V-God Vernacularが称賛するFHE完全同型暗号、その応用可能性を解き明かす
完全同形暗号化(FHE)の入門書。そのエキサイティングなアプリケーション、制限、そしてその人気を牽引する最新動向を探る。
 JinseFinance
JinseFinance

プリンストン大学のフェイフェイ・リー助教授がImageNetを作ろうと思ったときのデータセットのサイズは、これくらいだった。彼女はこのデータセットが、停滞しているコンピュータ・ビジョンの分野を発展させる一助になることを期待していた。22,000のカテゴリは、これまでに作成されたどの画像データセットよりも少なくとも2桁多い。
より優れたAIシステムを構築するための答えはアルゴリズムの革新にあると信じていた同僚たちは、彼女の知恵に疑問を投げかけた。"同僚とイメージネットのアイデアを議論すればするほど、孤独を感じました。"
懐疑的な見方にもかかわらず、フェイフェイと彼女の小さなチーム(博士号候補のジア・デンと時給10ドルの学部生数人を含む)は、検索エンジンから画像のラベル付けを始めた。を開始した。進捗は遅々として進まず、ジア・デンは、このままではイメージネットを完成させるのに18年はかかると見積もっていた。そんな時、修士課程の学生の一人が、フェイフェイにアマゾンのメカニカルタークを紹介した。菲菲はすぐに、これこそが自分たちが必要としているものだと気づいた。
2009年、菲菲が彼女の人生で最も重要なプロジェクトを始めてから3年後、分散化されたグローバルな労働力の助けを借りて、ImageNetはついに準備が整った。彼女は、コンピュータビジョンの共通の使命を前進させるために、自分の役割を果たしたのです。
現在は、この巨大なデータセットを使って、コンピュータが人間と同じように世界を見るためのアルゴリズムを開発する研究者の番だ。しかし、最初の2年間はそうはならなかった。アルゴリズムは、ImageNetの以前の状態よりもかろうじて良い結果を出しただけだった。
フライは、彼女の同僚がImageNetは無駄な試みだと言っていたのは正しかったのではないかと思い始めた。
そして2012年8月、菲菲が自分のプロジェクトが彼女の思い描く変化を促すという希望を捨てていた矢先、賈登がAlexNetについて熱心に電話で教えてくれた。ImageNetで訓練されたこの新しいアルゴリズムは、歴史上のあらゆるコンピュータビジョンアルゴリズムを凌駕している。トロント大学の3人の研究者によって作成されたAlexNetは、「ニューラルネットワーク」と呼ばれる、ほぼ放棄されたAIアーキテクチャを使用しており、Feifeiの想像を超えるものでした。
その瞬間、彼女は自分の努力が実を結んだことを知った。"歴史が作られたばかりなのに、それを知っているのは世界でほんの数人だけだった" フェイフェイ・リーは回顧録『The World I Saw』の中で、イメージネットの裏話を語っている。
ImageNetとAlexNetの組み合わせは、いくつかの理由から歴史的なものです。
第一に、長らく行き詰まり技術だと考えられていたニューラルネットワークの再参照が、10年以上にわたるAIの飛躍的成長を牽引してきたアルゴリズムの背後にある実際のアーキテクチャとなったことです。
第二に、トロントの3人の研究者(そのうちの1人は、イリヤ・スッツケバーという名前を聞いたことがあるかもしれません)が、AIモデルの学習にグラフィック・プロセッシング・ユニット(GPU)を初めて使用したことです。今では業界標準となっている。
第三に、AI業界は、何年も前にフェイフェイが最初に主張したこと、つまり高度なAIのための重要な要素は大量のデータであることに、ようやく気づきつつあります。
私たちは皆、「データは新しい石油である」や「ゴミを捨て、ゴミを入れる」といったことわざを数え切れないほど読んだり聞いたりしてきました。数え切れないほどだ。もしそれが私たちの世界に関する基本的な真実でなかったら、私たちはおそらくうんざりしていただろう。長年にわたり、人工知能は舞台裏で働き、私たちの生活のますます重要な一部となっている。私たちが読むツイート、見る映画、支払う価格、そして私たちが価値があるとみなされる信用に影響を与える。これらすべては、デジタル世界での私たちの一挙手一投足を注意深く追跡することによるデータ収集によって推進されている。
しかし、比較的無名のスタートアップであるOpenAIがChatGPTというチャットボットアプリをリリースして以来、この2年間で、AIの重要性は舞台裏から前景へと移ってきた。私たちは、機械知能が私たちの生活のあらゆる側面に浸透する入り口に立っている。誰がこのインテリジェンスをコントロールするかをめぐる競争が過熱するにつれ、その原動力となるデータの需要も高まっている。
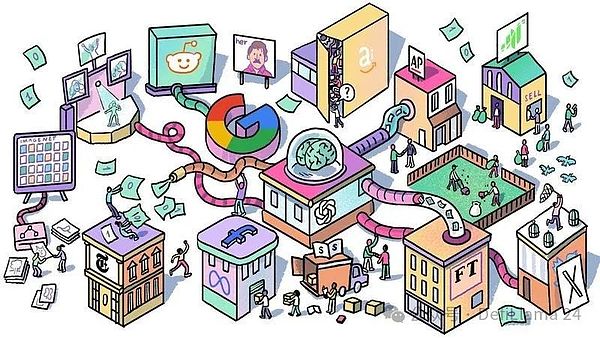
それがこの記事の主題です。私たちは、AI企業が必要とするデータの規模と緊急性、そしてそれを取得する際に直面する問題について議論しました。この飽くなきニーズが、インターネットと何十億もの貢献者に対する私たちの愛情をどのように脅かすかを探った。最後に、これらの問題や懸念に対処するために暗号通貨を利用している新興企業を紹介します。
本題に入る前にひとこと。この記事は、大規模言語モデル(LLM)のトレーニングの観点から書かれており、すべてのAIシステムについて書かれているわけではありません。このため、私はしばしば「AI」と「LLM」という言葉を同じ意味で使っています。この用法は技術的には不正確ですが、LLMの概念と問題点、特にデータに関しては、他の形式のAIモデルと同様に適用されます。
大規模な言語モデルのトレーニングは、計算、エネルギー、データという3つの主要なリソースによって制約されます。企業、政府、新興企業は同時に、大きな資本を背景に、これらのリソースをめぐって競争しています。この3つのうち、エヌビディアの株価が急上昇したこともあり、コンピュートに対する競争は最も熾烈です。
