Một ngày đầu tháng 12 năm 2012, một cuộc đấu giá bí mật đã diễn ra tại một khách sạn sòng bạc ở khu nghỉ mát trượt tuyết Lake Tahoe của Mỹ.
Hồ Tahoe nằm ở ngã ba California và Nevada. Đây là hồ trên núi lớn nhất ở Bắc Mỹ. Nó có mặt hồ giống như ngọc bích và mặt trên- Những con đường mòn tuyết nổi bật Nó được giới thiệu trong "Bố già 2" Được quay ở đây, Mark Twain đã từng nán lại đây và vì nó chỉ cách Khu vực Vịnh San Francisco hơn 200 dặm nên nó thường được gọi là "Khu vườn sau Thung lũng Silicon" , và những tên tuổi lớn như Zuckerberg và Larry Ellison cũng có mặt ở đây. Khu bao vây này chiếm một khu vực miền núi và được sử dụng để xây dựng biệt thự.
Mục tiêu của cuộc đấu giá bí mật là DNNresearch, một công ty mới thành lập được một tháng và chỉ có ba nhân viên. Người sáng lập là Jeff, một giáo sư tại trường. Đại học Toronto Geoffrey Hinton và hai sinh viên của ông.
Công ty này không có bất kỳ sản phẩm hay tài sản hữu hình nào, nhưng danh tính của những người cầu hôn cho thấy sức nặng của nó -Bốn người mua là Google, Microsoft, DeepMind và Baidu.

Harrah's Hotel tổ chức một cuộc đấu giá bí mật, Lake Tahoe, 2012
Hinton, 65 tuổi, đã già, gầy và có vấn đề về đĩa đệm cột sống thắt lưng Đau đớn, anh ngồi trên sàn phòng 703 của khách sạn và đặt ra luật lệ cho cuộc đấu giá - giá khởi điểm là 12 triệu đô la, với giá thầu ít nhất là 1 triệu đô la.
Kêu gọi dừng lại và quyết định bán công ty cho người trả giá cuối cùng - Google.
Thật thú vị, một trong những nguồn của cuộc đấu giá trị giá 44 triệu USD này đến từ Google 6 tháng trước.
Tháng 6 năm 2012, bộ phận nghiên cứu Google Brain của Google đã tiết lộ kết quả nghiên cứu của dự án The Cat Neurons (tức là "Google Cat"). Nói một cách đơn giản, dự án này là sử dụng thuật toán để xác định mèo trong video YouTube. Nó được khởi xướng bởi Andrew Ng, người đã gia nhập Google từ Stanford và đã thu hút huyền thoại Google Jeff Dean tham gia cùng mình. Nó cũng thu được một khoản ngân sách lớn từ người sáng lập Google, Larry Page. .
Dự án Google Cat đã xây dựng mạng lưới thần kinh, tải xuống một số lượng lớn video từ YouTube và không đánh dấu chúng, cho phép mô hình quan sát và tìm hiểu các đặc điểm số mèo và sau đó 16.000 CPU trải khắp các trung tâm dữ liệu của Google đã được sử dụng để đào tạo (GPU bị từ chối nội bộ vì chúng quá phức tạp và tốn kém) và cuối cùng đạt được độ chính xác nhận dạng là 74,8%. Con số này gây sốc cho cả ngành.
Ng Enda đã rời bỏ dự án "Google Cat" trước khi kết thúc và cống hiến hết mình cho dự án giáo dục Internet của riêng mình. Trước khi rời đi, anh đã đề nghị Hinton đến công ty để thay thế. anh ấy làm việc. Trước lời mời, Hinton cho biết anh sẽ không rời trường đại học và chỉ sẵn sàng đến Google để “ở lại một mùa hè”. Do tính chất đặc biệt trong quy định tuyển dụng của Google, Hinton, 64 tuổi, đã trở thành thực tập sinh mùa hè lớn tuổi nhất trong lịch sử Google.
Hinton đã đi đầu trong lĩnh vực trí tuệ nhân tạo từ những năm 1980. Với tư cách là một giáo sư, ông có một gia đình giàu có (trong đó có Ng Enda) và là bậc thầy trong lĩnh vực này. lĩnh vực học tập sâu. Vì vậy, khi tìm hiểu chi tiết kỹ thuật của dự án Google Cat, anh ấy đã ngay lập tức nhìn ra lỗ hổng tiềm ẩn đằng sau sự thành công của dự án: "Họ đã chạy sai mạng thần kinh và sử dụng sai sức mạnh tính toán."
Cùng một nhiệm vụ, Hinton nghĩ mình có thể làm tốt hơn. Vì thế sau khi “thời gian thực tập” ngắn ngủi kết thúc, anh đã ngay lập tức bắt tay vào hành động.
Hinton đã tìm thấy hai học trò của mình - Ilya Sutskever và Alex Krizhevsky, cả hai đều là người Do Thái sinh ra ở Liên Xô. Những người trước đây cực kỳ tài năng về toán học. người thứ hai giỏi triển khai kỹ thuật. Cả ba đã hợp tác chặt chẽ với nhau để tạo ra một mạng lưới thần kinh mới, sau đó ngay lập tức tham gia Cuộc thi nhận dạng hình ảnh ImageNet (ILSVRC) và cuối cùng đã giành chức vô địch với tỷ lệ nhận dạng chính xác đáng kinh ngạc là 84%.
Vào tháng 10 năm 2012, nhóm của Hinton đã giới thiệu thuật toán vô địch AlexNet tại Hội nghị Thị giác Máy tính ở Florence. So với Google Cat, sử dụng 16.000 CPU, AlexNet chỉ sử dụng 4. GPU của NVIDIA, nó đã gây ra một chấn động lớn trong giới học thuật và ngành công nghiệp. Bài báo của AlexNet đã trở thành một trong những bài báo có ảnh hưởng nhất trong lịch sử khoa học máy tính. Nó đã được trích dẫn hơn 120.000 lần, trong khi Google Cat nhanh chóng bị lãng quên.

