
Sự khác biệt giữa trò chơi Gacha và NFT
<nil>
 Chris
Chris

Mạng là một phần quan trọng của kỷ nguyên AI mô hình lớn đổ chuông. Trong kỷ nguyên của các mô hình lớn, chúng ta bắt đầu thấy sự tăng tốc trong việc lặp lại các thiết bị mạng như mô-đun quang và bộ chuyển mạch cũng như sự bùng nổ về nhu cầu. Tuy nhiên, thị trường còn ít hiểu biết tại sao card đồ họa cần được trang bị số lượng lớn mô-đun quang học và tại sao giao tiếp lại trở thành điểm yếu của các dòng máy cỡ lớn. Trong bài viết này, chúng ta sẽ bắt đầu từ các nguyên tắc và khám phá lý do tại sao mạng trở thành "vị trí C" mới trong kỷ nguyên AI. Chúng ta cũng sẽ thảo luận về sự đổi mới trong tương lai về phía mạng và các cơ hội đầu tư đằng sau nó dựa trên nền tảng. những thay đổi mới nhất của ngành.
Các yêu cầu về mạng đến từ đâu? Trong thời đại của các mô hình lớn, khoảng cách giữa khối lượng mô hình và giới hạn trên của một thẻ đã nhanh chóng mở rộng. Ngành này đã chuyển sang các cụm nhiều máy chủ để giải quyết vấn đề đào tạo mô hình, điều này cũng tạo cơ sở cho việc đào tạo mô hình. sự “tiến bộ” của mạng trong thời đại AI. Đồng thời, so với trước đây chỉ được sử dụng để truyền dữ liệu, mạng hiện được sử dụng nhiều hơn để đồng bộ hóa các thông số mô hình giữa các card đồ họa, điều này đặt ra yêu cầu cao hơn về mật độ và dung lượng mạng.
Khối lượng mô hình ngày càng lớn: (1) Thời gian đào tạo = kích thước dữ liệu đào tạo x số lượng tham số mô hình / tốc độ tính toán (2) Tốc độ tính toán = một Thiết bị tốc độ tính toán x số lượng thiết bị x hiệu suất song song đa thiết bị. Hiện tại, ngành đang theo đuổi mục tiêu kép về quy mô và thông số dữ liệu đào tạo. Chỉ bằng cách tăng tốc và cải thiện hiệu quả tính toán thì thời gian đào tạo mới có thể được rút ngắn. Vì vậy, sử dụng mạng như thế nào để phát huy tối đa hiệu quả đào tạo? Việc mở rộng “số lượng thiết bị” và “hiệu suất song song” quyết định trực tiếp đến sức mạnh tính toán.
Giao tiếp phức tạp của đồng bộ hóa nhiều thẻ: Trong quá trình đào tạo mô hình lớn, sau khi chia mô hình thành các thẻ đơn , Sau mỗi lần tính toán, các thẻ đơn cần được căn chỉnh (Giảm, Thu thập, v.v.). Đồng thời, trong hệ thống nguyên thủy giao tiếp NCCL, All-to-All của NVIDIA (nghĩa là tất cả các nút đều có thể lấy giá trị từ mỗi nút). các hoạt động khác) và căn chỉnh) phổ biến hơn, do đó đặt ra yêu cầu cao hơn về truyền tải và trao đổi giữa các mạng.
Chi phí thất bại ngày càng tốn kém: Việc đào tạo các mô hình lớn thường kéo dài hơn vài tháng và một khi xảy ra gián đoạn ở giữa , nó cần được đưa trở lại Retrain tại điểm dừng vài giờ hoặc vài ngày trước. Lỗi liên kết phần mềm hoặc phần cứng nhất định trong toàn bộ mạng hoặc độ trễ quá mức có thể dẫn đến gián đoạn. Nhiều gián đoạn hơn có nghĩa là tiến độ chậm hơn và chi phí cao hơn. Mạng AI hiện đại đã dần phát triển thành sự kết tinh của các khả năng kỹ thuật hệ thống của con người có thể so sánh với máy bay, tàu sân bay, v.v.
Đổi mới mạng sẽ đi về đâu? Phần cứng thay đổi theo nhu cầu. Sau hai năm, quy mô đầu tư sức mạnh điện toán toàn cầu đã mở rộng lên hàng chục tỷ đô la khi thông số mô hình mở rộng, cuộc chiến khốc liệt giữa những gã khổng lồ vẫn còn khốc liệt. Ngày nay, sự cân bằng giữa “giảm chi phí”, “độ mở” và quy mô sức mạnh tính toán sẽ là chủ đề chính của đổi mới mạng.
Những thay đổi trong phương tiện truyền thông:Ánh sáng, đồng và silicon là ba phương tiện lây truyền chính của con người Trong kỷ nguyên AI, các mô-đun quang học đang theo đuổi các công nghệ mới. Trong khi đạt được tốc độ cao, nó cũng đã đi theo con đường giảm chi phí như LPO, LRO và quang tử silicon. Tại thời điểm hiện tại, cáp đồng chiếm các kết nối trong tủ do các yếu tố như hiệu suất chi phí và tỷ lệ hỏng hóc. Các công nghệ bán dẫn mới như chiplets và chia tỷ lệ wafer đang đẩy nhanh việc khám phá giới hạn trên của kết nối dựa trên silicon.
Sự cạnh tranh của các giao thức mạng:Các giao thức giao tiếp giữa các chip bị ràng buộc chặt chẽ với card đồ họa, chẳng hạn như NV-LINK của NVIDIA và Infinity của AMD ;Vải, v.v., xác định giới hạn trên về khả năng của một máy chủ hoặc một nút điện toán duy nhất và là một chiến trường rất tàn khốc đối với những người khổng lồ. Cuộc đấu tranh giữa IB và Ethernet là chủ đề giao tiếp chính giữa các nút.
Những thay đổi trong kiến trúc mạng:Kiến trúc mạng hiện tại giữa các nút thường áp dụng kiến trúc lá-spine có các đặc điểm. sự tiện lợi, đơn giản và ổn định. Tuy nhiên, khi số lượng nút trong một cụm tăng lên, kiến trúc hơi dư thừa của gân lá sẽ mang lại chi phí mạng lớn hơn cho các cụm rất lớn. Hiện tại, các kiến trúc mới như kiến trúc Dragonfly và kiến trúc chỉ dành cho đường sắt được kỳ vọng sẽ trở thành hướng phát triển cho thế hệ tiếp theo của các cụm rất lớn.
Gợi ý đầu tư: Liên kết cốt lõi của hệ thống truyền thông: Zhongji InnoLight, Xinyisheng, Tianfu Communications, Industrial Fortune Lianhe, Invic, và Công ty TNHH Điện lực Hudian Truyền thông Liên kết đổi mới hệ thống truyền thông : YOFC, Taichenguang, Yuanjie Technology, Shengke Communications-U , Cambrian, Decoli.
Nhắc nhở rủi ro: Nhu cầu AI thấp hơn dự kiến, luật mở rộng quy mô thất bại và cạnh tranh trong ngành ngày càng gay gắt

1. Yêu cầu đầu tư< p style="text-align: left;">Thị trường chưa hiểu đầy đủ về tầm quan trọng của mạng truyền thông trong đào tạo AI. Kể từ khi có thị trường AI, thị trường đã chú ý hơn đến việc nghiên cứu chuỗi công nghiệp mạng từ logic chuỗi công nghiệp. Hướng nghiên cứu chính tập trung vào số lượng mô-đun quang cần thiết cho mỗi thế hệ kiến trúc mạng. và dựa trên đó, sản lượng và hiệu suất của từng mắt xích trong chuỗi ngành đã được tính toán, nhưng thị trường chưa thực hiện được nhiều nghiên cứu về mối quan hệ cơ bản giữa AI và truyền thông. Bài viết này tiến hành thảo luận sâu hơn về vị trí cốt lõi của mạng truyền thông trong kỷ nguyên AI từ ba khía cạnh chính: mô hình, đồng bộ hóa nhiều thẻ và hiệu quả chi phí đào tạo.
Tóm lại, có ba lý do chính khiến truyền thông đạt vị trí C trong kỷ nguyên AI. Đầu tiên, Với khối lượng mô hình ngày càng lớn, số lượng card đồ họa và hiệu suất tính toán sau khi kết nối trực tiếp quyết định thời gian cần thiết cho việc đào tạo và thời gian chính xác là thứ quý giá nhất trong cuộc cạnh tranh AI khổng lồ ngày càng khốc liệt . nguồn. Thứ hai, Bắt đầu từ nguyên tắc đào tạo, sau khi chế độ song song chính thống chuyển từ song song mô hình sang song song dữ liệu, sau mỗi lớp hoạt động, các NPU khác nhau trong cụm cần căn chỉnh các tham số và dữ liệu hiện có. Quá trình xử lý hàng nghìn lần chip đòi hỏi yêu cầu mạng cực cao để đảm bảo độ trễ và độ chính xác thấp. Thứ ba, chi phí khi mạng bị lỗi là cực kỳ cao. Thời gian đào tạo mô hình hiện tại thường kéo dài trong vài tháng. Một khi có nhiều lỗi hoặc gián đoạn, thậm chí có thể khôi phục về điểm lưu trong vài giờ. trước đây, nó sẽ có tác động tiêu cực đến hiệu quả đào tạo tổng thể và Chi phí cũng sẽ gây ra tổn thất lớn, điều này thậm chí còn nguy hiểm hơn đối với các lần lặp lại sản phẩm AI khổng lồ mà mỗi giây đều có giá trị. Đồng thời, quy mô cụm hiện tại đã lên tới 10.000 thẻ và có thể có hàng trăm nghìn thành phần được kết nối. Làm thế nào để đảm bảo tính ổn định tổng thể và tỷ lệ năng suất của các thành phần này đã trở thành một kỹ thuật hệ thống cực kỳ sâu sắc.
Thị trường thiếu hiểu biết về hướng phát triển trong tương lai của mạng truyền thông. Hiểu biết của thị trường về sự lặp lại của mạng truyền thông vẫn ở mức độ nghiên cứu sau khi thay thế cạc đồ họa. Chúng tôi tin rằng chu kỳ và hướng cập nhật do việc lặp lại phần cứng mang lại là tương đối cố định, trong khi các lần lặp lại theo các hướng khác và mức độ đổi mới của chuỗi ngành đang tăng lên từng ngày. Đồng thời, vốn đầu tư AI của các đại gia nước ngoài vào cuộc chiến hiện nay đã lên tới hàng chục tỷ đô la, và với việc mở rộng các thông số mô hình, cuộc chiến khốc liệt giữa các đại gia vẫn còn khốc liệt. Ngày nay, sự cân bằng giữa "giảm chi phí", "độ mở" và quy mô sức mạnh tính toán sẽ là chủ đề chính của đổi mới mạng.
Nói chung, việc khám phá các công nghệ tiên tiến của chuỗi ngành chủ yếu tập trung vào ba hướng. Đầu tiên, sự lặp lại của phương tiện truyền thông, không chỉ bao gồm tiến bộ chung của ba chất nền là ánh sáng, đồng và silicon mà còn cả những đổi mới công nghệ trong các phương tiện truyền thông khác nhau, chẳng hạn như LPO, LRO, ánh sáng silicon, và chiplets, chia tỷ lệ wafer, v.v. Thứ hai, việc đổi mới các giao thức truyền thông Điều này cũng bao gồm hai khía cạnh. Thứ nhất, giao tiếp nội bộ của các nút, chẳng hạn như NVLINK và Infinity Fabric, và sự đổi mới trong lĩnh vực này là vô cùng khó khăn và nó thuộc về chiến trường. gã khổng lồ Thứ hai, giao tiếp giữa các nút, ngành này chủ yếu tập trung vào sự cạnh tranh giữa hai giao thức chính IB và Ethernet. Thứ ba, cập nhật kiến trúc mạng, liệu kiến trúc lá có thể thích ứng với số lượng lớn nút hay không, liệu Drangonfly có thể trở thành xu hướng chủ đạo của kiến trúc mạng thế hệ tiếp theo với sự trợ giúp của OCS hay không và liệu Tối ưu hóa phần mềm chỉ dành cho đường sắt + có thể trưởng thành. Đây là một khía cạnh mới của ngành.
Xúc tác ngành:
1 Luật mở rộng quy mô tiếp tục có hiệu lực và quy mô của cụm đã tăng lên Bộ phận đang mở rộng và nhu cầu về mạng truyền thông tiếp tục tăng.
2. AI ở nước ngoài đang tăng tốc và các gã khổng lồ Internet đang đẩy nhanh cuộc cạnh tranh chi tiêu vốn của họ.
Lời khuyên đầu tư: Các liên kết cốt lõi của hệ thống truyền thông: Zhongji InnoLight, Xinyisheng, Tianfu Communications và Shanghai Electric Co., Ltd.
Liên kết đổi mới hệ thống truyền thông: YOFC, Zhongtian Technology, Hengtong Optoelectronics, Shengke Communications.
2. Chuyển từ kỷ nguyên điện toán đám mây sang kỷ nguyên AI, tại sao giao tiếp ngày càng trở nên phổ biến quan trọng hơn< /p>
Sự vinh quang của vòng giao tiếp cuối cùng có thể bắt nguồn từ thời kỳ Internet Nhu cầu bùng nổ về truyền tải lưu lượng mạng đã cho phép nhân loại. lần đầu tiên xây dựng các máy chủ và bộ lưu trữ lớn Một hệ thống chuyển mạch được hình thành cùng với các bộ chuyển mạch. Trong vòng xây dựng này, Cisco nổi bật và trở thành người dẫn đầu về tiến bộ công nghệ của con người. Tuy nhiên, khi làn sóng Internet có xu hướng lắng xuống, các mô-đun quang và thiết bị chuyển mạch sẽ biến động nhiều hơn theo tình hình kinh tế vĩ mô, chi tiêu trên đám mây và cập nhật sản phẩm, đồng thời có xu hướng thay đổi về tốc độ và công nghệ theo từng bước nhiều hơn. đã bước vào một chu kỳ phát triển ổn định với những biến động đi lên.