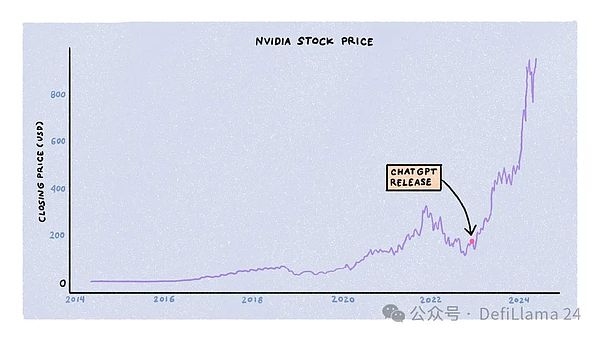
LLMのトレーニングには、専用のグラフィック処理ユニット(GPU)の大規模なクラスタが必要です。特にNVIDIAのA100、H100、そして近日発売予定のB100モデルです。これらは、アマゾンや近所のコンピューターショップですぐに買えるコンピューターではない。NVIDIAは、その供給がAIラボ、新興企業、データセンター、およびハイパースケールの顧客にどのように分配されるかを決定します。
ChatGPTがリリースされてから18カ月間、GPUの需要は供給をはるかに上回り、待ち時間は11カ月にも及んだ。しかし、当初の熱狂が収まるにつれ、需給関係は正常化しつつあります。新興企業の閉鎖、トレーニング・アルゴリズムとモデル・アーキテクチャの改善、他社からの専用チップの出現、およびNVIDIAによる生産の増加はすべて、GPUの利用可能性を高め、価格を下げることに貢献しています。
第二に、エネルギーです。データセンターでGPUを動かすには、多くのエネルギーが必要です。ある試算では、データセンターは2030年までに世界のエネルギーの4.5%を消費すると言われています。この需要の急増が既存の電力網に負担をかけるため、テック企業は代替エネルギーのソリューションを模索している。アマゾンは最近、原子力発電所を動力源とするデータセンターを6億5000万ドルで購入した。マイクロソフトは原子力技術の責任者を雇い、OpenAIのサム・アルトマンはHelion、Exowatt、Okloのようなエネルギー新興企業を支援している。
AIモデルのトレーニングという観点からすれば、エネルギーとコンピューティングは単なるコモディティだ。H100の代わりにB100を使用したり、伝統的なエネルギー源の代わりに原子力発電を使用したりすることで、トレーニング・プロセスがより安く、より速く、より効率的になるかもしれませんが、モデルの品質には影響しません。言い換えれば、最も賢く、最も人間に近いAIモデルを作成する競争において、エネルギーと計算は差別化要因ではなく、必要不可欠なものなのです。
重要なリソースはデータです。
ジェームス・ベトケ氏は、OpenAIのリサーチエンジニアである。彼自身の言葉を借りれば、彼は「誰も訓練する権利がないほど多くの生成モデル」を訓練してきた。彼はブログの投稿で、「同じデータセットで十分に長く訓練すれば、十分な重みと訓練時間を持つほぼすべてのモデルが同じ点に収束する」と指摘している。つまり、AIモデルと他のモデルを分けるものはデータセットである。他には何もない。
私たちがモデルを「ChatGPT」、「Claude」、「Mistral"または "Lambda "と呼ぶとき、私たちはアーキテクチャや使用されたGPU、消費されたエネルギーについて話しているのではなく、むしろそれがトレーニングされたデータセットについて話しているのです。
最先端の生成モデルを訓練するには、どれくらいのデータが必要なのでしょうか?
答え:たくさん。
GPT-4は、リリースから1年以上経った今でも最高の大規模言語モデルと考えられており、推定1.2兆トークン(または約9000億語)で学習されました。データは、Wikipedia、Reddit、Common Crawl(ウェブクローリングデータのフリーでオープンなリポジトリ)、100万時間以上書き起こされたYouTubeのデータ、GitHubやStack Overflowのようなコードプラットフォームなど、一般に利用可能なインターネットから得られています。
たくさんのデータだと思うかもしれないが、ちょっと待ってほしい。生成AIには「チンチラ・スケーリングの法則」と呼ばれる概念があり、与えられた計算予算では、より小さなデータセットでより大きなモデルを学習させるよりも、より大きなデータセットでより小さなモデルを学習させる方が効率的であるというものです。GPT-5やLlama-4のような次世代AIモデルを訓練するためにAI企業が割り当てる計算資源を外挿すると、これらのモデルは5~6倍の計算能力を必要とし、訓練に最大100兆トークンを使用すると予想されることがわかります。
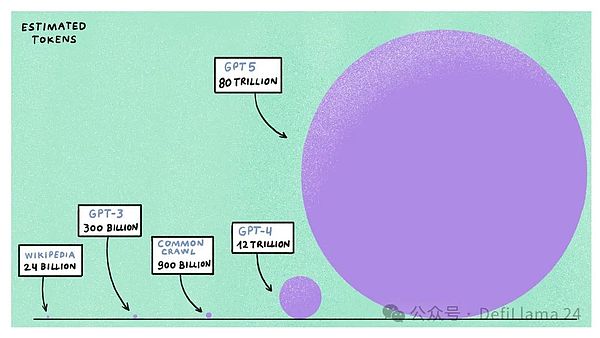
公開されているインターネットデータのほとんどはすでにクロールされ、インデックス化され、既存のモデルのトレーニングに使用されているため、これらのモデルは5~6倍の計算能力を必要とすることがわかりました。インデックスが作成され、既存のモデルのトレーニングに使用されている場合、追加のデータはどこから来るのでしょうか?これはAI企業にとって最先端の研究課題となっている。この問題へのアプローチには2つの方法がある。ひとつは、人間ではなくLLMが直接生成した合成データを使用する場合だ。しかし、モデルをより賢くするためのこのデータの有効性は検証されていない。
もう1つの選択肢は、合成的に作成されたデータではなく、単に高品質のデータを探すことです。しかし、特にAI企業が将来のモデルのトレーニングだけでなく、既存のモデルの妥当性をも脅かす問題に直面している場合、追加のデータを取得することは困難です。
最初のデータ問題は、法的な問題を含んでいる。AI企業は「一般に利用可能なデータ」でモデルを訓練すると主張していますが、その多くは著作権で保護されています。例えば、コモン・クロールのデータセットには、ニューヨーク・タイムズやAP通信などの出版物から数百万件の記事が含まれているほか、出版された書籍や歌の歌詞などの著作権で保護された素材も含まれています。
一部の出版物やクリエイターは、AI企業が著作権や知的財産を侵害しているとして、法的措置を取っている。タイムズ紙は、OpenAIとマイクロソフトを「タイムズ紙独自の貴重な作品を不法にコピーし、使用している」として提訴している。プログラマーのグループは、人気のあるAIプログラミングアシスタントであるGitHub Copilotを訓練するためにオープンソースコードを使用することの合法性に異議を唱える集団訴訟を起こした。
