韓国の空売り禁止期間延長:必要悪か?
韓国は11月以降、機関投資家による違法な空売りの取り締まりを強化し、世界的な銀行の間で広範な不正行為が発覚した。韓国は空売り禁止期間を2025年第1四半期まで延長する意向だ。
 Wilfred
Wilfred

Written by PREDA; Compiled by ChainFeeds Research
並列実行モデルの設計は、従来のデータベース領域でもブロックチェーン技術でも、より複雑になっている。 なぜなら、設計プロセスにおいて、複数の次元を包括的に考慮する必要があり、各次元の選択がシステム全体のパフォーマンスとスケーラビリティに大きな影響を与える可能性があるからである。本稿では、現在利用可能な最も代表的なブロックチェーン実行レイヤーの並列アーキテクチャをいくつか詳しく取り上げ、これらのアーキテクチャのパフォーマンスとスケーラビリティに関する実験結果を詳しく紹介します。
一面では、ブロックチェーン空間では、チェーンの高いパフォーマンスとスケーラビリティが常に追求されてきました。マルチチェーンやLayer2システムの出現によっても、各スマートコントラクトを実行する能力は、単一の仮想マシンVMの容量によって制限されています。パラレルVMの登場により、この制限は解消された。パラレルVMでは、1つのスマートコントラクトのトランザクションを複数のEVM/VMで同時に実行できるため、より多くのCPUコアを利用してパフォーマンスを向上させることができます。
私たちは、並列VMをサポートする数多くの高性能ブロックチェーンシステムの中で、Sei (V2)、Aptos、Sui、Crystality、および PREDA が最も代表的であり、各システムが設計上の独自の利点を提供していると考えています。独自の利点を提供している。
本稿の冒頭で、最初の実験結果を示しました。下のグラフは、128コアのマシンで同じERC20スマートコントラクトを実行したときの、Sei、Aptos、Sui、Crystality、PREDAの1秒あたりのトランザクションの絶対数(TPS)を示しています。この一連の実験結果から、5つの並列実行システムのTPSとスケーラビリティの比較において、PREDAモデルが大きく優位に立ちました。
その他の実験データと分析については、後で詳しく説明します。
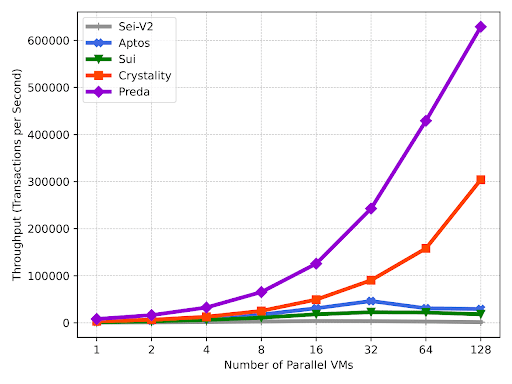
以下では、実験で使用した正確な方法論と操作について詳しく説明します。
まず、5つのシステムのTPS値、つまりスループットを比較しました。異なるチェーン上で行われたTPS比較実験では、同じトランザクションボリュームが使用されました。
異なるシステムで使用された異なるプログラミング言語と基礎となるVMを考慮すると、単一のスループット比較ではシステムの長所と短所を完全に説明できないため、相対的なスピードアップ結果の比較、すなわちスピードアップ比、すなわち1つのVMと比較して複数のVMで実行された同じ数のトランザクションのスピードアップの比較も行いました。Sui、Aptos、Crystality、PREDAでは、各スレッドに専用のCPUコアが割り当てられています。
TPSの絶対値やスピードアップ比率を含むすべての詳細な実験データについては、Full Experiment Reportを参照してください。
