Tác giả: Tu Min, CSDN
Tháng 5 này tựa như đang mơ về tháng 3 năm 2023, với những bữa tiệc AI sôi động lần lượt diễn ra.
Tuy nhiên, dù cố ý hay vô ý, vào tháng 3 năm ngoái, khi Google chọn mở mô hình ngôn ngữ lớn PaLM API , OpenAI đã phát hành mô hình GPT-4 mạnh mẽ nhất gần như cùng lúc. Chỉ vài ngày sau, Microsoft chính thức công bố trong cuộc họp báo rằng dòng Office của họ đã được cách mạng hóa bởi GPT-4, khiến Google dường như bị mọi người phớt lờ.
Thật đáng xấu hổ, tình huống tương tự dường như đang xảy ra trong năm nay. Một mặt, OpenAI đã mang đến một chiếc GPT4o hàng đầu được nâng cấp hoàn toàn vào sáng sớm hôm qua khi khai mạc Gala Lễ hội Mùa xuân AI của tháng này. , Microsoft sẽ tổ chức Bulid 2024 vào tuần tới, liệu Google, vốn lại bị tấn công lần này, có thể lật ngược tình thế của hai "nhóm" của mình hay không, chúng ta sẽ có cái nhìn thoáng qua về điều đó từ Hội nghị nhà phát triển I/O 2024 đã khai mạc. sáng sớm nay.
Hội nghị I/O năm nay cũng là năm thứ 8 Google thực hiện rõ ràng chiến lược “AI First” của mình.
01 Xem trước nội dung nổi bật
Đúng như dự đoán, trong Keynote dài gần 2 tiếng này, " "AI" là một từ khóa diễn ra xuyên suốt hội nghị I/O nhưng không ngờ nó lại được nhắc tới tới 121 lần. Không khó để nhận thấy sự lo lắng của Google về AI.

Đối mặt với các đối thủ cạnh tranh khốc liệt bên ngoài, CEO Google Sundar Pichai (Sundar Pichai "AI vẫn là trong giai đoạn đầu phát triển và tôi tin rằng Google cuối cùng sẽ giành chiến thắng trong cuộc chiến này, giống như Google không phải là công ty đầu tiên thực hiện tìm kiếm", Pichai nói trong một cuộc phỏng vấn gần đây trên một chương trình.
Tại hội nghị I/O, Sundar Pichai cũng nhấn mạnh điểm này: "Chúng tôi vẫn đang ở giai đoạn đầu của quá trình chuyển đổi nền tảng trí tuệ nhân tạo. Đối với người sáng tạo, nhà phát triển, công ty khởi nghiệp và tất cả mọi người, chúng tôi nhìn thấy những cơ hội to lớn ”
Sundar Pichai nói rằng khi Gemini được phát hành vào năm ngoái, nó đã được định vị là một mô hình lớn đa phương thức có thể mở rộng văn bản, hình ảnh, video, mã, v.v. Vào tháng 2 năm nay, Google đã phát hành Gemini 1.5 Pro, một bước đột phá về văn bản dài, mở rộng độ dài cửa sổ ngữ cảnh lên 1 triệu mã thông báo, nhiều hơn bất kỳ mô hình cơ sở quy mô lớn nào khác. Ngày nay, hơn 1,5 triệu nhà phát triển sử dụng mô hình Gemini trong các công cụ của Google.
Tại cuộc họp báo, Sundar Pichi đã chia sẻ tiến bộ mới nhất trong Google:
Ứng dụng Gemini hiện đã có sẵn. trên hệ thống Android và iOS. Gemini Advanced cung cấp cho người dùng quyền truy cập vào các mô hình mạnh mẽ nhất của Google.
Google sẽ tung ra phiên bản cải tiến của Gemini 1.5 Pro cho tất cả các nhà phát triển trên toàn thế giới. Ngoài ra, Gemini 1.5 Pro, hiện có 1 triệu bối cảnh mã thông báo, hiện có sẵn cho người tiêu dùng trực tiếp trong Gemini Advanced, nơi nó có sẵn trên 35 ngôn ngữ.
Google đã mở rộng cửa sổ ngữ cảnh Gemini 1.5 Pro lên 2 triệu mã thông báo và cung cấp cho các nhà phát triển dưới dạng bản xem trước riêng tư.
Mặc dù chúng tôi vẫn đang ở giai đoạn đầu của Đặc vụ, nhưng Google đã bắt đầu khám phá và thử nghiệm Project Astra, dự án phân tích thế giới thông qua camera của điện thoại thông minh, xác định và giải thích mã cũng như giúp con người tìm thấy Kính, còn có thể phân biệt được âm thanh...