Bộ ba nghiên cứu DNN
Yu Kai, người từng giành chức vô địch cuộc thi ImageNet đầu tiên, sau khi đọc bài báo đã vô cùng phấn khích, "như bị điện giật". Yu Kai là một chuyên gia về deep learning sinh ra ở Jiangxi. Anh ấy vừa chuyển từ NEC sang Baidu. Anh ấy đã ngay lập tức viết một email cho Hinton và bày tỏ ý định hợp tác. Hinton đã sẵn sàng đồng ý và chỉ cần gói gọn mình và hai học sinh vào một gia đình. công ty đã mời người mua đến đấu giá, và thế là có cảnh mở đầu.
Sau khi cuộc đấu giá thất bại, một cuộc cạnh tranh lớn hơn bắt đầu: Google theo đuổi chiến thắng và mua lại DeepMind vào năm 2014, "tất cả những anh hùng trên thế giới đều ở trong đó"; ra mắt AlphaGo vào năm 2016, gây chấn động thế giới; Baidu, thua Google, quyết định đặt cược vào AI và đầu tư hàng trăm tỷ trong mười năm. Yu Kai sau đó đã giúp Baidu mời Ng Enda, và anh ấy đã rời bỏ công việc của mình vài năm. sau đó để bắt đầu chân trời.
Microsoft có vẻ hơi chậm chạp nhưng cuối cùng đã giành được giải thưởng lớn nhất - OpenAI, người sáng lập bao gồm Hinton. Một trong những sinh viên là Ilya Sutskever. Bản thân Hinton sẽ ở lại Google cho đến năm 2023, trong thời gian đó ông đã giành được Giải thưởng ACM Turing. Tất nhiên, so với 44 triệu USD của Google (Hinton nhận được 40%), giải thưởng 1 triệu USD của Giải thưởng Turing có vẻ chỉ là tiền tiêu vặt.
Từ Google Cat vào tháng 6, đến bài báo AlexNet vào tháng 10, đến cuộc đấu giá ở Lake Tahoe vào tháng 12, trong gần 6 tháng, AI Hầu như đều là điềm báo trước của làn sóng đã bị chôn vùi - sự thịnh vượng của deep learning, sự trỗi dậy của GPU và NVIDIA, sự thống trị của AlphaGo, sự ra đời của Transformer, sự xuất hiện của ChatGPT... phong trào vĩ đại của kỷ nguyên thịnh vượng dựa trên silicon đã đóng vai trò đầu tiên ghi chú.
Trong 180 ngày từ tháng 6 đến tháng 12 năm 2012, số phận của loài người sống dựa vào carbon đã thay đổi mãi mãi - chỉ một số ít người nhận ra điều này.
Liquid Cat
Trong số rất ít người này, Stanford Giáo sư đại học Li Feifei là một trong số đó.
Năm 2012, khi có kết quả cuộc thi ImageNet của Hinton, Li Feifei, người vừa sinh con, vẫn đang trong thời gian nghỉ thai sản, nhưng Tỷ lệ mắc lỗi của đội Hinton khiến cô nhận ra rằng lịch sử đang được viết lại. Với tư cách là người sáng lập ImageNet Challenge, cô đã mua chuyến bay cuối cùng trong ngày tới Florence để đích thân trao giải cho đội Hinton [2].
Li Feifei sinh ra ở Bắc Kinh và lớn lên ở Thành Đô. Khi cô 16 tuổi, cô di cư sang Hoa Kỳ cùng cha mẹ. Cô giúp việc giặt giũ trong thời gian. hoàn thành việc học của mình tại Princeton. Năm 2009, Li Feifei vào Stanford với tư cách là trợ lý giáo sư. Hướng nghiên cứu của cô là thị giác máy tính và học máy. Mục tiêu của môn học này là giúp máy tính có thể tự hiểu được ý nghĩa của hình ảnh và hình ảnh giống như con người.
Ví dụ: khi máy ảnh chụp ảnh một con mèo, nó chỉ chuyển đổi ánh sáng thành pixel thông qua cảm biến và không biết liệu vật trong ống kính có là một con mèo hoặc một con chó. Nếu so sánh camera với mắt người, vấn đề được giải quyết bằng thị giác máy tính là trang bị cho camera một bộ não con người.
Cách truyền thống là trừu tượng hóa mọi thứ trong thế giới thực thành các mô hình toán học. Ví dụ, trừu tượng hóa các đặc điểm của một con mèo thành các hình hình học đơn giản có thể làm giảm đáng kể hiệu suất của máy. Khó khăn trong việc nhận dạng.
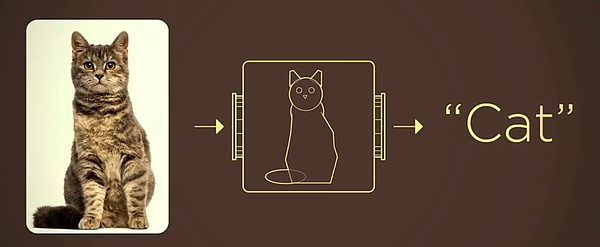
Nguồn hình ảnh: Bài phát biểu TED của Li Feifei
Nhưng ý tưởng này có những hạn chế rất lớn, vì mèo có thể trông như thế này:

Để cho phép máy tính nhận ra "mèo lỏng", một số lượng lớn những người tiên phong về deep learning như Jeff Hinton và Yann LeCun đã bắt đầu khám phá từ những năm 1980. Tuy nhiên, sẽ luôn có điểm nghẽn về sức mạnh tính toán hoặc thuật toán - các thuật toán tốt thiếu sức mạnh tính toán đủ và các thuật toán có yêu cầu sức mạnh tính toán nhỏ không thể đáp ứng độ chính xác nhận dạng và không thể công nghiệp hóa.
Nếu không giải quyết được vấn đề "con mèo lỏng", tính hấp dẫn của deep learning chỉ có thể dừng lại ở mức độ lý thuyết, trong các ngành như lái xe tự động, hình ảnh y tế và quảng cáo chính xác Khung cảnh chỉ là một lâu đài trên không.