コメディアンのサラ・シルヴァーマンと作家のポール・トレンブレイも、自分たちの作品を無断で使用したとしてAI企業を訴えている。
AI企業と提携することで、変革の時代を受け入れている企業もある。AP通信、フィナンシャル・タイムズ、アクセル・スプリンガーはすべて、OpenAIとコンテンツライセンス契約を結んでいる。アップルは、コンデナストやNBCのような報道機関と同様の提携を模索している。グーグルは、モデルを訓練するためにレディットのAPIにアクセスするために年間6000万ドルを支払うことに合意し、スタック・オーバーフローもOpenAIと同様の契約を結んでいる。
これらのコラボレーションは、AI企業が直面している2つ目の問題、つまりオープンウェブの閉鎖と一致している。
インターネット・フォーラムやソーシャルメディア・サイトは、AI企業がモデルの訓練にプラットフォーム上のデータを使用することで生み出す価値に気づいている。グーグル(そして将来的には他のAI企業も)と契約を結ぶ前に、レディットはそれまで無料だったAPIを有料化し、人気のあったサードパーティクライアントを停止した。同様に、TwitterはAPIへのアクセスを制限し、価格を引き上げ、イーロン・マスクは自身のAI会社xAIのモデルを訓練するためにTwitterのデータを使用した。
小規模な出版物やホモエロ小説のフォーラムなど、誰もが自由にコンテンツを消費でき、(もしあったとしても)広告から利益を得ていたインターネットのニッチなコーナーでさえ、今では閉鎖され始めている。インターネットはもともと、誰もが自分のユニークな興味や奇癖を共有できる仲間を見つけられる魔法のようなサイバースペースとして構想されていた。その魔法は徐々に消えつつあるようだ。
訴訟の脅威、何百万ものコンテンツを取引する傾向の高まり、そしてオープンなウェブの閉鎖が組み合わさったことで、2つの影響がもたらされました。align: left;">第一に、データ戦争はハイテク大手に非常に偏っている。新興企業や小規模企業は、これまで利用可能だったAPIにアクセスすることも、法的リスクを負うことなく利用権を購入するために必要な資金を支払うこともできません。これは、最高のデータを購入し、最高のモデルを作成できる金持ちがより金持ちになるという明らかな集中効果をもたらす。
第二に、ユーザー生成コンテンツプラットフォームのビジネスモデルは、ユーザーにとってますます不利になってきています。RedditやStack Overflowのようなプラットフォームは、何百万人もの無給のクリエイターやモデレーターからの投稿に依存しています。しかし、これらのプラットフォームがAI企業と数百万ドルの契約を結ぶ際、彼らはユーザーに補償もしなければ、彼らの許可も求めない。
RedditもStack Overflowも、こうした決定に抗議する注目すべきユーザーストライキを経験しています。米連邦取引委員会(FTC)は、AIモデルを訓練するために、Redditがユーザーの投稿を外部組織と販売、ライセンス供与、共有していることについて調査を開始しました。
これらの問題は、次世代のAIモデルとウェブコンテンツの訓練の将来について疑問を投げかけている。現状では、その未来はかなり絶望的に見えます。暗号化ソリューションは、これらの問題を解決するために、小規模な企業やインターネットユーザーの競争条件を平準化できるのでしょうか?
AIモデルをトレーニングし、有用なアプリを作成することは、計画、リソースの割り当て、実行に数カ月を要する、複雑で費用のかかる取り組みです。これらのプロセスには複数の段階があり、それぞれに異なる目的と異なるデータ要件があります。
これらの段階を分解して、暗号化がより大きなAIパズルにどのように当てはまるかを理解しましょう。
プリトレーニングは、LLM トレーニング プロセスの最初の、そして最もリソース集約的なステップであり、モデルの基礎を形成します。基盤を形成します。この段階では、AIモデルは、世界に関する一般的な知識と言語使用に関する情報を取得するために、大量のラベル付けされていないテキストで学習されます。GPT-4が1.2兆トークンで訓練されたというのは、事前訓練に使われたデータのことです。
なぜ事前学習がLLMの基礎となるのかを理解するためには、LLMがどのように機能するのかをハイレベルで概観する必要がある。これは簡略化された概要であることに注意してください。より詳しい説明は、
ジョン・ストークス
によるこの素晴らしい記事
や、
アンドレイ・クラーク
によるこの素晴らしいビデオをご覧ください。
アンドレイ・カルパシー
あるいは、この優れた本でさらに詳しく解説しています。
ステファン・ウルフラム
LLMは次のトークン予測と呼ばれる統計的テクニックを使います。簡単に言うと、一連のトークン(つまり単語)が与えられると、モデルは次に最も可能性の高いトークンを予測しようとし、このプロセスを繰り返して完全な応答を形成します。つまり、大規模な言語モデルは「完全な機械」と考えることができます。
これを例で理解しよう。
私がChatGPTに "太陽が昇るのはどの方角ですか?"と質問すると、ChatGPTはまず "the "という単語を予測します。 という質問をすると、まず "the "という単語を予測し、次に "the sun rises in the east "というフレーズに続く単語を予測します。しかし、これらの予測はどこから来ているのでしょうか?また、ChatGPTはどのようにして "the sun rises from "というフレーズの後に、"the west"(西)、"the north"(北)、"the south"(南)ではなく、"the east"(東)が続くべきだと判断しているのでしょうか?北」か「アムステルダム」か?言い換えれば、「東」が他の選択肢よりも統計的に可能性が高いことをどうやって知るのでしょうか?

