OpenAI Sora chính thức ra mắt và website đông đảo
Sam Altman: "Phiên bản video của GPT-1 có ở đây."
 JinseFinance
JinseFinance

Nguồn: Metaverse Daily Explosion
Chưa mở cửa thử nghiệm công khai, OpenAI đã gây chấn động giới công nghệ, Internet và mạng xã hội với đoạn giới thiệu do mô hình video tạo văn bản Sora sản xuất.
Theo video chính thức do OpenAI phát hành, Sora có thể tạo ra một cảnh "siêu video" phức tạp kéo dài một phút dựa trên thông tin văn bản do người dùng cung cấp. Không chỉ các chi tiết của hình ảnh thực tế, điều này mô hình cũng có thể mô phỏng chuyển động của thấu kính.
Đánh giá từ các hiệu ứng video đã phát hành, ngành công nghiệp rất vui mừng về khả năng hiểu biết về thế giới thực của Sora. So với các mô hình chuyển văn bản thành video lớn khác, Sora cho thấy lợi thế về khả năng hiểu ngữ nghĩa, trình bày hình ảnh, tính mạch lạc trực quan và thời lượng.
OpenAI trực tiếp gọi nó là "trình mô phỏng thế giới", thông báo rằng nó có thể mô phỏng các đặc điểm của con người, động vật và môi trường trong thế giới vật chất. Nhưng hãng cũng thừa nhận Sora vẫn chưa hoàn hảo và vẫn còn những điểm chưa hoàn hảo trong cách hiểu cũng như các vấn đề bảo mật tiềm ẩn.
Do đó, Sora chỉ mở cửa thử nghiệm cho một số lượng rất ít người. OpenAI vẫn chưa công bố khi nào Sora sẽ mở cửa cho công chúng, nhưng cú sốc mà nó mang lại cũng đủ để các công ty phát triển mô hình tương tự nhìn thấy khoảng cách.
Ngay khi mẫu video tạo văn bản OpenAI Sora ra mắt, đã có những bình luận "choáng" ở Trung Quốc .
Giới truyền thông chúng tôi đã thốt lên rằng "thực tế không còn tồn tại nữa", và các ông chủ Internet cũng khoe khoang về khả năng của Sora. Zhou Hongyi, người sáng lập 360, cho biết sự ra đời của Sora đồng nghĩa với việc việc triển khai AGI có thể rút ngắn từ 10 năm xuống còn khoảng hai năm. Chỉ trong vài ngày, chỉ số tìm kiếm trên Google của Sora đã tăng lên nhanh chóng và mức độ phổ biến của nó gần bằng ChatGPT.
Sự nổi tiếng của Sora bắt nguồn từ 48 video do OpenAI phát hành, trong đó video dài nhất là 1 phút. Điều này không chỉ phá vỡ giới hạn thời lượng của video được tạo bởi các mẫu video Vincent Gen2 và Runway trước đó mà hình ảnh còn rõ ràng và thậm chí còn học được ngôn ngữ ống kính.
Trong video dài 1 phút, một người phụ nữ mặc váy đỏ đang đi trên con phố rợp bóng đèn neon. Phong cách chân thực và hình ảnh mượt mà. Điều tuyệt vời nhất là cận cảnh của nhân vật nữ chính, bao gồm cả lỗ chân lông trên khuôn mặt, các đốm và vết mụn đều được mô phỏng, hiệu quả tẩy trang có thể so sánh với việc tắt bộ lọc làm đẹp trong một chương trình phát sóng trực tiếp, các đường cổ trên cổ thậm chí còn "rò rỉ" chính xác tuổi tác và hoàn toàn thống nhất với tình trạng khuôn mặt.
Ngoài việc mô phỏng các nhân vật một cách chân thực, Sora còn có thể mô phỏng các động vật và môi trường ngoài đời thực. Video quay cận cảnh nhiều góc độ của Chim bồ câu Victoria Crowned, độ nét cực cao cho thấy những chiếc lông màu xanh lam từ thân chim đến vương miện, thậm chí cả động lực và nhịp thở của đôi mắt đỏ, rất khó để nói cho dù điều này được tạo ra bởi AI hay do con người bắn ra.
