FMG INDEX分析:WEB3AIの機会と課題とは?
Web3の先にある物語としてのAIは、それよりもはるかに大きな商業的スケールを持ち、市場が引き起こした劇的なショックは、再配置の絶好のタイミングである。
 JinseFinance
JinseFinance

2017年のEtheroll、ETHLend、CryptoKittiesといったdAppsの最初の波から始まり、今ではさまざまなブロックチェーンに基づく金融、ゲーム、ソーシャルdAppsが急増しています。非中央集権的なオンチェーンアプリについて語るとき、私たちはこれらのアプリがやり取りで使用するデータのソースについて考えたことがあるでしょうか?
2024年には、AIとWeb3に焦点が当てられるだろう。AIの世界では、データは成長と進化のための生命源のようなものだ。植物が日光と水に依存して成長するように、AIシステムもまた、継続的に「学習」し「思考」するために大量のデータに依存している。データがなければ、AIアルゴリズムは天空の城ラピュタに過ぎず、本来の知性と有効性を発揮することはできない。
本記事では、ブロックチェーンのデータアクセシビリティの観点から、ブロックチェーンデータインデックスの進化を詳細に分析し、確立されたデータインデックスのプロトコルであるThe Graphと、新興のブロックチェーンデータサービスプロトコルを比較します。特に、AI技術を取り入れたこれら2つの新進気鋭のプロトコルのデータサービスと製品アーキテクチャの特徴における類似点と相違点を探っています。
2.1 データのソース:ブロックチェーンノード
「ブロックチェーンとは何か」を理解する最初の段階から、ブロックチェーンは分散型の帳簿であるという記述をよく目にします。ブロックチェーン・ノードはブロックチェーン・ネットワーク全体の基盤であり、チェーン上のすべての取引に関するデータを記録、保存、発信する責任を担っている。各ノードはブロックチェーン・データの完全なコピーを持ち、ネットワークの分散化された性質を確実に維持する。しかし、ブロックチェーン・ノードを自力で構築・維持することは、一般ユーザーにとって容易なことではない。専門的な技術スキルが必要なだけでなく、高いハードウェアと帯域幅のコストがかかる。同時に、一般的なノードでは、開発者が必要とする形式でデータを照会する能力に限界がある。その結果、理論的には誰もが自分のノードを動かすことができるものの、実際にはユーザーはサードパーティのサービスに頼ることを好むことが多い。
この問題に対処するために、RPC(リモートプロシージャコール)ノードプロバイダーが登場しました。これらのプロバイダーはノードのコストと管理を引き受け、RPCエンドポイントを通じてデータを利用できるようにします。これにより、ユーザーは独自のノードを構築することなく、ブロックチェーンのデータに簡単にアクセスできるようになる。パブリックRPCエンドポイントは無料ですが、レートが制限されているため、dAppのユーザーエクスペリエンスに悪影響を及ぼす可能性があります。プライベートRPCエンドポイントは輻輳を軽減することでより良いパフォーマンスを提供しますが、単純なデータ検索でさえ多くの往復通信を必要とします。そのため、複雑なデータクエリでは要求が重くなり、効率が悪くなります。さらに、プライベートRPCエンドポイントは拡張が難しく、異なるネットワーク間での互換性に欠けることが多い。しかし、ノードプロバイダーからの標準化されたAPIインターフェースは、ユーザーにチェーン内のデータにアクセスするためのより低い障壁を与え、その後のデータ解析やアプリケーションの基礎を築きます。
2.2データ解析:プロトタイプから使用可能なデータへ
ブロックチェーンノードから取得されたデータは、多くの場合、暗号化され、生データとしてエンコードされます。このデータはブロックチェーンの完全性とセキュリティを保持する一方で、その複雑さゆえにデータの解析の難易度も上がります。平均的なユーザーや開発者にとって、このプロトタイプデータを直接処理するには、かなりの技術的知識と計算リソースが必要です。
