米国、AIチップの輸出規制を強化 バイデン氏退任の最終日に新たな規制を1月10日までに導入か
バイデン政権は退任前にAIチップの輸出規制を強化しようとしており、早ければ金曜日にも世界的な半導体貿易を制限する新たな規制が導入される見込みだ。
 Catherine
Catherine

この調査の目的は、開発者にとってAIのどの分野が最も重要なのか、また、Web3とAIの分野で次に爆発的に普及する可能性があるのは何なのかを探ることです。
私たちの新しい研究洞察を共有する前に、私たちは RedPill の合計500万ドルの資金調達の最初のラウンドに参加できたことに興奮しています。strong>RedPill とともに成長することを楽しみにしています!

TL;DR
Web3とAIの組み合わせが暗号通貨コミュニティで注目される中、暗号の世界ではAIのインフラ構築がブームとなっているが、実際にAIを使って、あるいはAIのために構築されたアプリはそれほど多くなく、AIインフラの均質化という問題が徐々に明らかになってきている。最近、我々が参加したRedPillの最初の資金調達ラウンドは、いくつかの深い理解を呼び起こした。
AI Dappsを構築するための主なツールには、分散型OpenAIアクセス、GPUネットワーク、推論ネットワーク、エージェントネットワークなどがあります。
GPUネットワークが「ビットコインマイニング時代」よりもホットになっている理由は、AI市場がはるかに大きく、急速かつ着実に成長していること、AIが毎日何百万ものアプリをサポートしていること、AIが幅広いGPUモデルとサーバーを必要としていること、です。AIは多種多様なGPUモデルとサーバーロケーションを必要とし、テクノロジーはかつてないほど成熟し、顧客基盤はより広範になっています。
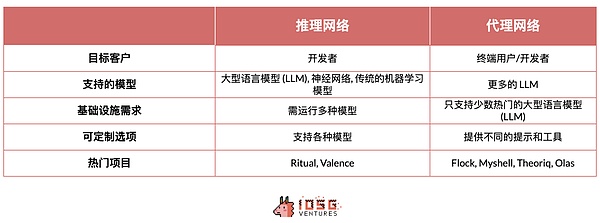
推論ネットワークとエージェント・ネットワークは、インフラは似ていますが、焦点は異なります。推論ネットワークは主に経験豊富な開発者が独自のモデルを展開するためのもので、非LLMモデルを実行するために必ずしもGPUを必要としません。エージェントネットワークはよりLLMに重点を置いたもので、開発者は独自のモデルを持ち込む必要がなく、キューエンジニアリングと異なるエージェントをどのように連携させるかに重点を置いています。
AIインフラストラクチャ・プロジェクトは多くのことを約束し、まだ新しい機能を展開しています。
ほとんどのネイティブ暗号化プロジェクトはまだテストネットの段階にあり、安定性が低く、複雑な構成で、機能が限られており、セキュリティとプライバシーを証明するにはまだ時間が必要です。
仮にAI Dappsがメガトレンドになると仮定すると、監視、RAG関連インフラ、Web3ネイティブモデル、暗号化ネイティブAPIとデータを組み込んだ分散エージェント、評価ネットワークなど、未開拓の分野がたくさんあります。
垂直統合は注目すべき傾向です。インフラプロジェクトは、AI Dapp開発者の作業を簡素化するために、ワンストップショップを提供しようとしています。
将来はハイブリッドになるでしょう。推論の一部はフロントエンドで行われ、一部はチェーン上で計算されるため、コストと検証可能性を考慮することができます。
Source: IOSG
はじめに
