IOSG|Deeply cultivating the crypto game sinking market——Ronin Thesis
During this period when there are not many incremental users, there is already an ecosystem that has maintained a very high user base and growth.
 JinseFinance
JinseFinance

At first glance, AI x Web3 appear to be separate technologies, each based on fundamentally different principles and serving different functions. However, a deeper look reveals that the two technologies have the opportunity to balance each other's trade-offs, and each other's unique strengths can complement and enhance each other. Balaji Srinivasan brilliantly articulated this concept of complementary capabilities at the SuperAI conference, inspiring a detailed comparison of how these technologies interact.
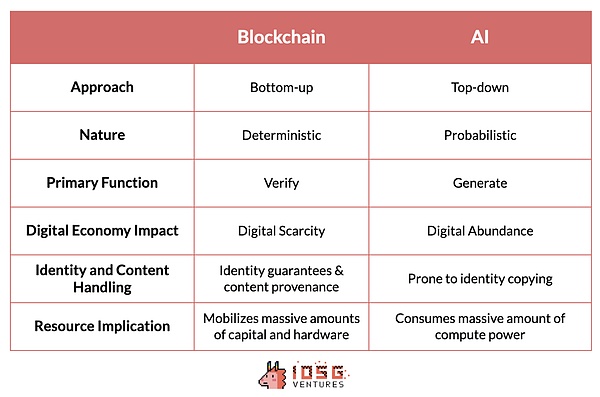
Token took a bottom-up approach, emerging from the decentralized efforts of anonymous cyberpunks and evolving through the collaborative efforts of numerous independent entities around the world for more than a decade. In contrast, artificial intelligence has been developed through a top-down approach, dominated by a small number of tech giants. These companies set the pace and dynamics of the industry, and the barrier to entry is determined more by resource intensity than technical complexity.
The two technologies also have very different natures. In essence, tokens are deterministic systems that produce unchangeable results, such as the predictability of hash functions or zero-knowledge proofs. This is in stark contrast to the probabilistic and generally unpredictable nature of AI.
Similarly, cryptography excels at verification, ensuring the authenticity and security of transactions and establishing trustless processes and systems, while AI focuses on generation, creating rich digital content. However, in the process of creating digital abundance, ensuring the source of content and preventing identity theft becomes a challenge.
Fortunately, tokens provide the opposite concept of digital abundance - digital scarcity. It provides relatively mature tools that can be generalized to AI technology to ensure the reliability of content sources and avoid identity theft problems.
A significant advantage of tokens is their ability to attract large amounts of hardware and capital into a coordinated network to serve a specific goal. This capability is particularly beneficial for artificial intelligence, which consumes a lot of computing power. Mobilizing underutilized resources to provide cheaper computing power can significantly improve the efficiency of artificial intelligence.
By contrasting these two technologies, we can not only appreciate their individual contributions, but also see how they work together to create new paths in technology and economy. Each technology can complement the shortcomings of the other to create a more integrated and innovative future. In this blog post, we aim to explore the emerging AI x Web3 industry landscape, focusing on some emerging verticals at the intersection of these technologies.
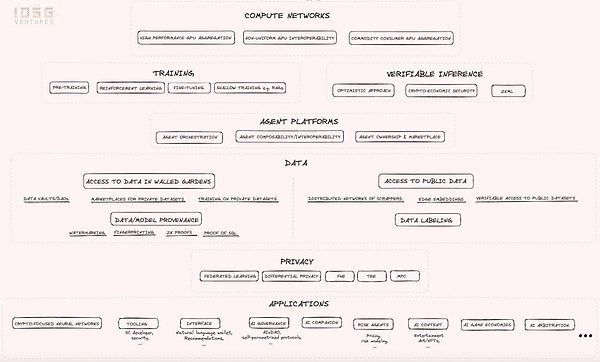
Source: IOSG Ventures

The industry map first introduces computing networks, which attempt to solve the problem of limited GPU supply and try to reduce computing costs in different ways. The following are worth focusing on:
Non-uniform GPU interoperability: This is a very ambitious attempt with high technical risks and uncertainties, but if successful, it will have the potential to create results of great scale and impact, making all computing resources interchangeable. Essentially, the idea is to build compilers and other prerequisites so that any hardware resource can be plugged in on the supply side, and on the demand side, the non-uniformity of all hardware will be completely abstracted so that your computing request can be routed to any resource in the network. If this vision succeeds, it will reduce the current dependence on CUDA software that is completely dominated by AI developers. Although the technical risks are high, many experts are highly skeptical about the feasibility of this approach.
High-performance GPU aggregation: Integrate the world's most popular GPUs into a distributed and permissionless network without worrying about interoperability issues between non-uniform GPU resources.
Commodity consumer GPU aggregation: refers to the aggregation of some lower-performance GPUs that may be available in consumer devices, which are the most underutilized resources on the supply side. It caters to those who are willing to sacrifice performance and speed for a cheaper and longer training process.
2.2 Training and Inference
Computation networks are mainly used for two main functions: training and inference. The demand for these networks comes from Web 2.0 and Web 3.0 projects. In the Web 3.0 field, projects like Bittensor use computing resources for model fine-tuning. On the inference side, Web 3.0 projects emphasize the verifiability of the process. This focus has given rise to verifiable inference as a market vertical, where projects are exploring how to integrate AI inference into smart contracts while maintaining the principle of decentralization.
Next is the Intelligent Agent Platform, and the graph outlines the core problems that startups in this category need to solve:
Agent interoperability and discovery and communication capabilities: Agents are able to discover and communicate with each other.
Agent cluster building and management capabilities: Agents are able to form clusters and manage other agents.
Ownership and market for AI agents: Provide ownership and market for AI agents.
These features emphasize the importance of flexible and modular systems that can be seamlessly integrated into a variety of blockchain and artificial intelligence applications. AI agents have the potential to revolutionize how we interact with the Internet, and we believe that agents will leverage infrastructure to support their operations. We envision AI agents relying on infrastructure in the following ways:
Leveraging a distributed scraping network to access real-time network data
Using DeFi channels for inter-agent payments
Requiring an economic deposit not only to penalize when misbehavior occurs, but also to improve the discoverability of agents (i.e., leveraging the deposit as an economic signal in the discovery process)
Leveraging consensus to decide which events should result in slashing
Open interoperability standards and agent frameworks to support the construction of composable collectives
Evaluating past performance based on an immutable data history and selecting appropriate collectives of agents in real time

