コイン印刷機を破壊する
ガイがETHを選んだのは、イーサネット・ネットワークがネイティブな収益を提供してくれるからだ。
 JinseFinance
JinseFinance

By Jeff Amico; Compiled by Deep Tide TechFlow
折りたたみ@ホームは、新クラウンの流行中に大きなマイルストーンを達成した。この研究プロジェクトは、世界中の200万人のボランティア・デバイスによって、2.4エクサフロップスの計算能力を獲得した。これは当時世界最大のスーパーコンピューターの15倍の処理能力であり、科学者たちはCOVIDタンパク質のダイナミクスを大規模にシミュレーションすることができた。彼らの研究は、特に流行の初期段階におけるウイルスとその病原体についての理解を前進させた。
Folding@homeユーザーの世界分布(2021年)Folding@home は、AIモデルをクラウドファンディングで資金調達するための基盤です。Folding@homeは、コンピューティング・リソースをクラウドソーシングすることで大規模な問題を解決するプロジェクトによる、ボランティア・コンピューティングの長い歴史の上に構築されています。このアイデアは1990年代、地球外生命体の探索のために500万台以上のボランティア・コンピュータを集めたSETI@homeで人気を博した。それ以来、このアイデアは宇宙物理学、分子生物学、数学、暗号学、ゲームなど多くの分野に応用されてきた。いずれの場合も、集合的な力は、個々のプロジェクトが単独で達成できる能力をはるかに超えて、その能力を高めてきた。これにより進歩が促進され、よりオープンで協力的な方法で研究を進めることができる。
多くの人が、このクラウドソーシング・モデルをディープラーニングに応用できないかと考えた。言い換えれば、大規模なニューラルネットワークを大衆の中で訓練できるのだろうか?フロンティア・モデルのトレーニングは、人類史上最も計算量の多いタスクのひとつだ。多くの@homeプロジェクトがそうであるように、現在のコストは最大規模の参加者だけが出せる金額を超えている。これでは、新たなブレークスルーを見つけるために、より少ない企業に頼ることになり、将来の進歩の妨げになりかねない。また、AIシステムのコントロールが少数の手に集中することにもなる。このテクノロジーをどう感じるかは別として、注目すべき未来である。
ほとんどの批評家は、分散型トレーニングのアイデアは現在のトレーニング技術とは相容れないとして退けています。しかし、この見方はますます時代遅れになりつつある。ノード間の通信の必要性を減らし、ネットワーク接続が不十分なデバイスでも効率的なトレーニングを可能にする新技術が登場している。これには、DiLoCo、SWARM Parallelism、lo-fi、異種環境におけるベースモデルの分散型トレーニングなどの技術がある。これらの多くはフォールトトレラントであり、ヘテロジニアスコンピューティングをサポートしている。また、DiPaCoや分散型ハイブリッドエキスパートモデルなど、分散型ネットワーク用に設計された新しいアーキテクチャもあります。
また、ネットワークが地球規模でリソースを調整することを可能にする、さまざまな暗号プリミティブの成熟も見られます。これらの技術は、デジタル通貨、国境を越えた支払い、予測市場などのアプリケーション・シナリオをサポートしている。初期のボランティア・プロジェクトとは異なり、これらのネットワークは驚異的な量のコンピューティング・パワーを集約することが可能であり、現在想定されている最大のクラウド・トレーニング・クラスタよりも桁違いに大きいことがよくあります。
これらの要素が一体となって、新しいモデルトレーニングパラダイムを形成しています。このパラダイムは、一緒に接続すれば使用できる多数のエッジデバイスを含む、グローバルなコンピューティングリソースを活用します。これにより、新たな競争メカニズムを導入することで、ほとんどのトレーニングワークロードのコストを削減することができる。また、モデル開発を孤立したモノリシックなアプローチではなく、協調的でモジュール化されたものにすることで、新たなトレーニングの形を解き放つことができる。モデルは大衆から計算やデータにアクセスし、リアルタイムで学習することができる。個人が作成したモデルの一部を所有することもできる。研究者はまた、高い計算予算を補うために発見を収益化することなく、新しい発見を公に再共有することができる。