この文脈では、データ解析のプロセスが特に重要です。複雑な原型データを解析し、理解しやすく操作しやすい形式に変換することで、ユーザーはより直感的にデータを理解し、活用することができます。データ解析の成功は、ブロックチェーンデータアプリケーションの効率性と有効性を直接決定し、データインデキシングプロセス全体における重要なステップです。
2.3データインデクサーの進化
ブロックチェーン上のデータ量の増加に伴い、データインデクサーの必要性も高まっています。インデクサは、チェーン上のデータを整理し、簡単にクエリできるようにデータベースに送信するという重要な役割を果たします。インデクサは、ブロックチェーンのデータにインデックスを付け、SQLのようなクエリ言語(GraphQLなどのAPI)を通じて容易に利用できるようにすることで機能する。データをクエリするための統一されたインターフェースを提供することで、インデクサは、開発者が標準化されたクエリ言語を使用して必要な情報を迅速かつ正確に取得できるようにし、プロセスを大幅に簡素化します。
さまざまなタイプのインデクサーは、さまざまな方法でデータ検索を最適化します:
フルノードインデクサー:これらのインデクサーは、ブロックチェーンノード全体を実行し、そこから直接データを抽出します。しかし、かなりのストレージと処理能力を必要とします。
軽量インデクサー:これらのインデクサーは、必要に応じて特定のデータをフェッチするためにフルノードに依存し、ストレージ要件を削減しますが、クエリ時間が増加する可能性があります。
特化型インデクサー:これらのインデクサーは、特定のタイプのデータまたは特定のブロックチェーンに特化しており、NFTデータやDeFiトランザクションなど、特定のユースケースにおける検索のために最適化することができます。
アグリゲートインデクサー:これらのインデクサーは、統一されたクエリインターフェースを提供するために、オフチェーン情報を含む複数のブロックチェーンやソースからデータを引き出します。
現在、イーサネット・アーカイブ・ノードはGethクライアントのアーカイブモードで約13.5TBのストレージを占有しており、Erigonクライアントではアーカイブ要件は約3TBです。ノードのデータストレージも増加する。このような膨大なデータを前にして、主流のインデクサ・プロトコルはマルチチェーン・インデックスをサポートするだけでなく、さまざまなアプリケーションのデータ要件に合わせてデータ解析フレームワークをカスタマイズしている。例えば、The GraphのSubgraphフレームワークはその一例です。
インデクサーの出現は、データのインデックス作成とクエリの効率を大幅に改善しました。従来のRPCエンドポイントと比較して、インデクサは大量のデータを効率的にインデックス化し、高速なクエリをサポートすることができます。これらのインデクサにより、ユーザーは複雑なクエリを実行したり、データを簡単にフィルタリングしたり、抽出後に分析したりすることができる。さらに、一部のインデクサは複数のブロックチェーンからのデータソースの集約をサポートしており、マルチチェーンdAppで複数のAPIをデプロイする必要性を回避している。複数のノードで分散して実行することで、インデクサーはセキュリティとパフォーマンスを強化するだけでなく、中央集権的なRPCプロバイダーがもたらす混乱やダウンタイムのリスクも低減します。
対照的に、インデクサーは、ユーザーが事前に定義されたクエリ言語を通してデータの根本的な複雑さに対処することなく、必要な情報に直接アクセスすることを可能にします。この仕組みは、データ検索の効率と信頼性を大幅に向上させ、ブロックチェーンのデータアクセスにおける重要なイノベーションとなります。
2.4フルチェーンデータベース:ストリームファーストに合わせる
