OpenAI Soraは公式に爆発的に売れており、ウェブページも大盛況だ!
サム・アルトマン:"GPT-1の瞬間のビデオバージョンはこちら"
 JinseFinance
JinseFinance

出典:Metaverse Daily Explosion
公開テストが始まる前に、OpenAIはテキスト生成動画モデル「Sora」の予告編を公開し、技術、インターネット、ソーシャルメディアのコミュニティを驚かせました。
OpenAIが公開した公式ビデオによると、Soraはユーザーから提供されたテキスト情報に基づいて、複雑なシーンの最大1分の「ハイパービデオ」を生成することができ、画像が詳細でリアルなだけでなく、モデルはカメラの動きの感覚もシミュレートする。
公開されたビデオ効果から、業界は Sora の現実世界を理解する能力に興奮している。
公開された動画効果から、業界はSoraの現実世界理解能力に期待を寄せています。
OpenAIはSoraを直接「ワールドシミュレータ」と呼び、物理世界の人、動物、環境の特徴をモデル化できると宣言している。しかし同社は、Soraがまだ完璧ではなく、理解不足や潜在的なセキュリティの問題を抱えていることも認めている。
その結果、Soraはごく少数の人にしかテストが公開されておらず、OpenAIはSoraがいつ一般公開されるかをまだ発表していませんが、同様のモデルを開発している企業がギャップに気づくには十分な衝撃をもたらしました。
OpenAI's text-generated video model Sora is now a "shocker" in China.
セルフメディアは「現実は存在しない」と叫び、ネット界の大物もSoraの実力を吹聴した。360の創設者である周宏毅氏は、Soraの誕生はAGIの実現が10年から2年程度に短縮される可能性があることを意味すると述べた。
Soraの炎上は、OpenAIが48本の動画を公開したことに端を発している。|にできるようにあなたがそれをすることができます本当に出くわすことあなたは、実際には私のパートナーとi約束、誰でも素早くこの人これらの一見正確にどのように{}人のことを忘れることができます。
1分のビデオ、ネオンに照らされた通りを歩く赤いドレスの女性、現実的なスタイル、滑らかな画像、最も驚くべきは、クローズアップの女性の主人公であっても、顔の毛穴、シミ、ニキビ跡がシミュレートされ、メイクオフカードパウダーの効果は、ライブ放送に匹敵する美容フィルター、首のネックラインをオフにし、さらに正確な "リーク "です。
リアルなキャラクターに加え、Soraは動物や環境のリアリティもシミュレートできる。ビクトリア朝冠鳩をマルチアングルでクローズアップした動画では、鳥の体中の青い羽が冠まで超クリアなレンダリングで表現され、赤い目玉や呼吸数のダイナミクスに至るまで、AIが生成したのか人間が撮影したのか見分けがつかないほどだ。
非現実的なクリエイティブ・アニメーションの場合、ソラの生成効果もディズニー・アニメーション映画のような絵のセンスを実現しており、ネットユーザーはアニメーターのどんぶり勘定を心配している。
そして、Soraのテキスト生成ビデオモデルは、ビデオの持続時間と画像効果に改善をもたらすだけでなく、レンズと撮影の移動軌跡、ゲームの一人称視点、空中視点、さらには映画のワンショットを最後までシミュレートすることもできる。
OpenAIが公開した素晴らしい動画を見れば、インターネットコミュニティやソーシャルメディアの意見がSoraに衝撃を受けた理由がわかるだろう。
では、Soraはどのようにしてシミュレーション機能を実現しているのでしょうか?
