Nguồn: Heart of the Metaverse
Trong khi Google, Samsung và Microsoft tiếp tục thúc đẩy mạnh mẽ công nghệ tạo trí tuệ nhân tạo trên PC và thiết bị di động, Apple cũng đã gia nhập hàng ngũ và ra mắt OpenELM.
Đây là dòng mô hình ngôn ngữ lớn (LLM) mã nguồn mở mới có thể chạy hoàn toàn trên một thiết bị duy nhất mà không cần kết nối với máy chủ đám mây.
01. Các tính năng và hiệu suất của mô hình
Vào thứ Tư theo giờ địa phương, OpenELM đã được phát hành trên cộng đồng mã trí tuệ nhân tạo Hugging Face. Nó bao gồm một loạt các mô hình nhỏ được thiết kế để thực hiện văn bản một cách hiệu quả. nhiệm vụ thế hệ.
OpenELM có tổng cộng tám mô hình: bốn mô hình được đào tạo trước và bốn mô hình được điều chỉnh theo hướng dẫn, bao gồm từ 270 triệu đến 3 tỷ tham số khác nhau (các tham số đề cập đến số lượng kết nối giữa các nơ-ron nhân tạo trong LLM, thường Càng nhiều tham số thì hiệu năng càng mạnh và càng nhiều chức năng).
Mặc dù đào tạo trước là một cách để LLM tạo ra văn bản mạch lạc và có khả năng hữu ích, nhưng nó chủ yếu là một bài tập mang tính dự đoán, trong khi việc điều chỉnh hướng dẫn là giúp LLM đưa ra những phản hồi phù hợp hơn cho các yêu cầu cụ thể của người dùng. Phương pháp đầu ra.
Đào tạo trước có thể khiến mô hình chỉ sử dụng văn bản đơn giản để hoàn thành lời nhắc. Ví dụ: đối mặt với lời nhắc của người dùng "Dạy tôi cách nướng bánh mì", mô hình có thể phản hồi tương tự như "Sử dụng. lò nướng tại nhà." Thay vì hướng dẫn thực tế từng bước.
Apple cung cấp trọng số mô hình OpenELM, cùng với hướng dẫn cho các điểm kiểm tra đào tạo khác nhau, thống kê hiệu suất mô hình, đào tạo trước, đánh giá, điều chỉnh hướng dẫn và tinh chỉnh tham số, theo cái mà hãng gọi là "Giấy phép mã mẫu" ."
"Giấy phép mã mẫu" không cấm sử dụng hoặc sửa đổi vì mục đích thương mại mà chỉ nêu rõ rằng "Nếu bạn phân phối lại toàn bộ Phần mềm Apple mà không sửa đổi, bạn phải giữ lại thông báo này trong văn bản."
Apple tuyên bố thêm rằng những mẫu máy này "không có đảm bảo về bảo mật". Do đó, những mô hình này có khả năng tạo ra “đầu ra không chính xác, có hại, sai lệch hoặc phản cảm” theo lời nhắc của người dùng.
Apple là một công ty công nghệ khét tiếng bí ẩn và thường "đóng cửa".
Ngoài ra, ngay từ tháng 10 năm ngoái, Apple đã âm thầm cho ra mắt Ferret, một mô hình ngôn ngữ nguồn mở với khả năng đa phương thức, gây xôn xao dư luận.
OpenELM là tên viết tắt của "Mô hình ngôn ngữ hiệu quả nguồn mở". Mặc dù mới được phát hành và chưa được thử nghiệm công khai nhưng danh sách của Apple trên HuggingFace cho thấy họ đang nhắm đến mô hình này. giống như các đối thủ Google, Samsung và Microsoft.
Điều đáng chú ý là tuần này Microsoft vừa tung ra mẫu Phi-3 Mini có thể chạy hoàn toàn trên điện thoại thông minh.
02. Chi tiết kỹ thuật và quy trình đào tạo
Trong bài viết giới thiệu loạt mô hình, Apple tuyên bố rằng quá trình phát triển OpenELM "được dẫn dắt bởi Sachin Mehta, cũng như bởi Mohammad Rastegari và Peter Zatloukal. Những người đóng góp chính", loạt mô hình "nhằm trao quyền và củng cố cộng đồng nghiên cứu mở và thúc đẩy các nỗ lực nghiên cứu trong tương lai."
Mô hình OpenELM có bốn kích thước tham số: 270 triệu, 450 triệu, 1,1 tỷ và 3 tỷ, mỗi mô hình nhỏ hơn nhiều mô hình hiệu suất cao (thường có khoảng 7 tỷ tham số). phiên bản được đào tạo và hướng dẫn.
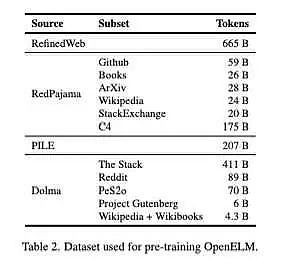
Các mô hình này được đào tạo trước trên tập dữ liệu công khai gồm 1,8 nghìn tỷ mã thông báo từ Reddit, Wikipedia, arXiv.org và các trang web khác.