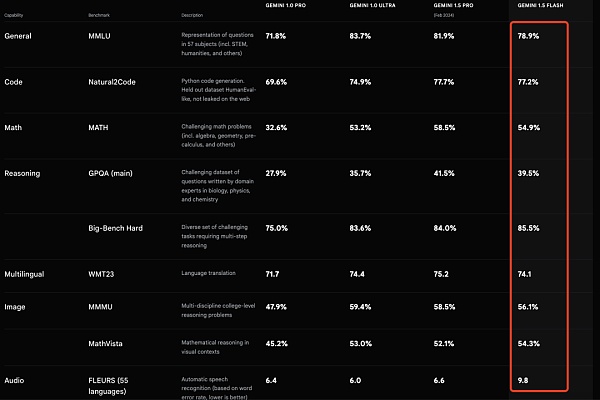
Gemini 1.5 Flash nhẹ hơn Gemini 1.5 Pro ra mắt và hướng tới những nhiệm vụ quan trọng chẳng hạn như độ trễ thấp và chi phí được tối ưu hóa.
Imagen 3, mô hình Veo và mô hình hình ảnh tạo văn bản có thể tạo ra video 1080p "chất lượng cao", được phát hành
Áp dụng Kiến trúc mới, kích thước 27B Gemma 2.0 đã có mặt;
Android, hệ điều hành di động đầu tiên bao gồm mô hình cơ bản về thiết bị tích hợp sẵn, tích hợp sâu Gemini mô hình và trở thành hệ điều hành cốt lõi dựa trên AI của Google;
TPU Trillium thế hệ thứ sáu đã được phát hành. So với TPU v5e thế hệ trước, hiệu suất tính toán của từng chip. đã tăng 4,7 lần.
02 Google "điên", nhiều mẫu ra đời
Đúng là như vậy cho biết, những người làm mô hình lớn đều rất “đồ sộ”. Không ngờ, trong quá trình tăng tốc để bắt kịp, “khối lượng” của Google lại vượt xa sức tưởng tượng. Tại buổi họp báo, Google không chỉ nâng cấp các mẫu máy lớn trước đây mà còn tung ra một số mẫu máy mới.
Nâng cấp và cập nhật Gemini 1.5 Pro
Khi Gemini được phát hành vào năm ngoái, Google đã định vị nó là một mô hình đa phương thức lớn có thể mở rộng Văn bản, hình ảnh , video, mã, v.v. để lý luận. Vào tháng 2 năm nay, Google đã phát hành Gemini 1.5 Pro, một bước đột phá về văn bản dài, mở rộng độ dài cửa sổ ngữ cảnh lên 1 triệu mã thông báo, nhiều hơn bất kỳ mô hình cơ sở quy mô lớn nào khác.
Tại cuộc họp báo, Google lần đầu tiên thực hiện các cải tiến về chất lượng cho một số trường hợp sử dụng chính của Gemini 1.5 Pro, chẳng hạn như dịch thuật, mã hóa, suy luận, v.v., phiên bản này có thể xử lý nhiều tác vụ phức tạp hơn và đa dạng hơn. 1.5 Pro hiện có thể tuân theo các chỉ thị phức tạp và nhiều sắc thái, bao gồm các chỉ thị chỉ định hành vi ở cấp độ sản xuất liên quan đến vai trò, định dạng và kiểu dáng. Nó cũng cho phép người dùng kiểm soát hành vi của mô hình bằng cách thiết lập các lệnh hệ thống.
Trong khi đó, Google đã bổ sung khả năng hiểu âm thanh cho API Gemini và Google AI Studio, vì vậy 1.5 Pro hiện có thể thực hiện suy luận về hình ảnh và âm thanh của video được tải lên trong Google AI Studio.
Điều đáng chú ý hơn là nếu bối cảnh 1 triệu mã thông báo đã đủ dài thì hôm nay, Google sẽ tiếp tục mở rộng khả năng của mình, mở rộng cửa sổ ngữ cảnh lên 2 triệu mã thông báo và với bản xem trước riêng tư Có sẵn cho các nhà phát triển trong phiên bản 2, nó thể hiện bước tiếp theo hướng tới mục tiêu cuối cùng là bối cảnh không giới hạn.
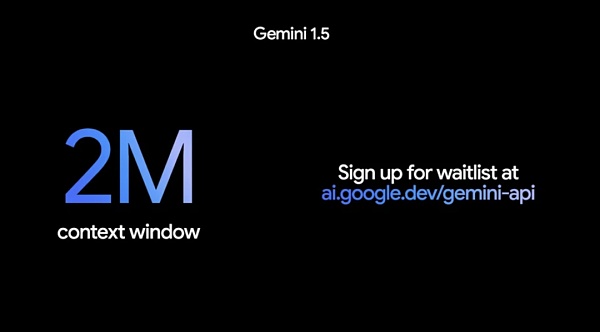
Để truy cập 1.5 Pro với cửa sổ ngữ cảnh 2 triệu mã thông báo, bạn cần tham gia Danh sách chờ Google AI trong Studio hoặc Vertex AI dành cho khách hàng Google Cloud.