Source: IOSG Ventures
2.4 Data Layer
In the convergence of AI x Web3, data is a core component. Data is a strategic asset in the AI competition and constitutes a key resource along with computing resources. However, this category is often overlooked because most of the industry's attention is focused on the computing layer. In fact, primitives provide many interesting value directions in the data acquisition process, mainly including the following two high-level directions: Access to public Internet data: This direction aims to build a distributed crawler network that can crawl the entire Internet in a few days, obtain massive data sets, or access very specific Internet data in real time. However, to crawl a large number of data sets on the Internet, the network requirements are very high, and at least a few hundred nodes are required to start some meaningful work. Fortunately, Grass, a distributed crawler node network, already has more than 2 million nodes actively sharing Internet bandwidth to the network, with the goal of crawling the entire Internet. This shows the great potential of economic incentives in attracting valuable resources.
While Grass provides a level playing field in terms of public data, there is still a challenge in leveraging the underlying data - namely, access to proprietary datasets. Specifically, there is still a large amount of data that is kept in a privacy-preserving manner due to its sensitive nature. Many startups are leveraging some cryptographic tools that enable AI developers to build and fine-tune large language models using the underlying data structures of proprietary datasets while keeping sensitive information private.
Federated Learning, Differential Privacy, Trusted Execution Environments, Fully Homomorphic, and Multi-Party ComputationTechniques offer different levels of privacy protection and trade-offs. An excellent overview of these techniques is summarized in Bagel's research article (https://blog.bagel.net/p/with-great-data-comes-great-responsibility-d67). These techniques not only protect data privacy during machine learning, but also enable comprehensive privacy-preserving AI solutions at the computational level.
2.5 Data and Model Provenance
Data and model provenance techniques aim to establish processes that can assure users that they are interacting with the expected models and data. In addition, these techniques provide assurances of authenticity and provenance. Take watermarking as an example. Watermarking is one of the model provenance techniques. It embeds signatures directly into machine learning algorithms, more specifically directly into model weights, so that it can be verified at retrieval time whether the inference comes from the expected model.
2.6 Application
In terms of application, the design possibilities are endless. In the industry landscape above, we list some development cases that are particularly exciting as AI technology is applied in the field of Web 3.0. Since most of these use cases are self-descriptive, we will not make additional comments here. However, it is worth noting that the intersection of AI and Web 3.0 has the potential to reshape many verticals in the field, as these new primitives provide developers with more freedom to create innovative use cases and optimize existing ones.

The AI x Web3 convergence brings a promising future full of innovation and potential. By leveraging the unique strengths of each technology, we can solve various challenges and open up new technological paths. As we explore this emerging industry, the synergy between AI x Web3 can drive progress and reshape our future digital experiences and the way we interact on the web.
The convergence of digital scarcity and digital abundance, the mobilization of underutilized resources to achieve computational efficiency, and the establishment of secure, privacy-preserving data practices will define the era of the next generation of technological evolution.
However, we must recognize that the industry is still in its infancy and the current landscape may become obsolete in a short period of time. The rapid pace of innovation means that today's cutting-edge solutions may soon be replaced by new breakthroughs. Nevertheless, the foundational concepts explored - such as computing networks, proxy platforms, and data protocols - highlight the huge possibilities of the convergence of AI and Web 3.0.
During this period when there are not many incremental users, there is already an ecosystem that has maintained a very high user base and growth.
JinseFinanceFully homomorphic encryption (FHE) is a class of cryptographic schemes that allows computations to be performed on encrypted data (ciphertext) without decrypting the data, opening up a range of use cases for privacy and data protection.
JinseFinanceFarcaster has built a strong infrastructure layer that paves the way for a decentralized social graph, tracking users and their overall social data.
JinseFinanceBitVM, Layer 2, BTC, IOSG | BitVM: The dawn of Bitcoin programmability Golden Finance, the rapid expansion of Bitcoin expansion solutions
JinseFinanceWe are at the dawn of AI and Web3, and the integration of AI and blockchain is still in its early stages compared to other industries.
JinseFinanceThere has been a lot of discussion recently around EigenLayer's re-staking and LRT. Users are placing bets around the protocol's potential airdrop expectations, and re-staking has become the hottest narrative in the Ethereum ecosystem. This article will briefly discuss some of the author’s thoughts and opinions on LRT.
JinseFinanceAIGC, IOSG|GPU supply crisis: The road to disruption for AI startups Golden Finance, as the supply of new GPUs tightens, where does blockchain play a role?
JinseFinance2023 is a year to be proud of and move forward boldly for IOSG Ventures.
JinseFinanceAs cryptocurrency market caps grow and more people have disposable capital on-chain, the prediction markets industry could be profitable, or at least useful.
JinseFinance像《黑暗森林》这样的全链游戏已经证明,你可以把游戏逻辑都放在链上,且由于其具有无许可的互操作性,鼓励了社区创造新工具、联盟和 DAO 等等。
 Others
Others