Các mẫu này phù hợp để chạy trên máy tính xách tay thương mại và thậm chí một số điện thoại thông minh và điểm chuẩn được chạy trên "MacBook Pro với CPU Intel i9-13900KF, GPU NVIDIA RTX 4090, Ubuntu 22.04 Workstation, macOS 14.4.1."
Điều thú vị là tất cả các mô hình trong loạt sản phẩm mới đều áp dụng chiến lược mở rộng quy mô theo cấp bậc, phân bổ các tham số trong mỗi lớp của mô hình máy biến áp.
Theo Apple, điều này cho phép họ cung cấp kết quả có độ chính xác cao hơn đồng thời tăng hiệu quả tính toán. Đồng thời, Apple đã đào tạo trước mô hình sử dụng thư viện CoreNet mới.
Apple đã lưu ý trên HuggingFace: “Tập dữ liệu đào tạo trước của chúng tôi chứa RefinedWeb, PILE lặp lại, một tập hợp con của RedPajama và một tập hợp con của Dolma v1.6, tổng cộng khoảng 1,8 nghìn tỷ mã thông báo”.
Về hiệu năng, kết quả OpenLLM được Apple chia sẻ cho thấy hiệu năng của các dòng máy này khá tốt, đặc biệt là biến thể chỉ báo 450 triệu thông số.
Ngoài ra, "biến thể OpenELM" với 1,1 tỷ tham số cao hơn 2,36% so với "OLMo" với 1,2 tỷ tham số, đồng thời yêu cầu mã thông báo đào tạo trước ít hơn 2 lần.
OLMo là một "mô hình ngôn ngữ quy mô lớn hiện đại, mã nguồn mở thực sự" được Viện Trí tuệ Nhân tạo Allen (AI2) phát hành gần đây.
03. Kiểm tra hiệu suất và phản hồi của cộng đồng
Trong tiêu chuẩn ARC-C, được thiết kế để kiểm tra kiến thức và khả năng suy luận, biến thể OpenELM-3B được đào tạo trước đã đạt được độ chính xác là 42,24%. Trong khi đó, trên MMLU và HellaSwag, độ chính xác của nó lần lượt là 26,76% và 73,28%.
Một người dùng đã bắt đầu thử nghiệm mô hình OpenELM đã lưu ý rằng mô hình này có vẻ là một "mô hình vững chắc nhưng rất đồng nhất", nghĩa là các phản hồi của nó không mang tính sáng tạo rộng rãi cũng như không có khả năng thuộc lĩnh vực NSFW.
Đối thủ cạnh tranh Phi-3 Mini mới ra mắt gần đây của Microsoft, với 3,8 tỷ thông số và độ dài ngữ cảnh 4k, hiện đang dẫn đầu lĩnh vực này.
Theo thống kê được chia sẻ gần đây, OpenELM đạt 84,9% trong 10 bài kiểm tra ARC-C, 68,8% trong 5 bài kiểm tra MMLU và 68,8% trong 5 bài kiểm tra HellaSwag. Tỷ lệ điểm là 76,7%.
Về lâu dài, hiệu suất của OpenELM dự kiến sẽ được cải thiện.
Nhưng các sáng kiến nguồn mở của Apple đã khiến cộng đồng phấn khích và chúng tôi sẽ chờ xem cộng đồng sử dụng OpenELM như thế nào trong các môi trường khác nhau.
04. Tầm nhìn AI của Apple
Apple đã giữ im lặng về các kế hoạch AI tổng quát của mình, nhưng với việc phát hành các mô hình AI mới, tham vọng ngắn hạn của công ty dường như đã thành hiện thực. lĩnh vực “đưa AI chạy tự nhiên trên các thiết bị Apple”.
CEO Tim Cook của Apple từng dự đoán: "Khả năng tạo ra trí tuệ nhân tạo sẽ xuất hiện trên các thiết bị của Apple". Và vào tháng 2 năm nay, Apple cho biết Apple đang dành "rất nhiều thời gian và sức lực" cho lĩnh vực này. Tuy nhiên, Apple chưa tiết lộ chi tiết cụ thể về các ứng dụng trí tuệ nhân tạo.
Công ty đã từng phát hành các mô hình AI khác trước đây nhưng vẫn chưa phát hành bất kỳ mô hình AI cơ bản nào cho mục đích thương mại như các đối thủ cạnh tranh.
Ngoài OpenELM, vào tháng 12 năm ngoái, Apple đã ra mắt khung máy học MLX. Trạng thái lý tưởng của khung này là giúp các mô hình trí tuệ nhân tạo chạy trên Apple silicon dễ dàng hơn. Ngoài ra, một mô hình chỉnh sửa hình ảnh có tên MGIE đã được phát hành cho phép mọi người sửa ảnh bằng các mẹo. Và một mô hình có tên Ferret-UI có thể được sử dụng để điều hướng trên điện thoại thông minh.
Tuy nhiên, mặc dù Apple đã tung ra rất nhiều mẫu máy nhưng công ty này được cho là đã liên hệ với Google và OpenAI với hy vọng đưa các mẫu máy của họ vào các sản phẩm của Apple.


 Weatherly
Weatherly






