가챠 게임과 NFT의 차이점
<nil>
 Chris
Chris

네트워킹은 AI 빅 모델 시대의 핵심 요소입니다. 빅 모델 시대에 접어들면서 광 모듈, 스위치 등 네트워크 장비의 반복이 가속화되고 수요가 폭발적으로 증가하기 시작했습니다. 그러나 시장은 왜 그래픽 카드가 많은 수의 광 모듈과 짝을 이루어야 하는지, 왜 통신이 대형 모델의 문제점이 되었는지에 대한 인식이 얕습니다. 이 기사에서는 AI 시대에 네트워크가 새로운 'C 포지션'이 된 이유에 대한 원칙에서 시작하여 최신 산업 변화의 이면에 있는 네트워크 측면의 혁신과 투자 기회에 대한 미래에 대해 논의할 것입니다.
네트워킹에 대한 수요는 어디에서 오는가? 대형 모델 시대에 모델 크기와 단일 카드 캡 간의 격차가 빠르게 벌어지고 있으며, 업계는 모델 학습 문제를 해결하기 위해 멀티 서버 클러스터로 전환하고 있으며, 이는 AI 시대 네트워크 '업'의 기반이 되고 있습니다. 동시에, 순전히 데이터 전송을 위한 과거에 비해 오늘날의 네트워크는 그래픽 카드 간의 모델 매개 변수를 동기화하는 데 더 많이 사용되며 네트워크의 밀도, 네트워크의 용량은 더 높은 요구 사항을 제시했습니다.
모델 볼륨 증가: (1) 훈련 시간 = 훈련 데이터 크기 x 모델 파라미터 수/계산 속도 (2) 계산 속도 = 단일 장치 계산 속도 x 장치 수 x 다중 장치 병렬처리 효율성. 이제 업계에서는 훈련 데이터 크기와 파라미터를 이중으로 추구하기 위해 계산 효율을 높여 훈련 시간을 단축하는 방법과 단일 장치 계산 속도 업데이트에는 주기와 한계가 있으므로 네트워크를 최대한 활용하여 '장치 수'와 '병렬 효율성'을 확장하는 방법이 산술을 직접적으로 결정합니다. 이 과정의 첫 번째 단계는 네트워크를 최대한 많이 사용할 수 있는지 확인하는 것입니다.
다중 카드 동기화의 복잡성: 대규모 모델 훈련 중에 모델을 개별 카드로 슬라이스하고 다이싱하려면 각 계산에 대해 카드 간 정렬(Reduce, Gather 등)을 해야 합니다. 올투올(모든 노드가 서로의 값에 액세스하고 정렬된 상태) 연산은 NVIDIA의 통신 프리미티브 시스템인 NCCL에서 더 일반적이므로 네트워크 간 전송 및 교환에 대한 요구가 더 높습니다.
고비용이 증가하는 장애 비용: 대규모 모델의 훈련은 종종 수개월 이상 지속되며, 중간에 중단되면 몇 시간 또는 며칠 전의 중단점으로 돌아가 다시 훈련해야 합니다. 또한 전체 네트워크에서 단일 하드웨어 또는 소프트웨어 링크에 장애가 발생하거나 지연 시간이 과도하게 길어지면 중단이 발생할 수 있습니다. 중단이 많을수록 진행이 지연되고 비용이 증가합니다. 현대 AI 네트워크는 항공기, 항공모함 등에 필적하는 인간 시스템 엔지니어링 능력의 정점으로 점차 진화하고 있습니다.
네트워크 혁신은 어디로 향하고 있을까요? 하드웨어는 수요에 따라 움직이며, 2년이 지난 지금 전 세계 산술적 투자 규모는 수백억 달러 수준으로 불어났고, 모델 파라미터의 확장, 비극적인 싸움의 거인들은 여전히 치열합니다. 오늘날 비용 절감, 개방성, 규모 사이의 균형은 네트워크 혁신의 주요 이슈가 될 것입니다.
통신 매체 반복: 광, 구리, 실리콘은 인간 전송의 3대 매체로, AI 시대에는 광 모듈이 더 빠른 속도를 추구하는 동시에 LPO, LRO, 실리콘 광학 등 비용 절감을 위한 조치를 취하고 있습니다. 현재 구리는 비용 효율성, 고장률 및 기타 요인으로 인해 캐비닛 내 연결성을 대신하고 있습니다. 그리고 칩렛, 웨이퍼 스케일링 등과 같은 새로운 반도체 기술은 실리콘 기반 인터커넥트의 상한선 탐구를 가속화하고 있습니다.
네트워크 프로토콜 경쟁: 칩 간 통신 프로토콜은 단일 서버 또는 단일 연산 노드의 성능을 결정하는 NVIDIA의 NV-LINK, AMD의 Infinity &;Fabric 등과 같은 그래픽 카드와 밀접하게 연관되어 있습니다. 상한을 결정하는 매우 잔인한 거대한 전쟁터입니다. 그리고 IB와 이더넷 간의 투쟁은 노드 간 통신의 주요 주제입니다.
네트워크 아키텍처의 변화: 현재 노드 간 네트워크 아키텍처는 편리하고 간단하며 안정적인 리프-리지 아키텍처에서 일반적으로 사용됩니다. 그러나 단일 클러스터의 노드 수가 증가함에 따라 리프-리지의 약간 중복적인 아키텍처는 매우 큰 클러스터에 더 큰 네트워크 비용을 초래합니다. 오늘날에는 드래곤플라이와 레일 전용 아키텍처와 같은 새로운 아키텍처가 차세대 메가 클러스터의 진화 방향이 될 것으로 예상됩니다.
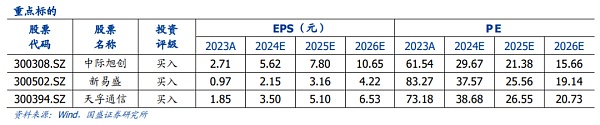
투자 조언: 통신 시스템 핵심 링크:국제 쉬촹, 새로운 이순, 티안푸 통신, 산업 풀리안, 인벡, 후뎬 주식. 통신통신 시스템 혁신 링크:창페이 광섬유, 타이청광, 위안지에 과학기술, 셩커 커뮤니케이션-U, 캄브리아기, 데켈리.
리스크 팁: 예상보다 적은 AI 수요, 스케일링법 실패, 업계 경쟁 심화