Mẫu mới, nhẹ hơn Gemini 1.5 Flash
Gemini 1.5 Flash, một mẫu nhẹ được xây dựng cho mô hình mở rộng và cũng là mẫu Gemini nhanh nhất trong API. Nó được tối ưu hóa cho các tác vụ có độ trễ thấp và chi phí quan trọng nhất, phục vụ tiết kiệm chi phí hơn và có cửa sổ ngữ cảnh dài mang tính đột phá.

Mặc dù nhẹ hơn mẫu 1.5 Pro nhưng nó có thể xử lý một lượng lớn thông tin Thực hiện lý luận đa phương thức. Theo mặc định, Flash cũng có cửa sổ ngữ cảnh 1 triệu mã thông báo, nghĩa là bạn có thể xử lý một giờ video, 11 giờ âm thanh, cơ sở mã gồm hơn 30.000 dòng mã hoặc hơn 700.000 từ.
Gemini 1.5 Flash vượt trội trong việc tóm tắt, trò chuyện, phụ đề hình ảnh và video, trích xuất dữ liệu từ các tài liệu và bảng dài, v.v. Đó là bởi vì 1.5 Pro đào tạo nó thông qua một quy trình gọi là "chưng cất", chuyển kiến thức và kỹ năng quan trọng nhất từ mô hình lớn hơn sang mô hình nhỏ hơn, hiệu quả hơn.
Giá của Gemini 1.5 Flash được đặt ở mức 35 xu cho mỗi 1 triệu mã thông báo. Giá này rẻ hơn một chút so với giá 5 USD trên 1 triệu token của GPT-4o.
Gemini 1.5 Pro và 1.5 Flash đều ở dạng xem trước công khai và có sẵn trong Google AI Studio và Vertex AI.
Mô hình mở ngôn ngữ hình ảnh đầu tiên của Google PaliGemma hiện đã có sẵn
PaliGemma là một VLM (mô hình ngôn ngữ hình ảnh) mở mạnh mẽ lấy cảm hứng từ PaLI-3. PaliGemma được xây dựng trên các thành phần mở như mô hình tầm nhìn SigLIP và mô hình ngôn ngữ Gemma, đồng thời được thiết kế để đạt được hiệu suất tinh chỉnh hiện đại trên nhiều tác vụ ngôn ngữ hình ảnh. Điều này bao gồm chú thích hình ảnh và video ngắn, trả lời câu hỏi trực quan, hiểu văn bản trong hình ảnh, phát hiện đối tượng và phân đoạn đối tượng.
Google cho biết để thúc đẩy hoạt động khám phá và nghiên cứu mở, PaliGemma có sẵn trên nhiều nền tảng và tài nguyên khác nhau. Bạn có thể tìm thấy nó trên GitHub, mô hình Hugging Face, Kaggle, Vertex AI Model Garden và ai. nvidia.com (sử dụng Find PaliGemma trên TensorRT-LLM Acceleration) và dễ dàng tích hợp thông qua JAX và Hugging Face Transformers.
Gemma 2 đã phát hành
Tất cả Gemma 2 đã phát hành sẽ có kích thước mới và có kiến trúc hoàn toàn mới được thiết kế để mang lại hiệu suất và hiệu quả đột phá. Với 27 tỷ thông số, Gemma 2 có hiệu năng tương đương với Llama 3 70B nhưng kích thước chỉ bằng một nửa.

Theo Google, thiết kế hiệu quả của Gemma 2 giúp giảm lượng tính toán cần thiết Ít hơn một nửa so với các mô hình tương tự. Mẫu 27B được tối ưu hóa để chạy trên GPU của NVIDIA và hiệu quả trên một máy chủ TPU duy nhất trong Vertex AI, giúp triển khai dễ dàng hơn và tiết kiệm chi phí hơn cho nhiều người dùng hơn.


Gemma 2 sẽ được ra mắt vào tháng 6.
Veo: mô hình tạo video mới nhất và tiên tiến nhất
Có thể coi là chuẩn mực so với Sora của OpenAI mà Google đã cho ra mắt mô hình tạo video Veo ngày nay. Nó có thể tạo ra các video có độ phân giải 1080p chất lượng cao theo nhiều phong cách điện ảnh và hình ảnh khác nhau, kéo dài hơn một phút.
Veo được xây dựng dựa trên nhiều năm làm việc của Google về các mô hình video tổng hợp, bao gồm Generative Query Network (GQN), DVD-GAN, Imagen-Video, Phenaki, WALT, VideoPoet và Lumiere, Kết hợp kiến trúc, thuật toán mở rộng quy mô và các kỹ thuật khác để cải thiện chất lượng và độ phân giải đầu ra.