次の表は、実験で使用したデータ ソース、実装プロセス、および評価方法を示しています。

次に、AptosとSuiの並列化モデルの違いを見て、異なるアプローチがパフォーマンスにどのように影響するかを分析し、それぞれの長所を強調します。
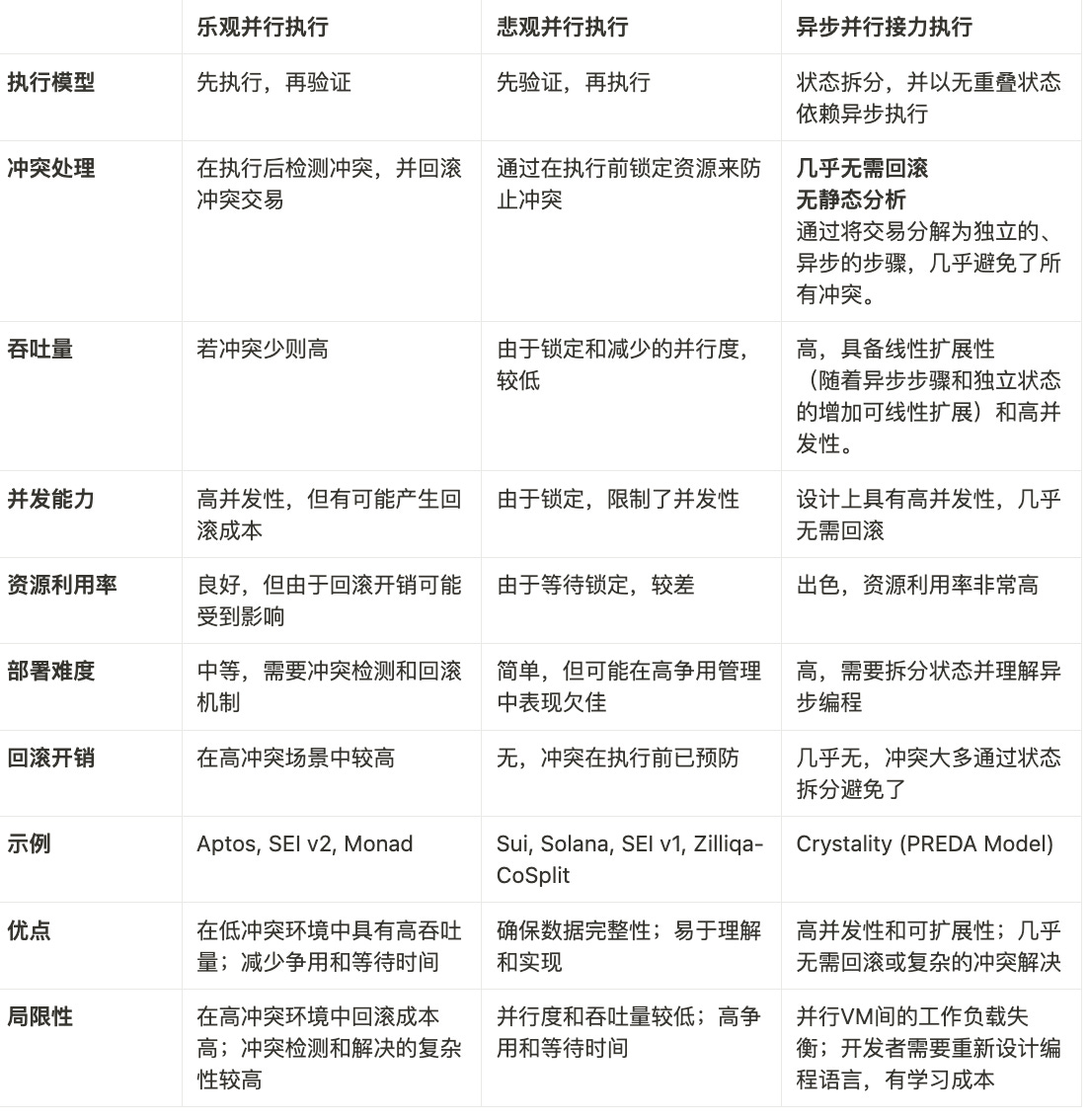
Aptosは、楽観的並列化メカニズムによってスマートコントラクトの並列実行を可能にすることで、高性能を実現するレイヤー1です。特に楽観的並列化では、トランザクションは最初にステートフルな競合がないと仮定され、並列に実行されます。実行後、システムは競合をチェックし、競合するトランザクションをロールバックして直列実行方式で再実行するか、別のスケジューリングによって解決する。この投機的実行アプローチは、ほとんどのトランザクションが競合しないことを前提としているため、競合を処理するためのフォールバックメカニズムを提供しながら、並列実行の利点を最大化します。
楽観的並列化の利点: (1)プログラムの修正が不要:既存のコードを変更することなく簡単に実装できる。(2)競合の割合が低~中程度しかないシナリオでの効率性:多くのトランザクションが同時に進行することを許可し、多くの実世界のシナリオでは比較的低い競合が発生した場合に対処することで、スループットを最大化します。
Aptosはスマートコントラクト開発にMOVEプログラミング言語を、システム実装にAptos MOVE仮想マシンを使用しています。
Suiは悲観的並列化戦略を採用しています。悲観的並列化では、システムは実行前に、リソース競合の可能性があるトランザクションを事前にチェックします。プログラマーは、各トランザクションがアクセスする必要があるリソース(つまり、状態)を指定する必要があります。システムは入力される各トランザクションを事前にチェックし、潜在的な競合を検出する。現在実行中のトランザクションとのリソース競合を伴わないトランザクションのみが、並列実行のために実行エンジンに送られる。
悲観的並列化の利点: (1) ロールバックの回避: 実行前に競合を特定し回避することで、このアプローチはロールバックと再実行の必要性を最小化し、より予測可能なパフォーマンスをもたらします。(2)高競合シナリオにおける効率性:高競合環境において非常に効果的で、競合しないトランザクションのみが並列に実行されるようにし、競合解決に伴うオーバーヘッドを削減します。
SuiもMOVEプログラミング言語を使用しますが、独自のSui MOVE拡張を持ち、システム実装ではSui MOVE仮想マシンを使用します。
Seiは当初、Cosmos SDK上に構築されたトランザクションアプリケーションチェーンとして位置づけられたパブリックチェーンとして発表され、最初の並列化されたEVMチェーンにアップグレードされました。並列実行のレベルでは、SeiはAptosモデルに似たアプローチを使用しており、楽観的並列化と呼んでいます。
Sei(V2)が使用する楽観的並列処理は、Solidityプログラミング言語と標準イーサネット仮想マシン(EVM)を使用することで差別化されており、EVMとSolidityの互換性を確保しています。
Crystality and PREDA: Parallel Relay-Execution Distributed Architecture