1< strong>. 투자 필수 요소
시장은 AI 학습에서 통신 네트워크의 중요성을 과소평가하고 있습니다. AI 시장은 산업 체인 로직에서 네트워크 산업 체인 연구에 더 집중하기 때문에 주요 연구 방향은 네트워크 아키텍처의 각 세대에 필요한 광 모듈의 수와 산업 체인의 각 링크의 생산 및 성능 측정의 기초로 집중하지만 연구 간의 기본 관계의 AI와 통신 시장은 적습니다. 이 논문에서는 모델, 다중 카드 동기화, 비용 효율적인 교육 및 기타 세 가지 측면에서 AI 시대에 통신 네트워크의 핵심 위치에 대해보다 심층적으로 논의합니다.
요약하면, AI 시대에 통신이 C 위치에 서는 이유는 크게 세 가지로 요약할 수 있습니다. 첫째, 점점 더 커지는 모델 볼륨과 그래픽 카드 수, 연결의 컴퓨팅 효율이 학습에 필요한 시간을 직접적으로 결정하며, 갈수록 치열해지는 거대 AI의 경쟁에서 시간은 가장 소중한 자원입니다. 둘째, 훈련의 원칙에서 모델 병렬 처리에서 데이터 병렬 처리에 이르는 주류 병렬 모드에서 각 컴퓨팅 계층이 서로 다른 NPU간에 클러스터링되어 기존 매개 변수, 정렬 프로세스의 수천 칩 시간을 정렬하여 네트워크의 매우 높은 요구 사항 인 낮은 지연 시간과 정확성을 보장해야합니다. 셋째, 네트워크 장애 비용은 매우 높으며, 현재 모델 학습 시간은 종종 몇 달 동안 지속되며, 아카이브 지점 몇 시간 전에 다시 보관하더라도 더 많은 실패 또는 중단이 발생하면 전체 학습 효율성과 비용이 거대한 AI 제품 반복의 분과 초에 더 치명적인 큰 손실을 초래할 수 있습니다. 동시에 클러스터 크기가 이미 최대 10,000개에 달하고 연결된 구성 요소가 수십만 개에 달할 수 있는 경우, 이러한 구성 요소의 전반적인 안정성과 수율을 보장하는 방법은 매우 심오한 시스템 엔지니어링이 되었습니다.
시장통신 네트워크의 미래 반복에 대한 인식 부족. 통신 네트워크의 반복에 대한 시장의 이해는 그래픽 카드 교체에 따른 연구 수준에 머물러 있습니다. 우리는 하드웨어 반복으로 인한 업데이트의 주기와 방향은 비교적 고정되어 있지만 나머지 반복의 방향과 산업 체인의 혁신 정도는 날로 증가하고 있다고 믿습니다. 동시에 현재 AI 자본 투자 전쟁의 해외 거인은 수백억 달러 수준에 도달했으며 모델 매개 변수의 확장, 비극적 인 싸움의 거인은 여전히 치열합니다. 앞으로 '비용 절감', '개방성', 산술적 규모 사이의 균형이 네트워크 혁신의 주요 화두가 될 것입니다.
전반적으로 산업 체인의 개척은 주로 세 가지 방향에 초점을 맞추고 있습니다. 첫째, 통신 매체 반복으로, 여기에는 광, 구리, 실리콘 기판의 공통적인 발전과 LPO, LRO, 실리콘 광학, 칩렛, 웨이퍼 스케일링 등 다양한 매체 내 기술 혁신이 포함됩니다. 둘째, 통신 프로토콜 혁신은 또한 두 가지 측면을 포함하는데, 첫째, 노드 내부 통신은 NVLINK 및 Infinity Fabric과 같은 장벽과 혁신의 분야가 매우 어렵고 거인의 전쟁터에 속하며 둘째, 노드 간 통신은 업계가 주로 두 가지 주요 프로토콜 인 IB와 이더넷의 경쟁에 집중하고 있습니다. 셋째, 네트워크 아키텍처 업데이트, 리프 릿지 아키텍처가 초다수 노드에 적응할 수 있는지, OCS의 도움으로 드랭곤플라이가 차세대 네트워크 아키텍처의 주류가 될 수 있는지, Rail-only+ 소프트웨어 최적화가 성숙될 수 있는지 등이 모두 업계의 새로운 관점입니다.
산업 촉매제 :
1. 확장 법칙이 계속 유효하며 통신 네트워크 수요 확대로 클러스터의 규모가 계속 증가하고 있습니다.
2. 해외 AI의 사이클이 가속화되고 있으며 인터넷 대기업의 자본 지출 경쟁이 가속화되고 있습니다.
투자 조언: 통신 시스템의 핵심 연결고리 : 중개자 Xutron, 새로운 Yisheng, Tianfu 통신, Hudian 주식.
통신 시스템 혁신 링크: 창페이 광섬유, 중톈 과학기술, 헝퉁 광전자, 셩커 커뮤니케이션.
2.클라우드 컴퓨팅 시대에서 AI 시대로, 커뮤니케이션이 점점 더 중요해지는 이유
이전 라운드 통신의 영광은 네트워크 트래픽 전송에 대한 폭발적인 수요로 인해 인류가 처음으로 대량의 서버, 스토리지, 스위치로 구성된 스위칭 시스템을 구축할 수 있었던 인터넷 시대로 거슬러 올라갑니다. 이 구축 과정에서 시스코는 인류 기술 발전의 선두주자로 홀로 우뚝 섰습니다. 그러나 인터넷 물결이 진정되는 경향에 따라 광 모듈 및 스위치는 거시 경제, 클라우드 지출 및 제품 업데이트 및 변동에 더 많이 편향되고 거시 경제 품종에 더 편향되고 속도, 기술의 반복도 더 단계적으로 변동주기 상승 정상 상태 개발 기간으로 이동합니다.
소형 모델 시대에는 업계가 알고리즘 혁신에 더 집중하고 단일 카드, 단일 서버 또는 비교적 단순한 소규모 클러스터로 전체 모델 볼륨을 감당할 수 있으므로 AI 측면의 네트워크 연결 요구가 두드러지지 않는 경우가 많았습니다. 그러나 대형 모델의 출현으로 모든 것이 바뀌었고, OpenAI는 현재 더 간단한 트랜스포머 알고리즘을 통해 더 나은 모델 성능의 형태로 매개 변수를 쌓아 전체 산업이 급속한 발전의 모델 볼륨을 가속화하는 기간에 접어 들었습니다.
먼저 모델의 계산 속도를 결정하는 두 가지 기본 공식을 살펴봄으로써 산술 규모 또는 산술 하드웨어 산업 체인이 대형 모델 시대에 가장 먼저 혜택을 받게 되는 이유를 더 잘 이해할 수 있습니다.
(1) 훈련 시간=훈련 데이터 크기 x 모델 파라미터 수/계산 속도
(2) 계산 속도=단일 장치 계산 속도 x 장치 수 x 다중 장치 병렬 효율성
(2) 계산 속도 = 단일 장치 계산 속도 x 장치. 수 x 다중 장치 병렬 효율
현재 대형 모델 시대에는 훈련 시간 소비의 분자 끝에있는 두 가지 요소가 동시에 확장되고 있으며, 일정한 산술 능력의 경우 훈련 시간 소비가 기하 급수적으로 길어지고 점점 더 치열한 거대 모델의 전장에서 시간은 가장 귀중한 자원입니다. 따라서 경쟁의 길은 분명합니다. 스택을 가속화하는 유일한 방법은 힘을 쌓는 것입니다.
두 번째 공식에서 우리는 오늘날 점점 더 확장되는 산술에서 모델 볼륨으로 인한 단일 카드 산술, 칩 업데이트의 상한, 비율의 산술 구성에서 전체에서 링 중 하나로 저하되고 그래픽 카드 수와 다중 장치 병렬 처리의 효율성도 똑같이 중요한 두 가지 링크가되었음을 알 수 있습니다. 엔비디아가 멜라녹스를 미래 지향적으로 인수한 이유는 컴퓨팅 속도를 결정하는 모든 요소에서 선두를 차지하기 위해서입니다.
이전 보고서인 "AI 산술의 ASIC 경로 - 이더 채굴기를 시작으로"에서 단일 카드 산술에 이르는 여러 경로를 자세히 설명했으며, 이 기사에서는 다루지 않겠지만 후자의 두 가지, 즉 장치 수와 다중 장치 병렬화의 효율성은 단순히 그래픽 카드 수를 쌓는 것으로 달성되지 않는다는 것을 알 수 있었습니다. 장치 수가 많을수록 네트워크 구조의 신뢰도가 기하급수적으로 증가하고 병렬 연산에 필요한 최적화 정도가 기하급수적으로 증가하기 때문에 네트워크가 AI의 주요 병목 현상 중 하나인 것입니다. 이 섹션에서는 트레이닝의 원리를 살펴보고 디바이스의 적층과 병렬 판매의 증가가 인류 역사상 가장 복잡한 시스템 프로젝트인 이유를 설명하겠습니다.
2.1빅 모델, 모델 병렬화 및 데이터 병렬화 시대의 멀티 카드 협업 원칙
모델에서 모델 훈련에서 모델을 여러 개의 카드로 분할하는 과정은 기존의 파이프라이닝이나 단순 분할처럼 간단하지 않고, 그래픽 카드 간에 작업을 분배하는 보다 복잡한 방식입니다. 전반적으로 작업 할당에는 크게 모델 병렬화와 데이터 병렬화라는 두 가지 접근 방식이 있습니다.
모델 크기는 작지만 데이터 양이 증가하던 초창기에는 데이터 병렬화가 일반적으로 사용되었습니다. 데이터 병렬 컴퓨팅에서는 모델의 전체 복사본을 각 GPU에 보관하고 학습용 데이터를 여러 그래픽 카드로 분할하여 학습한 후 역전파를 통해 각 카드의 모델 복사본의 기울기를 동시에 줄여나가는 방식입니다. 그러나 모델 파라미터 인플레이션으로 인해 단일 그래픽 카드가 전체 모델을 수용하기가 점점 더 어려워짐에 따라, 헤드 크기의 모델 학습을 위한 단일 병렬 할당으로 데이터 병렬성이 감소하고 있습니다.
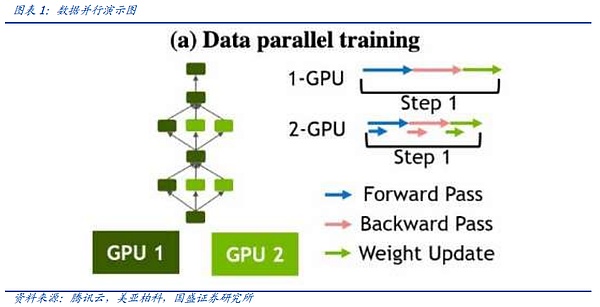
모델 병렬화는 빅 모델 시대에 새롭게 떠오르는 배포 방식입니다. 모델 병렬화는 대형 모델 시대에 떠오르는 배포 방식입니다. 모델이 매우 크기 때문에 모델의 여러 부분을 그래픽 카드에 로드하고 카드에 동일한 데이터 스트림을 공급하여 각 부분의 파라미터를 학습시킵니다.
모델 병렬 처리에는 텐서 병렬 처리와 파이프라인 병렬 처리라는 두 가지 주요 모델이 있습니다. 모델 훈련 연산의 기본 연산 행렬 곱셈(C=AxB)에서 텐서 병렬화는 먼저 B 행렬을 여러 개의 벡터로 분할하고 각 장치가 벡터를 보유한 다음 A 행렬에 이러한 각 벡터를 개별적으로 곱한 다음 결과를 합산하여 C 리프트를 요약하는 것을 의미합니다.
반면 파이프라인 병렬화는 모델을 레이어별로 분할하여 각 조각을 단일 장치에 부여하여 수행하며, 순방향 전파 중에 각 장치는 중간 활성화를 다음 단계로 전달하고 후속 역전파 중에 각 장치는 입력 텐서의 기울기를 이전 파이프라인 단계로 다시 전달합니다. 이전 파이프라인 단계로 전달됩니다.
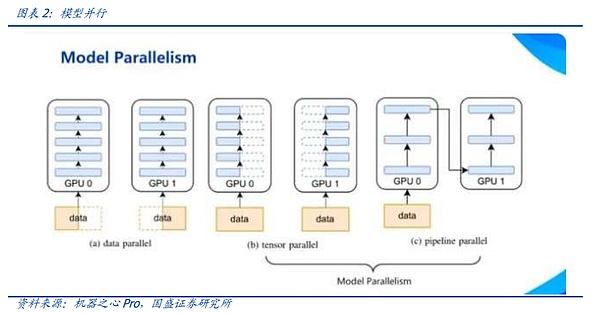
오늘날의 빅 모델 훈련에서는 어떤 종류의 데이터 병렬화는 단독으로 존재할 수 없으며, 헤드 빅 모델 학습에서는 다차원 하이브리드 병렬화를 달성하기 위해 위에서 언급한 여러 기술을 혼합해야 하는 경우가 많습니다. 실제 연결에서 이 AI 클러스터는 여러 단계로 나뉘며 각 단계는 논리적 배치에 해당하고 각 단계는 여러 GPU 노드로 구성됩니다. 이는 구조적으로 다차원 하이브리드 병렬 처리의 필요성을 충족합니다.
병렬화가 무엇이든, 각 계산 라운드에서 수행되어야 합니다.
2.2 빅 모델 시대의 멀티카드 상호 연결의 핵심: 동기화 정확도
AI 네트워크 클러스터가 수행하는 중요한 기능은 컴퓨팅 유닛 간 분업이 다른 여러 그래픽 카드에서 수행한 학습 결과를 정렬하여 그래픽 카드가 다음 단계를 수행할 수 있도록 하는 것으로, 이 작업을 역방향 방송이라고도 하며, 방송 프로세스는 종종 Reduce, Gather 등과 같은 알고리즘을 사용하여 결과를 처리하는 데 사용되며, 글로벌 방송은 올투올(All to All) 방송이라고 합니다. AI 클러스터 성능 지표에서 흔히 볼 수 있는 올투올 지연 시간은 글로벌 역방향 브로드캐스트를 수행하는 데 걸리는 시간을 의미합니다.
원칙적으로는 각 그래픽 카드에서 데이터를 주고받기만 하면 데이터를 동기화하는 리버스 브로드캐스트가 더 쉬워 보이지만 실제 네트워크 클러스터 구축에는 많은 문제가 있기 때문에 다양한 네트워크 솔루션에서 이 지연 시간을 줄이는 데 주력하고 있습니다.
첫 번째 문제는 각 그래픽 카드가 현재 연산을 완료하는 데 걸리는 시간이 일정하지 않고, 같은 그룹의 마지막 그래픽 카드가 작업을 완료할 때까지 기다렸다가 역전송하면 첫 단계에서 작업을 완료한 그래픽 카드가 유휴 상태로 있는 시간이 많아져 전체 컴퓨팅 클러스터의 성능이 저하된다는 점입니다. 클러스터의 성능을 저하시킵니다. 마찬가지로 지나치게 공격적인 동기화 방법은 동기화 중에 오류가 발생하여 훈련 중단을 초래할 수 있습니다. 따라서 안정적이고 효율적인 동기화 방법은 업계가 추구해 온 방향이었습니다.
현재의 관점에서 주요 동기화 방식은 동기 병렬, 비동기 병렬, 올-리듀스 등으로 분류할 수 있습니다.
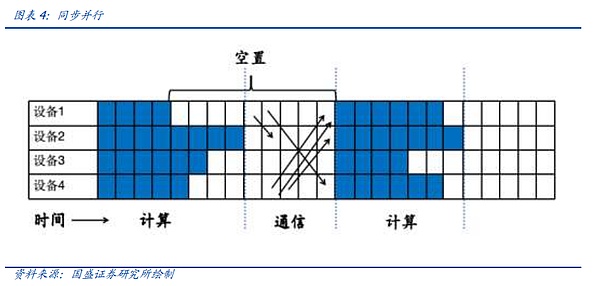
먼저 이전 기사에서 언급 한 아이디어의 동기 병렬 처리, 즉 현재 단위에서 모든 계산 단위가 통합 통신의 계산을 완료하고 안정성과 단순성의 장점이 있지만 많은 수의 계산 단위가 비어있게됩니다. 예를 들어 아래 그림에서 컴퓨팅 유닛 1이 계산을 완료한 후 컴퓨팅 유닛 4가 계산을 완료할 때까지 기다렸다가 통신을 수집할 때까지 기다려야 하므로 공석이 많이 발생하고 클러스터의 전체 성능이 저하됩니다.
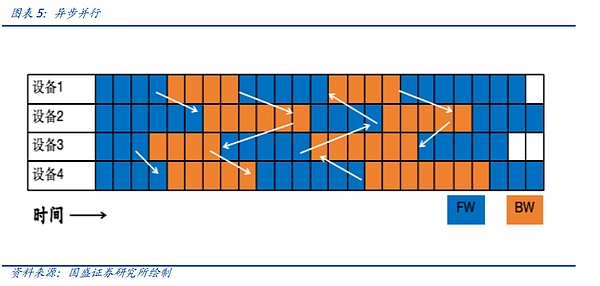
비동기 병렬화는 이자 프로모션과 같은 비발전형 대형 모델에 적합한 선택입니다. 비동기 병렬 처리는 관심도 프로모션과 같은 비생성 대형 모델을 처리할 때 선택하는 방법입니다. 한 장치가 순방향 및 역방향 계산을 완료하면 다른 장치가 사이클을 완료할 때까지 기다릴 필요가 없으며 데이터를 직접 동기화하므로 네트워크 모델 학습에서 수렴하지 않아 대형 모델 학습에는 적합하지 않지만 검색 모델 및 추천 모델에는 더 적합합니다.
세 번째 범주이자 현재 가장 많이 사용되고 있는 것은 올 리듀스(All-Reduce)입니다. 올-리듀스 또는 올-투-올-리듀스라고도 불리는 세 번째 클래스는 모든 디바이스(All)에 있는 정보를 모든 디바이스(All)로 요약(Reduce)하는 것입니다. 물론 직접 올 리듀스는 동일한 데이터가 여러 번 중복 전송될 수 있기 때문에 통신 리소스를 크게 낭비할 수 있습니다. 따라서 링 올 리듀스, 바이너리 트리 기반 올 리듀스 등 올 리듀스의 대역폭과 지연 시간을 크게 줄일 수 있는 최적화된 버전의 올 리듀스 알고리즘이 많이 제안되었습니다.
분산 컴퓨팅 엔지니어가 지속적인 반복을 통해 동기화 시간을 단축하는 방법을 보여주는 예로 중국의 AI 리더인 Baidu가 개발한 링 올 리듀스를 살펴봅시다.
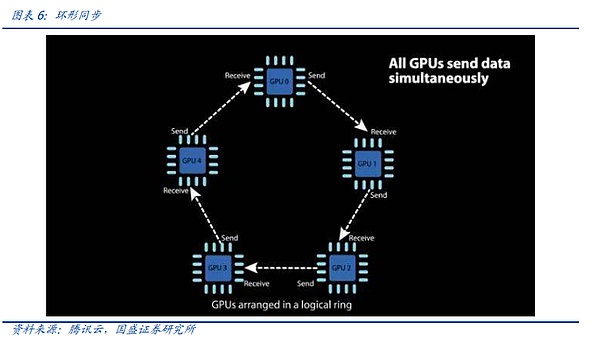
링 올-리듀스(링 동기화)에서는 각 장치가 두 개의 다른 장치와 통신하기만 하면 되는데, 이는 분산-리듀스와 올-개더링의 두 단계로 나뉩니다. 먼저, 인접한 디바이스가 각 디바이스에서 집계된 전체 데이터의 일부를 개별적으로 가져올 수 있도록 여러 번의 분산 감소 작업을 완료합니다. 그런 다음 각 디바이스는 인접한 디바이스를 정렬하여 각 디바이스의 전체 데이터를 구성하기 위해 여러 번의 올개더 작업을 완료합니다. 링 올-리듀스는 대역폭과 지연 시간을 줄일 뿐만 아니라 네트워크의 토폴로지를 단순화하고 네트워크 구축 비용을 절감합니다.