本レポートでは、大規模モデルトレーニングの現状と、それに伴うコストについて検証します。また、SETIからFolding、BOINCに至るまで、これまでの分散コンピューティングの取り組みをレビューし、別の道を探るインスピレーションとしています。本レポートでは、分散型トレーニングの歴史的な課題について議論し、それを克服するのに役立つかもしれない最近のブレークスルーに目を向ける。最後に、将来の機会と課題についてまとめています。
最先端モデルトレーニングの費用は、大規模な参加者以外には手の届かないものになっています。この傾向は新しいものではありませんが、現実的なレベルでは、フロンティアラボがスケーリングの前提に挑戦し続けているため、状況は悪化しています。OpenAIは、今年のトレーニングに30億ドル以上を費やしたと報告されており、Anthropicは、2025年までに、我々はトレーニングに100億ドルを行うようになり、モデルの1000億ドルもそう遠くないと予測しています。
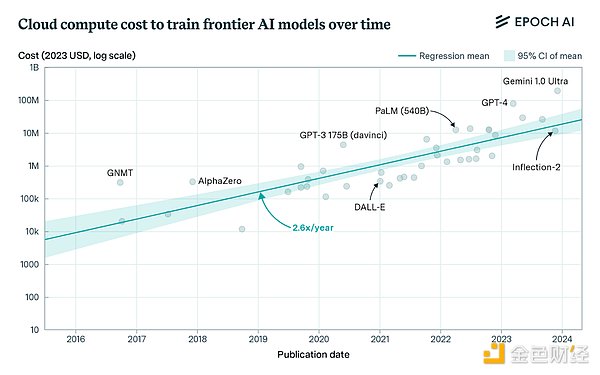
この傾向は、少数の企業しか参加する余裕がないため、業界の中央集権化につながっている。これは、将来の中心的な政策課題を提起している。すべての主要なAIシステムが、1社か2社によってコントロールされている状況を受け入れられるのか?また、小規模な研究所では実験の規模を拡大するのに必要な計算リソースを確保できないため、研究コミュニティでも明らかなように、進歩のペースが制限される。
メタ社のジョー・スピザック氏:(モデル)アーキテクチャの能力を本当に理解するには、それをスケールアップして探求する必要があります。アカデミアを見れば、アカデミアには多くの優れた頭脳がありますが、計算リソースへのアクセスが不足しています。
Togetherのマックス・リャビニン氏:高価なハードウェアが必要なため、研究コミュニティには大きなプレッシャーがかかります。必要な実験を行うにはコストがかかりすぎるため、ほとんどの研究者は大規模なニューラルネットワークの開発に参加できません。大規模化によってモデルのサイズを拡大し続ければ、いずれは競争できるようになるでしょう
グーグルのフランソワ・ショレ氏:大規模言語モデル(LLM)がまだ一般人工知能(AGI)を可能にしていないことは分かっています。同時に、AGIに向けた進歩も停滞しています。大規模言語モデルで私たちが直面している限界は、5年前に私たちが直面したものとまったく同じです。我々は新しいアイデアとブレークスルーを必要としている。次のブレークスルーは、外部のチームからもたらされる可能性が高いと私は考えている。 このような懸念に対して、ハードウェアの改善やクラウドの設備投資が問題を解決すると信じて懐疑的な人もいる。しかし、これは非現実的だ。ひとつには、この10年の終わりまでに、Nvidiaの次世代チップに搭載されるFLOP数は劇的に増加し、おそらく現在のH100の10倍まで増加するだろう。これにより、1FLOPあたりの価格は80~90%低下する。同様に、ネットワークや関連インフラの改善とともに、FLOP供給総量は10年後までに約20倍に増加すると予想される。これらすべてが、1ドルあたりのトレーニング効率を向上させるでしょう。
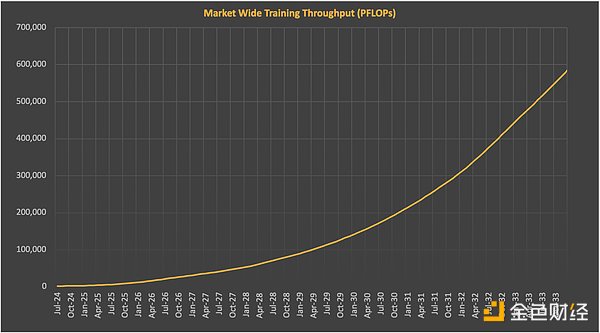
Source:SemiAnalysis AI Cloud TCO Models
一方、ラボがさらなる規模拡大を目指す中、FLOPの総需要は急増する見込みです。トレーニング計算の10年来のトレンドが維持される場合、フロンティア・トレーニングのFLOPは2030年までに約2e29に達すると予測されています。現在のトレーニングの実行時間と利用率に基づくと、この規模のトレーニングには約2,000万台のH100相当のGPUが必要になります。epochAIは、2024年までに出荷されるGPUの約50倍にあたる約1億個のH100相当GPUがその時までに必要になると予測しています。semiAnalysisも同様の予測を行っており、フロンティアトレーニングの需要とGPUの供給がこの期間でほぼ同じペースになることを示唆しています。SemiAnalysisも同様の予測を行っており、この期間中、最先端のトレーニング需要とGPU供給はほぼ同調して成長することを示唆しています。