インデックス付きノードを使用してデータを照会することは、通常、APIがチェーン上のデータを消化するための唯一のポータルになることを意味します。しかし、プロジェクトがスケーリング段階に入ると、標準化されたAPIでは提供できない、より柔軟なデータソースが必要になることがよくあります。アプリケーションの要件がより複雑になるにつれ、標準化されたインデックス形式を持つプライマリデータインデクサーは、検索、クロスチェーンアクセス、オフチェーンデータマッピングなど、ますます多様化するクエリニーズを満たすことができなくなります。
最新のデータパイプラインアーキテクチャでは、「ストリームファースト」アプローチが従来のバッチ処理の制限を解決するソリューションとなっています。これにより、リアルタイムのデータ取り込み、処理、分析が可能になりました。このパラダイムシフトにより、組織は入力データに即座に対応し、ほとんど瞬時に洞察を得て意思決定を行うことができるようになった。同様に、ブロックチェーンデータサービスプロバイダーの開発もブロックチェーンデータストリームの構築に向かっており、従来のインデクササービスプロバイダーは、The GraphのSubstreams、GoldskyのMirror、ブロックチェーンに基づいてリアルタイムデータストリームを生成するChainbaseやSubSquidのような製品など、ブロックチェーンデータをリアルタイムでストリーム配信する製品を発表している。ChainbaseやSubSquidも、ブロックチェーンに基づいてストリームを生成するリアルタイムのデータレイクだ。
これらのサービスは、ブロックチェーントランザクションのリアルタイム解析と、より包括的なクエリー機能のニーズに対応するために設計されています。ストリームファースト」アーキテクチャが、待ち時間を短縮し応答性を高めることで、従来のデータパイプラインでデータを処理し消費する方法に革命を起こしたように、これらのブロックチェーンデータストリーミングサービスプロバイダーは、より多くのアプリケーションの開発をサポートし、より高度で成熟したデータソースでオンチェーンデータ分析を支援しようとしています。
最新のデータパイプラインのレンズを通してオンチェーンデータを再定義するという課題によって、オンチェーンデータの管理、保存、配信の可能性をまったく新しい視点で見ることができます。イーサネットETLのようなサブグラフとインデクサーを、最終的な出力ではなく、データパイプラインのデータストリームとして考え始めると、どのようなビジネスユースケースにも対応できる高性能データセットの可能性の世界を思い描くことができます。Graph
Graphネットワークは、ノードの分散型ネットワークを通じてマルチチェーンのデータ索引付けとクエリサービスを可能にし、開発者が簡単にブロックチェーンのデータを索引付けし、分散型アプリケーションを構築できるようにします。その主な製品モデルは、データクエリ実行市場とデータインデックスキャッシング市場であり、両者は本質的にユーザーの製品クエリニーズに応えるものである。データクエリ実行市場は特に、データを提供する適切なインデックスノードを選択することで、消費者が必要なデータに対する支払いを行うことを指し、データインデックスキャッシング市場は、サブグラフのインデックス作成熱の履歴、課金されるクエリ料金、サブグラフ出力に対するオンチェーンキュレーターの需要に基づくインデックスノードのリソース割り当てである。データインデックスキャッシュの市場は、インデックスノードが、サブグラフの過去のインデックス熱、課金されたクエリ料金、およびチェーン上のキュレーターによるサブグラフ出力に対する需要に基づいて、リソースの割り当てを動員する市場です。
サブグラフは、グラフネットワークの基礎となるデータ構造です。データがどのようにブロックチェーンから抽出され、クエリ可能なフォーマット(GraphQLスキーマなど)に変換されるかを定義します。サブグラフは誰でも作成でき、複数のアプリケーションで再利用できるため、データの再利用性と効率が高まります。
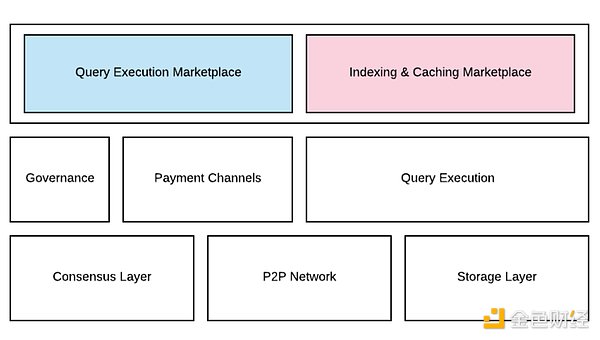
グラフ・プロダクト・アーキテクチャ(出典:グラフ・ホワイトペーパー)