Web3とAIの組み合わせは、今日の暗号で最も話題になっているトピックの1つです。才能ある開発者たちは、暗号世界のためにAIインフラを構築し、スマートコントラクトにインテリジェンスをもたらそうとしています。AI dAppsの構築は非常に複雑な作業であり、開発者はさまざまなデータ、モデル、計算能力、運用、デプロイメント、ブロックチェーンとの統合に取り組んでいる。こうしたニーズに応えるため、ウェブ3の創設者たちは、GPUネットワーク、コミュニティ・データのラベリング、コミュニティで訓練されたモデル、検証可能なAIの推論と訓練、エージェント・ショップなど、多くの初期ソリューションを開発した。
そして、この活況を呈するインフラを背景に、実際にAIを活用したり、AIのために構築されたアプリは多くありません。AI dApp開発のチュートリアルを探している開発者は、ネイティブの暗号AIインフラに関連するものがあまりなく、そのほとんどがフロントエンドでOpenAI APIを呼び出すことしか扱っていないことに気づきました
ソース: IOSG Ventures
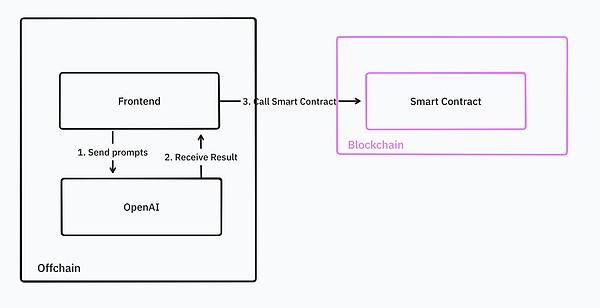
現在、アプリケーションはブロックの利点をフルに活用できていません。アプリケーションは、ブロックチェーンの分散型かつ検証可能な特徴を十分に活用できていませんが、それもすぐに変わるでしょう。ほとんどの暗号に特化したAIインフラは現在、テストネットワークを立ち上げており、今後6カ月以内に稼働する予定です。
この研究では、暗号空間のAIインフラで利用可能な主なツールについて詳しく説明します。暗号世界におけるGPT-3.5の瞬間に備えましょう!

前述したように私たちが投資しているRedPillは、素晴らしい導入ポイントです。
OpenAIにはGPT-4-vision、GPT-4-turbo、GPT-4oといった世界トップクラスの強力なモデルがあり、高度なAI Dappsを構築するのに優れています。
開発者は、述語またはフロントエンドのインターフェイスを介して呼び出すことで、OpenAIのAPIをdAppsに統合することができます。
RedPillは、さまざまな開発者のOpenAI APIを単一のインターフェースの下に統合することで、トップAIモデルリソースへのアクセスを民主化し、高速で手頃な価格の検証可能なAIサービスを世界中のユーザーに提供します。APIリクエストは、OpenAIからの可能な制限をバイパスして、その配布ネットワークを通じて実行され、以下のような暗号開発者が直面するいくつかの一般的な問題を解決します。制限付きTPM(トークン・パー・ミニッツ):新しいアカウントでは、人気のあるAI依存のdAppsのトークンへのアクセスが制限されています。
アクセス制限:新しいアカウントや特定の国へのアクセスに制限を設けているモデルもあります。
同じリクエストコードを使用してホスト名を変更することで、開発者はOpenAIのモデルに安価に、高いスケーラビリティで、制限なくアクセスすることができます。


OpenAIのAPIを使用することに加えて、多くの開発者は自宅でモデルをホストすることを選択します。彼らは、io.net、Aethir、Akash、およびその他の一般的なネットワークなどの分散 GPU ネットワークを利用して、独自の GPU クラスターをセットアップし、さまざまな強力な内部モデルまたはオープン ソース モデルを展開して実行することができます。