生産能力の状況は、さまざまな理由で厳しくなる可能性があります。たとえば、製造上のボトルネックによって、よくあることですが、予測される出荷サイクルが遅れる場合です。あるいは、データセンターに電力を供給するのに十分なエネルギーを生産できなかった場合。あるいは、エネルギー源を送電網に接続するのに問題が生じた場合。あるいは、設備投資に対する監視の目が厳しくなり、業界の規模縮小を招いた場合などだ。最良のシナリオでは、現在のアプローチでは、一握りの企業だけが研究を推進し続けることができ、それだけでは十分ではないかもしれません。
新しいアプローチが必要なのは明らかだ。次のブレークスルーを見つけるためにデータセンターを常に拡張し、設備投資やエネルギー消費を行うのではなく、このアプローチは既存のインフラを効率的に利用し、需要の変動に合わせて柔軟に拡張することができる。これにより、10億ドル規模のコンピューティング予算に対する投資対効果を確保するためのトレーニングが不要になり、研究においてより多くの実験が可能になる。この制限から解放されれば、現在の大規模言語モデリング(LLM)パラダイムを超えることができる。この代替案がどのようなものかを理解するために、私たちは過去の分散コンピューティングの実践からインスピレーションを得ることができます。
SETI@homeは1999年にこのコンセプトを普及させ、何百万人もの参加者が地球外知的生命体を探すために電波信号を分析することを可能にしました。SETIは、アレシボ望遠鏡から電磁波データを収集し、それをバッチに分割してインターネット経由でユーザーに送信する。ユーザーは日常生活の中でデータを分析し、結果を送り返す。ユーザー間の通信は不要で、バッチは独立してレビューできるため、高度な並列処理が可能である。SETI@homeは最盛期には500万人以上が参加し、当時の最大級のスーパーコンピューターよりも処理能力が高かった。最終的には2020年3月に閉鎖されたが、その成功はその後のボランタリーコンピューティング運動に刺激を与えた。
Folding@homeは2000年にこのアイデアを継続し、エッジコンピューティングを使ってアルツハイマー病、癌、パーキンソン病などの病気におけるタンパク質の折りたたみをシミュレーションしている。ボランティアがパソコンの空き時間にタンパク質のシミュレーションを行い、研究者がタンパク質がどのように折り畳まれ、病気の原因となるのかを研究するのに役立っている。2000年代後半やCOVIDの際には、分散コンピューティング・プロジェクトとして初めて1エクサフロップスを超えた。設立以来、フォールディングの研究者は200以上の査読付き論文を発表しており、そのどれもがボランティアの計算能力に依存しています。
バークレー・オープン・インフラストラクチャ・フォー・ネットワークド・コンピューティング(BOINC)は、2002年にこのアイデアを普及させ、さまざまな研究プロジェクトにクラウドソーシングのコンピューティング・プラットフォームを提供しました。BOINCは、SETI@homeやFolding@homeなどのプロジェクトに加え、天体物理学、分子生物学、数学、暗号学などの分野の新しいプロジェクトもサポートしている。2024年までに、BOINCは30の進行中のプロジェクトと、その計算ネットワークを使用して生成された約1,000の出版された科学論文をリストアップしている。
科学研究以外では、ボランティア・コンピューティングは、囲碁(LeelaZero、KataGo)やチェス(Stockfish、LeelaChessZero)などのゲームエンジンを訓練するために使用されている。LeelaZeroは、2017年から2021年まで、ボランティアのコンピューティングによって訓練され、自身と1000万局以上の対局を行い、現在最強の囲碁エンジンの1つを作り上げている。同様に、Stockfishは2013年からボランティアネットワークで継続的に訓練されており、最も人気があり強力なチェスエンジンの1つとなっています。
しかし、このモデルをディープラーニングに応用できるのだろうか?世界中のエッジ デバイスをネットワーク接続して、低コストのパブリック トレーニング クラスターを作成できるでしょうか?アップルのラップトップからNvidiaのゲーミング・グラフィックス・カードに至るまで、消費者向けハードウェアはディープラーニングの性能がどんどん向上している。多くの場合、これらのデバイスは、データセンターのグラフィックカードの1ドルあたりの性能を上回ってさえいます。