Nói một cách đơn giản, sự phát triển của học sâu đòi hỏithuật toán,sức mạnh tính toán và dữ liệu Thông qua troika, thuật toán xác định cách máy tính nhận dạng sự vật; nhưng thuật toán đòi hỏi phải có đủ sức mạnh tính toán để thúc đẩy đồng thời sự cải tiến của thuật toán. yêu cầu dữ liệu quy mô lớn và chất lượng cao, cả ba đều bổ sung cho nhau và không thể thiếu được.
Sau năm 2000, mặc dù nút thắt về năng lực tính toán dần được loại bỏ nhờ sự tiến bộ nhanh chóng của khả năng xử lý chip, giới học thuật chính thống vẫn tỏ ra ít quan tâm đến con đường học sâu. Li Feifei nhận ra rằng nút thắt có thể không phải là độ chính xác của thuật toán mà là do thiếu bộ dữ liệu quy mô lớn, chất lượng cao.
Cảm hứng của Li Feifei đến từ cách những đứa trẻ ba tuổi hiểu thế giới - lấy mèo làm ví dụ, trẻ sẽ gặp đi gặp lại mèo dưới sự hướng dẫn của người lớn, và dần dần nắm bắt được ý nghĩa của con mèo. Nếu đôi mắt của một đứa trẻ được coi như một chiếc máy ảnh và một chuyển động của mắt tương đương với một lần bấm nút chụp thì một đứa trẻ ba tuổi đã chụp được hàng trăm triệu bức ảnh.
Áp dụng phương pháp này trên máy tính. Nếu bạn cho máy tính xem hình ảnh mèo và các động vật khác, hãy viết câu trả lời đúng vào sau mỗi bức tranh. Mỗi lần máy tính nhìn vào bức tranh, nó sẽ kiểm tra nó dựa trên câu trả lời ở mặt sau. Sau đó cho đủ thời gian, máy tính có thể hiểu được ý nghĩa của con mèo giống như một đứa trẻ.
Vấn đề duy nhất cần được giải quyết là: Tôi có thể tìm thấy nhiều hình ảnh có câu trả lời bằng văn bản ở đâu?

Lý Phi Phi đến Trung Quốc vào năm 2016 và tuyên bố thành lập Trung tâm Google AI Trung Quốc
Đây là cơ hội cho sự ra đời của ImageNet . Vào thời điểm đó, ngay cả tập dữ liệu lớn nhất PASCAL cũng chỉ có 4 danh mục với tổng số 1.578 hình ảnh và mục tiêu của Li Feifei là tạo ra một tập dữ liệu chứa hàng trăm danh mục với tổng số hàng chục triệu hình ảnh. Bây giờ nghe có vẻ không khó, nhưng bạn phải nhớ rằng đó là năm 2006 và chiếc điện thoại di động phổ biến nhất thế giới là Nokia 5300.
Dựa vào nền tảng cung cấp dịch vụ cộng đồng của Amazon, nhóm của Li Feifei đã giải quyết được khối lượng công việc khổng lồ của việc chú thích thủ công. Năm 2009, bộ dữ liệu ImageNet chứa 3,2 triệu hình ảnh đã ra đời. Với tập dữ liệu hình ảnh, thuật toán có thể được huấn luyện trên cơ sở này để cho phép máy tính cải thiện khả năng nhận dạng của nó. Nhưng so với hàng trăm triệu bức ảnh của trẻ ba tuổi thì 3,2 triệu vẫn là quá nhỏ.
Để liên tục mở rộng tập dữ liệu, Li Feifei quyết định làm theo thông lệ phổ biến trong ngành và tổ chức một cuộc thi nhận dạng hình ảnh. Những người tham gia đã mang thuật toán của riêng họ đến. xác định các hình ảnh trong tập dữ liệu, với độ chính xác Người nào cao nhất sẽ thắng. Tuy nhiên, con đường học sâu vào thời điểm đó chưa phải là xu hướng chủ đạo, ImageNet chỉ có thể “liên kết” với cuộc thi PASCAL nổi tiếng ở châu Âu lúc đầu nên hầu như không thu hút được số lượng người tham gia.
Đến năm 2012, số lượng hình ảnh ImageNet đã mở rộng lên 1.000 danh mục, với tổng số 15 triệu hình ảnh. Li Feifei đã mất 6 năm để bù đắp những thiếu sót trong. dữ liệu. Tuy nhiên, kết quả tốt nhất của ILSVRC có tỷ lệ lỗi là 25%, vẫn chưa thể hiện đủ sức thuyết phục về mặt thuật toán và sức mạnh tính toán.
Lúc này, Thầy Hinton xuất hiện với AlexNet và hai card đồ họa GTX580.
Convolution
Thuật toán vô địch của nhóm Hinton AlexNet , sử dụng một thuật toán được gọi là Mạng thần kinh chuyển đổi (viết tắt là CNN). “Mạng lưới thần kinh” là một từ có tần suất sử dụng cực cao trong lĩnh vực trí tuệ nhân tạo và cũng là một nhánh của machine learning. Tên và cấu trúc của nó được rút ra từ cách thức hoạt động của bộ não con người.
Quá trình nhận dạng đồ vật của con người là trước tiên học sinh tiếp nhận các pixel, vỏ não thực hiện xử lý sơ bộ thông qua các cạnh và hướng, sau đó não đưa ra phán đoán thông qua sự trừu tượng liên tục. Vì vậy, bộ não con người có thể xác định được đồ vật dựa trên một số đặc điểm.
Ví dụ: không cần nhìn toàn bộ khuôn mặt, hầu hết mọi người đều có thể nhận ra người trong hình bên dưới là ai:

Mạng lưới thần kinh thực sự mô phỏng bộ não con người. cơ chế nhận dạng có thể được thực hiện bởi các máy tính thông minh mà về mặt lý thuyết có thể được thực hiện bởi bộ não con người. So với SVM, cây quyết định, rừng ngẫu nhiên và các phương pháp khác, chỉ mô phỏng bộ não con người mới có thể xử lý dữ liệu phi cấu trúc như "Liquid Cat" và "Half Trump".