これらのような分散型GPUネットワークは、個人または小規模のデータセンターの計算能力を活用することができ、柔軟な構成、より多くのサーバー場所の選択肢、および低コストを提供し、開発者が限られた予算でAI関連の実験を行うことを容易にします。しかし、分散型であるため、このようなGPUネットワークには、機能性、可用性、データプライバシーの点で限界があります。
GPUの需要はここ数カ月で爆発的に増加しており、以前のビットコインの採掘ブームを上回っています。その理由は以下の通りです。
ターゲットとする顧客が増加し、GPUネットワークは現在、AI開発者にサービスを提供しています。彼らは数が多いだけでなく、より忠実で、暗号通貨価格の変動の影響を受けにくくなっています。
分散型GPUは、マイニング専用デバイスよりも幅広いモデルと仕様を提供し、プレイスニーズの要件により適しています。特に、大規模なモデル処理にはより高いVRAMが必要ですが、小規模なタスクにはより適したGPUが利用できます。同時に、分散型GPUは地上に近いエンドユーザーにサービスを提供できるため、待ち時間が短縮されます。
テクノロジーは成熟しつつあり、GPUネットワークはSolana決済、Docker仮想化、Rayコンピュートクラスタなどの高速ブロックチェーンに依存しています。
投資収益率という点では、AI市場は拡大しており、新しいアプリやモデルの開発には多くの機会があります。H100モデルは60~70%の期待収益をもたらしますが、ビットコインマイニングはより複雑で、勝者総取りのシナリオがあり、生産量も限られています。
また、Iris Energy、Core Scientific、Bitdeerなどのビットコインマイニング企業も、GPUネットワークをサポートし、AIサービスを提供し始め、H100のようなAI用に設計されたGPUを積極的に購入しています
おすすめポイント SLAをあまり重視しないWeb2開発者にとって、io.netはクリーンで使いやすいエクスペリエンスを提供し、費用対効果の高い選択肢です。strong>
これは暗号ネイティブAIインフラの中核です。将来的には、何十億ものAI推論操作をサポートすることになるでしょう。多くのAIレイヤー1またはレイヤー2は、AI推論をオンチェーンでネイティブに呼び出す機能を開発者に提供している。
これらのネットワークは以下の点で異なります:
パフォーマンス(待ち時間、計算時間)
サポートされるモデル
検証可能性
開発経験
理想的には、開発者は、統合プロセスにほとんど支障をきたすことなく、どこからでも、どのような証明形式でも、カスタムAI推論サービスに簡単にアクセスできるようになります。
推論ネットワークは、オンデマンドでの証明の生成と検証、推論計算の実行、推論データの中継と検証、Web2およびWeb3へのインターフェースの提供、ワンクリックでのモデル展開、システム監視、クロスチェーン操作、同期された統合、時間指定された実行など、開発者が必要とするすべての基本的なサポートを提供します。
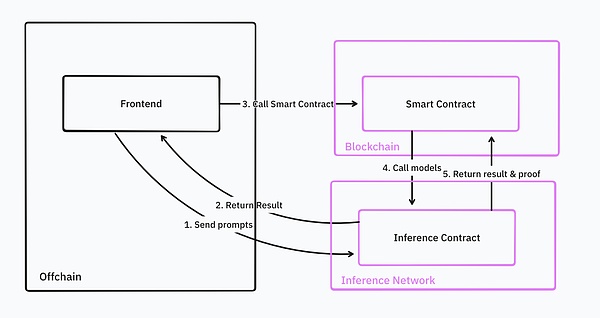
ソース: IOSG。 Ventures
これらの機能により、開発者は推論サービスを既存のスマートコントラクトにシームレスに統合することができます。例えば、DeFi取引ボットを構築する場合、これらのボットは機械学習モデルを使用して、特定のペアの売買タイミングを見つけ、基礎となる取引プラットフォーム上で対応する取引戦略を実行します。