オープンAIが発表したSoraのテクニカルレポートによると、このモデルは画像データ生成のこれまでのモデルの限界を超えつつあります。
テキストから生成された視覚画像に関するこれまでの研究では、リカレントネットワーク、生成的敵対ネットワーク(GAN)、自己回帰変換器、拡散モデルなど、さまざまなアプローチが使われてきましたが、共通しているのは、視覚データのカテゴリが少ないこと、短い動画、固定サイズの動画に焦点を当てていることです。
SoraはTransformerベースの拡散モデルを採用しており、グラフ生成プロセスを順方向プロセスと逆方向プロセスの2つのフェーズに分けることができます。
順方向プロセスの段階では、実画像から純粋なノイズ画像への拡散プロセスをシミュレートします。具体的には、このモデルは、画像が完全にノイズだらけになるまで、画像に徐々にノイズを加えます。逆プロセスは順プロセスの逆で、モデルはノイズ画像から徐々に元の画像を復元します。ポジティブとネガティブ、現実と現実の間を行ったり来たり、オープンAIはこのようにして、機械Soraに視覚の形成を理解させる。
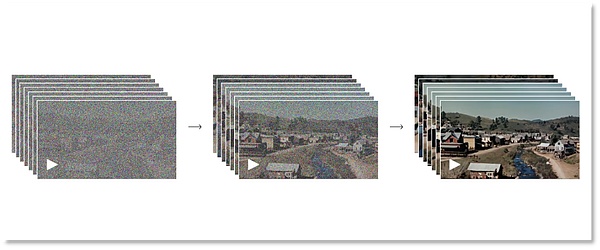 完全なノイズからクリアな画像へ。
完全なノイズからクリアな画像へ。
もちろん、このプロセスは、モデルが徐々にノイズを除去し、画像にディテールを復元する方法を学習するため、反復学習が必要です。この2つの段階を繰り返すことで、Soraの拡散モデルは高品質の画像を生成することができる。このモデルは、画像生成、画像編集、超解像などの分野で優れた性能を発揮している。
Soraが高精細・超精細を実現できるのは、以上のようなプロセスによるものです。しかし、静止画像から動的な動画まで、モデルを学習させるには、さらにデータを蓄積し、学習させる必要があります。
拡散モデルに基づいて、OpenAIはビデオや画像などのあらゆる種類の視覚データを統一された表現に変換し、Soraの大規模な生成学習に使用します。
Soraが使用する表現は、OpenAIによって "ビジュアルパッチ "として定義されています。
Soraが使用する表現は、OpenAIによって「ビジュアルパッチ」と定義されています。
研究者たちはまず、ビデオを低次元の潜在空間に圧縮し、その後、この表現を時空間パッチに分解しました。これは、ビデオからパッチへの移行を容易にし、複数の種類のビデオや画像を処理する生成モデルの学習に適した、拡張性の高い表現形式です。
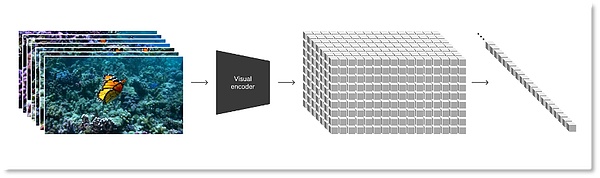 視覚データをパッチに変換する
視覚データをパッチに変換する
少ない情報と計算でSoraを学習させるために、OpenAI は動画圧縮ネットワークを開発しました。まず、動画を低次元潜在空間のピクセルレベルまで縮小し、圧縮された動画データを用いてパッチを生成します。同時にOpenAIは、圧縮された情報をピクセル空間にマッピングし直すために、対応するデコーダーモデルもトレーニングしました。
視覚的なパッチ表現に基づいて、研究者たちは異なる解像度、持続時間、アスペクト比の動画/画像に対してSoraを訓練することができました。推論フェーズに移行すると、Soraはビデオのロジックを決定し、ランダムに初期化されたパッチを適切なサイズのグリッドに配置することで、生成されるビデオのサイズを制御することができます。
OpenAIは、Soraが現実世界の人、動物、環境をリアルにシミュレートし、3Dの一貫性、時間的な一貫性、ひいては物理世界のリアルなシミュレーションを達成しながら、忠実度の高いビデオを生成する能力を含む、ビデオモデルがスケールで訓練されたときにエキサイティングな能力を示すと報告しています。その過程で、Soraは強力な能力を発揮するが、一般ユーザーは体験する方法がなく、現時点では、X @ OpenAIの創始者であるSam Altmanが第二の手となり、ネットユーザーがSoraでビデオを生成するのを助け、その効果を見るために公衆に公開することしかできない。