하지만 알고리즘이 무엇이든, 칩셋에서 기본적으로 프로토콜 수준에서 더 많은 대역폭을 지원하거나 순수 구리 연결에서 NVLink를 통한 연결로 전환하거나 IB 프로토콜 도입 등 네트워크 통신 하드웨어의 지원에 의존하며, RAM은 네트워크에서 더 많은 대역폭을 얻을 수 있는 유일한 방법입니다. 또는 IB 프로토콜의 도입, RDMA 수요의 폭발적인 증가 등 점점 더 복잡해지는 통신 및 동기화 요구 사항을 충족하기 위해 RAM이 필요한데, 이에 대해서는 나중에 자세히 설명하겠습니다.
이 시점에서 우리는 AI에 고밀도 통신이 필요한 이유에 대한 기본 논리를 예비적으로 이해했으며, 우선 소규모 모델 시대에서 대규모 모델 시대로 빠르게 전환되면서 멀티 노드 클러스터와 분산 학습이 필수가 되었고, 모델을 여러 컴퓨팅 노드로 분할할 것이며, 어떻게 분할하고 동기화를 어떻게 보장할지가 핵심 문제입니다. 첫 번째 단계는 모든 데이터가 서로 동기화되도록 하여 과거와 동일한 방식으로 데이터를 사용할 수 있고 미래에도 데이터를 사용할 수 있도록 하는 것입니다.
2.3 빅 모델 시대의 시스템 엔지니어링: 모니터링-요약-혁신, 반복은 항상 진행 중입니다.
위에서는 학습 원리에 따라 빅 모델이 통신 시스템에 의존하는 정도가 결정된다는 것을 설명했습니다. 수많은 다양하고 복잡한 병렬 처리 및 동기화 요구 사항이 AI 클러스터의 데이터 흐름을 구성합니다. 통신 네트워크는 이러한 요구 사항에 따라 가속화 속도와 제품 반복, 연결의 혁신에 따라 구동되지만 모든 문제를 단번에 해결할 수 있는 완벽한 클러스터는 아직 없으며, 클러스터의 안정성이 지속적으로 최적화되고 있지만 수백만 개의 정교한 장치로 구성된 시스템은 여전히 중단점과 중단으로 어려움을 겪고 있습니다.
따라서 대형 모델 통신 시스템의 진화 방향은 크게 세 가지로 나눌 수 있으며, 하나는 대형 모델 시스템의 모니터링 기능으로, 데이터 흐름의 대형 모델, 운영 상황을 실시간으로 인식하여 장애를 적시에 감지 할 수 있도록 하드웨어 및 소프트웨어의 네트워크 시각화를 기반으로 패킷을 캡처하는 프로세스가 주류 수단이되었습니다. FPGA 칩과 특수 소프트웨어를 통해 클러스터의 데이터 흐름을 모니터링하여 인식을 위한 기본 도구를 제공하며,
가장 일반적으로 사용되는 데이터 패킷 캡처의 소프트웨어 구현 국내외 잘 알려진 제품은 Wireshark(TCP/UDP 처리)입니다, Fiddler(HTTP/HTTPS 처리), tcpdump&windump, solarwinds, nast, Kismet 등이 있습니다. 기본 작동 원리는 프로그램이 네트워크 카드의 작동 모드를 "혼합 모드"(일반 모드, 카드가 자체 MAC 주소에 속한 패킷만 처리, 혼합 모드, 카드가 통과하는 모든 패킷을 처리)로 설정하고 동시에 Wireshark가 패킷을 수행합니다. 가로채고, 재전송하고, 편집하고, 덤프합니다.
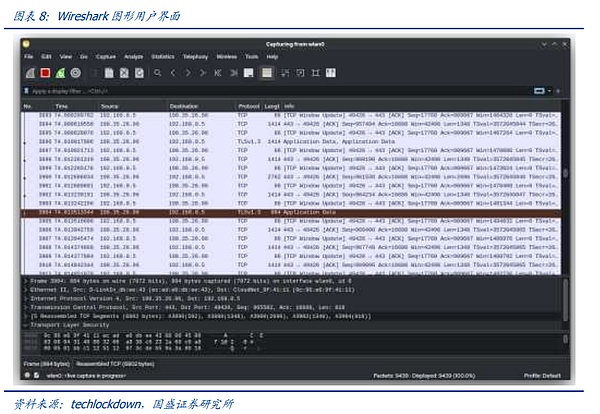
소프트웨어 패킷 캡처는 시스템 성능의 일부를 차지합니다. 시스템 성능의 일부를 차지합니다. 첫째, NIC는 네트워크의 하위 계층에서 주고받는 모든 패킷을 처리하는 무차별적 모드의 '브로드캐스트 모드'에 있으므로 NIC 성능의 일부를 소비하고, 둘째, 소프트웨어는 링크 계층에서 직렬 또는 병렬로 패킷을 캡처하지 않고 패킷을 복제하여 저장하므로 CPU 및 스토리지 리소스의 일부를 소모합니다. 리소스를 사용합니다. 동시에 Wireshark와 같은 대부분의 소프트웨어는 시스템에서 단일 네트워크 노드의 트래픽만 모니터링할 수 있으며, 글로벌 네트워크를 커버하기 어렵기 때문에 능동적 위험 모니터링이 아닌 수동적 문제 해결 작업에 적합합니다.
시스템의 전체 성능에 영향을 주지 않기 위해 하드웨어와 소프트웨어 도구를 조합한 병렬 또는 직렬 액세스가 등장했으며 일반적으로 사용되는 도구는 DPI와 DFI입니다. DPI(심층 패킷 검사)는 패킷 기반의 애플리케이션 계층 정보입니다. DPI(심층 패킷 검사)는 패킷의 애플리케이션 계층 정보를 기반으로 트래픽을 탐지하고 제어하는 기능으로, 애플리케이션 계층 분석에 중점을 두고 다양한 애플리케이션과 그 내용을 식별할 수 있습니다. IP 패킷, TCP 또는 UDP 데이터 스트림이 DPI 기술을 지원하는 하드웨어 장치를 통과하면 장치는 이를 심층적으로 읽어 메시지 부하를 재구성 및 분석하여 전체 애플리케이션의 내용을 파악한 후 장치에서 정의한 관리 정책에 따라 트래픽을 처리하는 기능입니다.dfi(심층/동적 흐름 검사)는 메시지의 애플리케이션 계층 정보를 기반으로 트래픽을 탐지 및 제어하는 기능입니다. DFI(심층/동적 흐름 검사)는 세션 연결 또는 데이터 흐름의 상태에 따라 애플리케이션 유형이 다르게 반영되는 흐름 동작을 기반으로 애플리케이션 식별 기술을 사용합니다. DPI 기술은 세밀하고 정확한 식별과 세밀한 관리가 필요한 환경에 적합하며, DFI 기술은 매우 효율적인 식별과 허술한 관리가 필요한 환경에 적합합니다.
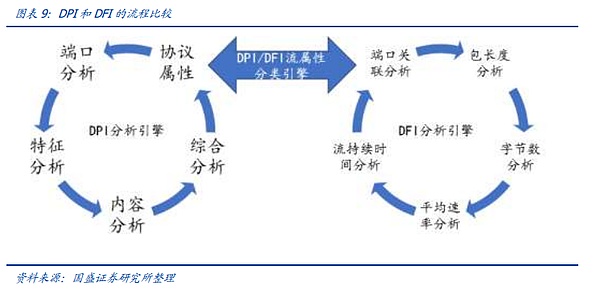
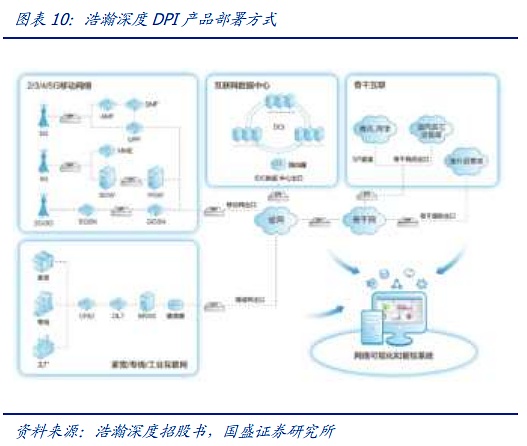
DPI/DFI는 다음과 같이 구성됩니다. 물리 계층의 성능에 영향을 미치지 않는 물리 계층의 독립적인 하드웨어 직렬/병렬 연결로 구성됩니다. Vast Depth의 DPI 하드웨어 및 소프트웨어 제품을 예로 들면, 통신 네트워크의 다양한 계층의 네트워크 노드에 배포할 수 있으며 동시에 SaaS/PaaS를 통해 다양한 계층의 모니터링 노드에 대한 데이터 수집, 분석 및 표시를 완료합니다. DPI 하드웨어는 통신의 물리적 계층에서 직렬 또는 병렬로 연결되고 패킷 미러링을 통해 거의 손실 없는 네트워크 모니터링을 달성하며 DPI 소프트웨어는 DPI 하드웨어에 내장되어 있습니다, DPI 소프트웨어는 DPI 하드웨어, 독립형 서버 또는 스위치/라우터에 내장되어 네트워크 모니터링을 가능하게 합니다.