これを理解するもう1つの方法は、これらのフレーズを含む語句をWikipediaの数と比較することです。ウィキペディアのページ数と比較することです。 "太陽は東から昇る "には55ページあり、"太陽は西から昇る "には27ページある。 "The sun rises in Amsterdam "は結果を示しません!これらはChatGPTが選択したモードです。
その答えは、大量の高品質な学習データから統計的パターンを学習することにあります。インターネット上のすべてのテキストを考えた場合、「太陽は東から昇る」と「太陽は西から昇る」のどちらが起こりやすいでしょうか?後者は、文学的比喩(「太陽が西から昇ると信じているのと同じくらい馬鹿げている」)や他の惑星(太陽が西から昇る金星など)に関する議論など、特定の文脈で見られることがある。しかし全体的には、前者の方がはるかに一般的である。
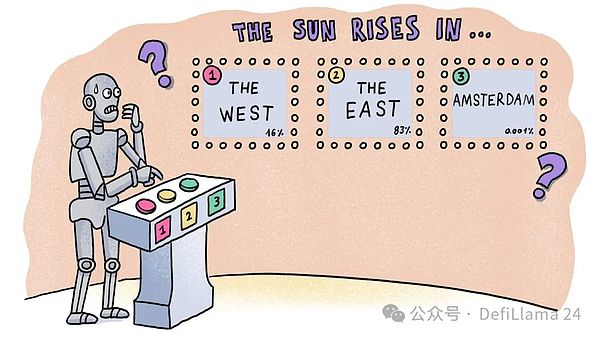
次の単語を繰り返し予測することで。LLMは、世界に対する全体的な見方(私たちはこれを常識と呼んでいる)と、言語のルールやパターンに対する理解を発達させる。LLMをインターネットの圧縮版として見る方法もある。これは、なぜデータが大きく(より多くのカテゴリーから選択できる)、高品質(パターン学習の精度を向上させるため)である必要があるのかを理解するのにも役立ちます。
しかし、先に述べたように、AI企業はより大きなモデルを訓練するためのデータを使い果たしている。学習データの需要は、オープンなインターネット上での新しいデータの生成よりもはるかに速く成長している。訴訟が迫り、主要なフォーラムが閉鎖される中、AI企業は深刻な問題に直面している。
この問題は、Redditのような独自のデータプロバイダーと数百万ドルの契約を結ぶ余裕のない中小企業にとってはさらに深刻だ。
そこで、このようなデータ問題を解決することを目的とした、分散型の居住地プロキシ・サービス・プロバイダーであるGrassを紹介しよう。彼らは自らを「AIのためのデータレイヤー」と呼んでいる。まず、住宅代理サービス・プロバイダーの役割を理解することから始めよう。
インターネットは学習データの最良のソースであり、インターネットをクロールすることは、企業がそのデータを取得するための好ましい方法である。実際には、クローリングソフトウェアは、規模や利便性、効率性を考慮して、データセンターでホスティングされることが多い。しかし、貴重なデータを持つ企業は、自社のデータがAIモデルのトレーニングに使われることを望まない(そうすることで報酬を得ている場合を除く)。このような制限を強化するために、企業はしばしば既知のデータセンターのIPアドレスをブロックし、大規模なクロールを防いでいる。
そこで登場するのが、レジデンシャルプロキシサービスプロバイダーです。ウェブサイトは既知のデータセンターからのIPアドレスのみをブロックし、あなたや私のような一般的なインターネットユーザーからのIPアドレスはブロックしません。レジデンシャル・プロキシ・サービス・プロバイダーは、AI企業のために大規模にウェブサイトをクロールするために、何百万ものこれらの接続を集約している。
しかし、集中型の家庭用プロキシ・サービス・プロバイダーは秘密裏に活動している。彼らは通常、その意図を明らかにしません。ある製品が自分の帯域幅を使用していて、その製品が補償してくれないと知れば、ユーザーは自分の帯域幅を利用可能にすることに消極的になるかもしれない。さらに悪いことに、ユーザーは帯域幅の使用に対する補償を要求する可能性があり、その結果、自社の利益が減少する。
家庭用プロキシサービスプロバイダは、自社の利益を守るために、モバイルユーティリティアプリ(電卓やボイスレコーダーなど)、VPNプロバイダ、さらには消費者向けテレビのスクリーンセーバーなど、広く配布されている無料アプリに帯域幅を消費するコードを添付しています。製品を無料で入手していると思っているユーザーは、サードパーティの住宅プロバイダーが帯域幅を消費していることに気づかないことがよくあります(こうした詳細は、ほとんど読む人がいない利用規約に埋もれていることがよくあります)。
最終的に、このデータの一部はAI企業に送られ、彼らはそれを使ってモデルを訓練し、自分たちのために価値を生み出します。
アンドレイ・ラドニッチ氏は、自身の住宅エージェントサービス・プロバイダーを経営していたときに、こうした慣行の非倫理的な性質と、ユーザーにとっていかに不公平であるかを実感した。彼は暗号通貨の成長を目の当たりにし、より公平な解決策を生み出す方法を見出した。こうしてグラスは2022年末に設立された。数週間後、ChatGPTがリリースされ、世界を変え、グラスは適切なタイミングで適切な場所に置かれた。

卑劣な手口を使う他の住宅エージェント・サービス・プロバイダーとは異なり、Grassは、そのようなサービス・プロバイダーであることを明確にしています。グラスは、AIモデルのトレーニングに帯域幅を使用していることを契約者に明らかにしている。その見返りとして、直接報酬が支払われる。このモデルは、家庭向け代理サービス・プロバイダーの運営方法を完全に破壊するものだ。自発的に帯域幅アクセスを提供し、ネットワークの一部所有者となることで、ユーザーは何も知らない受動的な参加者から能動的な伝道者に変わり、ネットワークの信頼性を向上させ、AIが生み出す価値から利益を得ることができる。
グラスの成長は目覚ましい。2023年6月にローンチして以来、(ブラウザ拡張機能やモバイルアプリをインストールして)ノードを実行し、ネットワークに帯域幅を提供するアクティブユーザーを200万人以上集めている。この成長は、外部のマーケティングコストを一切かけることなく、大成功を収めた紹介プログラムによってもたらされました。
Grassのサービスを利用することで、大規模なAIラボからオープンソースの新興企業まで、あらゆる規模の企業が数百万ドルを支払うことなく、クロールされた学習データにアクセスできるようになる。一方、一般ユーザーはインターネット接続を共有することで報酬を得ることができ、成長するAI経済の一部となる。
生のクロールデータに加え、グラスはいくつかの追加サービスを顧客に提供している。を提供しています。
まず、構造化されていないウェブページを、AIモデルで処理しやすい構造化データに変換する。このステップはデータクレンジングとして知られており、一般的にAIラボが行うリソース集約的なタスクである。構造化されたクリーンなデータセットを提供することで、グラスは顧客への価値を高めている。さらにGrassは、データのクロール、クリーニング、ラベリングのプロセスを自動化するために、オープンソースのLLMをトレーニングしている。
第二に、グラスはデータセットを紛れもない出所証明に結び付けている。AIモデルにとって高品質なデータが重要であることを考えると、AI企業にとって、ウェブサイトであれ住宅仲介業者であれ、悪質な業者がデータセットを改ざんする権利を持たないようにすることは非常に重要です。
この問題の大きさは、Meta、IBM、Walmartを含む20社以上の企業で構成される非営利団体であるData and Trust Allianceのような組織の形成に反映されています。
