Understanding Arweave donations: exploration and simulation
In this article, we discuss in detail how storage donation works and then study its characteristics and risk profile by simulating its execution using Markov chains.
 JinseFinance
JinseFinance

Author: Arweave Oasis
In our previous article "Understanding Arweave’s consensus mechanism iteration process" has learned about Arweave’s technology iteration process in the past five years, and promised in the article to compare the 2.6 version again. Comprehensive analysis. This article will fulfill this promise and take you through the design details of the consensus mechanism of Arweave 2.6 version.
In about a month, Bitcoin will start its next round of halving. But the author believes that Satoshi Nakamoto’s vision—a consensus in which everyone can participate using a CPU—has never been realized. In this regard, Arweave's mechanism iteration may be more faithful to Satoshi Nakamoto's original vision, and version 2.6 allows the Arweave network to truly comply with Satoshi Nakamoto's expectations. Compared with the previous version, it has been greatly improved to achieve:
Limit hardware acceleration, general-purpose CPU + mechanical hard disk is enough Participate in the consensus maintenance of the system to reduce storage costs;
Direct consensus costs as much as possible to effective data storage instead of energy-consuming hash arms race;
p>
Miners are incentivized to build their own copy of the complete Arweave dataset, allowing data to be routed faster and stored more distributedly.
Based on the above goals, the mechanism of version 2.6 is roughly as follows:
In the original SPoRA mechanism, a new component is called the Hash Chain, which is the encryption algorithm clock mentioned before and generates one SHA every second. Mining Hash of -256.
The miner selects the index of a partition in the data partition it stores, and uses it together with the mining hash and mining address as the mining input information to start mining.
Generate a lookback range 1 in the partition chosen by the miner, and a second lookback range 2 at a random location in the braided network.
Use the traceback data chunks (Chunks) within the traceback range 1 in turn to calculate and try whether it is a block solution. If the calculation result is greater than the current network difficulty, the miner obtains the right to produce the block; if it is unsuccessful, the next traceback block in the traceback range is calculated.
Blocks of traceback data in range 2 may also be computationally verified, but the solution there requires a range 1 hash.
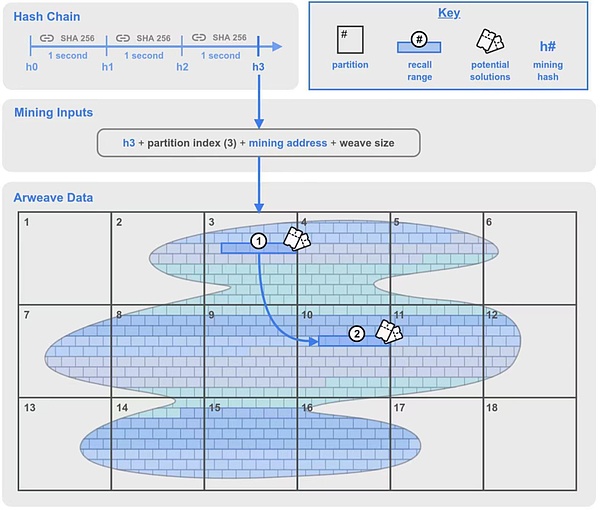
Figure 1: Schematic diagram of the 2.6 version of the consensus mechanism
Let’s get to know the various noun concepts that appear in this mechanism:< /p>
Arweave Data:Also known as "woven network". All data in the network is divided into data blocks one by one, the English name is Chunk (the blocks like "brick walls" in the picture above are chunks). These blocks can be evenly distributed in the Arweave network, and an addressing scheme (also called a Global Offset) is established for each data block through a Merkle tree to identify any location in the weave network. data block.
Chunk: The size of each data chunk is usually 256 KB. To win the right to produce blocks, miners must package and hash the corresponding data blocks and prove during the SPoRA mining process that they have stored a copy of the data.
Partition: "Partition" is a new concept in version 2.6. Each 3.6TB is a partition. Partitions are numbered from the beginning of the woven network (index 0) up to the number of partitions that cover the entire woven network.
Recall Range: Recall range is also a new concept in version 2.6. It is a series of contiguous data chunks (Chunk) of length 100MB starting from a specific offset in the weaving network. Based on a data block of 256 KB, a traceback range includes 400 data blocks. In this mechanism, there will be two lookback ranges, which will be explained in detail below.