Bắt đầu từ hôm nay, người dùng có thể tham gia danh sách chờ đăng ký Veo.
Imagen 3: Mô hình chuyển văn bản thành hình ảnh chất lượng cao
Imagen 3 mới phát hành có ít tạo tác hình ảnh gây mất tập trung hơn so với mô hình trước đây của Google. ít bóng hơn, nó có thể hiểu ngôn ngữ tự nhiên tốt hơn, ý định đằng sau các tín hiệu và kết hợp các chi tiết nhỏ trong các tín hiệu dài hơn.

Bắt đầu từ hôm nay, Imagen 3 có sẵn cho một số người sáng tạo chọn lọc trong chế độ xem trước và tham gia ImageFX Private danh sách chờ. Imagen 3 sắp có mặt trên Vertex AI.
Tầm nhìn tương lai: Dự án đặc vụ AI tổng quát Astra
Cái gọi là Tác nhân đề cập đến các hệ thống thông minh có khả năng suy luận, lập kế hoạch và ghi nhớ. có thể “Suy nghĩ” trước nhiều bước và làm việc trên các phần mềm và hệ thống.
Tại cuộc họp báo hôm nay, Giám đốc điều hành Google DeepMind và người đồng sáng lập Demis Harbis đã tiết lộ rằng Google đang làm việc nội bộ để phát triển các Tác nhân AI có mục đích chung hữu ích trong cuộc sống hàng ngày, Dự án Astra (Tầm nhìn nâng cao) và các tác nhân đáp ứng lời nói) là một trong những nỗ lực chính.
Dự án này dựa trên Gemini, nơi Google đã phát triển một tác nhân nguyên mẫu có thể thực hiện các cuộc gọi hiệu quả bằng cách mã hóa liên tục các khung hình video, kết hợp đầu vào video và giọng nói thành dòng thời gian của sự kiện và lưu thông tin này vào bộ nhớ đệm để có các cuộc gọi hiệu quả. Xử lý thông tin nhanh hơn.
Bằng cách tận dụng các mẫu giọng nói, Google cũng đã nâng cao khả năng phát âm của họ, mang lại cho tổng đài viên nhiều ngữ điệu hơn. Những tổng đài viên này có thể hiểu rõ hơn về bối cảnh mà họ đang làm việc và phản hồi nhanh chóng trong các cuộc trò chuyện.
Trong ví dụ được trình bày tại cuộc họp báo, Project Astra có thể tự động xác định những thứ tạo ra âm thanh trong cảnh thực và thậm chí có thể định vị trực tiếp các thành phần cụ thể tạo ra âm thanh và cũng có thể diễn giải chức năng của màn hình máy tính. mã xuất hiện trên đó cũng có thể giúp con người tìm kính, v.v.
"Với công nghệ như thế này, thật dễ dàng tưởng tượng một tương lai nơi mọi người có thể có trợ lý trí tuệ nhân tạo chuyên nghiệp thông qua điện thoại hoặc kính của họ. Một số tính năng này sẽ xuất hiện trong các sản phẩm của Google vào cuối năm nay", Google express.
03 Bản nâng cấp Gemini Advanced, Gemini có thể tùy chỉnh
Giờ đây, Gemini 1.5 Pro cải tiến giới thiệu gói đăng ký Gemini Advanced Under, một phiên bản cải tiến của Gemini 1.5 Pro có sẵn cho tất cả các nhà phát triển trên toàn thế giới, có thể sử dụng trên 35 ngôn ngữ.
Như đã đề cập ở trên, Gemini 1.5 Pro có 1 triệu ngữ cảnh mã thông báo theo mặc định. Cửa sổ ngữ cảnh dài như vậy có nghĩa là Gemini Advanced có thể hiểu nhiều tài liệu lớn, ước tính tổng cộng lên tới 1.500 trang hoặc 100 trang. tóm tắt email, làm việc trên một giờ nội dung video hoặc cơ sở mã hơn 30.000 dòng.
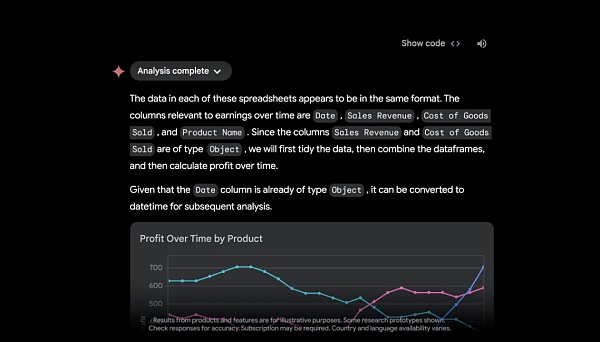
Với khả năng tải tệp lên Google Drive hoặc trực tiếp từ thiết bị của bạn, Google tiết lộ rằng sắp tới, Gemini Advanced sẽ đóng vai trò là nhà phân tích dữ liệu, khám phá thông tin chi tiết từ các tệp dữ liệu đã tải lên (chẳng hạn như bảng tính) và xây dựng động tự động Xác định trực quan hóa và biểu đồ.