完全に理想的な世界では、インフラはすべてクラウドホスティングされます。開発者は取引戦略モデルをtorchのような一般的なフォーマットでアップロードするだけで、推論ネットワークはWeb2やWeb3のクエリ用にモデルを保存し、提供します。
すべてのモデル展開ステップが完了した後、開発者はWeb3 APIまたはスマートコントラクトを通じて直接モデル推論を呼び出すことができます。推論ネットワークはこれらの取引戦略を継続的に実行し、その結果を基礎となるスマート・コントラクトにフィードバックする。開発者が大量のコミュニティ資金を管理する場合、推論結果の検証を提供する必要もある。推論結果を受け取ると、スマートコントラクトはその結果に基づいて取引を行う。
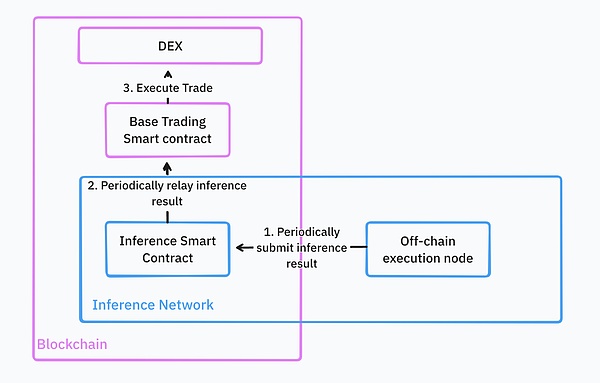
ソース: IOSG Ventures
3.1.1 Asynchronous vs. Synchronous
理論的には、非同期の推論操作はパフォーマンスが向上します。理論的には、非同期推論操作はより良いパフォーマンスにつながります。
非同期アプローチを使用する場合、開発者は最初に推論ネットワークのスマートコントラクトにタスクを提出する必要があります。推論タスクが完了すると、推論ネットワークのスマートコントラクトは結果を返します。このプログラミングモデルでは、ロジックは推論呼び出しと推論結果処理の2つに分けられる。
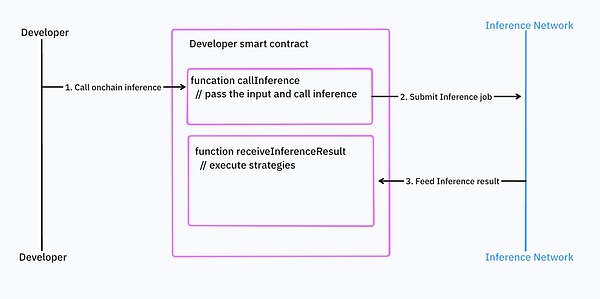
ソース: IOSG Ventures
開発者が推論呼び出しを入れ子にして、制御ロジックをたくさん持っていると、さらに悪化します。
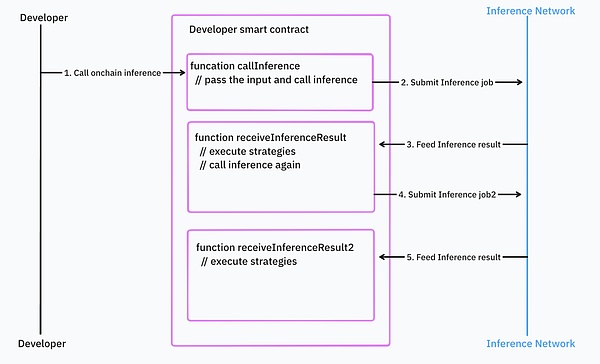
ソース: IOSG。 Ventures
非同期プログラミングモデルは、既存のスマートコントラクトとの統合を難しくしている。開発者は、エラー処理や依存関係の管理で多くの余分なコードを書く必要があります。
対照的に、同期プログラミングは開発者にとってより直感的ですが、応答時間やブロックチェーンの設計に問題が生じます。例えば、入力データがブロック時間や価格のように動きの速いものである場合、推論が完了した後のデータはもはや新鮮ではなく、特定の状況でスマートコントラクトの実行をロールバックする必要性につながる可能性がある。古い価格で取引を行ったとします。
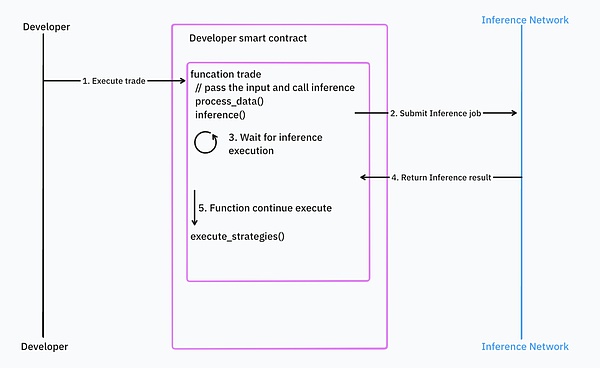
ソース: IOSG Ventures
ほとんどのAIインフラは非同期処理を使用していますが、Valenceはこれらの問題に対処しようとしています。
実は、新しい推論ネットワークの多くは、Ritualネットワークなど、まだベータ版です。彼らの公開文書によると、これらのネットワークは、現時点では機能が限られています(検証や証明などの機能はまだ稼働していません)。彼らは現在、オンチェーンでのAI計算をサポートするクラウドインフラを提供する代わりに、セルフホスト型のAI計算とチェーンへの結果配信のためのフレームワークを提供している。
これがAIGCのNFTを実行するアーキテクチャだ。
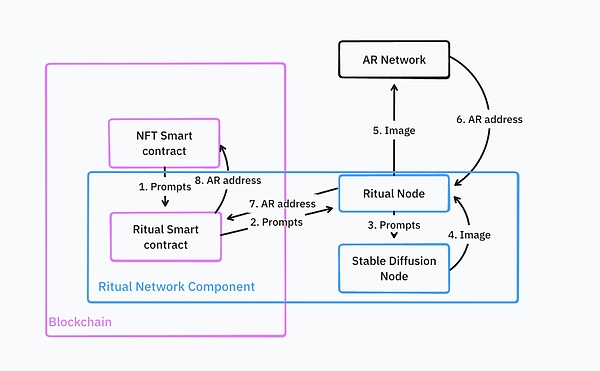
拡散モデルがNFTを生成し、Arweaveにアップロードします。 推論ネットワークは、このArweaveのアドレスを使用して、NFTをチェーン上にキャストします。
Source: IOSG Ventures