Crystality と PREDA の両方は Parallel Relay-Execution Distributed Architecture (PREDA) をサポートしています。PREDAは特に、マルチEVMブロックチェーンアーキテクチャで汎用スマートコントラクトを並列化するために設計されています。両者の関係は、CrystalityがPREDAモデルに基づく並列EVM/GPU用のプログラミング言語であるということです。システムの観点からは、PREDAはブロックチェーン分野で初めて、コントラクトの機能を完全に並列化し、トランザクションの同時実行性を最大化することを可能にします。これにより、すべてのEVMインスタンスの効率的な利用が保証され、与えられたハードウェア構成に対して最適なパフォーマンスとスケーラビリティが得られます。
SolidityやMoveの逐次実行やShared Everythingのアーキテクチャ設計とは異なり、PREDAモデルは、並列実行における状態の依存関係を断ち切るために初めてShared Nothingアーキテクチャを採用しました。競合を避けることができます。
PREDAでは、コントラクト機能は複数の順序付けられたステップに分解され、それぞれのステップは並列実行可能で競合のない状態の一部に依存する。ユーザーによって開始されたトランザクションは、まずユーザーのアドレスの状態を保持するEVMに送られます。トランザクションの実行中、実行フローはデータを移動することなく実施することができ、一方、実行フローは、現在の管理に必要なコントラクト状態を保持するEVMから別のEVMに切り替えるリレートランザクションを発行することにより、データ依存関係に基づいてEVM間を移動する。
評価では、広く使われている5つのスマートコントラクト(ETH TokenTransfer、Voting、Airdrop、CryptoKittiesとMillionPixel、そしてMyToken(ERC20)です。これらの契約は、Sei、Aptos、Sui、Crystality、PREDAを含む様々なブロックチェーンシステム上で実行されています。私たちは、異なる並列実行システムの性能を比較するために詳細な実験を行い、1秒あたりのトランザクション数(TPS)とアクセラレーション比(各システムの単一VMに対して複数のVMで実行した場合の相対的な性能向上を測定)に焦点を当てました。
TPSの絶対値やアクセラレーション比を含むすべての詳細な実験データについては、フル実験レポートを参照してください。
ETH TokenTransferコントラクト:この実験では、標準のERC20スマートコントラクトと同じ実際の過去のETHトランザクションを使用しました。
Votingコントラクト:Votingコントラクトは、PREDAモデルがどのように並列投票アルゴリズムを簡素化するかを示す素晴らしい例です。CrystalityとPREDAのデータ分割、中継、実行メカニズムを活用し、楽観的(Aptos)と悲観的(Sui)の並列化手法の両方を、絶対TPSとスピードアップ比の点で上回っています。元々Solidityに搭載されていた逐次的なアルゴリズムは、現在ではVM間の並列投票と一時的な配列からの結果の集約を可能にしています。