グラスも同様の措置を講じている。グラスのノードはウェブページをクロールするたびに、クロールされたページを検証するためのメタデータも記録する。これらの出所証明はブロックチェーンに保存され、顧客と共有される(顧客はさらにユーザーと共有できる)。
Grassは最も処理能力の高いブロックチェーンの1つであるSolanaの上に構築されているが、L1上のすべてのクロールジョブの出所を保存するのは現実的ではない。そこでGrassは、ZKプロセッサーを使って出所証明をバッチ処理し、それをSolana上で公開するロールアップ(Solana上で最初のもののひとつ)を構築している。Grassが「AIのためのデータレイヤー」と呼ぶこのロールアップは、クロールされたすべてのデータのデータ台帳となる。
グラスのウェブ3ファーストのアプローチは、中央集権型のレジデンシャル・エージェント・プロバイダーに対していくつかの利点を与えている。第一に、ユーザーが帯域幅を直接共有するインセンティブを利用することで、AIによって生み出される価値をより公平に分配することができる(同時に、コードをバンドルするためにアプリ開発者に支払うコストも節約できる)。第二に、この業界では非常に価値のある「正当なトラフィック」を提供することで、プレミアムを課すことができる。
「正当なトラフィック」という切り口で構築されたもう1つのプロトコルは、ユーザーがReddit、Twitter、TikTokなどのプラットフォームのログイン情報を渡すことを可能にするネットワーク、Masaだ。ネットワーク上のノードは、文脈に沿った更新データを取得する。このモデルの利点は、収集されたデータが通常のTwitterユーザーがフィードで見るものであることだ。リアルタイムで豊富なデータセットを手に入れ、センチメントやバイラルになりそうなコンテンツを予測することができる
彼らのデータセットは何に使われるのか?現状では、このコンテキストデータには主に2つの使用例がある。
金融 - 何千人もの人々がフィードで何を見ているかを見る仕組みがあれば、それに基づいて取引戦略を開発することができます。センチメントデータに基づくインテリジェントエージェントは、マサのデータセットで訓練することができる。
ソーシャル - AIベースの仲間(またはReplikaのようなツール)の出現は、人間の会話を模倣したデータセットが必要であることを意味します。これらの会話はまた、最新の情報で更新される必要があります。Masaのデータストリームは、Twitterの最新トレンドについて有意義に話すことができるエージェントを訓練するために使用できます。
Masaのアプローチは、Twitterのようなクローズド・ガーデンから情報を取得し、それを開発者が利用できるようにすることで、ユーザーの同意を得てアプリを構築することです。データ収集に対するこのソーシャル・ファースト・アプローチは、データセットをさまざまな国の言語で構築することも可能にしている。
例えば、ヒンディー語を話すボットは、ヒンディー語で運営されているソーシャルネットワークで収集されたデータを使用することができます。これらのネットワークが開くアプリケーションの種類は、まだ調査されていません。
事前に訓練されたLLMは、本番にはほど遠い状態です。考えてみてください。今のところ、モデルが知っているのは、シーケンス内の次の単語を予測する方法だけで、それ以上のことはありません。
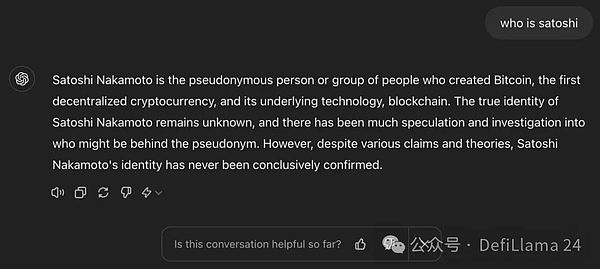
質問を終える:サトシ・ナカモト?
このフレーズを文章にしてください:それは何年もビットコイン信者を悩ませてきた質問です。
質問に本当に答えるなら:サトシ・ナカモトは、最初の分散型暗号通貨であるビットコインと、その基礎となるブロックチェーン技術を生み出した匿名の人物またはグループです。
有益な回答を提供するように設計されたLLMは、3つ目の回答を提供します。しかし、事前に訓練されたモデルの回答は首尾一貫しておらず、正しいものでもない。実際、エンドユーザーにとって意味のないテキストをランダムに出力することがよくある。最悪の場合、モデルは実際には正しくない、有害な、あるいは有害な情報を密かに返答する。このような場合、モデルは「幻想的」であると言われる。

これが事前に訓練されたGPT-3が質問に答える方法です。
モデルアライメントの目標は、事前訓練されたモデルを最終的にユーザーに役立つものにすることです。言い換えれば、単なる統計的なテキストツールから、ユーザーのニーズを理解し、それに沿い、首尾一貫した有益な対話を行うチャットボットへの変換を完了することです。
このプロセスの最初のステップは、対話の微調整です。微調整とは、事前にトレーニングされた機械学習モデルを、特定のタスクやユースケースに適応させるために、より小さな、対象となるデータセットでさらにトレーニングすることです。LLMを訓練する場合、この特定のユースケースは人間のような対話を行うことである。当然ながら、このような微調整のためのデータセットは、人間が生成したプロンプトとレスポンスのペアのセットであり、これらの対話はモデルがどのように振る舞うべきかを示している。
これらのデータセットは、さまざまなタイプの対話(質問-回答、要約、翻訳、コード生成)をカバーしており、一般的に、優れた言語スキルと専門知識を持つ高学歴の人間(AIメンターと呼ばれることもある)によって設計されています。
GPT-4のような最先端のモデルは、このようなプロンプトとレスポンスのペアを約10万組訓練したと推定されています。

手がかりと反応のペアの例
この段階を想像してください。">この段階は、人間がペットの子犬を訓練するのに似ていると想像してください:良い行動には報酬を与え、悪い行動には罰を与えます。モデルは合図を与え、その応答は人間のタグ付け担当者と共有され、タグ付け担当者は出力の正確さと質に基づいて数値スケール(たとえば1~5)で評価する。RLHFのもう1つのバージョンは、複数の応答を生成する手がかりを得ることであり、その応答は人間のタガーによってベストからワーストにランク付けされる。
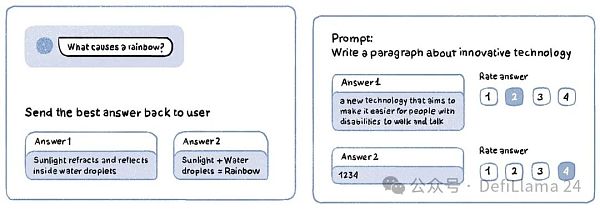
RLHFタスクの例
RLHFは、モデルを人間の好みや望ましい行動に向かわせるのに役立ちます。実際、ChatGPTを使用すると、OpenAIはあなたをRLHFデータタガーとしても使用します!これは、モデルが時々2つの応答を生成し、より良い方を選択するように求めるときに起こります。
回答の有用性を評価するよう促す単純な「好き」「嫌い」アイコンでさえ、モデルのRLHFトレーニングの一形態です。
私たちがAIモデルを使うとき、何百万時間もの工数を考慮することはほとんどありません。何百万時間もの人手が投入されていることを考慮することはほとんどありません。これはLLMに限ったことではありません。歴史的に、コンテンツレビュー、自律走行、腫瘍検出のような伝統的な機械学習のユースケースでさえ、データのアノテーションに人間が大きく関与する必要がありました。