これは非常に複雑なプロセスであり、開発者は、カスタマイズされたサービスを持つRitualノードなど、インフラのほとんどを自分でデプロイし、維持する必要があります。カスタムサービスロジックを持つRitualノード、Stable Diffusionノード、NFTスマートコントラクトなどです。
推奨:現在の推論ネットワークは、カスタムモデルを統合して展開するのが複雑で、現段階では検証をサポートしていないものがほとんどです。AI技術をフロントエンドに適用すれば、開発者にとって比較的シンプルなオプションを提供できるだろう。検証の必要性が高いのであれば、ZKMLプロバイダーのGizaは良い選択です。

5.strong>
プロキシ・ネットワークは、ユーザーがプロキシを簡単にカスタマイズできるようにします。このようなネットワークは、自律的にタスクを実行し、互いに相互運用し、ブロックチェーンネットワークと相互作用することができるエンティティやスマートコントラクトで構成され、すべて人間が直接介入することなく行うことができます。これは主にLLM技術を対象としている。例えば、イーサに関する洞察を提供するGPTチャットボットを提供することができる。このチャットボットには現在、より限定的なツールがあり、開発者はまだそれをベースに複雑なアプリケーションを開発することはできない。
ソース: IOSG Ventures
しかし将来的には、エージェントネットワークは、知識だけでなく、外部APIを呼び出したり、特定のタスクを実行したりする機能など、エージェントが使用できるツールをさらに提供するようになるでしょう。開発者は複数のエージェントを接続してワークフローを構築できるようになる。たとえば、Solidityスマートコントラクトを書くには、プロトコル設計エージェント、Solidity開発エージェント、コードセキュリティレビューエージェント、Solidityデプロイエージェントなど、複数の専門エージェントが必要です。出典: IOSG ベンチャーズ
ヒントとシナリオを使用して、これらのエージェントの協力を編成します。
エージェントネットワークの例としては、Flock.ai、Myshell、Theoriqなどがあります。
推奨:今日のエージェントのほとんどは、比較的限定的です。比較的限られています。

エージェントネットワークはLLMに重点を置いており、以下のようなツールを提供しています。複数のプロキシを統合するツールなどです。多くの場合、開発者自身が機械学習モデルを開発する必要はない。エージェントネットワークは、モデル開発とデプロイのプロセスを簡素化した。必要なエージェントとツールをリンクさせるだけでよい。ほとんどの場合、エンドユーザーはこれらのエージェントを直接使用する。
一方、推論ネットワークは、エージェントネットワークのインフラ的なバックボーンである。これは開発者により低いレベルのアクセスを提供します。通常、エンドユーザーは推論ネットワークを直接使用することはない。開発者は、LLMに限定されない独自のモデルを展開する必要があり、オフチェーンまたはオンチェーンのアクセスポイントを通じて使用することができます。
プロキシ・ネットワークと推論ネットワークは完全に別の製品というわけではありません。
プロキシ・ネットワークと推論ネットワークは完全に独立した製品ではありません。
エージェント機能と推論機能の両方を提供し、両方の機能が同様のインフラに依存しているからです。