Trong thời đại của các mô hình nhỏ, ngành tập trung nhiều hơn vào đổi mới thuật toán. Thông thường, toàn bộ khối lượng mô hình có thể được xử lý bởi một thẻ, một máy chủ hoặc một máy chủ. Cụm nhỏ tương đối đơn giản, do đó, yêu cầu kết nối mạng từ phía AI không nổi bật. Nhưng sự xuất hiện của các mô hình lớn đã thay đổi mọi thứ. OpenAI đã chứng minh rằng hiện tại, việc sử dụng thuật toán Transformer đơn giản hơn và các tham số xếp chồng có thể cải thiện hiệu suất của mô hình tốt hơn. Do đó, toàn bộ ngành đã bước vào giai đoạn phát triển nhanh chóng về việc mở rộng khối lượng mô hình một cách nhanh chóng.
Trước tiên chúng ta hãy xem xét hai công thức cơ bản xác định tốc độ tính toán của mô hình, để chúng ta hiểu rõ hơn tại sao trong thời đại của các mô hình lớn, quy mô của sức mạnh tính toán hoặc phần cứng sức mạnh tính toán Chuỗi công nghiệp sẽ là chuỗi công nghiệp đầu tiên được hưởng lợi.
(1) Thời gian đào tạo = kích thước dữ liệu đào tạo x lượng tham số mô hình/tốc độ tính toán
(2) Tốc độ tính toán = tốc độ tính toán của một thiết bị x số lượng thiết bị x hiệu suất song song của nhiều thiết bị
Trong thời đại mô hình lớn hiện nay, chúng ta có thể thấy hai yếu tố ở cuối tử số của thời gian huấn luyện đang đồng thời mở rộng. Khi sức mạnh tính toán không đổi thì thời gian huấn luyện sẽ được kéo dài theo cấp số nhân và khi nó trở nên lớn hơn. Càng ngày càng căng thẳng, thời gian huấn luyện sẽ dài hơn theo cấp số nhân. Trong chiến trường mô hình khổng lồ, thời gian là nguồn tài nguyên quý giá nhất. Do đó, con đường dẫn đến cạnh tranh rất rõ ràng và cách duy nhất là tăng tốc độ tích lũy sức mạnh tính toán.
Trong công thức thứ hai, chúng ta có thể thấy rằng trong sức mạnh tính toán ngày càng mở rộng ngày nay, sức mạnh tính toán của một thẻ bị hạn chế do kích thước mô hình và giới hạn trên giới hạn cập nhật chip. Tỷ lệ sức mạnh tính toán đã giảm từ tổng thể xuống chỉ còn một liên kết. Số lượng card đồ họa và hiệu suất song song của nhiều thiết bị cũng trở thành hai mắt xích quan trọng không kém. , hy vọng tăng tốc độ tính toán có thể dẫn đầu trong mọi yếu tố quyết định.
Chúng tôi đã trình bày chi tiết về các lộ trình khác nhau của sức mạnh tính toán một thẻ trong báo cáo trước đây "Con đường ASIC đến sức mạnh tính toán AI - Bắt đầu với máy khai thác Ethereum", tôi sẽ không đi sâu vào chi tiết trong bài viết này, nhưng hai mục cuối cùng mà chúng ta đã thấy, số lượng thiết bị và hiệu suất song song của nhiều thiết bị, không thể đạt được một cách đơn giản bằng cách xếp chồng số lượng card đồ họa. Số lượng thiết bị càng lớn, độ tin cậy của cấu trúc mạng và các yêu cầu tối ưu hóa cho tính toán song song càng tăng theo cấp số nhân. Đây là lý do cuối cùng khiến mạng trở thành một trong những điểm nghẽn quan trọng của AI. Trong phần này, chúng ta sẽ bắt đầu từ nguyên tắc đào tạo và giải thích tại sao việc sắp xếp thiết bị và cải thiện hoạt động bán hàng song song lại là kỹ thuật hệ thống phức tạp nhất trong lịch sử loài người.
2.1 Nguyên tắc hợp tác Doka trong kỷ nguyên của các mô hình lớn, song song mô hình và song song dữ liệu< / p>
Trong đào tạo mô hình, quá trình chia mô hình thành nhiều thẻ không đơn giản như quy trình truyền thống hoặc phân vùng đơn giản mà sử dụng một phương pháp phức tạp hơn để phân bổ nhiệm vụ giữa các card đồ họa. Nhìn chung, các phương pháp phân bổ nhiệm vụ có thể được chia đại khái thành hai loại: song song mô hình và song song dữ liệu.
Khi kích thước mô hình nhỏ nhưng lượng dữ liệu tăng lên, ngành thường áp dụng song song dữ liệu. Trong các hoạt động song song dữ liệu, một bản sao hoàn chỉnh của mô hình được giữ lại trên mỗi GPU và dữ liệu huấn luyện được chia và nhập vào các card đồ họa khác nhau để huấn luyện. Sau khi truyền ngược, độ dốc của bản sao mô hình trên mỗi thẻ sẽ đồng thời giảm xuống. . Tuy nhiên, khi các tham số mô hình mở rộng, việc một card đồ họa duy nhất có thể đáp ứng mô hình hoàn chỉnh ngày càng trở nên khó khăn. Do đó, trong quá trình huấn luyện các mô hình đầu lớn, tính song song của dữ liệu đang giảm dần như một phương pháp phân bổ song song duy nhất.
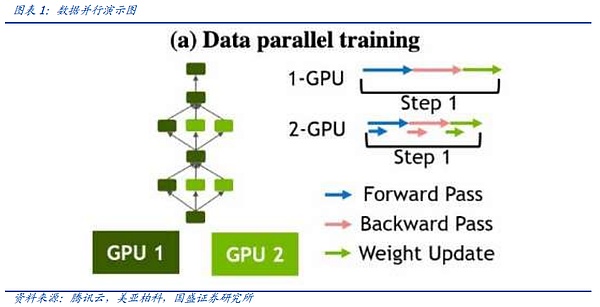
Song song mô hình là một phương pháp phân phối đang dần nổi lên trong thời đại của các mô hình lớn. Vì mô hình quá lớn nên các phần khác nhau của mô hình sẽ được tải vào card đồ họa và cùng một luồng dữ liệu được đưa vào card đồ họa để huấn luyện các thông số của từng phần.
Có hai chế độ song song mô hình chính, đó là song song tensor và song song đường ống. Trong phép nhân ma trận hoạt động cơ bản của một hoạt động huấn luyện mô hình (C=AxB), tính song song tensor đề cập đến việc trước tiên chia ma trận B thành nhiều vectơ, mỗi thiết bị giữ một vectơ, sau đó kết hợp ma trận A với mỗi vectơ. lên kết quả để tóm tắt bằng chứng của C.
Tính song song của đường ống chia mô hình theo lớp và chia mô hình thành nhiều khối theo lớp. Mỗi khối được cấp cho một thiết bị để xử lý, đồng thời. , nó được xử lý bởi giai đoạn trước. Trong quá trình lan truyền thuận, mỗi thiết bị chuyển các kích hoạt trung gian sang giai đoạn tiếp theo và trong quá trình lan truyền ngược tiếp theo, mỗi thiết bị sẽ chuyển độ dốc của tenxơ đầu vào trở lại giai đoạn đường ống trước đó.
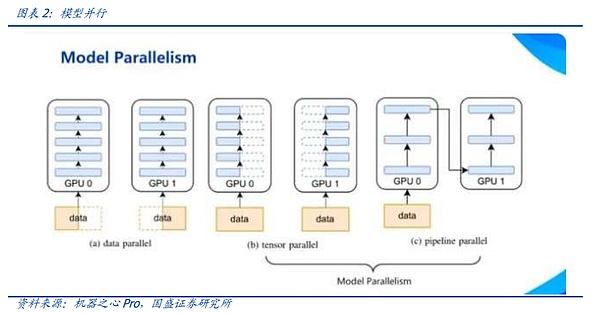
Trong đào tạo mô hình lớn hiện nay, không có sự song song dữ liệu nào có thể tồn tại một mình. Trong đào tạo mô hình đầu lớn, thường cần phải kết hợp các công nghệ nêu trên để đạt được sự song song lai đa chiều. Trong quá trình kết nối thực tế, cụm AI sẽ được chia thành nhiều giai đoạn, mỗi giai đoạn tương ứng với một lô logic và mỗi giai đoạn bao gồm một số nút GPU. Về mặt kiến trúc, điều này đáp ứng nhu cầu song song lai đa chiều.
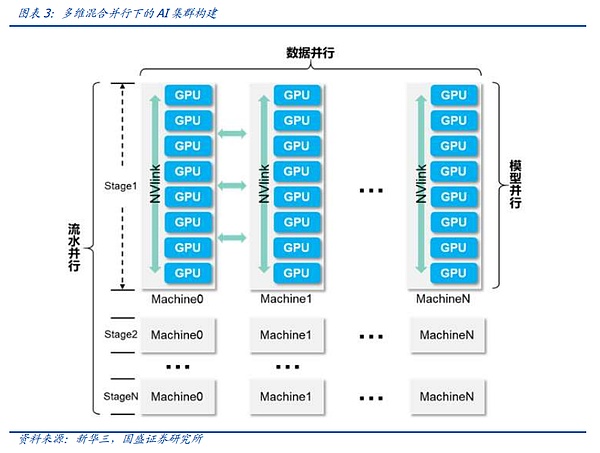
Cho dù là loại phương pháp song song nào thì sau mỗi vòng tính toán, các thông số trong mỗi GPU cần được đồng bộ hóa thông qua phát sóng ngược. Các phương pháp song song khác nhau tương ứng với các lần phát sóng khác nhau. Độ trễ cũng cần phải dựa vào các giao thức mạng khác nhau hoặc phương tiện truyền thông Từ đây, chúng ta có thể thấy rằng việc xây dựng cụm mạng hiện tại đang dần phát triển từ “truyền tải” sang “kỹ thuật hệ thống” thực sự.
2.2 Lõi kết nối nhiều thẻ trong kỷ nguyên mô hình lớn: độ chính xác đồng bộ hóa >
Một chức năng quan trọng được cụm mạng AI đảm nhận là căn chỉnh kết quả phân công lao động đào tạo card đồ họa khác nhau giữa các đơn vị tính toán, sao cho đồ họa thẻ Có thể thực hiện bước tiếp theo của công việc, công việc này còn được gọi là phát sóng ngược. Vì kết quả thường được xử lý bằng cách sử dụng Giảm, Thu thập và các thuật toán khác trong quá trình phát sóng nên chương trình phát sóng toàn cầu được gọi là Tất cả cho tất cả. Cụm AI Độ trễ phổ biến của All-to-All trong các chỉ báo hiệu suất đề cập đến thời gian cần thiết để thực hiện phát sóng ngược toàn cầu.
Về nguyên tắc, việc thực hiện phát sóng ngược để đồng bộ hóa dữ liệu có vẻ dễ dàng hơn. Nó chỉ yêu cầu mỗi card đồ họa gửi dữ liệu cho nhau nhưng trong mạng thực. cụm Trong quá trình xây dựng, sẽ gặp phải nhiều vấn đề, điều này khiến cho việc rút ngắn độ trễ này trở thành một hướng đi chính được nhiều giải pháp mạng khác nhau theo đuổi.
Vấn đề đầu tiên là khoảng thời gian cần thiết để mỗi card đồ họa hoàn thành phép tính hiện tại không nhất quán. cùng một nhóm hoàn thành, việc phát sóng ngược sau tác vụ sẽ khiến card đồ họa hoàn thành tác vụ đầu tiên mất nhiều thời gian nhàn rỗi, từ đó làm giảm hiệu suất của toàn bộ cụm máy tính. Tương tự như vậy, nếu bạn áp dụng phương pháp đồng bộ hóa quá mạnh mẽ, bạn có nguy cơ gây ra lỗi trong quá trình đồng bộ hóa, khiến quá trình đào tạo bị gián đoạn. Vì vậy, phương pháp đồng bộ hóa ổn định và hiệu quả luôn là hướng đi được ngành theo đuổi.
Theo quan điểm hiện tại, các phương pháp đồng bộ hóa chính có thể được chia thành song song đồng bộ, song song không đồng bộ, Giảm toàn bộ, v.v.
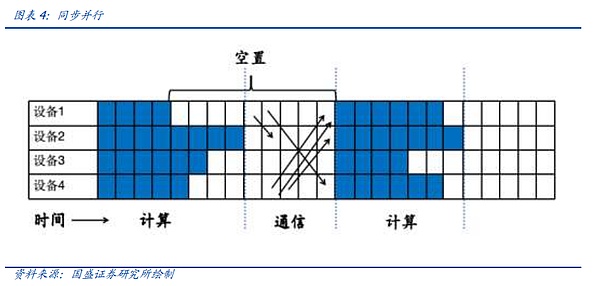
Trước tiên chúng ta hãy xem xét song song đồng bộ. Chúng tôi đã đề cập đến ý tưởng về song song đồng bộ trong bài viết trước, tức là sau tất cả các đơn vị tính toán trong đơn vị hiện tại. hoàn thành các tính toán của họ. Ưu điểm của truyền thông hợp nhất là tính ổn định và đơn giản, nhưng nó sẽ khiến một số lượng lớn các đơn vị máy tính bị bỏ trống. Lấy hình dưới đây làm ví dụ. Sau khi đơn vị tính toán hoàn thành việc tính toán, nó cần đợi đơn vị tính toán 4 hoàn thành việc tính toán và chờ giao tiếp tập thể, dẫn đến số lượng chỗ trống lớn và làm giảm hiệu suất chung của cụm. .