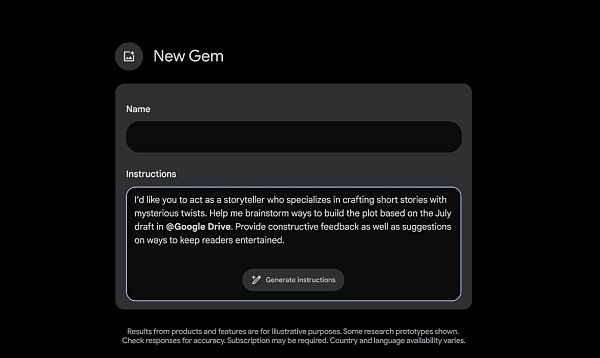
Để có trải nghiệm cá nhân hóa hơn, những người đăng ký Gemini Advanced sẽ sớm có thể Tạo Đá quý – phiên bản tùy chỉnh của Song Tử. Bạn có thể tạo bất kỳ Đá quý nào bạn muốn, chẳng hạn như người bạn tập luyện, đầu bếp phụ, người bạn viết mã hoặc hướng dẫn viết sáng tạo. Đơn giản chỉ cần mô tả những gì bạn muốn Đá quý của mình làm và cách bạn muốn nó phản hồi, chẳng hạn như "Bạn là huấn luyện viên chạy bộ của tôi, hãy cho tôi kế hoạch chạy bộ hàng ngày và hãy luôn tích cực, lạc quan và có động lực." một Nâng cao chúng chỉ bằng một cú nhấp chuột để tạo ra những viên ngọc đáp ứng nhu cầu cụ thể của bạn.
04 Sử dụng AI để viết lại tìm kiếm của Google< / h2>
Nếu không có ứng dụng thực tế trong các kịch bản kinh doanh, việc lặp lại công nghệ mô hình lớn dường như chỉ là “cuộc nói chuyện trên giấy”. Khác với lộ trình mà OpenAI đã đi, Google và Microsoft đều đang cạnh tranh về tốc độ trên đường đua ứng dụng AI. Đối với Google, khởi đầu là một công ty tìm kiếm, chắc chắn họ sẽ không bỏ lỡ làn sóng AI.
Liz Reid, phó chủ tịch kiêm người đứng đầu bộ phận tìm kiếm của Google, cho biết: "Với trí tuệ nhân tạo tổng hợp, tìm kiếm có thể làm được nhiều điều hơn bạn nghĩ. Vì vậy, bạn có thể nghĩ ra bất cứ điều gì bạn nghĩ tới hoặc bất cứ điều gì bạn cần hoàn thành mọi việc—từ nghiên cứu, lập kế hoạch cho đến động não—Google sẽ thực hiện mọi công việc”
Tổng quan về AI: “Một tìm kiếm, tất cả thông tin”< /. strong>
Tại cuộc họp báo, Google đã phát hành một tính năng có tên "Tổng quan về AI" nhằm đạt được "một tìm kiếm, nhận được tất cả thông tin".
Nói một cách đơn giản, đôi khi bạn muốn có câu trả lời nhanh chóng nhưng không có thời gian để tập hợp tất cả thông tin bạn cần lại với nhau, chẳng hạn như “Bạn đang tìm một phòng tập yoga hoặc Pilates mới và muốn Bạn muốn có một studio nổi tiếng với người dân địa phương, dễ tiếp cận và có giảm giá cho thành viên mới?” Tất cả những gì bạn phải làm là nêu rõ nhu cầu của mình và thực hiện tìm kiếm, sau đó Tổng quan về AI sẽ cung cấp câu trả lời cho các câu hỏi phức tạp.