Nhưng vấn đề là bộ não con người có khoảng 100 tỷ tế bào thần kinh, và có hàng nghìn tỷ nút (tức là các khớp thần kinh) giữa các tế bào thần kinh tạo thành một khối cực kỳ phức tạp. mạng. Để so sánh, "Google Cat" bao gồm 16.000 CPU có tổng cộng 1 tỷ nút bên trong và đây đã là hệ thống máy tính phức tạp nhất vào thời điểm đó.
Đây là lý do tại sao ngay cả "cha đẻ của trí tuệ nhân tạo" Marvin Minsky cũng không lạc quan về con đường này khi xuất bản cuốn sách mới "Cỗ máy cảm xúc" vào năm 2007. , Minsky vẫn bày tỏ sự bi quan về mạng lưới thần kinh. Để thay đổi thái độ tiêu cực lâu dài của cộng đồng học máy chính thống đối với mạng lưới thần kinh nhân tạo, Hinton chỉ cần đổi tên nó thành học sâu (Deep Learning).
Năm 2006, Hinton xuất bản một bài báo trên tạp chí Khoa học, đề xuất khái niệm "Mạng lưới thần kinh niềm tin sâu sắc (DBNN)" và đưa ra Phương pháp đào tạo đa lớp mạng lưới thần kinh sâu được coi là một bước đột phá lớn trong học sâu. Tuy nhiên, phương pháp của Hinton đòi hỏi một lượng lớn sức mạnh tính toán và dữ liệu nên khó triển khai trong các ứng dụng thực tế.
Học sâu đòi hỏi phải cung cấp dữ liệu liên tục cho thuật toán. Kích thước của tập dữ liệu vào thời điểm đó quá nhỏ cho đến khi ImageNet xuất hiện.
Trong hai cuộc thi ImageNet đầu tiên, các đội tham gia đã sử dụng các lộ trình học máy khác và kết quả khá tầm thường. Mạng thần kinh tích chập AlexNet được nhóm của Hinton sử dụng vào năm 2012 đã được cải tiến từ một nhà tiên phong về học sâu khác Yann LeCun. Mạng LeNet do ông đề xuất vào năm 1998 đã cho phép thuật toán trích xuất các đặc điểm chính của hình ảnh, chẳng hạn như mái tóc vàng của Trump.
Đồng thời, nhân tích chập sẽ trượt trên hình ảnh đầu vào, nên dù đối tượng được phát hiện ở đâu thì cũng có thể phát hiện được các đặc điểm giống nhau, điều này giúp ích rất nhiều giảm số lượng hoạt động.
Dựa trên cấu trúc mạng thần kinh tích chập cổ điển, AlexNet từ bỏ phương pháp không giám sát từng lớp trước đó và tiến hành học có giám sát các giá trị đầu vào, giúp cải thiện đáng kể Độ chính xác.
Ví dụ, trong hình ở góc dưới bên phải của hình bên dưới, AlexNet thực tế không xác định được câu trả lời đúng (mèo Madagascar), nhưng nó liệt kê câu trả lời tương tự như mèo Madagascar Động vật có vú nhỏ có thể trèo cây, điều đó có nghĩa là thuật toán không chỉ có thể xác định chính đối tượng đó mà còn đưa ra suy luận dựa trên các đối tượng khác [5].

Nguồn hình ảnh: AlexNet paper
Ngành công nghiệp rất vui mừng khi AlexNet có 60 triệu tham số và 650.000 nơ-ron, đào tạo đầy đủ dữ liệu ImageNet. Bộ này yêu cầu ít nhất 262 petaflop . Nhưng nhóm của Hinton chỉ sử dụng hai card đồ họa Nvidia GTX 580 trong suốt một tuần huấn luyện.
GPU
Sau khi đội của Hinton giành chức vô địch, The điều đáng xấu hổ nhất rõ ràng là Google.
Người ta nói rằng Google cũng đã tiến hành thử nghiệm nội bộ trên bộ dữ liệu ImageNet, nhưng độ chính xác nhận dạng thua xa nhóm của Hinton. Cho rằng Google có tài nguyên phần cứng mà ngành không thể sánh được, cũng như quy mô dữ liệu khổng lồ về tìm kiếm và YouTube, lãnh đạo Google Brain đã đặc biệt giao nhiệm vụ đặc biệt và kết quả rõ ràng là không đủ thuyết phục.
Nếu không có sự tương phản lớn này, deep learning có thể đã không làm rung chuyển ngành công nghiệp này và không được công nhận cũng như phổ biến trong một khoảng thời gian ngắn. Lý do khiến cả ngành phấn khích là do nhóm của Hinton chỉ sử dụng 4 GPU để đạt được kết quả tốt như vậy nên sức mạnh tính toán không còn là điểm nghẽn.
Khi thuật toán đang huấn luyện, nó sẽ thực hiện các phép toán phân cấp trên các chức năng và tham số của từng lớp của mạng nơ-ron để thu được kết quả đầu ra và GPU sẽ diễn ra có khả năng hoạt động song song rất mạnh mẽ. Ng thực tế đã chứng minh điều này trong một bài báo năm 2009, nhưng khi chạy "Google Cat" với Jeff Dean, họ vẫn sử dụng CPU. Sau đó, Jeff Dean đặc biệt đặt mua thiết bị trị giá 2 triệu đô la Mỹ, vẫn chưa bao gồm GPU [6].
Hinton là một trong số ít người đã nhận ra giá trị to lớn của GPU đối với deep learning từ rất sớm. Tuy nhiên, trước khi AlexNet xếp hạng danh sách này, các công ty công nghệ cao đã có mặt. nói chung là không có ý tưởng về GPU Thái độ không rõ ràng.
Năm 2009, Hinton được mời đến Microsoft làm cố vấn kỹ thuật ngắn hạn cho một dự án nhận dạng giọng nói. Ông đề nghị trưởng dự án Đặng Li mua phần đầu. GPU Nvidia, nhưng cũng có máy chủ tương ứng. Ý tưởng này được Đặng Li ủng hộ, nhưng ông chủ Alex Acero của Đặng Li tin rằng đây hoàn toàn là một sự lãng phí tiền bạc [6]. “GPU được sử dụng để chơi game chứ không phải để nghiên cứu trí tuệ nhân tạo.”