모니터링 문제를 해결 한 후 큰 모델 시스템 엔지니어링의 반복 경로에는 앞서 언급했듯이 실제 운영에서 시스템 운영 효율과 안정성 간의 균형에 더주의를 기울일 필요가 있으며 한편으로는 Reduce 방법이 있습니다. 첫 번째는 감소 방법의 최적화, 병렬 방법의 혁신 등 새로운 교육 방법과 이론을 만들기 위해 분산 교육 혁신의 바닥, 그러나 혁신의 바닥은 항상 관련 하드웨어의 지원, 스위치의 더 큰 처리량, 더 적합한 스위칭 프로토콜, 더 안정적이고 저렴한 통신 장치가 시스템의 큰 모델이 될 것입니다 링의 업그레이드에 항상 필수 불가결 할 것입니다.
3.통신 프로토콜 경쟁과 반복: 인공지능 데이터 스트림 담론
이전 섹션에서 우리는 AI 클러스터에서 통신의 주요 역할을 체계적으로 설명했으며, 이번 섹션에서는 전체 통신 시스템의 가장 기본적인 부분을 구성하는 통신 프로토콜에 대해 체계적으로 소개합니다.
직관적으로 통신 시스템은 주로 스위치, 광 모듈, 케이블, NIC 등 물리적 하드웨어로 구성되지만, 실제로 통신 시스템 구축의 실질적인 결정은 물리적 하드웨어에 흐르는 통신 프로토콜의 동작과 성능 특성입니다. 통신 프로토콜은 컴퓨터 네트워크에 있으며, 데이터의 원활하고 정확한 전송을 보장하기 위해 양측 간의 통신은 일련의 계약을 준수해야합니다. 이러한 규칙에는 데이터 형식, 인코딩 규칙, 전송 속도, 전송 단계 등이 포함됩니다.
AI 시대에 통신 프로토콜의 분류는 주로 크게 두 가지로 나뉘며, 첫 번째는 연산 노드 내의 연산 카드 간의 통신을위한 고속 프로토콜에 사용되며이 종류의 프로토콜은 빠른 속도, 강한 폐쇄성, 약한 확장 성 등의 특성을 가지고 있으며 종종 각 그래픽 카드 제조업체의 핵심 능력 장벽 중 하나, 속도, 인터페이스 등이 있습니다. 속도, 인터페이스 등은 칩 수준에서 지원되어야 합니다. 두 번째 유형의 프로토콜은 산술 노드 간을 연결하는 데 사용되며, 이러한 유형의 프로토콜은 느린 속도, 확장 성 등의 특성을 가지고 있으며, 현재 두 번째 유형의 프로토콜에는 RoCE 프로토콜 제품군에 따라 인피니밴드 프로토콜과 이더넷이 있으며, 노드 간 데이터 전송 용량뿐만 아니라 메가 클러스터의 기반을 구축할 뿐만 아니라 스마트 컴퓨팅 장치가 데이터 센터에 액세스하기 위해 솔루션입니다.
3.1 노드 내 통신 - 대형 벤더의 핵심 장벽이자 무어의 법칙에 대한 희망
3.1 노드 내 통신 - 대형 벤더의 핵심 장벽이자 무어의 법칙에 대한 희망
3.2 노드 내 통신 - 대형 벤더의 핵심 장벽이자 무어의 법칙에 대한 희망
단일 서버 내의 그래픽 카드 통신 프로토콜인 인트라노드 통신은 동일한 서버 내의 그래픽 카드 간 고속 상호 연결을 담당하며, 현재까지 이 프로토콜에는 주로 PCIe, NV링크, 인핀티 패브릭의 세 가지 프로토콜이 포함되었습니다.
가장 오래된 PCIe 프로토콜을 먼저 살펴보겠습니다. PCIe는 공개적으로 사용 가능한 범용 프로토콜로, 기존 서버 PC의 다양한 하드웨어를 PCIe 프로토콜을 통해 연결하며 타사 조립 연산 서버에서는 여전히 기존 서버처럼 그래픽 카드가 PCIe 슬롯과 마더보드를 통해 서로 연결됩니다. 마더보드의 PCIe 슬롯과 PCIe 라인.
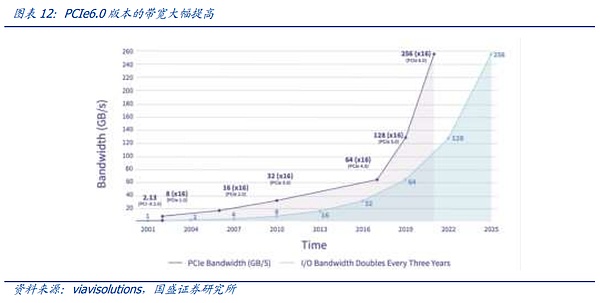
PCIe는 가장 널리 사용되는 버스 프로토콜입니다. 버스는 서버 마더보드의 여러 하드웨어가 서로 통신하는 통로이며 데이터 전송 속도에 결정적인 역할을 합니다. 현재 가장 널리 사용되는 버스 프로토콜은 2001년 인텔이 제안한 PCIe(PCI-Express) 프로토콜이며, PCIe는 주로 CPU를 GPU, SSD, NIC 및 그래픽 카드와 같은 다른 고속 장치에 연결할 때 사용됩니다. 2003년 PCIe 1.0 버전이 출시되었고, 이후 약 3년마다 세대가 업데이트되어 현재는 최대 64GT/s의 전송 속도와 최대 256GB/s의 16채널 대역폭을 갖춘 6.0 버전으로 업데이트되어 성능과 확장성이 지속적으로 향상되고 있습니다.
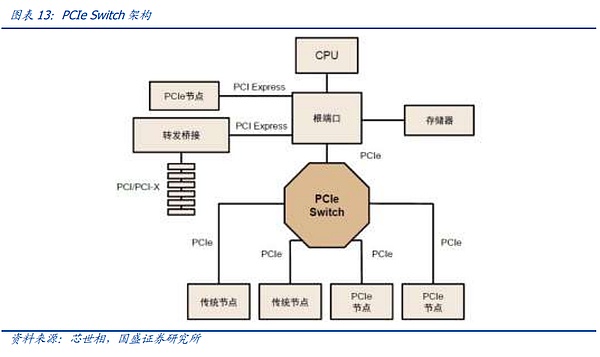
PCIe 버스 트리 토폴로지와 종단 간 전송 방식은 연결 수와 속도에 제한이 있어 PCIe 스위치가 탄생했습니다.
PCIe는 종단 간 데이터 전송 링크를 사용하는데, PCIe 링크의 각 끝에서 하나의 장치에만 액세스할 수 있고 식별되는 장치 수가 제한되어 있어 많은 수의 장치가 연결되거나 고속 데이터 전송이 필요한 시나리오를 충족할 수 없었기 때문에 PCIe 스위치가 탄생하게 되었습니다. PCIe 스위치는 연결과 스위칭 기능을 모두 갖추고 있어 PCIe 포트가 더 많은 장치를 인식하고 연결할 수 있어 채널 수 부족 문제를 해결하고 여러 PCIe 버스를 함께 연결하여 다중 장치 통신을 위한 고속 네트워크를 형성할 수 있습니다.
하지만 위에서 언급한 것처럼 모델 규모가 점차 확장되고 NPU 간 동기화가 이루어지면 NPU가 서로 통신하는 것이 더 쉬워질 것입니다. 그러나 위에서 언급했듯이 모델 크기가 커지고 NPU 간의 동기화 루프가 복잡해짐에 따라 속도가 낮고 최적화되지 않은 작동 모드인 PCIE는 더 이상 대형 모델 시대의 요구를 충족할 수 없기 때문에 대형 모델 시대에는 주요 그래픽 카드 제조업체의 독점 프로토콜이 빠르게 등장하고 있습니다.
업계에서 가장 많은 관심을 받고 가장 빠르게 진화한 프로토콜은 NVIDIA가 제안한 고속 GPU 상호 연결 프로토콜인 NV-Link 프로토콜이라고 생각합니다. 기존 PCIe 버스 프로토콜과 비교하여 NVLINK는 1) 제한된 채널 액세스 문제를 해결하기 위한 메시 토폴로지 지원, 2) 단일 GPU를 사용할 수 있는 통합 메모리, 3) 단일 GPU의 3가지 주요 영역에서 상당한 변화를 가져왔습니다. 제한된 문제; 2) 통합 메모리, GPU가 공통 메모리 풀을 공유할 수 있어 GPU 간 데이터 복사 필요성을 줄여 효율성을 개선; 3) 직접 메모리 액세스, CPU의 개입 없이 GPU가 서로의 메모리를 직접 읽을 수 있어 네트워크 지연 시간을 줄일 수 있습니다. 또한, GPU 간의 통신 불균일 문제를 해결하기 위해 NVIDIA는 스위치 ASIC과 유사한 물리적 칩인 NVSwitch를 도입하여 여러 GPU를 NVLink 인터페이스를 통해 고속으로 상호 연결하여 고대역폭 멀티 노드 GPU 클러스터를 만들었습니다.
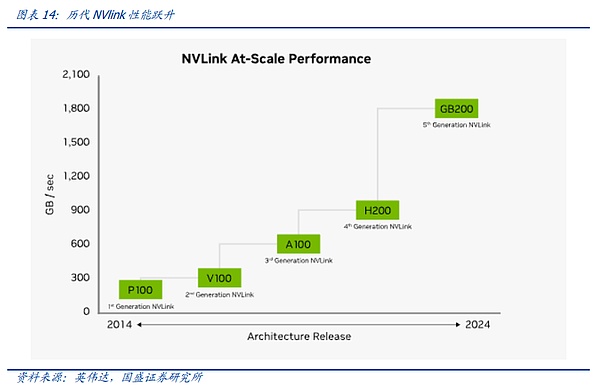
NV-link의 역사를 돌아보면 노드 간 NVSwitch가 GPU를 상호 연결하는 가장 효율적인 방법이라는 것을 알 수 있습니다.
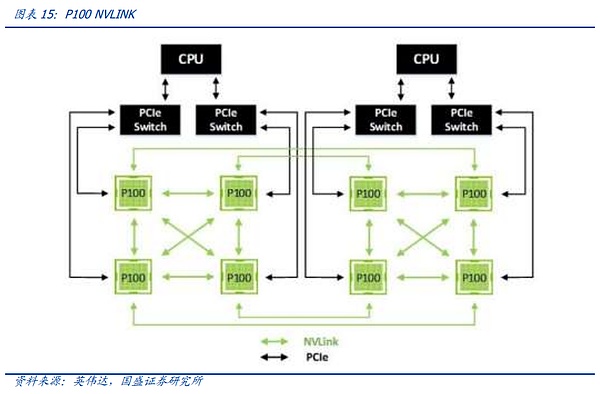
그래픽 카드 간 동기화의 필요성이 변화함에 따라 노드 간 NV-Link 상호 연결이 점진적으로 반복되어 왔음을 알 수 있습니다. 1세대 NV-Link는 파스칼 아키텍처에 등장했으며, 범용 PCIE 스위치뿐만 아니라 PCB 보드의 고속 구리선을 통해 NVIDIA는 단일 서버 내부 링크 8 카드 서버에서 아래 그림의 연결을 통해 4 개의 그래픽 카드의 내부 X 형 연결에 겹쳐진 그래픽 카드 외부 대형 링을 통해 8 개의 GPU 사이에서 시작점으로 어느 하나에 대해 찾을 수 있습니다. 최단 경로로 글로벌 데이터 정렬을 수행할 수 있습니다.
하지만 개별 카드의 성능이 확장됨에 따라 처리량이 증가하고 그래픽 카드가 서로 동기화되는 방식이 증가합니다. 따라서 3세대 NV링크에 해당하는 암페어 아키텍처에서 NVIDIA는 NV링크 속도와 유연성을 더욱 높이기 위해 1세대 전용 NV링크 스위치 칩셋을 도입했습니다.

파스칼 아키텍처에서 암페어로의 업데이트에서 파스칼에서 암페어 아키텍처로의 업데이트는 당시 고객 수요가 여전히 소형 모델에 집중되어 있기 때문에 대규모 컴퓨팅 클러스터가 나타나지 않았기 때문에 NV-LINK는 주로 칩 내부 채널 반복, NV-Link 스위치 칩 반복을 통해 정기 업데이트의 리듬을 유지하여 업데이트 속도를 달성하는 기간 동안 NVIDIA는 일부 하이 엔드 C의 요구를 충족하기 위해 게임용 그래픽 카드 용 NV-Link 브리지도 출시했습니다.

A100에서 H100으로의 업데이트에서 NVIDIA는 NV-Link 스위치로 한 걸음 더 나아갔습니다. 대형 모델에 대한 수요가 증가하기 시작하자 데이터 크기와 모델 볼륨이 커져 8개의 그래픽 카드로 제한되었던 NV-Link 인터커넥트를 감당하기 어려웠습니다. 사용자는 모델을 잘게 쪼개서 여러 서버에 로드하여 훈련 및 정렬해야 했고, 서버 간 통신 속도가 느려지면 모델 훈련의 효과에 직접적인 영향을 미쳤습니다. 가장 빠른 통신 프로토콜로 상호 연결할 수 있는 그래픽 카드의 수를 HB-DOMIN이라고 하며, 모델 파라미터가 점점 더 커짐에 따라 HB-DOMIN은 같은 세대 칩 내에서 모델 훈련 능력을 결정하는 핵심 요소가 되었습니다.
이러한 맥락에서 NVIDIA의 NV-LINK는 외부 전용 스위치를 통해 더 많은 NV-LINK 스위치 칩을 호스팅하여 기존 그래픽 카드의 HB-DOMIN을 확장함으로써 Hopper 아키텍처 진화의 첫 걸음을 내디뎠습니다. 시대에는 GH200 SuperPOD 제품을 통해 처음으로 NV-LINK가 서버 외부로 나와 서버 전체에서 256개의 그래픽 카드를 상호 연결할 수 있게 되었습니다.