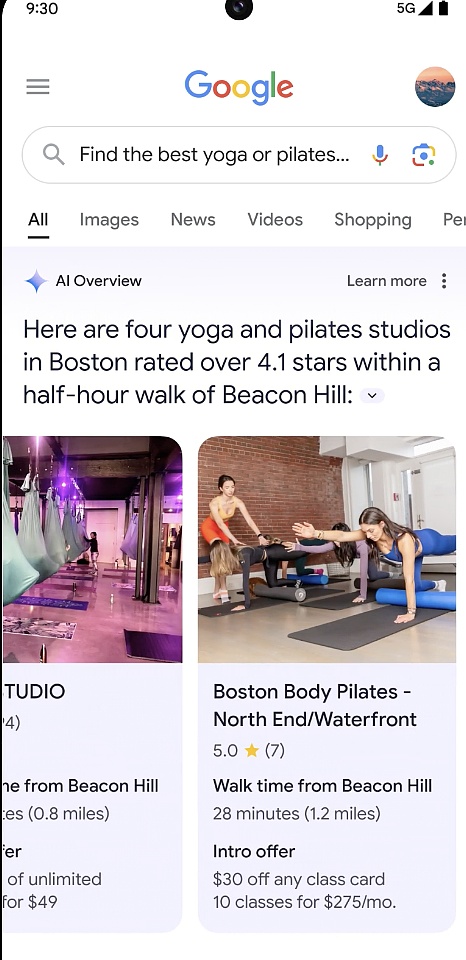
Quay video và nhận trợ giúp AI< br >
Google cũng đã nâng cao khả năng tìm kiếm bằng hình ảnh nhờ những tiến bộ trong khả năng hiểu video. Bạn có thể sử dụng tính năng tìm kiếm video của Google Lens để chụp ảnh các vấn đề bạn gặp phải hoặc những thứ bạn nhìn thấy xung quanh mình (bao gồm cả các vật thể chuyển động), để bạn có thể tìm kiếm câu trả lời và tiết kiệm thời gian cũng như rắc rối do những mô tả bằng lời không rõ ràng gây ra.
Tuy nhiên, hai chức năng trên hiện chỉ được triển khai tại Hoa Kỳ và sẽ được triển khai ở nhiều quốc gia hơn trong tương lai.
Ngoài mức độ tìm kiếm, sự xuất hiện của các mẫu mã lớn cũng sẽ nâng cao hơn nữa tính thông minh của sản phẩm.
Hỏi Ảnh
Ở cấp độ ứng dụng tìm kiếm ảnh, Google đã đưa ra chức năng “Hỏi Ảnh”.
Bạn có thể sử dụng Song Tử để xác định các thông tin cơ bản khác nhau trong ảnh, chẳng hạn như hỏi: Con gái bạn học bơi khi nào? Việc bơi lội diễn ra như thế nào? Những bức ảnh gắn kết mọi thứ lại với nhau, giúp người dùng nhanh chóng thu thập thông tin và giải các câu đố.
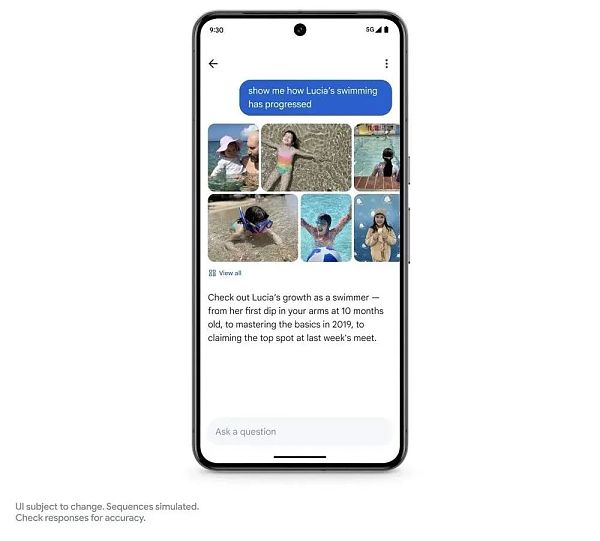
Tính năng này chưa trực tuyến, Google cho biết sẽ ra mắt mùa hè này sẽ được ra mắt.
Gemini 1.5 Pro đến với Google Workspace
Google cũng tích hợp các mô hình lớn vào Google Workspace, chẳng hạn như tìm kiếm trong Gmail Email, giữ theo dõi mọi việc xảy ra ở trường của con bạn thông qua các email gần đây với nhà trường. Chúng ta có thể yêu cầu Song Tử tóm tắt tất cả các email gần đây từ trường. Nó xác định các email có liên quan ở chế độ nền và thậm chí phân tích các tệp đính kèm như PDF.
Đã thêm đầu ra âm thanh trong NotebookLM
NotebookLM là một ứng dụng ghi chú AI được Google ra mắt vào tháng 7 năm ngoái, có thể được tải lên khắp nơi người dùng Tóm tắt hoàn thiện tài liệu, ý tưởng sáng tạo.
Dựa trên công nghệ mô hình lớn đa phương thức, Google đã bổ sung thêm chức năng xuất âm thanh cho ứng dụng này. Nó sử dụng Gemini 1.5 Pro để lấy tài liệu nguồn của người dùng và tạo các cuộc hội thoại âm thanh tương tác được cá nhân hóa.
05 Tích hợp sâu Android của Gemini
Sử dụng AI để kiểm soát hoạt động Nâng cấp hệ thống là điều mà Microsoft và Google đang thúc đẩy mạnh mẽ. Là hệ điều hành di động số một thế giới, Android có hàng tỷ người dùng. Google cho biết họ đã tích hợp mô hình Gemini vào Android và giới thiệu nhiều tính năng AI thiết thực.