グラフ・ネットワークは、4つの主要なプレーヤーで構成されています。グラフ・ネットワークは、4つの主要な役割で構成されています。すなわち、インデクサー、キュレーター、プリンシパル、デベロッパーであり、これらはWeb3アプリケーションをサポートするデータを提供するために協働します。
インデクサ:インデクサは、The Graphネットワークのノードのオペレーターであり、インデクシングノットは、インデクシングとクエリ処理サービスを提供するGRT(Graphのネイティブトークン)を誓約することでネットワークに参加します。
デリゲーター:デリゲーターは、インデックスノードの運営をサポートするために、インデックスノードにGRTトークンを誓約するユーザーです。デリゲーターは、委任したインデックスノードから報酬の一部を得ます。
キュレーター:キュレーターは、どのサブグラフがネットワークによってインデックスされるべきかを通知する責任があります。キュレーターは、価値のあるサブグラフが優先されるように支援する。
開発者:供給側である最初の3人とは異なり、開発者は需要側であり、グラフの主なユーザーです。彼らはサブグラフを作成し、The Graphネットワークに提出し、ネットワークがデータの需要を満たすのを待ちます。

現在、ザ・グラフは完全な分散型に移行しています。Graphは完全に分散化されたサブグラフのホスティングサービスに移行しており、システムが機能するように、さまざまな参加者の間で経済的インセンティブが循環しています。
インデックスノードの報酬:インデックスノードは、消費者のクエリ料金とGRTトークンブロックの部分的な報酬を通じて収益を得ます。
デリゲート報酬:デリゲートは、サポートするインデックスノードを通じて報酬の一部を獲得します。
キュレーター報酬:キュレーターは、価値のあるサブグラフにシグナルを送ると、クエリ報酬の一部を得る。
実際、The Graphの提供するサービスは、AIの波を受けて急速に進化してきた。The Graphエコシステムの中核開発チームの1つであるSemiotic Labsは、AI技術を使ったインデックスの価格設定とユーザーのクエリ体験の最適化に取り組んできた。現在、Semiotic Labsは、エコシステムのパフォーマンスを複数の方法で向上させるAutoAgora、Allocation Optimizer、AgentCツールを開発しています。
AutoAgoraは、クエリー量とリソース使用量に基づいてリアルタイムで価格を調整する動的な価格設定メカニズムを導入し、価格設定戦略を最適化して、インデクサーの競争力を確保し、収益を最大化します。
割り当てオプティマイザーは、サブグラフのリソース割り当ての複雑な問題を解決し、収益とパフォーマンスを向上させるために、インデクサがリソースの最適な割り当てを達成できるようにします。
AgentCは、ユーザーが自然言語を通じてThe Graphのブロックチェーンデータにアクセスできるようにすることで、ユーザーエクスペリエンスを向上させる実験的なツールです。
これらのツールを使用することで、The GraphはAIによるさらなるインテリジェンスとシステムの使いやすさを両立させることができました。
3.2チェーンベース
チェーンベースは、すべてのブロックチェーンのデータを単一のプラットフォームに統合するホールチェーンデータネットワークであり、開発者がシステムを構築・維持することを容易にします。開発者はより簡単にアプリケーションを構築し、保守することができます。
リアルタイムデータレイク:Chainbaseは、ブロックチェーンデータストリーム専用のリアルタイムデータレイクを提供し、データが生成されると即座にアクセスできるようにします。
デュアルチェーンアーキテクチャ:Chainbaseは、Eigenlayer AVSに基づいて実行レイヤーを構築し、CometBFTのコンセンサスアルゴリズムと並行して使用することで、デュアルチェーンアーキテクチャを形成しています。この設計は、クロスチェーンデータのプログラマビリティとコンポーザビリティを強化し、高スループット、低レイテンシ、ファイナリティをサポートし、二重誓約モデルによりネットワークセキュリティを向上させます。
