Kamala Harris sánh ngang Trump trong tỷ lệ cược cá cược tổng thống trên Polymarket
Kamala Harris và Donald Trump hòa nhau ở mức 49% trong tổng số tiền cược tổng thống trị giá 541 triệu đô la của Polymarket.
 ZeZheng
ZeZheng

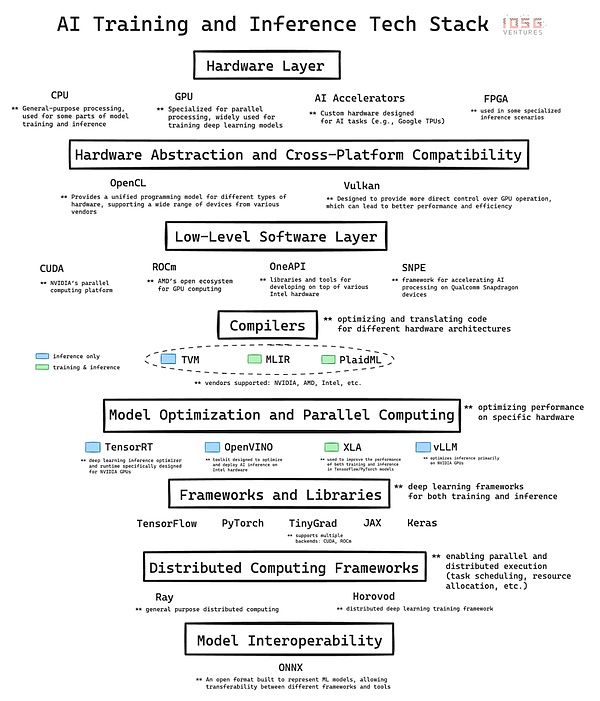
Hướng dẫn sử dụng Sự phát triển nhanh chóng của trí thông minh dựa trên cơ sở hạ tầng phức tạp. Ngăn xếp công nghệ AI là một kiến trúc phân lớp bao gồm phần cứng và phần mềm, là xương sống của cuộc cách mạng AI hiện nay. Ở đây, chúng tôi sẽ cung cấp phân tích chuyên sâu về các lớp chính của ngăn xếp công nghệ và minh họa sự đóng góp của từng lớp đối với việc phát triển và triển khai AI. Cuối cùng, chúng tôi sẽ suy nghĩ về tầm quan trọng của việc nắm vững các nguyên tắc cơ bản này, đặc biệt là khi đánh giá các cơ hội ở điểm giao thoa giữa tiền điện tử và AI, chẳng hạn như các dự án DePIN (cơ sở hạ tầng vật lý phi tập trung) như mạng GPU.

Ở mức thấp nhất là phần cứng, cung cấp sức mạnh tính toán vật lý cho trí tuệ nhân tạo.
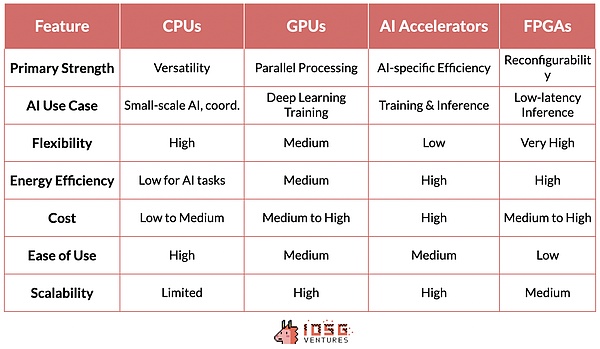
CPU (Bộ xử lý trung tâm): Nó là bộ xử lý cơ bản cho máy tính. Chúng vượt trội trong việc xử lý các tác vụ tuần tự và rất quan trọng đối với điện toán có mục đích chung, bao gồm tiền xử lý dữ liệu, các tác vụ trí tuệ nhân tạo quy mô nhỏ và điều phối các thành phần khác.