하지만 호퍼 아키텍처에 해당하는 NV

클라우드와 자동 동기화
클라우드 서비스와의 동기화를 위해 수동으로 작업할 필요가 없습니다. 동시에 GH200 출시 당시에는 모델의 파라미터가 아직 1조 수준으로 부풀려지지 않았으며, Meta의 연구 결과에 따르면 1조 파라미터 아래에서는 100을 초과하면 HB-Domin 확장의 한계 효과 감소가 가속화되는 것으로 나타났습니다.
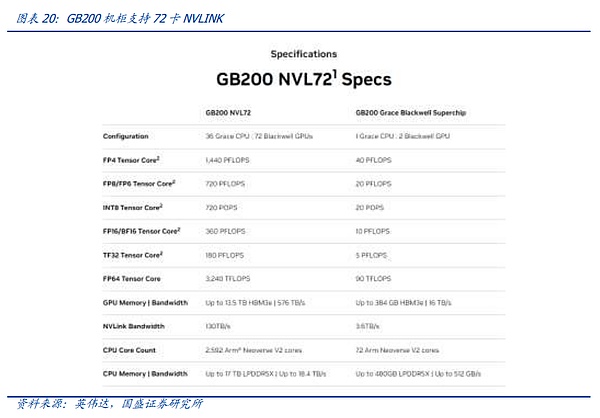
블랙웰 아키텍처 시대, NVIDIA 엔비디아는 공식적으로 NV링크의 확장 경로를 완성하고, 4NM의 최신 NV링크 스위칭 칩을 출시하면서 공식 주먹 제품인 GB200 NVL72를 출시했습니다. 엔비디아는 하나의 섀시 안에 NV링크+구리의 단일 레이어 연결을 통해 비용 효율적인 HB-DOMIN 수에 도달하는 목표를 달성하며 진정한 한 걸음 더 나아갔습니다. 노드 내 상호 연결 프로토콜을 상위 계층으로 확장하는 첫 번째 단계입니다.
최신 세대의 NV-LINK 를 통해 노드 간 상호 연결 프로토콜의 중요성에 대해 다시 한 번 알게 되었으며, 산술의 시대에 무어의 법칙이 지속되기 위해서는 노드 간 통신의 확장이 중요해졌다고 주장할 수도 있습니다. 노드 내 통신 프로토콜의 반복적이고 저렴한 구현은 오늘날 '통신 벽'과 '메모리 벽'을 해결하기 위한 최상의 솔루션입니다.
현재 NV-LINK의 가장 큰 경쟁자는 범용 그래픽 분야에서 NVIDIA의 최대 경쟁자인 AMD입니다. NVIDIA와 마찬가지로 개방형 네트워크 프로토콜을 가장 지지해 온 AMD도 여전히 인노드 상호 연결에 자체 독점 프로토콜을 사용하고 있습니다. "인피니티 패브릭"이라는 프로토콜을 사용하지만, NVIDIA와 달리 AMD는 이 프로토콜을 협력하는 세 개의 이더넷 리더인 Broadcom, Arista 및 Cisco와 공유합니다.

오늘, 인피니티 인피니티 패브릭과 NVLINK의 격차는 여전히 크고, 전용 스위칭 칩, 멀티 카드 상호 연결, 프로토콜 완성도 측면에서 AMD는 아직 따라잡을 길이 멀며, 이는 현재 범용 연산 경쟁이 칩 설계의 단일 링크에서 노드 간 통신의 링크로 천천히 확장되고 있다는 것을 보여줍니다.
요약하면, 노드 간 통신은 연산에서 점점 더 중요한 부분이 되고 있으며, 동시에 HB-DOMIN의 확장과 함께 '연산 노드'도 점차 확장되고 있으며, 이것이 전체 AI 클러스터 내에서 노드 간 프로토콜의 '상향 이동'의 이유라고 생각합니다. 이것이 전체 AI 클러스터 내에서 노드 간 프로토콜의 "상향 침투"의 배경이며, 동시에 노드 간 프로토콜과 호스팅 하드웨어의 체계적인 압축에 의존하는 것이 AI 산술의 미래를 위한 무어의 법칙을 달성하는 방법이기도 하다고 믿습니다.
3.2 노드 간 통신 프로토콜: 폐쇄형과 개방형 간의 싸움
이제 노드 외부를 살펴보고 글로벌 컴퓨팅 클러스터를 구성하는 주요 프로토콜을 살펴봅시다. 주요 프로토콜의 클러스터 연결성을 살펴보겠습니다. 오늘날의 연산 센터에서 NPU는 점차 백만 개 규모를 향해 나아가고 있으며, 연산 노드 또는 HB-DOMIN이라고 부르는 연산 노드가 빠른 속도로 확장되고 있지만, 노드 간 연결은 여전히 글로벌 AI 연산을 구성하는 초석의 일부분입니다.
현재의 관점에서 노드 간 연결 프로토콜은 주로 이더넷 제품군 내의 InfiniBand 프로토콜과 ROCE 프로토콜 제품군으로 나뉩니다. 슈퍼컴퓨팅 노드 간 상호 연결의 핵심은 RDMA 기능에 있습니다. 기존 CPU 기반 데이터센터에서는 송신 측의 메모리에서 데이터를 전송한 후 송신 측 장치의 CPU에서 인코딩하여 수신 측 장치의 CPU로 전송한 후 디코딩을 거쳐 메모리에 넣는 TCP/IP 프로토콜이 일반적으로 전송에 사용되었습니다. 이 과정은 여러 장치를 통해 데이터를 여러 번 코딩하고 디코딩하기 때문에 지연 시간이 길어지고, 지연 시간은 컴퓨팅 카드 간의 동기화에 가장 중요한 요소이므로 CPU를 우회하여 메모리 간의 원격 직접 메모리 액세스 (원격 직접 메모리 액세스) RDMA를 달성하기 위해 그래픽 카드 간의 상호 연결에 대한 요구가 AI 클러스터의 연결에 엄격하게 요구되고 있습니다.
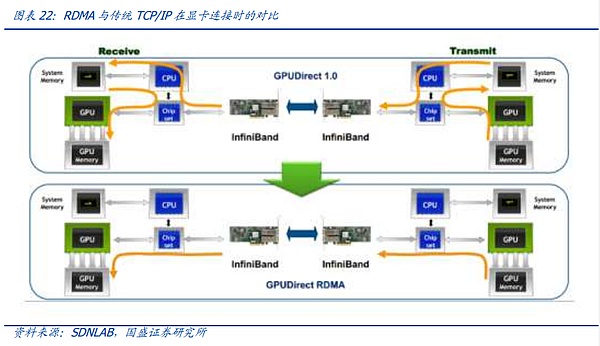
이러한 맥락에서 현재 RDMA를 지원하는 IEEE 802.168.1 표준은 NVIDIA가 주도하는 AI 클러스터 연결에 가장 널리 채택된 표준이 되었습니다. 이러한 맥락에서 현재 NVIDIA가 지원하는 IB 이더넷에서 RDMA를 지원하는 ROCE 프로토콜 제품군은 유일한 선택이 되었으며, 이 두 프로토콜의 고유한 특징으로 인해 전체 노드 간 프로토콜 경쟁이 흥미진진해졌습니다.
IB 프로토콜의 출현은 PCI 버스의 열악한 통신 기능이 점차 다양한 장치 간의 통신에 병목 현상을 일으킨 1999년까지 거슬러 올라갈 수 있으며, 이러한 맥락에서 인텔, 마이크로소프트, IBM, 여러 대기업이 FIO 개발자 포럼을 설립하고 NGIO 포럼이 합병되었습니다. 이러한 맥락에서 인텔, 마이크로소프트, IBM 및 기타 여러 대기업은 FIO 개발자 포럼과 NGIO 포럼을 설립하여 인피니밴드 무역 협회(IBTA)를 합병하고 2000년에 IB 프로토콜 프레임워크의 첫 번째 버전을 출시했습니다. 1999년에 설립된 스위칭 칩 회사인 멜라녹스도 IB 진영에 합류했습니다.
IB는 처음부터 PCI 버스의 한계를 우회하여 더 빠른 액세스를 가능하게 하는 RDMA 개념을 개척했지만 오래 가지 못했고 2022년 인텔, 마이크로소프트, 기타 대기업들이 위에서 언급한 PCIE 프로토콜을 선호하여 IB 컨소시엄을 탈퇴한다고 발표했습니다. 2022년 인텔, 마이크로소프트 및 기타 거대 기업들이 위에서 언급한 PCIE 프로토콜을 위해 IB 컨소시엄을 탈퇴한다고 발표하면서 IB는 쇠퇴의 길로 접어들었습니다. 하지만 2005년 저장 장치 간 통신에 대한 수요가 증가하면서 IB가 다시 부상했고, 이후 전 세계적인 슈퍼컴퓨팅 구축과 함께 점점 더 많은 슈퍼컴퓨터가 연결을 위해 IB를 사용하기 시작했습니다. 그 과정에서,IB 및 관련 인수에 대한 끊임없는 노력을 바탕으로 Mellanox는 칩 회사에서 모든 범위의 NIC, 스위치/게이트웨이, 텔레매틱스 시스템, 케이블 및 모듈로 확장하여 세계적인 수준의 네트워킹 공급업체가 되었고, 2019년에는 Nvidia가 인텔과 Microsoft를 제치고 69억 달러에 Mellanox를 성공적으로 인수했습니다.< /strong>

반면 이더넷은 2010년에 이더넷 프로토콜을 기반으로 RDMA를 구현하는 RoCE 프로토콜을 발표했으며, 2014년에 보다 성숙한 RoCE v2가 제안되었습니다.
빅 모델 시대에 접어든 이후 글로벌 데이터 센터는 빠르게 다음과 같은 방향으로 전환하고 있습니다. 스마트 컴퓨팅으로 빠르게 전환하고 있으므로 장비에 대한 주요 신규 투자에는 RDMA 연결이 필요합니다. 그러나 현재의 경쟁 환경은 이전의 RoCE V2 및 IB 경쟁과는 달라졌습니다. 글로벌 그래픽 분야에서 절대적인 선두를 달리고 있는 엔비디아의 그래픽 카드가 IB에 훨씬 더 적합하며, 가장 확실한 점은 멜라녹스 스위치에 배포된 샤프 프로토콜입니다.
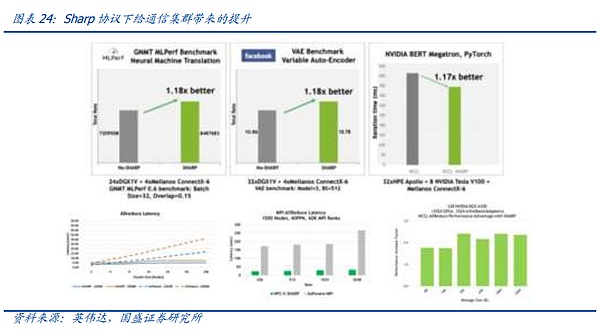
위에서 언급했듯이 AI 컴퓨팅에서 그래픽 카드와 그래픽 카드간에 복잡한 Reduce 통신이 많이 필요하기 때문에 이는 AI 통신 시스템의 엔지니어링에서 해결해야하는 핵심 문제이기도합니다. Mellanox 스위치 제품에서 회사는 NVIDIA의 도움으로 관련 Reduce 계산을 지원할 수있는 컴퓨팅 엔진 장치를 스위칭 칩에 혁신적으로 통합하여 GPU가 다음을 수행 할 수 있도록 지원합니다. 부하를 줄이지만 관련 기능을 사용하려면 GPU 제조업체의 협조가 필요합니다.
이것은 통신 프로토콜의 AI 시대에 그래픽 카드 공급 업체의 뒷면의 핵심이 투쟁의 권리가되었으며 현재 NVIDIA의 지원을받는 IB 프로토콜이 더 나은 경쟁 우위를 차지하고 있으며 강력한 칩 지원이 부족하기 때문에 전통적인 이더넷 공급 업체가 가장 중요하다는 것을 보여줍니다. 기존 이더넷 공급업체는 강력한 칩 지원 부족으로 인해 일부 기능에서 다소 취약합니다. 하지만 AMD가 주도하는 하이퍼 이더넷 연합의 출현으로 이러한 상황은 점차 반전될 것으로 예상됩니다.