革新的なデータフォーマット標準:チェーンベースは、暗号業界でデータが構造化され利用される方法を最適化する「原稿」と呼ばれる新しいデータフォーマット標準を導入しました。
暗号世界モデル:膨大なブロックチェーンデータリソースを活用し、チェーンベースはAIモデリング技術を組み合わせて、ブロックチェーン取引を効果的に理解、予測、相互作用できるAIモデルを作成しました。モデルの基本バージョンであるTheiaは現在、一般利用が可能です。
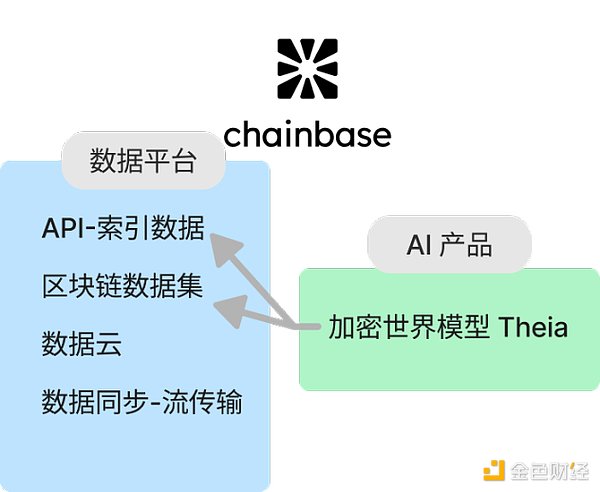
これらの機能により、Chainbaseはブロックベースの中でも際立っています。特に、リアルタイムのデータアクセシビリティ、革新的なデータフォーマット、オンチェーンデータとオフチェーンデータの組み合わせによる洞察力を高めるスマートモデルの作成に重点を置いています。
ChainbaseのAIモデルであるTheiaは、他のデータサービスプロトコルとの重要な差別化要因です。 NVIDIAが開発したDORAモデルをベースとするTheiaは、オンチェーンとオフチェーンのデータ、および時空間アクティビティを組み合わせて、暗号パターンを学習・分析し、因果推論で対応します。Theiaは、NVIDIAが開発したDORAモデルに基づいており、オンチェーンおよびオフチェーンデータと空間的・時間的活動を組み合わせて、暗号パターンを学習・分析し、因果推論によって応答することで、チェーン上のデータの潜在的な価値と法則性を深く探求し、ユーザーによりインテリジェントなデータサービスを提供します。
AI対応のデータサービスにより、チェーンベースは単なるブロックチェーンデータサービスプラットフォームではなく、より競争力のあるインテリジェントなデータサービスプロバイダーとなります。強力なデータリソースとAIによる積極的な分析により、チェーンベースはより広範なデータ洞察を提供し、ユーザーのデータ処理を最適化することができます。
3.3空間と時間
空間と時間(SxT)は、分散型データウェアハウスの上にゼロ知識証明を拡張する検証可能な計算レイヤーを作成することを目的としています。データウェアハウスの上にゼロ知識証明を拡張し、スマートコントラクト、ビッグ・ランゲージ・モデル、企業向けに信頼できるデータ処理を提供する検証可能なコンピュート・レイヤーを構築することを目的としている。Space and Timeは、Framework Ventures、Lightspeed Faction、Arrington Capital、Hivemind Capitalが主導する最新のシリーズA資金調達ラウンドで2000万ドルを確保しました。
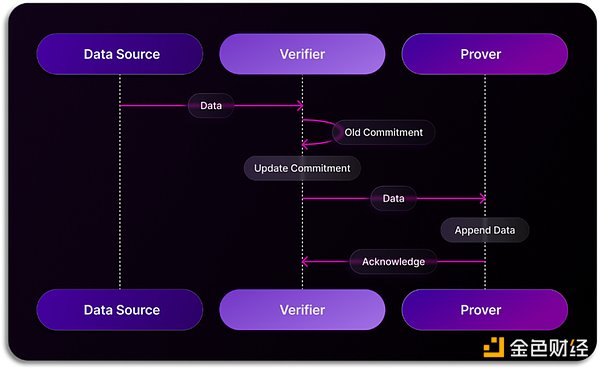
スペース・アンド・タイムは、データのインデックス作成と検証の分野で、スペース・アンド・タイムが開発した革新的なゼロ知識証明(Zero Knowledge Proof、「ZKP」)技術であるProof of SQLという全く新しい技術パスを導入し、データが最善の方法でインデックス作成され検証されることを保証します。ZKP)テクノロジーは、分散型データウェアハウス上で実行されるSQLクエリが改ざん防止され、検証可能であることを保証するためにスペース&タイム社によって開発されました。クエリが実行されると、Proof of SQLはクエリ結果の完全性と正確性を検証する暗号化証明を生成する。この証明はクエリ結果に添付され、どの検証者(スマートコントラクトなど)も、処理中にデータが改ざんされていないことを独自に確認できる。従来のブロックチェーン・ネットワークでは、データの真正性を検証するためにコンセンサス・メカニズムに依存するのが一般的だったが、Space and TimeのProof of SQLは、より効率的な方法でデータを検証することを可能にする。具体的には、スペース・アンド・タイムのシステムでは、1つのノードがデータの取得を担当し、他のノードがzk技術によってそのデータの真正性を検証する。このアプローチでは、複数のノードが同じデータのインデックス付けを繰り返すことによるリソースロスを、コンセンサスメカニズムの下でデータを取得するための最終的なコンセンサスに変更し、システム全体のパフォーマンスを向上させている。この技術が成熟すれば、データの信頼性を重視するさまざまな伝統産業が、ブロックチェーン上のデータを使って製品を構築する足がかりができる。