GPU (Bộ xử lý đồ họa): Ban đầu được thiết kế để kết xuất đồ họa, nhưng đã trở thành một phần quan trọng của trí tuệ nhân tạo vì khả năng thực hiện số lượng lớn các phép tính đơn giản đồng thời. Khả năng xử lý song song này làm cho GPU trở nên lý tưởng để đào tạo các mô hình học sâu. Nếu không có sự phát triển của GPU, các mô hình GPT hiện đại sẽ không thể thực hiện được.
Bộ tăng tốc AI: Các chip được thiết kế dành riêng cho khối lượng công việc trí tuệ nhân tạo. Chúng được tối ưu hóa cho các hoạt động trí tuệ nhân tạo thông thường và mang lại hiệu suất cao cho các nhiệm vụ đào tạo và suy luận cũng như tiết kiệm năng lượng cao. .
FPGA (Logic mảng có thể lập trình): Mang lại sự linh hoạt nhờ tính chất có thể lập trình lại của nó. Chúng có thể được tối ưu hóa cho các nhiệm vụ trí tuệ nhân tạo cụ thể, đặc biệt là trong các tình huống suy luận yêu cầu độ trễ thấp.

Lớp này trong ngăn xếp công nghệ AI rất quan trọng vì nó xây dựng kết nối giữa khung AI cấp cao và cầu nối phần cứng cơ bản giữa. Các công nghệ như CUDA, ROCm, OneAPI và SNPE tăng cường kết nối giữa các khung cấp cao và kiến trúc phần cứng cụ thể để đạt được tối ưu hóa hiệu suất.
Là lớp phần mềm độc quyền của NVIDIA, CUDA là nền tảng cho sự phát triển của công ty trên thị trường phần cứng AI. Vị trí dẫn đầu của NVIDIA không chỉ nhờ lợi thế về phần cứng mà còn phản ánh hiệu ứng mạng mạnh mẽ của việc tích hợp phần mềm và hệ sinh thái.
CUDA có sức ảnh hưởng rất lớn vì nó được tích hợp sâu vào nền tảng công nghệ AI và cung cấp một bộ tiêu chuẩn thực tế trong lĩnh vực này. Hệ sinh thái phần mềm này đã xây dựng một hiệu ứng mạng mạnh mẽ: Các nhà nghiên cứu và phát triển AI thành thạo CUDA đã phổ biến việc sử dụng nó cho các học viện và ngành công nghiệp trong quá trình đào tạo.
Chu kỳ tích cực đạt được sẽ củng cố vị trí dẫn đầu thị trường của NVIDIA khi hệ sinh thái các công cụ và thư viện dựa trên CUDA ngày càng trở nên dễ tiếp cận đối với những người thực hành AI. Nó càng trở nên không thể thiếu.
Sự cộng sinh giữa phần mềm và phần cứng này không chỉ củng cố vị thế dẫn đầu của NVIDIA trong lĩnh vực điện toán AI mà còn mang lại cho công ty khả năng định giá đáng kể so với phần cứng thông thường. hiếm trên thị trường.
Sự thống trị của CUDA và sự mờ nhạt tương đối của các đối thủ cạnh tranh có thể là do một số yếu tố tạo ra rào cản gia nhập đáng kể. Lợi thế đi đầu của NVIDIA trong lĩnh vực điện toán tăng tốc GPU cho phép CUDA xây dựng một hệ sinh thái mạnh mẽ trước khi các đối thủ cạnh tranh giành được chỗ đứng. Mặc dù các đối thủ cạnh tranh như AMD và Intel có phần cứng xuất sắc nhưng các lớp phần mềm của họ thiếu các thư viện và công cụ cần thiết và không thể tích hợp liền mạch với các công nghệ hiện có. Đây là lý do có khoảng cách lớn giữa NVIDIA/CUDA và các đối thủ khác.

TVM (Máy ảo Tensor), MLIR (Đa- Biểu diễn trung gian lớp) và PlaidML cung cấp các giải pháp khác nhau cho thách thức tối ưu hóa khối lượng công việc AI trên nhiều kiến trúc phần cứng.