Potential Solutions:Each 256KB data block within the lookback range will be a potential solution to obtain the right to produce the block. As part of the mining process, each block of data is hashed to test whether it meets the network’s difficulty requirements. If satisfied, the miner wins the right to produce the block and receives the mining reward. If not satisfied, the miner will continue trying to backtrack to the next 256KB block in the range.
Hash Chain: Hash Chain is a key update in version 2.6, which adds a cryptographic clock to the previous SPoRA , which plays a speed-limiting role in limiting the maximum hash amount. A hash chain is generated by hashing a piece of data consecutive times using the SHA-256 function. This process cannot be calculated in parallel (consumer-grade CPUs can easily do it), and the hash chain achieves a delay of 1 second by performing a certain number of consecutive hash processes.
Mining Hash: After a sufficient number of consecutive hashes (i.e. a delay of 1 second), the hash The chain produces a hash that is considered valid for mining. It is worth noting that the mining hash is consistent among all miners and can be verified by all miners.
After introducing all the necessary noun concepts, we can better understand how version 2.6 works together by how to obtain the best strategy.
The overall goal of Arweave has been introduced many times before, which is to maximize the number of copies of data stored on the network. But what to save? How to save? There are also many requirements and doorways. Here we discuss how to adopt an optimal strategy.
Replicas and Copies
Since version 2.6, the author has frequently seen two words, Replicas and Copies, in various technical materials. These two concepts can be translated into Chinese as copy, but in fact there is a very big difference between them, which also caused a lot of obstacles for me to understand the mechanism. For ease of understanding, I tend to translate Replicas as "copy" and Copies as "backup".
Copies backup refers to simply copying data, and there is no difference between backups of the same data.
Replicas means uniqueness. It is the act of storing data after unique processing. The Arweave network encourages the storage of copies, rather than pure backup storage.
Note: In version 2.7, the consensus mechanism became SPoRes, which is Succinct Proofs of Replications. The simple replication proof is based on replica storage. I will explain it in the future.
Packing unique replicas
Unique replicas are very important in the Arweave mechanism. If miners want to obtain the right to produce blocks, they must The data is packaged and processed in a specific format to form its own unique copy, which is a prerequisite.
If you want to run a new node, it is not possible to directly copy the data that has been packaged by other miners. You first need to download and synchronize the original data in the Arweave weaving network (of course you don’t want to download all of it, you can only download part of it. You can also set your own data policy to filter out risky data), and then package these through the RandomX function Every chunk of raw data makes it a potential mining solution.
The packaging process involves providing a Packing Key to the RandomX function, allowing the result generated by it to be used to pack the original data block through multiple operations. The process of decompressing the packed data block is the same. The packing key is provided, and the result generated by multiple operations is used to decompress the packed data block.
In version 2.5, Packing Key backup is the SHA256 hash associated with chunk_offset (the offset of the data block, which can also be understood as the position parameter of the data block) and tx_root (transaction root). This guarantees that each mining solution comes from a unique copy of the data blocks in a specific block. If a data block has multiple backups in different locations on the damaged network, each backup needs to be backed up individually to create a unique copy.
In version 2.6, this backup key is expanded to a SHA256 hash associated with chunk_offset, tx_root, and miner_address. This means that each copy is also unique to each mining address.
Advantages of storing complete copies
The algorithm advises miners to build a unique complete copy rather than a partial copy that is copied multiple times, which makes the network The data is evenly distributed.
How to understand this part? Let’s understand by comparing the two pictures below.
First, let us assume that the entire Arweave fracture network generates a total of 16 data partitions.
The first situation:
Miner Bob thinks that downloading data is too time-consuming. So only the data of the first 4 partitions that destroyed the network were downloaded.
In order to maximize the mining copies of these 4 partitions, Bob had an idea and copied 4 copies of the data of these 4 partitions, and used different 4 The mining addresses form them into 4 unique copy resources to fill their own storage space, so now there are 16 partitions in Bob's storage space. This is no problem and complies with the rule of unique copies.
Next, when Bob obtains the mining hash (Mining Hash) every second, he can generate a traceback range material for each partition and conduct intrusion testing on the data blocks in it. . This gives Bob 400*16=6400 potential mining solutions in one second.
But Bob also paid the second price for his little cleverness, because he had to lose a mining opportunity in the back range. Do you see these "little question marks"? ? They represent a lookback range related to the second time that is not found on Bob's hard drive because they mark Bob's data partition that is not stored in it. Of course, as luck would have it, there is a lower indicator light representing Bob's stored 4 partitions, which is only 25%, or 1600 potential solutions.