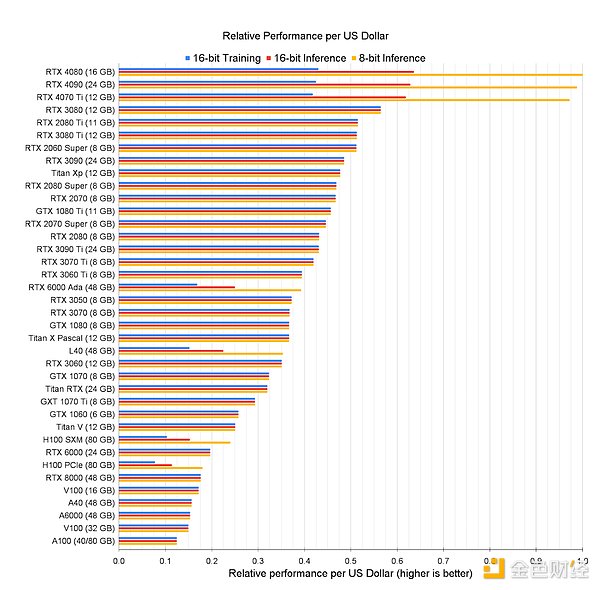
しかし、分散環境でこれらのリソースを効果的に活用するには、さまざまな課題を克服する必要があります。
第一に、現在の分散トレーニング技術は、ノード間の頻繁な通信を前提としています。
現在の最先端のモデルは、トレーニングが何千ものGPUに分割されなければならないほど大規模になっています。これは、さまざまな並列化技術によって達成され、通常、利用可能なGPU間でモデル、データセット、またはその両方を分割します。そうしないと、ノードがアイドル状態でデータの到着を待つことになります。
たとえば、分散データ並列(DDP)は、データセットをGPUに分散させ、各GPUはデータの特定のスライスで完全なモデルをトレーニングし、各ステップで新しいモデルの重みを生成するために勾配の更新を共有します。ノードは各バックプロパゲーションの後に勾配更新を共有するだけであり、集団的な通信操作は計算と部分的に重複することができるため、これは比較的限られた通信オーバーヘッドしか必要としない。しかし、このアプローチは、各 GPU がモデルの重み、活性化値、およびオプティマイザ の状態全体をメモリに格納する必要があるため、小規模なモデルにのみ適し ています。
この問題に対処するため、GPU間でモデルを分散させるためのさまざまな技術も使用しています。たとえば、テンソル並列処理では、各GPUが必要な演算を実行し、出力を他のGPUに渡すように、1つのレイヤー内の重みを分割します。これにより、各GPUのメモリ要件が削減されますが、GPU間で常に通信を行う必要があるため、効率を向上させるには広帯域幅で低遅延の接続が必要です。
パイプライン並列では、モデルのレイヤーをGPU間で分散させ、各GPUが作業を実行し、パイプライン内の次のGPUと更新を共有します。これはテンソル並列よりも少ない通信で済みますが、パイプラインの後方にあるGPUが作業を開始するために、その前にあるGPUからの情報を待つ「バブル」(アイドル時間など)が発生する可能性があります。
これらの課題に対処するために、さまざまな技術が開発されてきました。たとえば、ZeRO (Zero Redundancy Optimiser) は、より大きなモデルを特定のデバイスで学習できるように、通信オーバーヘッドを増加させることでメモリ使用量を削減するメモリ最適化手法です。ZeROは、GPU間でモデルパラメータ、勾配、およびオプティマイザの状態を分割することでメモリ要件を削減しますが、デバイスが分割されたデータにアクセスできるようにするために大量の通信に依存します。これは、FSDP (Fully Sliced Data Parallelism)やDeepSpeedのような一般的な手法の基礎となる方法論です。
これらの技術は、リソースの利用効率を最大化するために、大規模なモデル学習で組み合わせて使用されることが多く、3次元並列と呼ばれています。この構成では、分割された各レイヤー間で大量の通信が必要となるため、1つのサーバー内のGPU間で重みを分散させるためにテンソル並列が一般的に使用されます。次に、パイプライン並列は、通信量が少なくて済むため、異なるサーバー間(ただし、データセンターの同じ島内)でレイヤーを分散させるために使用されます。次に、データ並列または完全スライスデータ並列(FSDP)が、異なるサーバーのアイランド間でデータセットを分割するために使用されます。これは、更新を非同期で共有したり、勾配を圧縮したりすることで、より長いネットワーク遅延に対応することができるからです。
これらのアプローチは、(より低速で不安定な)コンシューマーグレードのインターネットを介して接続されたデバイスに依存する分散型トレーニングネットワークに中心的な課題を提示します。このような環境では、通信コストがエッジコンピューティングのメリットをすぐに上回ってしまいます。10億個のパラメータを持つ半精度モデルの分散データ並列トレーニングの簡単な例で説明すると、各GPUは最適化ステップごとに2GBのデータを共有する必要があります。一般的なインターネットの帯域幅(例えば毎秒1ギガビット)で、計算と通信が重複しないと仮定すると、勾配の更新を送信するのに少なくとも16秒かかり、かなりのアイドル時間が発生します。より多くの通信を必要とするテンソル並列のような技術は、もちろんさらにパフォーマンスが悪くなります。