TVM có nguồn gốc từ nghiên cứu tại Đại học Washington và được biết đến với khả năng tối ưu hóa các mô hình học sâu cho nhiều loại thiết bị, từ GPU hiệu suất cao đến tài nguyên -các thiết bị biên bị giới hạn. Thu hút sự chú ý một cách nhanh chóng. Ưu điểm của nó nằm ở quy trình tối ưu hóa từ đầu đến cuối, đặc biệt hiệu quả trong các kịch bản suy luận. Nó hoàn toàn trừu tượng hóa sự khác biệt cơ bản của nhà cung cấp và phần cứng, cho phép khối lượng công việc suy luận chạy liền mạch trên các phần cứng khác nhau, cho dù đó là thiết bị NVIDIA, AMD, Intel, v.v.
Tuy nhiên, ngoài lý luận, tình hình còn trở nên phức tạp hơn. Mục tiêu cuối cùng của điện toán có thể thay thế phần cứng để đào tạo AI vẫn chưa được giải quyết. Tuy nhiên, có một số sáng kiến đáng được đề cập về vấn đề này.
MLIR, một dự án của Google, sử dụng cách tiếp cận cơ bản hơn. Bằng cách cung cấp một biểu diễn trung gian thống nhất cho nhiều mức độ trừu tượng, nó nhằm mục đích đơn giản hóa toàn bộ cơ sở hạ tầng trình biên dịch cho cả trường hợp sử dụng suy luận và đào tạo.
PlaidML, hiện do Intel dẫn đầu, đã tự khẳng định mình là chú ngựa đen trong cuộc đua này. Nó tập trung vào tính di động trên nhiều kiến trúc phần cứng, bao gồm cả những kiến trúc ngoài bộ tăng tốc AI truyền thống và hình dung ra một tương lai nơi khối lượng công việc AI có thể chạy liền mạch trên nhiều nền tảng điện toán khác nhau.
Nếu bất kỳ trình biên dịch nào trong số này có thể được tích hợp tốt vào ngăn xếp công nghệ, không ảnh hưởng đến hiệu suất mô hình và không yêu cầu bất kỳ sửa đổi bổ sung nào từ nhà phát triển, Điều này có thể xảy ra để đe dọa hào nước của CUDA. Tuy nhiên, hiện tại MLIR và PlaidML chưa đủ trưởng thành và chưa được tích hợp tốt vào nền tảng công nghệ trí tuệ nhân tạo nên hiện tại chúng chưa gây ra mối đe dọa rõ ràng cho vị trí dẫn đầu của CUDA.


Ray và Horovod thể hiện hai cách tiếp cận khác nhau đối với điện toán phân tán trong lĩnh vực AI, mỗi phương pháp đều giải quyết được một yêu cầu quan trọng để xử lý có thể mở rộng trong các ứng dụng AI quy mô lớn.
Ray do RISELab của UC Berkeley phát triển là một khung điện toán phân tán chung. Nó vượt trội về tính linh hoạt, cho phép phân phối nhiều loại khối lượng công việc khác nhau ngoài học máy. Mô hình dựa trên tác nhân trong Ray giúp đơn giản hóa đáng kể quá trình song song hóa mã Python, khiến nó đặc biệt phù hợp cho việc học tăng cường và các tác vụ trí tuệ nhân tạo khác đòi hỏi quy trình công việc phức tạp và đa dạng.
Horovod, ban đầu do Uber thiết kế, tập trung vào việc triển khai học sâu một cách phân tán. Nó cung cấp một giải pháp ngắn gọn và hiệu quả để mở rộng quy trình đào tạo deep learning trên nhiều GPU và nút máy chủ. Điểm nổi bật của Horovod là tính thân thiện với người dùng và tối ưu hóa việc đào tạo song song dữ liệu mạng thần kinh, cho phép nó được tích hợp hoàn hảo với các framework deep learning chính thống như TensorFlow và PyTorch, cho phép các nhà phát triển dễ dàng mở rộng mã đào tạo hiện có của họ mà không cần để thực hiện sửa đổi mã mở rộng.

