ビットコインに隠されたノーベル賞:投票のパラドックスとアローの不可能性定理
BTC,ビットコインに隠されたノーベル賞(II):投票のパラドックスとアローの不可能性定理 ゴールデンファイナンス,サトシ・ナカモトが考えを変えた。
 JinseFinance
JinseFinance

ファッションは周期的であり、ウェブ3も同様である。
ニアはAIのパブリックチェーンとして「復活」した。創業者トランスフォーマーの共同執筆者としての地位により、NVIDIAのGTCカンファレンスに出席し、革をまとったオールド・イエローと生成AIの未来について話すことができた。io.net、Bittensor、Render Networkの本拠地であるSolanaは、AIコンセプトチェーンへの転換に成功しており、Akash、GAIMIN、Gensyn、その他GPUコンピューティングに関わる新興企業も存在する。
視野を広げると、コイン価格の上昇と並んで、いくつかの興味深い事実を見つけることができます。
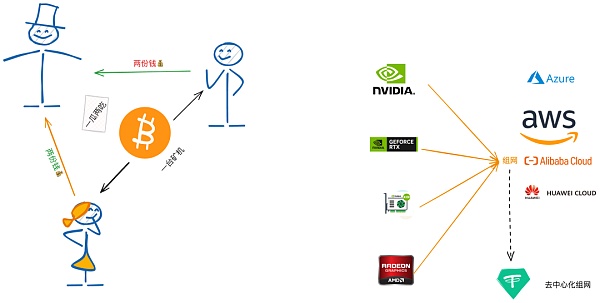
GPUコンピューティングパワーの戦いが始まる。strong>GPUコンピューティングパワーの戦いは分散型プラットフォームに到来し、より多くのコンピューティングパワーはより効果的なコンピューティングに等しく、CPU、ストレージ、GPUは互いにおんぶにだっこです。
クラウドから分散型への移行におけるコンピューティングパラダイム、その背後にあるのは、GPUのコンピューティングパワーです。
クラウドから分散へのコンピューティングパラダイムの移行において、AIトレーニングの需要が推論にシフトする背後で、オンチェーンモデルはもはや空虚なナンセンスではありません;
基盤となるソフトウェアとハードウェアの構成と動作ロジックのインターネットアーキテクチャは根本的に変わっておらず、分散演算層はネットワークの役割への刺激の多くを想定しています。
まず第一に、区別の概念は、クラウドコンピューティングパワーのWeb3の世界は、クラウドマイニングの時代に生まれた、ユーザーがマイナーに支出の膨大な量を購入する必要性を排除し、販売のためにパッケージ化された電力のマイニングマシンを指しますが、電力メーカーはしばしば "過剰販売されています!しかし、電力ベンダーはしばしば「過剰販売」を行い、例えば100台のマイニングマシンを105人に混ぜて販売し、超過収益を得るなど、最終的には詐欺に等しい用語となっている。
この記事におけるクラウドコンピューティングパワーとは、特にGPUベースのクラウドベンダーのコンピューティングリソースを指しており、ここでの問題は、分散型コンピューティングプラットフォームがクラウドベンダーの表の操り人形なのか、それとも次のバージョンのアップデートなのかということだ。
伝統的なクラウドベンダーとブロックチェーンの組み合わせは、我々が考えていたよりも深く、例えば、パブリックチェーンノード、開発、毎日のストレージは、基本的にAWS、アリクラウドとファーウェイクラウドの周りに、物理的なハードウェアの高価な投資を購入する必要性を排除し、実施するが、もたらされる問題を無視することはできません、ネットワークケーブルを抜くの極端なケースでは、引き起こす可能性があります。パブリックチェーンがダウンし、分散化の精神の重大な違反である。
一方、分散型演算プラットフォームは、ネットワークの堅牢性を維持するために「サーバールーム」を直接構築するか、IO.NETのようなインセンティブネットワークを直接構築する。その証拠に、MLのトレーニングや推論、グラフィックスのレンダリングなどにGPUを実際に使用する大企業や個人、学者はほとんどいません。
高いコイン価格とFOMO感情に直面して初めて、分散型算術がクラウド算術詐欺であるという非難はすべて消え去りました。
AIモデルに必要な計算パワーは、トレーニングから推論へと進化しています。
OpenAIのSoraを例にとると、同じくTransformerテクノロジーをベースにしているものの、パラメータ数はGPT-4の数兆個に比べ、1,000億個以下と推定され、Likun Yang氏によると、わずか30億個であるため、トレーニングコストが低くなるという。パラメータ数が少なく、必要な計算資源が比例して減衰していくため、これも非常に理解しやすい。
しかし一方で、Soraはより強力な「推論」能力を必要とするかもしれない。これは、指示に基づいて特定のビデオを生成する能力として理解できる。比較的単純で、既存のコンテンツに基づく法律の要約として理解することができ、計算能力の無脳の山は、精力的に奇跡から抜け出す。