AirDrop: このコントラクトは、1つのアドレスから複数のアドレスへの複数のトークンまたはNFT転送をトリガーします。1対多の状態変更モードがあります。この場合、Sei、Aptos、Suiの2つのトランザクションを並行して実行することはできません。並列度の高いPREDAモデルによってのみ、これらのトランザクションをパイプラインモードで並列処理することができる。
CryptoKitties: この契約は、親猫の遺伝子に基づいて子猫を繁殖させるという、イーサで人気のゲーム契約です。以前のコントラクトとは異なり、このコントラクトでは、ユーザー主導のトランザクションを処理する際に、「親猫」、「母猫」、「生まれたばかりの猫」など、複数のアドレス状態にアクセスする必要がある。また、このコントラクトでは、親の遺伝子から生まれたばかりの猫の遺伝子を計算する際に、以前のコントラクトよりも複雑な計算が必要となる。
MillionPixel: イーサ上のこのゲーム契約では、ユーザーは急いで地図上の座標をマークしなければならない。このスマートコントラクトは、PREDAモデルの柔軟性を実証するために使われています。コントラクトの状態をアドレスでパーティショニングすることに加え、プログラマーはパーティションキーをカスタマイズすることができます。
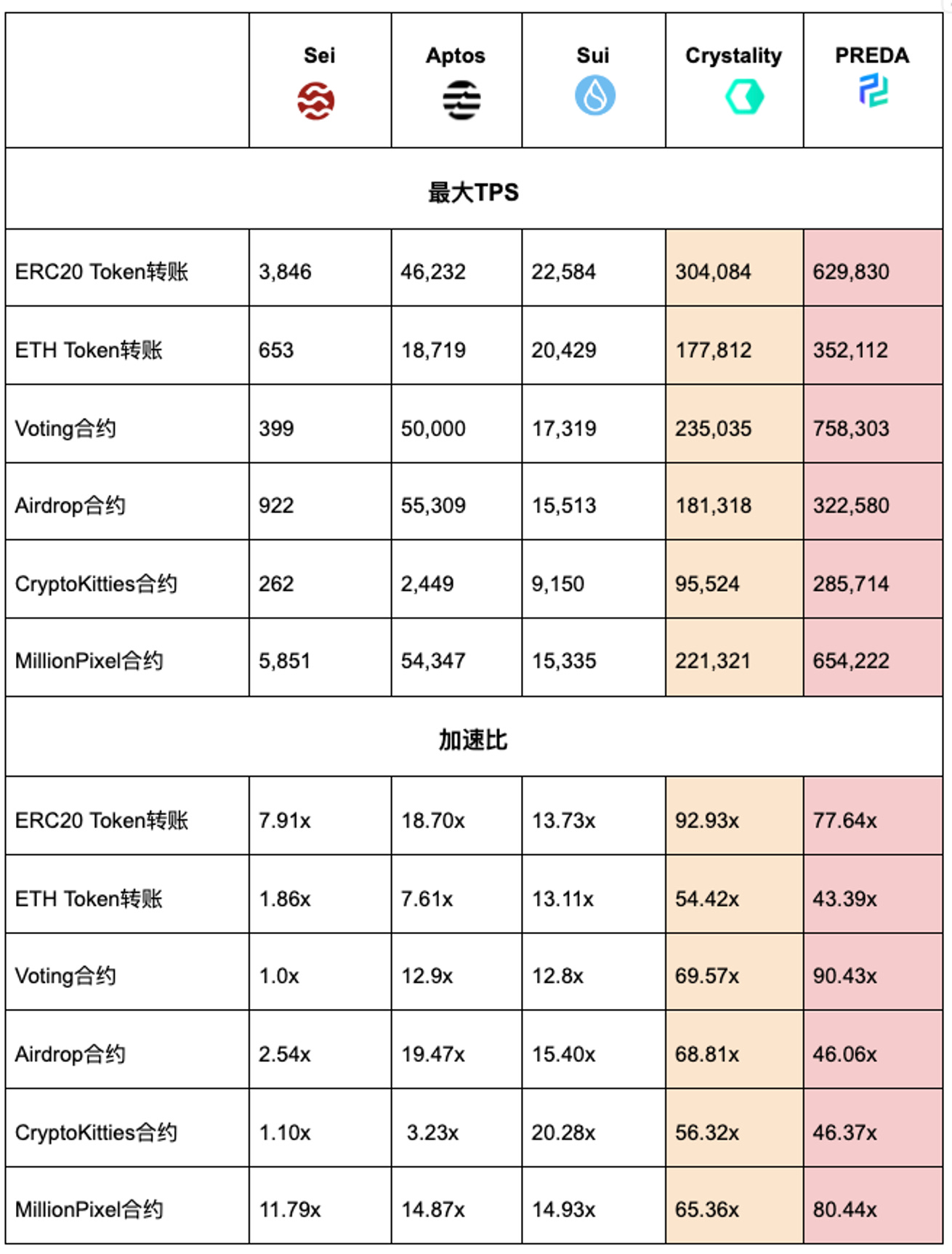
上述の大量のデータを読者が理解しやすくするため、以下では特に代表的な2つの契約の分析に焦点を当てます。
ETHトークン転送コントラクト: 過去のETHトランザクションデータを再生すると、5つのシステムすべての絶対的なスループットとスケーラビリティ比が、ERC20の実験から減少しました。これは、過去のトランザクションの重複アドレスによって引き起こされる状態競合(読み取りと書き込みの競合または書き込みと書き込みの競合)によるもので、並列EVMでのこれらのトランザクションの同時実行を妨げています。
投票コントラクト: Seiコントラクトはほとんどシーケンシャルにしか実行されず、複数のEVMを実行してもスピードアップはありません。アルゴリズムが並列アルゴリズムに変換されない場合、他のシステムでも同様の結果になります。AptosとSuiの並列実装では、"proposal "変数の一時的な結果のために、複数のリソースを異なるアドレスで初期化しなければならない。さらに並列実装では、投票者のアドレスに基づく手動スケジューリングを提供し、投票者のトランザクションを異なる仮想マシンに導き、並列実行のために一時結果にアクセスしなければならない。
実験結果から、以下のことがわかりました:
AptosとSuiは、それぞれ異なる特定のシナリオで最高のパフォーマンスを発揮します。ERC20転送のケースでは、ERC20転送が各トランザクションにランダムに生成されたアドレスを使用するため、競合が非常に少ないという事実により、AptosがSuiを上回ります。対照的に、ETHのテストケースでは、過去のETHトランザクションの再生に関連するコンフリクトの数が多いため、SuiがAptosを上回ります。
Aptosの実行時間分析