2023년 7월 지난 7월 19일 AMD, 브로드컴, 시스코, 아리스타, 메타, 마이크로소프트 등 컴퓨팅 칩, 네트워크, 사용자 측면의 주요 벤더들이 이더넷을 기반으로 IB의 성능을 능가하는 완전히 개방적이고 보다 유연한 네트워크 프로토콜을 구축하여 IB와 경쟁하는 것을 목표로 설립된 하이퍼 이더넷 연합이 공동으로 결성되었습니다.
하이퍼이더넷 연합은 이더넷 위에 완전히 개방적이고 유연한 고성능 네트워크 프로토콜을 구축하여 IB를 능가할 수 있도록 하기 위해 결성되었습니다.

AMD는 하이퍼 이더넷 연합의 핵심 회원으로서 MiTAC 플랫폼 개발에 크게 기여해 왔습니다. 하이퍼 이더넷 얼라이언스의 핵심 멤버로서 Mi300 시리즈 출시 당시 그래픽 카드의 백엔드 연결은 무조건 이더넷을 사용할 것이며, 노드 간 상호 연결에 사용되는 인피니티 패브릭 프로토콜을 이더넷 벤더들에게도 개방할 것이라고 밝힌 바 있습니다. <강>AMD와 브로드컴을 비롯한 UEC 연합의 다른 회원사들의 협력 진행이 점차 가속화됨에 따라 UEC 연합도 N 카드 + IB와 유사한 일련의 호환성 및 협력 체계를 실제로 형성할 것으로 예상되며, 이는 엔비디아에게 도전을 가져올 것으로 판단됩니다. 하지만 단일 카드 컴퓨팅 파워에서 AMD가 따라잡고, 스위칭 칩의 발전, 그리고 다른 벤더 간의 개방과 협력에 이르기까지 그 과정은 길어질 것이며, 아직 갈 길이 많이 남아있습니다.
요약하면, 노드 통신 프로토콜 분쟁은 분쟁의 원칙에서 점차적으로 어떤 종류의 계약을 사용하여 발언권으로 진화했으며, 더 많은 것은 GPU의 발언권의 확장이며, 엔비디아는 IB 발언권을 통해 전체 링크를 확장하기를 희망하며, 고객은이를 수용하기를 원합니다. IB가 더 개방적일수록 업계의 경쟁은 통신 프로토콜의 지속적인 진화를 이끌 것입니다.
4. 네트워크 하드웨어 혁신은 AI와 함께 어디로 갈까요?
이전 섹션에서는 AI 수요가 RDMA 기능의 진화와 규모를 어떻게 주도하고 있는지에 대해 설명했으며, 마찬가지로 네트워크 하드웨어 영역에서도 AI의 새로운 수요가 전송 매체, 스위치, 네트워크 아키텍처, 심지어 데이터센터의 전반적인 형태까지 변화를 가져오고 있습니다. 데이터센터의 전반적인 형태가 변화하고 있습니다.
4.1 광, 구리, 실리콘: 전송 매체 논쟁이 향하는 방향
최근 몇 년간 인간의 데이터 양이 급격히 늘어나고 전송 속도가 기하급수적으로 증가하면서 인터넷을 통해 전송 가능한 데이터의 양이 증가했습니다. 무선 네트워크, 유선 네트워크 및 기타 통신 분야는 초기의 전화 접속 인터넷에서 가정으로 연결되는 광섬유, 그리고 현재 구리를 점진적으로 대체하기 위한 광섬유 케이블의 공식적인 라운드인 FTTR에 이르기까지 구리 후퇴에 빛의 물결을 불러일으켰습니다.
데이터 센터 내부에서는 광 모듈, AOC 등에 의해 광 통신 시스템이 점차적으로 고속 전송, 구리 미디어 감쇠의 뒷면 인 구리 전송 시스템의 DAC, AEC 및 기타 구성 요소로 대체되는 구리 후퇴 과정도 진행 중이며 점점 더 극적인 불가피한 물리적 법칙입니다. AI가 가져온 다양한 요구가 없다면 광 전송은 점차 캐비닛 내부로 침투하여 시간이 지남에 따라 서버 포트 속도가 증가함에 따라 결국 모든 광 데이터 센터를 형성하게 될 것입니다.
그러나 AI의 등장으로 이 과정은 "구리 뒷면으로 들어오는 빛"으로 바뀌면서 시장에 혼란을 가져왔습니다. 그 핵심 이유는 AI가 통신 시스템의 복잡성과 비용을 비세대적으로 선형적으로 증가시키고 수요의 기하 급수적 인 증가 앞에서 고속 광학 모듈이 점점 더 비싸지기 때문입니다. 따라서 현재의 매력률에서보다 비용 효율적인 구리 케이블이 점차 증가하면서 냉각 및 기타 개선의 다른 지원 구성 요소에 겹쳐지면서 그래픽 카드 제조업체는 단일 캐비닛의 범위 내에서 가능한 한 많은 컴퓨팅 장치를 구리에서 가능한 한 많은 컴퓨팅 장치를 압축 할 수 있습니다.

이 이면에는 AI 시대가 도래했음을 쉽게 알 수 있습니다. 지출 증가로 인해 광-구리 논쟁의 핵심이 요금 상승에서 현재 2~3년 노드에서는 비용 우선으로 바뀌었고, 통신 시스템의 복잡성이 가속화되면서 단순성과 낮은 장애율이 고객들이 미디어를 선택하는 주요 고려사항이 되었습니다.
장거리 서버 간 전송: 광 모듈이 유일한 솔루션이며, 비용 절감과 단순성이 혁신의 방향입니다.
구리 전송 거리의 한계로 인해 소위 "라이트 아웃, 구리 인"은 단거리 전송에서만 발생할 수 있으며, 5미터 이상의 전송 거리, 즉 서버 간 또는 컴퓨터 노드 간 전송에서는 여전히 광 전송이 유일한 선택입니다. 그러나 이제는 기존 요금 업그레이드에 대한 고객의 우려 외에도 비용 및 고장률 (장치 복잡성) 추구가 점점 더 시급 해지고 있으며 이는 광통신 산업 업그레이드의 미래 방향을 주도하고 있습니다.
LPO/LRO: LPO는 기존 DSP를 선형 직접 구동 기술로 대체하여 그 기능을 스위칭 칩에 통합하고 드라이버와 TIA 칩만 남겨두고, LPO 광 모듈에 사용되는 TIA 및 드라이버 칩의 성능도 개선하여 선형성을 향상시켰습니다. LRO는 한쪽 끝에는 기존 광학 모듈을, 다른 쪽 끝에는 LPO 광학 모듈을 사용하는 과도기적 솔루션으로 고객 수용성을 높였습니다.
실리콘 광학: 개별 장치에서 광 엔진의 광학 모듈 일부를 실리콘 칩에 자동화 통합하는 기술의 성숙을 통해 실리콘 광학은 상당한 비용 절감을 달성 할 수있는 동시에 자동화 된 생산 및 프로세스 업데이트를 통해 실리콘 광학 칩 반복, 우리는 LPO, silicon 광학은 업계에서 가장 빠르게 진행되고 있는 비용 절감 혁신 중 두 가지입니다.
박막 리튬 니오베이트: 리튬 니오베이트는 신뢰할 수 있는 재료 중 전기 광학 계수(퀴리점 및 전기 광학 계수 고려)에 가장 적합한 선택입니다. 박막 공정은 전극 거리를 늘리고 전압을 낮춰 대역폭 대 전압 비율을 개선합니다. 다른 재료에 비해 넓은 대역폭, 낮은 손실, 낮은 구동 전압 및 기타 많은 광전자적 이점이 있습니다. 현재 박막 리튬 니오베이트는 주로 고속 실리콘 광 변조기에 사용되며, 박막 리튬 니오베이트 변조기의 사용은 더 나은 성능을 달성하기 위해 1.6T, 3.2T에있을 수 있다고 생각합니다.
CPO: CPO는 광 모듈이 스위치 마더보드에 직접 캡슐화되어 스위치 마더보드의 방열을 공유하고 동시에 스위치 마더보드에서 전송되는 전기 신호의 거리를 단축할 수 있지만 현재 광 모듈의 AI 센터가 부패하기 쉬운 상품에 속하기 때문에 공통 캡슐화의 유지 관리가 어렵습니다. 하지만 현재 AI 센터의 광모듈은 부패하기 쉬운 품목에 속하기 때문에 공동포장 후 유지보수가 어렵기 때문에 CPO에 대한 고객의 인식 정도는 아직 지켜봐야 할 것 같습니다.
내장 연결: 비용과 안정성이라는 두 가지 이점이 있는 구리는 단기 및 중기적으로 유리하며, 장기적인 상승률로 보면 여전히 구리로의 빛 유입이 일어날 것입니다.
DAC: 직접 연결 케이블, 즉 고속 구리 케이블은 초고속 연결 내에서 더 짧은 거리로 조정할 수 있으며, 현재 시장의 주류인 3미터 이하의 800G DAC 길이는 비용 효율적인 캐비닛 내 연결 솔루션입니다.
AOC: 액티브 광 케이블, 액티브 광 케이블, 즉 광 모듈과 광섬유의 하위 어셈블리 통합의 조기 완료의 두 끝이 시스템을 구성하고 기존의 다중 모드 또는 단일 모드 광 모듈에 비해 전송 거리는 짧지 만 비용은 저렴하며 단거리 연결 옵션 후 캐비닛 내 구리 케이블 전송의 한계를 넘어 섰습니다. 구리 케이블의 한계를 뛰어넘는 캐비닛 내 연결을 위해 선택한 단거리 연결입니다.
실리콘의 진화에서 현재 주류의 생각은 주로 칩렛과 웨이퍼 스케일링 두 가지를 포함하며, 이 두 가지 방법의 핵심 아이디어는보다 진보 된 반도체 제조 및 설계 프로세스를 통해 단일 칩으로 운반 할 수있는 계산 단위의 수를 최대한 멀리 확장하는 것입니다. 하나의 실리콘 조각에서 더 많은 통신 개발을하고 컴퓨팅 효율성을 극대화하는이 부분은 이전 "AI 산술 ASIC 도로 - 이더넷 채굴기에서 시작"의 깊이있는 내용에서이 기사에서 자세히 소개 한 내용을 반복하지 않습니다.
요약하면, 전송 매체와 경쟁의 반복은 수요를 따르며, 현재 수요는 MOE 및 기타 새로운 교육 프레임 워크에서 수조 달러 규모에 대한 모델 매개 변수, 더 잠재적으로 강력한 단일 노드 산술을 달성하기 위해 비용 효율적인 방법 또는 확장하는 방법이 매우 명확합니다. 모델의 절단이 너무 세분화되어 훈련 효율을 떨어뜨리지 않도록 "HB-DOMIN" 도메인의 수를 늘리는 방법 등을 끊임없이 연구하고 있습니다.
4.2 스위치 혁신: 지평선에 선 광 스위치
네트워크의 핵심인 스위치
네트워크의 핵심 노드인 스위치는 통신 프로토콜을 전달하는 핵심 구성 요소이며, 오늘날의 AI 클러스터에서 스위치는 위에서 언급한 멜라녹스 스위치와 같이 점점 더 복잡한 작업을 맡게 되고 있으며, 부분적으로 SHARP 프로토콜과 연계되어 AI 작업을 가속화하는 데 도움을 줍니다.
그러나 다른 한편으로 오늘날의 전기 스위치는 점점 더 강력해지고 반복 속도가 여전히 꾸준하지만 순수 광학 스위칭이 새로운 트렌드가 되고 있는 것 같습니다. 이러한 이유로 광 스위칭 트렌드의 배경에는 두 가지 주요 이유가 있다고 생각합니다. 첫째, AI 플레이어의 대형화입니다. 둘째, AI 클러스터의 가속화된 확장입니다.
광 스위칭 시스템은 전기 스위칭 시스템에 비해 전기 칩을 제거하고 광학 렌즈를 사용하여 스위치 내부로 들어오는 광 신호를 굴절 및 분배하여 변환되지 않도록 하여 해당 광학 모듈로 전달합니다. 전기 스위치에 비해 광 스위치는 광전 변환 프로세스가 제거되어 전력 소비, 지연 등이 낮아지는 동시에 네트워크 레이어 수를 최적화하기 위해 전기 스위치 칩의 용량 제한을받지 않고 단일 스위치로 커버 할 수있는 장치 수도 증가하지만 반대로 광 스위치의 사용은 네트워크 아키텍처를 동시에 조정할 수 있도록 특별히 설계해야하는 반면 클러스터를 구축하면 광 스위치는 단편적으로 확장 할 수없고 일회성 확장 만 할 수 있습니다. 동시에 광 스위치 클러스터가 구축되면 단편 확장을 수행 할 수 없으며 전체 네트워크 클러스터를 한 번만 확장 할 수 없으며 유연성도 좋지 않으며 현재 단계의 광 스위치에는 범용 버전이 없으며 자체 연구 또는 사용자 정의 설계가 필요하며 임계 값이 더 높습니다.
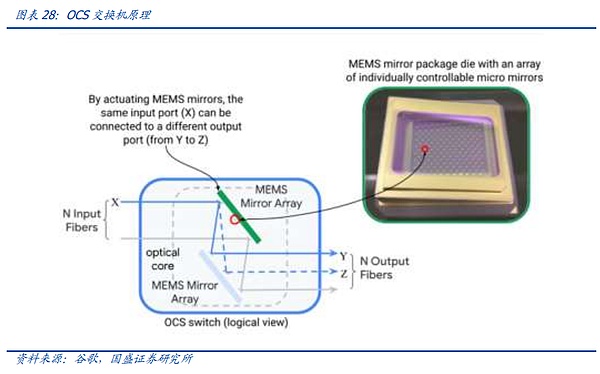
하지만 AI 경쟁이 공식적으로 거인 죽이기에 들어감에 따라 후반기에 접어들면서 거대 기업이 보유한 AI 클러스터의 규모가 빠르게 확대되고 있으며, 거대 기업은 성숙한 투자 계획, 네트워크 아키텍처의 자체 연구 능력, 충분한 자금을 보유하고 있어 현재 구글 등 거대 고객은 노드 규모가 계속 확대되면서 OCS 시스템의 연구 개발 및 구축에 박차를 가하고 있습니다.
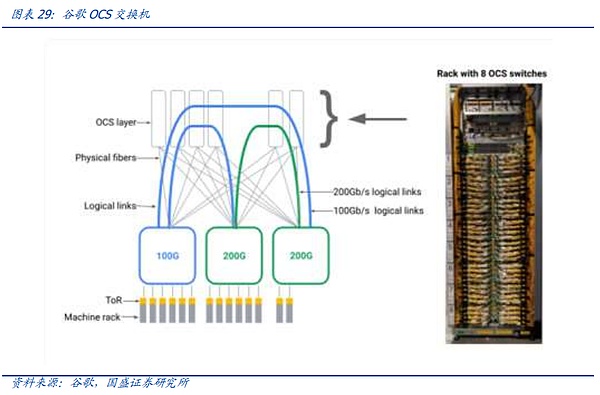
그리고 전통적인 전기 스위칭 구성 요소로 돌아가서 오늘날의 전기적 스위치 혁신은 위의 프로토콜 부분 외에도 프로세스 반복, 기능 혁신 등을 포함한 칩 부분에 더 중점을두고 있으며 동시에 Broadcom 및 기타 스위치 공급 업체와 같은 다른 다운 스트림 고객 칩에서 자체 IP를 사용하여 자체 및 고객 결합이 강화되고 전쟁 파벌의 통신 프로토콜과 결합하여 AI 시대에 스위치 산업은 공식적으로 칩 동맹으로 바뀌 었습니다. 전방위 경쟁.
4.3 네트워크 아키텍처 혁신: 리프 릿지 이후 어디로 갈 것인가?
네트워크 아키텍처는 프로토콜과 하드웨어 외에 통신 시스템의 중요한 부분입니다. 아키텍처는 서버의 데이터가 어떤 경로를 통해 전송될지 결정하며, 좋은 네트워크 아키텍처는 지연 시간을 줄이고 안정성을 보장하면서 전체 도메인에서 데이터 트래픽에 액세스할 수 있도록 합니다. 동시에 네트워크 아키텍처는 유지 관리 및 확장이 용이해야 하므로 아키텍처는 설계부터 물리적 엔지니어링에 이르기까지 통신 시스템의 중요한 부분입니다.
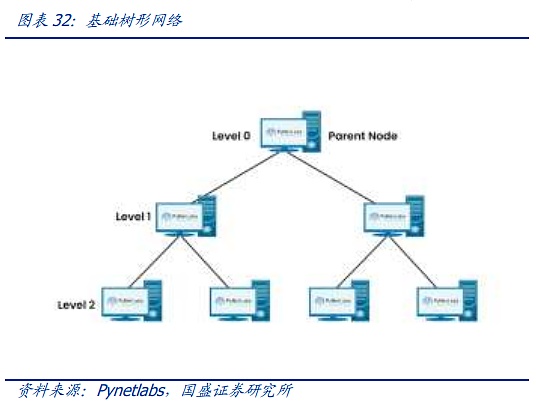
현대 사회의 네트워크 아키텍처는 매트릭스 다이어그램 구조의 전화 시대부터 현대 네트워크가 인프라를 구축하기위한 CLOS 네트워크 모델에 이르기까지 CLOS 아키텍처의 핵심은 다수의 소규모 저비용 장치로 복잡하고 대규모 네트워크를 구축하는 것입니다. CLOS 모델을 기반으로 스타, 체인, 링, 트리 및 기타 아키텍처와 같은 다양한 네트워크 토폴로지가 점차 진화했으며, 이후 트리 네트워크가 점차 주류 아키텍처가 되었습니다.