前の段階では、AIのコンピューティングパワーは、主に訓練レベル、推論能力のごく一部に使用され、基本的にNVIDIAによってラウンド製品のすべての種類が、物事の導入後にGroq LPU(言語処理ユニット)で、より良い推論能力を変更し始めた。しかし、Groq LPU (Language Processing Unit)が登場した後、物事は変わり始め、より良い推論能力、大きなモデルの間引きと精度の向上に重なり、論理を語る脳を持つことが徐々に主流になりつつあります。
さらに、GPUの分類について補足しておくと、AIを救うのはゲーム臭いものだとよく見かけますが、これはゲーム市場での高性能GPUの旺盛な需要が、ゲームやAIの錬金術に使われる4090グラフィックカードのような研究開発費をカバーしているからで、理にかなっているのですが、徐々にゲーミングカードや演算カードが高性能化していくことに注意が必要です。ゲーミングカードと演算カードは徐々に切り離されていくだろう。これは、ビットコインの採掘機がパソコンから専用の採掘機へと発展していく過程と似ており、使用されるチップはCPU、GPU、FPGA、ASICと順を追っていく。
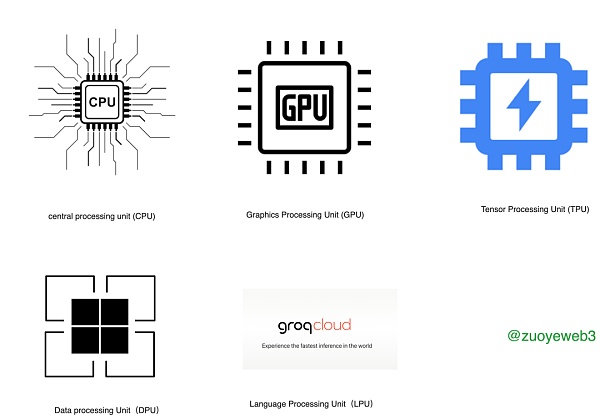
AI技術、特にLLM路線の成熟と進歩に伴い、より多くのTPU、DPU、LPUに対して同様の試みが行われるようになるでしょうが、もちろん、現在の主力製品は依然としてNVIDIAのGPUです。以下の議論はすべてGPUに基づいており、LPUはどちらかというとGPUを補完するもので、完全に取って代わるには時間がかかるでしょう。
分散型コンピューティング・パワーへの競争は、GPUの奪い合いではなく、むしろ新しい利益モデルを確立しようとするものです。
分散型コンピューティングの競争は、GPUの奪い合いではなく、新たな利益モデルを構築しようとするものです。
GPUの奪い合いは、GPUの奪い合いではなく、新たな利益モデルを構築しようとするものです。
絶対的な独占状態により、コンシューマー向けのRTX 4090からエンタープライズ向けのA100/H100まで、GPUは大混戦となり、クラウドベンダーはGPUを買いだめしている。しかし、Google、Meta、Tesla、OpenAIのようなAI企業はすべて、独自のチップを作る動きや計画を立てており、国内企業はすでにHuaweiのような国産ベンダーに目を向けているため、GPUトラックはまだ信じられないほど混雑しています。
伝統的なクラウドベンダーにとって、売り物は実際には演算とストレージスペースなので、AI企業ほど自社製チップを使う緊急性はありませんが、分散型演算プロジェクトにとっては、現在はプロセスの前半、つまり伝統的なクラウドベンダーと演算を奪い合うビジネスであり、安価で入手しやすいことを重視していますが、将来的にはビットコインマイニングのようにビットコインマイニング、Web3 AIチップの出現はあり得ない。
さらに、イーサがPoSに移行して以来、暗号通貨分野では専用ハードウェアが少なくなってきており、佐賀県携帯、ZKハードウェアアクセラレーション、DePINなどの市場が小さすぎるので、分散型演算にはWeb3機能を搭載した専用AIカードの道を探ってほしい。
分散演算は、クラウドへの次のステップ、または追加です。
GPUの演算能力は、GPUの仕様やアプリケーションの並列性などの最適化に関係なく、演算速度の指標として最も一般的に使用されているFLOPS(Floating Point Operations Per Second)と比較されることがよくあります。これは、GPUの仕様や並列性などの最適化に関係なく、コンピューティング速度の指標として最も一般的に使用されるものです。
ローカルコンピューティングからクラウドまで、約半世紀、コンピュータの誕生から分散の概念は、LLMの推進で分散と演算の概念の初めから存在している、分散と演算の組み合わせは、もはや以前のように漠然としている、私はできるだけ既存の分散演算プロジェクト、唯一の2つの次元の検討をまとめる:
GPUなどのハードウェアの数、つまり計算速度を調べると、ムーアの法則によると、新しいGPUほど計算能力が強く、同じ仕様の数が多いほど計算能力が高くなる。
デュアルトークン、ガバナンス機能、エアドロップのインセンティブなど、Web3の業界の特徴であるインセンティブ階層組織は、コインの短期的な価格に集中しすぎるよりも、各プロジェクトの長期的な価値を理解しやすくし、長期的には、所有または派遣できるGPUの数だけを見ます
。li>この観点からすると、分散型演算はやはりDePINルートの「既存のハードウェア+インセンティブネットワーク」をベースにしている、つまりインターネットアーキテクチャがボトムで、分散型演算層は「ハードウェアの仮想化」であることに変わりはありません。分散型演算層は「ハードウェアの仮想化」のマネタイズであり、アクセスのないアクセスを重視し、実際のネットワークは依然としてハードウェアの協力を必要としている。