So this strategy gives Bob 6400+1600=8000 potential solutions per second.
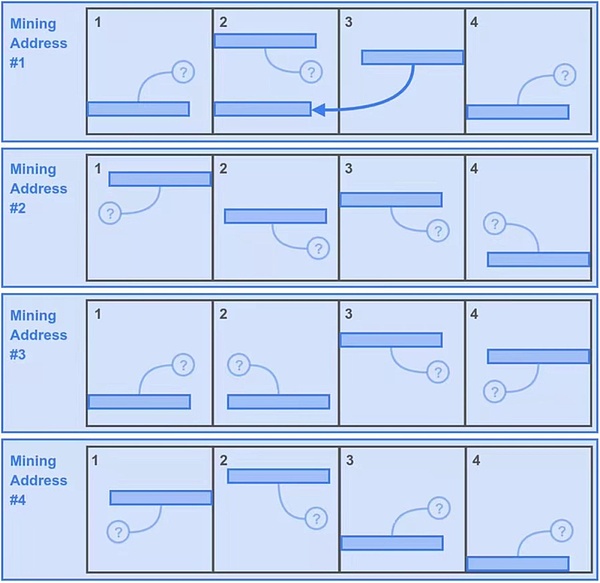
Figure 2: The first situation, Bob’s "little clever" strategy
< strong>The second situation:
Then let’s look at the second situation. Due to the mechanical arrangement of the two lookback ranges, a better strategy is to store the only copy with the most problems. As shown in Figure 3.
Miner Alice is not as "smart" as Bob. She dutifully downloaded the partition data of all 16 partitions and only Use one mining address to form a unique copy of 16 backups.
Because Alice also has 16 partitions, the total potential solutions for the first lookback range are consistent with Bob, which is also 6400.
But in this case, Alice gets all the second lookback scope potential solutions. That’s an additional 6,400.
So this gives Alice’s strategy 6400+6400=12800 potential solutions per second. The advantages are self-evident.
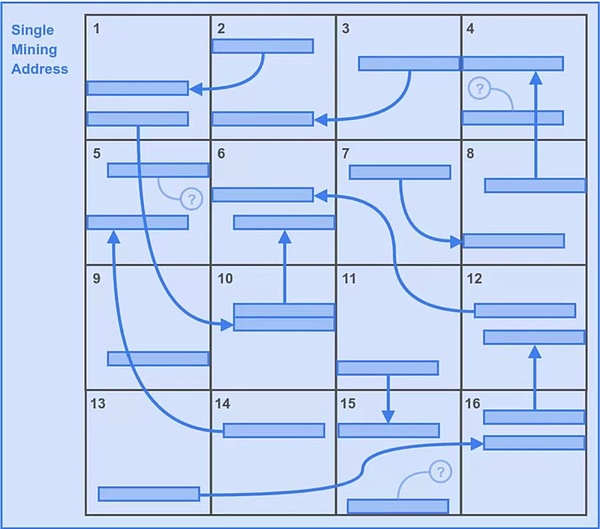
Figure 3: Alice’s strategy obviously has greater advantages
The role of the traceback range
You may be surprised that before version 2.5, the offset of a single traceback block was randomly hashed through a function and allowed miners to find and provide storage proof again. , why will the hash produce a traceback range in 2.6?
The reason is actually easy to understand. The traceback range is composed of continuous data blocks. This structure is for nothing else. Its purpose is to minimize the movement of the read head of the mechanical hard disk (HDD). . The physical optimizations brought about by this approach allow the read performance of HDDs to be comparable to that of more expensive SSD hard drives (SSDs). It's like tying one hand and one foot to the SSD. Of course, having an expensive SSD that can transfer four traceback ranges per second still has a slight speed advantage. But its count will be a key metric for miners to choose compared to cheaper HDDs.
Now let’s discuss the verification of the next new block.
To accept a new block, the verifier needs to verify the new block synchronized by the block producer. The method is to use the mining hash generated by itself to verify the mining hash of the new block.
If the validator is not at the current head of the hash chain, each mining hash consists of 25 checkpoints of 40 milliseconds. These checkpoints are the result of 40 milliseconds of consecutive hashes, and together they represent a one-second interval from the beginning of the hash from the previous mine.
The validator will quickly complete the verification of the first 25 checkpoints within 40 milliseconds before propagating the newly received block to other nodes. If the verification is successful, the propagation block will be triggered and continued to complete. Validation of remaining checkpoints. A complete checkpoint is completed by validating all remaining checkpoints. The first 25 checkpoints are followed by 500 validation checkpoints, then 500 validation checkpoints, with the subsequent 500 checkpoints doubled for each group.