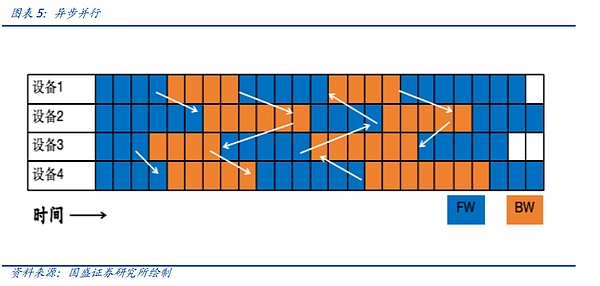
Song song không đồng bộ là sự lựa chọn khi đối mặt với các mô hình lớn không tạo ra như khuyến mãi lãi suất. Khi một thiết bị hoàn thành một vòng tính toán thuận và ngược, thiết bị đó không cần đợi thiết bị khác hoàn thành chu trình và trực tiếp đồng bộ hóa dữ liệu , Trong chế độ truyền này, việc huấn luyện mô hình mạng không hội tụ và không phù hợp với việc huấn luyện mô hình lớn mà phù hợp hơn với các mô hình tìm kiếm, mô hình đề xuất, v.v.
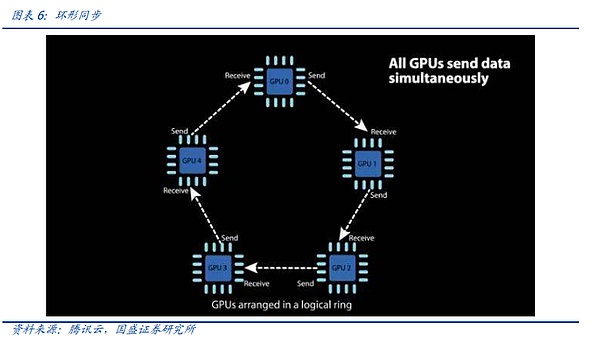
Loại thứ ba cũng là loại được sử dụng phổ biến nhất là All-Reduce hoặc All-to-All-Reduce, tức là tổng hợp (Reduce) thông tin trên tất cả các thiết bị (All) đến tất cả các thiết bị (All) TRÊN. Rõ ràng, All-Reduce trực tiếp sẽ mang lại sự lãng phí lớn về tài nguyên truyền thông, vì cùng một dữ liệu có thể được truyền dư thừa nhiều lần. Do đó, nhiều phiên bản tối ưu hóa của thuật toán All-Reduce đã được đề xuất, chẳng hạn như All-Reduce vòng, All-Reduce dựa trên cây nhị phân, v.v. Các thuật toán này có thể làm giảm đáng kể băng thông và độ trễ của All-Reduce.
Chúng tôi lấy Ring All-Reduce do công ty dẫn đầu AI của Trung Quốc là Baidu phát minh ra làm ví dụ minh họa cách các kỹ sư điện toán phân tán rút ngắn thời gian đồng bộ hóa thông qua việc lặp lại liên tục.
Trong Ring All-Reduce (đồng bộ hóa vòng), mỗi thiết bị chỉ cần giao tiếp với hai thiết bị khác, được chia thành Scatter-Reduce và All-Gather. các bước. Đầu tiên, nhiều thao tác Giảm phân tán được thực hiện trên các thiết bị lân cận và một phần dữ liệu hoàn chỉnh tổng hợp sẽ được lấy trên mỗi thiết bị. Sau đó, mỗi thiết bị sẽ căn chỉnh các thiết bị lân cận để hoàn thành nhiều thao tác All-Gather nhằm hoàn thành dữ liệu hoàn chỉnh trong mỗi thiết bị. Ring All-Reduce không chỉ có thể giảm băng thông và độ trễ mà còn đơn giản hóa cấu trúc liên kết mạng và giảm chi phí xây dựng mạng.
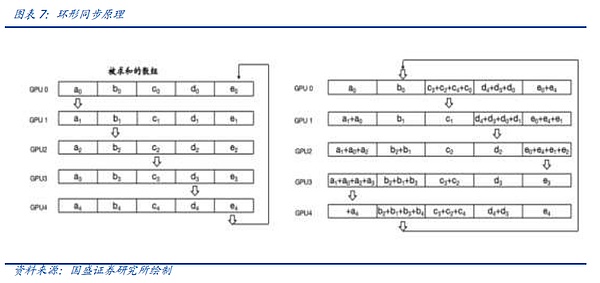
Nhưng dù đó là thuật toán nào thì nó cũng phụ thuộc vào mạng Sự hỗ trợ của phần cứng truyền thông, cho dù đó là hỗ trợ băng thông lớn hơn từ cấp độ giao thức và gốc chip, hay chuyển từ kết nối dây đồng thuần túy sang NVLink, hoặc giới thiệu giao thức IB, sự bùng nổ của nhu cầu RDMA là để đáp ứng nhu cầu ngày càng phức tạp yêu cầu về nhu cầu liên lạc và đồng bộ hóa, chúng tôi sẽ mở rộng về những nội dung này trong các bài viết sau.
Tại thời điểm này, chúng tôi đã hiểu sơ bộ về logic cấp độ nguyên tắc về lý do tại sao AI yêu cầu giao tiếp mật độ cao. Đầu tiên, từ mô hình nhỏ. kỷ nguyên sang kỷ nguyên mô hình lớn Chuyển đổi nhanh chóng làm cho các cụm nhiều nút và đào tạo phân tán trở nên cần thiết. Khi chia mô hình thành các nút điện toán khác nhau để tính toán, cách phân chia nó và cách đảm bảo đồng bộ hóa là một kỹ thuật hệ thống phức tạp hơn và giao tiếp là yếu tố chính. Nguyên tắc của tất cả phần mềm này Cơ sở để triển khai là các thành phần truyền thông và mạng truyền thông chất lượng cao, thông lượng cao và có độ ổn định cao.
2.3 Kỹ thuật hệ thống trong thời đại của các mô hình lớn: giám sát-tóm tắt-đổi mới, lặp đi lặp lại luôn được tiến hành.
Ở trên, chúng tôi đã giải thích rằng nguyên tắc đào tạo quyết định sự phụ thuộc của mô hình lớn vào hệ thống truyền thông. Vô số yêu cầu đồng bộ hóa và song song khác nhau và phức tạp hình thành nên luồng dữ liệu trong các cụm AI. Mặc dù mạng truyền thông được điều khiển bởi các yêu cầu đó nhưng tốc độ và số lần lặp lại sản phẩm không ngừng tăng tốc và các phương thức kết nối không ngừng được đổi mới. vẫn chưa có cụm hoàn hảo nào có thể giải quyết mọi vấn đề một lần và mãi mãi. Mặc dù độ ổn định của cụm liên tục được tối ưu hóa, nhưng thỉnh thoảng các điểm dừng và gián đoạn vẫn xảy ra trong một hệ thống bao gồm hàng triệu thiết bị chính xác.
Do đó, các hướng phát triển của hệ thống truyền thông mô hình lớn có thể được chia đại khái thành ba. Một là khả năng giám sát của các hệ thống mô hình lớn và khả năng nhận biết dòng chảy. dữ liệu mô hình lớn trong thời gian thực, trạng thái hoạt động, để có thể phát hiện lỗi kịp thời. Trong quá trình này, việc chụp gói phần mềm và phần cứng dựa trên trực quan hóa mạng đã trở thành một phương pháp chủ đạo thông qua chip FPGA và phần mềm đặc biệt. trong cụm được giám sát, từ đó cung cấp cơ sở cho nhận thức. Công cụ
Việc thu thập gói dữ liệu được thực hiện bằng phần mềm được sử dụng phổ biến nhất. > Các sản phẩm nổi tiếng trong và ngoài nước bao gồm Wireshark (xử lý TCP/UDP), Fiddler (Xử lý HTTP/HTTPS), tcpdump&windump, Solarwinds, nast, Kismet, v.v. Lấy Wireshark làm ví dụ, nguyên lý làm việc cơ bản của nó là: chương trình đặt chế độ làm việc của card mạng thành "chế độ lăng nhăng" (ở chế độ bình thường, card mạng chỉ xử lý các gói dữ liệu thuộc địa chỉ MAC của chính nó. Ở chế độ lăng nhăng, card mạng xử lý tất cả các gói đi qua nó), trong khi Wireshark chặn, truyền lại, chỉnh sửa và loại bỏ các gói.
Việc chụp gói phần mềm sẽ chiếm một phần hiệu suất của hệ thống. Trước hết, ở chế độ lăng nhăng, card mạng ở "chế độ phát sóng" và sẽ xử lý tất cả các gói dữ liệu được gửi và nhận bởi lớp bên dưới của mạng, chính việc này sẽ tiêu tốn một phần hiệu suất của card mạng thứ hai, việc chụp gói phần mềm không phải là chụp nối tiếp hoặc song song ở lớp liên kết mà là sao chép và lưu trữ các gói dữ liệu, chiếm một phần tài nguyên CPU và lưu trữ. Đồng thời, hầu hết các phần mềm như Wireshark chỉ có thể giám sát lưu lượng của một nút mạng duy nhất trong hệ thống và không thể bao phủ mạng toàn cầu. Nó phù hợp cho các hoạt động khắc phục sự cố thụ động và không phù hợp để giám sát rủi ro chủ động.
Để không ảnh hưởng đến hiệu suất chung của hệ thống, các công cụ kết hợp phần mềm và phần cứng để truy cập song song hoặc nối tiếp đã xuất hiện. và DFI. DPI (Kiểm tra gói sâu) là chức năng phát hiện và kiểm soát lưu lượng truy cập dựa trên thông tin lớp ứng dụng của gói. DPI tập trung vào việc phân tích lớp ứng dụng và có thể xác định các ứng dụng khác nhau cũng như nội dung của chúng. Khi các gói dữ liệu IP, luồng dữ liệu TCP hoặc UDP đi qua một thiết bị phần cứng hỗ trợ công nghệ DPI, thiết bị sẽ tập hợp lại và phân tích tải trọng tin nhắn bằng cách đọc sâu để xác định nội dung của toàn bộ ứng dụng, sau đó xử lý theo quy định. chính sách quản lý được xác định bởi thiết bị. Lưu lượng truy cập sẽ được xử lý sau. DFI (Kiểm tra luồng sâu/động) sử dụng công nghệ nhận dạng ứng dụng dựa trên hành vi lưu lượng, nghĩa là, các loại ứng dụng khác nhau có trạng thái khác nhau được phản ánh trong các kết nối phiên hoặc luồng dữ liệu. Công nghệ DPI phù hợp với các môi trường yêu cầu nhận dạng chính xác và tỉ mỉ, trong khi công nghệ DFI phù hợp với các môi trường yêu cầu nhận dạng hiệu quả và quản lý sâu rộng.
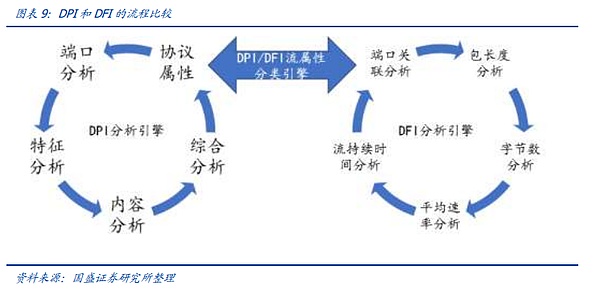
DPI/DFI được kết nối nối tiếp/song song với lớp vật lý bằng phần cứng độc lập và sẽ không ảnh hưởng đến hiệu suất của lớp vật lý. Lấy ví dụ về các sản phẩm phần mềm và phần cứng có phạm vi rộng và sâu, có thể được triển khai trên các nút mạng ở tất cả các cấp độ của mạng viễn thông, đồng thời hoàn thành việc thu thập, phân tích và trình bày dữ liệu từ các nút giám sát ở mọi cấp độ thông qua SaaS/PaaS. Phần cứng DPI được kết nối nối tiếp hoặc song song với lớp vật lý giao tiếp để đạt được khả năng giám sát mạng gần như không mất dữ liệu bằng cách phản chiếu các gói dữ liệu. Phần mềm dpi được nhúng trong phần cứng dpi, máy chủ độc lập hoặc bộ chuyển mạch/bộ định tuyến để cho phép giám sát mạng.
Sau khi giải quyết vấn đề giám sát, kỹ thuật hệ thống mô hình lớn Con đường lặp lại có nền tảng, như đã đề cập trước đó, trong thực tế, điều cần được chú ý hơn là sự cân bằng giữa hiệu quả vận hành hệ thống và tính ổn định, một mặt, chúng ta tối ưu hóa phương pháp Giảm, đổi mới các phương pháp song song, v.v. Tạo ra các phương pháp và lý thuyết đào tạo mới, những đổi mới cơ bản trong đào tạo phân tán. Tuy nhiên, những đổi mới cơ bản luôn đòi hỏi sự hỗ trợ của các thiết bị chuyển mạch thông lượng cao hơn, giao thức chuyển mạch phù hợp hơn, các thiết bị liên lạc ổn định hơn và rẻ hơn sẽ luôn là yếu tố chính. một phần không thể thiếu trong việc nâng cấp hệ thống mô hình.