モデル推論、トレーニング、エージェントネットワークに加えて、ウェブ3の領域には、探索する価値のある多くの新しい分野があります。機械学習に使えるデータセットに変えるには?機械学習の開発者は、より具体的でテーマ性のあるデータを必要としている。例えば、GizaはDeFi上で機械学習のトレーニングに特化した高品質なデータセットを多数提供している。理想を言えば、データは単純な表データにとどまらず、ブロックチェーンの世界での相互作用を描いたグラフデータを含むべきです。現在のところ、この分野では不足している。現在、個人データのプライバシー保護を約束するBagelやSaharaのように、新しいデータセットを作成した個人に報酬を与えることでこれに取り組んでいるプロジェクトもある。
モデルの保存:モデルの中には膨大なものもあり、それらをどのように保存、分散、バージョン管理するかが、チェーン上の機械学習のパフォーマンスとコストの鍵を握っています。Filecoin、AR、0gのような先駆的なプロジェクトは、この分野で進歩を遂げています。
モデル学習:分散された検証可能なモデル学習は課題であり、Gensyn、Bittensor、Flock、Alloraから注目すべき進歩がありました。
モニタリング:モデルの推論はオンチェーンでもオフチェーンでも行われるため、web3の開発者がモデルの使用状況を追跡し、潜在的な問題や偏りを特定するための新しいインフラが必要です。適切な監視ツールがあれば、web3の機械学習開発者は、モデルの精度を継続的に最適化するために、タイムリーな調整を行うことができます。
RAGインフラ:分散RAGは、データのプライバシーとセキュリティを確保しつつ、ストレージ、組み込みコンピューティング、ベクトルデータベースに対する高い要求を備えた、まったく新しいインフラ環境を必要とします。
Models customised for Web3: すべてのモデルがWeb3に適しているわけではありません。すべてのモデルがWeb3のシナリオに適しているわけではありません。ほとんどの場合、モデルは価格予測やレコメンデーションなど、特定の用途向けに再トレーニングする必要があります。AIインフラがブームになるにつれて、将来的には、AIアプリケーションに対応するWeb3ネイティブモデルが増えることが予想される。例えば、Pondは、価格予測、レコメンデーション、詐欺検出、アンチマネーロンダリングなど、様々なシナリオのためのブロックチェーンGNNを開発している。
ネットワークの評価:人間のフィードバックがない状態でエージェントを評価するのは簡単ではありません。エージェント作成ツールが普及すれば、無数のエージェントが市場に出回ることになります。そのため、これらのエージェントの能力を実証し、ユーザーが与えられた状況でどのエージェントが最もうまく機能するかを判断できるようなシステムが必要になります。例えば、Neuronetsはこの分野のプレーヤーです。
Consensus Mechanisms: AIタスクの場合、PoSが常に最良の選択というわけではありません。計算の複雑さ、検証の難しさ、確実性の欠如が、PoSが直面する主な課題です。 Bittensorは、機械学習モデルと出力への貢献に対してネットワーク内のノードに報酬を与える、新しいインテリジェントなコンセンサスメカニズムを作成しました。

現在、垂直統合の傾向が見られます。基礎となる計算レイヤーを構築することで、ウェブは、トレーニング、推論、エージェントウェブサービスを含む、幅広い機械学習タスクのサポートを提供することができます。このモデルは、Web3の機械学習開発者のための包括的なワンストップ・ソリューションとなることを意図しています。