When the hash chain generates mining hashes, it must be performed in a single line in sequence. However, validators can perform hash verification when verifying checkpoints, which can shorten the time to verify blocks and improve efficiency.
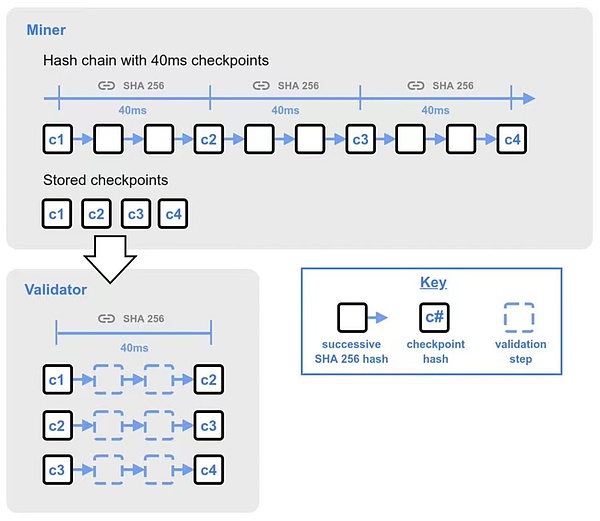
Figure 4: Verification process of hash chain
Seed of hash chain
If the miner or mine Pools have faster SHA256 hashing power and their hash chains may be ahead of other nodes in the network. Over time, this block speed advantage can accumulate into a huge hash chain offset, resulting in mining hashes that are out of sync with the rest of the validators. This may lead to a series of uncontrollable bifurcation and reorganization phenomena.
To reduce the possibility of such hash chain drift, Arweave synchronizes the global hash chain by using tokens from historical blocks at fixed intervals. This periodically provides a new seed to the hash chain, synchronizing the individual miner's hash chain with a verified block.
The interval of the hash chain seed is every 50 * 120 mining hashes (50 represents the number of blocks, 120 represents the number of mining hashes within 2 minutes of a block production cycle). Choose a new seed block. This makes the seed block appear approximately once every ~50 Arweave blocks, but due to some variation in block times, the seed block may appear earlier than 50 blocks.
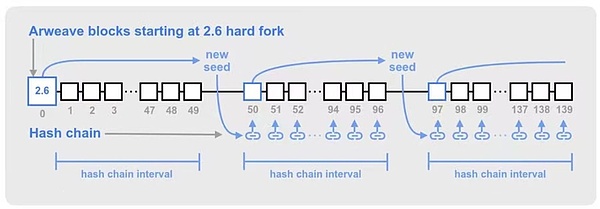
Figure 5: How to generate hash chain seeds
The above is what the author spent some time to learn from the 2.6 specification Excerpted from the content, it can be seen from these that Arweave has achieved low power consumption since 2.6. Next, a more decentralized ideological mechanism is used to run the entire network. Satoshi Nakamoto’s vision has been implemented in Arweave.
Arweave 2.6:
https://2-6-spec.arweave.dev/https://2-6-spec.arweave. dev
In this article, we discuss in detail how storage donation works and then study its characteristics and risk profile by simulating its execution using Markov chains.
JinseFinanceThis article will explore the redundancy mechanisms of Arweave and IPFS, and which option is safer for your data.
JinseFinance100 billion WhatsApp messages are sent every day. Most blockchains are not designed for storage. If you want to store 100 billion WhatsApp messages on Ethereum or any blockchain, it will be extremely expensive.
JinseFinanceThis article explores how Arweave and IPFS store, maintain, and access files, and how this affects the reliability and durability of digital assets.
JinseFinanceArweave is a decentralized data storage solution that provides permanent and immutable data storage services through its Blockweave technology and native cryptocurrency AR token.
JinseFinanceWhy is Arweave not a replacement for Filecoin, but a more significant innovation worthy of attention?
JinseFinanceJinseFinanceThis event is poised to host more than a hundred Arweave ecosystem developers and investors, offering attendees exclusive perks such as product testing opportunities, AR airdrop rewards, and practical merchandise.
 Samantha
Samantha Nulltx
Nulltx“This quarter, we saw significant improvements in the energy efficiency and sustainability of Bitcoin mining, a trend that will continue,” said MicroStrategy founder and CEO Michael Saylor.
 Cointelegraph
Cointelegraph