So với hệ thống AI hiện có Tích hợp là rất quan trọng đối với dự án DePin, nhằm mục đích xây dựng các hệ thống máy tính phân tán. Sự tích hợp này đảm bảo khả năng tương thích với các công cụ và quy trình làm việc AI hiện tại, giảm bớt rào cản trong việc áp dụng.
Trong lĩnh vực tiền điện tử, mạng GPU hiện tại về cơ bản là một nền tảng cho thuê GPU phi tập trung, đánh dấu bước chuyển hướng tới nền tảng AI phân tán phức tạp hơn. bởi cơ sở. Các nền tảng này hoạt động giống như các thị trường kiểu Airbnb hơn là các đám mây phân tán. Mặc dù hữu ích cho một số ứng dụng nhất định nhưng những nền tảng này không đủ mạnh để hỗ trợ đào tạo phân tán thực sự, một yêu cầu then chốt để thúc đẩy phát triển AI quy mô lớn.
Các tiêu chuẩn điện toán phân tán hiện tại như Ray và Horovod không được thiết kế cho các mạng phân tán toàn cầu. Để có một mạng phi tập trung thực sự hoạt động được, chúng ta cần Phát triển một khuôn khổ khác bên trên một khuôn khổ khác. lớp. Một số người hoài nghi thậm chí còn tin rằng vì các mô hình Transformer yêu cầu giao tiếp chuyên sâu và tối ưu hóa các chức năng toàn cầu trong quá trình học tập nên chúng không tương thích với các phương pháp đào tạo phân tán. Mặt khác, những người lạc quan đang cố gắng đưa ra các khung máy tính phân tán mới hoạt động tốt với phần cứng phân tán toàn cầu. Yotta là một trong những công ty khởi nghiệp đang cố gắng giải quyết vấn đề này.
NeuroMesh tiến thêm một bước nữa. Nó thiết kế lại quá trình học máy theo một cách đặc biệt sáng tạo. Bằng cách sử dụng Mạng mã hóa dự đoán (PCN) để tìm ra sự hội tụ trong việc giảm thiểu lỗi cục bộ, thay vì trực tiếp tìm ra giải pháp tối ưu cho hàm mất mát toàn cầu, NeuroMesh giải quyết được nút thắt cơ bản trong đào tạo AI phân tán.
Phương pháp này không chỉ cho phép song song hóa chưa từng có mà còn giúp đào tạo các mô hình trên phần cứng GPU cấp độ người tiêu dùng như RTX 4090, giúp đào tạo Dân chủ hóa AI . Cụ thể, sức mạnh tính toán của GPU 4090 tương đương với H100 nhưng do băng thông không đủ nên chúng không được tận dụng hết trong quá trình huấn luyện mô hình. Vì PCN giảm tầm quan trọng của băng thông, giúp có thể tận dụng các GPU cấp thấp này, điều này có thể giúp tiết kiệm đáng kể chi phí và tăng hiệu quả.
GenSyn, một công ty khởi nghiệp AI về tiền điện tử đầy tham vọng khác, có mục tiêu xây dựng một bộ trình biên dịch. Trình biên dịch của Gensyn cho phép mọi loại phần cứng máy tính được sử dụng liền mạch cho khối lượng công việc AI. Ví dụ: những gì TVM làm để suy luận, GenSyn đang cố gắng xây dựng các công cụ tương tự để đào tạo mô hình.
Nếu thành công, nó có thể mở rộng đáng kể khả năng của các mạng điện toán AI phi tập trung để xử lý các tác vụ AI phức tạp và đa dạng hơn bằng cách sử dụng hiệu quả nhiều phần cứng khác nhau. Tầm nhìn đầy tham vọng này, tuy đầy thách thức do tính phức tạp và rủi ro kỹ thuật cao trong việc tối ưu hóa trên các kiến trúc phần cứng đa dạng, nhưng có thể là một công nghệ mà nếu họ có thể thực thi, vượt qua các trở ngại như duy trì hiệu năng hệ thống không đồng nhất. Làm suy yếu các hào của CUDA và NVIDIA.