Đối với những hoạt hình sáng tạo phi thực tế, hiệu ứng thế hệ của Sora cũng mang dáng dấp của các bộ phim hoạt hình Disney, khiến cư dân mạng lo lắng về công việc của các họa sĩ hoạt hình.
Những cải tiến mà Sora mang đến cho mô hình video tạo văn bản không chỉ ở thời lượng video và hiệu ứng hình ảnh mà còn ở việc mô phỏng quỹ đạo chuyển động của ống kính và cách bắn, góc nhìn thứ nhất của trò chơi, góc nhìn từ trên không, và thậm chí cả bộ phim A quay ở phần cuối.
Sau khi xem video tuyệt vời do OpenAI phát hành, bạn có thể hiểu tại sao cộng đồng Internet và dư luận mạng xã hội lại bị sốc trước Sora, và đây chỉ là những đoạn giới thiệu.
Vậy, Sora đạt được khả năng mô phỏng bằng cách nào?
Theo báo cáo kỹ thuật Sora do Open AI công bố, mô hình này đang vượt qua những hạn chế của các mô hình tạo dữ liệu hình ảnh trước đó.
Nghiên cứu trước đây về hình ảnh trực quan tạo văn bản đã sử dụng nhiều phương pháp khác nhau, bao gồm mạng hồi quy, mạng đối kháng tổng quát (GAN), biến áp tự hồi quy và mô hình khuếch tán, nhưng điểm chung là chúng tập trung vào ít danh mục dữ liệu trực quan hơn, ngắn hơn video hoặc video có kích thước cố định.
Sora áp dụng mô hình khuếch tán dựa trên Transformer. Quá trình tạo biểu đồ có thể được chia thành hai giai đoạn: quá trình tiến và quá trình đảo ngược, để Sora có thể tiến hoặc lùi dọc theo dòng thời gian. Mở rộng video khả năng.
Giai đoạn xử lý tiếp theo mô phỏng quá trình khuếch tán từ ảnh thật sang ảnh nhiễu thuần túy. Cụ thể, mô hình dần dần thêm nhiễu vào ảnh cho đến khi ảnh trở nên nhiễu hoàn toàn. Quá trình ngược lại là nghịch đảo của quá trình chuyển tiếp và mô hình sẽ dần dần khôi phục ảnh gốc từ ảnh nhiễu. Một tích cực và một tiêu cực, qua lại giữa ảo và thực. Bằng cách này, OpenAI cho phép cỗ máy Sora hiểu được sự hình thành của tầm nhìn.
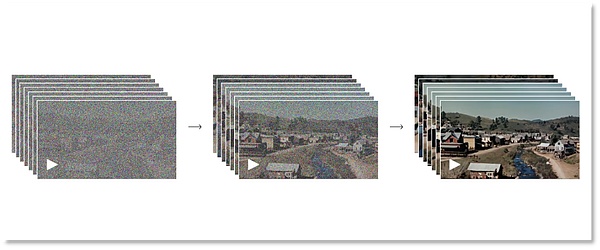 Quá trình từ nhiễu hoàn toàn đến hình ảnh rõ nét
Quá trình từ nhiễu hoàn toàn đến hình ảnh rõ nét
Tất nhiên, quá trình này đòi hỏi phải đào tạo và học hỏi nhiều lần. Mô hình sẽ học cách loại bỏ dần nhiễu và khôi phục các chi tiết của hình ảnh. Thông qua việc lặp lại hai giai đoạn này, mô hình khuếch tán của Sora có thể tạo ra hình ảnh chất lượng cao. Mô hình này đã cho thấy hiệu suất tuyệt vời trong việc tạo hình ảnh, chỉnh sửa hình ảnh, độ phân giải siêu cao và các lĩnh vực khác.
Quy trình trên giải thích tại sao Sora có thể đạt được độ nét cao và độ chi tiết cực cao. Tuy nhiên, từ hình ảnh tĩnh đến video động, mô hình vẫn cần tích lũy thêm dữ liệu và đào tạo, học hỏi.