Ví dụ: thông qua "Vòng tròn để tìm kiếm", người dùng có thể Thay vì chuyển đổi ứng dụng , sử dụng các tương tác đơn giản như vẽ hình tròn, vẽ nguệch ngoạc và nhấp chuột để biết thêm thông tin. Giờ đây, Circle to Search có thể giúp học sinh hoàn thành bài tập về nhà. Khi học sinh khoanh tròn các gợi ý gặp phải, các em sẽ được cung cấp một loạt giải pháp để giải quyết vấn đề. Giải thích từng bước các bài toán vật lý và toán học để hiểu sâu hơn chứ không chỉ là đáp án.
Ngoài ra, Google sẽ sớm cập nhật Gemini trên Android để giúp người dùng dễ dàng đưa lớp phủ của Gemini lên đầu ứng dụng, giúp sử dụng Gemini theo nhiều cách dễ dàng hơn.
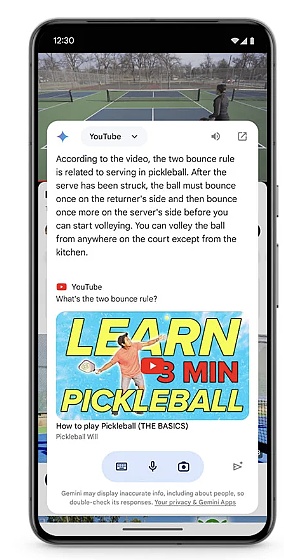
"Android là hệ điều hành di động đầu tiên có nền tảng thiết bị tích hợp sẵn model", với Gemini Nano, người dùng Android có thể nhanh chóng trải nghiệm các chức năng AI. Google đã tiết lộ rằng họ sẽ ra mắt mẫu máy mới nhất của mình, Gemini Nano, với nhiều chế độ, bắt đầu với Pixel vào cuối năm nay. Điều này có nghĩa là điện thoại Pixel mới có thể xử lý nhiều thứ hơn ngoài việc nhập văn bản mà còn hiểu được nhiều thông tin theo ngữ cảnh hơn như hình ảnh, âm thanh và ngôn ngữ nói.
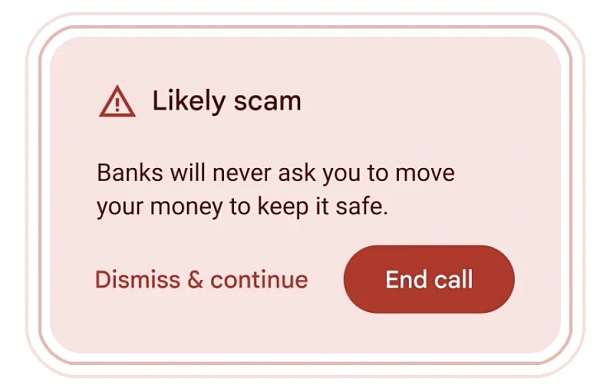
Ngoài ra, Google đang sử dụng Gemini Nano trong Android để cung cấp cảnh báo theo thời gian thực khi phát hiện các cuộc trò chuyện trong cuộc gọi thường liên quan đến lừa đảo, chẳng hạn như nếu ai đó tự xưng là "ngân hàng" hỏi bạn khẩn cấp Bạn sẽ nhận được cảnh báo khi chuyển tiền, thanh toán bằng thẻ quà tặng hoặc yêu cầu thông tin cá nhân như mã PIN hoặc mật khẩu thẻ (đây là những yêu cầu không phổ biến của ngân hàng), nhưng tính năng này vẫn đang trong quá trình thử nghiệm.
06 TPU thế hệ thứ sáu; Trillium
Sundar Pichai cho biết việc đào tạo các mô hình tiên tiến đòi hỏi rất nhiều sức mạnh tính toán. Nhu cầu về điện toán ML của ngành đã tăng 1 triệu lần trong sáu năm qua. Và nó tăng gấp 10 lần mỗi năm.
Để thích ứng với nhu cầu ngày càng tăng về điện toán ML, hãng đã tung ra TPU - Trillium thế hệ thứ sáu. So với TPU v5e thế hệ trước, hiệu năng tính toán của mỗi chip Trillium đã tăng 4,7 lần. Để đạt được mức hiệu suất này, Google đã tăng kích thước của đơn vị nhân ma trận (MXU) và tăng tốc độ xung nhịp.
Ngoài ra, Trillium còn được trang bị SparseCore thế hệ thứ ba, một công cụ tăng tốc chuyên dụng được thiết kế để xử lý các phần nhúng rất lớn thường gặp trong khối lượng công việc xếp hạng và đề xuất nâng cao. Trillium TPU có thể đào tạo làn sóng mô hình cơ sở tiếp theo nhanh hơn và phục vụ chúng với độ trễ ít hơn và chi phí thấp hơn.