3.Sự cạnh tranh và sự lặp lại của các giao thức truyền thông: quyền lên tiếng trong việc truyền tải luồng dữ liệu AI< /p >
Trong chương trước, chúng tôi đã giải thích một cách có hệ thống các chức năng giao tiếp chính trong cụm AI. Trong phần này, chúng tôi sẽ giới thiệu một cách có hệ thống các thành phần cấu thành nên toàn bộ. hệ thống truyền thông Phần cơ bản nhất - giao thức truyền thông.
Về mặt trực quan, một hệ thống truyền thông chủ yếu bao gồm phần cứng vật lý như bộ chuyển mạch, mô-đun quang, cáp, card mạng, v.v., nhưng trên thực tế, điều gì thực sự quyết định một hệ thống truyền thông là các giao thức truyền thông chạy bên trong phần cứng vật lý thiết lập, vận hành và thực hiện các đặc tính hiệu suất. Giao thức truyền thông là một loạt các thỏa thuận mà cả hai bên giao tiếp phải tuân theo để đảm bảo việc truyền dữ liệu trơn tru và chính xác trong mạng máy tính. Các thỏa thuận này bao gồm định dạng dữ liệu, quy tắc mã hóa, tốc độ truyền, các bước truyền, v.v.
Trong kỷ nguyên AI, các giao thức truyền thông chủ yếu được phân thành hai loại. Thứ nhất, giao tiếp tốc độ cao giữa các thẻ máy tính trong các nút máy tính, loại này. Giao thức có các đặc điểm là tốc độ nhanh, khả năng niêm phong mạnh mẽ và khả năng mở rộng yếu. Nó thường là một trong những rào cản năng lực cốt lõi của các nhà sản xuất card đồ họa khác nhau, v.v., yêu cầu hỗ trợ ở cấp độ chip. Loại giao thức thứ hai là giao thức được sử dụng để kết nối các nút máy tính. Loại giao thức này có đặc điểm là tốc độ chậm và khả năng mở rộng mạnh mẽ. Loại giao thức thứ hai hiện có hai dòng chính là giao thức InfiniBand và RoCE thuộc họ Giao thức Ethernet. loại giao thức đảm bảo khả năng truyền dữ liệu qua các nút và là cơ sở để xây dựng các cụm rất lớn. Nó cũng cung cấp giải pháp cho các đơn vị tính toán thông minh truy cập vào trung tâm dữ liệu.
3.1 Giao tiếp nội bộ nút - rào cản cốt lõi của các nhà sản xuất lớn, niềm hy vọng của "Định luật Moore" về sức mạnh tính toán
Giao tiếp nội bộ nút, tức là giao thức giao tiếp card đồ họa trong một máy chủ, chịu trách nhiệm kết nối tốc độ cao giữa các card đồ họa trong cùng một máy chủ. hiện tại, giao thức này chủ yếu bao gồm các thỏa thuận PCIe, NVLink và Infinity Fabric 3.
Trước tiên chúng ta hãy xem giao thức PCIe có lịch sử lâu đời nhất. Giao thức PCIe là một giao thức mở và phổ biến. Các phần cứng khác nhau trong máy chủ cá nhân truyền thống đều vượt qua PCIe. Để kết nối, trong máy chủ điện toán do bên thứ ba lắp ráp, các card đồ họa vẫn được kết nối với nhau như một máy chủ truyền thống thông qua khe cắm PCIe và đường PCIe trên bo mạch chủ.
PCIe là giao thức bus được sử dụng rộng rãi nhất. Bus là đường dẫn truyền dữ liệu giữa các phần cứng khác nhau trên bo mạch chủ máy chủ. Nó đóng vai trò quyết định tốc độ truyền dữ liệu. Giao thức bus phổ biến nhất hiện nay là giao thức PCIe (PCI-Express) do Intel đề xuất. vào năm 2001. PCIe được sử dụng chủ yếu. Để kết nối CPU với các thiết bị tốc độ cao khác như GPU, SSD, card mạng, card đồ họa, v.v., phiên bản PCIe 1.0 được phát hành vào năm 2003. Nó sẽ được cập nhật khoảng ba lần một lần. năm. Nó đã được cập nhật lên phiên bản 6.0 với tốc độ truyền lên tới 64GT/s và 16 kênh. Với băng thông đạt 256 GB/s, hiệu suất và khả năng mở rộng tiếp tục được cải thiện.
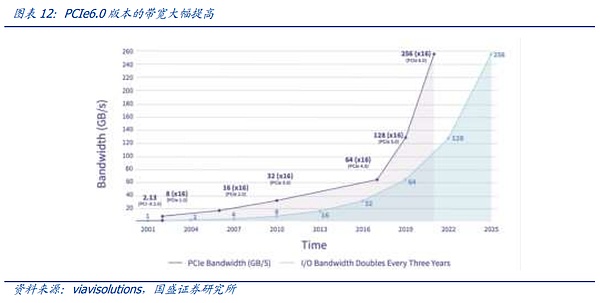
Cấu trúc liên kết cây bus PCIe và phương thức truyền dẫn đầu cuối giới hạn số lượng và tốc độ kết nối, và PCIe Switch đã ra đời. PCIe sử dụng liên kết truyền dữ liệu đầu cuối. Chỉ có thể kết nối một thiết bị với mỗi đầu của liên kết PCIe. Số lượng nhận dạng thiết bị bị hạn chế và không thể đáp ứng các trường hợp có nhiều thiết bị được kết nối hoặc. Do đó, việc truyền tải dữ liệu tốc độ cao là cần thiết. PCIe Switch có chức năng kép là kết nối và chuyển mạch, cho phép một cổng PCIe xác định và kết nối nhiều thiết bị hơn, giải quyết vấn đề không đủ số lượng kênh và kết nối nhiều bus PCIe với nhau để tạo thành một mạng tốc độ cao nhằm đạt được giao tiếp đa thiết bị. Tóm lại, PCIe Switch tương đương với một thiết bị mở rộng PCIe.
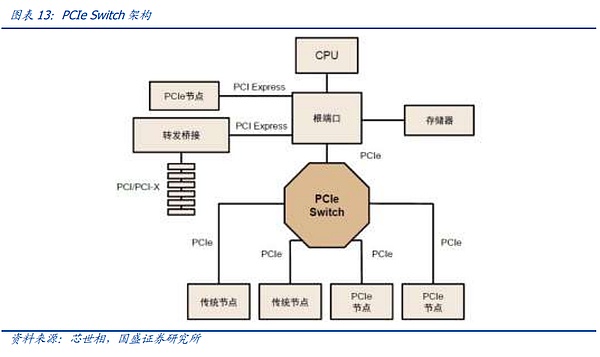
Nhưng như đã đề cập ở trên, khi quy mô mô hình dần mở rộng và chu trình đồng bộ hóa giữa các NPU ngày càng phức tạp, PCIE với tốc độ thấp và không có chế độ vận hành mô hình được tối ưu hóa đặc biệt không còn có thể đáp ứng nhu cầu của kỷ nguyên mô hình lớn Do đó, các giao thức độc quyền của các nhà sản xuất card đồ họa lớn đang nhanh chóng xuất hiện trong thời đại của các mẫu card lớn.
Chúng tôi tin rằng giao thức thu hút nhiều sự chú ý nhất trong ngành và phát triển nhanh nhất là giao thức kết nối GPU tốc độ cao. được NVIDIA đề xuất so sánh với giao thức PCIe Bus truyền thống, NVLINK chủ yếu thực hiện những thay đổi lớn ở ba khía cạnh: 1) hỗ trợ cấu trúc liên kết dạng lưới để giải quyết vấn đề về các kênh hạn chế; 2) hợp nhất bộ nhớ, cho phép GPU chia sẻ nhóm bộ nhớ chung, giảm nhu cầu để sao chép dữ liệu giữa các GPU, do đó Cải thiện hiệu quả; 3) Truy cập bộ nhớ trực tiếp không yêu cầu CPU tham gia. Các GPU có thể đọc trực tiếp bộ nhớ của nhau, do đó giảm độ trễ mạng. Ngoài ra, để giải quyết vấn đề giao tiếp không đồng đều giữa các GPU, NVIDIA cũng giới thiệu NVSwitch, một chip vật lý tương tự như switch ASIC, giúp kết nối nhiều GPU với tốc độ cao thông qua giao diện NVLink để tạo ra GPU đa nút băng thông cao. cụm.
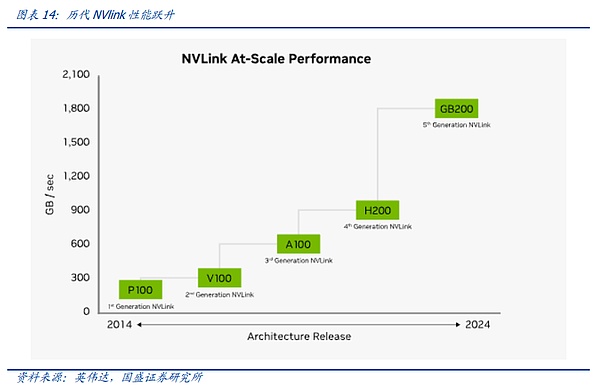
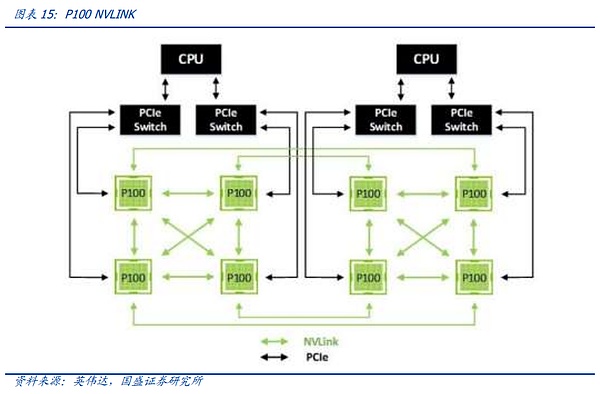
Bằng cách xem lại lịch sử phát triển của NV-link, chúng ta có thể thấy rằng kết nối NV-Link giữa các nút đang dần lặp lại với những thay đổi về yêu cầu đồng bộ hóa giữa các card đồ họa. Thế hệ NV-Link đầu tiên xuất hiện trên kiến trúc Pascal. NVIDIA liên kết các máy chủ 8 card trong một máy chủ duy nhất thông qua dây đồng tốc độ cao trên bo mạch PCB và PCIE Switch phổ quát. Chúng ta có thể tìm hiểu qua phương thức kết nối trong hình. bên dưới, bằng cách đặt vòng lớn bên ngoài của card đồ họa lên kết nối hình chữ X bên trong của bốn card đồ họa, việc căn chỉnh dữ liệu toàn cầu có thể được hoàn thành bằng cách sử dụng đường dẫn ngắn nhất giữa 8 GPU, bắt đầu từ bất kỳ GPU nào.
Tuy nhiên, với việc mở rộng hiệu suất của một card đồ họa, việc cải thiện thông lượng và các phương thức đồng bộ hóa ngày càng phức tạp giữa các card đồ họa, kết nối cáp thuần túy và đường dây cố định không còn có thể đáp ứng nhu cầu liên lạc giữa các card đồ họa. Do đó, trong kiến trúc Ampere, tương ứng là NVLINK thế hệ thứ ba, NVIDIA đã giới thiệu chip chuyển mạch NV-Link chuyên dụng thế hệ đầu tiên để tăng thêm tốc độ và tính linh hoạt của NV-Link.

Tuy nhiên, trong bản cập nhật từ kiến trúc Pascal lên kiến trúc Ampere, do nhu cầu của khách hàng lúc đó vẫn tập trung vào các mô hình nhỏ và các cụm tính toán quy mô lớn chưa xuất hiện nên NV-LINK duy trì nhịp độ cập nhật thường xuyên, chủ yếu thông qua nội bộ kênh lặp của chip, lặp lại chip NV-Link Switch để đạt được tốc độ cập nhật, trong đó NVIDIA cũng ra mắt cầu nối NV-Link dành cho card đồ họa chơi game nhằm đáp ứng nhu cầu của một số người dùng C-end cao cấp.

Trong bản cập nhật từ A100 lên H100, NVIDIA đã thực hiện bước đầu tiên trong quá trình phát triển NV-Link. Khi nhu cầu về các model lớn bắt đầu xuất hiện, quy mô dữ liệu và khối lượng model lớn đã khiến NV-Link trước đây bị hạn chế đến 8 card đồ họa. Việc kết nối liên kết rất khó khăn. Người dùng phải chia mô hình thành các máy chủ khác nhau để đào tạo và căn chỉnh. Tốc độ liên lạc chậm giữa các máy chủ ảnh hưởng trực tiếp đến hiệu quả của việc đào tạo mô hình. Chúng tôi gọi số lượng card đồ họa có thể kết nối với nhau bằng giao thức truyền thông tốc độ cao nhất là HB-DOMIN. Trong quá trình tăng các thông số mô hình, HB-DOMIN đã trở thành nhân tố then chốt quyết định khả năng huấn luyện mô hình trong cùng một thế hệ chip.
Trong bối cảnh này, NV-LINK của NVIDIA đã thực hiện bước đầu tiên trong quá trình phát triển kiến trúc Hopper, mang nhiều dữ liệu hơn thông qua một bộ chuyển mạch chuyên dụng bên ngoài. chuyển đổi chip, từ đó mở rộng HB-DOMIN của các card đồ họa hiện có. Trong kỷ nguyên Hopper100, thông qua sản phẩm GH200 SuperPOD, NV-LINK lần đầu tiên rời khỏi máy chủ và nhận ra khả năng kết nối của 256 card đồ họa trên toàn máy chủ.