Dựa trên mô hình phổ biến, OpenAI chuyển đổi tất cả các loại dữ liệu trực quan, chẳng hạn như video và hình ảnh, thành một bản trình bày thống nhất để thực hiện quá trình đào tạo tổng hợp Sora trên quy mô lớn. Cách biểu diễn mà Sora sử dụng được OpenAI định nghĩa là "các bản vá trực quan", là tập hợp các đơn vị dữ liệu nhỏ hơn, tương tự như bộ sưu tập văn bản trong GPT.
Đầu tiên, các nhà nghiên cứu nén video vào một không gian tiềm ẩn có chiều thấp, sau đó phân tách cách biểu diễn này thành các bản vá không gian thời gian. Đây là dạng biểu diễn có khả năng mở rộng cao, tạo điều kiện thuận lợi cho việc chuyển đổi từ video sang bản vá, cũng phù hợp để đào tạo các mô hình tổng quát xử lý nhiều loại video và hình ảnh.
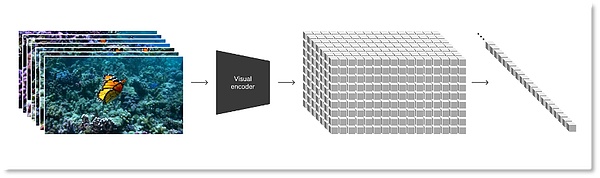 Chuyển đổi dữ liệu hình ảnh thành các bản vá
Chuyển đổi dữ liệu hình ảnh thành các bản vá
Để đào tạo Sora với ít thông tin và tính toán hơn, OpenAI đã phát triển một mạng nén video để trước tiên giảm kích thước của video xuống kích thước thấp ở cấp độ pixel . Không gian tiềm ẩn, sau đó sử dụng dữ liệu video đã nén để tạo các bản vá, điều này có thể làm giảm thông tin đầu vào và giảm áp lực tính toán. Đồng thời, OpenAI cũng đào tạo mô hình giải mã tương ứng để ánh xạ thông tin nén trở lại không gian pixel.
Dựa trên việc thể hiện các mảng hình ảnh, các nhà nghiên cứu có thể đào tạo Sora về video/hình ảnh có độ phân giải, thời lượng và tỷ lệ khung hình khác nhau. Bước vào giai đoạn suy luận, Sora có thể xác định logic video và kiểm soát kích thước của video được tạo ra bằng cách sắp xếp các bản vá được khởi tạo ngẫu nhiên trong một lưới có kích thước phù hợp.
OpenAI báo cáo rằng khi được đào tạo trên quy mô lớn, mô hình video đã thể hiện những khả năng thú vị, bao gồm khả năng của Sora trong việc mô phỏng chân thực con người, động vật và môi trường trong thế giới thực, tạo ra video có độ trung thực cao và đồng thời Đạt được Tính nhất quán 3D và tính nhất quán về thời gian để mô phỏng thực sự thế giới vật chất.
Từ kết quả đến quy trình R&D, Sora cho thấy những khả năng mạnh mẽ nhưng người dùng thông thường vẫn chưa thể trải nghiệm, hiện tại họ chỉ có thể viết những lời nhắc nhở. Trên X, người sáng lập @OpenAI Sam Altman, vì Setter giúp cư dân mạng tạo video trên Sora và sau đó phát hành chúng cho công chúng để xem hiệu quả.
Điều này cũng khiến mọi người thắc mắc liệu Sora có thực sự tuyệt vời như những gì OpenAI chính thức thể hiện hay không.
Về vấn đề này, OpenAI thẳng thắn tuyên bố rằng mô hình hiện tại vẫn còn một số vấn đề. Giống như GPT đời đầu, Sora hiện tại cũng có "ảo giác", là những biểu hiện cụ thể hơn về lỗi trong kết quả video tập trung vào hình ảnh.
Ví dụ: nó không thể mô phỏng chính xác nhiều quá trình vật lý tương tác cơ bản, chẳng hạn như mối quan hệ giữa đường chạy của máy chạy bộ và chuyển động của con người, logic thời gian của việc vỡ kính và chất lỏng chảy ra khỏi cốc, v.v.
Trong video clip dưới đây “Các nhà khảo cổ khai quật được một chiếc ghế nhựa”, chiếc ghế nhựa “nổi” thẳng ra khỏi cát.