ブロックチェーンのトリレンマフレームワークでは、分散化された演算のセキュリティは特別に考慮する必要はなく、主に分散化とスケーラブルであり、後者はGPUネットワーキングの目的である。後者はGPUネットワーキングの利用であり、現在AIが隆盛を極めている状態である。
パラドックスから言えば、もし分散型演算プロジェクトが作られるのであれば、そのネットワーク上のGPUの数は可能な限り多くあるべきです。それ以外の理由は、GPTやその他の大きなモデルが爆発的に増えており、トレーニングや推論ができないGPUの規模はないからです。
もちろん、クラウドベンダーの絶対的な制御に比べて、現段階では、分散型演算プロジェクトは、少なくともGPUリソースやその他のメカニズムのアクセスや自由な移行を設定することはできませんが、改善の資本効率のうち、将来的には、マイニングプールの製品の形成に似ていない可能性があります。
スケーラビリティの面では、GPUはAIだけでなく、クラウドコンピューティングやレンダリングにも使用することができ、たとえば、Render Networkはレンダリングに焦点を当て、Bittensorなどはモデルトレーニングを提供することに焦点を当て、より率直に言えば、スケーラビリティは、使用や目的のシナリオに等しくなります。
そのため、GPUとインセンティブ・ネットワークに、分散化とスケーラビリティという2つのパラメーターを追加して、4点比較にすることができます。

上記のプロジェクトにおいて、レンダー ネットワークは実は非常に特殊で、本質的には分散レンダリング ネットワークであり、AIとは直接の関係はありません。AIのトレーニングや推論では、SGD(確率的勾配降下法)であれ、バックプロパゲーション・アルゴリズムであれ、リンクは連動しており、一貫性が要求されるが、レンダリングなどの作業はそうである必要はなく、タスクの分散を容易にするために、ビデオと画像に分割されることが多いだろう。
このAIのトレーニング機能は、主にio.netと並行しており、io.netのプラグインのようなものとして存在しています。 GPUがすべてなので、どうすればいいのかが重要です。さらに先見性があるのは、Solanaの過小評価時に離反したことで、レンダリング用のネットワークの高性能要件に適していることが証明されました。
第二に、io.netの暴力的なGPU-for-GPU規模開発ルートは、現在の公式ウェブサイトは、分散型演算プロジェクトでは、他のライバルと桁違いの存在の最初のギアにある、完全な18万GPUをリストし、スケーラビリティ、io.netは、AIの推論に焦点を当て、AIの訓練は、付随的な手作業に属します。トレーニングは手作業に属する。
厳密に言えば、AIのトレーニングは分散配置には適していません。 軽量なLLMであっても、パラメータの絶対数はそれほど少なくなく、集中コンピューティングの方がコスト効率が良いのです。トレーニングにおけるWeb 3とAIの組み合わせは、ZKやFHE技術のようなデータプライバシーや暗号操作に関するものである一方、AI推論Web 3は非常に有望である。 一方では、GPU性能に対する要求が高くなく、ある程度の損失も許容できる。他方では、AI推論はアプリケーション側に近く、ユーザーから見ればインセンティブがより大きい。
もう一つの暗号通貨交換会社であるファイルコインも、io.netとGPU利用協定を結んでおり、ファイルコインはio.netと並行して自社のGPU1,000個を利用するとのことで、先達と後継者が手を取り合っているようなもので、頑張ってほしいものです。
繰り返しになりますが、Gensynはまだオンライン化されておらず、ネットワーク構築の初期段階であるため、GPUの数は発表されていませんが、主な利用シーンはAIのトレーニングであり、個人的には高性能GPUの数はRender Networkのレベルを下回ることはないだろうと感じています。ネットワークレベルは、AI推論、AIトレーニングとクラウドベンダーと比較して、直接の競争であり、具体的なメカニズムの設計でも、より複雑になります。
具体的には、Gensynは、モデルの訓練の妥当性を確保する必要があり、訓練の効率を向上させるために、オフチェーンコンピューティングパラダイムの大規模な使用は、モデルの認証とアンチチートシステムは、マルチロールゲームである必要があります:
提出者:最終的にトレーニング費用を支払うタスクの開始者。
解答者:モデルを訓練し、妥当性の証明を提供する。
検証者:モデルを検証します。
内部告発者:検証者の働きをチェックする。