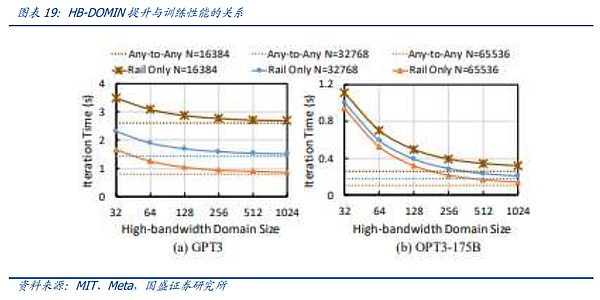
Tuy nhiên, do độ trưởng thành thấp của chip chuyển mạch NV-Link 3.0 tương ứng theo kiến trúc Hopper nên NVIDIA yêu cầu kiến trúc hai lớp để kết nối card đồ họa. Vì vậy, một cụm card GH200 256 yêu cầu số lượng lớn - mô-đun quang học cuối cùng cực kỳ tốn kém và cung cấp cho khách hàng dịch vụ Mua sắm đã gây ra sự bất tiện. Đồng thời, khi GH200 được ra mắt, các thông số của mô hình vẫn chưa mở rộng đến mức nghìn tỷ Theo kết quả nghiên cứu của Meta, dưới các thông số nghìn tỷ, tác động biên của việc mở rộng HB-Domin sau khi vượt quá 100 sẽ tăng tốc và giảm dần.
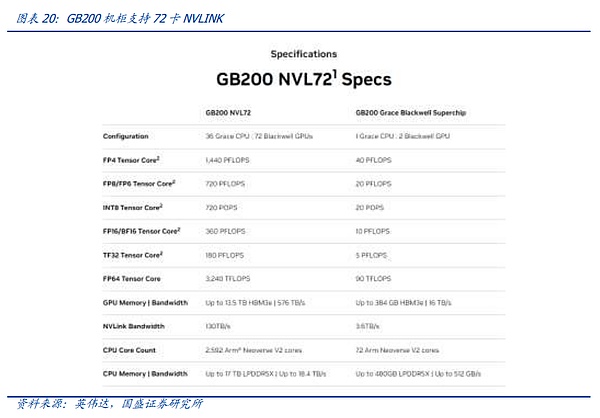
Trong kỷ nguyên kiến trúc Blackwell, NVIDIA đã chính thức hoàn thiện việc mở rộng NVLINK. Với việc ra mắt chip chuyển mạch NV-Link 4NM thế hệ mới nhất, NVIDIA đã ra mắt sản phẩm chủ lực chính thức GB200 NVL72. NVIDIA đã đạt được mục tiêu đạt được số HB-DOMIN hiệu quả về mặt chi phí với chi phí thấp hơn thông qua kết nối một lớp cáp đồng NVlink+ trong một tủ duy nhất, thực sự thực hiện bước đầu tiên trong việc mở rộng giao thức kết nối nội bộ nút lên cấp cao hơn lớp.
Bên cạnh thế hệ NV-LINK mới nhất, chúng tôi một lần nữa hiểu lại tầm quan trọng của các giao thức kết nối nội bộ nút. Thậm chí có thể nói rằngviệc mở rộng giao tiếp nội bộ nút đã trở thành một câu hỏi về việc liệu Định luật Moore có thể tăng sức mạnh tính toán hay không. Chìa khóa cho sự tiếp nối của thời đại. Việc lặp lại và triển khai các giao thức truyền thông nội bộ nút với chi phí thấp hiện là giải pháp tốt nhất để giải quyết các "bức tường giao tiếp" và "bức tường bộ nhớ".
Đối thủ lớn nhất hiện nay của NV-LINK đến từ AMD, đối thủ lớn nhất của NVIDIA trong lĩnh vực card đồ họa thông thường. Nó cũng giống như NVIDIA. , ngay cả đối với AMD, công ty hỗ trợ nhiều nhất cho tính mở giao thức mạng, vẫn sử dụng giao thức chuyên dụng "Infinity Fabric" trong lĩnh vực kết nối trong các nút của mình. Tuy nhiên, không giống như NVIDIA, AMD chia sẻ giao thức này với ba công ty Ethernet hợp tác với. nó: vòi Broadcom, Arista và Cisco.

Nhìn vào tình hình hiện tại, khoảng cách giữa Infinity Fabric và NVLINK vẫn còn lớn. Về chip chuyển mạch đặc biệt, kết nối nhiều thẻ và hoàn thiện giao thức, AMD vẫn còn một chặng đường dài để bắt kịp. Điều này cũng phản ánh rằng Hiện tại, sự cạnh tranh về sức mạnh tính toán chung trong đầu đã dần mở rộng từ liên kết duy nhất của thiết kế chip sang liên kết giao tiếp nội bộ nút.
Tóm lại, giao tiếp giữa các nút đang ngày càng trở thành một phần quan trọng của sức mạnh tính toán. Đồng thời, với sự mở rộng của HB-DOMIN, "sức mạnh tính toán". các nút " cũng đang dần mở rộng. Chúng tôi tin rằng đằng sau điều này là sự "thâm nhập đi lên" của các giao thức giữa các nút trong toàn bộ cụm AI. Đồng thời, dựa vào việc nén có hệ thống các giao thức giữa các nút và phần cứng mang theo của chúng cũng sức mạnh tính toán AI trong tương lai để đạt được giải pháp Định luật Moore.
3.2 Giao thức truyền thông giữa các nút: vượt thời gian, cuộc tranh luận giữa đóng và mở
Bây giờ chúng ta chuyển quan điểm của mình ra ngoài nút sức mạnh điện toán và xem xét các giao thức chính hiện đang cấu thành kết nối cụm sức mạnh điện toán toàn cầu. Trung tâm sức mạnh tính toán hiện tại, NPU, đang dần tiến tới quy mô hàng triệu cấp. Ngay cả khi các nút sức mạnh tính toán hay cái mà chúng tôi gọi là HB-DOMIN đang tăng tốc mở rộng, thì kết nối giữa các nút vẫn là nền tảng của sức mạnh tính toán AI toàn cầu.
Theo quan điểm hiện tại, các giao thức kết nối giữa các nút chủ yếu được chia thành giao thức InfiniBand và họ giao thức ROCE trong họ Ethernet. Cốt lõi của kết nối giữa các nút siêu máy tính nằm ở chức năng RDMA. Trước đây, trong các trung tâm dữ liệu dựa trên CPU truyền thống, giao thức TCP/IP thường được sử dụng để truyền. Nghĩa là, sau khi dữ liệu được gửi từ bộ nhớ đầu gửi, nó sẽ được mã hóa bởi CPU của thiết bị đầu cuối gửi và sau đó được gửi đến. CPU của thiết bị đầu nhận sau khi giải mã, vào bộ nhớ. Trong quá trình này, do dữ liệu đi qua nhiều thiết bị và được mã hóa và giải mã nhiều lần nên độ trễ cao sẽ xảy ra. Độ trễ cao là yếu tố quan trọng nhất để đồng bộ hóa lẫn nhau giữa các card máy tính. CPU và thực hiện truy cập bộ nhớ trực tiếp từ xa (Truy cập bộ nhớ trực tiếp từ xa) giữa các bộ nhớ, RDMA đã trở nên cần thiết cho các kết nối cụm AI.
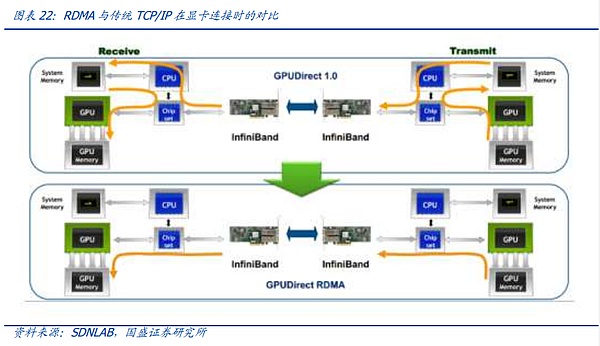
Trong bối cảnh này, họ giao thức ROCE hỗ trợ chức năng này theo giao thức IB Ethernet, hiện do NVIDIA dẫn đầu và hỗ trợ RDMA nguyên gốc, đã trở thành lựa chọn duy nhất vào lúc này và các đặc điểm khác biệt của hai giao thức này có khiến toàn bộ Cuộc cạnh tranh về giao thức giữa các nút trở nên sôi động.
Sự xuất hiện của giao thức IB có thể bắt nguồn từ năm 1999. Vào thời điểm đó, bus PCI với khả năng giao tiếp kém dần trở thành nút cổ chai trong giao tiếp giữa các thiết bị khác nhau Trong bối cảnh này Tiếp theo, Intel, Microsoft, IBM, Diễn đàn nhà phát triển FIO và Diễn đàn NGIO do một số gã khổng lồ thành lập đã sáp nhập để tạo ra Hiệp hội Thương mại InfiniBand (IBTA) và ra mắt phiên bản đầu tiên của khung giao thức IB vào năm 2000. Melanox, một công ty chip chuyển mạch được thành lập vào năm 1999, cũng đã tham gia trại IB.
IB là người đầu tiên đề xuất khái niệm RDMA kể từ khi thành lập, cho phép nó vượt qua những hạn chế của bus PCI và thực hiện tốc độ cao hơn access., nhưng thời gian tốt đẹp không kéo dài được lâu. Vào năm 2022, những gã khổng lồ như Intel và Microsoft liên tiếp tuyên bố rút khỏi liên minh IB và chuyển sang nghiên cứu và phát triển giao thức PCIE mà chúng tôi đã đề cập ở trên. . Nhưng đến năm 2005, khi nhu cầu liên lạc giữa các thiết bị lưu trữ tăng lên, IB lại mở ra một thời kỳ tăng trưởng sau đó, với việc xây dựng các siêu máy tính toàn cầu, ngày càng nhiều siêu máy tính bắt đầu sử dụng IB để kết nối. Trong quá trình này,Dựa vào sự kiên trì của mình trong IB và các thương vụ mua lại liên quan, Mellanox đã mở rộng từ một công ty chip sang toàn bộ lĩnh vực card mạng, bộ chuyển mạch/cổng, hệ thống liên lạc từ xa, cáp và mô-đun, trở thành nhà cung cấp mạng đẳng cấp thế giới Năm 2019, Nvidia mua lại thành công Mellanox, đánh bại Intel và Microsoft với lời đề nghị trị giá 6,9 tỷ USD.

Mặt khác, Ethernet đã phát hành giao thức RoCE vào năm 2010 để triển khai RDMA dựa trên giao thức Ethernet. Đồng thời, RoCE v2 hoàn thiện hơn đã được đề xuất vào năm 2014.
Kể từ khi bước vào kỷ nguyên mô hình lớn, các trung tâm dữ liệu toàn cầu đã nhanh chóng chuyển sang điện toán thông minh, vì vậy các thiết bị đầu tư mới quan trọng cần có kết nối RDMA. hỗ trợ phương pháp. Tuy nhiên, bối cảnh cạnh tranh hiện tại đã thay đổi so với cuộc cạnh tranh trước đây giữa RoCE V2 và IB. Do sự dẫn đầu tuyệt đối của NVIDIA trong lĩnh vực card đồ họa toàn cầu, card đồ họa NVIDIA có khả năng thích ứng tốt hơn với IB. Điểm rõ ràng nhất được thể hiện ở các thiết bị chuyển mạch Mellanox. trong giao thức Sharp.
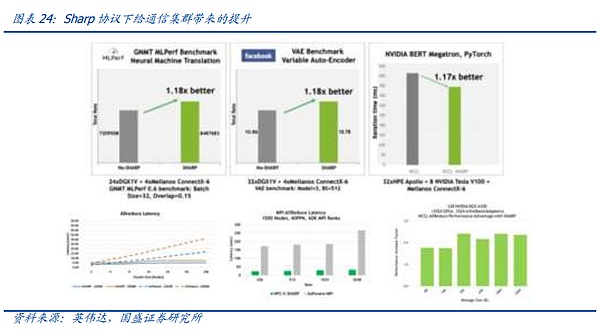
Do số lượng lớn phức tạp. Giảm yêu cầu giao tiếp giữa các card đồ họa trong hoạt động AI, như đã đề cập ở trên, đây cũng là vấn đề cốt lõi cần được giải quyết trong kỹ thuật hệ thống truyền thông AI. Ở Mellanox Trong sản phẩm, với sự trợ giúp của NVIDIA, công ty đã tích hợp một cách sáng tạo một đơn vị động cơ điện toán vào chip chuyển mạch, có thể hỗ trợ các phép tính Giảm liên quan, từ đó giúp GPU giảm tải, nhưng các chức năng liên quan cần có sự hợp tác của các nhà sản xuất GPU.
Có thể thấy rằng cốt lõi đằng sau cuộc chiến về giao thức truyền thông trong kỷ nguyên AI đã trở thành cuộc chiến giành quyền Quyền lên tiếng giữa các nhà sản xuất card đồ họa Hiện tại, giao thức IB có lợi thế cạnh tranh tốt hơn với sự hỗ trợ của NVIDIA, trong khi các nhà sản xuất Ethernet truyền thống lại yếu hơn một chút ở một số chức năng do không có chip hỗ trợ mạnh. Tuy nhiên, sự xuất hiện của Super Ethernet Alliance dưới sự lãnh đạo của AMD được kỳ vọng sẽ dần đảo ngược tình trạng này.