第二に、現在のトレーニング技術には耐障害性がない。他の分散システムと同様に、トレーニングクラスタは規模が大きくなるにつれて故障しやすくなります。しかし、現在の技術ではGPUがほぼ同期的に動作するため、トレーニングにおいてこの問題はさらに悪化します。何千ものGPUのうち1つのGPUが故障すると、トレーニングプロセス全体が停止し、他のGPUはゼロからトレーニングを開始せざるを得なくなります。GPUが完全に故障するのではなく、さまざまな理由で動作が鈍くなり、クラスタ内の他の何千ものGPUの動作が遅くなるケースもあります。今日のクラスターの規模を考えると、これは数千万ドルから数億ドルの追加コストを意味します。
Metaは、Llamaのトレーニング中にこれらの問題について詳しく説明しました。そこでは、1日平均約8回、400回以上の計画外の停止が発生しました。これらの中断は、主にGPUやホストのハードウェア障害など、ハードウェアの問題に起因していた。GPT-4トレーニング中のOpenAIのパフォーマンスはさらに悪く、32-36%でした。
言い換えれば、最先端のラボは、均質で最先端のハードウェア、ネットワーク、電力、冷却システムを備えた完全に最適化された環境でトレーニングを行っても、40%の利用率を達成するのに苦労しているということです。これは主にハードウェアの故障とネットワークの問題によるもので、処理能力、帯域幅、レイテンシ、信頼性の点でデバイスにばらつきがあるエッジトレーニング環境ではさらに悪化する。言うまでもなく、分散型ネットワークは、さまざまな理由でプロジェクト全体を妨害したり、特定のワークロードを不正に利用しようとしたりする悪意のあるアクターに対して脆弱である。純粋なボランティア・ネットワークであるSETI@homeでさえ、さまざまな参加者による不正行為を見てきました。
第三に、最先端のモデルトレーニングには膨大な計算能力が必要です。GPT-4は20,000台のA100のクラスタ上で訓練され、ピーク時のスループットは半精度で6.28ExaFLOPSでした。Llama 405bは16,000台のH100で学習され、ピーク時のスループットは15.8ExaFLOPSで、Foldingのピーク時の7倍である。
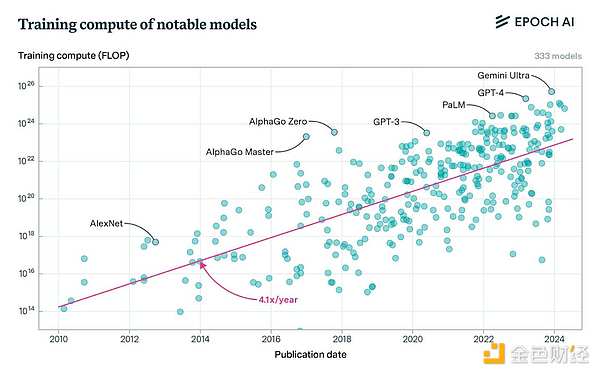
@home プロジェクトはボランティア主導であるため、これは理にかなっています。貢献者はメモリとプロセッササイクルを寄付し、関連コストを負担します。このため、当然ながら商用プロジェクトと比較して規模が制限されます。
これらの問題は、歴史的に分散型トレーニングの取り組みを苦しめてきましたが、もはや克服できないようには見えません。ノード間の通信の必要性を減らし、インターネットに接続されたデバイスでの効率的なトレーニングを可能にする新しいトレーニング技術が登場しました。これらの技術の多くは、モデルトレーニングの規模を拡大しようとしている大規模ラボから生まれたものであり、データセンター間の効率的な通信技術を必要としている。また、エッジ環境での大規模なトレーニングをサポートできる、フォールトトレラントトレーニングメソッドや暗号化システムも進歩しています。
DiLoCoはGoogleの最近の研究です。通信オーバーヘッドを削減している。彼らのアプローチ(以前の連合学習研究に基づく)は、ノード間の通信を500分の1に削減しながら、従来の同期学習と同等の結果を示した。その後、この手法は他の研究者たちによって再現され、より大規模なモデル(10億以上のパラメータ)を学習するために拡張された。また、非同期トレーニングにも拡張されており、ノードは勾配の更新を一度に行うのではなく、異なるタイミングで共有することができる。これは、処理能力やネットワーク速度が異なるエッジハードウェアによりよく対応することを意味します。
lo-fiやDisTrOなどの他のデータ並列アプローチは、通信コストをさらに削減することを目的としています。lo-fiは、ノードが独立して訓練され、重みが最後に渡されるだけであることを意味する、完全にローカルな微調整を提案しています。このアプローチでは、10億以上のパラメーターを持つ言語モデルを微調整する際に、通信のオーバーヘッドを完全に排除しながら、ベンチマークに匹敵する性能を発揮する。予備報告では、DisTrOは新しい分散オプティマイザを採用し、通信要件を4~5桁削減できると主張しているが、このアプローチはまだ確認されていない。