以下の表は、2つのコントラクトを実行したときのAptosのパフォーマンス分析データを示しています(同じスマートコントラクトを使用していますが、ランダムに生成された、または過去のトランザクションデータを使用しています)。データはそれぞれランダムに生成されたトランザクションまたは過去のトランザクションです)。パフォーマンス分析には時間がかかるため、テストに使用した並列仮想マシンの数は最大64に制限しました。
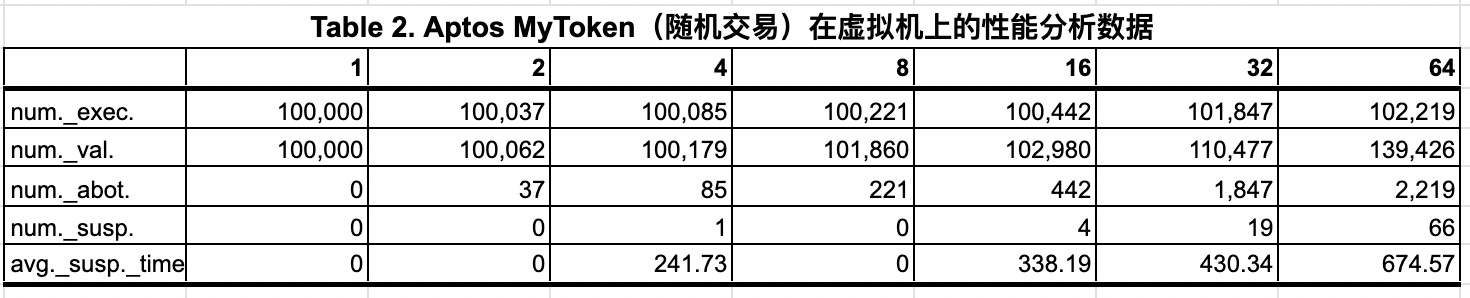
Aptos の取引執行は、執行と検証の2つのステップで構成されており、テストデータによると、「SUSPEND」と表示された執行ステータスの取引が多く、執行に長い時間がかかっています。SUSPEND」は、状態の依存関係が解決されるまでトランザクションの実行が一時停止されることを意味する。64台のVM上でのランダムトランザクションの場合、実行と検証の総数はそれぞれ102,219件と139,426件であった。履歴トランザクションの場合、これらの数は186,948と667,148に増加し、トランザクションのハング数は66から46,913に増加した。結果として、トランザクションの実行で多くの状態競合がある場合、ロールバックは楽観的並列化にとって大きな負担となります。
Suiの実行における時間分析
以下のチャートは、ETHトークンの転送契約テストと投票契約テストに費やされたSuiの時間の内訳を示しています。(1)キューイング時間:トランザクションがTransaction Managerによって選択されるまでの待ち時間、(2)タスク管理時間:トランザクションがSuiのExecuting TxnsハッシュマップまたはPending Txnsハッシュマップに置かれてから、SuiのExecution Driverによって受信されるまでの時間、(3) 関数実行時間:トランザクションがSuiのExecuting TxnsハッシュマップまたはPending Txnsハッシュマップに置かれてから、SuiのExecution Driverによって受信されるまでの時間。関数実行時間:コントラクト関数がExecution Driverのワーカースレッドによって実行される時間。
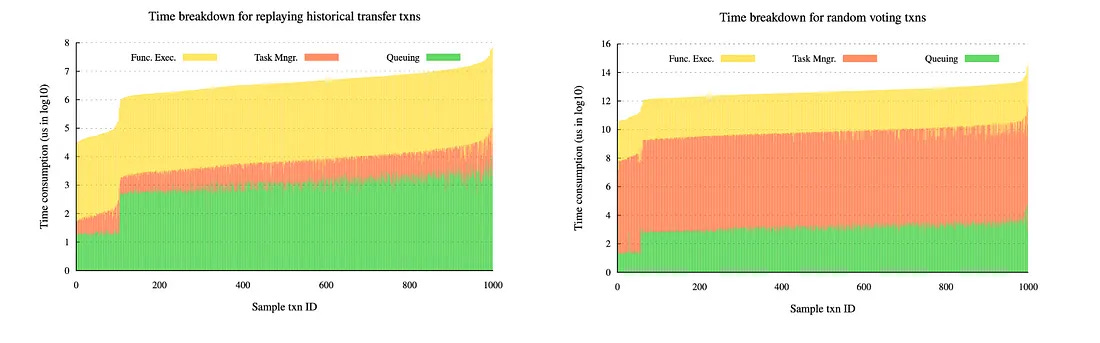
タスク管理時間には、ロックと待機の両方の要素が含まれます。この2つのグラフを比較すると、全体の実行時間に占めるタスク管理時間の割合が、ETHトークン転送テストよりも投票テストの方が大幅に大きいことがわかります。これは、Voting テストでは、共有オブジェクトへのアクセスに競合を避けるための Locking と Waiting が必要なため、タスク管理時間が関数実行時間やキューイング時間よりも 2~4 桁多くなっているためです。対照的に、ETHトークン転送テストでは、所有オブジェクトのみが使用され、同時実行制御がバイパスされるため、タスク管理時間ははるかに短くなります。
AptosとSuiの限界