フェイフェイ・リーがImageNetデータベースの作成に利用しているMechanical Turkは、AIトレーニングの舞台裏で作業員が果たす役割から、ジェフ・ベゾスによって「人間のための人工AI」と呼ばれている。データのラベリング
今年初めの奇妙な物語では、顧客が棚から商品を選んで外に出ることができる(そして後日自動的に請求される)アマゾンのJust Walk Outショップは、一部の高度なAIによって駆動されているわけではないことが明らかにされた。高度なAIによって動いているのだ。その代わりに、1,000人のインド人請負業者が手作業で店の映像を選別しているのだ。

重要なのは、どんな大規模なAIシステムも、ある程度は人間に依存しているということだ。LLMはこうしたサービスの必要性を高めるだけだ。OpenAIを顧客に持つScale AIのような企業は、このような需要を背景に、すでに11桁の評価額に達している。Uberでさえ、車両を運転していないときは、インドの従業員の一部をAI出力のタグ付けに再利用している。
フルスタックのAIデータソリューションを目指して、グラスもこの市場に参入した。同社は間もなくAIラベリング・ソリューションをリリースし(主要製品の拡張機能として)、同社のプラットフォームのユーザーはRLHFタスクを完了することでインセンティブを得ることができるようになる。
問題は、グラスがプロセスを分散化することで、同じ空間にいる何百もの中央集権的な企業に対して、どのような利点を得ることができるかということだ。
グラスは、トークンのインセンティブを使ってワーカーネットワークを立ち上げることができる。インターネット帯域幅を共有するユーザーに報酬を与えるためにトークンを使うのと同じように、AIのトレーニングデータをラベリングする人間に報酬を与えるためにもトークンを使うことができる。Web2の世界では、ギグエコノミー、特にグローバルに分散された仕事に対する労働者への支払いは、Solanaのような高速ブロックチェーンで提供される即時流動性よりも劣ったユーザーエクスペリエンスだ。
一般的に、暗号コミュニティ、特にGrassの既存コミュニティには、教育を受け、インターネットネイティブで技術に精通したユーザーがすでに集中している。そのため、グラスは労働者の採用やトレーニングに費やすリソースを削減することができる。
AIモデルの反応をラベリングするためのインセンティブを取引する作業が、農家やボットの注目を集めるかどうか疑問に思うかもしれない。私も同じ疑問を抱いていた。幸いなことに、質の高いアノテーターを特定し、ボットをフィルタリングするために、コンセンサスに基づく技術を用いて広範な研究が行われています。
少なくとも今のところ、グラスはRLHF(人間のフィードバックによる強化学習)市場に参入しているに過ぎず、高度に専門化された労働市場を必要とし、自動化が難しい会話の微調整を行う企業を支援しているわけではないことに注意してほしい。
事前学習と位置合わせのステップが完了すると、ベースモデルと呼ばれるものができます。ベースモデルは、世界がどのように機能するかについての一般的な理解を持っており、幅広いトピックについて流暢で人間のような対話をすることができます。また、言語をしっかりと理解しており、ユーザーが電子メール、物語、詩、記事、歌を簡単に作成することができる。
ChatGPTを使用する場合、ベースモデルのGPT-4と対話することになります。
ベースモデルは一般的なモデルです。彼らは何百万ものトピックのカテゴリーに精通していますが、どれかに特化しているわけではありません。ビットコインのトークンエコノミクスを理解するのに役立つと問われれば、その答えは有用で、ほぼ正確だろう。しかし、EigenLayerのようなリプレッディング・プロトコルのリスクを軽減する方法を明確に説明するよう求められたら、それを信用すべきではありません。
思えば、微調整とは、事前に訓練された機械学習モデルを、特定のタスクやユースケースに適応させるために、より小規模で的を絞ったデータセットでさらに訓練するプロセスです。以前、生のテキスト補完ツールを対話モデルに変換するという文脈で微調整について説明した。同様に、特定のドメインや特定のタスクに特化するために、生成されたベースモデルを微調整することができます。
Googleの基本モデルPaLM-2を微調整したMed-PaLM2は、医学的な質問に対して高品質な回答を提供するように学習された。微調整されたモデルの中には、ストーリーテリング、テキストの要約、カスタマーサービスといった特定のカテゴリーに特化したものもあれば、ポルトガルの詩、ヒンディー語-英語翻訳、スリランカの法律といったニッチな領域に特化したものもあります。
特定のユースケースのためにモデルを微調整するには、そのユースケースに関連する高品質のデータセットが必要です。このようなデータセットは、ドメイン固有のウェブサイト(暗号化されたデータのニュースフラッシュなど)、独自のデータセット(病院は何千もの医師と患者のやり取りを記録しているかもしれません)、または専門家の経験(徹底的なインタビューで把握する必要があります)から得ることができます。

何百万ものAIモデルが存在する世界に移行するにつれ、このようなニッチで長期的なデータセットが必要となります。世界では、こうしたニッチでロングテールのデータセットの価値がますます高まっています。アーンスト・アンド・ヤングのような大手会計事務所からガザのフリーランスの写真家まで、これらのデータセットの所有者は、AI軍拡競争において最もホットな商品になるため、すぐに求愛されている。Gulp Dataのようなサービスは、組織がデータを公正に評価するのを助けるために登場した。
OpenAIは、「人間社会を反映する大規模なデータセットで、現在ではオンラインで容易に公開されていないもの」を持つ団体とのデータパートナーシップを公募している。
私たちは、特定の商品を探している買い手と売り手をマッチングさせる少なくとも1つの方法を知っています:インターネットマーケットプレイスです!Ebayは収集品のためのマーケットプレイスを作り、Upworkは人間の労働のためのマーケットプレイスを作り、他にも数え切れないほどのカテゴリのプラットフォームを作りました。当然のことながら、ニッチなデータセットのためのマーケットプレイスも出現している。
Bagelは、「高品質で多様なデータ」の保有者が信頼できる方法でAI企業と関わることを可能にするツール群、Common Infrastructureを構築している、AI企業とデータを共有するための、プライバシーを保護する方法だ。ZK(Zero Knowledge)やFHE(Fully Homomorphic Encryption)などのテクノロジーを使ってこれを行う。
企業は多くの場合、プライバシーや競争上の問題から、収益化できないが非常に価値のあるデータを保有している。例えば、研究室が患者のプライバシーを守るために共有できない大量のゲノムデータを持っていたり、消費財メーカーが競争上の秘密を明らかにすることなく公開できないサプライチェーンの廃棄率削減データを持っていたりします。Bagelは暗号技術の進歩を利用して、付随する懸念を軽減しながら、これらのデータセットを有用なものにします。
