには十分ではありません。
RayやHorovodのような現在の分散コンピューティング標準は、グローバルな分散ネットワーク用に設計されておらず、真に機能する分散ネットワークのためには、このレイヤーの上に別のフレームワークを開発する必要がある。Transformerモデルは、学習過程で集中的な通信とグローバル関数の最適化を必要とするため、分散学習手法とは相容れないと主張する懐疑論者さえいる。一方、楽観主義者たちは、グローバルに分散したハードウェアでうまく機能する新しい分散コンピューティングフレームワークを考え出そうとしている。
NeuroMeshはさらに進んでいる。特に革新的な方法で機械学習プロセスを再設計している。予測符号化ネットワーク(PCN)を使用して、大域的な損失関数の最適解に直接向かうのではなく、局所的な誤差最小化の収束を見つけることで、NeuroMeshは分散AIトレーニングにおける根本的なボトルネックを解決します。
このアプローチは、前例のない並列化を可能にするだけでなく、RTX 4090のようなコンシューマー向けGPUハードウェアでモデルをトレーニングできるようにすることで、AIトレーニングの民主化を実現します。具体的には、4090 GPUはH100と同程度の計算能力を備えていますが、帯域幅が不十分なため、モデルのトレーニング中に十分に活用されていません。PCNは帯域幅の重要性を低減するため、これらのローエンドGPUを活用することが可能になり、大幅なコスト削減と効率化につながる可能性があります。
もう1つの野心的な暗号AIのスタートアップであるGenSynは、コンパイラスイートの構築を目指しています。Gensynのコンパイラは、あらゆるタイプの計算ハードウェアをAIワークロードにシームレスに使用できるようにします。例えるなら、TVMが推論に有用であるように、Gensynはモデルトレーニングのための同様のツールを構築しようとしている。
成功すれば、幅広いハードウェアを効率的に活用することで、より複雑で多様なAIタスクを処理できるよう、分散型AI計算ネットワークの能力を大幅に拡張できるだろう。この野心的なビジョンは、多様なハードウェア・アーキテクチャにわたって最適化することの複雑さと高い技術的リスクのために挑戦的ではあるが、もし彼らがそれを実行し、異種システム上でのパフォーマンス維持などの障害を克服することができれば、CUDAとNVIDIAの堀を弱めることができる技術である。
推論について:検証可能な推論と異種コンピューティングリソースの分散型ネットワークを組み合わせたHyperbolicのアプローチは、比較的現実的な戦略を反映しています。TVMのようなコンパイラ標準を活用することで、ハイパーボリックは性能と信頼性を維持しながら、幅広いハードウェア構成を利用することができる。コンシューマーグレードのハードウェアや高性能ハードウェアを含む、複数のベンダー(NVIDIAからAMD、Intelなど)のチップを集約することができます。
暗号-AIクロスオーバーにおけるこれらの開発は、AIコンピューティングがより分散され、効率的で、アクセスしやすくなるかもしれない未来を予告しています。これらのプロジェクトが成功するかどうかは、技術的なメリットだけでなく、既存のAIワークフローとシームレスに統合し、AI実務者や企業の実用的な懸念に対処できるかどうかにかかっています。
Polymarketの大統領選ベッティングプールでは、カマラ・ハリスとドナルド・トランプが49%で並んだ。
ZeZheng予測市場最大の投資家であるパラファイ・キャピタルによれば、初めてのユーザーは選挙に関係のない市場に参加することがほとんどだという。
 JinseFinance
JinseFinance暗号予測プラットフォームは爆発的な規模拡大を遂げており、今後も高い成長率を維持すると予想されている。
JinseFinanceバイデン大統領は、ラスベガスを旅行中にコビッドの陽性反応が出た。
 WenJun
WenJunPolymarket、7月に1億1640万ドルの取引記録を更新、米選挙ベットが牽引。ネイト・シルバーの顧問就任は、市場の影響力が高まる中、予測精度を高めるのが狙い。
 Hafiz
Hafiz予測市場は、将来の結果に関する知識を持つ誰もが、ベットという形でその知識を提供できるオープンな市場である。
JinseFinance11月の米大統領選後、ポリマーケットが大きく衰退すると多くの人が予測している。
JinseFinanceETHETF成立への期待が高まる中、市場の関心は徐々にEVMエコシステムに戻りつつあり、現在チェーン上で最大の予測市場であるPolymarketは、ETHETF成立の成功により脚光を浴びている。
JinseFinancePyth,Pythガバナンス・システム投票ガイド ゴールデンファイナンス,投票をお願いします!
JinseFinanceFTXの元CTOがFTXの保険ファンドの操作を暴露、実際のFTTトークンがなく、虚偽の説明だったと主張。
 Bitcoinworld
Bitcoinworld