Kamala Harris Matches Trump in Presidential Betting Odds on Polymarket
Kamala Harris and Donald Trump tied at 49% in Polymarket's $541M presidential betting pool.
 ZeZheng
ZeZheng

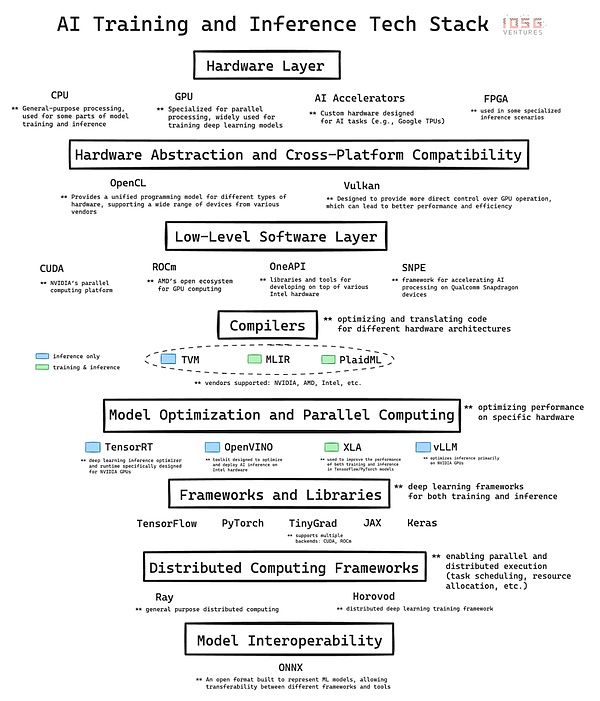
The rapid development of artificial intelligence is based on a complex infrastructure. The AI technology stack is a layered architecture consisting of hardware and software, which is the backbone of the current AI revolution. Here, we will analyze the main layers of the technology stack in depth and explain the contribution of each layer to AI development and implementation. Finally, we will reflect on the importance of mastering these basics, especially when evaluating opportunities in the intersection of cryptocurrency and AI, such as DePIN (decentralized physical infrastructure) projects, such as GPU networks.

At the bottom is the hardware, which provides the physical computing power for AI.
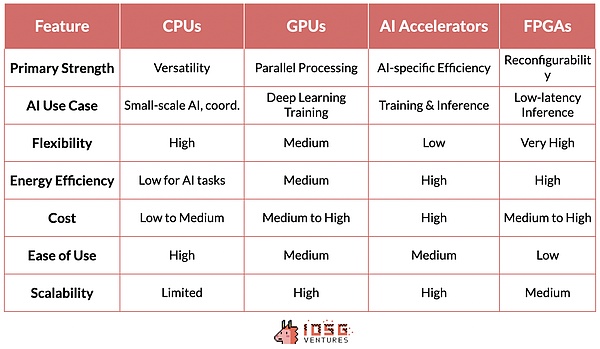
CPU (Central Processing Unit): is the foundational processor for computing. They excel at handling sequential tasks and are very important for general computing, including data preprocessing, small-scale AI tasks, and coordinating other components.
GPU (Graphics Processing Unit): was originally designed for graphics rendering, but has become an important component of AI because of its ability to perform a large number of simple calculations simultaneously. This parallel processing capability makes GPUs ideal for training deep learning models, and without the development of GPUs, modern GPT models would not be possible.
AI accelerators: Chips designed specifically for AI workloads, they are optimized for common AI operations, providing high performance and energy efficiency for training and inference tasks.
FPGAs (Field Programmable Array Logic): Provide flexibility with their reprogrammable nature. They can be optimized for specific AI tasks, especially in inference scenarios that require low latency.