Đặng Li
Điều thú vị là Alex Acero sau đó đã chuyển việc sang Apple và chịu trách nhiệm về phần mềm nhận dạng giọng nói Siri của Apple.
Việc Microsoft không cam kết về GPU rõ ràng đã khiến Hinton hơi tức giận. Sau đó, ông gợi ý trong một email rằng Đặng Li nên mua một bộ thiết bị và ông ấy sẽ mua ba bộ. và nói một cách mỉa mai [6]: Suy cho cùng, chúng tôi là trường đại học Canada có nguồn tài chính vững mạnh chứ không phải là người bán phần mềm thiếu tiền.
Nhưng sau Thử thách ImageNet 2012, tất cả các học giả về trí tuệ nhân tạo và các công ty công nghệ đã quay ngoắt 180 độ đối với GPU. Năm 2014, GoogLeNet của Google đã giành chức vô địch với độ chính xác nhận dạng là 93%, sử dụng GPU NVIDIA. Năm nay, số lượng GPU được tất cả các đội tham gia sử dụng đã tăng vọt lên 110.
Lý do khiến thử thách này được coi là "thời điểm bùng nổ" nằm ở bộ ba deep learning - thuật toán, sức mạnh tính toán và dữ liệu mà các bo mạch có. được bổ sung và công nghiệp hóa chỉ còn là vấn đề thời gian.
Ở cấp độ thuật toán, bài báo trênAlexNet do nhóm của Hinton xuất bản đã trở thànhKhoa học máy tính Một trong những bài báo được trích dẫn nhiều nhất trong lĩnh vực này. Con đường kỹ thuật ban đầu có hàng trăm trường phái tư tưởng cạnh tranh nay đã trở thành một trong nhữnghọc sâu và gần như tất cảthị giác máy tínhnghiên cứu đã chuyển sang NMạng eural.
Sức mạnh tính toánmức độ, GPU Khả năngđiện toán song songvàhọc sâukhả năng thích ứng nhanh chóng được ngành công nhận và việc bố trí bắt đầu > sáu năm trước NVIDIA của /strong>CUDA đã trở thành người chiến thắng lớn nhất.
Mức dữ liệu, ImageNettrở thành Tiêu chuẩn của thuật toán xử lý hình ảnhvới bộ dữ liệu chất lượng cao, độ chính xác của nhận dạng thuật toán đang được cải thiện từng ngày. Trong thử thách vừa qua vào năm 2017, độ chính xác nhận dạng của thuật toán vô địch đạt 97,3%, vượt qua con người.
Vào cuối tháng 10 năm 2012, Alex Krizhevsky, sinh viên của Hinton đã xuất bản một bài báo tại Hội nghị Thị giác Máy tính ở Florence, Ý. Sau đó, các công ty công nghệ cao trên khắp thế giới bắt đầu thực hiện hai việc bất kể chi phí: Một là mua tất cả card đồ họa NVIDIAhai là mua; săn trộm tất cả card đồ họa của các trường đại học strong>AINhà nghiên cứu.
44 triệu USD của Lake Tahoe đã định giá lại những bậc thầy về deep learning trên thế giới.
Giữ cờ
Từ thông tin công khai , Yu Kai, người vẫn còn ở Baidu vào thời điểm đó, thực sự là người đầu tiên khai thác Hinton.
Vào thời điểm đó, Yu Kai giữ chức vụ trưởng Bộ phận Đa phương tiện Baidu tại Baidu, tiền thân của Baidu Deep Learning Institute (IDL). Sau khi nhận được email của Yu Kai, Hinton nhanh chóng trả lời rằng anh ấy đồng ý hợp tác, và nhân tiện, anh ấy bày tỏ mong muốn Baidu cung cấp một số vốn. Yu Kai yêu cầu một con số cụ thể, Hinton nói rằng 1 triệu đô la Mỹ là đủ - con số này cực kỳ thấp và chỉ có thể thuê hai chiếc P8.
Yu Kai đã nhờ Robin Li hướng dẫn và người sau đã sẵn sàng đồng ý. Sau khi Yu Kai trả lời rằng không có vấn đề gì, Hinton, có lẽ cảm thấy sự khao khát của ngành, đã hỏi Yu Kai liệu anh ấy có phiền khi hỏi các công ty khác, chẳng hạn như Google không. Yu Kai sau này nhớ lại [6]:
"Lúc đó tôi cảm thấy hơi tiếc nuối. Tôi đoán là mình đã trả lời quá nhanh, điều này khiến Hinton nhận ra Cơ hội to lớn. Tuy nhiên, tôi chỉ có thể hào phóng nói rằng tôi không bận tâm.” Cuối cùng, nhóm của Baidu và Hinton đã bỏ lỡ cơ hội đó. Nhưng Yu Kai không phải là không chuẩn bị cho kết quả này. Bởi vì một mặt, Hinton có vấn đề nghiêm trọng về sức khỏe đĩa đệm thắt lưng và không thể lái xe hay bay, khiến chuyến đi xuyên Thái Bình Dương đến Trung Quốc trở nên khó khăn; mặt khác, Hinton có quá nhiều sinh viên và bạn bè đang làm việc tại Google, và cả hai đều khó khăn. các bên Nguồn gốc quá sâu và ba công ty còn lại về cơ bản là đồng hành cùng cuộc đấu thầu.
Nếu ảnh hưởng của AlexNet vẫn tập trung trong giới học thuật thì cuộc đấu giá bí mật ở Lake Tahoe đã khiến cả ngành hoàn toàn bị sốc - bởi Google có tầm ảnh hưởng rất lớn đến toàn cầu Dưới mũi ông, ông đã chi 44 triệu USD để mua lại một công ty mới thành lập được chưa đầy một tháng, chưa có sản phẩm, không có doanh thu, chỉ có ba nhân viên và một vài giấy tờ.