Trillium TPU tiết kiệm năng lượng hơn 67% so với TPU v5e.
Có thông tin cho rằng Google sẽ cung cấp Trillium cho khách hàng trên nền tảng đám mây của mình vào cuối năm 2024.
07 Các biện pháp bảo mật
Ngoài các bản cập nhật về mẫu và sản phẩm nêu trên, Google cũng đã thực hiện các hành động mới nhất trong bảo mật, nhằm mục đích lạm dụng AI và các tình huống khác.
Một mặt, Google đã tung ra loạt mô hình mới dựa trên Gemini và tinh chỉnh nó để phục vụ việc học tập, phát hành LearnLM. Nó tích hợp các nguyên tắc học thuật và khoa học học tập dựa trên nghiên cứu vào các sản phẩm của Google để giúp quản lý tải nhận thức và điều chỉnh cho phù hợp với mục tiêu, nhu cầu và động lực của người học.

Mặt khác, để làm cho kiến thức dễ tiếp thu và dễ tiêu hóa hơn, Google đã xây dựng một công cụ thử nghiệm mới, Illuminate, tận dụng khả năng ngữ cảnh dài của Gemini 1.5 Pro để chuyển đổi các tài liệu nghiên cứu phức tạp thành các cuộc hội thoại âm thanh ngắn. Illuminate có thể tạo ra một cuộc trò chuyện bao gồm hai giọng nói do AI tạo ra trong vài phút, cung cấp cái nhìn tổng quan và thảo luận ngắn gọn về những hiểu biết quan trọng từ một bài nghiên cứu.
Cuối cùng, Google đã áp dụng công nghệ "đội đỏ được AI hỗ trợ" để chủ động kiểm tra các điểm yếu trong hệ thống của chính mình và cố gắng khắc phục chúng, bằng cách mở rộng công cụ tạo hình mờ SynthID sang hai chế độ mới: Văn bản và video, giúp nội dung do AI tạo dễ dàng xác định hơn.
08 Bạn nghĩ gì về hội nghị Google I/O?
Trên đây là nội dung chính của Keynote Google I/O 2024 Các sản phẩm rất phong phú nhưng đa số đều phải đợi.
Kết thúc buổi họp báo này, nhiều chuyên gia cũng bày tỏ một số ý kiến. Từ Jim Fan, giám đốc nghiên cứu cấp cao tại NVIDIA:
Google I/O. Một số suy nghĩ: Mô hình này có vẻ đa phương thức cho đầu vào nhưng không đa phương thức cho đầu ra. Các mô hình gen Imagen-3 và âm nhạc vẫn tách biệt với Gemini như những thành phần riêng biệt. Việc hợp nhất nguyên bản tất cả đầu vào/đầu ra phương thức là xu hướng tất yếu trong tương lai:
Cho phép "sử dụng giọng nói robot hơn", Nhiệm vụ như như "Nói nhanh hơn gấp 2 lần", "Chỉnh sửa hình ảnh này nhiều lần" và "Tạo một bộ truyện tranh nhất quán".
Thông tin vượt qua ranh giới phương thức, chẳng hạn như cảm xúc và âm thanh nền, không bị mất.
Cung cấp các tính năng theo ngữ cảnh mới. Bạn có thể dạy mô hình của mình kết hợp các giác quan khác nhau theo những cách mới lạ với một số ít ví dụ.
GPT-4o không được thực hiện một cách hoàn hảo, nhưng yếu tố hình thức của nó là chính xác. Để sử dụng phép tương tự LLM-as-OS của Andrej: chúng tôi cần mô hình hỗ trợ nguyên bản càng nhiều phần mở rộng tệp càng tốt.
Google đang làm đúng một việc: cuối cùng họ cũng đang nỗ lực nghiêm túc để tích hợp trí tuệ nhân tạo vào hộp tìm kiếm. Tôi cảm nhận được quy trình của Tác nhân: lập kế hoạch, duyệt trực tiếp và nhập liệu đa phương thức, tất cả đều từ trang đích. Con hào mạnh nhất của Google là phân phối. Gemini không cần phải là người mẫu giỏi nhất để trở thành người mẫu được sử dụng nhiều nhất trên thế giới.
Học giả AI nổi tiếng Andrew Ng nói: “Xin chúc mừng tất cả bạn bè Google của tôi về những thông báo thú vị tại I/O! Cá nhân tôi rất mong đợi Gemini có 200 người tham gia! 10.000 cửa sổ ngữ cảnh đầu vào mã thông báo và hỗ trợ tốt hơn cho AI trên thiết bị – sẽ mang lại cơ hội mới cho người xây dựng ứng dụng”



 JinseFinance
JinseFinance