Ngoài ra còn có những chú sói con đột nhiên xuất hiện, được cư dân mạng gọi đùa là "sự phân bào của sói".
Đôi khi nó không thể phân biệt được mặt trước và mặt sau.
Những sai sót trong những bức tranh động này dường như chứng tỏ rằng Sora vẫn cần hiểu biết và rèn luyện nhiều hơn về logic chuyển động của thế giới vật chất. Ngoài ra, so với rủi ro của ChatGPT, rủi ro về đạo đức và bảo mật của Sora, vốn mang lại trải nghiệm trực quan, thậm chí còn lớn hơn.
Trước đây, mô hình đồ thị Vincentian Midjourney đã nói với con người rằng "hình ảnh không nhất thiết có nghĩa là sự thật." Những bức ảnh do trí tuệ nhân tạo tạo ra trông giống như ảnh thật đã bắt đầu trở thành yếu tố của tin đồn. Tiến sĩ Newell, giám đốc khoa học của công ty xác minh danh tính iProov, cho biết Sora giúp "các tác nhân độc hại dễ dàng tạo ra các video giả mạo chất lượng cao hơn". bạo lực, khiêu dâm và hậu quả khôn lường, đây chính là lý do Sora khiến người ta bị sốc và sợ hãi.
OpenAI cũng đã xem xét các vấn đề bảo mật mà Sora có thể mang lại, đây có lẽ là lý do tại sao Sora chỉ mở cửa cho một số rất ít người tham gia thử nghiệm chỉ dành cho những người được mời. Khi nào nó sẽ được mở cửa cho công chúng? OpenAI không đưa ra thời gian biểu và đánh giá từ video chính thức được phát hành, các công ty khác có rất ít thời gian để bắt kịp mô hình Sora.
Sam Altman: "Phiên bản video của GPT-1 có ở đây."
JinseFinanceĐây là câu chuyện về cách các nhà đầu tư cá voi (hoặc một nhóm nhà đầu tư) buộc Hợp chất DAO tạo ra doanh thu từ mã thông báo quản trị của nó.
JinseFinanceSOLANA, Đặt lại, Mạng Jito, Solana có cần Đặt lại không? Golden Finance, phân tích ngắn gọn về các sản phẩm mới nhất của Jito.
JinseFinanceMột phân tích chuyên sâu nhưng cân bằng được thực hiện từ nhiều khía cạnh như trạng thái hiện tại của Ethereum, các chất xúc tác tiềm năng, những thay đổi về cung và cầu, v.v., và một suy nghĩ thận trọng nhưng lạc quan có hệ thống được đưa ra cho câu hỏi “liệu giá của Ethereum sắp cất cánh”.
JinseFinanceHai ngày trước, truyền thông nước ngoài đã thực hiện một cuộc phỏng vấn độc quyền với nhóm nòng cốt của Sora, sau khi xem video gốc, gần như không nói gì, khung cảnh giống như một bài phát biểu của Trưởng phòng Mã của Ủy ban Cải cách và Phát triển Quốc gia.
JinseFinanceTrung Quốc gần đây đã phát sóng loạt phim hoạt hình GenAI đầu tiên, "Qianqiu Shisong", thể hiện vai trò của AI trong hoạt hình cùng với các công cụ giống Sora. Động thái này phản ánh nỗ lực tích hợp AI vào truyền thông của Trung Quốc, làm dấy lên những cuộc tranh luận về tác động của nó đối với sự sáng tạo và an ninh việc làm.
 Weatherly
WeatherlyHình ảnh Sora gây sốc đến mức đạo diễn Hollywood vội vàng đóng cửa trường quay trị giá 800 triệu USD.
JinseFinanceKhông lâu sau khi Sora được phát hành, Stable AI đã phát hành Stable Diffusion 3.
JinseFinanceCó bốn cách để tích hợp AI và Web3: sức mạnh tính toán phi tập trung, cộng tác thuật toán và mô hình, dữ liệu lớn phi tập trung và Dapp được hỗ trợ bởi AI.
JinseFinanceNếu dùng tiền ảo để trả lương cho người giúp việc, liệu có rủi ro pháp lý không?
JinseFinance