Điều thú vị nhất rõ ràng là Baidu. Mặc dù thất bại trong cuộc đấu giá nhưng ban lãnh đạo Baidu đã tận mắt chứng kiến cách Google đầu tư vào deep learning bằng mọi giá, thúc đẩy Baidu thực hiện. Quyết tâm đầu tư và công bố thành lập Viện nghiên cứu Deep Learning IDL tại cuộc họp thường niên vào tháng 1 năm 2013. Vào tháng 5 năm 2014, Baidu đã mời Andrew Ng, một nhân vật chủ chốt trong dự án "Google Cat", và vào tháng 1 năm 2017, họ đã mời Lu Qi, người đã rời Microsoft.
Google tiếp tục nỗ lực sau khi chiến thắng đội của Hinton và mua DeepMind, đối thủ đấu thầu năm đó, với giá 600 triệu USD vào năm 2014.
Vào thời điểm đó, Musk đã giới thiệu DeepMind mà ông đã đầu tư vào cho người sáng lập Google, Larry Page để đưa Hinton cùng ông đến London để kiểm tra chất lượng. nhóm Google cũng Một máy bay riêng đã được thuê đặc biệt và ghế đã được sửa đổi để giải quyết vấn đề không thể bay của Hinton [6].

"Cầu thủ người Anh" DeepMind đã đánh bại Lee Sedol trong ván cờ vây năm 2016
Chính Facebook đã cạnh tranh với Google để giành lấy DeepMind. Khi DeepMind rơi vào tay Google, Zuckerberg quay sang chiêu mộ Yang Likun, một trong "Big Three" về deep learning. Để đặt Yang Likun dưới sự chỉ huy của mình, Zuckerberg đã đồng ý với nhiều yêu cầu khắt khe của anh ấy, chẳng hạn như thành lập phòng thí nghiệm AI ở New York, vạch ra ranh giới rõ ràng giữa phòng thí nghiệm và nhóm sản phẩm, đồng thời cho phép Yang Likun tiếp tục làm việc tại Đại học New York, v.v.
Sau Thử thách năm 2012ImageNetThách thức, lĩnh vực trí tuệ nhân tạo đang phải đối mặt với một thách thức rất nghiêm trọng " Vấn đề "Không phù hợp giữa cung và cầu nhân tài":
Khi các không gian công nghiệp hóa như thuật toán đề xuất, nhận dạng hình ảnh và lái xe tự động nhanh chóng được mở ra , nhu cầu về nhân tài tăng mạnh. Tuy nhiên, vì đã lâu không được ưa chuộng nên các nhà nghiên cứu deep learning chỉ là một vòng tròn nhỏ, các học giả hàng đầu đếm trên hai tay, nguồn cung thì thiếu trầm trọng.
Trong trường hợp này, các công ty công nghệ đói khát chỉ có thể mua "tương lai nhân tài":Lừa các giáo sư, rồi đợi họ tuyển sinh viên Mang nó vào .
Sau khi Yang Likun gia nhập Facebook, sáu sinh viên đã theo anh gia nhập công ty. Apple, công ty đang chuẩn bị thực hiện một bước nhảy vọt trong lĩnh vực chế tạo ô tô, đã thuê sinh viên Ruslan Salakhutdinov của Hinton làm giám đốc AI đầu tiên của Apple. Ngay cả quỹ phòng hộ Citadel cũng tham gia cuộc cạnh tranh và chiêu mộ Đặng Li, người làm việc về nhận dạng giọng nói với Hinton và sau đó tham gia đấu thầu bí mật thay mặt cho Microsoft.



Chúng tôi biết rất rõ lịch sử: nhận dạng khuôn mặt, dịch máy, lái xe tự động và các kịch bản công nghiệp hóa khác đang tiến xa hàng ngàn dặm mỗi năm Ngày càng có nhiều đơn đặt hàng GPU rơi xuống trụ sở chính của NVIDIA ở Santa Clara như những bông tuyết, và tòa nhà lý thuyết về trí tuệ nhân tạo cũng đang được đổ về ngày này qua ngày khác.
Năm 2017, Google đã đề xuất mô hình Transformer trong bài báo "Sự chú ý là tất cả những gì bạn cần", mở ra kỷ nguyên của các mô hình lớn ngày nay. Vài năm sau, ChatGPT nổi lên.
Sự ra đời của tất cả những điều này có thể bắt nguồn từ năm 2012ImageNetThử thách .
Vậy, quá trình lịch sử thúc đẩy sự ra đời của "Khoảnh khắc Big Bang" năm 2012 xuất hiện vào năm nào?
Câu trả lời là năm 2006.
Tuyệt vời
Trước năm 2006, deep learning Tình hình hiện nay Có thể tóm tắt bằng câu nói nổi tiếng của Nam tước Kelvin: Việc xây dựng deep learning cơ bản đã hoàn thành nhưng vẫn có ba đám mây đen nhỏ lơ lửng dưới bầu trời đầy nắng.
Ba đám mây đen nhỏ này là thuật toán, sức mạnh tính toán và dữ liệu.
Như đã đề cập trước đó, deep learning là một giải pháp hoàn hảo về mặt lý thuyết vì nó mô phỏng cơ chế của bộ não con người. Nhưng vấn đề là cả dữ liệu nó cần nuốt lẫn sức mạnh tính toán mà nó cần tiêu thụ đều ở mức độ khoa học viễn tưởng vào thời điểm đó. Từ khoa học viễn tưởng đến thế giới học thuật, quan điểm chủ đạo về deep learning là: Học giả với. bộ não bình thường sẽ không Nghiên cứuMạng lưới thần kinh.
Nhưng có ba điều đã xảy ra vào năm 2006 đã thay đổi điều này:
Hinton và sinh viên Salakhutdinov (người sau này chuyển sang Apple) đã xuất bản một bài báo Giảm tính chiều của dữ liệu bằng mạng lưới thần kinh trong Khoa học, đây là lần đầu tiên một nghiên cứu hiệu quả giải pháp cho vấn đề độ dốc biến mất được đề xuất, đây là một bước tiến lớn ở cấp độ thuật toán.