モデル並列化への新しいアプローチも登場し、より大きなスケールを達成することが可能になりました。DiPaCo(同じくグーグル)は、モデルをモジュールに分割し、それぞれのモジュールには、特定のタスクに関するトレーニング用の異なるエキスパートモジュールが含まれています。トレーニングデータは、各データサンプルに対応するエキスパートのシーケンスである「パス」を通してスライスされる。スライスが与えられた場合、各ワーカーは、モジュールを共有するために必要な通信を除いて、ほぼ独立して特定のパスを訓練することができる。このアーキテクチャにより、10億パラメータモデルの訓練時間が半分以下に短縮されます。
SWARM Parallelism and Decentralised Training of Foundation Models in Heterogeneous Environments (DTFMHE)もまた、異種環境における大規模モデルのトレーニングを可能にするモデル並列性を提案しています。SWARMは、パイプライン並列通信制約がモデルサイズが大きくなるにつれて減少することを発見しました。このアイデアを異種環境で適用するために、SWARMは、各反復でリアルタイムに更新できるノード間の一時的な「パイプライン接続」を使用している。これにより、ノードは次のパイプライン・ステージのピアノードに出力を送信することができる。つまり、1つのピアノードが他のピアノードよりも高速であったり、参加者の誰かが切断したりしても、各ステージに少なくとも1人のアクティブな参加者がいる限り、トレーニングが継続されるように出力を動的に再ルーティングすることができる。彼らはこのアプローチを使って、低速の相互接続を持つ低コストのヘテロジニアスGPU上で10億を超えるパラメーターを持つモデルを訓練しました(下図)。
DTFMHEも同様に、パイプライン並列性とデータ並列性だけでなく、新しいスケジューリングアルゴリズムを提案し、3大陸にまたがるデバイス上で大規模モデルを訓練しました。DTFMHEのネットワークは標準的なDeepspeedよりも100倍低速ですが、データセンターで標準的なDeepspeedを使用するよりも1.7~3.5倍低速です。SWARMと同様に、DTFMHEは、地理的に分散したネットワークであっても、モデルサイズが大きくなるにつれて通信コストを効果的に隠蔽できることを示している。これにより、隠れ層のサイズを大きくしたり、パイプラインステージごとに層を増やすなど、さまざまな手法でノード間の接続の弱さを克服することができます。
上述のデータ並列アプローチの多くは、各ノードがモデル全体をメモリに保存するため、デフォルトでフォールトトレランスです。この冗長性は通常、他のノードが故障してもノードが独立して動作できることを意味する。ノードはしばしば信頼性に欠け、異質であり、悪意を持って行動する可能性さえあるため、これは分散型トレーニングにとって重要である。しかし、前述したように、データのみの並列手法はより小さなモデルにしか適していないため、モデルサイズはネットワーク内の最小ノードのメモリ容量によって制約されます。
上記の問題に対処するために、モデル並列(またはハイブリッド並列)トレーニングに適したフォールトトレラント技術を提案しているものがあります。SWARMは、レイテンシの低い安定したピアノードを優先し、障害が発生した場合はパイプラインフェーズでタスクを再ルーティングすることで、ピアノードの障害に対応します。Oobleckのような他のアプローチでは、複数の「パイプラインテンプレート」を作成することで、部分的なノード障害に対応する冗長性を提供し、同様のアプローチをとっている。データセンターでテストされていますが、Oobleckのアプローチは、分散環境にも同様に適用できる強力な信頼性保証を提供します。
また、分散環境でのフォールトトレラントなトレーニングをサポートするDecentralised Mixture of Experts(DMoE)モデルのような新しいモデルアーキテクチャも見られます。DMoEは、分散ハッシュテーブルを使用して、非同期更新を分散的に追跡し、統合する。DMoEは、分散ハッシュテーブルを使用して、非同期更新を追跡し、分散的に統合します。このメカニズム(SWARMでも使用)は、一部のノードが故障したり、タイムリーに応答できなかったりした場合に、特定のエキスパートを平均化計算から除外することができるため、ノードの故障に対して堅牢です。