Vào ngày 19 tháng 7 năm 2023, AMD, Broadcom, Cisco, ARISTA, Meta, Microsoft và các nhà sản xuất hàng đầu khác về chip điện toán, phía mạng và phía người dùng đã cùng nhau thành lập Liên minh Ultra Ethernet. Chúng tôi tin rằng, < strong>Mục đích của việc thành lập Liên minh Super Ethernet là xây dựng một giao thức mạng dựa trên Ethernet hoàn toàn mở, linh hoạt hơn và có hiệu suất vượt trội để cạnh tranh với IB.

AMD là thành viên cốt lõi của Liên minh Ultra Ethernet. Tại hội nghị ra mắt dòng Mi300, công ty đã tuyên bố rằng kết nối back-end của card đồ họa của họ sẽ sử dụng Ethernet một cách vô điều kiện, cũng như giao thức Infinity Fabric được sử dụng để kết nối nội bộ nút. Sẽ được mở cho các nhà cung cấp Ethernet. Chúng tôi đánh giá rằng khi sự hợp tác giữa AMD và các thành viên như Broadcom trong liên minh UEC dần được tăng tốc, liên minh UEC cũng được kỳ vọng sẽ thực sự hình thành một hệ thống tương thích và hợp tác tương tự như N card + IB, do đó đặt ra thách thức cho Nvidia. Nhưng quá trình này dự kiến sẽ còn dài. Từ việc AMD theo đuổi sức mạnh tính toán thẻ đơn, đến sự tiến bộ của chip chuyển mạch của Broadcom, đến sự cởi mở và hợp tác giữa các nhà sản xuất khác nhau, vẫn còn một chặng đường dài phía trước.
Tóm lại, tranh chấp về giao thức liên lạc giữa các nút đã dần phát triển từ tranh chấp về nguyên tắc thành cuộc chiến về quyền phát biểu . Giao thức nào được sử dụng sẽ là phần mở rộng tiếng nói của GPU. NVIDIA hy vọng sẽ mở rộng tiếng nói của mình về mọi mặt thông qua IB và khách hàng hy vọng đón nhận một cuộc cạnh tranh IB cởi mở hơn trong ngành sẽ tiếp tục thúc đẩy sự phát triển không ngừng của truyền thông. giao thức.
4. Được thúc đẩy bởi AI, sự đổi mới phần cứng mạng sẽ đi về đâu?
Trong phần trước, chúng tôi đã thảo luận về cách các yêu cầu AI thúc đẩy sự phát triển và số lượng chức năng RDMA. Tương tự, trong lĩnh vực phần cứng mạng. , AI Các nhu cầu mới cũng đang kéo theo những thay đổi khác ngoài cập nhật tốc độ, bao gồm những thay đổi về phương tiện truyền dẫn, bộ chuyển mạch, kiến trúc mạng và thậm chí cả hình dạng tổng thể của trung tâm dữ liệu.
4.1 Ánh sáng, đồng và silicon, cuộc chiến về phương tiện truyền thông sẽ đi về đâu?
Trong những năm gần đây, với sự mở rộng nhanh chóng của khối lượng dữ liệu con người và tốc độ truyền tải tăng gấp đôi, chúng ta đã dẫn đầu làn sóng tiến bộ quang học và rút tiền đồng về phía viễn thông như mạng không dây và cố định Từ việc truy cập Internet dial-up sớm nhất, sau đó đến cáp quang tại nhà và thậm chí bây giờ là FTTR, cáp quang đã chính thức thay thế dần dây đồng.
Bên trong trung tâm dữ liệu, quá trình ánh sáng đi vào và thoát ra bằng đồng cũng đang diễn ra. Các hệ thống truyền thông bao gồm các mô-đun quang học, AOC và các truyền thông quang học khác đang dần thay thế hiện có. Đằng sau hệ thống truyền dẫn đồng bao gồm DAC, AEC, v.v., là quy luật vật lý tất yếu rằng khi truyền tốc độ cao, sự suy giảm môi trường đồng ngày càng nghiêm trọng. Nếu không có nhu cầu đa dạng do AI mang lại, khi tốc độ cổng mạng máy chủ tăng dần từ thế hệ này sang thế hệ khác, đường truyền quang sẽ dần dần thâm nhập vào bên trong các tủ và cuối cùng hình thành một trung tâm dữ liệu toàn quang.
Tuy nhiên, sự xuất hiện của AI đã mang lại một số khúc mắc cho quá trình "tiến nhẹ và lùi đồng", hoặc gây ra sự nhầm lẫn nhất định trên thị trường . Lý do cốt lõi đằng sau điều này là: AI đã mang lại sự tăng trưởng tuyến tính không liên thế hệ về độ phức tạp và chi phí của các hệ thống truyền thông. Trước nhu cầu tăng theo cấp số nhân, các mô-đun quang tốc độ cao ngày càng trở nên đắt đỏ. Do đó, sức hấp dẫn của cáp đồng tiết kiệm chi phí hơn ở tốc độ hiện tại đang dần tăng lên. Đồng thời, cùng với những cải tiến trong các thành phần hỗ trợ như tản nhiệt, các nhà sản xuất card đồ họa có thể nén càng nhiều đơn vị máy tính càng tốt trong tầm tay. của một tủ duy nhất trong tầm với của cáp đồng.

Nhìn từ phía sau, không khó để nhận ra rằng trong thời đại AI, do chi tiêu tăng lên, trong nút 2-3 năm hiện tại, cốt lõi của cuộc chiến quang-đồng đã thay đổi từ nâng cấp tốc độ sang Đồng thời, do sự phức tạp của hệ thống truyền thông. Tăng trưởng nhanh, tính đơn giản và tỷ lệ thất bại thấp cũng trở thành những cân nhắc quan trọng đối với khách hàng khi lựa chọn phương tiện truyền thông.
Truyền từ xa qua máy chủ: mô-đun quang là giải pháp duy nhất, đồng thời việc giảm và đơn giản hóa chi phí là hướng đổi mới.
Do hạn chế về khoảng cách truyền của cáp đồng, cái gọi là "rút quang và chuyển tiếp đồng" chỉ có thể xảy ra trong truyền dẫn khoảng cách ngắn và để truyền trên 5 mét Đối với khoảng cách, tức là khi truyền qua các máy chủ hoặc qua các nút nguồn điện toán, truyền dẫn quang vẫn là lựa chọn duy nhất. Nhưng hiện nay, ngoài mối lo ngại về việc nâng cấp tốc độ thông thường, khách hàng ngày càng theo đuổi chi phí và tỷ lệ hỏng hóc (độ phức tạp của thiết bị), điều này cũng đang thúc đẩy hướng nâng cấp trong tương lai của ngành truyền thông quang học.
LPO/LRO: LPO thay thế DSP truyền thống bằng công nghệ truyền động trực tiếp tuyến tính và tích hợp các chức năng của nó vào chip chuyển mạch, chỉ để lại trình điều khiển và chip TIA. Hiệu suất của TIA và chip điều khiển được sử dụng trong mô-đun quang LPO cũng đã được cải thiện để đạt được độ tuyến tính tốt hơn. LRO là giải pháp chuyển tiếp sử dụng mô-đun quang truyền thống ở một đầu và mô-đun quang LPO ở đầu kia, giúp khách hàng dễ chấp nhận hơn.
Silicon Photonics: Silicon Photonics sử dụng công nghệ hoàn thiện để cho phép các thiết bị rời rạc trong động cơ quang học của một số mô-đun quang học được tích hợp tự động trên các chip dựa trên silicon, từ đó cho phép Giảm chi phí đáng kể, trong khi cập nhật quy trình và sản xuất tự động cũng có thể giúp các chip quang tử silicon lặp lại.Chúng tôi tin rằng LPO và quang tử silicon là hai giải pháp đổi mới giảm chi phí nhanh nhất trong ngành.
Lithi niobate màng mỏng: Vật liệu lithium niobate là sự lựa chọn tốt nhất cho hệ số quang điện trong số các vật liệu đáng tin cậy (xem xét điểm Curie và hệ số quang điện ). Quá trình màng mỏng rút ngắn khoảng cách điện cực, giảm điện áp và tăng tỷ lệ băng thông trên điện áp. So với các vật liệu khác, nó có nhiều ưu điểm cần thiết nhất cho quang điện tử, chẳng hạn như băng thông lớn, tổn thất thấp và điện áp truyền động thấp. Hiện tại, lithium niobate màng mỏng chủ yếu được sử dụng trong các bộ điều biến ánh sáng silicon tốc độ cao.Chúng tôi tin rằng việc sử dụng bộ điều biến lithium niobate màng mỏng có thể đạt được hiệu suất tốt hơn ở mức 1,6T và 3,2T.
CPO: CPO đề cập đến việc đóng gói mô-đun quang trực tiếp trên bo mạch chủ switch, để nó có thể chia sẻ khả năng tản nhiệt của bo mạch chủ switch và rút ngắn thời gian việc truyền tín hiệu điện trên bo mạch chủ công tắc. Khoảng cách truyền dẫn, nhưng hiện tại, do các mô-đun quang học trong trung tâm AI là những vật dụng dễ vỡ nên khó bảo trì sau khi đóng gói chung nên mức độ nhận biết của khách hàng đối với CPO vẫn ở mức thấp. được nhìn thấy.
Kết nối trong tủ: Với ưu điểm kép về chi phí và tính ổn định, dây đồng là sự lựa chọn có lợi trong ngắn hạn và trung hạn vì lãi suất dài hạn. tăng lên thì sự tiến lên của ánh sáng và sự rút lui của đồng vẫn sẽ xảy ra.
DAC: Cáp gắn trực tiếp, là cáp đồng tốc độ cao, có thể thích ứng với các kết nối tốc độ cực cao trong khoảng cách ngắn 800G phổ thông hiện nay. Chiều dài DAC trên thị trường là trong vòng 3 mét, là giải pháp kết nối trong tủ có hiệu quả cao về mặt chi phí.
AOC: Cáp quang chủ động, cáp quang chủ động, là một hệ thống bao gồm các mô-đun quang và sợi quang đã được tích hợp và đóng gói trước ở cả hai đầu. khoảng cách truyền tương tự. So với các mô-đun quang đa chế độ hoặc đơn chế độ truyền thống, chúng ngắn hơn nhưng giá thành cũng thấp hơn. Chúng là lựa chọn tốt nhất cho các kết nối khoảng cách ngắn trong các tủ vượt quá giới hạn truyền của cáp đồng.
Liên quan đến sự phát triển của silicon, các ý tưởng chủ đạo hiện nay chủ yếu bao gồm chia tỷ lệ chiplet và wafer. Ý tưởng cốt lõi của hai phương pháp này là sử dụng và sản xuất Chất bán dẫn tiên tiến hơn. quá trình thiết kế, từ đó mở rộng số lượng đơn vị tính toán mà một con chip có thể mang theo và cho phép phát triển nhiều thông tin liên lạc hơn trong một con chip silicon duy nhất càng nhiều càng tốt để tối đa hóa hiệu quả tính toán. Phần nội dung này mà chúng ta đã thảo luận sâu trước đây. "Điện toán AI" Phần giới thiệu chi tiết được đưa ra trong "Con đường ASIC mạnh mẽ - Bắt đầu từ máy khai thác Ethereum" và sẽ không lặp lại trong bài viết này.
Tổng hợp lại, những thay đổi và cạnh tranh trong phương tiện truyền tải đi theo nhu cầu và nhu cầu hiện tại là rất rõ ràng Theo các khuôn khổ đào tạo mới như MOE, mô hình. các tham số đang hướng tới quy mô hàng nghìn tỷ đồng, làm thế nào để đạt được sức mạnh tính toán nút đơn mạnh hơn một cách hiệu quả về mặt chi phí hoặc mở rộng số lượng miền "HB-DOMIN" để việc phân đoạn mô hình không cần phải quá chi tiết, dẫn đến đến việc giảm hiệu quả tập luyện. Hạ thấp, dù là lớp nhẹ, đồng hay lớp silicon thấp nhất, chúng tôi vẫn không ngừng nỗ lực trên lộ trình này.
4.2 Đổi mới về công tắc: Công tắc quang còn ở giai đoạn sơ khai
Bộ chuyển mạch là lõi của mạng
Là nút lõi của mạng, bộ chuyển mạch là thành phần cốt lõi mang giao thức truyền thông. Trong cụm AI ngày nay, switch còn đảm nhận trách nhiệm Thực hiện các tác vụ ngày càng phức tạp, ví dụ như Mellanox switch nói trên có chức năng căn chỉnh từng phần hoạt động thông qua giao thức SHARP giúp tăng tốc hoạt động AI.
Nhưng mặt khác, mặc dù các công tắc điện ngày nay ngày càng mạnh mẽ hơn và tốc độ cập nhật lặp lại vẫn ổn định, nhưng chuyển mạch quang học thuần túy dường như đang trở thành một xu hướng mới . Điều tra nguyên nhân, chúng tôi tin rằng có hai nguyên nhân chính đằng sau xu hướng chuyển mạch quang học. Thứ nhất, sự khổng lồ hóa của những người tham gia AI. Thứ hai, sự mở rộng nhanh chóng của các cụm AI.
So với hệ thống chuyển mạch điện, hệ thống chuyển mạch quang loại bỏ chip điện và sử dụng thấu kính quang học để khúc xạ và phân phối tín hiệu quang đi vào công tắc. Điều này cho phép. nó đi vào mô-đun quang tương ứng mà không cần chuyển đổi. So với các công tắc điện, công tắc quang bỏ qua quá trình chuyển đổi quang điện nên mức tiêu thụ điện năng, độ trễ, v.v. sẽ thấp hơn, đồng thời do không bị giới hạn trên về công suất của chip công tắc điện nên rất lý tưởng. để tối ưu hóa lớp mạng và chuyển mạch đơn vị. Tuy nhiên, ngược lại, việc sử dụng các bộ chuyển mạch quang đòi hỏi một kiến trúc mạng được thiết kế đặc biệt để thích ứng. một khi một cụm công tắc quang được thiết lập thì không thể mở rộng từng phần. Nó chỉ có thể mở rộng toàn bộ cụm mạng cùng một lúc. Ngoài ra, ở giai đoạn hiện tại, các công tắc quang không có phiên bản phổ thông. yêu cầu tự nghiên cứu hoặc thiết kế tùy chỉnh và ngưỡng cao.