要約すると、Aptosは楽観的並列化を使用して、競合が存在する場合でも並列トランザクションの実行を可能にします。この楽観的同時実行制御(OCC)に基づくアプローチは、書き込み要求がまばらなデータベースやビッグデータシステムで一般的な、読み取りベースの作業負荷にうまく機能します。しかし、ブロックチェーンシステムでは、このアプローチはオンチェーン実行に伴うガスコストにより、大きなガスオーバーヘッドが発生する可能性があります。実際には、ユーザーは通常、Etherscanのようなオフチェーン・データベースに読み取り専用のリクエスト(過去のトランザクションやブロック・クエリなど)を送信し、書き込みリクエストはオンチェーン実行に使用される。この場合、AptosのようなOCCシステムでは、トランザクションの「サスペンド」やハングが頻繁に発生し、並列VMの全体的なパフォーマンスが低下します。
対照的に、Suiは悲観的並列化を採用しており、トランザクション間の状態依存性を厳密に検証し、ロック機構によって実行中の競合を防ぎます。この悲観的並行制御(PCC)に基づくアプローチは、PCCに関連するオーバーヘッドが無視できるほど小さい、計算集約的なワークロードに適しています。しかし、論理的に単純な処理では、PCC関連のオーバーヘッドが性能のボトルネックになりやすい。現実の世界では、ERC20トークンの移転、Moveトークンの移転、NFTの移転など、ブロックチェーンシステムで実行される多くのトランザクションは比較的単純な操作を伴います。具体的には、ERC20トークンの送金では通常、あるアドレスから一定額を差し引き、別のアドレスに追加します。同様に、Move Token転送やNFT転送では、リソースやオブジェクトをあるアドレスから別のアドレスに移動します。これらの操作は、所有権の確認などの追加チェックを考慮に入れても、非常に高速です。この時点で、PCCに関連するオーバーヘッドが並列システムの性能を制限する要因になります。
これらの課題に対処するため、PREDAはPCCのオーバーヘッドとOCC再実行の必要性をほぼ完全に回避するシステムを提案している。このアプローチは、チェーンの状態を効率的に分割することで、実質的に競合のない並列実行を実現します。
CrystalityとPREDAの性能
CrystalityとPREDAは、すべてのコントラクトテストにおいて、Sei、Aptos、Suiを大幅に上回っており、PREDAはWASMではなくネイティブバイナリモードで実行するため、上回っている。PREDAは、WASMではなくネイティブバイナリモードで実行されるため、特に優れたパフォーマンスを発揮します。
システムの状態を分割して維持するために使用する、コントラクト状態の異なる範囲を定義します。
1つのVMから別のVMへのトランザクションの実行フローの切り替えを可能にする。
PREDAの中核は、プログラム可能なコントラクトスコープの導入です。これは、コントラクトの状態を、重ならない、並列可能な、きめの細かい部分に分割します。Asynchronous Functional Relay)を使用して、異なるEVM間の実行フロースイッチを記述します。
これらの概念の意味をさらに説明しましょう。PREDAでは、コントラクト関数は複数の順序付けられたステップに分解され、各ステップは競合を発生させない単一の並列可能な状態の断片に依存します。
一例として、トークン転送には通常2つのステップが含まれます。送信者の状態にアクセスして指定された量のトークンを抽出する抽出ステップと、受信者の状態にアクセスして適切な量のトークンを入金する入金ステップです。各トランザクションのすべてのステップの実行を同期させようとする。SenderやRecipientが同じ場合など、アクセスされた状態が2つのトランザクション間で共有または更新される場合、2つのトランザクションを並列に実行することはできません。