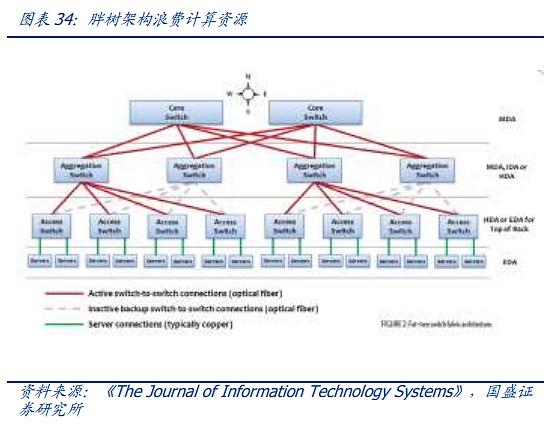
트리 아키텍처는 3세대에 걸쳐 발전해 왔으며, 1세대는 가장 전통적인 트리 아키텍처로 각 계층의 대역폭이 엄격한 2:1 수렴, 즉 100M 2개가 특징인 것이 특징입니다. 스위치에 대한 다운 스트림 장비 액세스, 100M 데이터 스트림까지 고정 출력, 더 작은 데이터 스트림이 도착하기 전 클라우드 컴퓨팅에 직면하여이 아키텍처는 여전히 대처할 수 있지만 인터넷과 클라우드 컴퓨팅 시대의 도래로 대역폭의 수렴은 트래픽 전송 요구 사항을 충족 할 수 없으므로 데이터 센터에서 "Fat Tree"라는 일종의 향상된 아키텍처가 점차적으로 사용되고 있습니다. 따라서 데이터 센터에서는 "팻 트리"라는 개선된 아키텍처가 점차적으로 사용되고 있습니다. 팻 트리 아키텍처는 3계층의 스위치를 사용하며, 핵심 개념은 많은 수의 저성능 스위치를 사용하여 대규모 비차단 네트워크를 구축하는 것입니다. 모든 통신 패턴이 네트워크 카드의 대역폭에 도달할 수 있는 경로는 항상 존재하지만, 최상위 계층 스위치의 수렴 비율을 최대한 낮게 유지하기 위해 상위 계층에서는 고급 스위치가 사용됩니다.

팻 트리 아키텍처는 최신 데이터센터 연결의 기반을 제공하지만 대역폭 낭비, 확장 어려움, 대규모 클라우드 컴퓨팅 지원의 어려움 등의 문제를 안고 있기도 합니다. 그러나 대역폭 낭비, 확장의 어려움, 대규모 클라우드 컴퓨팅 지원의 어려움 등 내재된 문제가 있습니다. 네트워크 규모가 점점 더 커지는 상황에서 기존 팻 트리의 단점은 점점 더 분명해지고 있습니다.

팻 트리를 기반으로 진화한 현재 고급 데이터 센터 및 AI 클러스터는 리프 리지 (Spine-Leaf) 아키텍처를 사용하며, 팻 트리에 비해 리프 리지는 평탄화에 더 중점을두고 있습니다. 복잡한 3계층 팻 트리에 비해 각 하위 레벨 스위치(리프)는 각 상위 레벨 스위치(스파인)에 연결되어 풀 메시 토폴로지를 형성합니다. 리프 계층은 서버 및 기타 장치에 연결하는 데 사용되는 액세스 스위치로 구성되며 스파인 계층은 네트워크의 백본이며 모든 리프 연결을 담당합니다. 이 구성에서는 두 물리적 서버 간의 데이터 전달, 리프와 스파인 스위치를 통과하는 노드 수를 고정하여 동서 트래픽 부담과 지연을 방지할 뿐만 아니라 스파인 스위치의 확장을 통해 매우 비싼 코어 레이어 스위치의 광범위한 사용을 피하고 언제든지 스파인 레이어 스위치의 수를 늘려 전체 네트워크를 확장할 수 있습니다.
오늘날 많은 장점을 가진 리프 리지는 주류 AI 클러스터와 헤드 데이터센터의 표준 아키텍처가 되었지만, 단일 AI 클러스터 내의 노드 수가 급격히 확장되고 AI 학습 중 지연 시간을 극도로 추구하면서 팻트리 아키텍처의 몇 가지 문제가 표면화되기 시작했고, < 강한>첫째, 규모가 급격히 확장될 때 스위치의 용량 캡 업데이트가 그래픽 클러스터의 진화 속도를 충족시킬 수 있는지 여부. 둘째, 수백만 개의 컴퓨팅 노드를 상호 연결하는 상황에서 리프 리지가 여전히 비용 효율적일까요?
리프 릿지의 위의 두 가지 질문은 네트워크 아키텍처 수준에서의 혁신으로 이어지며, 저희는 첫째, 매우 큰 노드 수를 위한 새로운 아키텍처 추구, 둘째, 소프트웨어 최적화를 통한 HB-DOMIN 오버레이 확장 등의 접근 방식을 통해 두 가지 방향에 초점을 맞추고 있습니다. 첫 번째는 초대형 노드 수를 위한 새로운 아키텍처를 추구하는 것이고, 두 번째는 모델에 대한 완전한 이해를 바탕으로 소프트웨어 최적화를 통해 HB-DOMIN 오버레이를 확장하는 등 노드 간 트래픽 통신을 줄이는 것입니다.
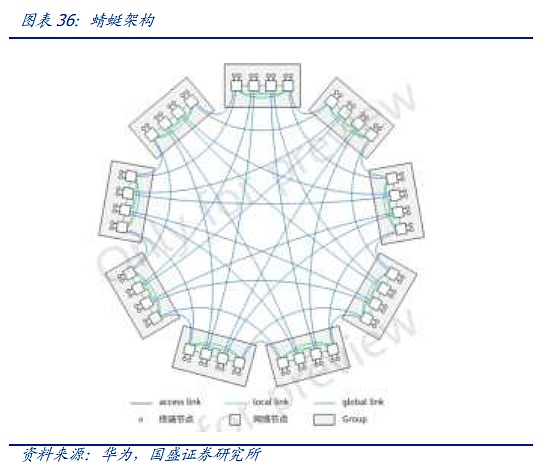
첫 번째 솔루션의 대표적인 것이 2008년에 처음 제안되어 HPC에 처음 사용된 Dragonfly 아키텍처인데, 확장할 때마다 배선을 다시 해야 하고 배선이 복잡하기 때문에 Cisco HB-DOMIN에 비해 스위치처럼 사용하기 쉽지는 않습니다. 그러나 확장할 때마다 배선을 다시 해야 하고 배선이 더 복잡하기 때문에 CLOS 아키텍처에 비해 스위치를 적게 사용하지만 결국 주류가 되지 못했습니다. 그러나 오늘날 대규모 노드와 값비싼 AI 하드웨어 CAPEX의 맥락에서 드래곤플라이 아키텍처는 점차 업계의 선두에서 다시 주목받기 시작했습니다. 현재 위에서 언급 한 OCS 광 스위칭 시스템의 출현으로 복잡한 케이블 링이 OCS를 통해 단순화 될 것으로 예상되는 두 번째 거인 인 AI 클러스터 계획 및 CAPEX 템포가 더 명확 해 지므로 더 번거로운 확장 프로세스가 더 이상 제약이되지 않습니다. 셋째, 잎 능선에 비해 지연의 잠자리는 물리적 수준에서 더 유리하며, 이제 Groq 및 기타 AI 칩의 지연에 더 민감한 다른 아키텍처가 클러스터를 구축하기 위해 아키텍처를 사용하기 시작했습니다.