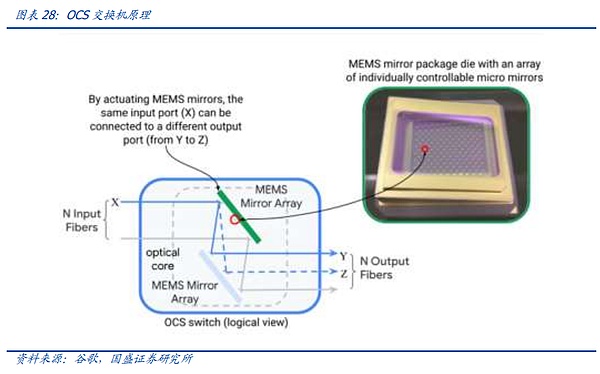
Tuy nhiên, khi cuộc cạnh tranh AI chính thức bước vào nửa sau của cuộc chiến giữa những gã khổng lồ, quy mô cụm AI thuộc sở hữu của những gã khổng lồ đang nhanh chóng mở rộng. Những gã khổng lồ có kế hoạch đầu tư chín chắn, khả năng tự nghiên cứu về kiến trúc mạng và Do đó, trong nút Ngày nay, khi quy mô tiếp tục mở rộng, các khách hàng khổng lồ như Google đang đẩy nhanh việc phát triển và triển khai hệ thống OCS.
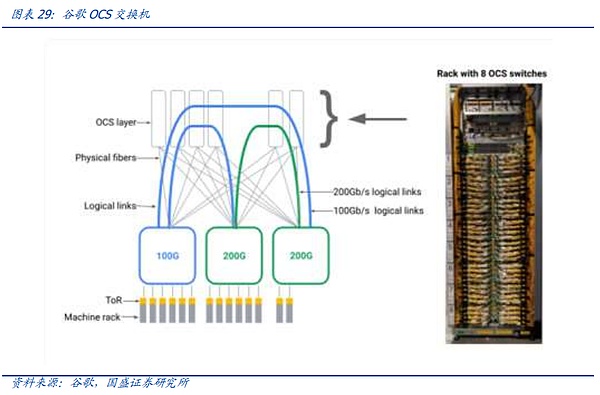
Quay trở lại phần chuyển mạch điện truyền thống, sự đổi mới của các công tắc điện ngày nay, ngoài phần giao thức trên, tập trung nhiều hơn vào phần chip, bao gồm các bước lặp quy trình, đổi mới chức năng, v.v. Đồng thời, chẳng hạn như Các nhà sản xuất Broadcom Switch, chẳng hạn như những nhà sản xuất khác, dựa vào việc sử dụng IP của chính họ trong các chip khách hàng hạ nguồn khác nhau để tạo mối liên kết chặt chẽ hơn với khách hàng. Kết hợp với nhóm giao thức truyền thông, trong kỷ nguyên AI, ngành công nghiệp chuyển mạch đã chính thức trở thành một ngành công nghiệp. liên minh chip. Một cuộc cạnh tranh toàn diện giữa họ.
4.3 Đổi mới trong kiến trúc mạng: Đi đâu sau Ye Spine?
Kiến trúc mạng là một phần quan trọng của hệ thống truyền thông ngoài các giao thức và phần cứng. Kiến trúc xác định đường dẫn mà dữ liệu trong máy chủ được truyền đi. ., đồng thời, kiến trúc mạng tuyệt vời có thể giúp lưu lượng dữ liệu có thể truy cập được trong toàn khu vực, giảm độ trễ và đảm bảo tính ổn định. Đồng thời, kiến trúc mạng cũng cần đáp ứng yêu cầu dễ dàng bảo trì và mở rộng. Do đó, kiến trúc là một phần quan trọng của hệ thống truyền thông từ thiết kế trên giấy đến kỹ thuật vật lý.
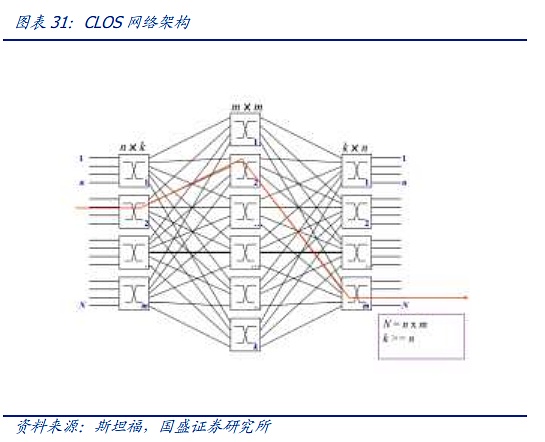
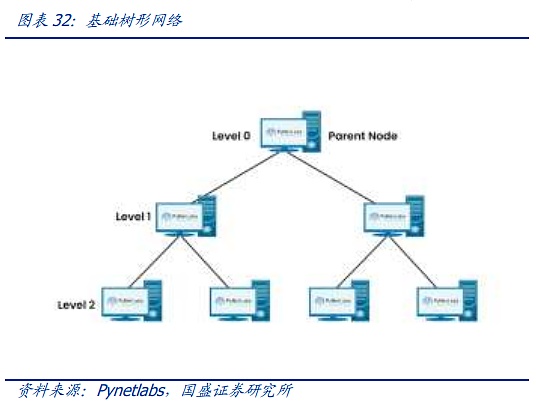
Kiến trúc mạng của xã hội hiện đại, từ cấu trúc đồ thị ma trận của thời đại điện thoại đến mô hình mạng ClOS, đặt nền tảng cho các mạng hiện đại. Kiến trúc CLOS là sử dụng Nhiều đơn vị quy mô nhỏ, chi phí thấp xây dựng các mạng quy mô lớn, phức tạp. Trên cơ sở mô hình CLOS, các cấu trúc liên kết mạng khác nhau đã dần được phát triển, chẳng hạn như các kiến trúc hình sao, chuỗi, vòng, cây và các kiến trúc khác. Sau đó, mạng cây đã dần trở thành kiến trúc chủ đạo.

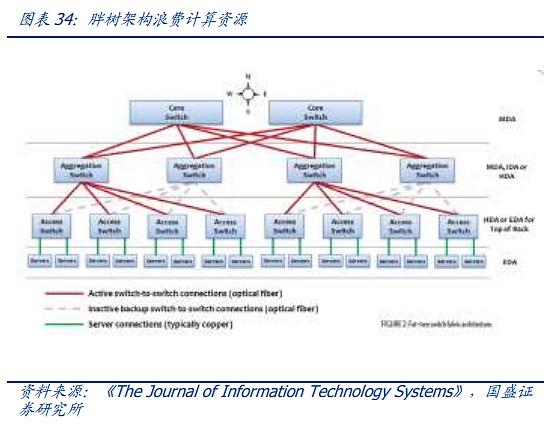
Kiến trúc cây chủ yếu phát triển qua ba thế hệ. Thế hệ đầu tiên là kiến trúc cây truyền thống nhất. Đặc điểm của kiến trúc cây này là sau mỗi lớp, băng thông hội tụ đúng 2:1, nghĩa là sau khi hai thiết bị hạ lưu 100M được kết nối với bộ chuyển mạch, đầu ra cố định là luồng dữ liệu 100M. , trước sự xuất hiện của các luồng dữ liệu nhỏ hơn trước khi điện toán đám mây xuất hiện, kiến trúc này vẫn có thể đáp ứng được. Tuy nhiên, với sự ra đời của Internet và kỷ nguyên điện toán đám mây, băng thông hội tụ dần không thể đáp ứng được nhu cầu truyền tải lưu lượng. phương pháp gọi là "cây mỡ" "Kiến trúc cải tiến dần được áp dụng cho các trung tâm dữ liệu. Kiến trúc cây béo sử dụng các thiết bị chuyển mạch ba lớp. Khái niệm cốt lõi của nó là sử dụng một số lượng lớn các thiết bị chuyển mạch hiệu suất thấp để xây dựng một mạng không chặn quy mô lớn. Đối với bất kỳ chế độ liên lạc nào, luôn có một đường dẫn để cho phép băng thông liên lạc của chúng đạt tới băng thông card mạng, nhưng hãy sử dụng các switch nâng cao hơn ở lớp trên để giữ mức chuyển mạch cấp cao nhất ở mức thấp nhất có thể.
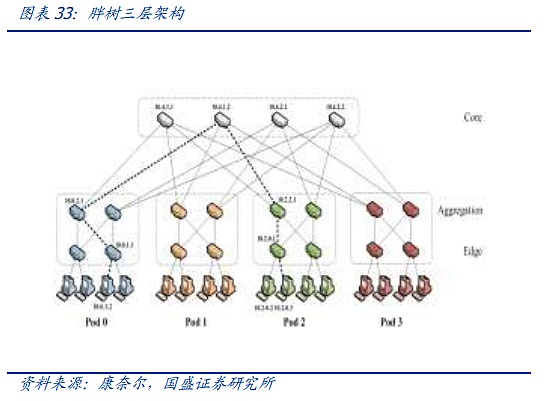
Kiến trúc "cây béo" cho kết nối trung tâm dữ liệu hiện đại Nó đã đặt nền móng nhưng nó cũng tồn tại những vấn đề như lãng phí băng thông, khó mở rộng, khó hỗ trợ điện toán đám mây quy mô lớn, v.v. Trước quy mô mạng ngày càng lớn, những khuyết điểm của cây mỡ truyền thống ngày càng lộ rõ .
Vì vậy, dựa trên cây béo, đã phát triển The Spine- Kiến trúc lá hiện đang được sử dụng trong các trung tâm dữ liệu và cụm AI tiên tiến nhấn mạnh đến tính phẳng so với cây béo. So với cây mỡ ba lớp phức tạp, mỗi switch (lá) cấp thấp được kết nối với từng switch (cột sống) cấp cao để tạo thành. một cấu trúc liên kết toàn lưới. Lớp lá bao gồm các switch truy cập và được sử dụng để kết nối các máy chủ và các thiết bị khác. Lớp gai là xương sống của mạng và chịu trách nhiệm kết nối tất cả các lá. Trong cấu hình này, số lượng nút để chuyển tiếp dữ liệu giữa hai máy chủ vật lý bất kỳ là cố định: một công tắc lá và một công tắc cột sống, đảm bảo khả năng chịu lực và độ trễ của lưu lượng truy cập đông-tây, đồng thời tránh việc mở rộng công tắc cột sống. việc sử dụng một số lượng lớn các thiết bị chuyển mạch lớp lõi cực kỳ đắt tiền. Đồng thời, toàn bộ mạng có thể được mở rộng bằng cách tăng số lượng thiết bị chuyển mạch cột sống bất kỳ lúc nào.
Nhìn vào tình hình hiện tại, Ye Spine đã trở thành kiến trúc tiêu chuẩn cho các cụm AI chính thống và trung tâm dữ liệu chính với nhiều ưu điểm. Tuy nhiên, giống như cấu trúc bên trong của nó. một cụm AI duy nhất Số lượng nút đã mở rộng nhanh chóng, đồng thời, do quá trình đào tạo AI quá chú trọng đến độ trễ, một số vấn đề về kiến trúc cây mỡ cũng bắt đầu trở nên nổi bật. Thứ nhất, khi quy mô mở rộng nhanh chóng, liệu việc cập nhật công suất cao hơn của switch có đáp ứng được tốc độ phát triển của các cụm card đồ họa hay không? Thứ hai, liệu Ye Spine có còn hiệu quả về mặt chi phí khi phải đối mặt với sự kết nối của hàng triệu nút máy tính?
Hai vấn đề trên của kiến trúc leaf-spine cũng dẫn đến sự đổi mới ở cấp độ kiến trúc mạng. Chúng tôi tin rằng sự đổi mới chủ yếu tập trung. trong hai vấn đề này Có hai hướng. Thứ nhất, theo đuổi các kiến trúc mới với số lượng nút cực lớn. Thứ hai, thông qua các phương pháp như mở rộng tối ưu hóa phần mềm lớp phủ HB-DOMIN, dựa trên sự hiểu biết đầy đủ về mô hình, giảm lưu lượng giao tiếp giữa các nút. .