最後に、ビットコインやイーサで採用されているような暗号インセンティブシステムは、必要なスケールを達成するのに役立ちます。これら2つのネットワークは、普及が進むにつれて価値が上がるローカル資産を貢献者に支払うことで、計算をクラウドソーシングしている。この設計では、初期の貢献者に手厚い報酬を与えることでインセンティブを与え、ネットワークが実行可能な最小規模に達すると、その報酬を徐々に減らすことができる。
この仕組みには、避けなければならないさまざまな落とし穴があるのは事実だ。こうした落とし穴の最たるものは、供給に過度のインセンティブを与えながら、それに見合った需要を生み出せないことだ。さらに、基盤となるネットワークが十分に分散化されていない場合、規制上の問題が生じる可能性もある。しかし、適切に設計されていれば、分散型インセンティブ・システムは長期にわたって大きな規模を達成することができる。
例えば、ビットコインの年間消費電力は約150テラワット時(TWh)であり、これは現在考えられている最大のAIトレーニングクラスターの消費電力(10万台のH100が1年間フル稼働)よりも2桁高い。参考までに、OpenAIのGPT-4は20,000台のA100で学習し、Metaの主要モデルLlama 405Bは16,000台のH100で学習した。同様に、イーサネットはピーク時に約70TWhの電力を消費し、数百万のGPUに分散している。今後数年間でAIデータセンターが急速に成長することを考慮しても、このようなインセンティブ・コンピューティング・ネットワークは、その規模を何倍も上回るでしょう。
もちろん、すべての計算がカンタンにできるわけではありませんし、トレーニングには、マイニングと比較して考慮すべき独自のニーズがあります。それにもかかわらず、これらのネットワークは、これらのメカニズムによって達成できるスケールを示しています。
これらの断片をつなぎ合わせると、新しい道の始まりが見えてきます。
間もなく、新しいトレーニング技術により、デバイスが有用であるために共同配置する必要がなくなり、データセンターの枠を超えることができるようになります。現在の分散型トレーニング手法はまだ比較的小規模で、主に10億から20億のパラメーターの範囲であり、GPT-4のようなモデルよりもはるかに小さいため、これには時間がかかるだろう。通信効率や耐障害性といった重要な特性を犠牲にすることなく、これらの手法の規模を拡大するには、さらなるブレークスルーが必要だ。あるいは、今日の大規模なモノリシック・モデルとは異なる新しいモデル・アーキテクチャが必要です。おそらく、より小さく、よりモジュール化され、クラウドではなくエッジ・デバイス上で実行されます
いずれにせよ、この方向でのさらなる進歩を期待するのは妥当なことです。さらなる進歩がなされるでしょう。現在のアプローチのコストは持続不可能であり、イノベーションのための強力な市場インセンティブとなります。アップルのようなメーカーは、クラウドに依存するのではなくローカルでより多くのワークロードを実行するため、より強力なエッジデバイスを製造している。また、より分散化された研究開発を促進するために、メタのような企業内でもオープンソース・ソリューションへの支持が高まっている。このような傾向は、時間の経過とともに加速していくでしょう。
同時に、エッジでデバイスを使用できるように接続するための新しいネットワークインフラが必要になります。これらのデバイスには、ラップトップやゲーミングデスクトップ、そして最終的には高性能グラフィックカードと大容量のRAMを搭載した携帯電話も含まれます。これによって、トレーニングタスクを並行して処理できる、低コストで常時稼働のコンピューティングパワーの「グローバルクラスタ」を構築できるようになる。これはまた、複数の分野での進歩を必要とする挑戦的な問題でもある。
異種環境におけるトレーニングのための、より優れたスケジューリング技術が必要です。特に、デバイスがいつでも切断されたり接続されたりする可能性がある場合、最適化のためにモデルを自動的に並列化する方法は今のところありません。これは、エッジベースのネットワークのスケールメリットを維持しながらトレーニングを最適化するための重要な次のステップです。