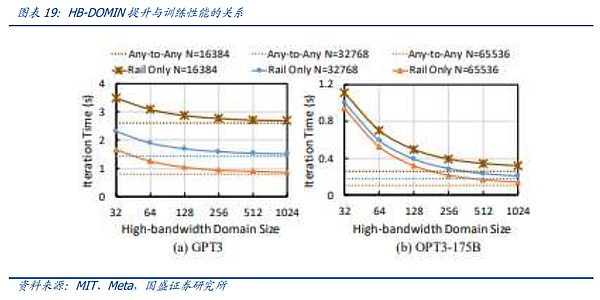
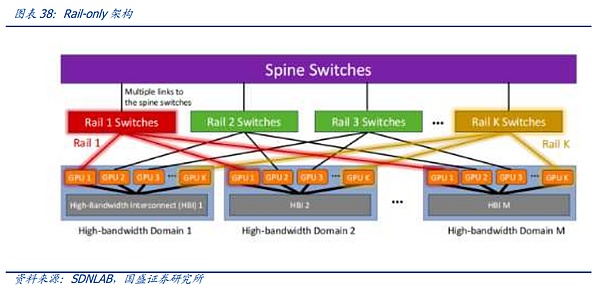
두 번째 솔루션의 대표적인 것 중 하나는 Meta와 MIT가 제안한 Rail-only 아키텍처입니다. Rail-Only 아키텍처는 GPU를 고대역폭으로 그룹화하여 작동합니다. Rail-Only 아키텍처는 GPU를 그룹화하여 고대역폭 상호 연결 도메인(HB 도메인)을 형성한 다음 이러한 HB 도메인 내의 특정 GPU를 특정 Rail 스위치로 교차합니다. 도메인 간 통신의 라우팅 및 스케줄링 복잡성이 증가하지만 전체 아키텍처는 HB 도메인과 Rail 스위치의 합리적인 설계를 통해 스위치 사용을 크게 줄여 네트워크 통신 소비를 최대 75%까지 줄일 수 있습니다. 이 아키텍처는 또한 위에서 언급한 슬라이스 간 통신을 통한 혁신을 암시하며, 확장된 HB-DOMIN 도메인을 통해 트레이닝 슬라이싱 및 소프트웨어 최적화를 구현할 수 있는 더 많은 공간을 제공하므로 HB-DOMIN 간의 스위치 요구 사항을 줄이고 초대형 클러스터에서 네트워크 비용을 절감할 수 있는 여지를 제공합니다.
4.4 데이터센터 클러스터링의 혁신: 미래 산술 네트워크의 궁극적인 형태는?
AI 클러스터의 규모가 계속 커지면서 단일 데이터센터의 용량은 결국 자본 지출이나 통신 네트워크가 수용할 수 있는 최대 노드 수가 아니라 데이터센터의 로컬 또는 비용 효율적인 전력 자원의 용량 측면에서 상한선에 도달하게 될 것입니다. 이 상한은 자본 지출이나 통신 네트워크가 처리할 수 있는 노드 수에 대한 상한이 아닙니다.
2024년 초, Microsoft와 OPENAI는 2028년에 슈퍼컴퓨터인 스타게이트를 구축하는 방안을 검토하기 시작했는데, The Information에 따르면 이 프로젝트에는 1,000달러 이상의 투자가 필요하고, 1,000만달러 이상의 투자가 필요할 수 있으며, The Information에 따르면 1,000만달러 이상의 투자가 필요할 수 있다고 합니다. 더 인포메이션에 따르면 스타게이트의 최종 전체 계획에는 1,000달러 이상의 투자가 포함될 수 있으며 최대 5기가와트의 전력을 사용해야 하는데, 이는 칩과 자금 조달 외에 프로젝트에서 가장 시급한 문제 중 하나가 될 것입니다.
따라서 오늘날 업계에서는 스마트 컴퓨팅 센터 간 장거리 상호 연결을 통해 비용 효율적인 전력으로 산술 연산이 균등하게 분산되도록 하여 단일 지역 과다 책정으로 인한 산술 비용 증가 또는 산술 용량 제한을 피하는 방법이 최전선에 서 있습니다. 데이터센터 간 상호 연결은 클러스터 내 상호 연결과 비교하여 매우 다른 프로토콜, 하드웨어 등을 사용합니다.
오늘날의 데이터 센터는 일반적으로 상위 계층 스위치 또는 코어 스위치를 통해 외부 네트워크에 연결되는 반면, 데이터 센터 인터넷 DCI는 장거리 코히어런트 광 모듈을 사용하는 통신사가 구축하는 경우가 많지만 전송 속도는 더 길지만 광 모듈을 사용하는 데이터 센터에 비해 속도와 안정성이 큰 차이가 있고 가격도 높습니다. 동시에 가격이 높기 때문에 비용 절감, 아키텍처 재구축은 고려해야 할 필요성 이전에 문제의 공식적인 구성에 있습니다.
그러나 시야를 더 거시적 인 관점으로 당기면 단일 산술 센터는 본질적으로 이전과 유사하고 더 강력한 HB-DOMIN 도메인이므로 이러한 유형의 연결의 미래 발전 경로는 한편으로는 일관된 광 모듈 산업에 대한 투자를 가속화하여 AI 센터 상호 연결 베어러를 차지할 수 있도록하는 것이라고 믿습니다. 이러한 유형의 연결을 위한 미래의 길은 코히어런트 광 모듈 산업에 대한 투자를 가속화하여 AI 센터 상호 연결의 부하와 용량 요구 사항을 감당할 수 있도록 하고, 한편으로는 데이터 센터 내 상호 연결 밀도를 강화하고, 데이터 센터를 단일 HB 도메인과 더 유사하게 만들고, 마지막으로 분산 및 교육 소프트웨어를 혁신하여 교차 IDC 데이터와 모델 슬라이싱 및 병렬화를 가능하게 하는 것이라고 생각합니다.
5. 투자 조언: 혁신은 멈추지 않는다, 핵심 링크와 새로운 변수 모두
칩과 마찬가지로 통신 시스템도 AI 수요에 의해 주도되고 있습니다. 통신 시스템 역시 AI 수요에 힘입어 혁신을 가속화하고 있지만, 한 두 명의 '천재'에 의존해 아키텍처와 아이디어를 혁신하는 칩 산업과 달리 통신 하드웨어와 소프트웨어는 많은 엔지니어가 다양한 측면에서 함께 혁신하고 노력해야 하는 체계적인 프로젝트입니다. 가장 기본적인 스위칭 칩인 광 칩부터 스위치의 상위 계층인 광 모듈, 통신 아키텍처, 통신 프로토콜 설계, 운영 및 유지 보수 후 시스템 구성에 이르기까지 각 링크는 다른 기술 거인과 수많은 엔지니어에 해당합니다.
우리는 기업가 적 투자에 더 관심이있는 칩 산업에 비해 통신 산업에 대한 투자가 더 추적 가능하며 산업의 반복은 종종 거인에 의해 시작되고 구현되며 동시에 통신 시스템 엔지니어링의 안정성 요구 사항으로 인해 대규모 AI 클러스터의 공급 업체 선택은 네트워크 아키텍처와 프로토콜이 어떻게 변경되는지에 관계없이 하드웨어에서 우선 스위치와 프로토콜이 변경되는지에 관계없이 매우 엄격하다고 믿습니다. 네트워크 아키텍처와 프로토콜이 어떻게 변화하든, 스위치와 광 모듈은 항상 시스템의 가장 기본적인 빌딩 블록이 될 것이며, 스케일링 법칙이 효과적인 한 인간이 매개 변수를 추구하는 과정이 여전히 존재하는 한 빌딩 블록에 대한 수요는 항상 계속 될 것입니다. 물론 LPO, 잠자리 아키텍처, 철도 전용 아키텍처와 같이 관련 장치의 비율이나 가치를 줄일 수 있지만 비용 절감은 항상 AI의 최우선 과제였으며 수요 확대 후 비용 절감은 업계에 더 넓은 공간을 가져올 것입니다. 이것이 첫 번째 AI 통신 투자는 핵심 개념과 링크를 파악해야합니다.
동시에 혁신 링크의 경우, 우리는 또한 새로운 기술의 역학을 적극적으로 추적하여 구성 요소 변경의 핵심 링크가 미래에 가져온 새로운 기술 반복에 의해 발견해야하며, 우선 구리 케이블 수요에 의해 가져온 비용 효율적인 HB-DOMIN 도메인 구축이 먼저 출시되고, 새로운 기술에 의해 가져온 바이어스 보존 광섬유, 광섬유, 광섬유 등과 같은 장거리 데이터 센터 인 CPO가 그 뒤를 따를 것입니다. 두 번째는 바이어스 보존 광섬유, 미끼 도핑 광섬유 및 기타 특수 광섬유 수요와 같은 CPO, 장거리 데이터 센터, 마지막으로 모든 광 스위치, 울트라 이더넷 얼라이언스 등으로 국내 스위치가 산업 기회의 진화를 가속화할 수 있도록 하는 것입니다.
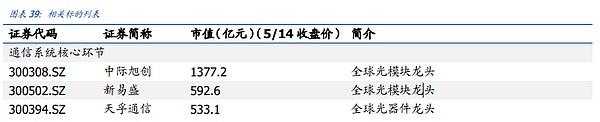

6. 위험 팁
1. AI 수요가 예상보다 적음.
현재 AI는 모델 개발 단계에 머물러 있고, 구체적인 최종 제품 개발은 아직 진행 중이며, 후속 최종 수요가 예상보다 적으면 AI에 대한 글로벌 수요가 감소할 위험이 있습니다.
2. 스케일링 법칙의 실패.
현재 글로벌 용량 방출의 주요 근거는 모델을 개선하기 위해 매개변수 스케일을 쌓는 법칙이 여전히 유효하며, 매개변수 스택이 상한에 도달하면 컴퓨팅 파워 수요에 영향을 미친다는 것입니다.
3. 업계 경쟁 심화.
글로벌 연산 산업과 네트워킹 산업은 AI에 힘입어 빠르게 성장하고 있으며, 경쟁을 위해 너무 많은 신규 진입자가 유입되면 기존 선도 기업의 이익이 희석될 것입니다.
<nil>
Chris에테나, UST처럼 망할까? 에테나와 UST 황금금융의 차이점 해부,에테나는 UST식 위기로 무너질까?
 JinseFinance
JinseFinance강세장이 실제로 돌아왔지만 이번에는 더 활발하고 많은 사람들이 예상했던 것보다 약간 일찍 나타났습니다. 이번 시장이 무엇이 다른지 자세히 살펴보겠습니다.
JinseFinance암호화폐 투자 방법은 진화합니다: ICO와 IEO. ICO의 역사: 이더리움의 기념비적인 성공. IEO가 안전한 대안으로 부상. ICO와 IEO 모두 위험은 상존합니다. 투자자들은 철저한 조사를 할 것을 촉구합니다.
 Bernice
Bernice3개의 BTC ETF와 3개의 BTC 선물을 보여주는 차트입니다.
JinseFinance차이나 모바일이 출시한 LinkNFT는 홍콩의 디지털 환경을 변화시켜 물리적 세계와 가상 세계 사이의 간극을 좁히고 웹 3.0의 새로운 시대를 예고하고 있습니다.
 Huang Bo
Huang Bo이 출판물은 NFT 플랫폼 개발을 위해 약 390,000 달러를 할당했으며 프로젝트에 참여할 블록체인 전문가를 모집하고 있습니다.
 Clement
Clement이 회사는 또한 중국의 국가 지원 블록체인 기반 서비스 네트워크의 창립 멤버로서 블록체인 기술에 참여한 것으로도 유명합니다.
 Brian
Brian Cointelegraph
Cointelegraph이 기사에서는 사이드체인과 L2 솔루션이 무엇이며 확장성에 어떻게 도움이 되는지 보여줍니다.
 Ftftx
Ftftx