しかしながら、PREDAは、トランザクションのステップがデータアクセスの依存関係に従って分解され、各ステップが他のステップから独立して非同期に実行されることを可能にする、切り離し可能で非同期なメカニズムを採用している。同じ状態へのアクセスは、元のトランザクションブロックで決定され、コンセンサスアルゴリズムによって保証された順序、すなわちブロック作成者によってソートされた順序で厳密に直列化される。
例えば、トークン転送トランザクションTxn 0(アドレス状態Aから状態Bへのトークン転送)とTxn 1(状態Aから状態Cへのトークン転送)は、(それぞれTxn 0とTxn 1について)順番に2回Aにアクセスでき、その後並行してBとCにアクセスできます。
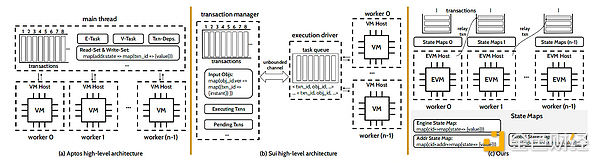
Aptos、Sei、PREDAにおける並列実行のアーキテクチャ比較
PREDAの限界とCrystalityの制限
PREDAとCrystalityはブロックチェーンシステムに力を与え、大きなパフォーマンス上の利点をもたらすことができますが、以下の点で制限もあります。
並列EVM間の作業負荷の不均衡
Crystalityのデータ分割と実行フローのリダイレクトメカニズムは、実行時に並列EVMの負荷不均衡につながる可能性があります。私たちは、MyTokenコントラクトで過去のETHトークン転送トランザクションを再生したときに、この問題を観察しました。
負荷分散を評価するために、各EVMで実行されたトランザクションの数をカウントし、元のトランザクションとリレートランザクションの両方を含めて、これらの数の極性と標準偏差を計算しました。その結果、64個のEVM上で実行されたトランザクション数の極端な偏差は、2個のEVM上の範囲に匹敵することが示され、一部のEVMアドレスにホットスポット問題(すなわち、アドレスのサブセットで発生する履歴トランザクションの集中)が存在することが示唆された。ETHデータセットをさらに調査した結果、各ホットスポットアドレスには4000件以上のトランザクションが含まれていることが判明した。ここで重要なのは、AptosとSuiもこのケースでは並列実行ができないことを理解していることです。
私たちのテストデータは、EVMの数が増えるにつれて標準偏差が減少することを示しています。これは、EVMを増やすと負荷不均衡の問題が緩和されることを意味します。
ブロックチェーン上のホットスポット問題を解決するためには、トークンの送受信に単一のアドレスではなく複数のアドレスを使用することが考えられます。負荷の不均衡が、同じ仮想マシンにマッピングされた複数の非ホットスポットアドレスによって引き起こされている場合は、データ移行などのシャーディングブロックチェーンの既存の方法が役立つ可能性があります。
手続き書き換え
PREDAとCrystalityのもう1つの顕著な制限は、開発者がディレクティブを使ってスマートコントラクトを書き換える必要があることです。Solidity、Move、またはRustで書かれた既存のスマートコントラクトを、同等のCrystalityスマートコントラクトに自動的に翻訳できるツールがあれば、開発者のエクスペリエンスが大幅に最適化されます。