現在、オンチェーン推論はコストと時間がかかるものの、優れた検証可能性とスマートコントラクトなどのバックエンドシステムとのシームレスな統合を提供しています。私は、将来はハイブリッド・アプリケーションの道に進むと思う。推論処理の一部はフロントエンドやオフチェーンで行われ、重要な意思決定を行う推論はオンチェーンで行われる。このモデルはすでにモバイル・デバイスで使われている。モバイル機器の性質を利用することで、小さなモデルをローカルで素早く実行し、より複雑なタスクをクラウドに移行し、より大規模なLLM処理を利用することができる。
バイデン政権は退任前にAIチップの輸出規制を強化しようとしており、早ければ金曜日にも世界的な半導体貿易を制限する新たな規制が導入される見込みだ。
Catherineカザフスタンは、金融犯罪撲滅に向けた大規模な取り組みの一環として、36の違法暗号取引所を閉鎖し、480万ドルの資産を押収した。政府はまた、暗号関連のマネーロンダリングやマルチ商法を防止するための規制を強化している。
 Anais
Anais韓国の金融委員会は、2024年に仮想資産利用者保護法が成立した後、非営利団体を始めとする機関投資家の暗号取引に対する規制を緩和している。同国はまた、2025年に20%の暗号税を導入し、暗号ETFとセキュリティトークンを模索して市場参加を促進する計画だ。
 Weatherly
WeatherlyPolymarketがカリフォルニアの山火事に関するベットを可能にしたことで反発に直面し、災害から利益を得ることへの倫理的懸念が高まっている。さらに悪いことに、AIのディープフェイクの出現は、誤った情報をさらに広めている。悲劇はエンターテイメントになりつつあるのだろうか?
CatherineCircleの$1M USDCの寄付は、Ripple、Coinbase、Kraken、Ondo Financeに加わり、トランプの就任資金を後押しし、政治における安定したコインの役割の高まりを強調している。トップドナーたちは独占的な特典を確保しており、次に寄付するのは誰だろうか?
 Kikyo
KikyoMastercardはUAEとカザフスタンでCrypto Credentialサービスを開始し、複雑なウォレット・アドレスの代わりに安全なエイリアスを使用することで、暗号通貨取引を簡素化した。
AnaisNansenは、Telegramが開発した高性能レイヤー1であるTON Blockchainと提携し、洞察力を高め、イノベーションを促進し、Web3の導入を加速させる高度な分析ツールを導入する。次はどのような新しいツールが登場するのだろうか?
Catherineスタンダード・チャータードは、欧州の機関投資家向けに、ビットコインとイーサを中心としたデジタル資産のカストディ・サービスをルクセンブルグで開始した。
Weatherlyティム・スコット上院議員率いる米上院銀行委員会が、史上初の暗号通貨小委員会を設置することになった。これはトランプ大統領の就任直前のことで、トランプ大統領は暗号通貨規制推進策を打ち出すと見られている。
KikyoテザーはAI映像制作に進出し、専門家を雇用し、2025年半ばまでにチームを200人に増やす計画だ。同社はまた、拡張性と技術を強化するため、AIとクラウドコンピューティングに投資している。
Anais