Salakhutdinov (đầu tiên bên trái) và Hinton (giữa), 2016
Fefeifei Li của Đại học Stanford nhận ra rằng nếu dữ liệu Thang đo Rất khó để khôi phục lại hình dáng ban đầu của thế giới thực, nên dù thuật toán có tốt đến đâu thì thông qua rèn luyện cũng khó đạt được hiệu quả “mô phỏng bộ não con người”. Vì vậy, cô bắt đầu xây dựng bộ dữ liệuImageNet.
Nvidia phát hành GPU mới dựa trên Tesla và ra mắt nó theo đó < /strong>nền tảng CUDA, các nhà phát triển sử dụng GPU để đào tạo mạng lưới thần kinh sâuvới ít khó khăn và nản chí hơn nhiều >< strong>Sức mạnh tính toánNgưỡng đã bị cắt giảm rất nhiều.
Sự xuất hiện của ba điều này đã thổi bay ba đám mây đen đối với deep learning và chúng hội tụ tại Thử thách ImageNet 2012, nó đã được viết lại hoàn toàn số phận của ngành công nghệ cao và thậm chí của toàn bộ xã hội loài người.
Nhưng vào năm 2006, cả Jeff Hinton, Li Feifei, Huang Renxun và những người thúc đẩy sự phát triển của deep learning đều không thể dự đoán rõ ràng về tương lai của trí tuệ nhân tạo. sự thịnh vượng theo sau, chưa kể đến vai trò của họ.

Bài viết của Hinton và Salakhutdinov
Ngày nay, cuộc cách mạng công nghiệp lần thứ tư do AI làm cốt lõi đã bắt đầu lại và tốc độ phát triển của trí tuệ nhân tạo sẽ chỉ nhanh hơn và nhanh hơn. Nếu chúng ta có thể nói chúng ta có thể nhận được bao nhiêu nguồn cảm hứng thì đó có thể không gì khác hơn ba điểm sau:
1. đỉnh cao của sự đổi mới.
Khi ChatGPT ra đời đã có rất nhiều tiếng nói "Tại sao lại là Hoa Kỳ?" Nhưng nếu kéo dài thời gian, bạn sẽ thấy rằng từ bóng bán dẫn và mạch tích hợp đến kiến trúc Unix và x86, và bây giờ là học máy, giới học thuật và ngành công nghiệp Mỹ hầu như luôn dẫn đầu.
Điều này là do, mặc dù có những cuộc thảo luận không ngừng nghỉ về việc "loại bỏ ngành công nghiệp" ở Hoa Kỳ, nhưng ngành khoa học máy tính với phần mềm là cốt lõi của nó vẫn chưa chỉ có điều là không bao giờ “di tản” “Ở các nền kinh tế khác, lợi thế ngày càng lớn hơn. Cho đến nay, hầu hết trong số hơn 70 người đoạt giải ACM Turing Award đều là người Mỹ.
Lý do Andrew Ng chọn Google hợp tác với dự án "Google Cat" phần lớn là do chỉ Google mới có đủ dữ liệu và sức mạnh tính toán cần thiết cho việc đào tạo thuật toán và điều này Nó cũng được xây dựng dựa trên khả năng sinh lời mạnh mẽ của Google. Đây là lợi thế do độ dày của ngành mang lại - nhân tài, khả năng đầu tư và đổi mới đều sẽ tiến gần hơn đến vị trí cao của ngành.
Trung Quốc cũng phản ánh "lợi thế về độ dày" này trong các ngành công nghiệp có lợi thế của chính mình. Hiện nay, điển hình nhất là xe sử dụng năng lượng mới, một bên là các hãng xe châu Âu thuê chuyến bay đến China Auto Show để học hỏi các thế lực mới, một bên là giám đốc điều hành các hãng xe Nhật Bản thường xuyên chuyển việc sang. BYD - để làm gì? Rõ ràng, tôi không chỉ cố gắng trả tiền an sinh xã hội ở Thâm Quyến.
2. Lĩnh vực kỹ thuật càng tiên tiến thì tầm quan trọng của nhân tài càng lớn.
Lý do Google sẵn sàng chi 44 triệu USD để mua công ty của Hinton là vì trong lĩnh vực công nghệ tiên tiến như deep learning, một học giả hàng đầu. Vai trò này thường lớn hơn 10.000 sinh viên mới tốt nghiệp chuyên ngành thị giác máy tính. Nếu lúc đó Baidu hay Microsoft đấu thầu thành công thì sự phát triển của trí tuệ nhân tạo có thể đã được viết lại.
Loại hành vi "mua toàn bộ công ty cho bạn" này thực ra rất phổ biến. Ở giai đoạn quan trọng trong quá trình tự phát triển chip của Apple, họ đã mua một công ty nhỏ tên là PASemi chỉ để chiêu mộ chuyên gia kiến trúc chip Jim Keller - chip A4 của Apple, Zen của AMD và FSD của Tesla đều được Jim Keller xóa đói giảm nghèo nhờ công nghệ.
Đây cũng là lợi thế lớn nhất mà năng lực cạnh tranh công nghiệp mang lại - thu hút nhân tài.
Không ai trong số "Big Three" của deep learning là người Mỹ. Cái tên AlexNet xuất phát từ học trò của Hinton là Alex Krizhevsky, người sinh ra ở Ukraine dưới thời Liên Xô. Tôi lớn lên ở Israel và đến Canada để học. Chưa kể đến nhiều gương mặt Trung Quốc hiện nay vẫn đang hoạt động trong các công ty công nghệ cao của Mỹ.
3. Khó khăn của sự đổi mới nằm ở cách đối mặt với sự không chắc chắn.
Ngoài sự phản đối của "Cha đẻ trí tuệ nhân tạo" Marvin Minsky đối với việc học sâu, một đối thủ nổi tiếng khác của học sâu là Jitendra của Đại học California, Berkeley Malik, Hinton và Ng đều bị anh ta chế nhạo. Li Feifei cũng đã hỏi ý kiến Malik khi xây dựng ImageNet và sau này đã cho cô lời khuyên: Hãy làm điều gì đó hữu ích hơn.