自然言語処理における技術的進歩は、自動コード生成の可能性を大きく高めています。これらの進歩は、ビッグデータ向けのSQLからMapReduceへの翻訳や、ディープラーニング向けの計算グラフから行列への翻訳など、ルールベースやパターンベースのコンパイラ翻訳技術と組み合わさることで、スマートコントラクト向けの自動翻訳ツールの開発に拍車をかけることができます。
Sei、Aptos、Sui、Crystality/PREDAの性能比較は、ブロックチェーン並列化の発展分野を浮き彫りにしています。aptos(Seiとともに)とSuiは、それぞれ楽観的並列化メカニズムと悲観的並列化メカニズムの可能性を示しており、それぞれが異なるシナリオで優位性を示しています。しかし、CrystalityとPREDAの大幅な性能向上は、より高度な並列化モデルが、より高いレベルのスケーラビリティと効率を引き出す鍵になる可能性を示唆しています。
ブロックチェーン領域における並列化に対する3つの主なアプローチに関する調査と観察をまとめるために、要約表を作成しました。この投稿から「収穫」を得たいのであれば、それがこの表にあるものです。
韓国は11月以降、機関投資家による違法な空売りの取り締まりを強化し、世界的な銀行の間で広範な不正行為が発覚した。韓国は空売り禁止期間を2025年第1四半期まで延長する意向だ。
WilfredBinance、Chrome拡張機能攻撃への対応で精査に直面。プラットフォームのセキュリティやコミュニケーションに懸念がある中、補償やユーザーの責任をめぐって議論が続いている。
 Huang Bo
Huang Boブラウザの拡張機能は、実行ファイルを直接実行するのと同じくらい危険なので、インストールする前に注意深く吟味すること。
 JinseFinance
JinseFinanceレイヤ2中心のイーサネット・エコシステムは、本質的に多様性に富み、スケーリング設計、VM設計、その他の技術的特徴に対して、より自然に多様なアプローチを可能にする。
JinseFinance調査の結果、このトレーダーは、グーグル・クローム・ブラウザのセキュリティ侵害が、特に特定の暗号ウォレット拡張機能を狙ったキーロガーによって実際に引き起こされたことを確認した。
 Kikyo
Kikyoバージョン 10.28 の MetaMask の導入により、ユーザーは、これらの一意のトークンの表示と転送を簡素化する専用の NFT タブを利用できるようになりました。
 Beincrypto
Beincryptoクォン氏の弁護士は、モンテネグロ当局が定めた30日間の拘留延長期間を短縮するよう努める予定です。
 cryptopotato
cryptopotatoより多くの暗号通貨プロジェクトが展開されるにつれて、主流の採用には簡素化されたマルチチェーン エクスペリエンスが必要になります。
 Cointelegraph
Cointelegraphセガのゲームプロデューサー菊池正義氏は「今後のゲームはクラウドゲームやNFTなどの新たな領域に拡大するのは自然な流れだ」と述べた。
Cointelegraphセガのプロデューサーである菊地正義氏は、「クラウドゲームやNFTなどの新しい分野にまで拡大することは、ゲームの将来にとって自然な延長です。
Cointelegraph