Về lý luận: Cách tiếp cận của Hyperbolic kết hợp lý luận có thể kiểm chứng được với mạng lưới phi tập trung gồm các tài nguyên điện toán không đồng nhất, thể hiện một chiến lược tương đối thực dụng. Bằng cách tận dụng các tiêu chuẩn trình biên dịch như TVM, Hyperbolic có thể tận dụng nhiều cấu hình phần cứng trong khi vẫn duy trì hiệu suất và độ tin cậy. Nó có thể tổng hợp chip từ nhiều nhà cung cấp (từ NVIDIA đến AMD, Intel, v.v.), bao gồm phần cứng cấp độ người tiêu dùng và phần cứng hiệu suất cao.
Những phát triển này ở điểm giao thoa giữa tiền điện tử-AI báo trước một tương lai trong đó điện toán AI có thể trở nên phân tán, hiệu quả và dễ tiếp cận hơn. Sự thành công của các dự án này sẽ không chỉ phụ thuộc vào giá trị kỹ thuật mà còn phụ thuộc vào khả năng tích hợp hoàn hảo với quy trình công việc AI hiện có và giải quyết các mối quan tâm thực tế của những người thực hành và doanh nghiệp AI.
Kamala Harris và Donald Trump hòa nhau ở mức 49% trong tổng số tiền cược tổng thống trị giá 541 triệu đô la của Polymarket.
ZeZhengParaFi Capital, nhà đầu tư lớn nhất vào thị trường dự đoán, cho biết những người dùng lần đầu hầu hết tham gia vào các thị trường không liên quan đến bầu cử.
 JinseFinance
JinseFinanceQuy mô của các nền tảng dự đoán tiền điện tử đang có sự tăng trưởng bùng nổ và dự kiến sẽ tiếp tục duy trì tốc độ tăng trưởng nhanh chóng trong những năm tới.
JinseFinanceTổng thống Biden có kết quả xét nghiệm dương tính với Covid khi đi du lịch ở Las Vegas ngay sau khi ông cho biết “tình trạng sức khỏe” có thể khiến ông phải rút lui.
 WenJun
WenJunPolymarket phá kỷ lục giao dịch với 116,4 triệu USD trong tháng 7, nhờ đặt cược vào cuộc bầu cử Hoa Kỳ. Vai trò cố vấn của Nate Silver nhằm mục đích nâng cao độ chính xác của dự đoán trong bối cảnh ảnh hưởng của thị trường ngày càng tăng.
 Hafiz
HafizThị trường dự đoán là một thị trường mở nơi bất kỳ ai có kiến thức về kết quả trong tương lai đều có thể đóng góp kiến thức của mình dưới hình thức đặt cược.
JinseFinanceNhiều người đang dự đoán về một cuộc khủng hoảng lớn của Polymarket sau cuộc bầu cử Mỹ vào tháng 11
JinseFinanceKhi kỳ vọng về việc $ETH ETF được thông qua ngày càng nóng lên, sự chú ý của thị trường dần quay trở lại hệ sinh thái EVM. Với tư cách là thị trường dự đoán lớn nhất trên chuỗi, Polymarket đã thu hút nhiều sự chú ý về việc liệu $ETH ETF có thể diễn ra suôn sẻ hay không.
JinseFinancePyth, Hướng dẫn bỏ phiếu Hệ thống quản trị Pyth Golden Finance, vui lòng bỏ phiếu bầu quý giá của bạn!
JinseFinanceCựu CTO của FTX tiết lộ hành vi thao túng quỹ bảo hiểm của FTX, cho rằng quỹ này thiếu token FTT thực tế và bị trình bày sai.
 Bitcoinworld
Bitcoinworld