Bài phát biểu Ted của Li Feifei
Chính sự thiếu lạc quan của những người tiên phong trong ngành này đã khiến deep learning trải qua nhiều thập kỷ im lặng. Mặc dù Hinton đã phát hiện ra tia sáng vào năm 2006, Yang Likun, một thành viên khác của Big Three, vẫn liên tục chứng minh cho cộng đồng học thuật rằng “deep learning cũng có giá trị nghiên cứu”.
Yang Likun đã nghiên cứu mạng lưới thần kinh từ những năm 1980. Khi còn ở Bell Labs, Yang Likun và các đồng nghiệp của ông đã thiết kế một con chip có tên ANNA để cố gắng giải quyết các vấn đề tính toán. vấn đề lực lượng. Sau đó, AT&T yêu cầu bộ phận nghiên cứu "trao quyền kinh doanh" do áp lực điều hành, câu trả lời của Yang Likun là "Tôi chỉ muốn nghiên cứu về thị giác máy tính. Nếu có thể, hãy sa thải tôi". Cuối cùng, tôi đã nhận được chiếc búa và tôi rất vui khi đề cập đến N+1[6].
Các nhà nghiên cứu trong bất kỳ lĩnh vực công nghệ tiên tiến nào cũng phải đối mặt với một vấn đề -Nếu thứ này không thể được tạo ra thì sao?
Kể từ khi vào Đại học Edinburgh năm 1972, Hinton đã chiến đấu ở tuyến đầu của lĩnh vực học sâu trong 50 năm. Ông đã 65 tuổi khi Thử thách ImageNet 2012 được tổ chức. Thật khó để tưởng tượng anh ấy đã phải vượt qua bao nhiêu sự nghi ngờ và phủ nhận bản thân khi đối mặt với nhiều nghi ngờ khác nhau trong thế giới học thuật trong một thời gian dài.
Bây giờ chúng ta biết rằng Hinton năm 2006 đã kiên trì cho đến bóng tối cuối cùng trước bình minh, nhưng bản thân anh ta có thể không biết điều này chứ đừng nói đến toàn bộ cộng đồng học thuật và thế giới. ngành công nghiệp. Giống như khi iPhone được ra mắt vào năm 2007, hầu hết mọi người có lẽ đều có phản ứng giống như CEO Ballmer của Microsoft khi đó:

Hiện tại, iPhone vẫn là điện thoại di động đắt nhất thế giới và nó không có bàn phím
Những người đề cao lịch sử thường không đoán được tọa độ của chính mình trong tiến trình lịch sử.
Sở dĩ sự vĩ đại không phải vì vẻ ngoài lộng lẫy khi xuất hiện, mà vì nó phải chịu đựng một thời gian dài mờ mịt và mù mờ trong vô biên bóng tối Không hiểu. Phải đến nhiều năm sau, người ta mới noi theo những bậc thống trị này và than thở rằng các vì sao đang tỏa sáng rực rỡ và những thiên tài xuất hiện đông đảo.
Trong hết lĩnh vực nghiên cứu khoa học này đến lĩnh vực khác, vô số học giả chưa bao giờ nhìn thấy tia hy vọng trong suốt cuộc đời của họ. Vì vậy, từ một góc độ nào đó, Hinton và những người quảng bá deep learning khác thật may mắn. Họ đã tạo ra sự vĩ đại và gián tiếp thúc đẩy hết thành công này đến thành công khác trong ngành.
Thị trường vốn sẽ định giá hợp lý cho thành công, lịch sử sẽ ghi lại sự cô đơn và mồ hôi tạo nên sự vĩ đại.
Tài liệu tham khảo
[1] 16.000 máy tính cùng nhau Nhìn lại cho một con mèo, The New York Times
[2] Nhiệm vụ của Fei-Fei Li nhằm làm cho AI trở nên tốt hơn cho nhân loại, có dây
[3] Bài nói chuyện TED của Li Feifei
[4] Xem tất cả các mô hình ImageNet trong 21 giây, hơn 60 kiến trúc mô hình được thực hiện trên cùng một giai đoạn, Trái tim máy
[5] "Con đường đến với các vị thần" của Mạng thần kinh chuyển đổi: Mọi thứ bắt đầu với AlexNet, Trí tuệ mới
[6] Cuộc cách mạng học tập sâu, Cade Metz
[7] Để tìm kỹ sư AI, Google và Facebook hãy thuê họ Các giáo sư, The Information
[8] Ba mươi năm đổi mới trong lĩnh vực học sâu, Zhu Long
[9] ImageNet trong 8 năm qua: Li Feifei và thế giới AI mà cô ấy đã thay đổi, qubits
[10] HỌC SÂU: ỨNG DỤNG TRƯỚC ĐÂY VÀ HIỆN TẠI , Ramiro Vargas
[11] Đánh giá về học sâu: khái niệm, kiến trúc CNN, thách thức, ứng dụng, hướng đi trong tương lai, Laith Alzubaidi et al
[12] Đánh giá tài liệu về các lĩnh vực nghiên cứu học tập sâu, Mutlu Yapıcı, v.v.
[13] Người hùng thực sự đằng sau ChatGPT: Bước nhảy vọt về niềm tin của nhà khoa học trưởng OpenAI Ilya Sutskever, Trí tuệ mới
[14] 10 năm sau, 'cuộc cách mạng' học sâu sẽ nổ ra dữ dội, những người tiên phong về AI Hinton cho biết , LeCun và Li , Venturebeat
[15] Từ không hoạt động đến mạng lưới thần kinh, The Economist
[ 16] “Các mô hình nền tảng” khổng lồ đang thúc đẩy tiến bộ AI, The Economist
[17] 2012: Một năm đột phá cho việc học sâu, Bryan House
p>
[18] Học sâu: "cây đũa thần" của trí tuệ nhân tạo, Essence Securities
[19] Phát triển các thuật toán deep learning: từ đa dạng đến thống nhất, Guojin Securities


 XingChi
XingChi