同時に、SxTはマイクロソフトのAI共同イノベーションラボと緊密に協力し、次のようなツールの開発を加速させています。同時に、SxTはマイクロソフトのAI Co-Innovation Labsと緊密に連携し、自然言語によるブロックチェーン・データの処理を容易にする生成AIツールの開発を加速させている。現在、Space and Time Studioでは、ユーザーが自然言語のクエリを入力すると、AIが自動的にSQLに変換し、ユーザーに代わってクエリを実行し、ユーザーが必要とする最終結果を提供することができます。
3.4 違いの比較

要約すると、ブロックチェーンデータインデキシング技術は、最初のノードデータソースから、データ解析とインデクサーの開発を経て、段階的な改善プロセスを経て、最終的にはAI対応のホールチェーンデータサービスへと進化してきました。.これらの技術の継続的な進化は、データアクセスの効率と精度を向上させるだけでなく、ユーザーにこれまでにないインテリジェントな体験をもたらします。
AI技術やゼロ知識証明などの新技術の継続的な開発により、ブロックチェーンデータサービスはさらにインテリジェントで安全なものになるでしょう。私たちは、ブロックチェーンデータサービスが将来もインフラとして重要な役割を果たし、業界の進歩と革新を強力にサポートすると信じる理由があります。
Web3の先にある物語としてのAIは、それよりもはるかに大きな商業的スケールを持ち、市場が引き起こした劇的なショックは、再配置の絶好のタイミングである。
JinseFinanceJinseFinanceWeb3 ゲームは、衰退するまでは期待に満ちていました。復活は成功するでしょうか?
 Clement
Clement Coinlive
Coinlive DeFi プラットフォーム ArrayFi が主催する Bridge Web3 2023 は、ベトナムのフーコック島で開催された 3 日間のカンファレンスでした。
 Davin
Davinweb3 の主な利点には、データ プライバシーの向上、透明性、イノベーションが含まれます。
 Beincrypto
BeincryptoJack Dorsey の Web5 に対するビジョンを際立たせる要素がいくつかあります。たとえば、Web2 を完全に置き換えるのではなく、Web2 と連携させたいということです。
 Coindesk
Coindeskトピックの「独占性」により、一部の人は不快に感じ、そのトピックについて十分な知識がないとわかった場合に質問するのが恥ずかしいと感じます。
 Cointelegraph
CointelegraphWeb 3 が重要な理由 🧵 Web 1 (およそ 1990 年から 2005 年) は、分散型でコミュニティが管理するオープン プロトコルに関するものでした。価値のほとんどは、ネットワークのエッジ (ユーザーとビルダー) で発生します。 Web 2 (およそ 2005 年から 2020 年) は、企業が運営するサイロ化された集中型サービスに関するものでした。価値のほとんどは、Google、Apple、Amazon、Facebook などの一握りの企業にもたらされました。
 Cdixon
CdixonWeb3 テクノロジーは、現在のインターネットの仕組みに革命を起こすためにここにあります。 Web3 は、現在のフレームワークを ... に分散化することでこれを実現します。
 Bitcoinist
Bitcoinist