This layer in the AI technology stack is critical because it builds a bridge between high-level AI frameworks and the underlying hardware. Technologies such as CUDA, ROCm, OneAPI, and SNPE strengthen the connection between high-level frameworks and specific hardware architectures, achieving optimized performance.
As NVIDIA's proprietary software layer, CUDA is the cornerstone of the company's rise in the AI hardware market. NVIDIA's leadership is not only due to its hardware advantages, but also reflects the strong network effect of its software and ecosystem integration.
CUDA has such a great influence because it is deeply integrated into the AI technology stack and provides a complete set of optimized libraries that have become the de facto standard in the field. This software ecosystem has built a strong network effect: AI researchers and developers who are proficient in CUDA spread its use to academia and industry during training.
The resulting virtuous circle strengthens NVIDIA's market leadership as the CUDA-based tool and library ecosystem becomes increasingly indispensable to AI practitioners.
This symbiosis of software and hardware not only solidifies NVIDIA's position at the forefront of AI computing, but also gives the company significant pricing power, which is rare in the typically commoditized hardware market.
CUDA's dominance and the relative obscurity of its competitors can be attributed to a series of factors that have created significant barriers to entry. NVIDIA's first-mover advantage in GPU-accelerated computing has enabled CUDA to build a strong ecosystem before competitors have gained a foothold. Although competitors such as AMD and Intel have excellent hardware, their software layer lacks the necessary libraries and tools and cannot be seamlessly integrated with the existing technology stack, which is why there is a huge gap between NVIDIA/CUDA and other competitors.

TVM (Tensor Virtual Machine), MLIR (Multi-layer Intermediate Representation), and PlaidML provide different solutions to the challenge of optimizing AI workloads across multiple hardware architectures.
TVM originated from research at the University of Washington and has quickly gained attention for its ability to optimize deep learning models for a variety of devices, from high-performance GPUs to resource-constrained edge devices. Its advantage lies in the end-to-end optimization process, which is particularly effective in inference scenarios. It completely abstracts the differences in underlying vendors and hardware, allowing inference workloads to run seamlessly on different hardware, whether it is NVIDIA devices or AMD, Intel, etc.
However, outside of inference, the situation becomes more complicated. The ultimate goal of hardware-replaceable computation for AI training remains unsolved. However, there are several initiatives worth mentioning in this regard.
MLIR, Google's project, takes a more fundamental approach. By providing a unified intermediate representation for multiple levels of abstraction, it aims to simplify the entire compiler infrastructure to target both inference and training use cases.
PlaidML, now led by Intel, is positioning itself as a dark horse in this race. Its focus on portability across multiple hardware architectures (including those beyond traditional AI accelerators) envisions a future where AI workloads run seamlessly on a variety of computing platforms.
If any of these compilers can be well integrated into the technology stack without affecting model performance and without requiring any additional modifications by developers, this could threaten CUDA's moat. However, at present, MLIR and PlaidML are not mature enough and not well integrated into the AI technology stack, so they do not pose a clear threat to CUDA's leadership at present.


Ray and Horovod represent two different approaches to distributed computing in the AI field, each addressing the key need for scalable processing in large-scale AI applications.
Ray, developed by UC Berkeley's RISELab, is a general-purpose distributed computing framework. It excels in flexibility, allowing the distribution of various types of workloads beyond machine learning. The actor-based model in Ray greatly simplifies the process of parallelizing Python code, making it particularly suitable for reinforcement learning and other artificial intelligence tasks that require complex and diverse workflows.
Horovod, originally designed by Uber, focuses on the distributed implementation of deep learning. It provides a concise and efficient solution for scaling deep learning training processes on multiple GPUs and server nodes. The highlight of Horovod is its user-friendliness and optimization of data-parallel training of neural networks, which enables it to perfectly integrate with mainstream deep learning frameworks such as TensorFlow and PyTorch, allowing developers to easily expand their existing training codes without making a lot of code modifications.