GrassのResidential Proxyサービスは、特殊なデータセットの作成にも役立ちます。例えば、専門家による料理のアドバイスを提供するモデルを微調整したい場合、Redditのサブセクションであるr/Cookingやr/AskCulinaryからデータを取得するようGrassに依頼することができます。同様に、旅行指向のモデル作成者は、TripAdvisorのフォーラムからデータを取得するようにGrassに依頼することができます。
これらは正確には独自のデータソースではありませんが、それでも他のデータセットに付加価値を与えることができます。
お気に入りのLLMに「トレーニングの締め切りはいつですか?"2023年11月のような答えが返ってくるでしょう。つまり、ベースモデルはその日までに入手可能な情報しか提供しないということです。これは、これらのモデルをトレーニングする(あるいは微調整する)ための計算コストと時間の消費を考えれば、理にかなっている。
リアルタイムで最新の状態に保つには、毎日新しいモデルをトレーニングして配備しなければなりませんが、これは(少なくとも今のところ)実現不可能です。
しかし、世界に関する最新の情報を持っていないAIは、多くのユースケースでかなり役に立ちません。例えば、LLMからの応答に依存するパーソナルデジタルアシスタントを使用する場合、未読の電子メールを要約したり、直近のリバプール戦のゴールスコアラーを提供するように要求された場合、それらは制限されるでしょう。
このような制限を回避し、リアルタイムの情報に基づいた応答をユーザーに提供するために、アプリ開発者は、ベースモデルの「コンテキストウィンドウ」として知られているものに情報を照会し、挿入することができます。コンテキスト・ウィンドウは、LLMが応答を生成するために処理できる入力テキストである。これはトークンで測定され、LLMが任意の瞬間に「見る」ことができるテキストを表します。
つまり、私がデジタルアシスタントに未読メールの要約を依頼するとき、アプリはまず私の電子メールプロバイダに未読メールの内容を問い合わせ、その応答をLLMに送信されるプロンプトに挿入し、「シュロックの受信トレイにあるすべてのメッセージとそのリストを提供しました。Shlokの受信トレイにあるすべての未読メッセージのリストを提供しました。それらを要約してください。"この新しいコンテキストで、LLMはタスクを完了し、返答をすることができる。このプロセスは、あたかもChatGPTにメールをコピー&ペーストして、応答を生成するように依頼するようなものだと考えてください。
分刻みのレスポンスを持つアプリを作成するには、開発者はリアルタイムのデータにアクセスする必要があります。そして、あらゆるウェブサイトをリアルタイムでクロールできるグラスノードは、このデータを開発者に提供することができます。例えば、LLMベースのニュース・アプリケーションは、Googleニュースの人気記事を5分ごとにクロールするようGrassに依頼することができる。ユーザーが "ニューヨークを襲った地震のマグニチュードは?"と尋ねると、ニュースアプリは記事を検索し、その記事を表示する。ニュースアプリは記事を取得し、LLMのコンテキストウィンドウに追加し、ユーザーと応答を共有します。
これが現在のMasaの位置づけだ。現在のところ、アルファベット、メタ、そしてXが、常に更新されるユーザーデータを持つ唯一の大規模プラットフォームである。
このプロセスの技術用語は、検索機能付きジェネレーション(RAG)である。このプロセスでは、テキストをベクトル化したり、テキストをコンピュータが解釈、操作、保存、検索しやすい数字の配列に変換したりします。
グラスは将来、物理的なハードウェアノードをリリースし、顧客にベクトル化された低レイテンシのリアルタイムデータを提供し、RAGワークフローを合理化する予定です。
業界のほとんどのビルダーは、コンテキストレベルのクエリ(推論としても知られている)が将来的にリソース(エネルギー、計算、データ)の大部分を使用すると予測しています。これは理にかなっている。モデルのトレーニングは、常に一定のリソース割り当てを消費する時間制限のあるプロセスである。一方、アプリケーションレベルの使用は、理論的には無制限の需要を持つ可能性があります。
グラスは、テキストデータのリクエストのほとんどが、リアルタイムのデータを求める顧客からのものであり、このようなことが起こるのを目の当たりにしてきました。
LLMのコンテキストウィンドウは時間とともに拡大しています。OpenAIが最初にChatGPTをリリースしたとき、そのコンテキストウィンドウは32,000トークンでした。それから2年も経たないうちに、GoogleのGeminiモデルは100万トークンを超えるコンテキストウィンドウを持つようになりました。100万トークンは、300ページの本11冊分以上に相当する。
これらの開発により、リアルタイムの情報にアクセスするだけでなく、はるかに大きなコンテキストウィンドウを構築することが可能になります。たとえば、誰かがテイラースウィフトの歌詞のすべてや、このニュースレターのアーカイブ全体を取り出し、コンテキストウィンドウにダンプし、LLMに同じようなスタイルで新しいコンテンツを生成するように依頼することができます。
そうしないように明示的にプログラムされていない限り、モデルはかなり良い出力を生成するでしょう。
この議論がどこに向かっているのか感じ取れたなら、次に何が起こるか少し待ってください。これまでは主にテキストモデルについて説明してきましたが、生成モデルは、音や画像、動画の生成など、他のモダリティにおいても非常に熟練してきています。私は最近、TwitterでOrkhan Isayenによるロンドンのとてもクールなイラストを見つけました。

Midjourneyは、人気の(そして非常に優れた)テキストから画像への変換ツールです。この機能もRAGのワークフローに似ていますが、まったく同じではありません)。私はOrkhanによる手作りのイラストをアップロードし、スタイル・アジャスターを使ってMidjourneyに都市をニューヨークに変更するよう促した。

このアーティストのイラストを閲覧すると、4つの画像が表示されます。このアーティストのイラストを閲覧すれば、彼らの作品と見間違えるのは簡単だ。これらは1枚の入力画像をもとにAIが30秒で生成したものだ。私は「ニューヨーク」をリクエストしたが、テーマは何でもいい。同様の複製は、音楽など他のモダリティでも可能だ。
クリエイターを含め、AI企業を提訴しているいくつかの団体についての以前の議論を思い返すと、彼らがそうすることに意味がある理由がわかるでしょう。
かつてインターネットはクリエイターにとって恩恵であり、ストーリーやアート、音楽などのクリエイティブな表現を世界と共有する手段であり、1000人の真のファンを見つける手段だった。そして今、その世界的なプラットフォームが、彼らの生活を脅かす最大の脅威となりつつある。
月30ドルのMidjourney購読料でオルカンの作品にスタイル的に近いコピーが手に入るのに、なぜ500ドルの委託料を払うのか?