全体として、動作はPoWマイニング+プルーフ・オブ・オプティミズムの仕組みに似ており、アーキテクチャは非常に複雑です。 おそらく計算をチェーンの下に移すことでコストを削減できるのでしょうが、アーキテクチャの複雑さはさらなるランニングコストをもたらすでしょう。AIの推論に焦点を当てた分散型演算が主流となっている現在、Gensynの評判は上々です。ここでもGensynに幸あれ。
最後になりますが、基本的にRender Networkと同時期にスタートしたAkashはCPU分散にフォーカスしていますが、Render Networkは早い段階でGPU分散にフォーカスしており、AIの爆発的な普及の両側がGPU+AIになるとは予想していませんでした。違いは、Akashがより推論に重点を置いていることだ。
Akashの復活の鍵は、アップグレードされたイーサリアムにマイニングの問題を見いだし、アイドルGPUが女子大生に使われているという名目でIdle Fishに出品されるだけでなく、いずれにせよ人類の文明に貢献するAIを一緒に行うために使われるようになったことだ。
しかし、Akashは基本的にトークンの流通が充実しているという利点がある。何しろ非常に古いプロジェクトで、PoSでよく使われるプレッジシステムも積極的に採用しているが、チームをどう見るかというと仏教色が強く、高飛車なio.netのような若々しさはない。
そのほか、エッジクラウドコンピューティングのTHETA、ニッチな分野のAIコンピューティングソリューションを提供するPhoenix、Bittensor、Ritualなど、スペースの関係でここには掲載できないが、GPUの数がどうしても見つからない新旧コンピュータもある。
コンピューティングの歴史を通して、あらゆる種類のコンピューティング・パラダイムが、分散化されたバージョンの構築を可能にしてきました。唯一の残念な点は、主流のアプリケーションに影響を与えなかったこと、そして現在のWeb3コンピューティング・プロジェクトがまだ大部分が利己的なプロジェクトであることです。現在のWeb3コンピューティング・プロジェクトは、まだ大部分が業界の自己改良であり、Nearの創設者たちがGTCカンファレンスに行ったのは、Transformerの著者であるからであって、Nearの創設者たちのためではない。
より悲観的なのは、現在のクラウドコンピューティング市場の規模とプレイヤーが強力すぎることだ。io.netはAWSを置き換えることができるが、GPUの数が十分に多ければ可能だ。何しろAWSは長い間、オープンソースのRedisをビルディングブロックとして使ってきたのだから。
ある意味、オープンソースと分散化のパワーは同等ではなく、分散化プロジェクトはDeFiのような金融分野に過度に集中している一方で、AIは主流市場への重要な道かもしれない。
BTC,ビットコインに隠されたノーベル賞(II):投票のパラドックスとアローの不可能性定理 ゴールデンファイナンス,サトシ・ナカモトが考えを変えた。
JinseFinance暗号の世界における混乱と革新の欠如は、一つの疑問を抱かせる:我々は望ましい未来に向けて実質的な一歩を踏み出しているのだろうか?
JinseFinanceCatizen,Telegram,Gamefi,TG投資パラドックスの下でCatizenに投資する理由とCatizenの希少性について語る Golden Finance,TGエコシステムの下で今日もCatizenに強気であり続ける理由。
JinseFinance夏の旅行シーズンが始まると、必然的に燃料消費量が増える。しかし、不思議な現象が起きている。原油価格が6月の安値から反発する一方で、ガソリン価格は比較的安定しているのだ。
 Wilfred
Wilfredイーロン・マスクは、単に誤解された天才であり、不適合な手段を使っているだけなのか、それとも自分が果たせる以上の約束をする圧倒的な何でも屋なのか。彼を愛そうが馬鹿にしようが、私たちはかなり長い間、彼の噂を耳にすることになりそうだ。
 Catherine
CatherineHuobiが買収の噂の対象となったのはこれが初めてではありません。
 Beincrypto
Beincrypto最大の暗号通貨取引所の 1 つである Huobi は現在、中国へのサービスの拡大を検討しています。
 Bitcoinist
Bitcoinist2023年は仮想通貨市場にとってはかなり良いスタートを切ったが、フォビにとってはそうではなかった.
 cryptopotato
cryptopotatoフォビコリアは独立した取引所になりたいと考えています。すべての株式を購入し、ブランドを変更して、Huobi Global から距離を置きます。
cryptopotato Nulltx
Nulltx