Integration with existing AI stacks is crucial for the DePin project, which aims to build a distributed computing system. This integration ensures compatibility with current AI workflows and tools, lowering the threshold for adoption.
In the cryptocurrency space, the current GPU network, which is essentially a decentralized GPU rental platform, marks an initial step towards a more sophisticated distributed AI infrastructure. These platforms are more like Airbnb-style marketplaces than operating as distributed clouds. Although they are useful for some applications, these platforms are not yet sufficient to support true distributed training, which is a key requirement for advancing large-scale AI development.
Current distributed computing standards like Ray and Horovod are not designed for globally distributed networks. For truly working decentralized networks, we need to develop another framework on this layer. Some skeptics even believe that due to the intensive communication and optimization of global functions required by Transformer models during the learning process, they are incompatible with distributed training methods. On the other hand, optimists are trying to come up with new distributed computing frameworks that work well with globally distributed hardware. Yotta is one of the startups trying to solve this problem.
NeuroMesh goes a step further. It redesigns the machine learning process in a particularly innovative way. By using a predictive coding network (PCN) to find convergence to local error minimization, rather than directly finding the optimal solution to the global loss function, NeuroMesh solves a fundamental bottleneck in distributed AI training.
This approach not only enables unprecedented parallelization, but also makes it possible to train models on consumer-grade GPU hardware such as RTX 4090, thereby democratizing AI training. Specifically, the 4090 GPU has similar computing power to the H100, but they are underutilized during model training due to insufficient bandwidth. Because PCN reduces the importance of bandwidth, it is possible to utilize these low-end GPUs, which may bring significant cost savings and efficiency improvements.
GenSyn, another ambitious crypto AI startup, aims to build a set of compilers. Gensyn's compilers allow any type of computing hardware to be seamlessly used for AI workloads. To put it in an analogy, just like TVM does for inference, GenSyn is trying to build similar tools for model training.
If successful, it could significantly expand the capabilities of decentralized AI computing networks to handle more complex and diverse AI tasks by efficiently leveraging a variety of hardware. This ambitious vision, while challenging due to the complexity and high technical risk of optimizing across diverse hardware architectures, could erode the moat of CUDA and NVIDIA if they can execute on it and overcome obstacles such as maintaining performance on heterogeneous systems.
About Inference: Hyperbolic's approach, combining verifiable inference with a decentralized network of heterogeneous computing resources, embodies a relatively pragmatic strategy. By leveraging compiler standards such as TVM, Hyperbolic can leverage a wide range of hardware configurations while maintaining performance and reliability. It can aggregate chips from multiple vendors (from NVIDIA to AMD, Intel, etc.), including consumer-grade hardware and high-performance hardware.
These developments at the intersection of crypto-AI herald a future where AI computing could become more distributed, efficient, and accessible. The success of these projects depends not only on their technical merits, but also on their ability to integrate seamlessly with existing AI workflows and address practical concerns of AI practitioners and businesses.
Kamala Harris and Donald Trump tied at 49% in Polymarket's $541M presidential betting pool.
ZeZhengParaFi Capital, the largest investor in prediction markets, said first-time users are mostly participating in markets not related to the election.
 JinseFinance
JinseFinanceThe scale of crypto prediction platforms is experiencing explosive growth and is expected to continue to maintain a high growth trend in the next few years.
JinseFinancePresident Biden tested positive for Covid while traveling in Las Vegas soon after he said a “medical condition” could prompt him to withdraw.
 WenJun
WenJunPolymarket breaks trading records with $116.4 million in July, driven by U.S. election bets. Nate Silver's advisory role aims to enhance prediction accuracy amid growing market influence.
 Hafiz
HafizThe prediction market is an open market where anyone who knows about future outcomes can contribute their knowledge in the form of bets.
JinseFinanceMany predict a massive Polymarket retreat after the US election in November
JinseFinanceAs the expectations of $ETH ETF passing heat up, the market’s attention is gradually returning to the EVM ecosystem. As the largest prediction market on the chain, Polymarket has attracted much attention because of whether $ETH ETF can pass smoothly.
JinseFinancePyth, Pyth Governance System Voting Guide Golden Finance, please cast your precious vote!
JinseFinanceFormer FTX CTO reveals the manipulation of FTX's insurance fund, claiming it lacked actual FTT tokens and was misrepresented.
 Bitcoinworld
Bitcoinworld