反ユートピア的に聞こえるか?
テクノロジーの素晴らしいところは、自らが作り出した問題を解決するための新しい方法をほとんど常に考え出すことだ。クリエイターにとって厳しいと思われる状況を逆手に取れば、前例のない規模で才能をマネタイズするチャンスであることに気づくだろう。
AIが導入される以前は、オルカンが創造できる芸術作品の量は、1日の時間数によって制限されていた。AIを使えば、理論的には無限のクライアントにサービスを提供できる。
どういうことか、ミュージシャン、グライムスのAI音楽プラットフォーム、elf.techを見てみよう。elf techでは、録音した曲をアップロードすると、グライムスのサウンドとスタイルに変換してくれる。その楽曲から得られるロイヤリティは、グライムスとクリエイターの間で折半される。つまり、グライムス、彼女の歌声、コンサート、配信のファンであれば、曲のアイデアを思いつくだけで、プラットフォームがAIを使ってグライムスの歌声に変換してくれるのだ。
曲がバイラルになれば、あなたとグライムスの双方にメリットがある。また、グライムスの才能を広げ、彼女の配信を受動的に利用することもできる。
elf.techを動かすテクノロジーであるTRINITIは、CreateSafeによって作られたツールです。彼らのライトペーパーは、ブロックチェーンとジェネレーティブAI技術の間に予見される最も興味深い接点の1つを明らかにしています。
クリエイターが制御するスマートコントラクトを通じてデジタルコンテンツの定義を拡張し、ブロックチェーンベースのピアツーピア、有料アクセスのマイクロトランザクションを通じて配信を再構築することで、あらゆるストリーミングプラットフォームがデジタルコンテンツを即座に検証し、アクセスできるようになります。そしてGenerative AIは、クリエイターが指定した条件に基づいて即座にマイクロペイメントを実行し、その体験を消費者にストリーミングします。
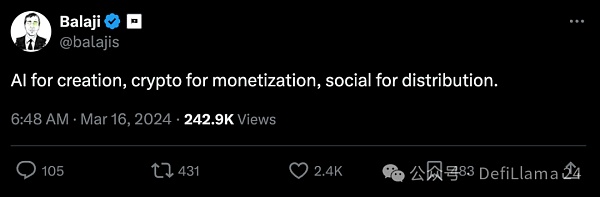
バラジはこれをより簡潔に表現した。
新しいメディアの出現に伴い、私たちは人間がどのようにそれらと相互作用するかを解明することに躍起になっています。私たちは、新しいメディアの出現によって、人間がそれらとどのようにインタラクションするのかを解明することに躍起になっています。それらがウェブと組み合わさったとき、変化のための強力なエンジンとなる。書籍はプロテスタント革命の燃料となった。ラジオとテレビは冷戦の重要な一部だった。メディアは通常、諸刃の剣である。善にも悪にも使える。
今日あるのは、ユーザーデータのほとんどを所有する中央集権的な企業だ。私たちはまるで、創造性や精神衛生、より良い社会のために正しいことをしてくれる企業を信頼しているかのようです。それは、私たちがその内部構造をほとんど知らない一握りの企業に渡すには、あまりにも大きな力だ。
我々はまだLLM革命の初期段階にいる。2016年のEtherのように、LLMを使ってどのようなアプリが作られるのか、ほとんど見当がつきません。祖母とヒンディー語で会話するLLM、情報のストリームを閲覧し、高品質のデータのみを提示する知的エージェント?独立した投稿者が文化特有のニュアンス(スラングなど)を共有する仕組み?私たちはまだその可能性について多くを知りません。
しかし、はっきりしているのは、これらのアプリの構築は、データという1つの重要な要素によって制限されるということです。
Grass、Masa、Bagelのようなプロトコルは、公正な方法でデータをソースとするインフラです。その上に何が構築できるかを考えるとき、人間の想像力は限界に達している。私には、それがエキサイティングに思える。
完全同形暗号化(FHE)の入門書。そのエキサイティングなアプリケーション、制限、そしてその人気を牽引する最新動向を探る。
JinseFinanceZamaが7,300万ドルの資金調達を完了し、ホモモーフィック暗号エコシステムの全貌が明らかに。
JinseFinanceゼロ知識証明(ZKP)は、Web3におけるスケーラビリティとプライバシーの向上に有用であることは明らかだが、暗号化されていないデータを処理するサードパーティへの依存が妨げとなっている。
JinseFinance4月20日、Global Encryption Coalitionのメンバーを含む40以上の組織とサイバーセキュリティの専門家が、トルコ政府に対してエンド・ツー・エンドの暗号化を損なわないよう求める共同声明を発表した。
 Pr0phetMoggy
Pr0phetMoggy Coinlive
Coinlive  CointelegraphCoinlive
CointelegraphCoinlive この記事は、デジタルアートの流通メカニズムとしての「非代替トークン(NFT)」の使用を含む、最近出現した「暗号アート」分野の概要です。
 Ftftx
Ftftxブロックチェーン・ライフの創設者によると、ロシアにルーツを持つ仮想通貨取引所の多くが国外に逃亡したか、違法に運営されているという。
Cointelegraph下院民主党のグループによる最新の提案は、税法の更新が「仲介サービスに従事していない」仮想通貨事業体にどのような影響を与えるかを変更しようとしている。
Cointelegraph