これはまた、Soraが本当にOpenAIが公式に言うほど優れているのかという疑問を投げかけるものでもある。
これに対してOpenAIは、このモデルにはまだいくつかの問題があると述べています。初期のGPTのように、Soraは現在「錯覚」を持っており、このエラーは主に視覚的なビデオ結果でより具体的に現れています。
例えば、人に対するトレッドミルのトラックの動きや、グラスが割れてグラスから液体が流れ出る時間的ロジックなど、基本的な相互作用である物理プロセスの多くを正確にモデル化していません。
次のビデオクリップ「考古学者がプラスチックの椅子を掘り起こす」では、椅子が砂から「浮いて」いる。
そして、ネットユーザーが「オオカミの分裂」と名付けた、どこからともなく現れたオオカミの子もいる。
オオカミは前と後ろの区別がつかないことがある。
このような間違いは、ソラが物理的な世界における動きの論理について、まだまだ理解と訓練を必要としていることを証明しているようだ。加えて、ソラの直感的な視覚体験は、ChatGPTのそれよりも倫理的で安全なリスクをもたらす。
以前は、ヴァンセンヌの地図モデルMidjourneyは、「絵が真実である必要はありません」と人間に伝えました。
予測するに、もしSoraが生成した動画が悪意を持って悪用され、詐欺や中傷、暴力やポルノの拡散に従事すれば、その結果は計り知れないものになるだろう。
OpenAIは、Soraがもたらすかもしれないセキュリティの問題も考慮しており、Soraが招待制でごく少数の人だけにテスト公開されているのはそのためだろう。OpenAIは、いつ一般に利用可能になるかのスケジュールを示しておらず、公式ビデオリリースから判断すると、他社がSoraモデルに追いつくのにそれほど時間はないだろう。
サム・アルトマン:"GPT-1の瞬間のビデオバージョンはこちら"
JinseFinanceこれは、あるクジラ投資家(あるいは投資家グループ)が、Compound DAOにそのガバナンス・トークンが収益を生むように強制した話である。
JinseFinanceソラーナ,再構築,持統ネットワーク,ソラーナに再構築は必要か? ゴールデンファイナンス, Jitoの最新製品についての簡単な分析。
JinseFinanceエーテルの現状、潜在的な触媒、需給の変化、その他の側面について、綿密だがバランスの取れた分析を行い、「エーテルの価格はこれから上昇するのか」という疑問について、保守的だが体系的に楽観的な見解を示している。
JinseFinance2日前、外国メディアはソラのコアチームにインタビューを行い、元のビデオを見て、何も言うことはありません、シーンは馬発展改革委員会主任の演説のようなものです。
JinseFinance中国は最近、初のGenAIアニメシリーズ「前秋思松」を放映し、SoraのようなツールとともにアニメーションにおけるAIの役割を紹介した。この動きは、メディアにおけるAIの統合を推進する中国の動きを反映したもので、創造性や雇用の安定への影響に関する議論を巻き起こしている。
 Weatherly
Weatherlyハリウッド監督が8億ドルのスタジオ撤退を急ぐ中、そらの神々しい写真が顎を落とす。
JinseFinanceソラがリリースされて間もなく、ステイブルAIはステイブル・ディフュージョン3をリリースした。
JinseFinanceAIとWeb3の融合には、分散型演算、アルゴリズムとモデルのコラボレーション、分散型ビッグデータ、AI対応Dappsという4つの道がある。
JinseFinance国内で従業員への給与支払いに仮想通貨を使用した場合、法的リスクはありますか?
JinseFinance