分散型ネットワークの一般的な複雑さにも対処しなければなりません。スケールを最大化するために、ネットワークはオープンプロトコルとして構築されるべきです。TCP/IPのような、参加者間の相互作用を規定する標準と命令のセットですが、機械学習コンピューティングのためのものです。これにより、特定の仕様に従ったデバイスであれば、所有者や場所に関係なくネットワークに接続できるようになる。また、ネットワークが中立であることも保証されるため、ユーザーは好みのモデルをトレーニングすることができます。
これはスケールを最大化する一方で、単一のエンティティに依存することなく、すべてのトレーニングタスクの正しさを検証するメカニズムも必要となります。例えば、報酬を得るために特定のトレーニング課題を完了したと主張するが、実際には行っていないなど、不正を行うインセンティブが内在しているため、これは非常に重要である。これは、異なるデバイスが異なる方法で機械学習操作を実行することが多く、標準的な複製技術を使用して正しさを検証することが困難であることを考えると、特に困難である。この問題を正しく解決するには、暗号学やその他の学問分野での深い研究が必要です。
幸いなことに、私たちはこれらすべての面で進歩を続けています。過去数年に比べれば、課題はもはや乗り越えられないものではありません。また、GoogleがDiPaCoの論文で最もよく要約しているように、分散型トレーニングが破壊する可能性のある負のフィードバックメカニズムを指摘しています。
機械学習モデルのトレーニングを分散させることの進歩は、インフラの簡素化につながり、最終的にはコンピューティングリソースのより広い利用可能性につながる可能性があります。計算資源の利用可能性の拡大。現在、インフラストラクチャーは、大規模でモノリシックなモデルをトレーニングするための標準的な方法を中心に設計されており、機械学習モデルのアーキテクチャは、現在のインフラストラクチャーとトレーニング方法を活用するように設計されている。このフィードバックループは、実際に必要とされる以上に計算リソースが制約される、誤解を招くローカルミニマムにコミュニティを陥れる可能性があります。
おそらく最もエキサイティングなことに、研究コミュニティではこれらの問題に取り組む熱意が高まっています。ジェンシンの私たちのチームは、上記のサイバーインフラを構築しています。HivemindやBigScienceのようなチームは、これらのテクニックの多くを実際に適用している。Petals、sahajBERT、Bloomのようなプロジェクトは、これらのテクニックのパワーと、コミュニティベースの機械学習への関心の高まりを実証している。その他にも、よりオープンで協調的なモデル学習エコシステムを構築することを目標に、研究を推進している多くの人々がいる。この研究に興味がある方は、ぜひ私たちにご連絡ください。
ガイがETHを選んだのは、イーサネット・ネットワークがネイティブな収益を提供してくれるからだ。
JinseFinance4月15日から16日にかけて、国際フォーラム「ブロックチェーン・ライフ2024」がドバイで開催される。
 Joy
Joy91Pornの公式ツイートによれば、AVAVは間もなくBitget Innovation Zoneで取引される。
 铭文老幺
铭文老幺SolanaのSaga携帯電話によるBONKトークンのプレゼントは、携帯電話の販売価格を驚くほど上回り、需要と市場評価の急上昇に火をつけ、不安定な暗号技術の相乗効果を示している。
 Alex
Alex Coinlive
Coinlive 世論調査は、エルサルバドルの有力な野党新聞の 1 つから行われ、「ビットコイン大統領」からの自画自賛のツイートを促しました。
 CryptoSlate
CryptoSlateMeta の Reality Labs は昨年第 4 四半期に収益の 17% を失ったにもかかわらず、Meta は中国のソフトウェア会社 Tencent に Meta Quest VR ヘッドセットの販売を依頼しました。
 Beincrypto
Beincrypto Nulltx
Nulltx水曜日の時点で提案に対する圧倒的な承認にもかかわらず、ソーシャル メディアの多くの Terra ユーザーは、ネットワークがその LUNA トークンをバーンすることを提案しました。
 Cointelegraph
Cointelegraphコインテレグラフ フランスの公式発表は、ヨーロッパの主要なブロックチェーン イベントであるパリ ブロックチェーン ウィーク サミットで行われます。
Cointelegraph