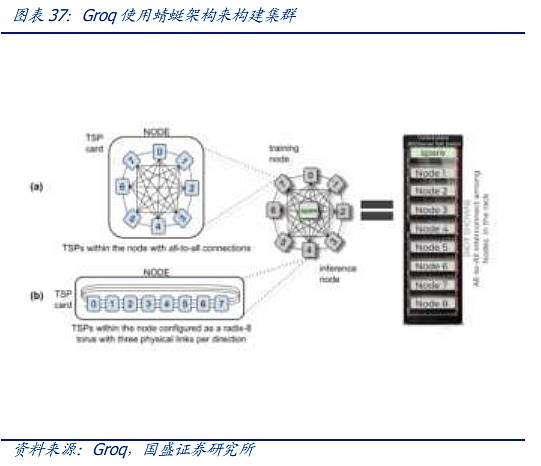
Một trong những đại diện của giải pháp đầu tiên là kiến trúc Dragonfly. Kiến trúc Dragonfly được đề xuất lần đầu tiên vào năm 2008 và là kiến trúc đầu tiên được đề xuất. Nó được sử dụng trong HPC, nhưng vì nó phải được nối lại mỗi khi mở rộng và hệ thống dây điện phức tạp hơn, mặc dù nó sử dụng ít công tắc hơn kiến trúc CLOS nên cuối cùng nó không thể trở thành xu hướng chủ đạo. Nhưng giờ đây, trong bối cảnh có số lượng nút khổng lồ và chi phí vốn cho phần cứng AI đắt đỏ, kiến trúc Dragonfly đã dần bắt đầu thu hút sự chú ý của ngành một lần nữa. Hiện tại, với sự xuất hiện của hệ thống chuyển mạch quang OCS nêu trên, việc đi dây phức tạp dự kiến sẽ được đơn giản hóa thông qua OCS, gã khổng lồ thứ hai có kế hoạch và nhịp độ chi vốn rõ ràng hơn cho các cụm AI. Do đó, quá trình mở rộng rườm rà hơn của chuồn chuồn cũng không còn nữa. còn là một hạn chế. Thứ ba, chuồn chuồn có lợi thế ở cấp độ vật lý so với gai lá về độ trễ. Hiện tại, các chip AI nhạy cảm hơn với độ trễ, chẳng hạn như Groq, đã bắt đầu sử dụng kiến trúc này để xây dựng các cụm.
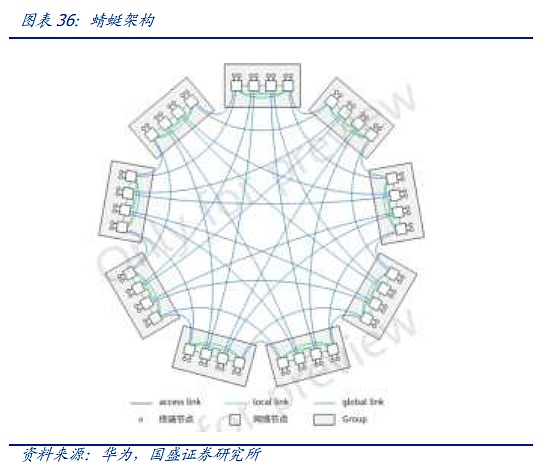
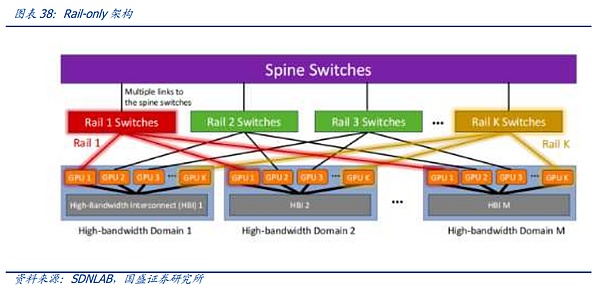
Một trong những đại diện của giải pháp thứ hai là Kiến trúc Rail-only do Meta và MIT đề xuất. Kiến trúc Rail-Only nhóm các GPU để tạo thành miền kết nối băng thông cao (miền HB), sau đó kết nối các GPU cụ thể trong các miền HB này với các bộ chuyển mạch Rail cụ thể. độ phức tạp trong việc định tuyến và lập lịch của giao tiếp giữa các miền, nhưng thông qua thiết kế chuyển mạch Rail và miền HB hợp lý, kiến trúc tổng thể có thể giảm đáng kể việc sử dụng các bộ chuyển mạch và có thể giảm mức tiêu thụ liên lạc mạng tới 75%. Kiến trúc này cũng trùng hợp với sự đổi mới được đề cập ở trên thông qua giao tiếp giữa các chip. Thông qua miền HB-DOMIN được mở rộng, nó mang lại nhiều không gian hơn cho việc đào tạo phân đoạn và tối ưu hóa phần mềm, từ đó giảm nhu cầu chuyển đổi giữa HB-DOMIN, cung cấp không gian cho mạng. giảm chi phí trong các cụm rất lớn.
4.4 Đổi mới trong cụm trung tâm dữ liệu: hình thức tối ưu của mạng điện toán trong tương lai?
Khi quy mô của cụm AI tiếp tục mở rộng, công suất của một trung tâm dữ liệu cuối cùng sẽ đạt đến giới hạn trên. không đề cập đến chi phí vốn hoặc Đó là giới hạn trên của các nút mà mạng truyền thông có thể mang theo, nhưng nguồn điện hoặc nguồn điện hiệu quả về mặt chi phí nơi đặt trung tâm dữ liệu sẽ đạt đến giới hạn trên.
Đầu năm 2024, Microsoft và OPENAI bắt đầu thảo luận về việc xây dựng siêu máy tính "Stargate" vào năm 2028. Theo The Information, Stargate cuối cùng sẽ được hoàn thành dưới dạng một Toàn bộ kế hoạch có thể yêu cầu khoản đầu tư hơn 1.000 USD và yêu cầu sử dụng tới 5 gigawatt điện, điều này cũng sẽ trở thành một trong những vấn đề cấp bách nhất của dự án bên cạnh chip và nguồn vốn.
Do đó, ở vị trí hàng đầu trong ngành hiện nay, làm thế nào để có thể phân bổ đồng đều sức mạnh điện toán ở những khu vực có nguồn điện tiết kiệm chi phí thông qua kết nối khoảng cách xa giữa các trung tâm điện toán thông minh? sự gia tăng chi phí điện năng tính toán hoặc giới hạn trên của công suất điện toán do giá quá cao ở một khu vực. Việc kết nối giữa các trung tâm dữ liệu rất khác với hệ thống kết nối nội bộ của cụm về giao thức, phần cứng, v.v.
Hiện nay, các trung tâm dữ liệu thường được kết nối với mạng bên ngoài thông qua các switch lớp trên hoặc switch lõi, trong khi Internet DCI của trung tâm dữ liệu thường được các nhà khai thác xây dựng và sử dụng lâu dài. -khoảng cách Mặc dù tốc độ truyền của các mô-đun quang kết hợp dài hơn nhưng tốc độ và độ ổn định của nó khác biệt đáng kể so với các mô-đun quang được sử dụng trong trung tâm dữ liệu, đồng thời giá thành của nó vẫn cao nên đều giảm chi phí và xây dựng lại kiến trúc. thực hiện trước khi xây dựng chính thức các câu hỏi cần xem xét.
Nhưng nếu chúng ta nhìn nó từ góc độ vĩ mô hơn, thì một trung tâm sức mạnh điện toán duy nhất về cơ bản tương tự như miền HB-DOMIN trước đó và có nhiều chức năng hơn. , chúng tôi tin rằng con đường phát triển trong tương lai của loại kết nối này một mặt là đẩy nhanh đầu tư vào ngành mô-đun quang kết hợp để nó có thể chịu được các yêu cầu về tải và công suất của kết nối trung tâm AI, mặt khác, tăng cường mật độ kết nối trong trung tâm dữ liệu. Làm cho trung tâm dữ liệu giống với một miền HB duy nhất và cuối cùng đổi mới phần mềm đào tạo và phần mềm phân tán để cho phép phân đoạn và song song hóa dữ liệu và mô hình chéo IDC.
5. Lời khuyên đầu tư: Sự đổi mới không bao giờ dừng lại, tập trung vào cả các liên kết cốt lõi và các biến số mới
Giống như chip, hệ thống truyền thông không ngừng tăng tốc đổi mới do nhu cầu về AI. Tuy nhiên, không giống như ngành công nghiệp chip thường dựa vào một hoặc hai "thiên tài" Kiến trúc đổi mới. và phần mềm truyền thông và phần cứng là một dự án hệ thống đòi hỏi sự đổi mới và nỗ lực chung của nhiều kỹ sư ở các khía cạnh khác nhau, từ các chip chuyển mạch và chip quang cơ bản nhất, đến các thiết bị chuyển mạch tích hợp hệ thống lớp trên, mô-đun quang, cho đến Từ. thiết kế kiến trúc truyền thông và các giao thức truyền thông đến vận hành và bảo trì hệ thống, mỗi liên kết tương ứng với các gã khổng lồ công nghệ khác nhau và vô số kỹ sư.
Chúng tôi tin rằng so với ngành công nghiệp chip, vốn thiên về đầu tư mạo hiểm hơn, đầu tư vào ngành truyền thông dễ theo dõi hơn và những thay đổi trong ngành thường được bắt đầu và được khởi xướng bởi những người khổng lồ. Việc triển khai và do yêu cầu về tính ổn định của kỹ thuật hệ thống truyền thông, việc lựa chọn nhà cung cấp cho các cụm AI quy mô lớn thường rất nghiêm ngặt. Trước hết, ở khía cạnh phần cứng, bất kể kiến trúc và giao thức mạng có thay đổi như thế nào. , công tắc và mô-đun quang học sẽ luôn là các khối xây dựng cơ bản nhất của hệ thống, miễn là Luật mở rộng vẫn còn hiệu quả và quá trình theo đuổi các thông số của con người vẫn tồn tại thì nhu cầu về các khối xây dựng sẽ tiếp tục. Đúng là kiến trúc LPO, Dragonfly và kiến trúc chỉ dành cho đường sắt thực sự sẽ làm giảm tỷ lệ hoặc giá trị của các thiết bị liên quan, nhưng việc giảm chi phí luôn là ưu tiên hàng đầu của AI. Việc mở rộng nhu cầu do giảm chi phí mang lại sẽ mang lại triển vọng rộng lớn hơn cho AI. không gian ngành công nghiệp. Đây là khái niệm cốt lõi và mối liên kết cần được nắm bắt đầu tiên trong đầu tư truyền thông AI.
Đồng thời, đối với liên kết đổi mới, chúng ta cũng phải tích cực theo dõi các xu hướng công nghệ mới và tìm hiểu những thay đổi về thành phần trong liên kết cốt lõi do liên kết cốt lõi mang lại. sự thay thế của các công nghệ mới, trước hết, nhu cầu về cáp đồng do việc xây dựng miền HB-DOMIN tiết kiệm chi phí sẽ tăng đầu tiên về số lượng, tiếp theo là CPO, các trung tâm dữ liệu đường dài mang lại nhu cầu đặc biệt. các sợi quang như sợi quang duy trì phân cực, sợi quang pha tạp erbium và cuối cùng là Bộ chuyển mạch toàn quang, Liên minh Super Ethernet, v.v. mang đến cơ hội cho ngành để đẩy nhanh sự phát triển của bộ chuyển mạch trong nước.
6. Cảnh báo rủi ro
1. Nhu cầu về AI ít hơn mong đợi.
AI hiện tại vẫn đang trong giai đoạn nghiên cứu và phát triển mô hình và việc phát triển sản phẩm C-end cụ thể vẫn đang được tiến hành Nếu nhu cầu C-end tiếp theo là. không như mong đợi, có nguy cơ nhu cầu AI toàn cầu suy giảm.
2. Luật chia tỷ lệ không hợp lệ.
Cơ sở chính cho sự gia tăng sức mạnh tính toán toàn cầu hiện nay là quy luật xếp chồng liên tục thang đo tham số thông qua sức mạnh tính toán để mô hình tốt hơn vẫn có hiệu lực Nếu ngăn xếp tham số đạt đến giới hạn trên, sẽ có tác động đến yêu cầu về năng lượng tính toán.
3. Cạnh tranh trong ngành ngày càng gay gắt.
Ngành công nghiệp điện toán và mạng toàn cầu đang phát triển nhanh chóng nhờ AI. Nếu có quá nhiều người mới tham gia để cạnh tranh, lợi nhuận của các công ty hàng đầu hiện tại sẽ bị giảm sút.
<nil>
ChrisETHena, UST sẽ thất bại như UST? Phân tích sự khác biệt giữa ETH và UST Golden Finance, liệu ETH có sụp đổ trong cuộc khủng hoảng kiểu UST?
 JinseFinance
JinseFinanceThị trường giá lên thực sự đã quay trở lại, nhưng lần này nó sôi động hơn và diễn ra sớm hơn một chút so với dự đoán của nhiều người. Hãy cùng tìm hiểu xem thị trường lần này có gì khác biệt.
JinseFinanceCác phương thức đầu tư tiền điện tử phát triển: ICO và IEO. Lịch sử của ICO: Thành công vang dội của Ethereum. IEO nổi lên như một giải pháp thay thế có vẻ an toàn. Rủi ro vẫn tồn tại trong cả ICO và IEO. Các nhà đầu tư kêu gọi tiến hành nghiên cứu kỹ lưỡng.
 Bernice
BerniceMột hình ảnh cho bạn thấy 3 loại BTC ETF và 3 loại hợp đồng tương lai BTC.
JinseFinanceLinkNFT, do China Mobile ra mắt, đang thay đổi bối cảnh kỹ thuật số của Hồng Kông, thu hẹp khoảng cách giữa thế giới thực và ảo, đồng thời báo trước một kỷ nguyên mới trong Web3.0.
 Huang Bo
Huang BoẤn phẩm đã phân bổ khoảng 390.000 đô la để phát triển nền tảng NFT của mình và đang chào đón các chuyên gia blockchain tham gia vào dự án.
 Clement
ClementCông ty cũng được biết đến với sự tham gia vào công nghệ blockchain với tư cách là thành viên sáng lập của Mạng dịch vụ dựa trên Blockchain do nhà nước hậu thuẫn của Trung Quốc.
 Brian
Brian Cointelegraph
CointelegraphTrong bài viết này, chúng tôi sẽ chỉ ra sidechains và giải pháp L2 là gì và cách chúng có thể hỗ trợ khả năng mở rộng.
 Ftftx
Ftftx